💖💖作者:计算机编程小央姐
💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持! 💜💜
💕💕文末获取源码
目录
学生考试表现影响因素Hadoop+Spark实现方案-系统功能介绍
基于大数据的学生考试表现影响因素数据可视化分析系统是一个运用现代大数据技术栈构建的教育数据分析平台。该系统采用Hadoop分布式存储框架和Spark大数据计算引擎作为核心技术架构,结合Python编程语言和Django Web框架进行后端开发,前端采用Vue.js配合ElementUI组件库和ECharts可视化库实现交互界面。系统通过MySQL数据库存储学生的学习行为数据、家庭背景信息、教育资源获取情况等多维度数据,运用Spark SQL和Pandas、NumPy等数据处理工具对海量教育数据进行深度挖掘分析。平台能够从学生个人学习行为、家庭背景因素、教育资源环境、社会健康因素等五大维度对影响学生考试成绩的关键要素进行量化分析,通过相关性分析、回归分析等统计方法揭示各因素与考试表现之间的内在关联,并以直观的图表形式展现分析结果,为教育管理者和研究人员提供数据驱动的决策支持工具。
学生考试表现影响因素Hadoop+Spark实现方案-系统技术介绍
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
学生考试表现影响因素Hadoop+Spark实现方案-系统背景意义
