大模型技术正从实验室走向产业界,成为驱动业务创新的核心引擎。然而,大模型落地并非简单的 "拿来主义",需要结合业务场景进行系统性设计。本文将围绕大模型微调 、提示词工程 、多模态应用 、企业级解决方案四大核心方向,通过代码实例、流程图解、Prompt 模板等形式,提供一套可落地的技术方案,帮助企业快速实现大模型价值转化。
一、大模型微调:定制化模型的核心路径
大模型微调是基于预训练大模型,通过业务数据进行二次训练,使模型具备场景化能力的关键技术。根据数据规模和业务需求,微调可分为全参数微调、LoRA 微调、Prefix Tuning 等多种方式,不同方案在效果、成本、效率上存在显著差异。
1.1 微调方案选型决策
选择合适的微调方案是项目成功的第一步,需综合评估数据量、计算资源、效果要求三大维度。
1.1.1 微调方案对比表
| 微调方案 | 数据需求 | 计算资源 | 效果表现 | 适用场景 | 代表框架 |
|---|---|---|---|---|---|
| 全参数微调 | 10 万 + 样本 | 8×A100 以上 | 最佳 | 核心业务、高精准度需求 | Hugging Face Trainer |
| LoRA 微调 | 1 万 - 10 万样本 | 1×A10 以上 | 优秀 | 垂直领域、中等数据量 | PEFT、LoRA-Llama |
| Prefix Tuning | 5 千 - 5 万样本 | 1×T4 以上 | 良好 | 文本生成、小数据场景 | PrefixTuning 库 |
| Prompt Tuning | 1 千 - 1 万样本 | 1×T4 以上 | 一般 | 分类任务、数据稀缺 | Hugging Face PEFT |
1.1.2 微调方案选型流程图
flowchart TD
A[开始:微调需求分析] --> B{数据量评估}
B -->|>10万样本| C[全参数微调]
B -->|1万-10万样本| D[LoRA微调]
B -->|5千-5万样本| E[Prefix Tuning]
B -->|<1万样本| F[Prompt Tuning]
C --> G[评估计算资源]
D --> G
E --> G
F --> G
G -->|资源充足| H[效果优先方案]
G -->|资源有限| I[效率优先方案]
H --> J[确定微调方案]
I --> J
J --> K[数据预处理]
K --> L[模型训练]
L --> M[效果评估]
M -->|达标| N[模型部署]
M -->|不达标| O[方案迭代优化]
O --> B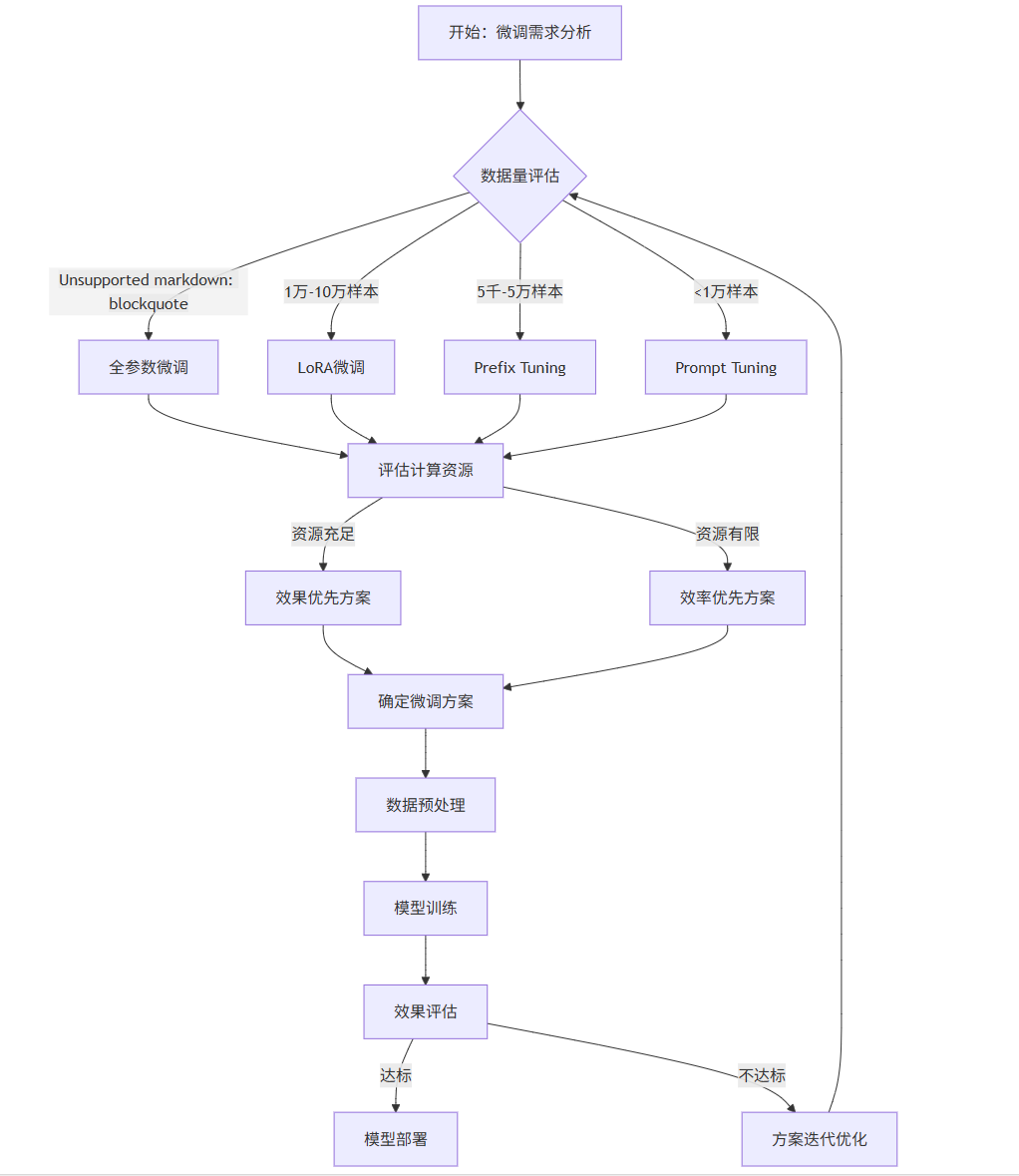
1.2 LoRA 微调实战(代码示例)
LoRA(Low-Rank Adaptation)是当前最流行的微调方案,通过冻结预训练模型参数,仅训练低秩矩阵,实现高效微调。以下以金融领域情感分析任务为例,展示基于 Llama 2 的 LoRA 微调过程。
1.2.1 环境配置
python
运行
# 安装必要依赖库
!pip install transformers datasets peft accelerate bitsandbytes evaluate
import torch
import evaluate
import numpy as np
from datasets import load_dataset
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
Trainer,
TrainingArguments,
BitsAndBytesConfig
)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")1.2.2 量化配置(降低显存占用)
python
运行
# 4-bit量化配置,适用于显存有限场景
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# 加载预训练模型和Tokenizer
model_name = "meta-llama/Llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # 设置pad token
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
quantization_config=bnb_config,
num_labels=2, # 二分类:正面/负面
device_map="auto"
)
# 准备模型用于kbit训练
model = prepare_model_for_kbit_training(model)1.2.3 LoRA 参数配置
python
运行
# LoRA配置
lora_config = LoraConfig(
r=8, # 秩,控制低秩矩阵维度
lora_alpha=32, # 缩放因子
target_modules=["q_proj", "v_proj"], # 目标模块,Llama 2的注意力层
lora_dropout=0.05,
bias="none",
task_type="SEQ_CLS" # 序列分类任务
)
# 应用LoRA适配器
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 打印可训练参数比例
# 输出示例:trainable params: 1,179,648 || all params: 6,742,609,920 || trainable%: 0.01751.2.4 数据预处理
python
运行
# 加载金融情感分析数据集(示例使用自定义数据集)
def load_financial_dataset(data_path):
dataset = load_dataset("csv", data_files={"train": f"{data_path}/train.csv", "test": f"{data_path}/test.csv"})
# 数据预处理函数
def preprocess_function(examples):
return tokenizer(
examples["text"],
truncation=True,
max_length=512,
padding="max_length"
)
# 应用预处理
tokenized_dataset = dataset.map(
preprocess_function,
batched=True,
remove_columns=["text"] # 移除原始文本列
)
# 重命名标签列
tokenized_dataset = tokenized_dataset.rename_column("label", "labels")
# 转换为PyTorch格式
tokenized_dataset.set_format("torch", columns=["input_ids", "attention_mask", "labels"])
return tokenized_dataset
# 加载数据
dataset = load_financial_dataset("./financial_sentiment_data")
train_dataset = dataset["train"]
eval_dataset = dataset["test"]
# 查看数据样例
print(f"训练集规模: {len(train_dataset)}")
print(f"测试集规模: {len(eval_dataset)}")
print(f"数据格式: {train_dataset[0].keys()}")1.2.5 训练配置与执行
python
运行
# 评估指标
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return accuracy.compute(predictions=predictions, references=labels)
# 训练参数配置
training_args = TrainingArguments(
output_dir="./llama2-financial-sentiment",
learning_rate=2e-4,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
num_train_epochs=3,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
fp16=True, # 混合精度训练
logging_dir="./logs",
logging_steps=10,
report_to="none"
)
# 初始化Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics
)
# 开始训练
model.config.use_cache = False # 禁用缓存以支持训练
trainer.train()
# 保存LoRA适配器
model.save_pretrained("llama2-financial-sentiment-lora")1.2.6 模型推理与效果验证
python
运行
# 加载微调后的LoRA模型
from peft import PeftModel, PeftConfig
peft_model_id = "llama2-financial-sentiment-lora"
config = PeftConfig.from_pretrained(peft_model_id)
# 加载基础模型
base_model = AutoModelForSequenceClassification.from_pretrained(
config.base_model_name_or_path,
num_labels=2,
device_map="auto",
quantization_config=bnb_config
)
# 加载LoRA适配器
fine_tuned_model = PeftModel.from_pretrained(base_model, peft_model_id)
# 推理函数
def predict_sentiment(text):
inputs = tokenizer(
text,
return_tensors="pt",
truncation=True,
max_length=512,
padding="max_length"
).to(device)
with torch.no_grad():
outputs = fine_tuned_model(**inputs)
logits = outputs.logits
predicted_class_id = torch.argmax(logits, dim=1).item()
sentiment = "正面" if predicted_class_id == 1 else "负面"
return {"text": text, "sentiment": sentiment, "confidence": torch.softmax(logits, dim=1)[0][predicted_class_id].item()}
# 测试样例
test_cases = [
"本季度公司营收同比增长20%,净利润超市场预期",
"受宏观经济影响,公司核心业务板块出现15%的下滑",
"新产品上线后用户活跃度提升30%,市场份额进一步扩大"
]
for case in test_cases:
result = predict_sentiment(case)
print(f"文本: {result['text']}")
print(f"情感: {result['sentiment']} (置信度: {result['confidence']:.4f})\n")1.3 微调效果评估体系
建立科学的评估体系是验证微调效果的关键,需从功能正确性 、性能指标 、业务指标三个维度进行全面评估。
1.3.1 评估指标体系表
| 评估维度 | 核心指标 | 计算方式 | 目标值 | 业务意义 |
|---|---|---|---|---|
| 功能正确性 | 准确率(Accuracy) | 正确预测数 / 总样本数 | >90% | 模型基础预测能力 |
| 功能正确性 | 精确率(Precision) | 真阳性 /(真阳性 + 假阳性) | >85% | 避免误判的能力 |
| 功能正确性 | 召回率(Recall) | 真阳性 /(真阳性 + 假阴性) | >85% | 覆盖正确样本的能力 |
| 功能正确性 | F1 分数 | 2*(精确率 * 召回率)/(精确率 + 召回率) | >85% | 综合评价指标 |
| 性能指标 | 推理延迟 | 单条请求平均响应时间 | <500ms | 用户体验保障 |
| 性能指标 | 吞吐量 | 单位时间处理请求数 | >100 QPS | 系统承载能力 |
| 性能指标 | 显存占用 | 推理时 GPU 显存使用 | <10GB | 资源成本控制 |
| 业务指标 | 业务转化率 | 模型输出驱动的业务转化 | 提升 10%+ | 业务价值体现 |
| 业务指标 | 人工审核率 | 需要人工干预的比例 | <5% | 自动化效率 |
1.3.2 微调效果对比图
barChart
title 不同微调方案效果对比(金融情感分析任务)
x-axis 微调方案 [预训练模型, Prompt Tuning, LoRA微调, 全参数微调]
y-axis F1分数 (%)
series
F1分数 [65.2, 78.5, 92.3, 94.1]
推理延迟(ms) [120, 150, 280, 450]
显存占用(GB) [8.5, 8.8, 10.2, 24.5]二、提示词工程:释放大模型潜能的艺术
提示词工程(Prompt Engineering)是通过精心设计输入文本,引导大模型产生高质量输出的技术。在数据稀缺或无需微调的场景中,优秀的提示词设计可显著提升模型性能,是大模型落地的 "轻量型" 解决方案。
2.1 提示词设计核心原则
有效的提示词设计需遵循五大核心原则,这些原则是构建高质量 Prompt 的基础。
- 明确任务目标:清晰定义模型需要完成的具体任务,避免模糊表述
- 提供上下文信息:补充与任务相关的背景信息,帮助模型理解场景
- 设定输出格式:指定输出的结构、格式、长度等要求,确保结果可用性
- 添加示例演示:通过少量示例(Few-shot Learning)展示期望输出
- 优化指令表述:使用精确、简洁的语言,避免歧义或冗余信息
2.2 提示词模板库(按场景分类)
不同业务场景需要不同结构的提示词,以下提供六大核心场景的 Prompt 模板,可直接复用或修改使用。
2.2.1 文本分类模板
plaintext
# 任务:客户反馈情感分类
# 背景:你是一家电商平台的客服助手,需要对客户反馈进行情感分类,用于后续服务优化。
# 分类标准:
- 正面情感:包含表扬、满意、推荐、肯定等积极表述
- 负面情感:包含投诉、不满、批评、失望等消极表述
- 中性情感:仅陈述事实,无明显情感倾向
# 输出格式:
反馈文本:[客户反馈内容]
情感分类:[正面/负面/中性]
分类理由:[简要说明分类依据,50字以内]
# 示例:
反馈文本:商品质量很好,物流也很快,下次还会购买
情感分类:正面
分类理由:客户明确表达了对商品质量和物流的满意,有复购意愿
# 待分类反馈:
反馈文本:{{客户反馈内容}}2.2.2 信息提取模板
plaintext
# 任务:简历关键信息提取
# 背景:你是人力资源专员,需要从候选人简历文本中提取关键信息,用于初步筛选。
# 需要提取的字段:
1. 姓名:候选人的全名
2. 年龄:候选人的年龄或出生年份
3. 学历:最高学历(如本科、硕士、博士)
4. 专业:相关专业背景
5. 工作经验:总工作年限及关键岗位经历
6. 核心技能:专业技能、工具掌握、证书等
7. 期望薪资:明确提及的薪资要求
# 输出格式:
{
"姓名": "xxx",
"年龄": "xxx",
"学历": "xxx",
"专业": "xxx",
"工作经验": "xxx",
"核心技能": ["xxx", "xxx", "xxx"],
"期望薪资": "xxx"
}
# 注意事项:
- 若某字段未提及,填写"未明确"
- 提取信息需准确,不得添加原文中没有的内容
- 工作经验需包含具体年限和关键岗位名称
# 简历文本:
{{简历内容}}2.2.3 代码生成模板
plaintext
# 任务:Python数据分析代码生成
# 背景:你是数据分析师,需要根据业务需求生成Python数据分析代码,使用pandas和matplotlib库。
# 业务需求:
1. 数据读取:读取CSV格式的数据文件,文件路径为"{{file_path}}"
2. 数据清洗:
- 处理缺失值(数值型字段用均值填充,字符型字段用"未知"填充)
- 处理异常值(使用3σ原则识别并替换为边界值)
3. 数据分析:
- 计算各数值字段的描述性统计(均值、中位数、标准差)
- 分析{{target_column}}与其他字段的相关性
4. 数据可视化:
- 绘制{{target_column}}的分布直方图
- 绘制{{target_column}}与{{correlation_column}}的散点图
5. 结果保存:将分析结果保存到"analysis_result.xlsx"
# 输出要求:
- 代码需包含详细注释,说明每一步的功能
- 处理可能出现的异常(如文件不存在、字段不存在)
- 使用规范的变量命名和代码格式
- 输出完整可运行的Python代码
# 开始生成代码:2.2.4 客户服务模板
plaintext
# 任务:客户投诉处理回复
# 背景:你是某电信运营商的客服代表,需要针对客户的网络问题投诉,生成专业、友好的回复。
# 回复原则:
1. 态度诚恳:首先表达歉意,理解客户的困扰
2. 信息明确:明确回应客户提出的具体问题
3. 解决方案:提供清晰、可操作的解决步骤
4. 后续保障:说明后续跟进措施和联系方式
5. 语言规范: