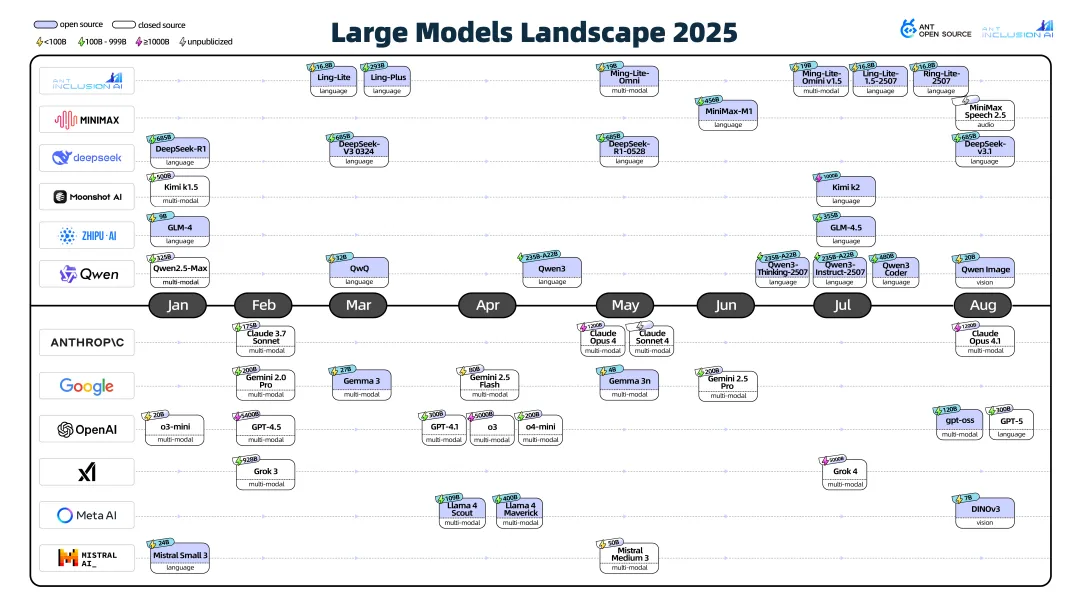
2025年主流大模型呈现快速迭代态势,各版本频繁更新,部分模型在特定领域实现突破性创新,达到SOTA水平。值得注意的是,开源模型的涌现有力推动了AI技术的民主化进程。具体数据如下图所示:
LLM架构变化
2025年LLM架构前沿的探索情况也是如火如荼,各大厂商都在不断探索,不断优化,不断推出新的架构。目前大语言模型架构呈现多样化发展,主要包括基于Transformer、基于Mamba以及混合架构(如Transformer与Mamba结合)等多种形式。从当前的发展趋势来看,混合架构在LLM领域的应用会越来越广泛,未来可能会成为一个重要的发展方向。
一篇深入解析LLM架构的对比研究 The Big LLM Architecture Comparison From DeepSeek-V3 to Kimi K2: A Look At Modern LLM Architecture Design
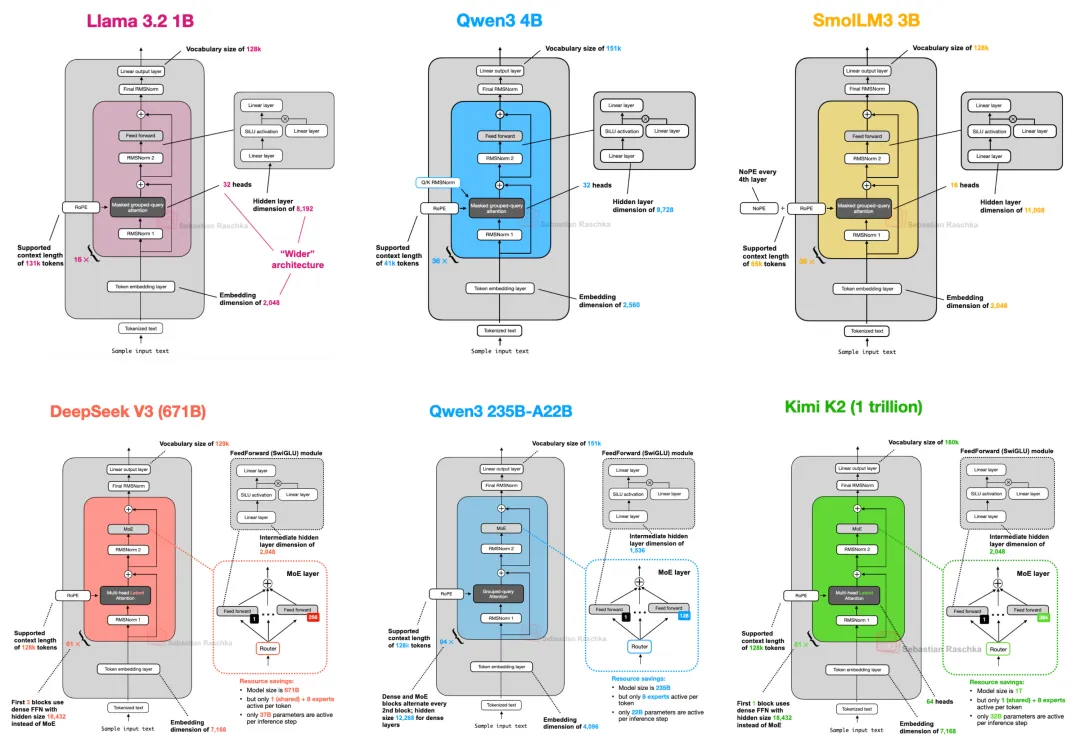
文中观点2025 年一些旗舰开源大语言模型(LLM)在架构上的发展变化。虽部分组件如位置编码、注意力机制、激活函数有改进,但整体架构基础变化不大。当前头部的LLM架构都是在Decoder-only Transformer上不断做优化,使得训练出来的模型表现越来越好。
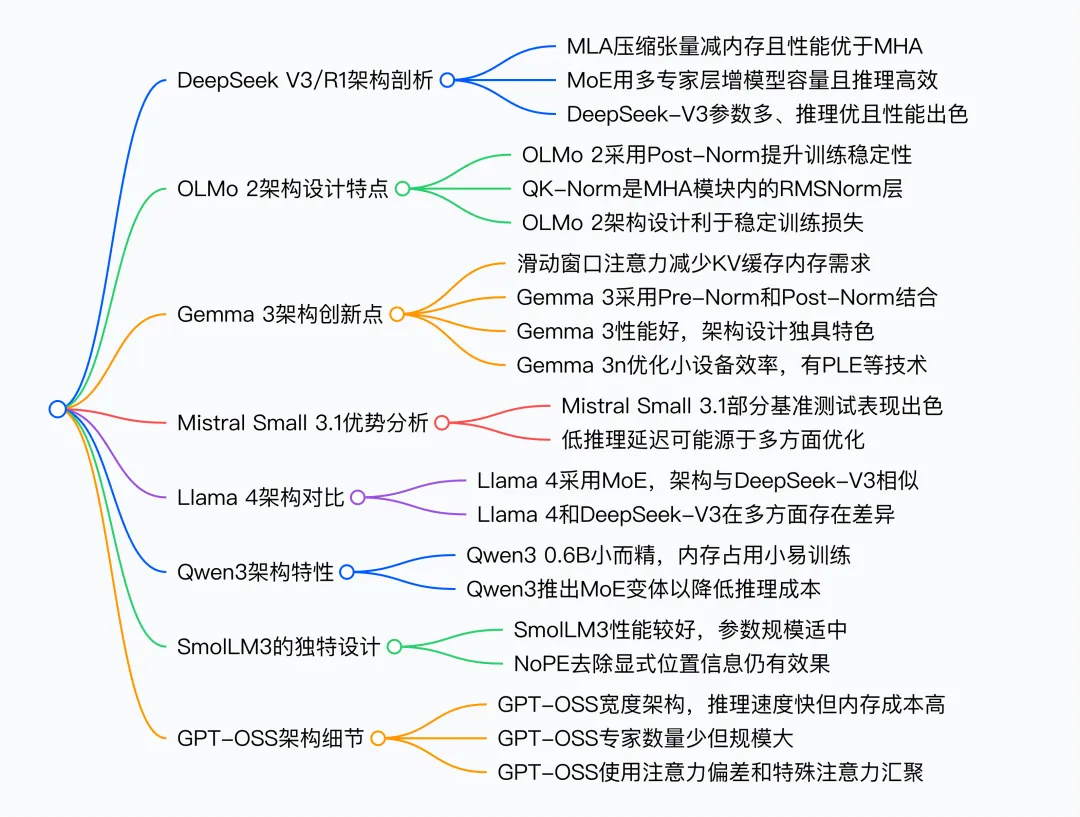
DeepSeek V3/R1 的创新架构:DeepSeek V3 基于其推出的推理模型 R1 备受关注。它采用了Mixture of Experts (MoE) 和 Multi-Head Latent Attention (MLA) 机制,使用 MoE,以多个专家层替代前馈模块,虽增加总参数,但每次仅少量专家激活,如 DeepSeek - V3 有 256 个专家,推理时仅 9 个激活,既提升模型能力又保持推理效率,还设有共享专家提升整体性能。