基于Django的协同过滤旅游推荐系统:从0到1落地实战
一套可跑通、可扩展、可二开的旅游推荐系统,涵盖用户端与管理端,内置 UserCF/ItemCF 推荐,支持评分、收藏、浏览行为采集与"猜你喜欢"。本文完整拆解技术架构、目录结构与核心代码,并预留可视化展示位。
目录
- 项目概览
- 技术栈
- 目录结构
- 数据模型设计
- 核心业务流程
- 首页与分类检索
- 猜你喜欢(个性化推荐)
- 协同过滤算法实现
- 接口与路由
- 前端与可视化)
- 部署与运行
- 性能与扩展建议
- 常见问题 FAQ
- 结语与联系方式
项目概览
本项目是一个基于 Django 的智能旅游推荐系统,面向"景点、美食、酒店、路线"等多类型内容,支持:
- 用户体系:注册、登录、个人信息管理、头像上传
- 行为采集:评分、收藏、浏览记录
- 推荐能力:基于用户/物品的协同过滤(UserCF/ItemCF),"猜你喜欢"与随机补全
- 内容展示:首页轮播、卡片列表、详情页、搜索与类型切换
- 管理后台:基于 Django Admin 的数据增删改查
技术栈
- 后端:Django 3.x,Django Admin
- 数据库:MySQL
- 前端:Django Template、Bootstrap、jQuery
- 可视化:ECharts(本地静态资源)
- 推荐算法:UserCF、ItemCF(余弦相似度、邻域、预测评分)
- 其他:Pillow、SimpleUI(美化后台)
目录结构
text
TravelRecSystem/
├── apps/
│ ├── app/ # 核心业务模型:美食(App)、酒店(Hotel)、景点(ScenicSpot)、路线(Router)
│ ├── user/ # 用户模块
│ ├── record/ # 评分记录
│ ├── collection/ # 收藏记录
│ ├── comment/ # 评论(如需)
│ ├── type/ # 类型管理
│ ├── index/ # 首页、推荐、检索
│ └── common/ # 常量、历史记录、通用视图
│ └── ...
├── apps/util/cfra/ # 协同过滤算法实现(UserCF/ItemCF 等)
├── static/ # 静态资源(CSS/JS/Images)
├── media/ # 媒体资源(上传头像/图片)
├── templates/ # 模板页面(首页、详情、用户中心等)
├── TravelRecSys/ # Django 项目配置、全局路由
├── requirements.txt
├── design_278_travel.sql # 初始数据库结构
└── manage.py数据模型设计
以 apps/app/models.py 为例,项目内置了多类型旅游对象:
python
class App(models.Model):
name = models.CharField(max_length=100)
typeid = models.ForeignKey('type.Type', models.CASCADE, db_column='typeid')
image = models.ImageField(upload_to='')
deal = models.CharField(blank=True, max_length=1000)
price = models.CharField(blank=True, max_length=50)
address = models.TextField(max_length=200)
grade = models.CharField(blank=True, max_length=5)
comment_count = models.IntegerField(blank=True)
meishi_url = models.CharField(blank=True, max_length=300)
img_url = models.CharField(blank=True, max_length=300)
class Hotel(models.Model):
name = models.CharField(max_length=255)
hotelHeadPicture = models.CharField(max_length=255)
commentScore = models.FloatField()
city = models.CharField(max_length=255)
description = models.TextField()
class ScenicSpot(models.Model):
name = models.CharField(max_length=255)
img = models.CharField(max_length=255)
ticket = models.IntegerField()
star_num = models.IntegerField() # 收藏人数
lat = models.FloatField()
lng = models.FloatField()
class Router(models.Model):
name = models.CharField(max_length=255)
img = models.CharField(max_length=255)
detail = models.TextField()用户行为数据(评分、收藏、浏览)在推荐中至关重要:
python
# apps/record/models.py
class Record(models.Model):
score = models.IntegerField(validators=[MaxValueValidator(5), MinValueValidator(1)])
userid = models.ForeignKey('user.User', models.CASCADE, db_column='userid')
appid = models.IntegerField() # 评分对象ID
type = models.CharField(max_length=255)
createtime = models.DateTimeField(auto_now_add=True)
# apps/collection/models.py
class Collection(models.Model):
userid = models.ForeignKey('user.User', models.CASCADE, db_column='userid')
appid = models.IntegerField() # 收藏对象ID
type = models.CharField(max_length=255)
createtime = models.DateTimeField(auto_now_add=True)
# apps/common/models.py
class History(models.Model):
userid = models.ForeignKey('user.User', models.CASCADE, db_column='userid')
appid = models.IntegerField() # 浏览对象ID
type = models.CharField(max_length=255)
createtime = models.DateTimeField(auto_now_add=True)核心业务流程
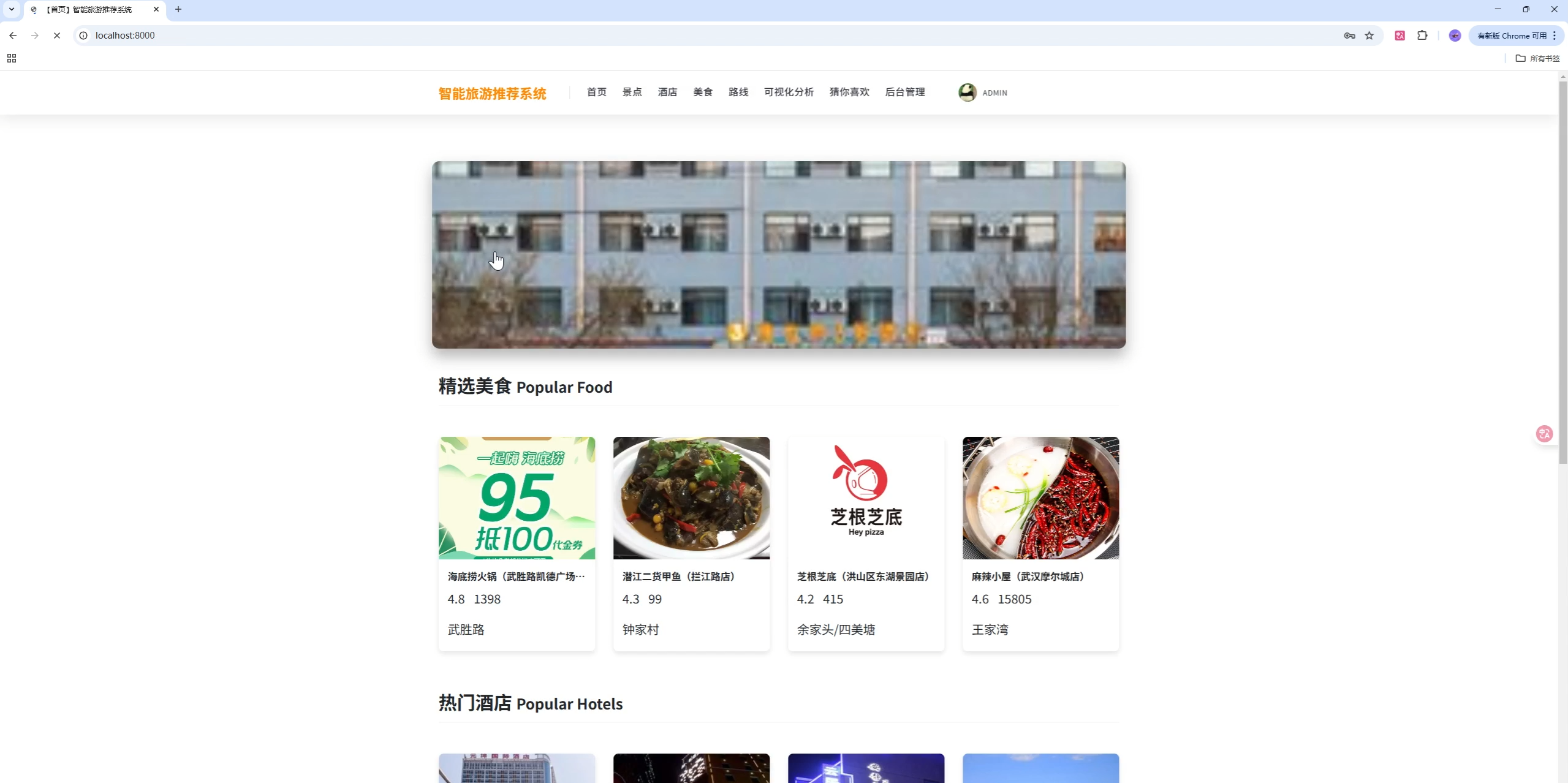
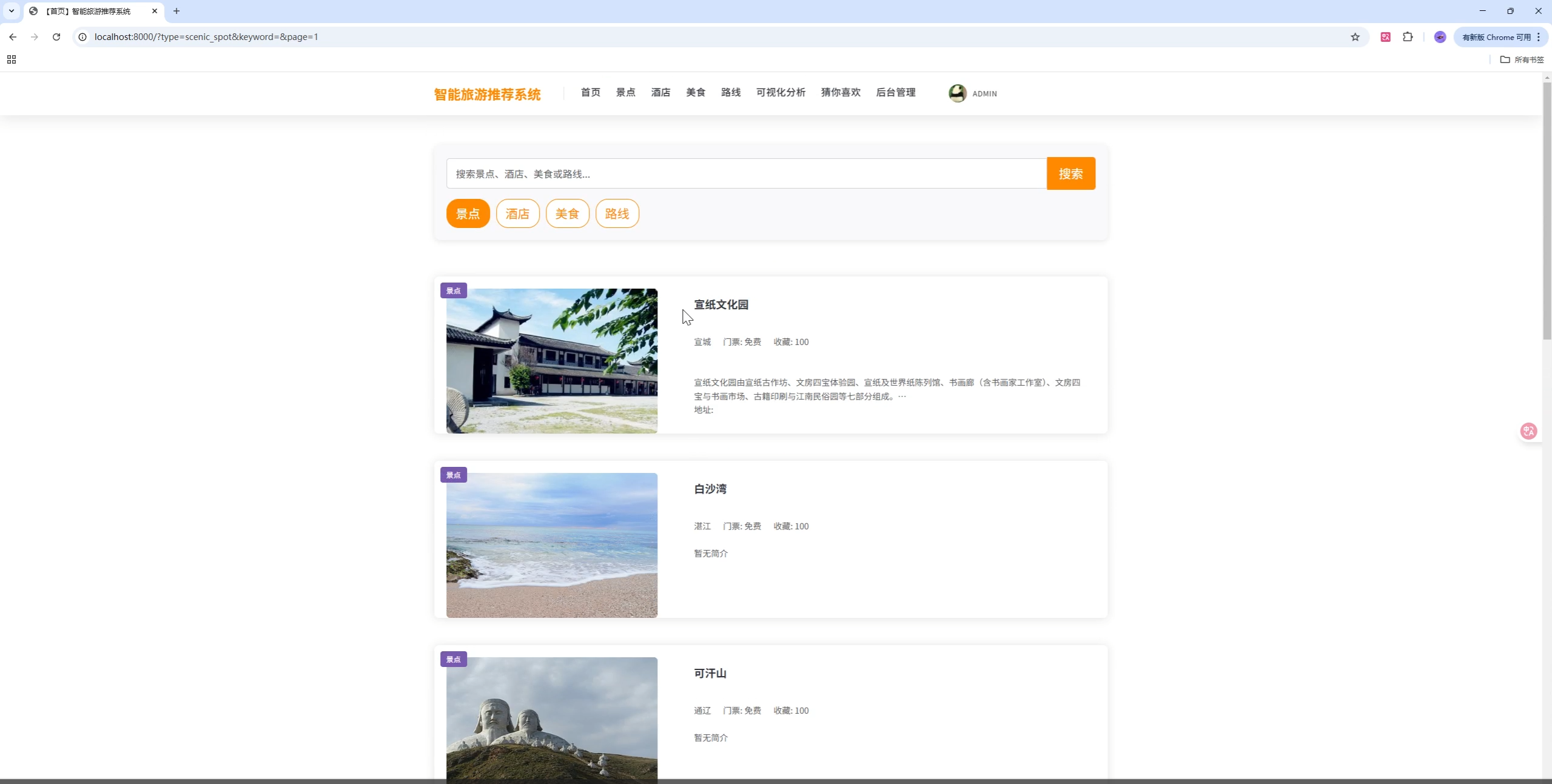
首页与分类检索
首页聚合轮播与卡片位,支持类型切换和搜索,代码见 apps/index/views.py:
python
def index(request):
# 未传 type 时渲染首页轮播与卡片
if not request.GET.get('type'):
carousel_items = []
top_app = App.objects.order_by('?').first()
top_hotel = Hotel.objects.order_by('?').first()
top_scenic = ScenicSpot.objects.order_by('?').first()
top_router = Router.objects.order_by('?').first()
# ... 组装 carousel_items 与四类卡片数据 apps/hotels/scenics/routers
return render(request, 'index/home.html', context)
# 传入 type 与 keyword 时,进入列表检索与分页逻辑
item_type = request.GET.get('type')
keyword = request.GET.get('keyword', '')
