最近在准备面试,正把平时积累的笔记、项目中遇到的问题与解决方案、对核心原理的理解,以及高频业务场景的应对策略系统梳理一遍,既能加深记忆,也能让知识体系更扎实,供大家参考,欢迎讨论。
在分布式环境下,为了避免单一节点负载过高导致的不稳定,Redis 提供了 集群模式(Cluster) ,哨兵模式的升级版,Master 节点支持水平扩容。
在集群模式中,通过计算 Key 的哈希值,把它映射到哈希槽中的一个,再由槽映射到具体的 Master 节点。 将 Key 分布到多个节点上,每个 Master 节点后会配置若干 Slave 节点,用于在故障时进行主备切换。客户端可以连接任意 Master 节点,集群内部会根据 Key 自动将请求转发到正确的 Master 节点。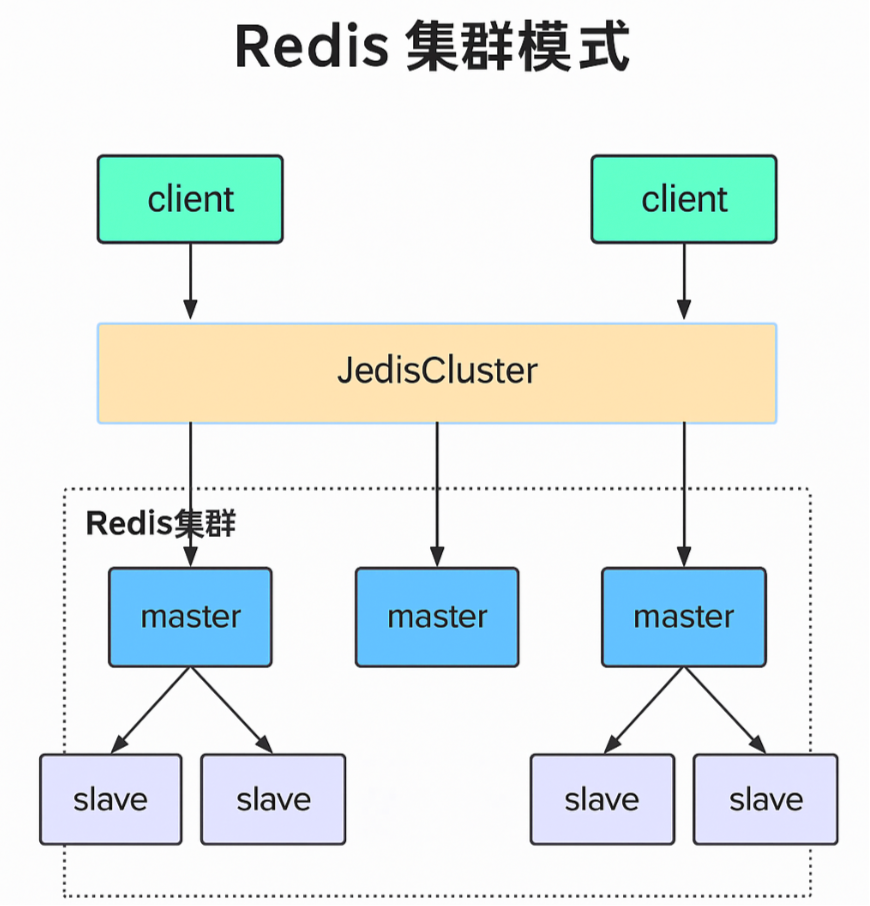
节点类型
Master 节点 :负责存储和写操作,是集群的核心。
Slave 节点 :作为备份,支持故障切换,通过调整配置可承担读请求。
数据分片(Sharding)
-
使用 哈希槽 (Hash Slot) 方式分片。
-
一共 16384 个槽,分配到不同 Master 节点(集群最多 16384 个 Master 节点,不建议设置过多个,因为每个节点之间都要互相发送心跳包,节点越多,开销越大(近似 O(N²) 复杂度))。
-
客户端根据 Key 的 CRC16 哈希值定位到具体槽,再找到对应 Master 节点。
-
-
奇数投票机制
- 建议 Master 数量为
奇数,集群内部需要多数投票才能判定某个 Master 下线。如果是偶数个 Master,容易出现"脑裂"或无法形成多数投票,奇数更稳。
- 建议 Master 数量为
-
工作中常见 Master 数量
- Redis单节点 QPS 大约在 10 万 ~ 20 万 ops/s(纯内存读写,开启持久化、网络延迟、复杂命令会降低)。
- 30 万并发场景,Redis Cluster 建议配置3 个或 5 个 Master 节点;前期业务上线时,建议预留空间,避免因集群规模过小导致性能瓶颈或高可用风险,影响生产环境稳定性。
高可用的实现
集群模式的高可用机制与哨兵模式类似:
- 集群内节点之间会定期进行心跳检测;
- 如果多数节点判定某个 Master 节点失效,就会将其踢出集群;
- 随后从该 Master 的 Slave 节点中选举出一个新的 Master,继续提供服务。
这样,即使某个节点宕机,集群也能保持可用性,保证系统的稳定。
使用场景
虽然集群模式能够避免单 Master 的性能瓶颈,但数据同步会占用一定带宽,特别是写操作多时更为明显。因此:
- 写操作密集型场景:推荐使用集群模式,以实现负载分摊与高可用。
- 常规场景:大多数情况下,哨兵模式即可满足需求,部署和维护成本也更低。