同时通过将关键值张量压缩进低维空间存储于 KV 缓存,推理时再投影回原尺寸,减少内存使用且建模性能优于传统多头注意力(MHA)。最新的V3.2还创新性应用了DSA稀疏注意力机制,效率大幅提升和成本显著降低。DeepSeek构建了包含1800多个虚拟环境和超过8.5万条复杂指令的数据集进行强化学习,使其智能体能力达到开源模型最高水平。
OLMo 2 的架构调整:OLMo 2 由非营利机构开发,因训练数据和代码透明受关注。其架构主要在归一化方面有特色,采用类似 Post - LN 的方式,将 RMSNorm 层置于注意力和前馈模块之后,且在注意力机制内对查询和键添加 RMSNorm(QK - norm),两者共同稳定训练损失,虽仍使用传统 MHA,但三个月后发布的 32B 变体采用了 GQA。
Gemma 3 的独特设计:Gemma 3 是性能良好却在开源界未受充分重视的模型。它使用滑动窗口注意力,限制上下文大小,减少 KV 缓存内存需求,相比 Gemma 2 调整了全局与局部注意力比例,窗口大小也从 4096 降至 1024,对建模性能影响小。此外,其归一化层在注意力和前馈模块前后都放置 RMSNorm,结合 Pre - Norm 和 Post - Norm 优点。之后推出的 Gemma 3n 针对小设备优化,采用 Per - Layer Embedding 参数层和 MatFormer 概念提升效率。
MoE 架构的广泛应用:MoE 架构在 2025 年颇受欢迎,DeepSeek V3、Llama 4、Qwen3 等模型都采用。如 Llama 4 架构与 DeepSeek V3 相似,但 Llama 4 使用分组查询注意力,MoE 设置为较少但更大的专家,且 MoE 和密集模块在变压器块中交替。Qwen3 推出密集和 MoE 两种版本,MoE 版本用于降低大模型推理成本,满足不同用户需求。
参考资料: