HunyuanCustom:一种面向多模态驱动的定制化视频生成架构
paper title:HunyuanCustom: A Multimodal-Driven Architecture
for Customized Video Generation
paper是腾讯hunyuan发布在Arxiv 2025的工作
Code:链接
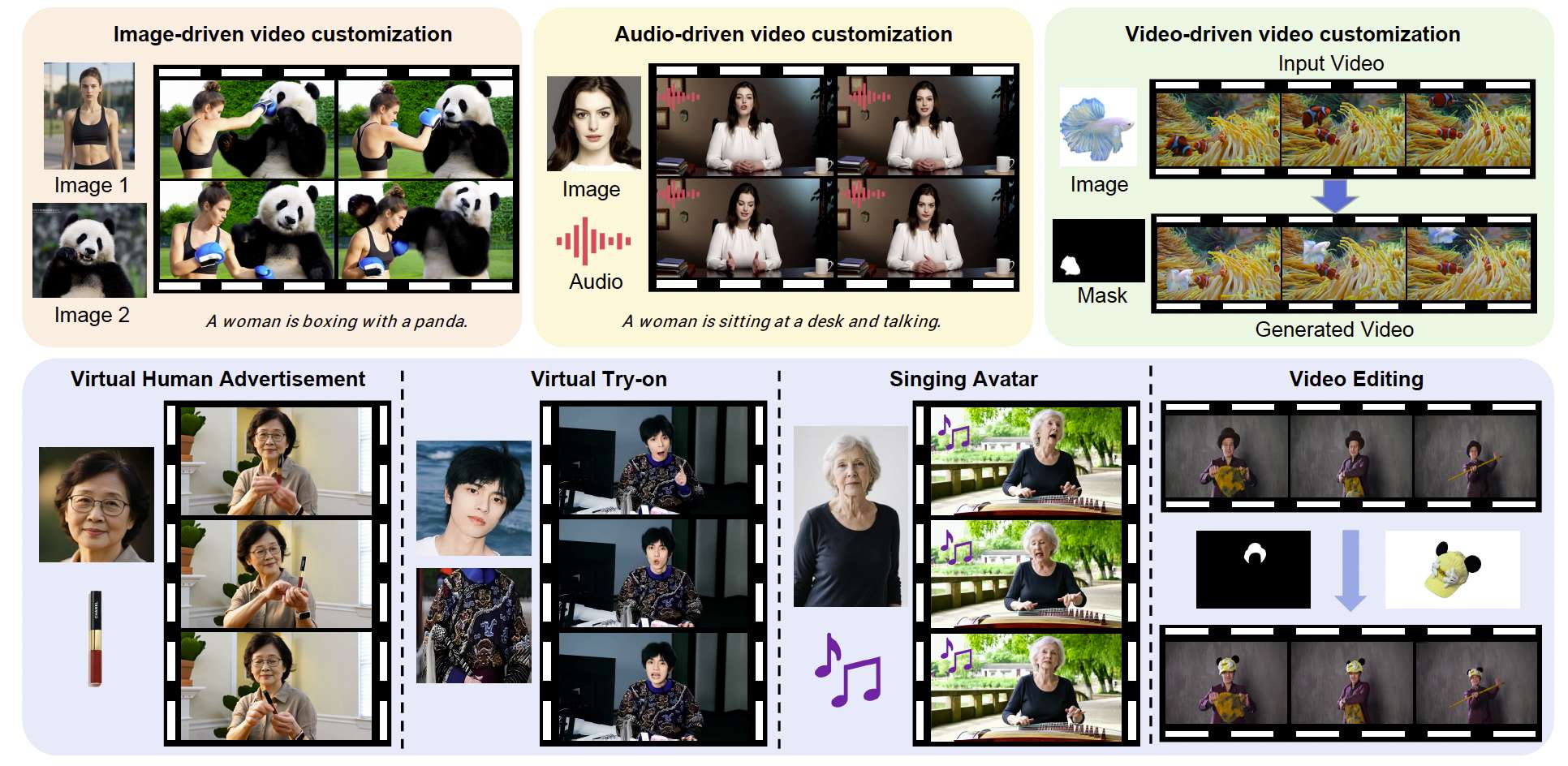
图 1:HunyuanCustom 支持多模态驱动的视频定制,能够基于文本、图像、音频和视频输入生成视频。它适用于广泛的应用场景,如虚拟人广告、虚拟试穿、歌唱头像和视频编辑,大大增强了以主体为中心的视频生成的可控性。
Abstract
定制化视频生成旨在在灵活的用户定义条件下生成包含特定主体的视频,但现有方法常常在身份一致性和输入模态受限方面遇到困难。本文提出了 HunyuanCustom,这是一种多模态定制视频生成框架,强调主体一致性,同时支持图像、音频、视频和文本条件。在 HunyuanVideo 的基础上,我们的模型首先通过引入一个基于 LLaVA 的文本-图像融合模块来提升多模态理解,并通过一个利用时间拼接来强化跨帧身份特征的图像 ID 增强模块,解决了图像-文本条件生成任务。为了支持音频和视频条件生成,我们进一步提出了模态特定的条件注入机制:一个通过空间交叉注意力实现分层对齐的 AudioNet 模块,以及一个通过基于 patchify 的特征对齐网络整合潜在压缩条件视频的视频驱动注入模块。在单主体和多主体场景中的大量实验表明,HunyuanCustom 在身份一致性、真实感和文本-视频对齐方面显著优于现有最先进的开源和闭源方法。此外,我们在下游任务(包括音频和视频驱动的定制视频生成)中验证了其鲁棒性。我们的结果突出了多模态条件和身份保持策略在推进可控视频生成中的有效性。所有代码和模型可在 https://hunyuancustom.github.io 获取。
1 Introduction
近年来,视频生成领域在开源和商业视频生成模型的推动下取得了快速发展。这些进展具有重要的现实意义,从娱乐行业的内容创作到教育、广告等应用都有所涉及 Xu et al., 2025; Hu et al., 2024; Zhou et al., 2024b; Pan et al., 2024; Huang et al., 2024b。然而,一个关键的限制仍然存在:当前模型缺乏精确的可控性。生成严格符合用户特定需求的视频仍然具有挑战性,这限制了它们在需要细粒度定制的真实场景中的潜在应用。
可控视频生成通常聚焦于合成包含特定主体的视频,也称为定制化视频生成。一些现有方法(如 ConsisID Yuan et al., 2024 和 MovieGen Polyak et al., 2025)专门用于生成单一人类 ID 的视频,但无法处理任意对象。其他方法(包括 ConceptMaster Huang et al., 2025、Video Alchemist Chen et al., 2025、Phantom Liu et al., 2025 和 SkyReels-A2 Fei et al., 2025)将这一能力扩展到多主体生成。然而,这些方法在保持主体一致性和视频质量方面表现不佳,并且它们依赖单一模态(图像驱动)输入,限制了更广泛的适用性。最近,VACE Jiang et al., 2025 基于 Wan 视频生成模型 Wang et al., 2025 提出了一个多模态条件视频生成框架。然而,其过多的训练任务削弱了 ID 一致性。因此,在本研究中,我们优先考虑主体一致性生成,并开发了一个能够稳健保持主体一致性的多模态定制化视频生成模型。我们的模型支持多种输入,包括图像身份、音频条件、视频背景和文本提示,实现多模态的主体一致性视频生成。
