1. 什么是大模型
大模型(Large Language Model, LLM)是一种基于深度学习的通用人工智能模型,通过海量数据训练,能够理解和生成自然语言(甚至多模态内容),具备广泛的知识储备和推理能力。
大模型像一个"超级大脑",吸收了互联网上的海量知识(书籍、文章、对话等),可以像人类一样回答问题、总结信息、创作内容,甚至解决复杂问题(例如写代码、数学推理)。它的特点是:
- 规模大:参数数量级从百亿到万亿(如 DeepSeek-V3 有6710亿参数)。
- 通用性强:无需针对特定任务训练,通过自然语言指令即可适应多种需求。
- 交互 自然:直接通过对话或文本交互,无需编程基础。
可以简单理解为大语言模型是一种将文本映射到文本的函数。只不过这个函数不是由程序员开发的,而是由深度学习算法生成的。给定一个输入文本字符串,大型语言模型会预测接下来最有可能出现的文本。
2. 什么是提示词
提示词是用户输入给大模型的指令、问题或信息片段,用于引导模型生成特定类型的回答。提示词是模型生成内容的"起点",决定了输出的方向、风格和深度。模型通过分析提示词的语义、结构和隐含需求来生成结果。
提示词 可以包含以下任意要素:
- 指令: 想要模型执行的特定任务或指令。
- 上下文: 包含外部信息或额外的上下文信息,引导语言模型更好地响应。
- 输入数据: 用户输入的内容或问题。
- 输出指示: 指定输出的类型或格式。
示例:
- 简单提示词:写一首关于秋天的诗
- 复杂提示词:以李白的风格,写一首七言绝句,主题是秋天的离别,包含"落叶""孤雁"等意象
3. 大语言模型的"局限"
大语言模型(LLM)虽然拥有强大的知识储备和语言理解能力,但也面临着以下困境:
- 缺乏行动力: LLM只能提供信息,无法直接与现实世界互动。无法执行实际操作,例如煮咖啡、订票、安排会议等。类似于一个博学的教授,只能讲解理论知识,无法进行实际操作。
- 信息滞后: 知识库的更新速度有限,无法获取最新的实时信息。可能提供过时或错误的信息,例如天气预报、股价等。类似于一本印刷好的百科全书,内容固定,无法实时更新。
- 缺乏个性化: 无法根据用户的特定需求提供个性化服务。只能提供通用的信息,无法满足用户的个性化需求。类似于一个没有情感的机器人,只能按照预设的程序执行任务。
- 无法处理复杂 任务 : 无法完成需要多个步骤和工具的协同配合的复杂任务。例如,安排一次旅行,因为旅行需要预订机票、酒店、安排行程等。
- 容易产生" 幻觉 ": 基于统计概率进行预测,而不是真正的理解语言的含义。可能生成不准确或虚构的信息。
4. 什么是大模型应用
基于大模型能力,结合具体场景需求开发的软件或服务。其核心是通过工程化手段,将大模型的通用能力转化为解决实际问题的工具。
关键特点:
- 场景 化:聚焦具体问题(如客服、写作、数据分析)。
- 增强可靠性:通过流程设计避免大模型的"幻觉"(编造错误信息)。
- 集成外部 能力:连接数据库、搜索、API等工具扩展功能。
例子:
- 智能客服:用大模型理解用户问题,自动从知识库提取答案。
- 文档 助手:上传PDF文件,让模型总结内容并回答相关问题。
- 代码生成工具:输入需求描述,自动生成可运行的代码片段。
常见的开发框架和平台
| LangChain | LlamaIndex | AutoGPT | AutoGen | Dify | |
| 定位 | 模块化的通用大模型应用开发框架,支持复杂流程编排和工具集成 | 专注于数据索引与检索增强生成(RAG)的框架 | 基于目标拆解的自主 Agent 框架。 | 多智能体协作框架,支持复杂任务协同 | 低代码LLMOps平台,降低大模型应用开发门槛 |
| 核心功能 | - 多模型兼容:支持OpenAI、Anthropic、通义、deepseek、本地模型等 |
- 链式流程(Chains) :支持多步骤任务串联(如输入处理→检索增强→模型生成→结果过滤)
- 代理(Agents) :动态调用外部工具(API、数据库、搜索引擎)完成任务
- 记忆管理 :支持多轮对话状态维护,结合向量数据库实现长期记忆 | - 高效数据索引:支持结构化/非结构化数据向量化存储,优化检索效率
- 语义 搜索:基于相似性匹配返回精准上下文片段
- 轻量级 API :简化文档加载、分块、查询流程 | - 任务 递归 分解:将用户目标拆解为子任务,自动调用工具执行
- 长期记忆 管理 :结合向量数据库存储历史交互信息 | - 多角色代理:定义不同职能的代理(如执行者、验证者、协调者)
- 动态 交互:代理间通过消息传递协作,解决复杂问题
- 集成外部工具 :支持调用API、数据库和自定义函数 | - 可视化编排:通过拖拽界面设计Prompt、RAG流程和Agent逻辑
- 多模型支持:集成主流模型(如GPT-4、Claude)和第三方API
- 一键部署 :支持快速发布为Web应用或API | | 优点 | - 灵活性强,适合复杂业务逻辑
- 社区生态完善,文档丰富 | - 数据管理能力突出,适合垂直领域知识库
- 代码简洁,学习成本低 | - 自动化程度高,减少人工干预
- 适用于开放式问题解决 | - 支持高并发协作场景
- 与微软生态系统深度集成(如Azure AI) | - 适合非技术团队快速搭建原型
- 内置监控和日志功能,简化运维 | | 缺点 | - 学习曲线陡峭,需熟悉大量组件
- 默认配置性能依赖开发者优化 | - 功能聚焦检索,复杂流程需结合其他工具
- 部署工具链不如LangChain完善 | - 资源消耗不可控(如多次模型调用导致成本高)
- 输出结果稳定性差,易出现逻辑错误 | - 部署复杂度高,需熟悉多线程和分布式系统
- 文档和社区支持相对较少 | - 定制化能力有限,难以满足复杂需求
- 私有化部署依赖云服务,存在数据安全顾虑 | | 场景 | 智能客服、自动化工作流、多模态应用开发 | 企业知识库问答、法律文档摘要、学术论文检索 | 自动化代码生成、数据分析、市场调研 | 智能制造调度、多智能体游戏NPC、分布式数据分析 | 企业内部知识助手、营销文案生成、快速PoC验证 |
5. LangChain
5.1 简介
LangChain 是一个用于开发由大型语言模型 (LLM) 驱动的应用程序的框架。LangChain 简化了 LLM 应用程序的开发、测试和部署。基于 LangChain 的链功能,可以像搭乐高积木一样,、快速构建项目。
LangChain 支持 Python 和 JavaScript 两个开发版本。
5.1.1 v0.1 架构
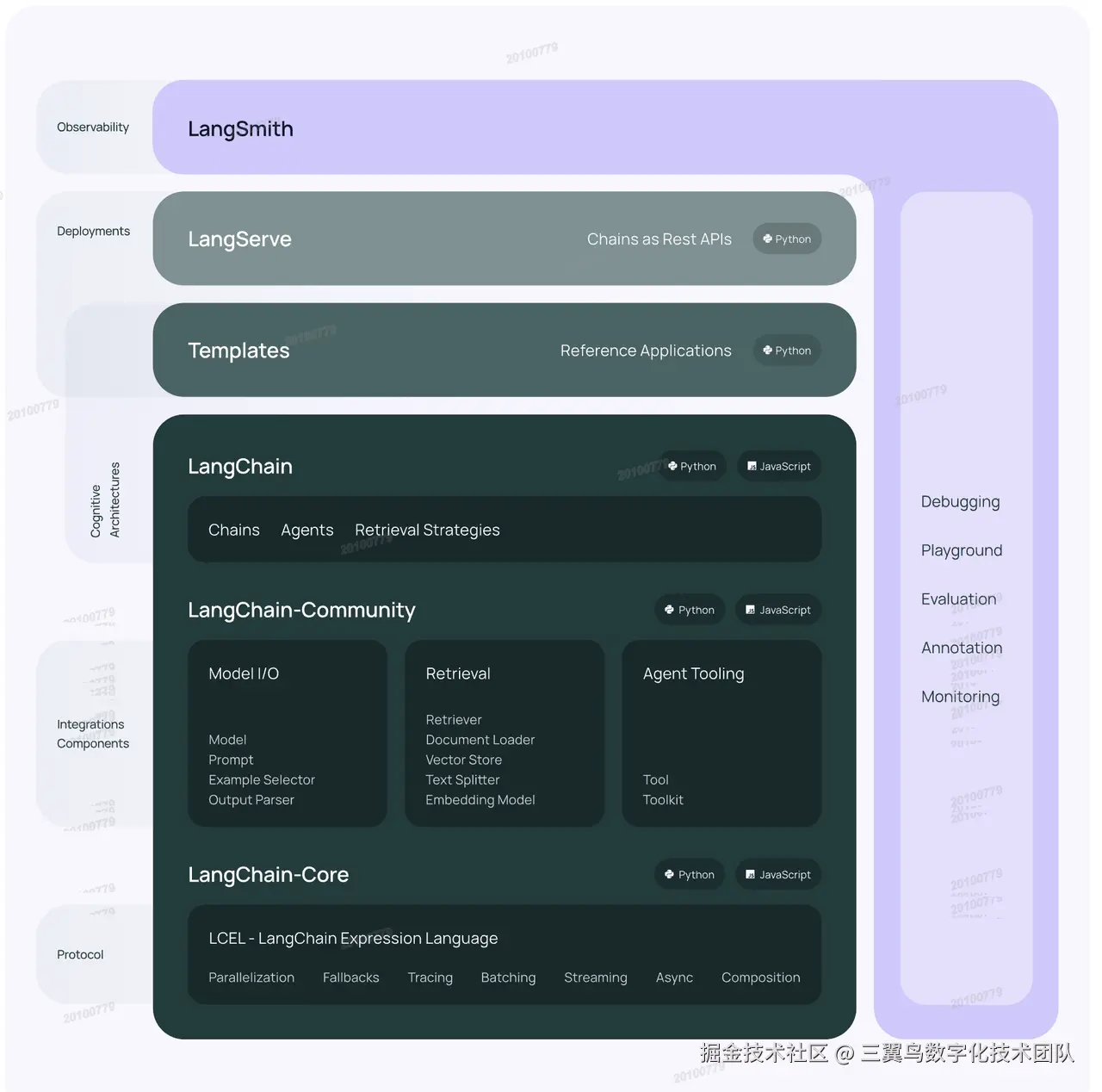
5.1.2 v0.3 架构
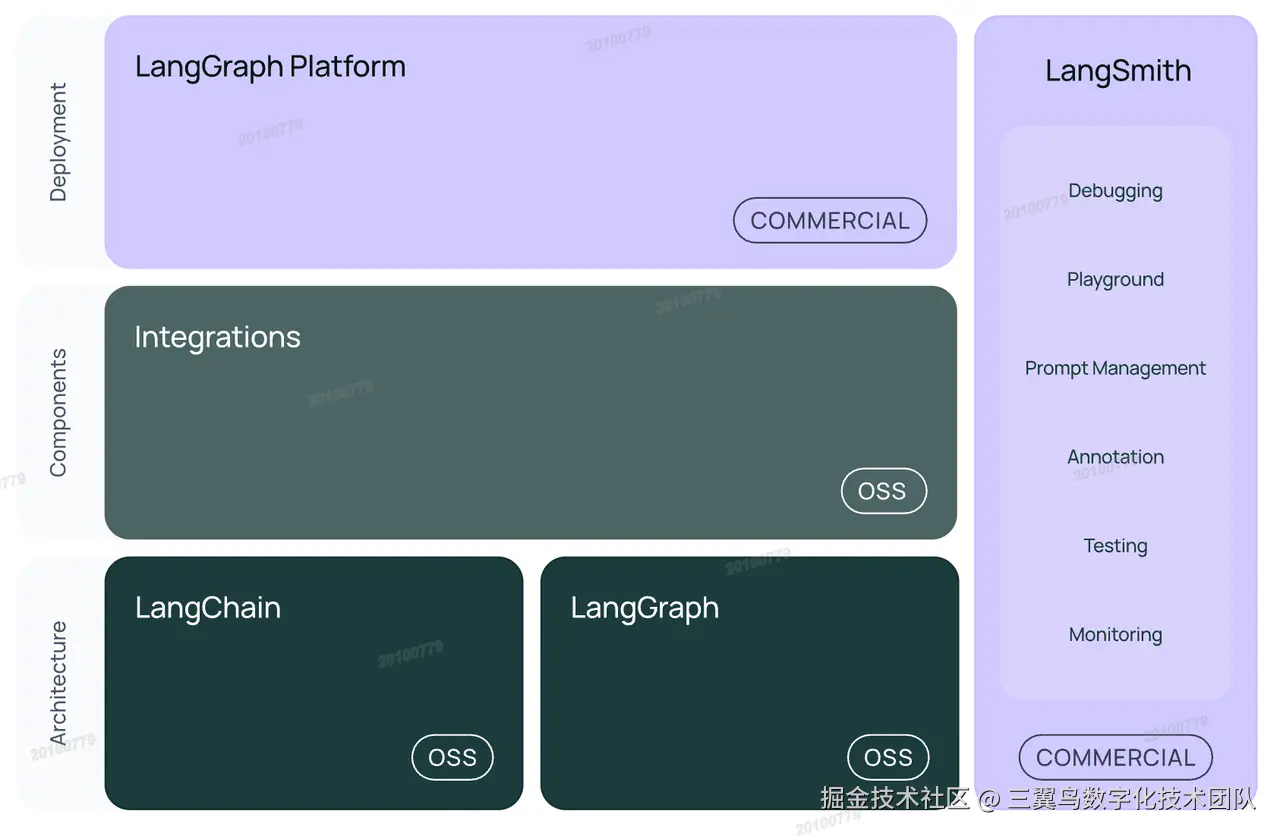
5.2 简单示例
ini
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# other params...
)
messages = [
(
"system",
"你是一个翻译助手,将英语翻译成中文",
),
("human", "I love programming."),
]
ai_msg = llm.invoke(messages)
ai_msg.content5.3 模型 I/O 模块
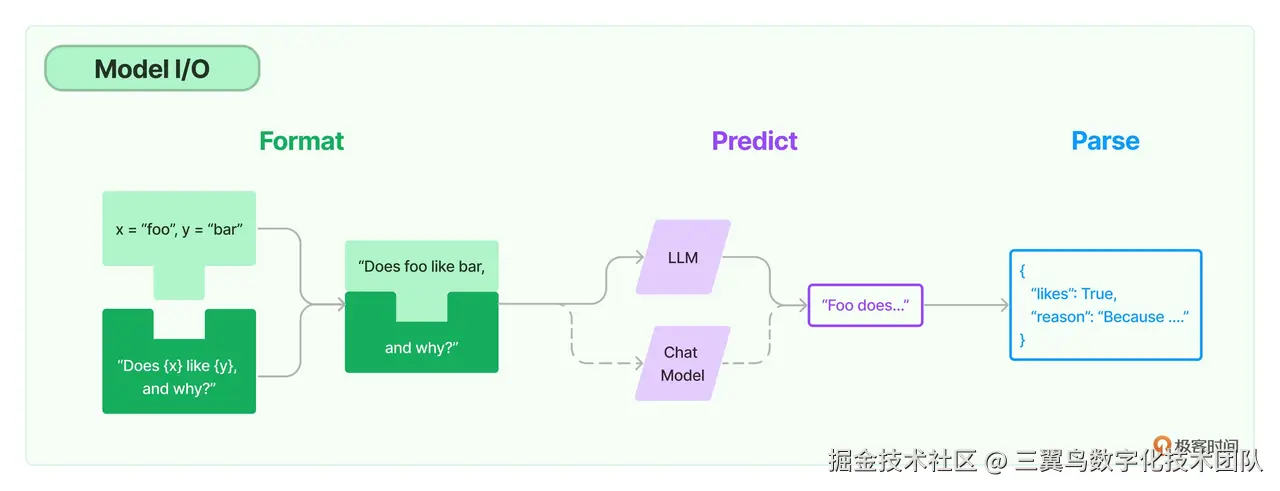
模型 I/O 组件是一种与大语言模型交互的基础组件。模型 I/O 组件的设计目标是:使开发者无须深入理解各个模型平台的 API 调用协议,就可以方便地与各种大语言模型平台进行交互。本质上来说,模型 I/O 组件是对各个模型平台 API 的封装。
5.3.1 模型包装器
LangChain 中支持的模型有三大类,对应有三种模型包装器。
LLM 模型包装器用来与 LLM 模型的API进行交互,LLM 模型也叫 Text Model,这些模型将文本字符串作为输入,并返回文本字符串作为输出。Open AI 的 text-davinci-003、Facebook 的 LLaMA、ANTHROPIC 的 Claude,都是典型的 LLM。
python
from langchain_community.llms import Tongyi
llm = Tongyi()
print(llm.invoke("讲一个笑话"))输出:

聊天模型包装器用来与聊天模型(Chat Model)的API进行交互,主要代表 Open AI 的 ChatGPT 系列模型。这些模型通常由语言模型支持,但它们的 API 更加结构化。具体来说,这些模型将聊天消息列表作为输入,并返回聊天消息。
scss
from langchain_community.chat_models import ChatTongyi
from langchain_core.messages import SystemMessage, HumanMessage
chatLLM = ChatTongyi()
messages = [ SystemMessage( content="你是一个喜剧大师,擅长讲段子" ), HumanMessage( content="讲一个笑话" ),]
aiMessage = chatLLM(messages)
print(aiMessage)输出:

嵌入模型包装器是用来与嵌入模型(Embedding Model)的API进行交互,嵌入模型将文本作为输入并返回浮点数列表,也就是 Embedding。稍后在数据增强模块会再介绍嵌入模型相关知识。
python
from langchain_community.embeddings import ZhipuAIEmbeddings
embeddings = ZhipuAIEmbeddings()
print(embeddings.embed_query("hello world"))输出:
5.3.2 提示词模版
在LangChain框架中,提示词是由"提示模板"(PromptTemplate)这个包装器对象生成的。提示模版(Prompt Templates)是一种将用户输入与预定义的格式或指令结合,生成针对语言模型的输入的工具。可复制、可重用。
提示词模板中可能包含(不是必须包含)以下3个元素。
- 明确的指令:这些指令可以指导大语言模型理解用户的需求,并按照特定的方式进行回应。
- 少量示例:这些示例可以帮助大语言模型更好地理解任务,并生成更准确的响立。
- 用户输入:用户的输人可以直接引导大语言模型生成特定的答案。
LangChain 中提供 String(StringPromptTemplate)和 Chat(BaseChatPromptTemplate)两种基本类型的模板,并基于它们构建了不同类型的提示模板:
| 含义 | |
| StringPromptTemplate | String提示模板 |
| ChatPromptTemplate | Chat 提示模板,用于组合各种角色的消息模板,传入聊天天模型(Chat Model),具体消息模板包括ChatMessagePromptTemplate、HumanMeessagePrompt TemplateAlMessagePromptTemplate 和 SystemMessagePromptTeemplate |
| FewShotPromptTemplate | 少样本提示模板,通过示例的展示来"教"模型如何回答。 |
| PipelinePromptTemplate | 用于把几个提示组合在一起使用。 |
| 自定义模版 | LangChain 还允许基于其他模板类来定制自己的提示模板。 |
StringPromptTemplate
python
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template("Tell me a joke about {topic}.")
print(prompt.invoke({"topic": "cats"}))输出:
ini
text='Tell me a joke about cats.'ChatPromptTemplate
Chat 提示模板,用于组合各种角色的消息模板,传入聊天天模型(Chat Model),具体消息模板包括ChatMessagePromptTemplate、HumanMeessagePrompt TemplateAlMessagePromptTemplate 和 SystemMessagePromptTeemplate
ini
from langchain_core.prompts import ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate
systemMessagePromptTemplate = SystemMessagePromptTemplate.from_template("You are a helpful assistant")
humanMessagePromptTemplate = HumanMessagePromptTemplate.from_template("Tell me a joke about {topic}")
prompt_template = ChatPromptTemplate([
systemMessagePromptTemplate,
humanMessagePromptTemplate
])
print(prompt_template.invoke({"topic": "cats"}))输出:
ini
messages=[SystemMessage(content='You are a helpful assistant', additional_kwargs={}, response_metadata={}), HumanMessage(content='Tell me a joke about cats', additional_kwargs={}, response_metadata={})]FewShotPromptTemplate
少样本提示模板,通过示例的展示来"教"模型如何回答。
ini
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_deepseek import ChatDeepSeek
examples = [
{"input":"高","output":"矮"},
{"input":"胖", "output":"瘦"},
{"input":"精力充沛","output":"萎靡不振"},
{"input": "快乐","output":"伤心"},
{"input":"黑","output":"白"}]
example_prompt = PromptTemplate(intput_variables=["input","output"],
template="""
词语:{input}
反义词:{output}\n
""")
few_shot_prompt = FewShotPromptTemplate(examples=examples,
example_prompt=example_prompt,
example_separator="\n",
prefix="来玩个反义词接龙游戏,我说词语,你说它的反义词\n",
suffix="现在轮到你了,词语:{input}\n反义词:",
input_variables=["input"])
chat = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2
)
chain = few_shot_prompt | chat
ai_message = chain.invoke("坚持")
print(ai_message.content)输出:
放弃提示词 的重要性
1.模型高度依赖输入
大模型(如DeepSeek-V3、GPT-4、Claude)本质上是"无状态的统计生成器",其输出完全由提示词驱动。模糊的提示词会导致模型自由发挥,可能偏离用户需求。
案例:
- 弱提示词:告诉我关于AI → 模型可能泛泛而谈。
- 强提示词:列出2023年AI领域三大技术突破,并分析其对医疗行业的影响 → 输出更聚焦、实用。
2.解决模型局限性
大模型存在幻觉(编造事实)、偏见或逻辑错误,通过提示词工程可显著缓解:
- 约束输出:仅基于权威医学期刊信息回答,不确定时注明"暂无可靠数据"。
- 引导推理:用链式思考(Chain-of-Thought)提示模型分步思考,提升逻辑性。
3.提升效率与可控性
- 减少迭代次数:精准的提示词避免多次调试,节省时间。
- 适配场景需求:通过调整提示词,同一模型可灵活应用于客服(友好简洁)、编程(严谨结构化)、创意(开放发散)等场景。
4.降低使用门槛
无需重新训练模型(成本极高),普通用户通过优化提示词即可定制化输出,极大扩展了大模型的应用范围。
5.应对模型敏感度
大模型对提示词措辞、语序甚至标点敏感,细微改动可能导致结果差异。例如:写一个恐怖故事 vs. 写一个温馨的恐怖故事(以家庭亲情为核心)
提示工程
提示工程 (Prompt Engineering) 是一门新兴的学科,专注于设计、开发和优化用于与大语言模型 (LLM) 交互的提示词。其目的是通过精心设计的提示词来:
- 引导大语言模型生成更准确、更有针对性的输出。
- 提升大语言模型在特定任务上的性能。
- 扩展大语言模型的应用范围。
简而言之,提示工程的目标是最大化大语言模型的潜力,使其能够更好地服务于各种场景和需求。
核心方法包括:
- 结构化指令:明确步骤(如"分三步回答""先解释再举例")。
- 角色扮演: 指定模型身份(如"你是一位资深医生")。
- 上下文增强: 补充背景信息或示例(Few-Shot Learning)。
- 关键词控制: 强调关键术语或排除无关内容。
- 格式约束: 指定输出格式(如JSON、Markdown)。
5.3.3 输出解析器
在使用GPT-4或类似的大语言模型时,一个常见的挑战是如何将模型生成的输出格式转化为可以在代码中直接使用的格式。对于这个问题,通常使用LangChain 的输出解析器(OutputParser)工具来解决。
输出解析器具有两大功能:添加提示词模板的输出指令和解析输出格式。输出解析器通过改变提示词模板,即增加输出指令,来指导模型按照特定格式输出内容。
LangChain提供了一系列预设的输出解析器,这些输出解析器能够针对不同的数据类型给出合适的输出指令,并将输出解析为不同的数据格式。这些输出解析器包括:
| 名称 | 输入类型 | 输出类型 | 描述 |
| Str | str | Message | 解析消息对象中的文本内容,适用于处理不同格式的消息内容 |
| JSON | str | JSON 对象 | 返回指定的 JSON 对象,可用于获取结构化数据 |
| XML | str | dict | 返回标签字典,适用于需要 XML 输出的场景 |
| CSV | str | Liststr | 返回逗号分隔的值列表 |
| OutputFixing | str | Message | 包装另一个输出解析器,如果发生错误,则将错误信息传递给 LLM 并请求修复输出 |
| RetryWithError | str | Message | 包装另一个输出解析器,如果发生错误,则将原始输入、错误输出和错误信息传递给 LLM 并请求修复输出 |
| Pydantic | str | pydantic.BaseModel | 使用用户定义的 Pydantic 模型,返回数据在该格式 |
| YAML | str | pydantic.BaseModel | 使用用户定义的 Pydantic 模型,返回数据在该格式,使用 YAML 编码 |
| PandasDataFrame | str | dict | 用于操作 pandas DataFrame 的数据 |
| Enum | str | Enum | 将响应解析为提供的枚举值之一 |
| Datetime | str | datetime.datetime | 将响应解析为 datetime 字符串 |
| Structured | str | Dictstr, str | 返回结构化信息,字段为字符串,适用于处理较小的 LLM |
ini
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_deepseek import ChatDeepSeek
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
model = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# other params...
)
# Define your desired data structure.
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
# And a query intented to prompt a language model to populate the data structure.
joke_query = "Tell me a joke."
# Set up a parser + inject instructions into the prompt template.
parser = JsonOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
print(chain.invoke({"query": joke_query}))输出:

5.4 数据增强模块
LangChain 框架中的数据增强模块主要用来连接外部的数据。例如本地的文档、网页上的知识、企业内部的知识库、各类研究报告、软件数据库以及聊天的历史记录等。
为什么要连接外部数据
大语言模型虽然很强大,但是知识是有限的,以OpenAI的GPT-4为例, 它的数据集只训练到2023年4月的数据,对之后的信息无法学习理解,因此在训练数据之外领域,其预测准确性受限。
除此之外,有些场景需要个性化的知识,比如企业聊天机器人要准确回答关于产品或服务的问题,必须将内部专有知识整合到大语言模型中,因为模型本身无法直接获取这些知识 。
5.4.1 外部数据处理
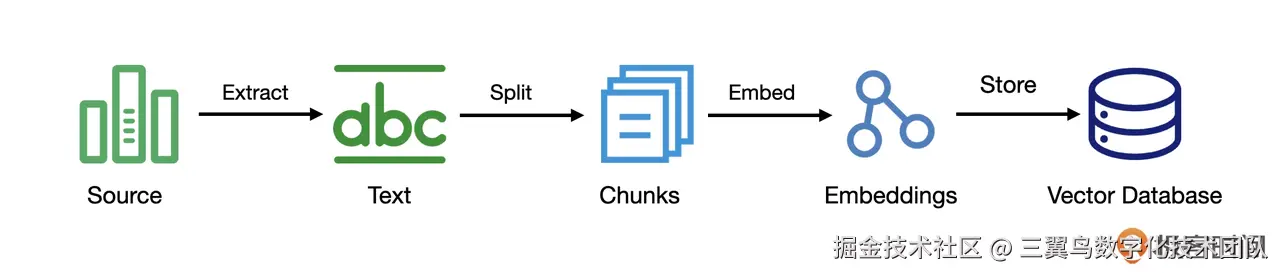
5.4.2 数据增强生成
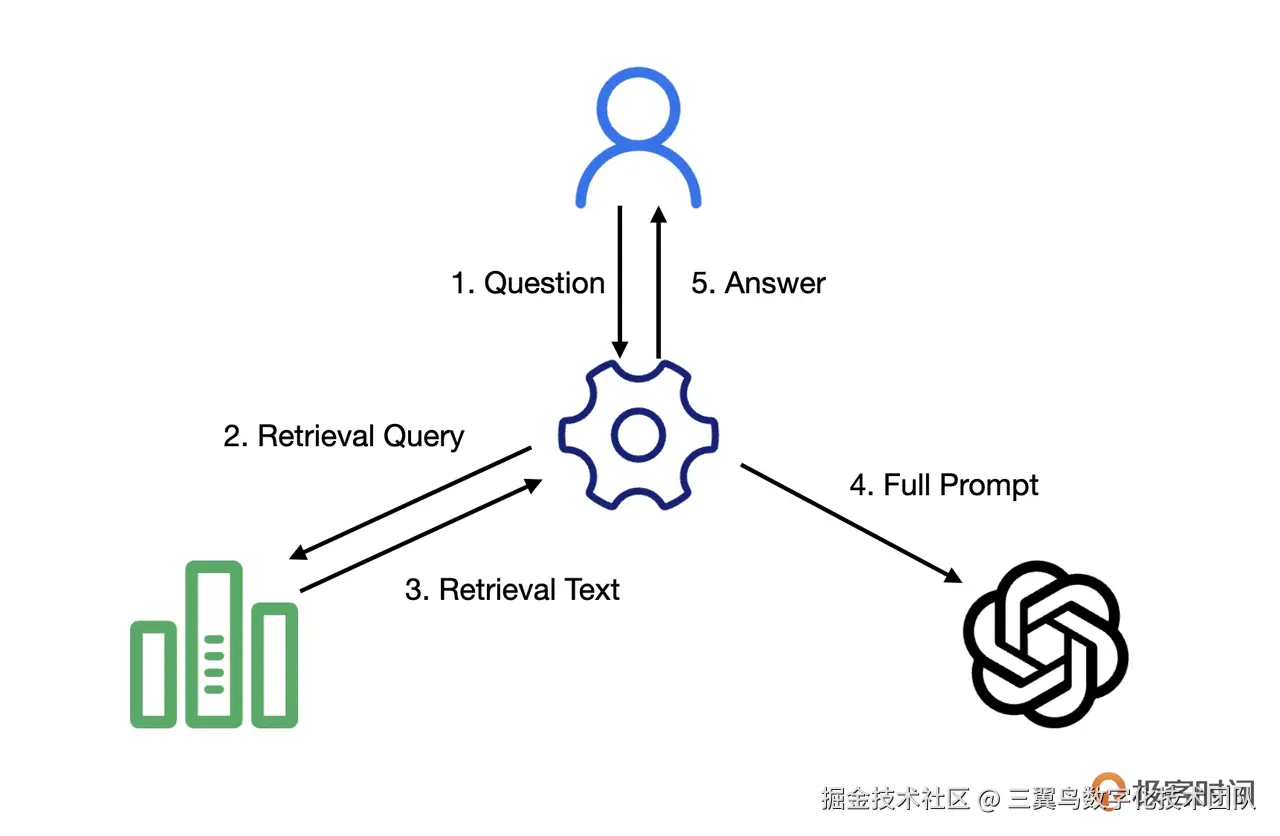
5.4.3 加载器
在 LangChain 的数据处理流程中,加载器可以从各种数据源加载数据,并将数据转换为"文档"(Document)的格式。而且可以处理多种数据格式,例如CSV、文件目录、HTML、JSON、Markdown 及 PDF等。
加载本地 CSV 文件:
ini
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='data.csv',encoding='utf-8')
data = loader.load()加载 web 页面:
ini
import bs4
from langchain_community.document_loaders import WebBaseLoader
page_url = "https://python.langchain.com/docs/how_to/chatbots_memory/"
loader = WebBaseLoader(web_paths=[page_url])
docs = []
async for doc in loader.alazy_load():
docs.append(doc)
assert len(docs) == 1
doc = docs[0]5.4.4 文本分割器
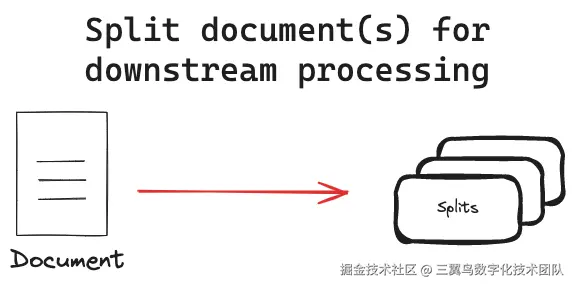
文本分割器的作用是将大型文本拆分成更小的、更易于管理的片段。这主要有以下几个目的:
- 处理非均匀文档长度: 确保所有文档都能以一致的方式进行处理,即使它们的长度不同。
- 克服模型限制: 许多嵌入模型和语言模型都有最大输入大小限制。通过分割文档,可以处理超出这些限制的文档。
- 提高表示 质量 : 对于较长的文档,嵌入或表示的质量可能会下降,因为它们试图捕获过多的信息。分割可以使每个部分的表示更加集中和准确。
- 提高检索精度: 在信息检索系统中,分割可以提高搜索结果的粒度,从而更精确地匹配查询与相关文档部分。
- 优化计算资源: 使用文本的较小片段可以提高内存效率,并允许更好地并行化处理任务。
切割方法
1.基于长度的切割:
- 按字符切割: 将文本按固定字符数切割成多个片段。
- 按词切割: 将文本按固定词数切割成多个片段。
2.基于文本结构的切割:
- 按段落切割: 将文本按段落进行切割。
- 按句子切割: 将文本按句子进行切割。
- 按标题切割: 将文本按标题进行切割(例如,Markdown 中的标题 #、##、###)。
- 按 标签 切割: 将 HTML 文档按标签进行切割。
- 按 JSON 结构切割: 将 JSON 文档按对象或数组元素进行切割。
- 按代码结构切割: 将代码按函数、类或逻辑块进行切割。
3.基于语义意义的切割:
- 通过分析文本的语义,找到文本中语义意义发生显著变化的点,并将文本切割成多个片段。
LangChain 提供的文本切割器:
| 文本切割器 | 切割依据 |
| CharacterTextSplitter | 基于字符数进行切割。 |
| RecursiveCharacterTextSplitter | 基于文本结构进行切割,尝试保持段落等较大单元的完整性。 |
| MarkdownTextSplitter | 基于 Markdown 标题进行切割。 |
| HTMLTextSplitter | 基于 HTML 标签进行切割。 |
| RecursiveJSONTextSplitter | 基于 JSON 结构进行切割。 |
| CodeTextSplitter | 基于代码结构进行切割。 |
swift
markdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n ### Boo \n\n Hi this is Lance \n\n ## Baz\n\n Hi this is Molly"
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits输出:
css
[Document(page_content='Hi this is Jim \nHi this is Joe', metadata={'Header 1': 'Foo', 'Header 2': 'Bar'}), Document(page_content='Hi this is Lance', metadata={'Header 1': 'Foo', 'Header 2': 'Bar', 'Header 3': 'Boo'}), Document(page_content='Hi this is Molly', metadata={'Header 1': 'Foo', 'Header 2': 'Baz'})]5.4.5 文本嵌入
文本嵌入是使用嵌入模型(Embedding Model) 将高维、离散的符号化数据(如文本、图像、音频等)转换为低维、连续的向量表示(即嵌入向量,Embedding Vector)。这种向量化表示能够捕捉数据中的语义、结构和关系。
python
from langchain_community.embeddings import ZhipuAIEmbeddings
embeddings = ZhipuAIEmbeddings()
print(embeddings.embed_query("hello world"))输出:
什么是向量和向量数据
为什么AI大模型离不开向量数据库?_哔哩哔哩_bilibili
5.4.6 检索器
向量存储库种类繁多,比如Chroma、Milvus、FAISS、Pinecone等。如果直接和这些向量存储库进行交互,则可能需要具备深入的数据库操作知识,如了解查询语法管理数据库连接,处理错误和异常等。这样的操作可能较为复杂,并带来不便。LangChain为我们提供了一个标准接口。开发者可以通过在向量存储库的实例上调用as_retriever方法得到一个基于向量存储库的检索器。
从 Chroma 向量库检索:
ini
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import ZhipuAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import CharacterTextSplitter
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, ZhipuAIEmbeddings())
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)从 FAISS 向量库检索:
ini
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import ZhipuAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import CharacterTextSplitter
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, ZhipuAIEmbeddings())
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)5.5 记忆模块
大语言模型本身无记忆能力,无法记住交互历史或学习用户信息,不能满足人们对于聊天机器人的期望。人们期望聊天机器人能理解对话内容、记住交流历史,甚至理解情绪和需求。因此,需要给大语言模型赋予"记忆"能力,使其具备类似人类的记忆功能。这样的记忆能力可以让模型获取最新、准确的上下文数据,提高输出的可靠性,同时作为一种低成本的应用策略。
下面重点探讨不同类型的记忆组件如何影响模型响应。
ConversationBufferMemory
在 LangChain 中,通过 ConversationBufferMemory(缓冲记忆)可以实现最简单的记忆机制。
python
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferMemory
from langchain_deepseek import ChatDeepSeek
# 初始化大语言模型
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# other params...
)
# 初始化对话链
conversation = ConversationChain(
llm=llm,
memory=ConversationBufferMemory()
)
# 第一天的对话
# 回合1
conversation("我姐姐明天要过生日,我需要一束生日花束。")
print("第一次对话后的记忆:", conversation.memory.buffer)
## 输出
## 第一次对话后的记忆:
## Human: 我姐姐明天要过生日,我需要一束生日花束。
## AI: 哦,你姐姐明天要过生日,那太棒了!我可以帮你推荐一些生日花束,你想要什么样的?我知道有很多种,比如玫瑰、康乃馨、郁金香等等。
# 回合2
conversation("她喜欢粉色玫瑰,颜色是粉色的。")
print("第二次对话后的记忆:", conversation.memory.buffer)
## 输出
## 第二次对话后的记忆:
## Human: 我姐姐明天要过生日,我需要一束生日花束。
## AI: 哦,你姐姐明天要过生日,那太棒了!我可以帮你推荐一些生日花束,你想要什么样的?我知道有很多种,比如玫瑰、康乃馨、郁金香等等。
## Human: 她喜欢粉色玫瑰,颜色是粉色的。
## AI: 好的,那我可以推荐一束粉色玫瑰的生日花束给你。你想要多少朵?我可以帮你定制一束,比如说十朵、二十朵或者更多?
# 回合3 (第二天的对话)
conversation("我又来了,还记得我昨天为什么要来买花吗?")
print("/n第三次对话后时提示:/n",conversation.prompt.template)
print("/n第三次对话后的记忆:/n", conversation.memory.buffer)
## 输出
## Human: 我姐姐明天要过生日,我需要一束生日花束。
## AI: 哦,你姐姐明天要过生日,那太棒了!我可以帮你推荐一些生日花束,你想要什么样的?我知道有很多种,比如玫瑰、康乃馨、郁金香等等。
## Human: 她喜欢粉色玫瑰,颜色是粉色的。
## AI: 好的,那我可以推荐一束粉色玫瑰的生日花束给你,你想要多少朵?
## Human: 我又来了,还记得我昨天为什么要来买花吗?
## AI: 是的,我记得你昨天来买花是因为你姐姐明天要过生日,你想要买一束粉色玫瑰的生日花束给她。ConversationBufferWindowMemory
说到记忆,我们人类的大脑也不是无穷无尽的。所以说,有的时候事情太多,我们只能把有些遥远的记忆抹掉。
ConversationBufferWindowMemory 是缓冲窗口记忆,它的思路就是只保存最新最近的几次人类和 AI 的互动。因此,它在之前的"缓冲记忆"基础上增加了一个窗口值 k。这意味着我们只保留一定数量的过去互动,然后"忘记"之前的互动。
ini
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
# 创建大语言模型实例
llm = OpenAI(
temperature=0.5,
model_name="gpt-3.5-turbo-instruct")
# 初始化对话链
conversation = ConversationChain(
llm=llm,
memory=ConversationBufferWindowMemory(k=1)
)
# 第一天的对话
# 回合1
result = conversation("我姐姐明天要过生日,我需要一束生日花束。")
print(result)
#输出:
# {'input': '我姐姐明天要过生日,我需要一束生日花束。',
# 'history': '',
# 'response': ' 哦,你姐姐明天要过生日!那太棒了!你想要一束什么样的花束呢?有很多种类可以选择,比如玫瑰花束、康乃馨花束、郁金香花束等等,你有什么喜欢的吗?'}
# 回合2
result = conversation("她喜欢粉色玫瑰,颜色是粉色的。")
# print("\n第二次对话后的记忆:\n", conversation.memory.buffer)
print(result)
# 输出:
# {'input': '她喜欢粉色玫瑰,颜色是粉色的。',
# 'history': 'Human: 我姐姐明天要过生日,我需要一束生日花束。\nAI: 哦,你姐姐明天要过生日!那太棒了!你想要一束什么样的花束呢?有很多种类可以选择,比如玫瑰花束、康乃馨花束、郁金香花束等等,你有什么喜欢的吗?',
# 'response': ' 好的,那粉色玫瑰花束怎么样?我可以帮你找到一束非常漂亮的粉色玫瑰花束,你觉得怎么样?'}
# 第二天的对话
# 回合3
result = conversation("我又来了,还记得我昨天为什么要来买花吗?")
print(result)
# 输出:
# {'input': '我又来了,还记得我昨天为什么要来买花吗?',
# 'history': 'Human: 她喜欢粉色玫瑰,颜色是粉色的。\nAI: 好的,那粉色玫瑰花束怎么样?我可以帮你找到一束非常漂亮的粉色玫瑰花束,你觉得怎么样?',
# 'response': ' 当然记得,你昨天来买花是为了给你喜欢的人送一束粉色玫瑰花束,表达你对TA的爱意。'}ConversationSummaryMemory
ConversationSummaryMemory(对话总结记忆)的思路就是将对话历史进行汇总,然后再传递给 {history} 参数。这种方法旨在通过对之前的对话进行汇总来避免过度使用 Token。
ini
from langchain.chains.conversation.memory import ConversationSummaryMemory
# 初始化对话链
conversation = ConversationChain(
llm=llm,
memory=ConversationSummaryMemory(llm=llm)
)ConversationSummaryBufferMemory
对话总结缓冲记忆,它是一种混合记忆模型,结合了上述各种记忆机制,包括 ConversationSummaryMemory 和 ConversationBufferWindowMemory 的特点。这种模型旨在在对话中总结早期的互动,同时尽量保留最近互动中的原始内容。
它是通过 max_token_limit 这个参数做到这一点的。当最新的对话文字长度在 max_token_limit 字之内的时候,LangChain 会记忆原始对话内容;当对话文字超出了这个参数的长度,那么模型就会把所有超过预设长度的内容进行总结,以节省 Token 数量。
ini
from langchain.chains.conversation.memory import ConversationSummaryBufferMemory
# 初始化对话链
conversation = ConversationChain(
llm=llm,
memory=ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=300))5.6 链
LangChain 的 Logo 是一只鹦鹉和链条 🦜🔗。鹦鹉,象征大语言模型的"学舌"能力,提示这类模型对人类文本的强大预测能力。而链条,则由无数链组成,象征链模块中各种链组件的有序连接。
链模块的强大之处在于,它将分散的组件连接在一起,使得整个应用程序的流程更加清晰、有序,从而更易于理解和管理。
通过链模块对数据的组织和管理,我们看到了一个完整的数据处理流程,从输人数据的接收,到数据的处理,再到最终的模型预测。
5.6.1 链的类型
| 链名称 | 功能 | 适用场景 |
| LLMChain | ||
| LLMRouterChain | 使用 LLM 来路由输入 | 适用于需要根据 LLM 的判断将输入路由到不同模型或知识库的场景,例如多模型问答系统、知识图谱问答系统等。 |
| RetrievalQA | 使用检索器检索相关文档,并使用 LLM 生成响应 | 适用于需要从大量文档中检索信息并生成回答的场景,例如问答系统、信息提取等。 |
| RetrievalQAWithSources | 在检索的文档上执行问答并引用来源 | 适用于需要生成带有来源引用的答案的场景,例如学术写作、新闻报道等。 |
| RetrievalQAWithSourcesChain | 在检索的文档上执行问答并引用来源 | 与 RetrievalQAWithSources 功能类似,但提供链的形式,方便与其他链组合使用。 |
| QAGenerationChain | 从文档中创建问题和答案 | 适用于需要生成问题/答案对进行评估的场景,例如信息检索系统、自动问答系统等。 |
| MultiPromptChain | 在多个提示之间路由输入 | 适用于需要根据不同条件使用不同提示的场景,例如多模态问答系统、个性化推荐系统等。 |
| MapReduceDocumentsChain | 将文档分组并通过迭代减少它们 | 适用于需要将大量文档分解成小块进行处理并生成最终答案的场景,例如文本摘要、文本分类等。 |
| RefineDocumentsChain | 通过生成初始答案并循环遍历剩余文档来细化答案 | 适用于需要逐步改进答案的场景,例如机器翻译、文本摘要等。 |
| EmbeddingRouterChain | 使用嵌入相似度来路由查询 | 适用于需要根据查询语义将查询路由到不同模型或知识库的场景,例如多模型问答系统、知识图谱问答系统等。 |
ini
# LLMChain:简单问答
chain = LLMChain(llm=llm, prompt=prompt)
response = chain.run("问题")5.6.2 LangChain Expression Language (LCEL)
LCEL 是 LangChain 提供的一种类似Linux管道操作的符号语言,用于方便地构建LLMChain。
makefile
# LCEL:多步骤流程(检索 → 生成 → 后处理)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| output_parser
)除了语法简洁以外,LCEL 还具备以下优势:
- 优化 并行 执行: 可以使用 RunnableParallel 或 Runnable Batch API 并行执行 Runnable,从而显著提高效率。
- 确保异步支持: 任何使用 LCEL 构建的链式操作都可以异步执行,适用于需要处理大量并发请求的服务器环境。
- 简化流式输出: LCEL 链式操作可以流式输出,允许在执行过程中逐步获取输出结果,并优化输出流以提高效率。
- 标准 API : 所有链式操作都使用 Runnable 接口,因此可以使用相同的 API 进行调用。
5.7 Agent 模块
这里的 Agent 模块是指 LangChain 框架内所有与Agent功能有关的组件的集合。
在大模型应用领域,Agent ( 智能体 ) 是指一种能够通过感知环境、自主规划、调用工具并执行任务,最终实现复杂目标的智能系统。它以大语言模型(LLM)为核心,结合规划、记忆、工具调用等模块,赋予模型主动决策和动态执行的能力,突破了传统模型仅被动响应用户输入的局限。
在 LangChain 的代理中,有这样几个关键组件。
- 代理( Agent ) :这个类决定下一步执行什么操作。它由一个语言模型和一个提示(prompt)驱动。提示可能包含代理的性格(也就是给它分配角色,让它以特定方式进行响应)、任务的背景(用于给它提供更多任务类型的上下文)以及用于激发更好推理能力的提示策略(例如 ReAct)。LangChain 中包含很多种不同类型的代理。
- 工具(Tools): 工具是代理调用的函数。这里有两个重要的考虑因素:一是让代理能访问到正确的工具,二是以最有帮助的方式描述这些工具。如果你没有给代理提供正确的工具,它将无法完成任务。如果你没有正确地描述工具,代理将不知道如何使用它们。LangChain 提供了一系列的工具,同时你也可以定义自己的工具。
- 工具包(Toolkits): 工具包是一组用于完成特定目标的彼此相关的工具,每个工具包中包含多个工具。比如 LangChain 的 Office365 工具包中就包含连接 Outlook、读取邮件列表、发送邮件等一系列工具。当然 LangChain 中还有很多其他工具包供你使用。
- 代理执行器(AgentExecutor): 代理执行器是代理的运行环境,它调用代理并执行代理选择的操作。执行器也负责处理多种复杂情况,包括处理代理选择了不存在的工具的情况、处理工具出错的情况、处理代理产生的无法解析成工具调用的输出的情况,以及在代理决策和工具调用进行观察和日志记录。
ini
from langchain.agents import initialize_agent, AgentType
from langchain_community.agent_toolkits.load_tools import load_tools
from langchain_deepseek import ChatDeepSeek
# 初始化聊天模型
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# other params...
)
tools = load_tools(["serpapi", "llm-math"], llm = llm)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.invoke("海尔智家今天股票收盘价是多少?")输出:

5.7.1 Tools/Toolkits
| 工具 | 描述 |
| Search | 执行在线搜索的工具,例如 SerpAPI、Bing Search、Brave Search、DuckDuckGoSearch 等。 |
| Code Interpreter | 可以作为代码解释器的工具,例如 Azure Container Apps dynamic sessions、Bearly Code Interpreter、Riza Code Interpreter 等。 |
| Productivity | 用于自动化生产力工具任务的工具,例如 Github Toolkit、Gitlab Toolkit、Gmail Toolkit、Infobip Tool、Jira Toolkit、Office365 Toolkit、Slack Toolkit、Twilio Tool 等。 |
| Web Browsing | 用于自动化网页浏览器任务的工具,例如 AgentQL Toolkit、Hyperbrowser Browser Agent Tools、Hyperbrowser Web Scraping Tools、MultiOn Toolkit、PlayWright Browser Toolkit、Requests Toolkit 等。 |
| Database | 用于自动化数据库任务的工具,例如 Cassandra Database Toolkit、SQLDatabase Toolkit、Spark SQL Toolkit 等。 |
| Finance | 用于执行金融交易等任务的工具,例如 GOAT。 |
| All tools | 包含所有以上工具以及其他更多工具,例如 ADS4GPTs、AgentQL、AINetwork Toolkit、Alpha Vantage、Amadeus Toolkit、Apify Actor、ArXiv、AskNews、AWS Lambda、Azure AI Services Toolkit、Azure Cognitive Services Toolkit、Azure Container Apps dynamic sessions 等。 |
5.7.2 Function calling
LangChain Agent 模块的工具调用基于 Function calling 技术,Function calling 是一种让大型语言模型(如GPT-4、Claude等)与外部工具、API或程序化功能交互的关键技术。其核心思想是让模型不仅能生成文本,还能根据用户需求动态调用预定义的外部函数,从而扩展模型的能力边界,解决其固有局限性(如无法实时获取数据、无法执行具体操作等)。
核心机制
-
意图识别:当用户提出请求时,模型首先分析其意图,判断是否需要调用外部函数(例如查询天气、计算数学公式、调用数据库等)。
-
参数生成:若需要调用函数,模型会按照预定义的函数格式(如函数名称、参数结构)生成结构化参数(通常是JSON格式)。例如:
json
{
"function": "get_weather",
"params": {"location": "北京", "date": "2024-07-20"}
}-
执行外部函数:开发者通过代码实际实现这些函数(如调用天气API、执行代码片段),并将结果返回给模型。
-
结果整合:模型将函数返回的结果(如实时天气数据)与上下文结合,生成最终的自然语言回复。
交互流程
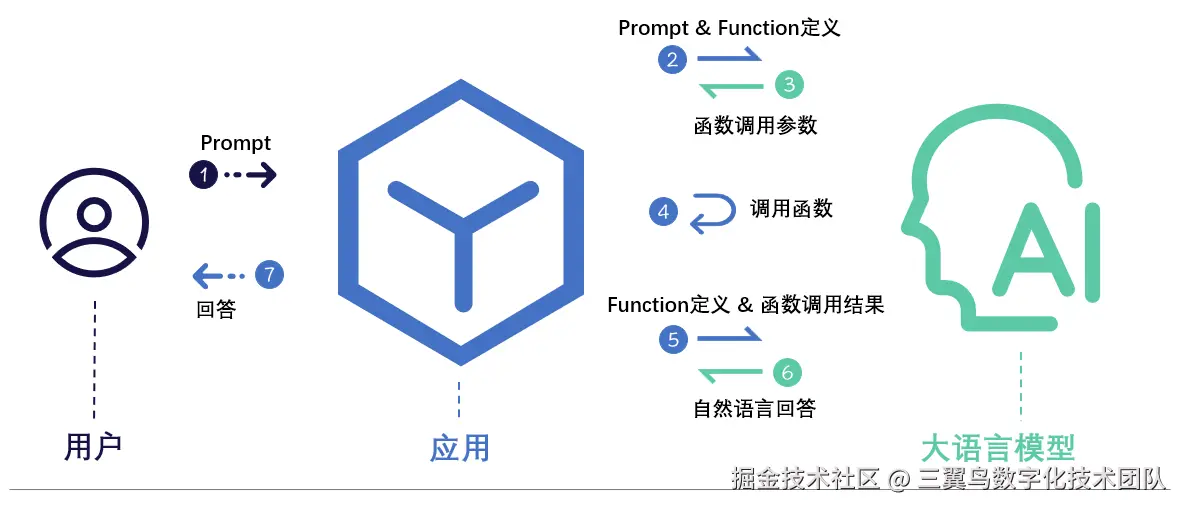
缺点
Function Calling 的缺点在于处理不好多轮对话和复杂需求,适合边界清晰、描述明确的任务。如果需要处理很多的任务,那么 Function Calling 的代码比较难维护。
5.7.3 MCP
模型上下文协议(MCP)是一种开放协议,它能够实现大模型应用与外部数据源和工具的无缝集成。MCP 协议的目的是让各个应用程序和 AI 模型之间,有一种通用的标准的方式,能够快捷的交换信息。
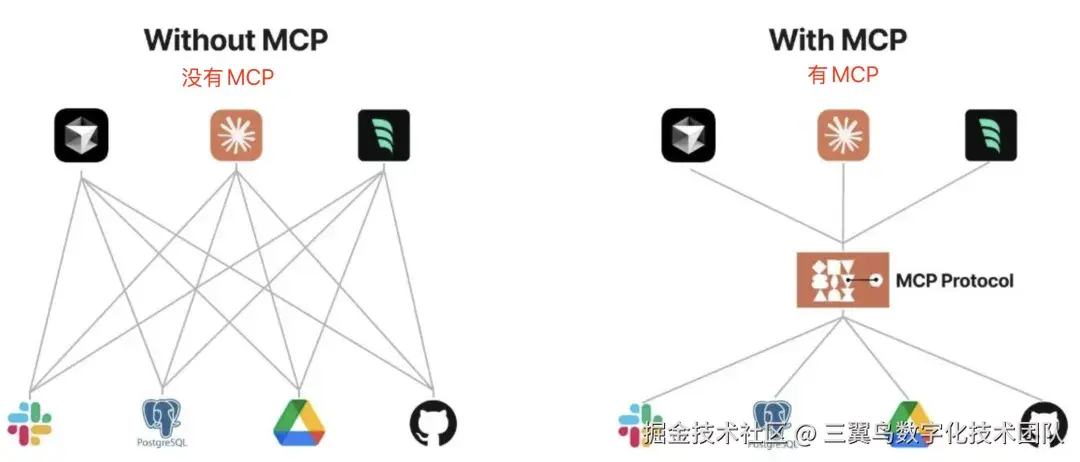
MCP 总体架构
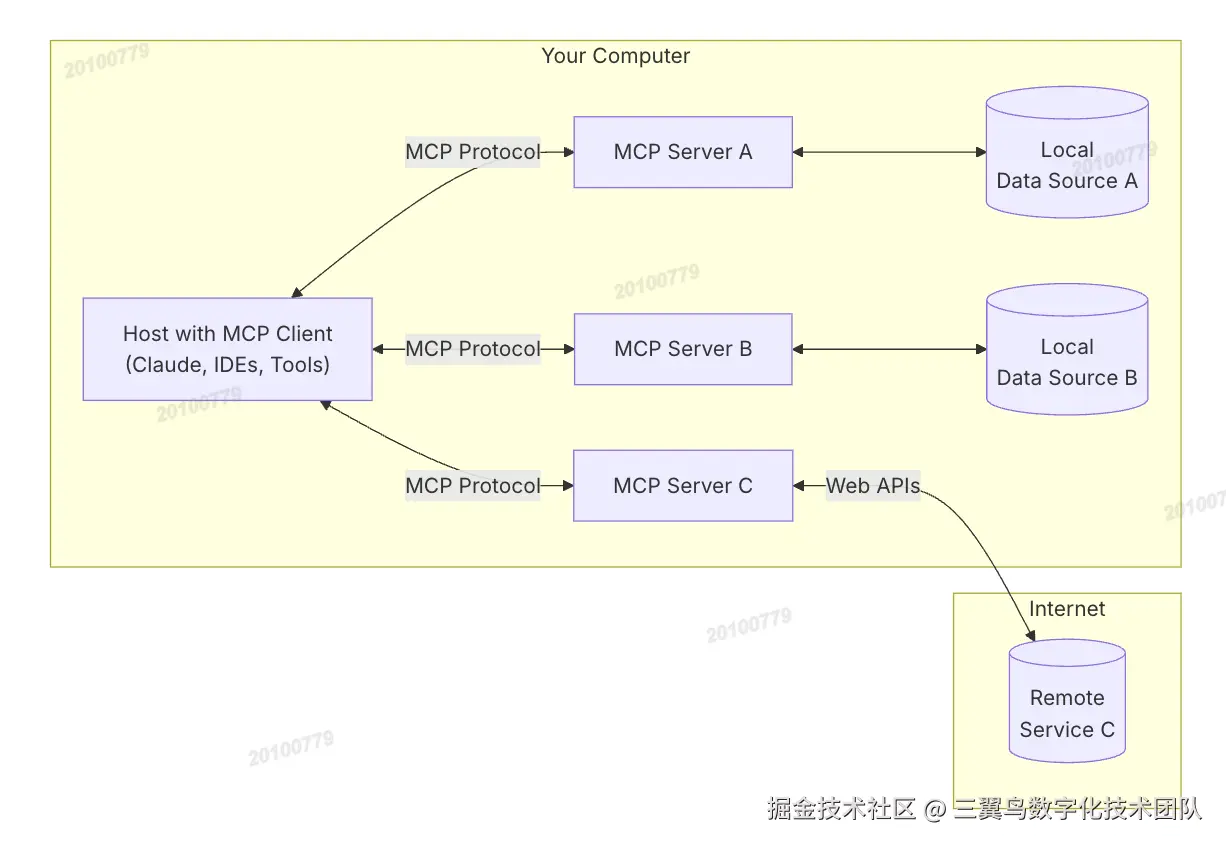
总共分为了下面五个部分:
- MCP Hosts: Hosts 是指大模型应用程序,像 Cursor, Claude Desktop、Cline 这样的应用程序。
- MCP Clients: 客户端是用来在 Hosts 应用程序内维护与 Server 之间连接。
- MCP Servers: 通过标准化的协议,为 Client 端提供上下文、工具和提示。
- Local Data Sources: 本地的文件、数据库和 API。
- Remote Services: 外部的文件、数据库和 API。
6. LangSmith
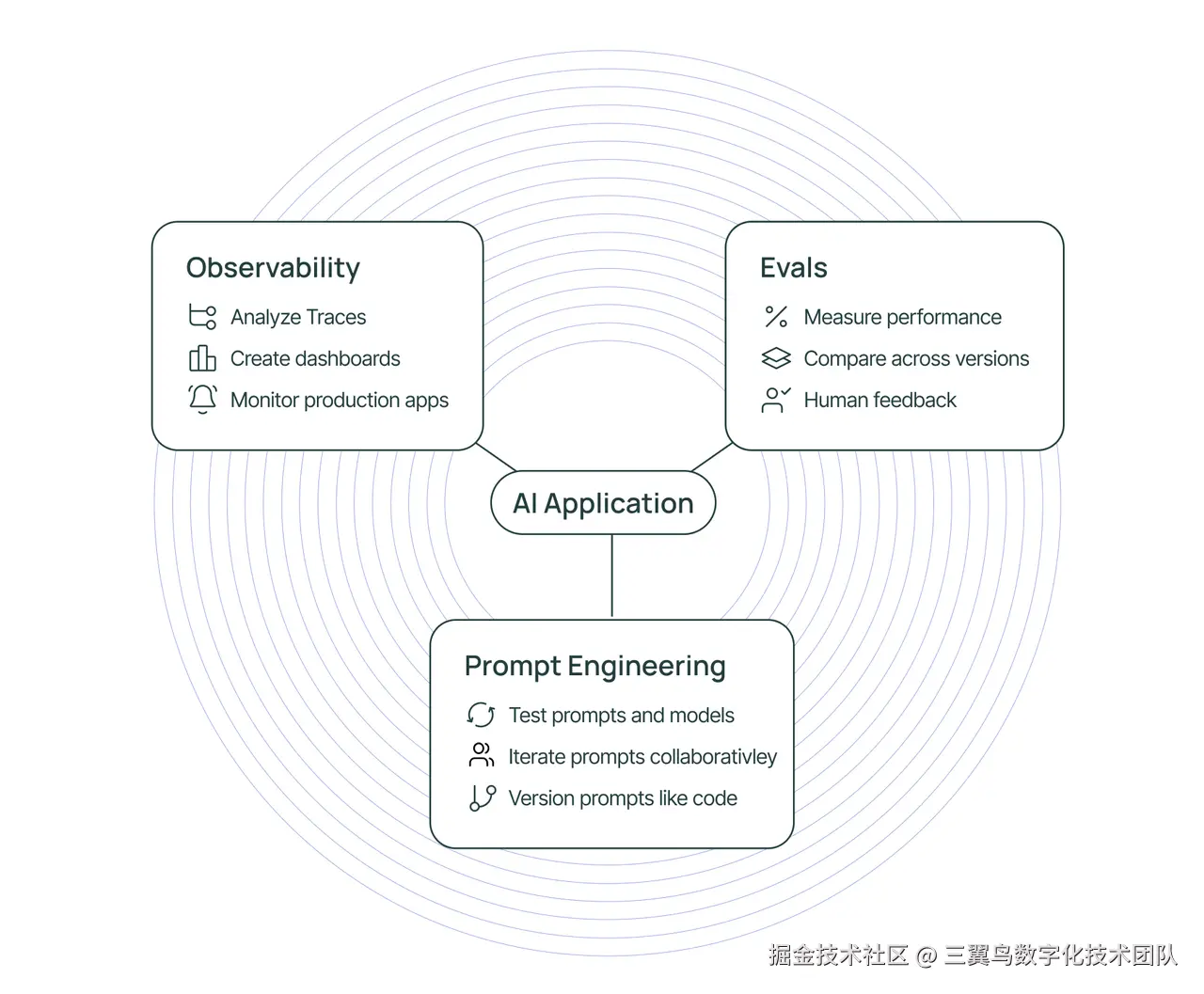
LangSmith 是一个支持跟踪、监控和评估LLM应用程序的平台,具有可观测性、评估和提示工程功能,能无缝集成LangChain和LangGraph,也可独立使用。
可观测性
LangSmith 提供了 LLM 原生的可观测性功能,帮助用户分析应用程序的运行情况,并通过仪表板、指标和警报来监控关键性能指标。
评估
LangSmith SDK 和 UI 简化了高质量评估的构建和运行,包括创建评估、分析结果和收集人类反馈。
提示工程
LangSmith 提供了一套工具,帮助用户迭代和改进提示,包括自动版本控制和协作功能。
6.1 如何 Debug 应用
与构建其他类型的软件一样,在使用 LangChain 构建 LLM 应用时,有时我们也需要进行调试。模型调用可能会失败,或者模型输出格式错误,或者会有一些嵌套的模型调用,不清楚哪一步输出错误。
主要有三种调试方法:
- Verbose Mode: 会为链中的"重要"事件添加打印语句。
- Debug Mode: 会为链中的所有事件添加日志语句。
- LangSmith Tracing: 会将事件记录到 LangSmith 以便在那里进行可视化。
Verbose Mode
通过设置 verbose=True 或 verbose=False 来开启或关闭 Verbose Mode
verbose=True 时:
verbose=False 时:

Debug Mode
python
from langchain.globals import set_debug
## 开启 Debug Mode
set_debug(True)
## 关闭 Debug Mode
set_debug(False)7. LangGraph
LangGraph 是 LangChain的一个库,专为构建有状态、多角色应用而设计。该库扩展了 LangChain 表达式语言的功能,使之能够协调多条链(或多个角色)在多个计算步骤中的循环交互。
循环在智能体行为中扮演着关键角色,例如,在一个循环中调用LLM,以确定接下来应采取的行动。
LangGraph通过引入了"状态图"(StateGraph)这个概念,改进了原来基于 AgentExecutor 的黑盒调用过程。它将基于 LLM 的任务细节(如RAG、代码生成等)通过图的形式(包括图的节点和边)进行精确定义。基于这个图,LangGraph编译生成应用。
7.1 LangGraph 的基本概念
-
StateGraph: 整个状态图的基础类,它构成了图的核心框架。
-
Nodes(节点): 状态图的重要组成部分,可以是可调用的函数、运行的链或代理。点 END 表示任务运行的结束。
-
Edges(边): 用于连接节点,表示节点之间的跳转关系。边包括3种类型。
- StartingEdge:特殊边,标识任务运行的起始点,无前置节点。
- NormalEdge:普通边,表示节点间的顺序执行关系。
- Conditional Edge:条件边,根据上游节点的执行结果和预设条件函数,决定跳转到哪个下游节点。
7.2 LangGraph 的使用场景
- 异步工作流程。在异步工作流程中,建议将LangGraph的节点默认设置为异步,以优化执行效率。
- 流式传输。当语言模型响应时间较长时,流式传输数据至最终用户,以确保实时、流畅的交互体验。
- 持久性存储。LangGraph具有内置持久性,支持保存图的状态并在需要时恢复,确保数据安全和连续性。
- 人机交互循环。LangGraph 支持人机交互循环工作流,允许在特定节点前进行人工审核,确保流程的准确性。
- 图形可视化。为便于理解复杂代理的内部逻辑,LangGraph提供图形输出和可视化方去支持生成ASCII艺术和PNG图像。
- 时光旅行功能。该功能允许用户跳转到图形执行的任意点,修改状态并重新执行,对调试和面向最终用户的工作流极为有用。
7.3 示例
python
from langgraph.graph import StateGraph, END
from typing import TypedDict, List, Annotated
import operator
# 1. 定义状态结构(自动合并消息历史)
class State(TypedDict):
messages: Annotated[List[str], operator.add] # 自动累积消息
continue_loop: bool # 控制循环的标记
# 2. 定义两个节点(问答处理逻辑)
def question_node(state: State):
"""生成问题"""
return {
"messages": [f"系统提问:请描述您遇到的问题?"],
"continue_loop": True
}
def answer_node(state: State):
"""处理回答(模拟简单逻辑)"""
last_msg = state["messages"][-1]
if "error" in last_msg.lower():
return {"messages": ["解决方案:请尝试重启应用"]}
else:
return {"messages": ["解决方案:请检查网络连接"]}
# 3. 构建工作流
graph = StateGraph(State)
# 添加节点
graph.add_node("ask", question_node)
graph.add_node("answer", answer_node)
# 设置入口点
graph.set_entry_point("ask")
# 定义边(带条件循环)
graph.add_edge("ask", "answer") # 提问 → 回答
# 根据用户回答决定是否继续
graph.add_conditional_edges(
"answer",
lambda state: "ask" if state["continue_loop"] else END, # 如果 continue_loop=True 则继续循环
{"ask": "ask", "end": END}
)
# 编译应用
app = graph.compile()
# 4. 运行示例(手动模拟用户输入)
initial_state = {"messages": [], "continue_loop": True}
result = app.invoke(initial_state)
print("\n对话历史:")
for msg in result["messages"]:
print(f"- {msg}")8. References
《LangChain入门指南:构建高可复用、可扩展的LLM应用程序》
《LangChain实战派:大语言模型+LangChain+向量数据库》
python.langchain.com/docs/introd...
time.geekbang.org/column/intr...
modelcontextprotocol.io/introductio...
guangzhengli.com/blog/zh/mod...
9. 团队介绍
「三翼鸟数字化技术平台-ToC服务平台」以用户行为数据为基础,利用推荐引擎为用户提供"千人千面"的个性化推荐服务,改善用户体验,持续提升核心业务指标。通过构建高效、智能的线上运营系统,全面整合数据资产,实现数据分析-人群圈选-用户触达-后效分析-策略优化的运营闭环,并提供可视化报表,一站式操作提升数字化运营效率。