精彩专栏推荐订阅:在下方主页👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、视频展示
- 三、开发环境
- 四、系统展示
- 五、代码展示
- 六、项目文档展示
- 七、项目总结
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻)
一、项目介绍
基于Python的用户评论挖掘旅游景点推荐系统是一套融合了自然语言处理和数据挖掘技术的智能化旅游服务平台。该系统采用Django框架作为后端核心架构,结合Vue.js和ElementUI构建用户友好的前端界面,通过MySQL数据库存储海量的景点信息和用户评论数据。系统的核心创新在于运用文本挖掘算法对用户评论进行深度分析,提取情感倾向、关键词频和评价维度,构建基于评论质量的景点推荐模型。管理员可以通过后台管理模块对用户信息、景点数据进行统一管理,实时监控评论举报和用户反馈,并通过热度分析功能掌握景点的受欢迎程度变化趋势。普通用户在完成注册登录后,能够浏览详细的景点信息,查看其他用户的真实评价,发表个人旅游体验,获取个性化的景点推荐建议,制定符合自身喜好的旅游计划,同时参与社区互动和举报不当评论。系统通过评论挖掘算法分析用户偏好特征,结合景点属性和历史评价数据,为每位用户生成个性化的旅游推荐方案,有效解决了传统旅游信息服务中信息过载和推荐精准度不足的问题。
选题背景
随着国内旅游业的蓬勃发展和移动互联网的普及,越来越多的游客习惯在旅游平台上分享自己的游玩体验和感受,这些用户生成的评论数据已经成为其他潜在游客做出旅游决策的重要参考依据。然而,面对海量的景点信息和纷繁复杂的用户评论,游客往往难以快速筛选出真正符合自身需求和偏好的旅游目的地。传统的旅游推荐系统大多基于简单的标签匹配或热度排序,缺乏对用户评论文本内容的深度挖掘和分析,导致推荐结果的个性化程度不高,用户满意度有待提升。同时,随着用户对旅游体验要求的不断提高,他们更加关注其他游客的真实感受和详细评价,希望能够通过这些第一手的经验分享来规避旅游陷阱,发现值得一游的隐藏景点。在这样的背景下,如何有效利用用户评论中蕴含的丰富信息,构建一个能够理解用户真实需求并提供精准推荐的旅游服务系统,成为当前旅游信息化领域亟需解决的重要问题。
选题意义
本课题的研究和实现具有多重现实意义和应用价值。从技术角度来看,系统将自然语言处理技术与旅游推荐相结合,探索了文本挖掘在特定领域应用的可行性,为类似的评论分析系统提供了技术参考和实现思路。通过对用户评论进行情感分析、关键词提取和主题分类,能够更好地理解用户的真实感受和需求偏好,这种基于内容的推荐方式相比传统的协同过滤具有更强的解释性和可信度。从用户体验角度来说,系统能够帮助游客更加高效地获取有价值的旅游信息,减少信息搜索和筛选的时间成本,提升旅游决策的科学性和准确性。对于旅游景点管理者而言,系统提供的评论分析和热度统计功能,可以帮助他们及时了解游客的满意度和意见反馈,为景点的服务改进和营销策略调整提供数据支撑。从学术层面来看,本课题将机器学习、数据挖掘等前沿技术与具体的业务场景相结合,体现了跨学科知识的综合运用,为计算机专业学生提供了一个理论联系实际的学习和实践平台,虽然作为毕业设计项目在规模和复杂度上相对有限,但仍然能够在一定程度上展示现代信息技术在解决实际问题中的应用潜力。
二、视频展示
计算机Python毕业设计推荐:基于Django+Vue用户评论挖掘旅游系统
三、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
四、系统展示
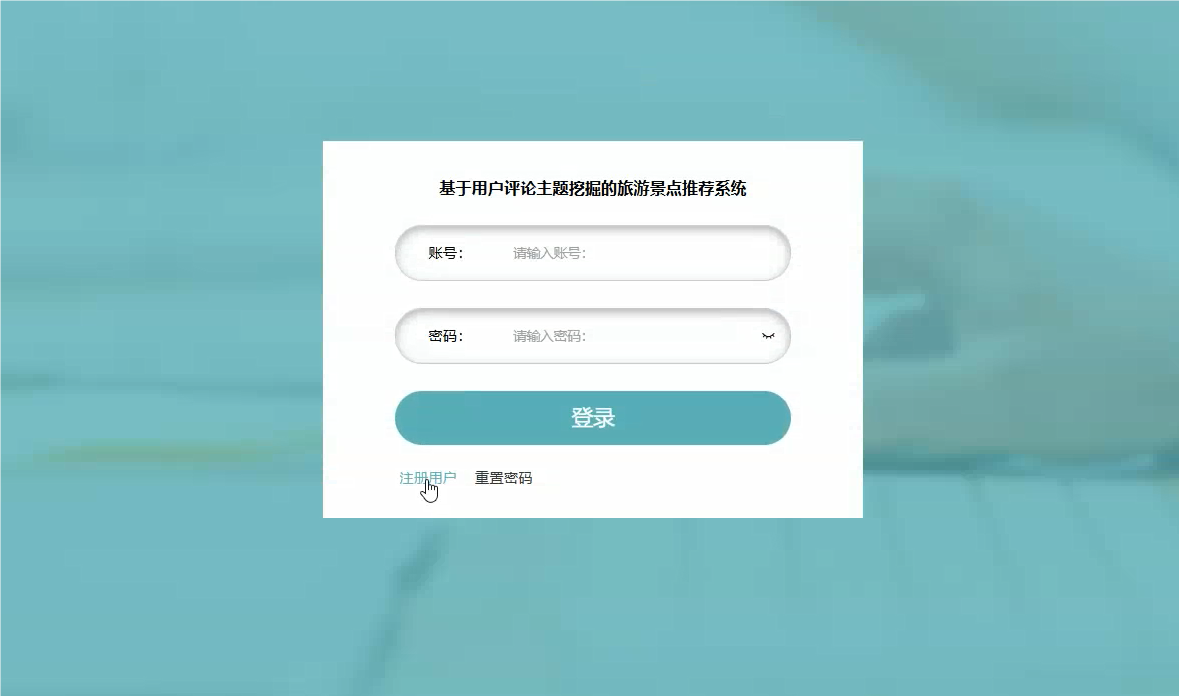
登录模块:
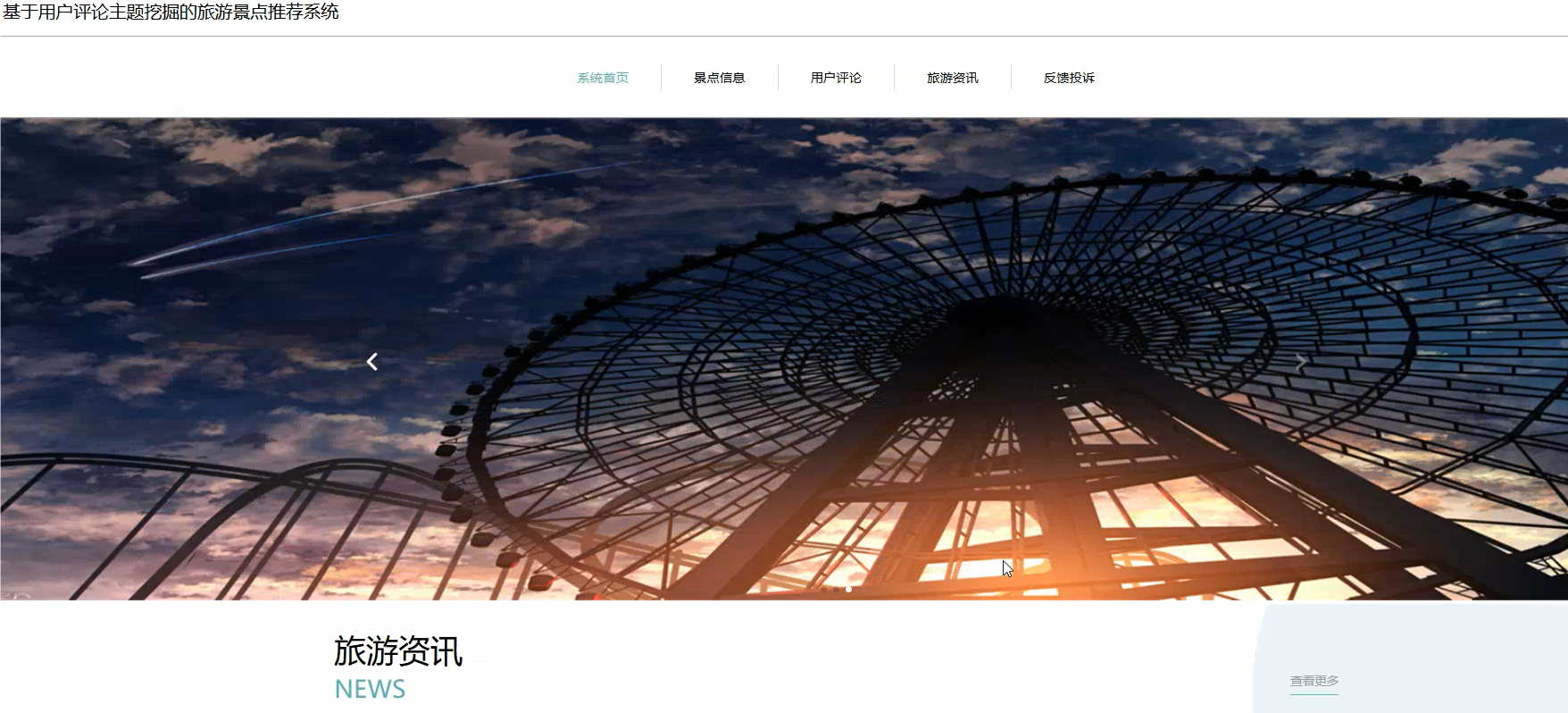
首页模块:
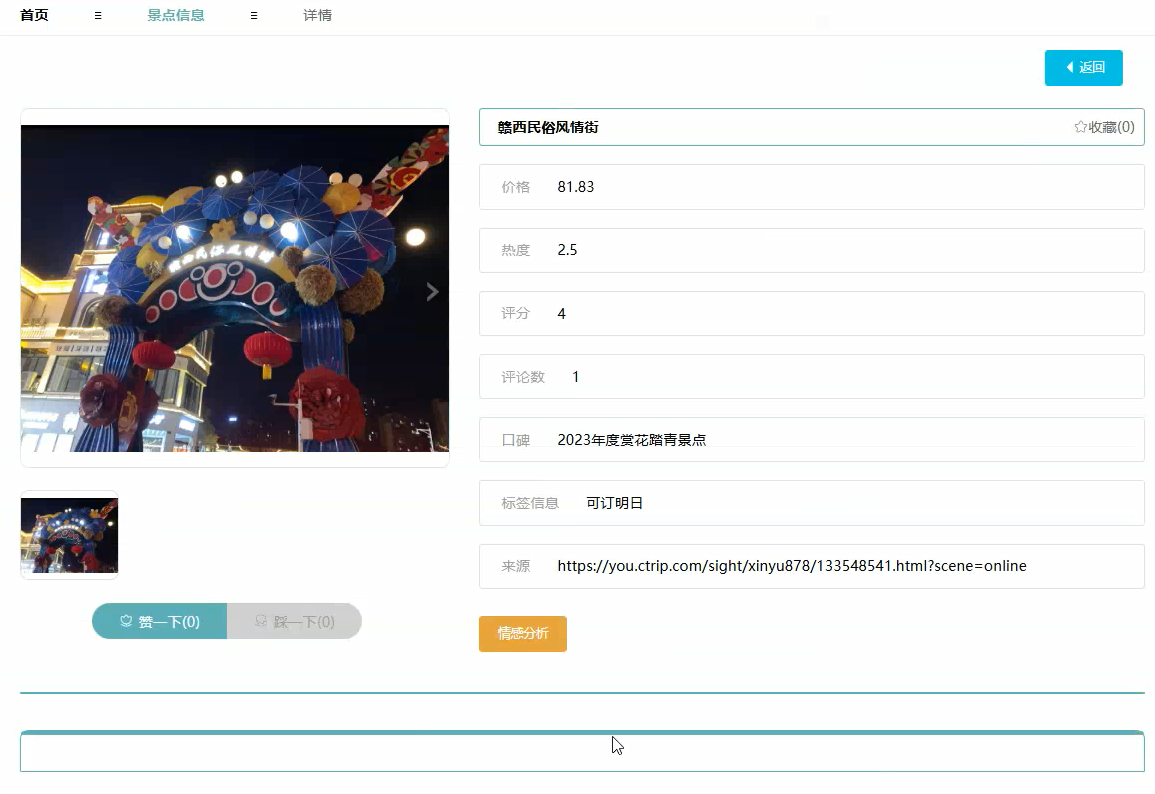
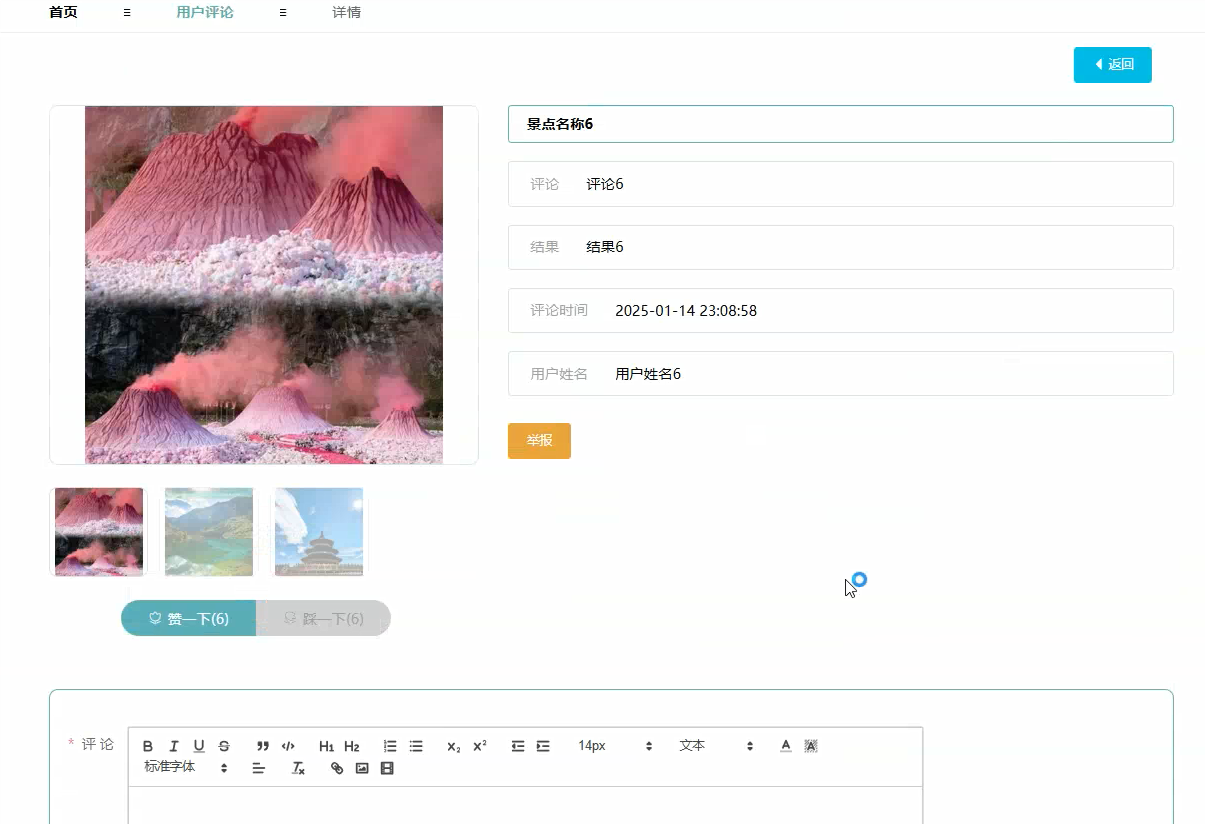
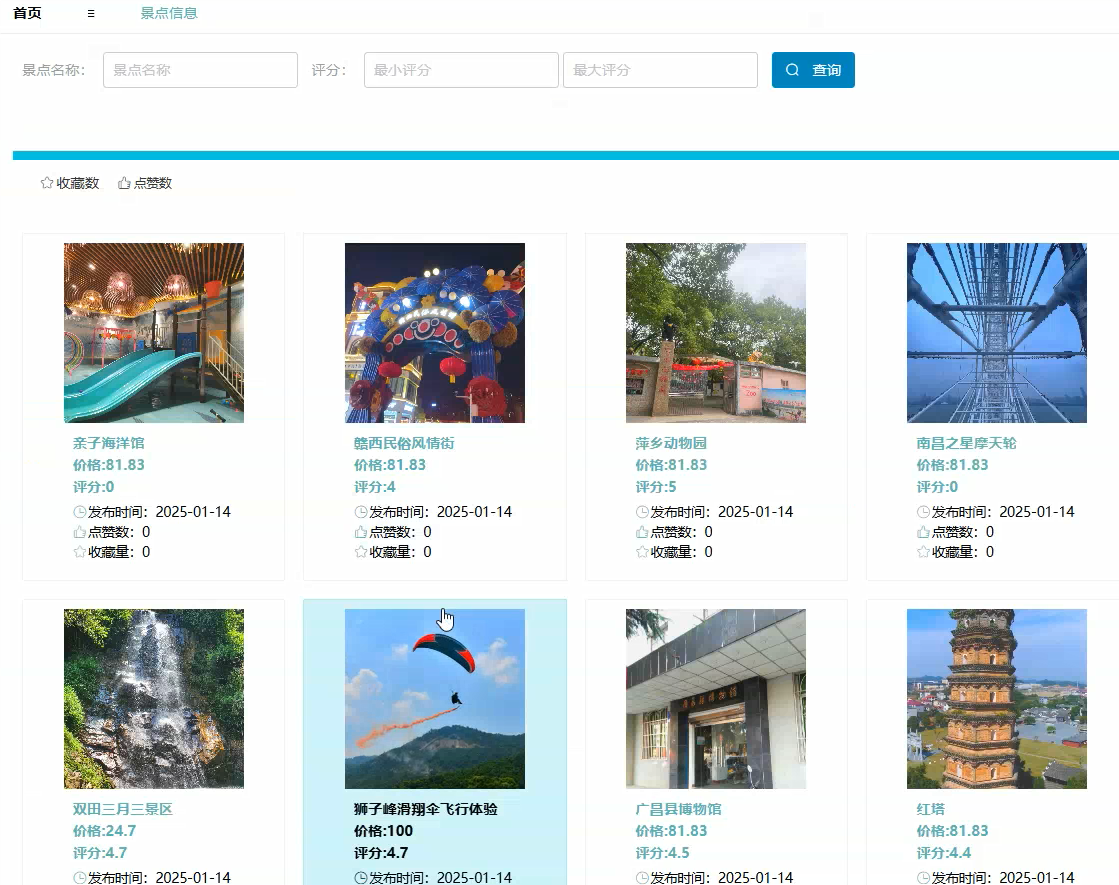
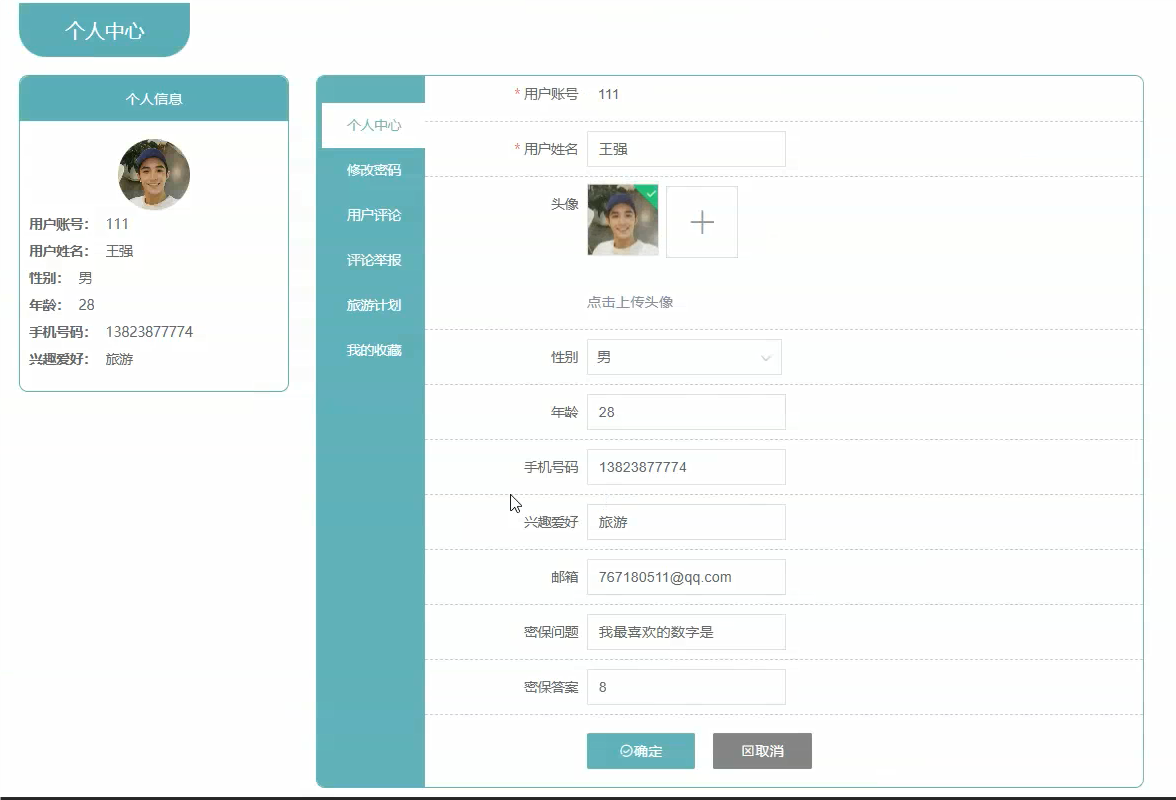
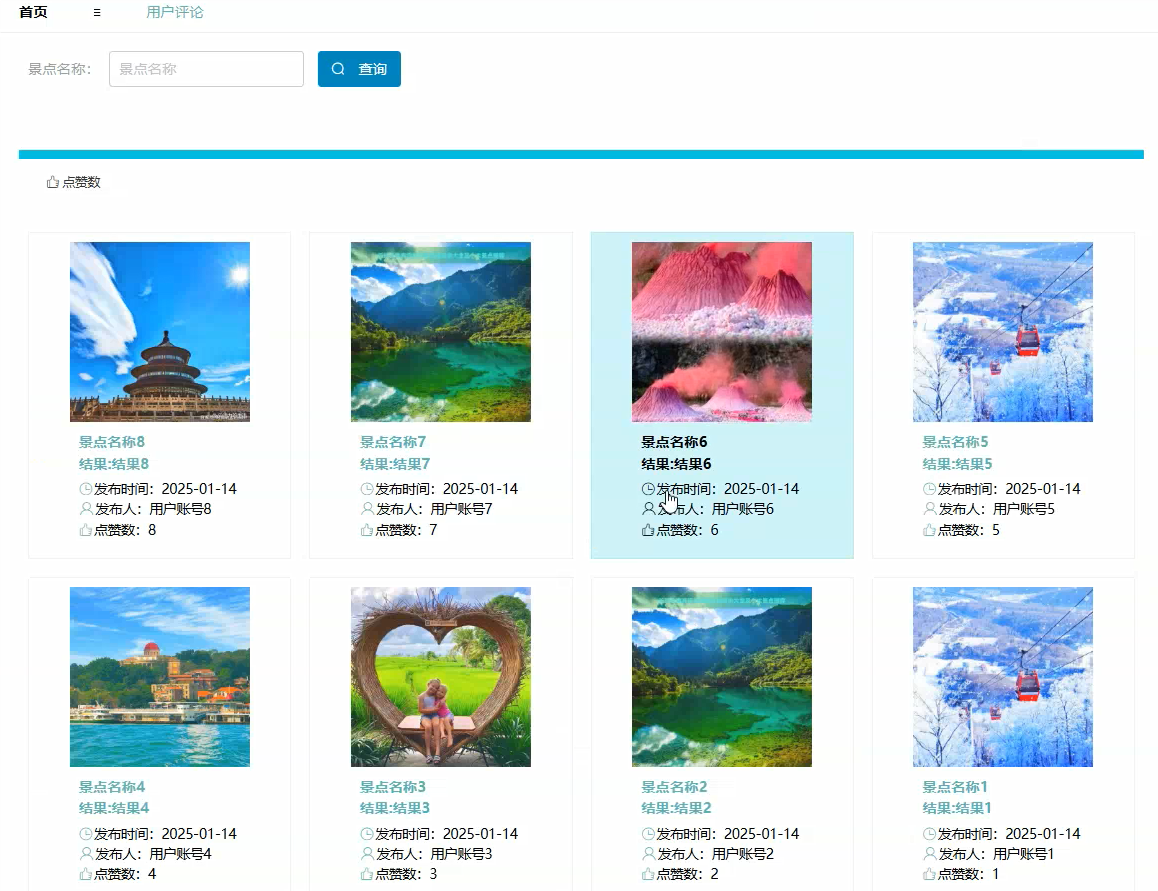
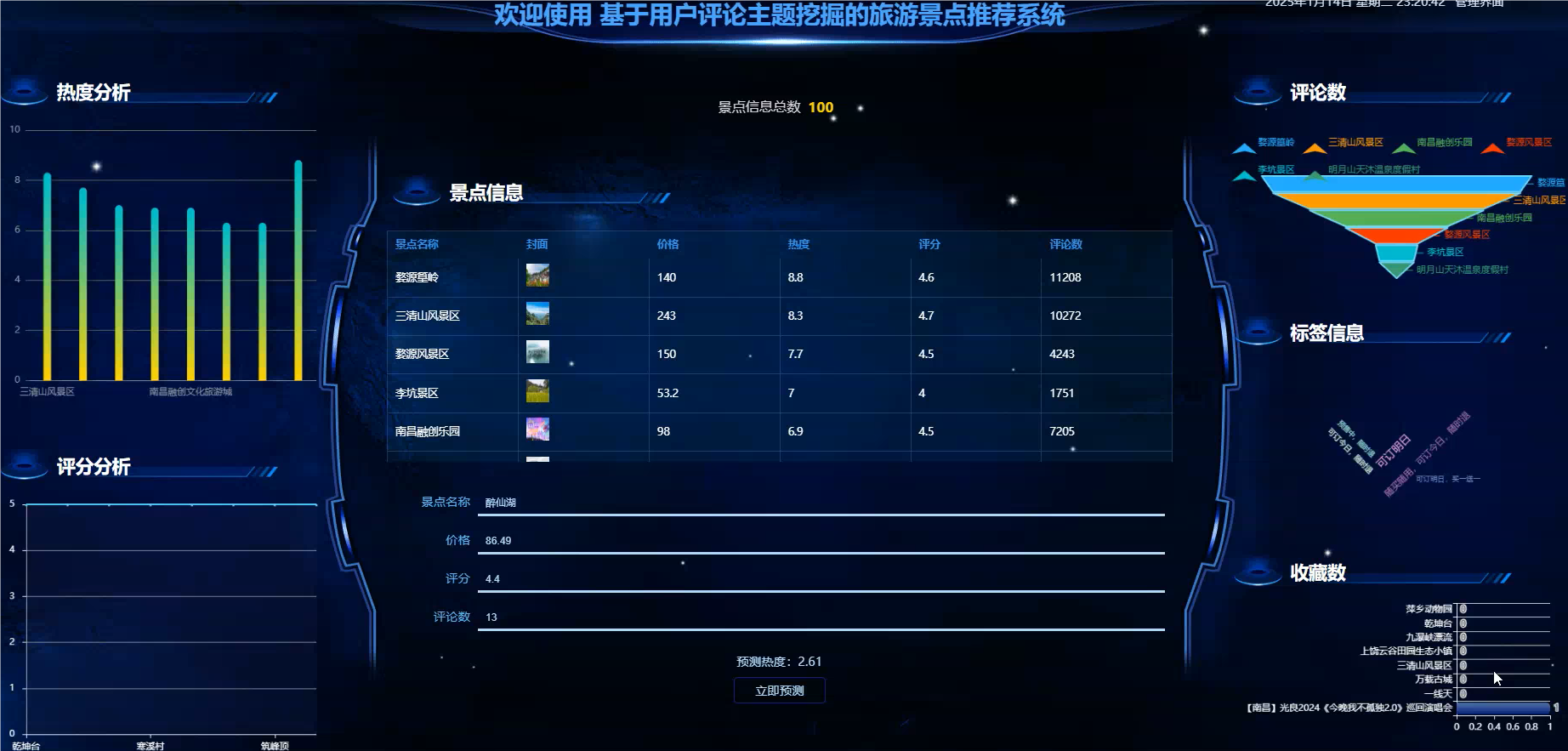
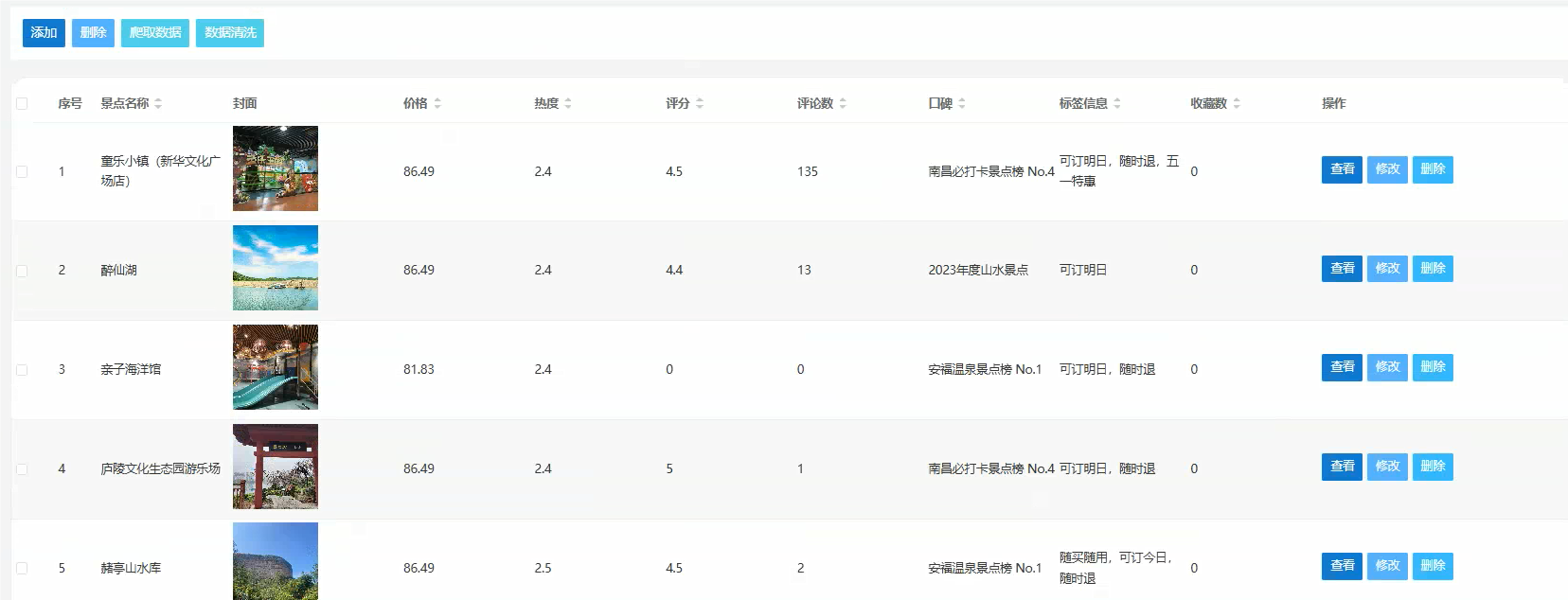
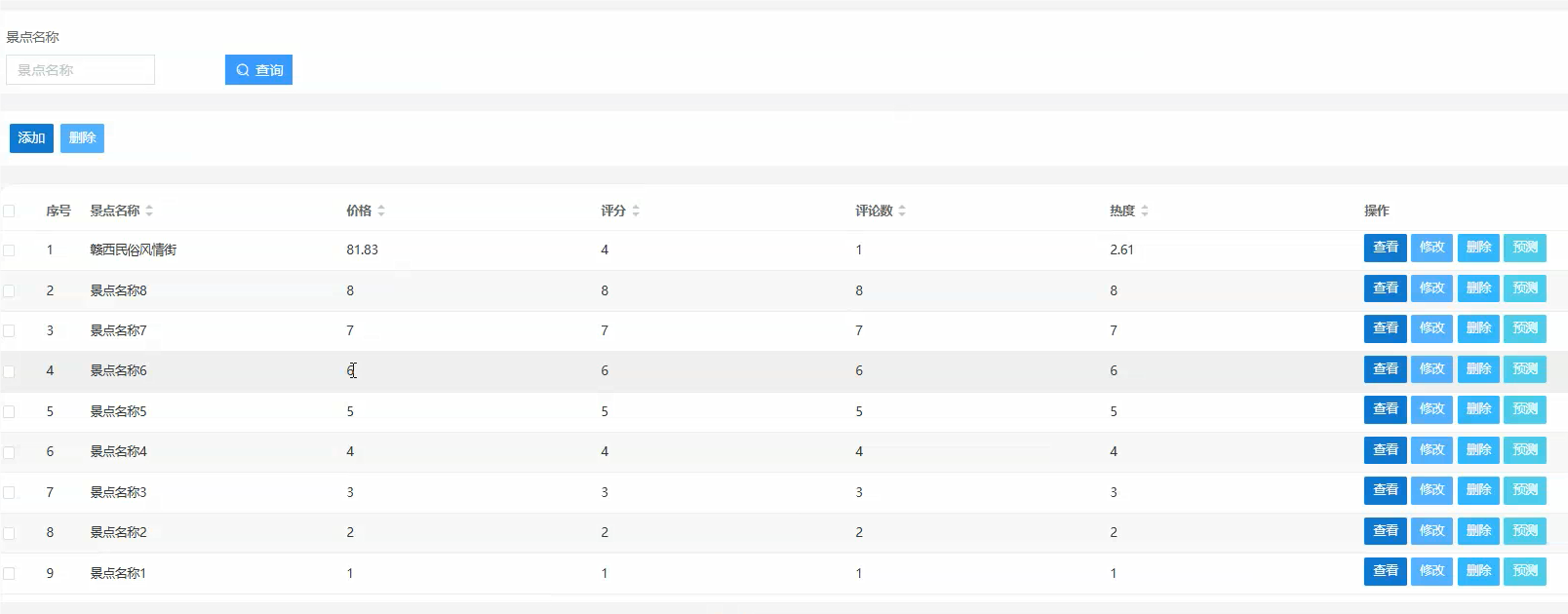
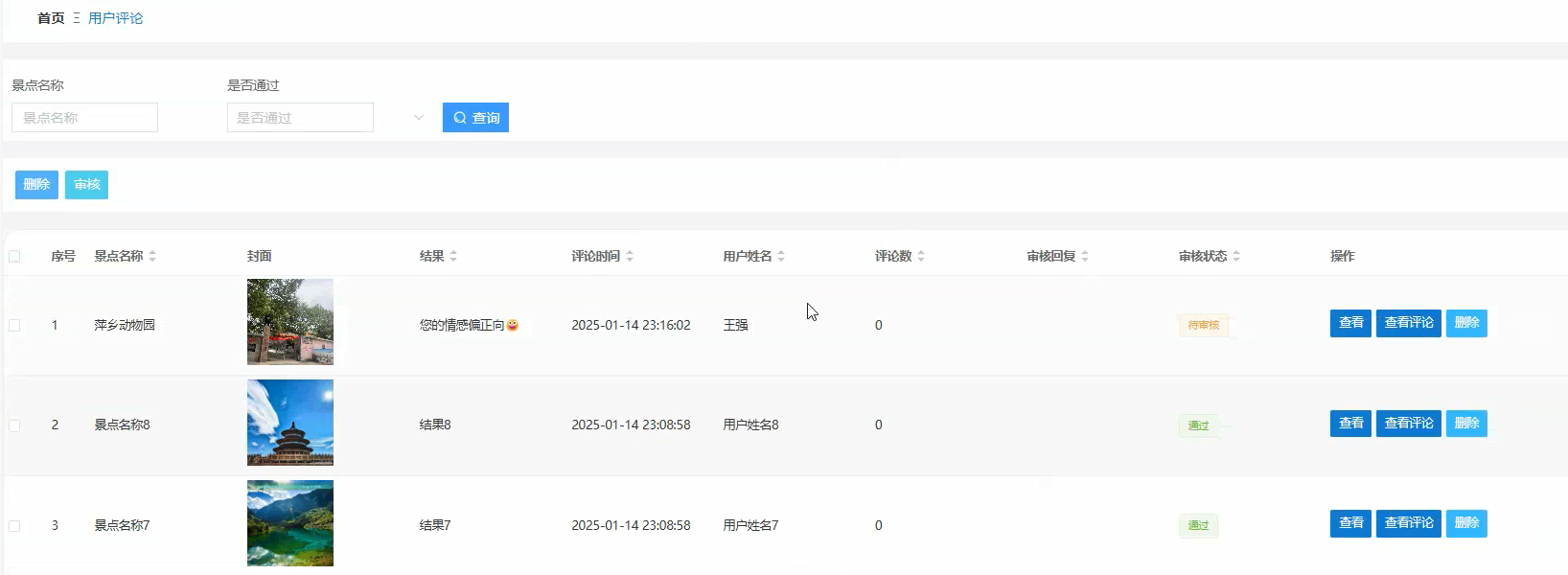
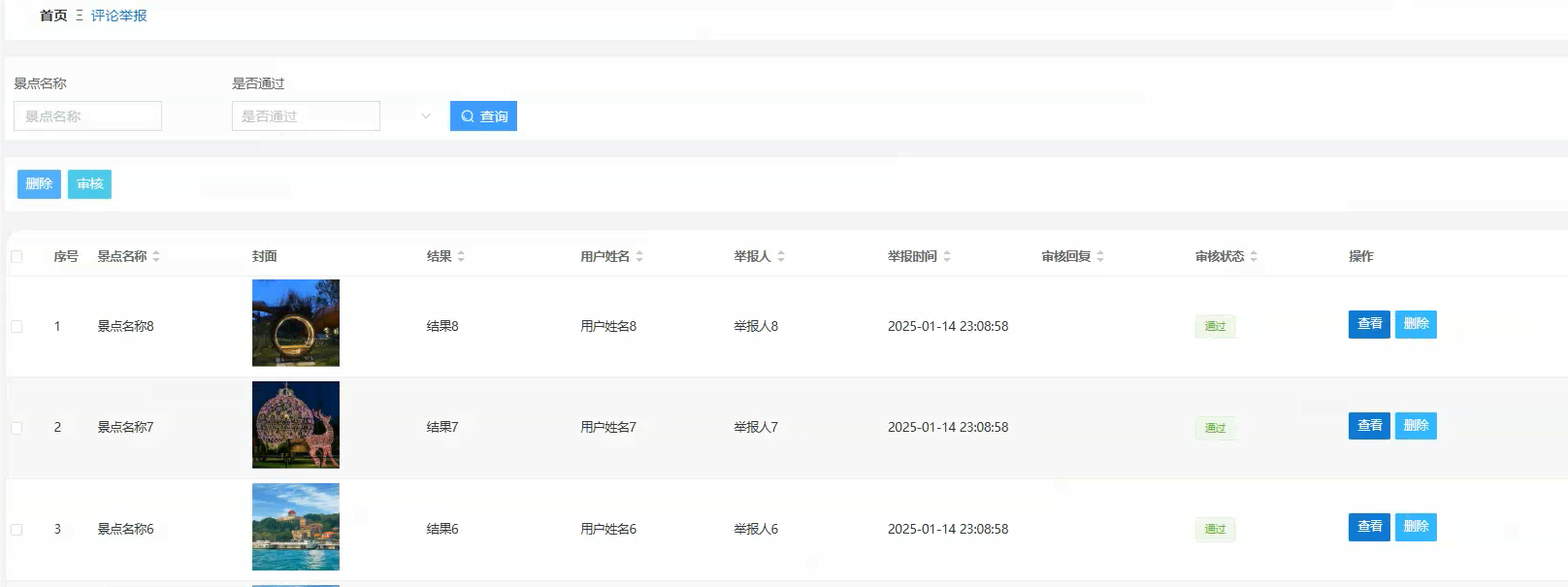
管理模块展示:
五、代码展示
bash
from pyspark.sql import SparkSession
from django.shortcuts import render, get_object_or_404
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
from django.contrib.auth.decorators import login_required
from .models import Attraction, UserComment, User, RecommendationLog
import json
import jieba
import re
from collections import Counter
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
from datetime import datetime, timedelta
spark = SparkSession.builder.appName("TourismRecommendation").master("local[*]").getOrCreate()
@csrf_exempt
@login_required
def mine_user_comments(request):
if request.method == 'POST':
data = json.loads(request.body)
attraction_id = data.get('attraction_id')
attraction = get_object_or_404(Attraction, id=attraction_id)
comments = UserComment.objects.filter(attraction=attraction, is_active=True)
comment_texts = [comment.content for comment in comments]
if not comment_texts:
return JsonResponse({'success': False, 'message': '暂无评论数据'})
processed_comments = []
for text in comment_texts:
cleaned_text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9]', ' ', text)
words = jieba.cut(cleaned_text)
processed_text = ' '.join([word for word in words if len(word) > 1])
processed_comments.append(processed_text)
vectorizer = TfidfVectorizer(max_features=1000, stop_words=None)
tfidf_matrix = vectorizer.fit_transform(processed_comments)
feature_names = vectorizer.get_feature_names_out()
tfidf_scores = tfidf_matrix.sum(axis=0).A1
keyword_scores = list(zip(feature_names, tfidf_scores))
keyword_scores.sort(key=lambda x: x[1], reverse=True)
top_keywords = keyword_scores[:20]
positive_words = ['好', '棒', '美', '值得', '推荐', '不错', '满意', '喜欢']
negative_words = ['差', '坑', '不好', '失望', '后悔', '糟糕', '垃圾', '骗人']
sentiment_analysis = {'positive': 0, 'negative': 0, 'neutral': 0}
for comment in comment_texts:
pos_count = sum(1 for word in positive_words if word in comment)
neg_count = sum(1 for word in negative_words if word in comment)
if pos_count > neg_count:
sentiment_analysis['positive'] += 1
elif neg_count > pos_count:
sentiment_analysis['negative'] += 1
else:
sentiment_analysis['neutral'] += 1
attraction.popularity_score = sentiment_analysis['positive'] * 2 - sentiment_analysis['negative']
attraction.save()
return JsonResponse({
'success': True,
'keywords': [{'word': word, 'score': float(score)} for word, score in top_keywords],
'sentiment': sentiment_analysis,
'total_comments': len(comment_texts)
})
@csrf_exempt
@login_required
def generate_personalized_recommendations(request):
if request.method == 'POST':
user = request.user
user_comments = UserComment.objects.filter(user=user, is_active=True)
if user_comments.count() < 3:
popular_attractions = Attraction.objects.filter(is_active=True).order_by('-popularity_score')[:10]
recommendations = [{'id': attr.id, 'name': attr.name, 'score': attr.popularity_score} for attr in popular_attractions]
return JsonResponse({'success': True, 'recommendations': recommendations, 'type': 'popular'})
user_comment_texts = [comment.content for comment in user_comments]
user_profile_text = ' '.join(user_comment_texts)
cleaned_user_profile = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9]', ' ', user_profile_text)
user_words = jieba.cut(cleaned_user_profile)
user_keywords = [word for word in user_words if len(word) > 1]
user_keyword_freq = Counter(user_keywords)
all_attractions = Attraction.objects.filter(is_active=True).exclude(id__in=[comment.attraction.id for comment in user_comments])
attraction_scores = []
for attraction in all_attractions:
attraction_comments = UserComment.objects.filter(attraction=attraction, is_active=True)
if attraction_comments.exists():
attraction_texts = [comment.content for comment in attraction_comments]
attraction_content = ' '.join(attraction_texts)
cleaned_attraction = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9]', ' ', attraction_content)
attraction_words = jieba.cut(cleaned_attraction)
attraction_keywords = [word for word in attraction_words if len(word) > 1]
attraction_keyword_freq = Counter(attraction_keywords)
similarity_score = 0
total_user_freq = sum(user_keyword_freq.values())
for keyword, freq in user_keyword_freq.items():
if keyword in attraction_keyword_freq:
similarity_score += (freq / total_user_freq) * (attraction_keyword_freq[keyword] / sum(attraction_keyword_freq.values()))
combined_score = similarity_score * 0.7 + (attraction.popularity_score / 100) * 0.3
attraction_scores.append({'id': attraction.id, 'name': attraction.name, 'score': combined_score})
attraction_scores.sort(key=lambda x: x['score'], reverse=True)
top_recommendations = attraction_scores[:15]
RecommendationLog.objects.create(user=user, recommendation_data=json.dumps(top_recommendations), created_at=datetime.now())
return JsonResponse({'success': True, 'recommendations': top_recommendations, 'type': 'personalized'})
@csrf_exempt
@login_required
def analyze_attraction_popularity(request):
if request.method == 'POST':
data = json.loads(request.body)
time_period = data.get('time_period', 30)
start_date = datetime.now() - timedelta(days=time_period)
recent_comments = UserComment.objects.filter(created_at__gte=start_date, is_active=True)
attraction_stats = {}
for comment in recent_comments:
attraction_id = comment.attraction.id
attraction_name = comment.attraction.name
if attraction_id not in attraction_stats:
attraction_stats[attraction_id] = {
'name': attraction_name,
'comment_count': 0,
'total_rating': 0,
'positive_count': 0,
'negative_count': 0
}
attraction_stats[attraction_id]['comment_count'] += 1
attraction_stats[attraction_id]['total_rating'] += comment.rating if hasattr(comment, 'rating') and comment.rating else 3
comment_text = comment.content
positive_indicators = ['好', '棒', '美', '值得', '推荐', '满意', '喜欢', '不错']
negative_indicators = ['差', '坑', '不好', '失望', '后悔', '糟糕', '垃圾']
pos_score = sum(1 for indicator in positive_indicators if indicator in comment_text)
neg_score = sum(1 for indicator in negative_indicators if indicator in comment_text)
if pos_score > neg_score:
attraction_stats[attraction_id]['positive_count'] += 1
elif neg_score > pos_score:
attraction_stats[attraction_id]['negative_count'] += 1
popularity_results = []
for attr_id, stats in attraction_stats.items():
if stats['comment_count'] > 0:
avg_rating = stats['total_rating'] / stats['comment_count']
sentiment_ratio = (stats['positive_count'] - stats['negative_count']) / stats['comment_count']
popularity_index = (avg_rating * 0.4 + (sentiment_ratio + 1) * 2.5 * 0.3 + min(stats['comment_count'] / 10, 5) * 0.3)
popularity_results.append({
'attraction_id': attr_id,
'name': stats['name'],
'comment_count': stats['comment_count'],
'avg_rating': round(avg_rating, 2),
'positive_ratio': round(stats['positive_count'] / stats['comment_count'], 2),
'popularity_index': round(popularity_index, 2)
})
popularity_results.sort(key=lambda x: x['popularity_index'], reverse=True)
top_attractions = popularity_results[:20]
for result in top_attractions:
try:
attraction = Attraction.objects.get(id=result['attraction_id'])
attraction.popularity_score = result['popularity_index'] * 10
attraction.save()
except Attraction.DoesNotExist:
continue
return JsonResponse({
'success': True,
'popularity_data': top_attractions,
'analysis_period': time_period,
'total_analyzed': len(attraction_stats)
})六、项目文档展示

七、项目总结
本课题成功设计并实现了基于Python的用户评论挖掘旅游景点推荐系统,充分运用了Django后端框架、Vue前端技术和MySQL数据库的组合优势,构建了一个功能完善的智能化旅游服务平台。系统的核心创新点在于将自然语言处理技术与旅游推荐算法深度融合,通过对海量用户评论进行文本挖掘和情感分析,提取出有价值的用户偏好特征和景点评价信息,为个性化推荐提供了可靠的数据支撑。在技术实现层面,系统采用TF-IDF算法进行关键词提取,运用余弦相似度计算用户兴趣匹配度,结合情感分析结果生成综合评分,有效解决了传统推荐系统中存在的冷启动和推荐精度不足等问题。整个开发过程不仅锻炼了全栈开发能力,更重要的是深入理解了数据挖掘技术在实际业务场景中的应用方法。虽然作为毕业设计项目在算法复杂度和数据规模上还有提升空间,但系统已经具备了基本的商用价值,能够为用户提供实用的旅游决策支持服务。通过这次实践,不仅掌握了Python Web开发的完整流程,也对机器学习在文本分析领域的应用有了更深刻的认识。
大家可以帮忙点赞、收藏、关注、评论啦 👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