在这项工作中,我们提出了 HunyuanCustom,这是一个建立在 HunyuanVideo 基础上的视频生成模型,专注于在图像、视频、音频和文本条件下实现主体一致性生成。具体而言,我们的模型首先在文本驱动的条件下,生成与给定图像身份一致的视频。我们提出了一个基于 LLaVA 的文本-图像融合模块,实现文本与图像的交互式整合,以增强模型对两种模态的理解。此外,我们提出了一个图像 ID 增强模块,通过在视频帧之间进行图像信息的时间拼接,利用视频模型在时间序列信息传递上的固有效率,有效地强化了视频的身份一致性。
在主体一致性定制化视频生成框架的基础上,HunyuanCustom 将其能力扩展到音频和视频模态,实现音频驱动的定制视频生成和视频驱动的定制视频生成。为了解耦音频、视频和图像模态,HunyuanCustom 针对音频和视频采用了不同的条件注入机制,从而独立于图像级身份注入模块。对于音频驱动的视频定制,我们提出了 AudioNet,它提取多层次的深度音频特征,并通过空间交叉注意力将其注入到相应的视频特征中,实现分层的音频-视频对齐。对于视频驱动的视频定制,HunyuanCustom 提出了一个条件视频与潜在表示之间的对齐与融合模块。通过 VAE 将给定视频压缩到潜在空间,我们将视频投射到与噪声潜在变量相同的空间。为了补偿清晰视频特征与噪声潜在变量之间的差异,我们设计了一个视频 patchify 模块用于视频-潜在特征对齐。随后,我们引入了一个新的身份解耦视频条件模块,以确保无缝集成,从而实现高效的视频特征注入潜在空间。
HunyuanCustom 在单主体一致性和多主体一致性生成方面进行了严格的评估。我们将其与现有的开源方法和闭源商业软件进行了比较,在 ID 一致性、生成质量和视频-文本对齐等关键指标上进行了全面对比。实验结果表明,HunyuanCustom 在定制化视频生成方面优于所有现有方法。此外,我们通过大量音频驱动和视频驱动的视频定制实验验证了其鲁棒性,突出了该方法的优越性能。凭借强大的身份保持能力和多模态控制能力,HunyuanCustom 在虚拟人广告、虚拟试穿和细粒度视频编辑等实际应用中展现出巨大潜力。这些结果证明了 HunyuanCustom 的有效性,并为未来在可控的、主体一致性的视频生成研究中提供了坚实基础。
2 Related Work
2.1 Video Generation Model
近期的视频生成进展在很大程度上得益于扩散模型,这类模型已经成功地从静态图像合成 Rombach et al., 2022; Li et al., 2024c; Labs, 2024 发展到动态时空建模 Hong et al., 2022; Zhang et al., 2023a。随着大规模框架的出现 Liu et al., 2024; Yang et al., 2024; Kong et al., 2024; Wang et al., 2025; Zhou et al., 2024a,该领域取得了实质性进展,这些框架通过在大规模视频-文本对上进行训练,展现了前所未有的高质量内容生成能力和多样化的生成结果。然而,现有方法主要集中在文本引导的视频生成 Lin et al., 2025 或基于单一参考图像的视频生成 Gao et al., 2023; Xu et al., 2025。这些方法往往难以对生成内容提供细粒度的控制,也难以实现精确的概念驱动编辑。尽管在多条件控制方面已有进展,这一局限性仍然存在。虽然诸如 VACE Jiang et al., 2025 之类的开创性工作通过多模态建模实现了多条件能力,但由于训练任务过多,未能保持身份一致性。在本研究中,我们精心设计了一种多条件驱动的模型,该模型融合了图像、视频、音频和文本等多种模态,同时强调主体一致性生成。
2.2 Video Customization
实例特定的视频定制。实例特定的视频定制方法 Wu et al., 2025; Wang et al., 2024b; He et al., 2024 通常通过使用同一身份的多张图像对预训练的视频生成模型进行微调,其中每个身份都需要单独训练。为了捕捉目标图像的身份信息,Textual Inversion Gal et al., 2022 和 DreamBooth Ruiz et al., 2023 将图像身份信息嵌入到文本空间中,从而实现与文本的有效交互,并促进在对应文本条件下生成目标身份的图像。为了将这些方法扩展到视频生成,Still-Moving Chefer et al., 2024 提出先基于 PEFT 方法微调视频生成模型,使其生成静态帧的视频,然后将图像重复作为静态视频,并利用 DreamBooth 学习目标身份。类似地,CustomCrafter Wu et al., 2025 将图像重复 n 帧后,再通过文本反演嵌入到文本空间中,进一步微调视频生成模型以更好地学习目标身份。CustomVideo Wang et al., 2024b 将定制从单一主体扩展到多主体,通过分割多个主体图像并将它们拼接到一起,再通过与交叉注意力图和主体掩码的对齐,将主体身份绑定到相应文本上。DisenStudio Chen et al., 2024 则将不同主体与注意力区域关联,确保每个主体仅在视频中的特定位置出现,从而为不同主体分配不同的动作。然而,这些方法依赖于实例特定的优化,这在实时或大规模视频定制中带来了挑战。
端到端视频定制。端到端的视频定制方法通过训练一个额外的条件网络,将目标图像的身份信息注入视频生成模型,使其在推理阶段能够泛化到任意身份图像输入,从而显著推进了视频定制的发展。部分已有工作专注于保持人脸身份一致性 He et al., 2024; Yuan et al., 2024; Polyak et al., 2025。例如,ID-Animator He et al., 2024 引入了一个人脸适配器,并结合人脸身份损失来维持人脸 ID 一致性。ConsisID Yuan et al., 2024 通过全局和局部人脸特征提取器从人脸图像中提取低频与高频信息,从而实现全面的身份捕捉。MovieGen Polyak et al., 2025 将人脸 ID 信息注入文本空间,并利用来自不同视频的人脸图像引导视频生成,从而缓解了人脸拷贝问题。为了实现任意对象的定制化,VideoBooth Jiang et al., 2024c 通过粗粒度的 CLIP 特征和细粒度的图像特征注入任意图像的身份信息。近期,包括 ConceptMaster Huang et al., 2025、Video Alchemist Chen et al., 2025、Phantom Liu et al., 2025、SkyReels-A2 Fei et al., 2025 和 VACE Jiang et al., 2025 在内的一些工作,将定制从单一主体扩展到多主体,通过将文本提示中的词语与对应的主体图像绑定,从而生成包含多个主体的视频。然而,由于多个 ID 之间的相互影响以及多主体交互的复杂性,在保持和交互多个主体 ID 方面仍有显著的提升空间。
3 Method
3.1 Overview
HunyuanCustom 是一个以主体一致性为核心的多模态定制生成模型,建立在 Hunyuan Video 生成框架 Li et al., 2024c 之上。它能够在文本、图像、音频和视频输入条件下生成主体一致的视频,如图 2 所示。具体而言,HunyuanCustom 引入了一个基于 LLaVA 的图像-文本融合模块,以促进图像与文本之间的交互,使图像中的身份信息能够有效地融入文本描述中。此外,提出了一个身份增强模块,该模块沿时间轴拼接图像信息,并利用视频模型高效的时间建模能力,在整个视频中增强主体身份。为了支持音频和视频的条件注入,HunyuanCustom 为每种模态设计了独立的注入机制,并与图像级身份条件模块有效解耦。最终,HunyuanCustom 实现了对图像、音频和视频条件的解耦控制,展示了在以主体为中心的多模态视频定制中的巨大潜力。
3.2 Multi-modal task
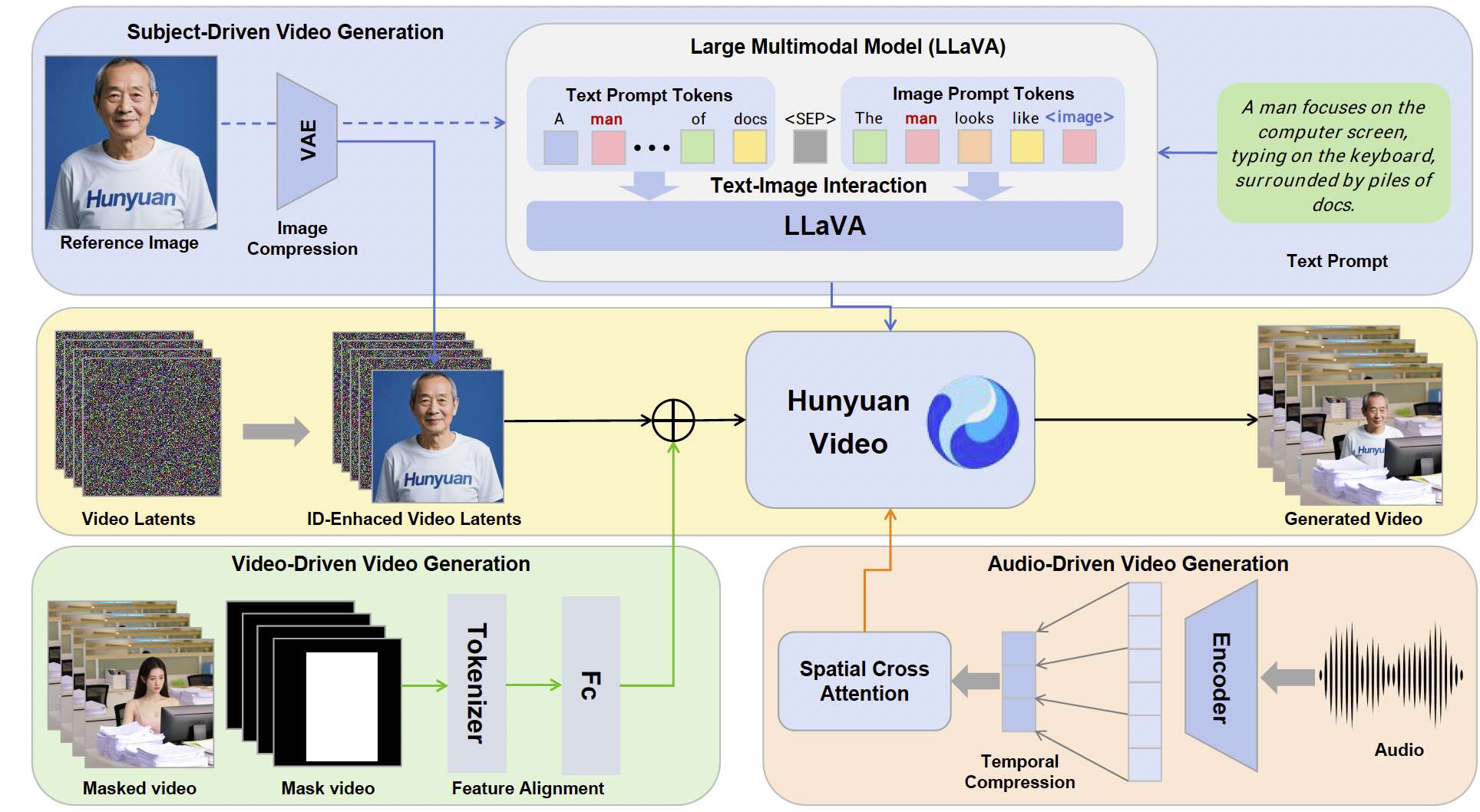
图 2:HunyuanCustom 的主要框架,可以在文本、图像、音频和视频条件下生成身份一致性的视频。
HunyuanCustom 支持来自文本、图像、音频和视频的条件。所有任务都建立在生成身份一致性视频的能力之上,如图 2 所示。这些任务可以分为以下四类:
-
文本驱动的视频生成。文本到视频的生成能力来自基础模型 HunyuanVideo,它支持生成与给定文本提示相一致的视频;
-
图像驱动的视频定制。HunyuanCustom 的核心能力是接收输入图像,提取身份信息,并在文本描述的引导下生成对应身份的视频,从而实现定制化视频生成。HunyuanCustom 支持人类和非人类身份,并进一步允许多个身份作为输入,从而实现涉及多主体的交互式生成;
-
音频驱动的视频定制。在主体定制的基础上,HunyuanCustom 将音频作为额外的模态引入。给定一个人类身份、一个文本提示以及对应的音频,系统能够使该主体在文本描述的语境中执行与音频同步的动作(如讲话、演奏、歌唱)。这扩展了传统的音频驱动人类动画,使指定身份能够在任意场景和动作中自由表现,从而显著增强可控性;
-
视频驱动的视频定制。HunyuanCustom 还支持视频到视频的生成,能够基于身份定制进行对象替换或插入。给定一个源视频和指定目标身份的图像,系统可以将视频中的对象替换为该身份。此外,它还允许在文本引导下将该身份插入到背景视频中,从而实现灵活的对象添加。
3.3 Multi-Modal Data Construction
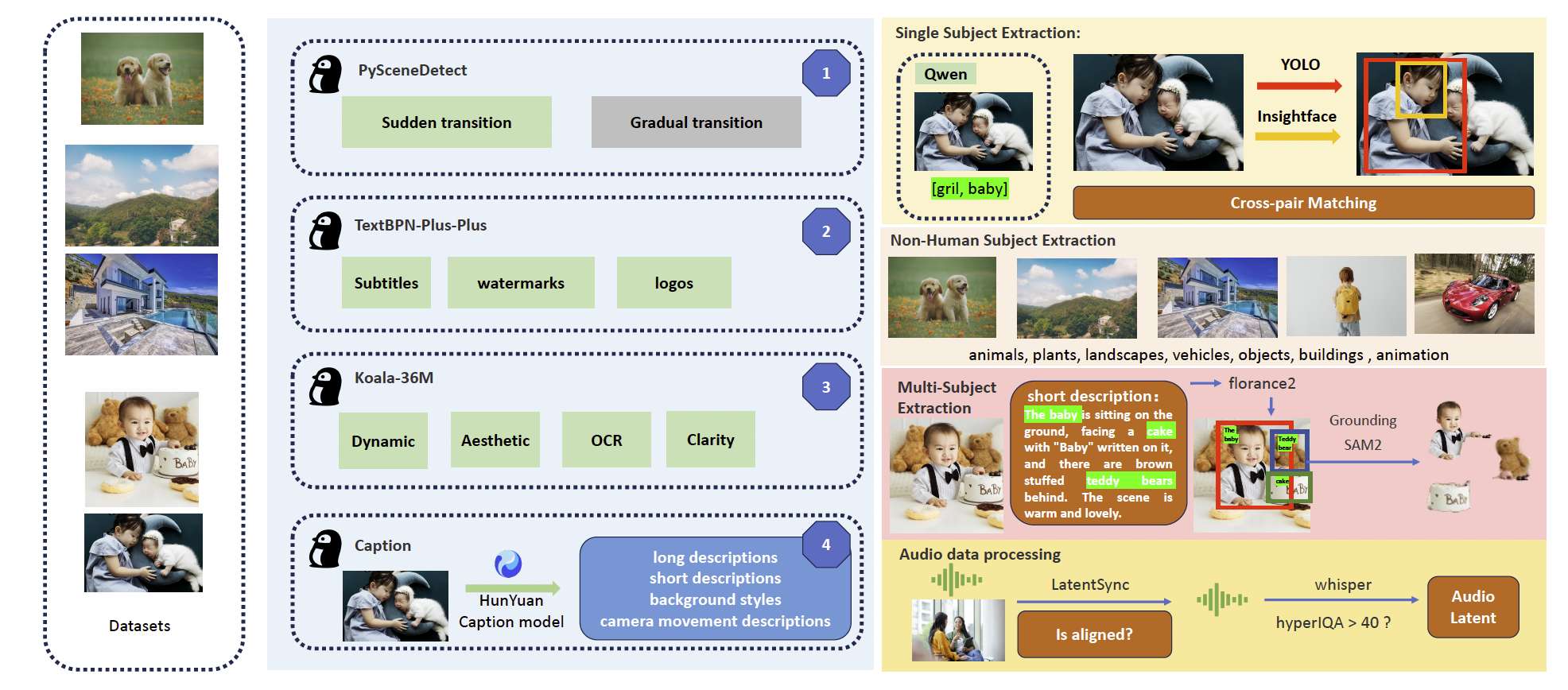
图 3:数据构建流程。
我们的数据经过严格的处理流程,以确保高质量的输入,从而提升模型性能。实验结果表明,高质量数据在主体一致性、视频编辑和音频驱动的视频生成等任务中发挥着关键作用。虽然不同任务可能各自有特定的数据处理步骤,但初始的处理阶段在各任务中是共享的,主要差异在于后续的步骤。基于此,本节深入探讨视频数据准备的详细方法,重点介绍通用的预处理技术,以及针对不同任务设计的任务特定后处理方法。
我们的数据来源多样,并严格遵循《通用数据保护条例》(GDPR)Regulation, 2018 框架所提出的原则。在数据收集过程中,我们采用数据合成和隐私保护计算技术来加以规范。原始数据覆盖了广泛的领域,主要包括八大类别:人类、动物、植物、风景、交通工具、物体、建筑和动漫。除了自采数据外,我们还严格筛选并处理了开源数据集(例如 OpenHumanvid Li et al., 2024b),这极大地扩展了数据分布的多样性并提升了模型性能。实验结果验证了高标准数据的引入对显著提升模型性能至关重要。
数据过滤与预处理。由于我们的数据集分布广泛,其中也包含开源数据,导致视频在时长、分辨率和质量方面差异较大。为解决这些问题,我们实施了一系列预处理技术。首先,为了避免训练数据中的镜头切换,我们使用 PySceneDetect Castellano, 2020 将原始视频切分为单一镜头片段。对于视频中的文本区域,我们采用 textbpn-plus-plus Zhang et al., 2023b 筛除带有大量文字的片段,并裁剪掉包含字幕、水印和 Logo 的视频。由于视频尺寸和时长分布不均,我们进行了裁剪与对齐,将短边标准化为 512 或 720 像素,并将视频长度限制在 5 秒(129 帧)以内。最后,考虑到 PySceneDetect 无法检测渐变过渡,textbpn-plus-plus Zhang et al., 2023b 对检测小文本的能力有限,同时还需保证美学质量、运动幅度和场景亮度,我们使用 koala-36M Wang et al., 2024a 模型进行进一步筛选。然而,由于 koala-36M Wang et al., 2024a 的训练数据与我们的数据集存在差异,且缺乏对美学质量和运动幅度的精细评估,我们制定了自有的评估标准,设定 0.06 的 koala 阈值专门用于本数据集的精细过滤。实验结果确认了我们在数据选择与处理方法上的重要性,它们有效提升了模型性能。
主体提取。单主体提取:为了从视频中提取主要主体,我们首先使用 Qwen7B Bai et al., 2023 模型对每帧中的所有主体进行标注并提取其 ID。随后,采用聚类算法(如并查集 Union-Find)计算每个 ID 在帧中的出现频率,选择出现次数最多的 ID 作为目标主体。如有需要,也可以选择多个 ID;但如果所有 ID 的出现次数均低于预设阈值(例如 50 帧),则该视频被丢弃。接着,我们使用 YOLO11X Khanam and Hussain, 2024 进行人体分割以获得人体边界框,并利用 InsightFace Ren et al., 2023 检测人脸位置并生成面部边界框。如果人脸边界框在人体边界框中的比例小于 0.5,则认为 YOLO11X 的检测结果有误,相应的边界框将被丢弃。
非人类主体提取:对于非人类主体,我们使用 QwenVL Bai et al., 2025b 从视频中提取主体关键词,并采用 GroundingSAM2 Ravi et al., 2024; Liu et al., 2023b; Ren et al., 2024a,b; Jiang et al., 2024b 基于这些关键词生成掩码和边界框。如果边界框的大小小于原始视频尺寸的 0.3 倍,则该框被丢弃。为了确保训练数据的类别分布均衡,我们利用 QwenVL 将主要主体分类为八个预定义类别:动物、植物、风景、交通工具、物体、建筑和动漫。随后在这些类别间进行均衡采样,以实现公平的分布。
多主体提取:在多主体场景中,我们使用 QwenVL 从单人数据集中筛选包含人与物体交互的视频。由于需要对齐视频字幕中的主体关键词与图像中的关键词,若直接使用 QwenVL 重新提取主体关键词,可能导致与视频提示中的关键词不一致。因此,我们采用 Florence2 Xiao et al., 2024 提取视频字幕中提到的所有主体的边界框。随后,使用 GroundingSAM2 对这些边界框区域进行主体提取。接着,我们应用聚类方法去除未包含所有主体的帧。为了解决"硬拷贝"问题,我们在训练模型时使用视频的前 5 秒,而将后 15 秒用于主体分割。
视频分辨率标准化:我们首先基于所有主体的边界框计算联合边界框,并确保裁剪区域至少包含联合边界框面积的 70%。为了使模型支持多分辨率输出,我们定义了多种宽高比,包括 1:1、3:4 和 9:16。
视频标注:我们使用由 HunYuan 团队开发的结构化视频标注模型对视频进行标注。该模型提供了详细的描述信息,包括长描述、短描述、背景风格和相机运动描述。在训练过程中,这些结构化标注被用于增强视频字幕,从而提升模型的鲁棒性和性能。
掩码数据增强:在视频编辑中,直接使用提取的主体掩码进行训练,在替换不同类型或形状的对象时可能导致过拟合。例如,将一个没有耳朵的玩偶替换成有耳朵的玩偶时,生成的视频可能仍然显示没有耳朵的玩偶,这不是期望的结果。因此,在训练过程中,我们采用掩码膨胀或将掩码转换为边界框等技术来柔化掩码边界。这些方法有助于在最终视频中实现更逼真且符合预期的编辑效果。通过采用这些增强策略,我们旨在缓解过拟合问题,确保编辑后的视频更符合预期,从而提升模型在不同类型和形状对象上的灵活性与适用性。
音频数据处理:我们首先使用 LatentSync Li et al., 2024a 评估音频与视频在片段中的同步性。具体而言,我们丢弃同步置信度评分低于 3 的视频,并将音视频偏移调整为 0。同时,我们计算 hyperIQA 质量评分,并移除评分低于 40 的视频,以确保数据质量。最后,我们使用 Whisper Radford et al., 2023 提取音频特征,这些特征将作为后续模型训练的输入。
3.4 Image-driven Video Customization
HunyuanCustom 的核心任务是基于输入图像 I(表示特定身份)和文本描述 T 生成视频。关键挑战在于如何让模型有效理解图像中蕴含的身份信息,并将其与文本语境结合,实现交互式理解。为此,HunyuanCustom 引入了一个基于 LLaVA 的图像-文本交互模块,用于联合建模视觉与文本输入,从而增强模型对身份和描述信息的理解。此外,还提出了一个身份增强模块,用于在视频序列中传播图像提取的特征,借助视频模型的时间建模能力,在生成视频的全过程中强化身份一致性。
基于 LLaVA 的图像-文本交互。在视频定制的背景下,有效整合图像与文本信息一直是以往方法中的关键难点 Fei et al., 2025; Jiang et al., 2025; Liu et al., 2025。这些方法要么缺乏图像与文本之间交互理解的设计,要么依赖额外新训练的分支网络来实现交互。HunyuanCustom 则充分利用了 Hunyuan Video Kong et al., 2024 在 LLaVA Liu et al., 2023a 文本空间中训练的文本理解能力,并借助 LLaVA 固有的多模态交互理解能力。通过将 HunyuanVideo 的原始文本输入扩展为同时包含图像和文本输入,HunyuanCustom 基于 LLaVA 卓越的多模态理解能力,实现了有效的图像-文本交互式理解。
具体来说,给定一个文本输入 T T T和一个图像输入 I I I,其中在文本中包含相应的描述词 T I T_I TI,我们设计了一种模板以促进文本与图像之间的交互。我们探索了两种类型的模板:(1) 图像嵌入模板,其中文本中的描述词 T I T_I TI被替换为图像标记<image>(例如,对于文本提示"A man is playing guitar",如果我们输入"man"的身份图像,结果模板为"A <image> is playing guitar");(2) 图像附加模板,其中图像标记放置在文本提示之后,通过添加身份提示"The T I T_I TI looks like <image>"(例如,对于文本提示"A man is playing guitar",结果模板为"A man is playing guitar. The man looks like <image>")。在处理之后,图像标记<image>被LLaVA提取的 24 × 24 24 \times 24 24×24隐藏图像特征所替代。由于图像特征标记显著多于文本特征标记,为防止图像特征过度影响文本理解,我们在文本提示和图像提示之间插入一个特殊标记<SEP>。这有助于LLaVA模型在建立文本提示与图像身份之间联系的同时,保留来自文本提示的信息。
身份增强。LLaVA模型作为一个多模态理解框架,旨在捕捉文本与图像之间的相关性,主要提取类别 、颜色 和形状 等高级语义 信息,而常常忽略文本 和纹理 等细节 。然而,在视频定制中,身份在很大程度上由这些图像细节决定,这使得仅依靠LLaVA分支不足以保持身份。为了解决这个问题,我们提出了一个身份增强模块。通过在时间轴上拼接视频潜变量与目标图像,并利用视频模型在时间维度上高效的信息传递能力,我们可以有效地增强视频的身份一致性。
具体来说,我们首先调整图像大小以匹配视频帧的尺寸。然后,我们采用HunyuanVideo的预训练因果3DVAE将图像 I I I从图像空间映射到潜在空间。通过得到图像潜变量 z I ∈ R w h × c z_I \in \mathbb{R}^{wh \times c} zI∈Rwh×c(其中 w h wh wh表示潜变量的宽度和高度, c c c是特征维度),我们将其与视频潜变量 z t ∈ R f w h × c z_t \in \mathbb{R}^{fwh \times c} zt∈Rfwh×c(其中 f f f是视频帧数)在第一个序列维度上拼接,以获得新的潜变量
z = { z I , z t } ∈ R ( f + 1 ) w h × c . z = \{z_I, z_t\} \in \mathbb{R}^{(f+1)wh \times c}. z={zI,zt}∈R(f+1)wh×c.
鉴于预训练的HunyuanVideo在建模时间信息上的强先验,身份信息可以沿时间轴高效传播。因此,我们为拼接后的图像潜变量分配一个沿时间序列的3D-RoPE Su et al., 2024。在原始HunyuanVideo中,视频潜变量被分配一个沿时间、宽度和高度轴的3D-RoPE;对于位于 ( f , i , j ) (f,i,j) (f,i,j)的像素(其中 f f f是帧索引, i i i是宽度, j j j是高度),它接收一个 R o P E ( f , i , j ) RoPE(f,i,j) RoPE(f,i,j)。对于图像潜变量,为了实现身份在时间序列上的有效传播,我们将图像潜变量定位在第 − 1 -1 −1帧,即在时间索引为0的第一帧之前。此外,受Omnicontrol Tan et al., 2024的启发,在可控图像生成中,为了防止模型简单地将目标图像复制粘贴到生成的帧中,我们为图像潜变量引入空间位移:
R o P E z I ( f , i , j ) = R o P E ( − 1 , i + w , j + h ) . (1) RoPE_{z_I}(f,i,j) = RoPE(-1,i+w,j+h). \tag{1} RoPEzI(f,i,j)=RoPE(−1,i+w,j+h).(1)
多主体定制。对于多主体定制,我们使用已训练的单主体定制模型作为基础,并在此基础上进行微调以适应多主体定制任务。具体而言,我们有若干条件图像 { I 1 , I 2 , ... , I m } \{I_1, I_2, \ldots, I_m\} {I1,I2,...,Im},每个图像都对应有相应的文本描述 { T I , 1 , T I , 2 , ... , T I , m } \{T_{I,1}, T_{I,2}, \ldots, T_{I,m}\} {TI,1,TI,2,...,TI,m}。对于每张图像,我们将其模板化为"the T I , k T_{I,k} TI,k looks like <image>",并使用LLaVA模型建模文本与图像的相关性。此外,为了增强图像身份,我们使用3D-VAE将所有图像编码到潜在空间中,以获得图像潜变量 { z I , 1 , z I , 2 , ... , z I , m } \{z_{I,1}, z_{I,2}, \ldots, z_{I,m}\} {zI,1,zI,2,...,zI,m},然后将它们与视频潜变量拼接。为了区分不同身份的图像,我们为第 k k k张图像分配时间索引 − k -k −k,其与3D-RoPE关联:
R o P E z I , k ( f , i , j ) = R o P E ( − k , i + w , j + h ) . (2) RoPE_{z_{I,k}}(f,i,j) = RoPE(-k,i+w,j+h). \tag{2} RoPEzI,k(f,i,j)=RoPE(−k,i+w,j+h).(2)
训练过程。在训练过程中,我们采用 Flow Matching Lipman et al., 2022 框架来训练视频生成模型。训练时,我们首先获取视频潜在表示 z 1 z_1 z1以及对应的身份图像 I I I。然后,从logit-normal分布 Esser et al., 2024 中采样 t ∈ 0 , 1 t \in 0,1 t∈0,1,并根据高斯分布初始化噪声 z 0 ∼ N ( 0 , I ) z_0 \sim N(0,I) z0∼N(0,I)。之后,我们通过线性插值构造训练样本 z t z_t zt。模型的目标是预测速度
u t = d z t d t u_t = \frac{dz_t}{dt} ut=dtdzt
并以目标图像 I I I为条件,指导样本 z t z_t zt向 z 1 z_1 z1逼近。模型参数通过最小化预测速度 v t v_t vt与真实速度 u t u_t ut之间的均方误差来优化,损失函数定义为:
L g e n e r a t i o n = E t , x 0 , x 1 ∥ v t − u t ∥ 2 . (3) \mathcal{L}{generation} = \mathbb{E}{t, x_0, x_1} \| v_t - u_t \|^2. \tag{3} Lgeneration=Et,x0,x1∥vt−ut∥2.(3)
为了赋予模型更强的表示能力,并使其能够捕捉和学习更广泛的复杂模式,我们对预训练视频生成模型和LLaVA模型的权重进行全面微调,从而最大限度地释放其在视频定制中的潜力,提供更优质的生成结果。
4 Multimodal subject-centric video generation
以往的视频定制方法 Yuan et al., 2024, Huang et al., 2025, Fei et al., 2025, Liu et al., 2025 主要关注于保持主体身份,而缺乏对主体驱动的视频生成的进一步探索。我们进一步研究了以多模态的音频-视频信息作为条件,并以主体身份为核心,从而实现由图像-音频-视频共同驱动的主体特定生成。
4.1 Audio-driven video customization
音频驱动的视频定制。音频是视频生成中不可或缺的组成部分,大量研究致力于将音频作为条件来驱动视频创作。其中,音频驱动的人体动画是一个重要的研究课题。现有的音频驱动人体动画模型 Jiang et al., 2024a, Ji et al., 2024 通常以人物图像和音频作为输入,使图像中的人物生成对应语音的说话动作。然而,这种图像到视频的范式会导致生成的视频中人物的姿势、服饰和场景与输入图像保持一致,从而限制了目标人物在不同姿势、服饰和场景下的视频生成能力。这一局限性制约了其应用。借助 HunyuanCustom 在有效捕捉和保持人物身份信息方面的能力,我们进一步融合音频输入,使得人物能够在文本描述的场景中说出对应的音频,从而实现更加灵活和可控的语音驱动数字人生成,我们称之为音频驱动的视频定制。
身份解耦的 AudioNet。为了有效地将音频信号与身份信息解耦,我们提出了身份解耦的 AudioNet。正如第 3 节所述,身份信息主要通过 LLaVA 在文本模态中注入,以及通过在潜在时间维度上的 token 拼接来注入。为了确保解耦的音频条件,AudioNet 采用了一种替代的条件机制,以避免与身份线索的纠缠。给定一个长度为 f ′ f' f′的音频视频序列,我们首先为每个音频帧提取音频特征,得到一个大小为 f ′ × 4 × c f' \times 4 \times c f′×4×c的张量,其中4表示每个音频帧的token数量。由于视频潜在表示通过VAE被时间压缩为 f f f帧
f = ⌊ f ′ 4 ⌋ + 1 , f = \left\lfloor \frac{f'}{4} \right\rfloor + 1, f=⌊4f′⌋+1,
其中1对应于未压缩的初始帧,4是时间压缩比,ID增强的视频潜变量由于在开头插入身份图像而包含 f + 1 f+1 f+1帧。为了在时间上将音频特征与压缩后的视频潜变量对齐,我们首先在初始帧之前填充音频特征,以匹配 ( f + 1 ) × 4 (f+1)\times 4 (f+1)×4帧。然后我们将每4个连续的音频帧聚合为一个单帧,形成一个新的音频特征张量 f A f_A fA,该张量在时间上与视频潜在表示对齐:
f A = R e a r r a n g e ( f A , 0 ) : b , ( f + 1 ) × 4 , 4 , c → b , ( f + 1 ) , 16 , c . (4) f_A = Rearrange(f_{A,0}): b,(f+1)\\times 4,4,c \to b,(f+1),16,c. \tag{4} fA=Rearrange(fA,0):b,(f+1)×4,4,c→b,(f+1),16,c.(4)
利用时间对齐的音频特征 f A f_A fA,我们采用交叉注意力模块将音频信息注入视频潜变量 z t z_t zt。为了防止音频和视频在不同帧之间产生帧间干扰,我们采用了一种空间交叉注意力机制,在逐帧的基础上执行音频注入。具体而言,我们将视频潜变量中的时间维度与空间维度解耦,并仅在空间轴(宽度 w w w和高度 h h h)上应用交叉注意力:
z t , A ′ = R e a r r a n g e ( z t ) : b , ( f + 1 ) w h , c → b , f + 1 , w h , c z'{t,A} = Rearrange(z_t): b,(f+1)wh,c \to b,f+1,wh,c zt,A′=Rearrange(zt):b,(f+1)wh,c→b,f+1,wh,c
z t , A ′ ′ = z t , A ′ + λ A × C r o s s A t t n ( f A , z t ′ ) z''{t,A} = z'{t,A} + \lambda_A \times CrossAttn(f_A,z'{t}) zt,A′′=zt,A′+λA×CrossAttn(fA,zt′)
z t , A = R e a r r a n g e ( z t , A ′ ′ ) : b , f + 1 , w h , c → b , ( f + 1 ) w h , c , (5) z_{t,A} = Rearrange(z''_{t,A}): b,f+1,wh,c \to b,(f+1)wh,c, \tag{5} zt,A=Rearrange(zt,A′′):b,f+1,wh,c→b,(f+1)wh,c,(5)
其中 λ A \lambda_A λA是控制音频特征影响权重的系数。
4.2 Video-driven video customization
在实际的视频创作中,编辑是一项基础任务,通常涉及修改视频中主体的外观和动作。这与 HunyuanCustom 的主体生成能力自然契合,使其能够实现主体级别的编辑,例如替换和插入。视频包含丰富的时空信息,这在有效内容提取和高效集成到生成模型中都带来了挑战。现有方法(如 VACE Jiang et al., 2025)通过适配器模块注入视频条件,这会使计算成本翻倍,严重限制效率。其他方法 Bai et al., 2025a 将条件视频和生成视频的潜变量在时间轴上进行拼接,导致序列长度翻倍,注意力计算呈二次增长。为克服这些限制,HunyuanCustom 采用了一种更高效的视频条件注入策略,将视频信息与图像和音频模态解耦。具体而言,它首先利用预训练的因果 3D-VAE 对条件视频进行压缩,通过特征对齐将得到的特征与噪声视频潜变量对齐,然后直接将对齐后的特征加入视频潜在表示。这种方式能够高效且有效地引入视频条件,而不会产生显著的计算开销。
视频潜在特征对齐。条件视频作为一个干净的、无噪声的输入,而视频潜变量则来自一个带噪声的编码过程。为了改进视频条件注入,我们首先在条件视频与视频潜变量之间进行特征对齐。具体而言,条件视频通过预训练的因果 3D-VAE 编码器进行编码,然后通过 HunyuanVideo 中的预训练视频分词器进行压缩和序列化。接着,一个四层全连接网络将条件视频特征映射到潜在空间,实现与视频潜变量的对齐。
身份解耦的视频条件注入。我们探索了两种将条件视频注入预训练视频生成模型的策略。第一种是将条件视频特征与视频潜变量在 token 维度上拼接,然后进行维度压缩,将结果投影回原始潜在空间。第二种是沿时间维度逐帧地将条件视频特征直接添加到视频潜变量中,从而保持原始特征维度。在这两种情况下,条件后的潜变量与原始视频潜变量保持相同的形状,在推理过程中不会引入额外的计算开销。我们的实验表明,基于拼接的方法难以保持内容信息,并存在严重的信息丢失。相比之下,基于相加的方法能够实现更有效的内容注入。得益于先前的特征对齐步骤,条件视频特征与视频潜变量能够很好地匹配,从而促进高效的融合和信息传递,进而支持有效且轻量化的视频条件注入。