page = int(request.GET.get('page', 1))
page_size = 10
if item_type == 'scenic_spot':
queryset = ScenicSpot.objects.filter(Q(name__icontains=keyword)) if keyword else ScenicSpot.objects.all()
queryset = queryset.annotate(is_gif=Case(When(img__iendswith='.gif', then=Value(1)), default=Value(0), output_field=IntegerField())).order_by('is_gif', '-star_num')
paginator = Paginator(queryset, page_size)
items = paginator.get_page(page)
# hotel/app/router 分支类似
return render(request, 'index/index.html', context=data)亮点:
- 首页轮播从"美食/酒店/景点/路线"四类随机抽取,过滤 GIF
- 列表按类型与关键词检索,并对景点优先展示"非 GIF + 收藏热度高"的内容
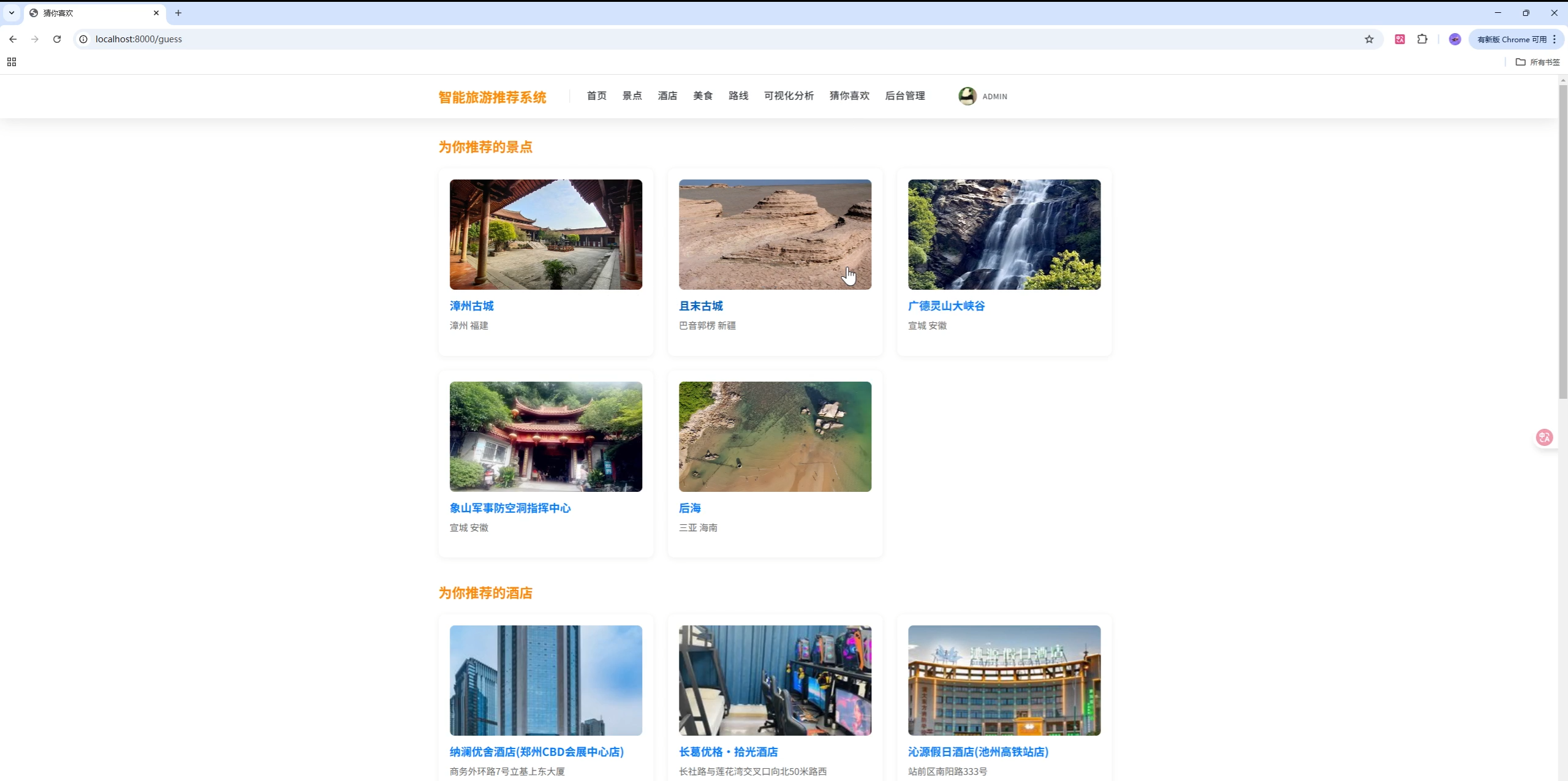
猜你喜欢(个性化推荐)
登录用户可见,综合评分、收藏、浏览构建评分矩阵,调用 UserCF 生成推荐:
python
def guess_you_like(request):
if not request.session.get(Constant.session_user_isLogin, None):
return render(request, 'index/guess.html', {"not_login": True})
cUserid = request.session.get(Constant.session_user_id)
records = Record.objects.all()
collections = Collection.objects.all()
historys = History.objects.all()
dataModel = setDataModelWithRules(historys, records, collections, None)
userCf = UserCF()
scenic_list = list(getRecommendItems(userCf.recommend(dataModel, int(cUserid)), 'scenic_spot') or [])
# 若不足 6 条,随机补全,hotel/app/router 同理
return render(request, 'index/guess.html', context)评分矩阵构建规则(关键加权策略):
python
def setDataModelWithRules(historys, records, collections, item_type):
dataModel = DataModel()
# 评分:1→-2、2→-1、3→+1、4→+2、5→+3(最低不低于0)
for record in records:
score = float(record.score)
if score == 1: adjusted_score = max(0, score - 2)
elif score == 2: adjusted_score = max(0, score - 1)
elif score == 3: adjusted_score = score + 1
elif score == 4: adjusted_score = score + 2
elif score == 5: adjusted_score = score + 3
else: adjusted_score = score
dataModel.setUserItemValue(record.userid_id, record.appid, adjusted_score)
dataModel.setItemUserValue(record.appid, record.userid_id, adjusted_score)
# 收藏:+5 分(在已有分数基础上叠加)
for collection in collections:
current_score = dataModel.userItemPrefMatrixDic.get(collection.userid_id, {}).get(collection.appid, 0)
new_score = current_score + 5 if current_score else 5
dataModel.setUserItemValue(collection.userid_id, collection.appid, new_score)
dataModel.setItemUserValue(collection.appid, collection.userid_id, new_score)
# 浏览:+1 分(在已有分数基础上叠加)
for history in historys:
current_score = dataModel.userItemPrefMatrixDic.get(history.userid_id, {}).get(history.appid, 0)
new_score = current_score + 1 if current_score else 1
dataModel.setUserItemValue(history.userid_id, history.appid, new_score)
dataModel.setItemUserValue(history.appid, history.userid_id, new_score)
return dataModel协同过滤算法实现
UserCF 通过"用户-用户相似度 + 邻域 + 预测评分"进行推荐:
python
class UserCF(object):
def recommend(self, dataModel, cUserid):
# 1) 基于余弦相似度计算目标用户与其他用户相似度
userSimilarityDic = UserSimilarity().getUserSimilaritys(cUserid, CosineSimilarity(), dataModel)
# 2) 选取前 K 个最近邻
kNUserNeighborhood = UserNeighborhood().getKUserNeighborhoods(userSimilarityDic)
# 3) 预测评分并返回 TopN 推荐
recommenderItemFinalDic = UserRecommender().getUserRecommender(cUserid, dict(kNUserNeighborhood), dataModel)
return sorted(recommenderItemFinalDic.items(), key=operator.itemgetter(1), reverse=True)[:Constant.cfCount]ItemCF 通过"物品-物品相似度 + 用户历史偏好"进行推荐:
python
class ItemCF(object):
def recommend(self, dataModel: DataModel, cUserid):
# 1) 计算物品-物品相似度
itemSimilarityDic = ItemSimilarity().getItemSimilaritys(cUserid, CosineSimilarity(), dataModel)
# 2) 基于用户的已评物品与候选物品的相似度,预测喜好
recItemDic = ItemRecommender().getItemRecommender(cUserid, itemSimilarityDic, dataModel)
return sorted(recItemDic.items(), key=operator.itemgetter(1), reverse=True)[:Constant.cfCount]接口与路由
主路由 TravelRecSys/urls.py:
python
urlpatterns = [
path('', include('apps.common.urls')),
path('', include('apps.index.urls')),
path('index/', include('apps.index.urls')),
path('app/', include('apps.app.urls')),
path('user/', include('apps.user.urls')),
path('record/', include('apps.record.urls')),
path('collection/', include('apps.collection.urls')),
path('comment/', include('apps.comment.urls')),
path('admin/', admin.site.urls),
] + static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)首页与推荐 apps/index/urls.py:
python
urlpatterns = [
path('', views.index), # 首页/列表
path('guess', views.guess_you_like), # 猜你喜欢(登录用户)
]前端与可视化
🦀 项目源码获取,码界筑梦坊各平台同名,博客底部含联系方式卡片,欢迎咨询!
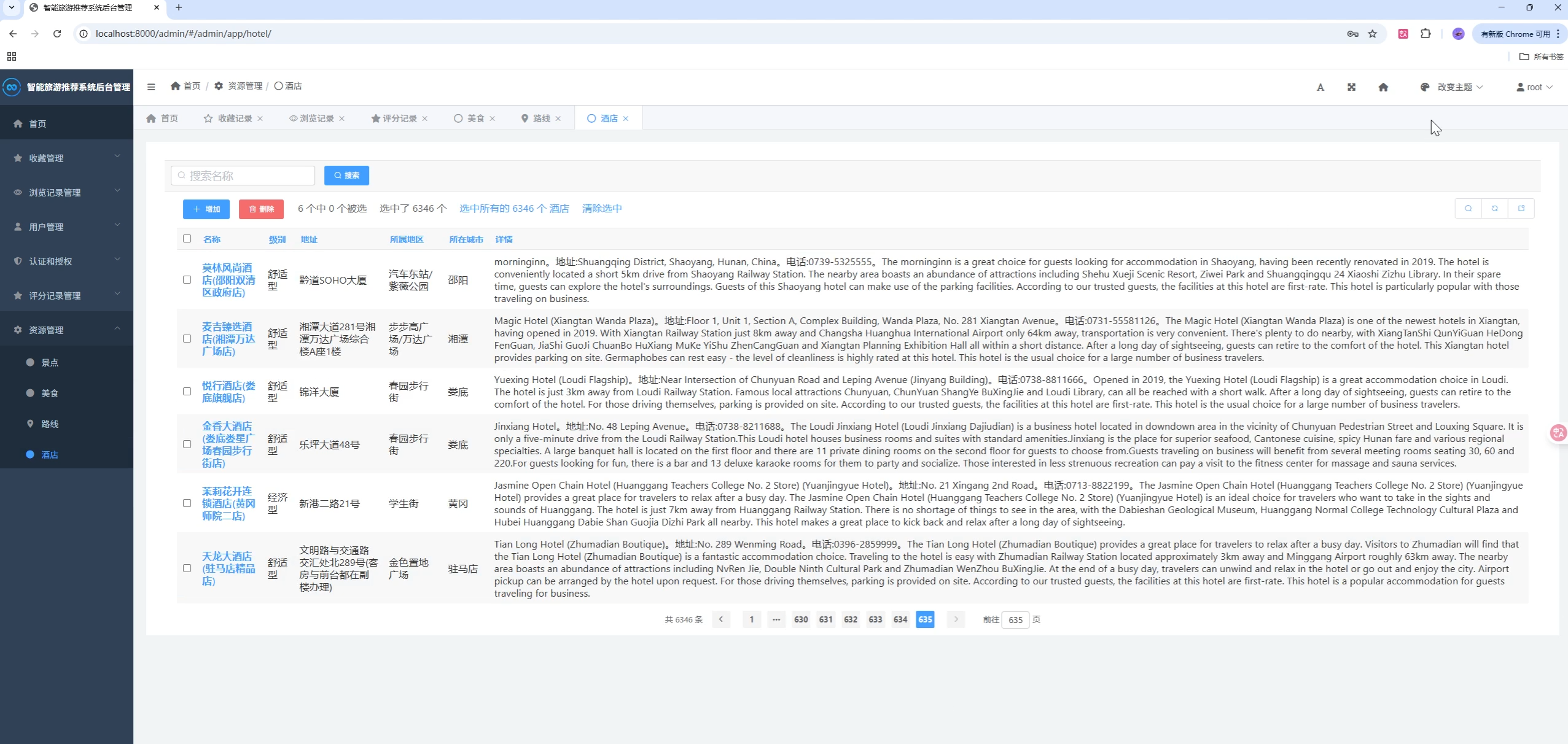
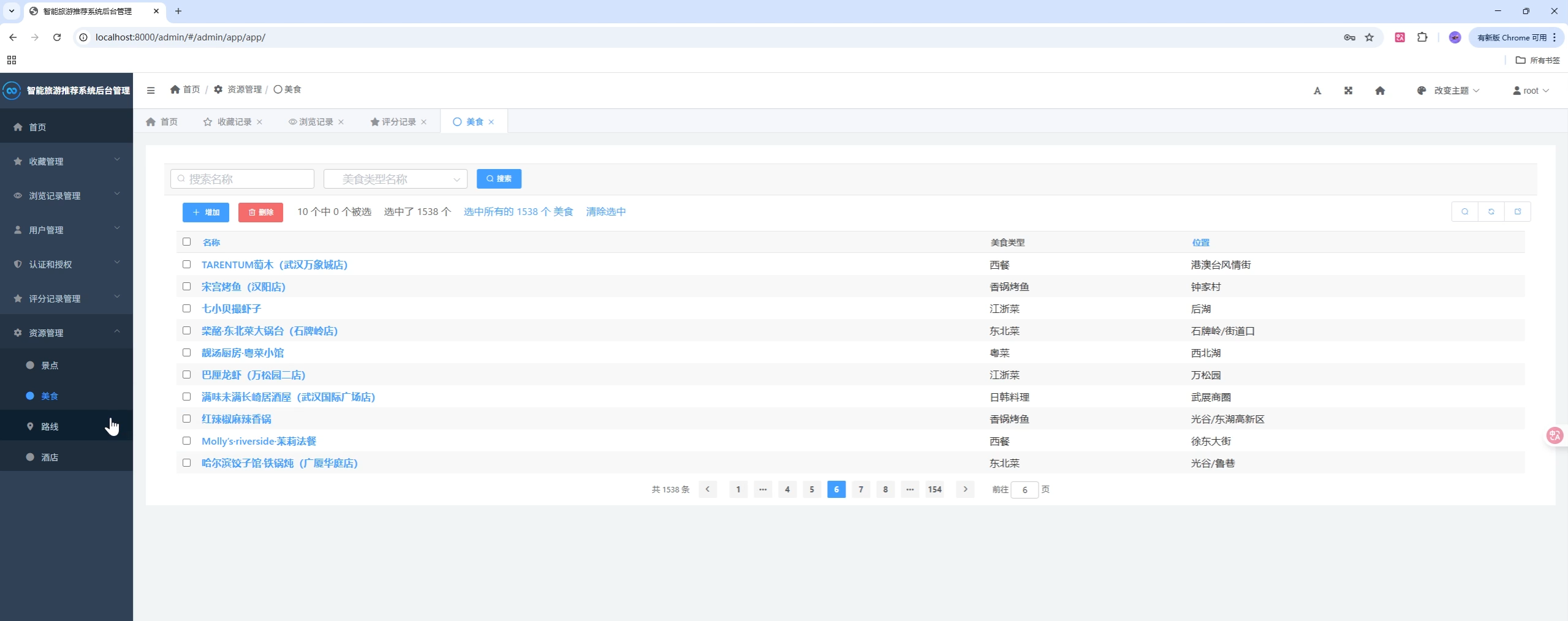
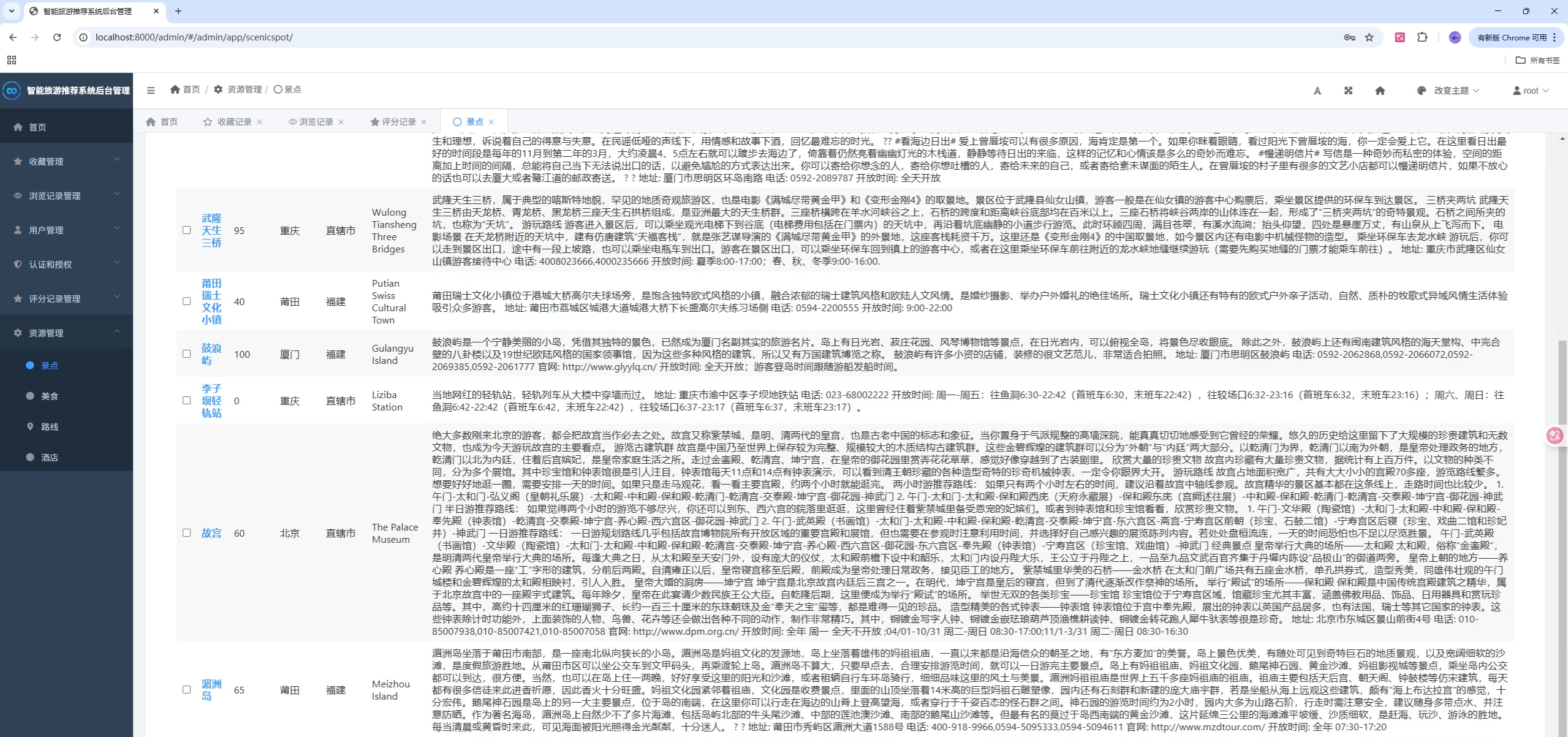
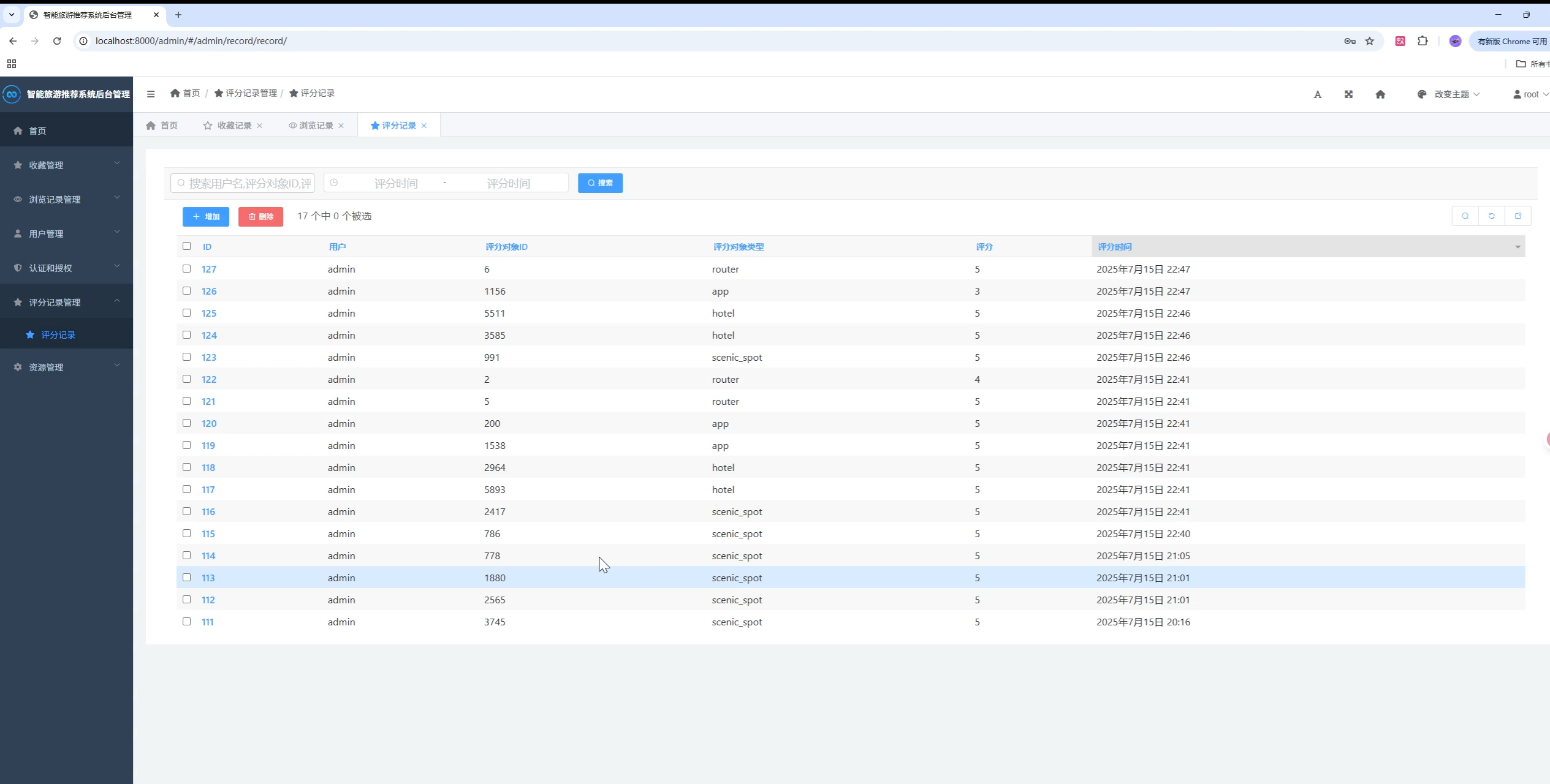
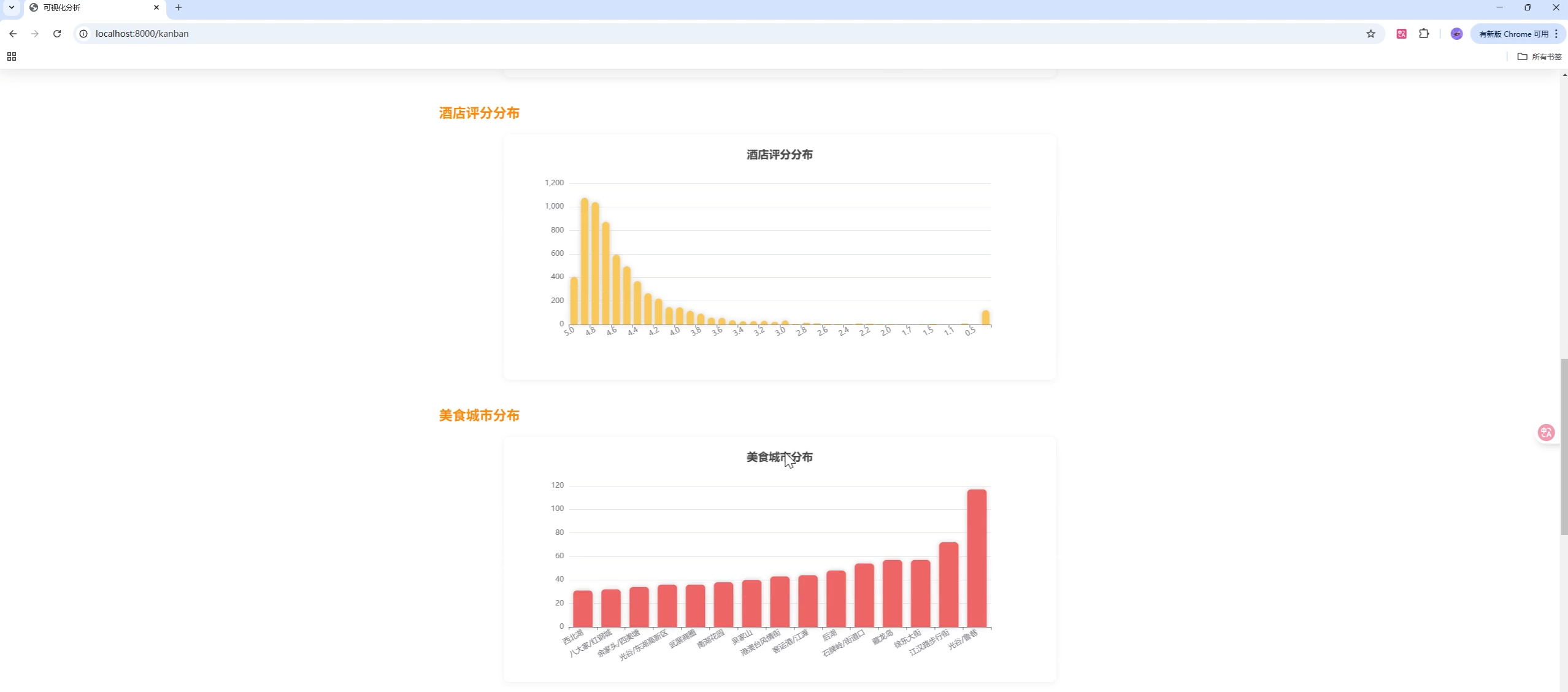
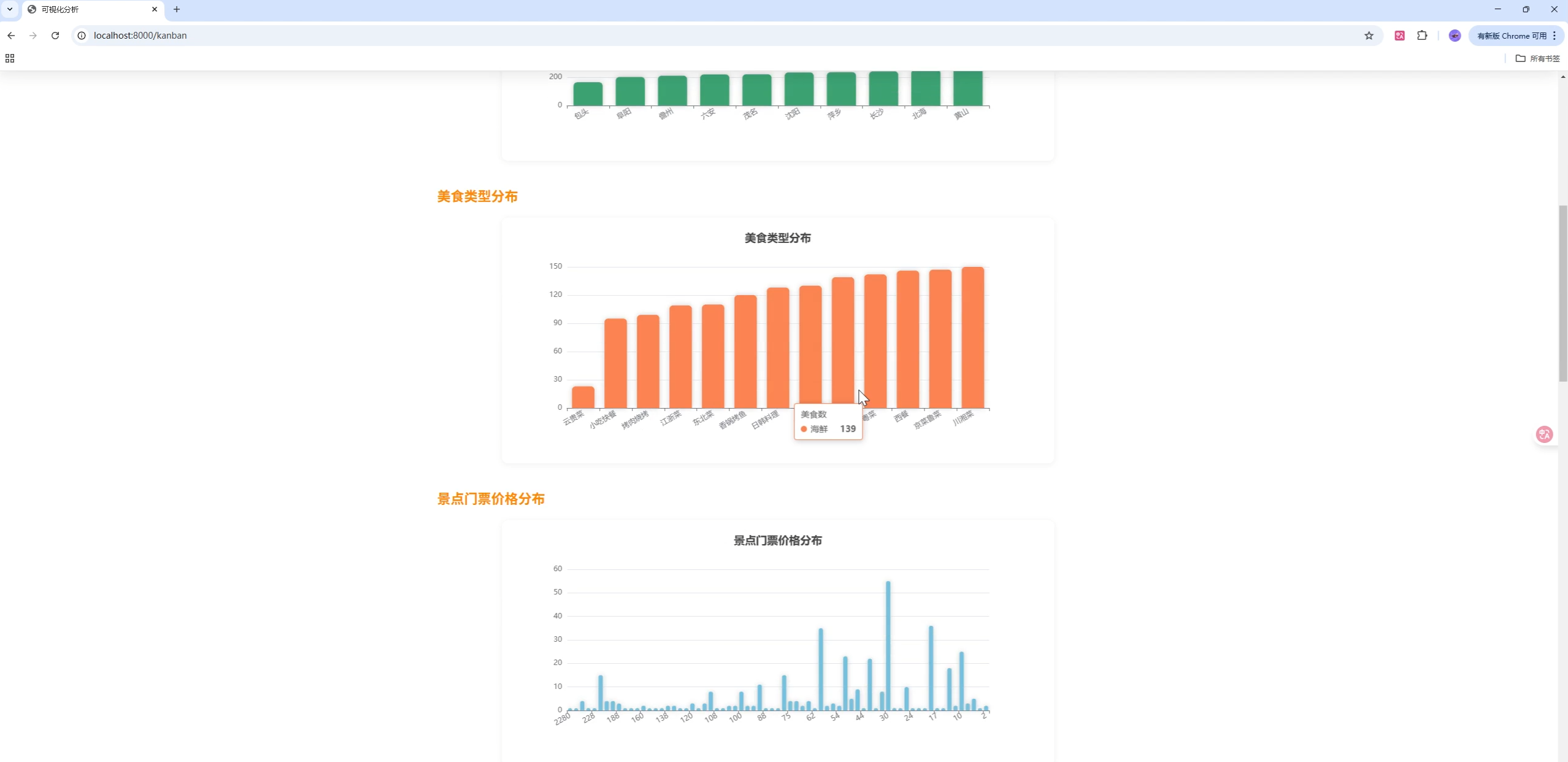
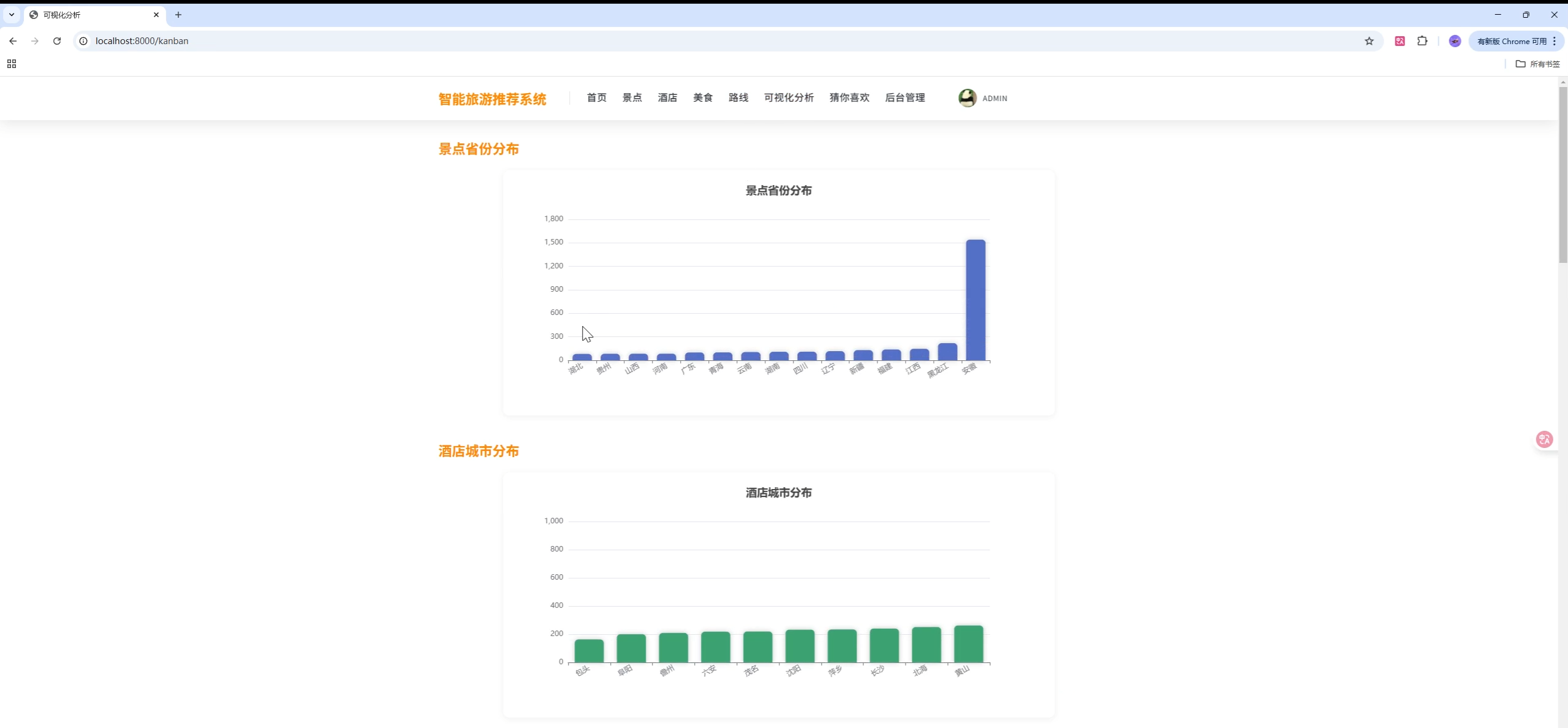
页面模板位于 templates/,静态资源位于 static/。建议在首页与"猜你喜欢"侧添加 ECharts 大盘,可展示:
- 省份分布(Geo/Map)
- 类型占比(Pie/Donut)
- 收藏与评分趋势(Line/Bar)
ECharts 选项(示例,可放入 templates/index/kanban.html):
html
<div id="chart1" style="height: 360px;"></div>
<script src="/static/js/echarts.min.js"></script>
<script>
var chart = echarts.init(document.getElementById('chart1'));
var option = {
title: { text: '景点类型占比' },
tooltip: { trigger: 'item' },
legend: { bottom: 0 },
series: [{
type: 'pie', radius: ['40%', '70%'],
data: [
{ name: '景点', value: 123 },
{ name: '美食', value: 98 },
{ name: '酒店', value: 76 },
{ name: '路线', value: 45 }
]
}]
};
chart.setOption(option);
</script>部署与运行
- 安装依赖
bash
pip install -r requirements.txt-
配置 MySQL 连接(在
TravelRecSys/settings.py内修改数据库配置) -
数据迁移与初始化
bash
python manage.py makemigrations
python manage.py migrate- 创建超级用户
bash
python manage.py createsuperuser- 启动服务
bash
python manage.py runserver- 访问
- 前台:
http://localhost:8000/ - 后台:
http://localhost:8000/admin/
性能与扩展建议
- 分页与延迟加载:列表页默认分页 10 条,减少单页渲染压力
- 缓存:热门资源与推荐结果可加缓存(如基于用户维度的短期缓存)
- 向量化召回:可引入向量检索(Faiss/ScaNN)作为召回层,CF 作为精排
- 多信号融合:评分、收藏、浏览之外,可引入评论情感、停留时长等行为信号
- 推荐评估:A/B 测试、点击率/转化率监控,闭环优化
常见问题 FAQ
- ECharts 图表不显示?
- 确认
static/js/echarts.min.js是否就绪,并正确引入
- 确认
- 图片 404 或显示异常?
- 检查
MEDIA_URL/MEDIA_ROOT配置,确保图片位于media/目录
- 检查
- 后台未显示模型?
- 使用超级用户登录
/admin/,确认相关模型在各 app 的admin.py注册
- 使用超级用户登录
- 推荐结果为空?
- 初期行为数据不足时,会进行随机补全;建议先产生评分/收藏/浏览数据
- 数据库连接失败?
- 检查 MySQL 服务、账号权限与
settings.py配置
- 检查 MySQL 服务、账号权限与
结语与联系方式
如果你正在做课程设计、毕设或企业内小型 PoC,本项目是不错的起点:结构清晰、功能完整、算法可替换。欢迎在此基础上二次开发,如引入多模态、图网络或大模型增强。
联系方式:码界筑梦坊各大平台同名
s.min.js` 是否就绪,并正确引入
- 图片 404 或显示异常?
- 检查
MEDIA_URL/MEDIA_ROOT配置,确保图片位于media/目录
- 后台未显示模型?
- 使用超级用户登录
/admin/,确认相关模型在各 app 的admin.py注册
- 使用超级用户登录
- 推荐结果为空?
- 初期行为数据不足时,会进行随机补全;建议先产生评分/收藏/浏览数据
- 数据库连接失败?
- 检查 MySQL 服务、账号权限与
settings.py配置
- 检查 MySQL 服务、账号权限与
结语与联系方式
如果你正在做课程设计、毕设或企业内小型 PoC,本项目是不错的起点:结构清晰、功能完整、算法可替换。欢迎在此基础上二次开发,如引入多模态、图网络或大模型增强。
联系方式:码界筑梦坊各大平台同名