随着教育信息化进程的不断深入,各类教育机构积累了大量关于学生学习过程和成果的数据资源,这些数据涵盖了学生的出勤记录、学习时长、历史成绩、家庭背景、教师评价等多个维度的信息。传统的教育评估方式往往依赖于经验判断和单一指标分析,难以全面把握影响学生学业表现的复杂因素网络。学生的考试成绩作为衡量学习效果的重要指标,其背后隐藏着学习习惯、家庭环境、教育资源配置、身心健康状况等多重影响机制的交互作用。在大数据时代背景下,如何运用现代数据处理技术对这些多元化的教育数据进行有效整合和深度分析,从中发现影响学生考试表现的关键要素及其作用规律,成为教育研究领域亟待解决的重要课题。
本课题的研究具有较为重要的理论价值和实践意义。从理论层面来看,通过运用大数据分析技术对学生考试表现的影响因素进行系统性研究,有助于丰富教育数据挖掘领域的理论基础,为后续相关研究提供方法参考和技术路径。从实践应用角度分析,该系统能够帮助教育管理者更加客观地认识影响学生学业成就的多维因素,为制定针对性的教学改进措施和学生个性化辅导方案提供数据支撑。教师可以通过系统分析结果了解不同因素对学生表现的影响程度,从而调整教学策略和关注重点。学生及家长也能够通过可视化分析结果更好地理解学习成效的影响机制,促进家校合作和学习行为的优化调整。作为一个毕业设计项目,本系统在技术实现上综合运用了Hadoop、Spark等大数据处理框架,体现了对现代数据科学技术栈的掌握和应用能力,同时在教育领域的具体应用中展现了一定的创新性思考。
学生考试表现影响因素Hadoop+Spark实现方案-系统演示视频
大数据毕业设计选题推荐:学生考试表现影响因素Hadoop+Spark实现方案
学生考试表现影响因素Hadoop+Spark实现方案-系统演示图片
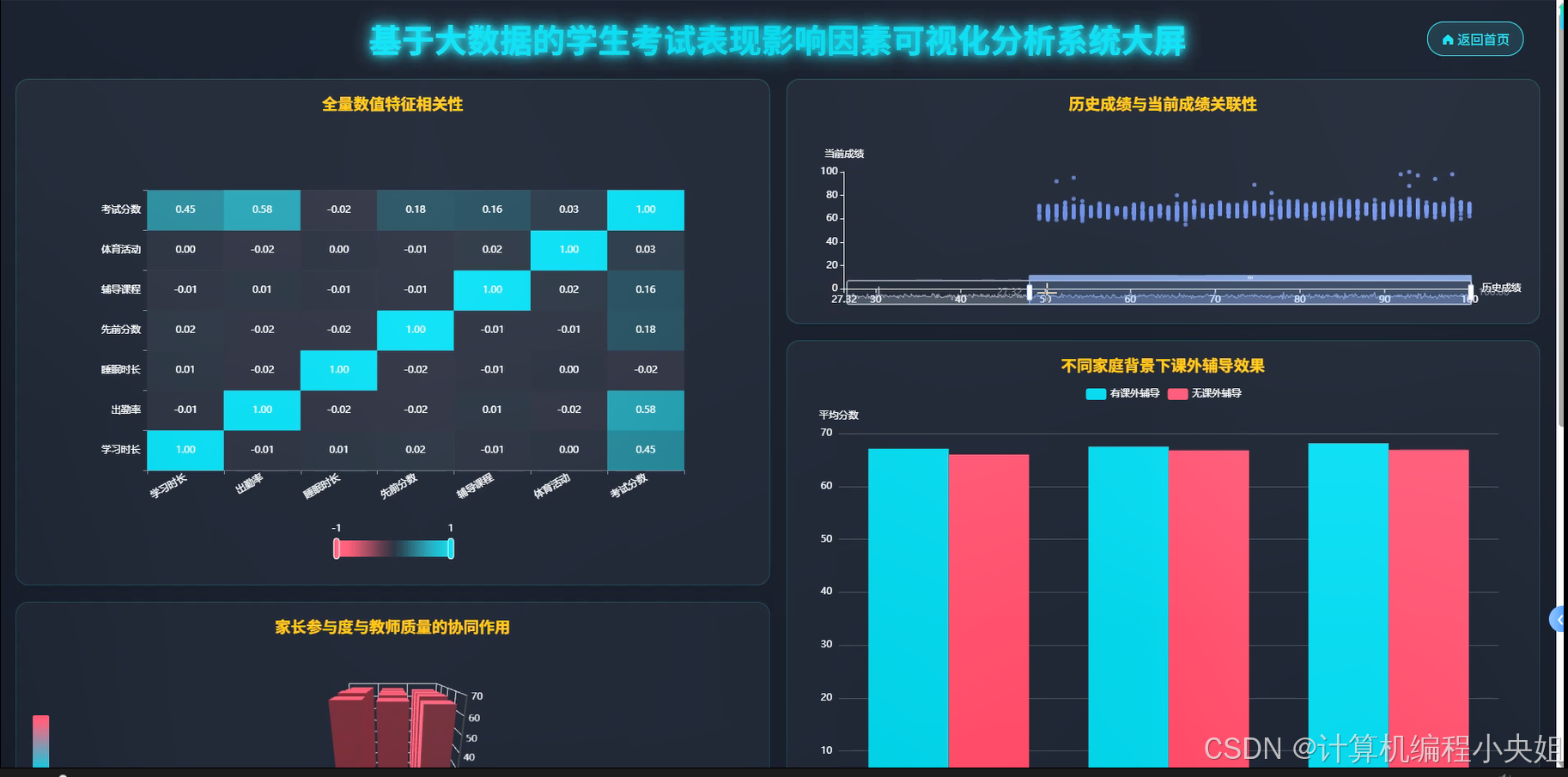
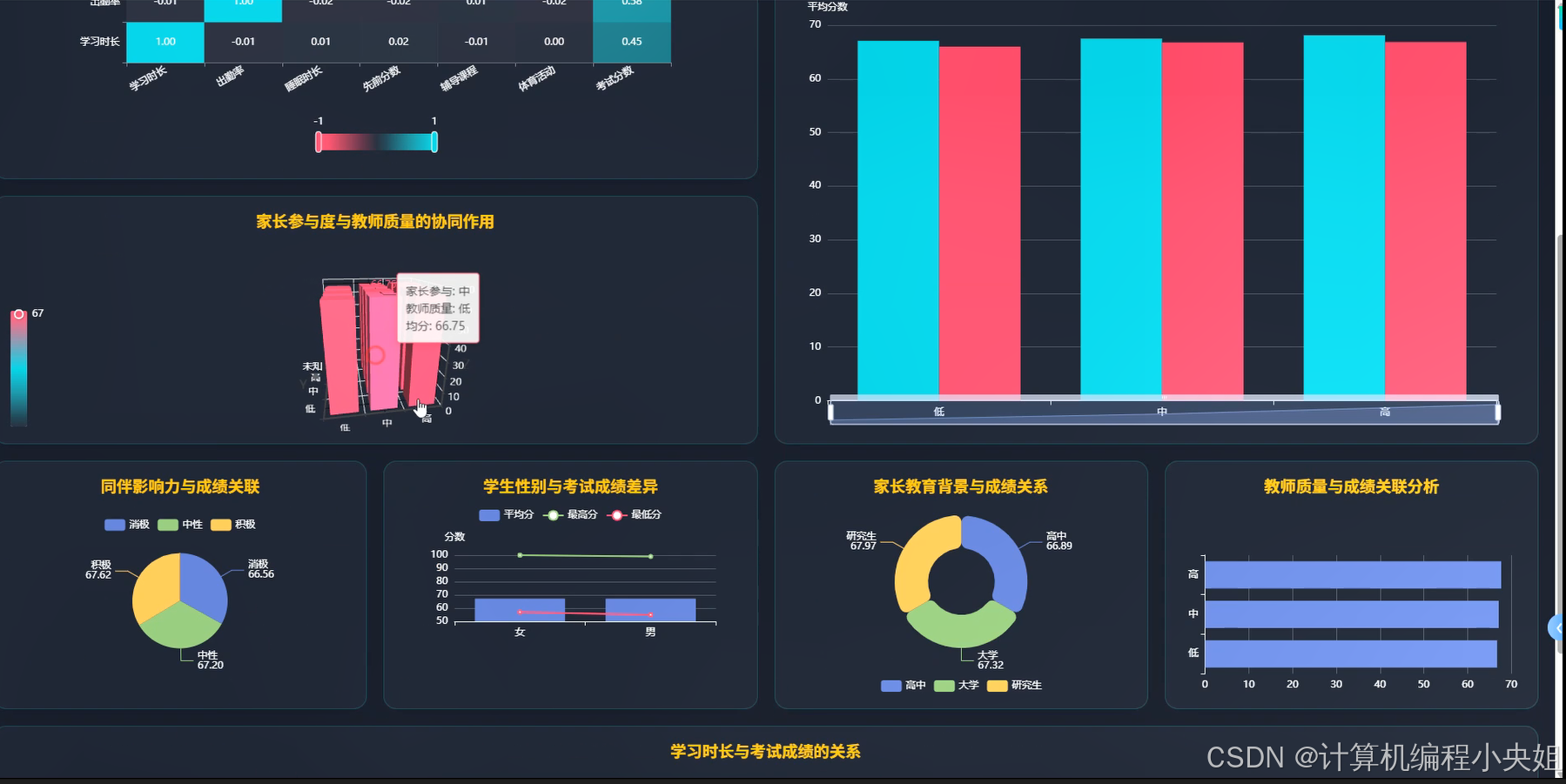
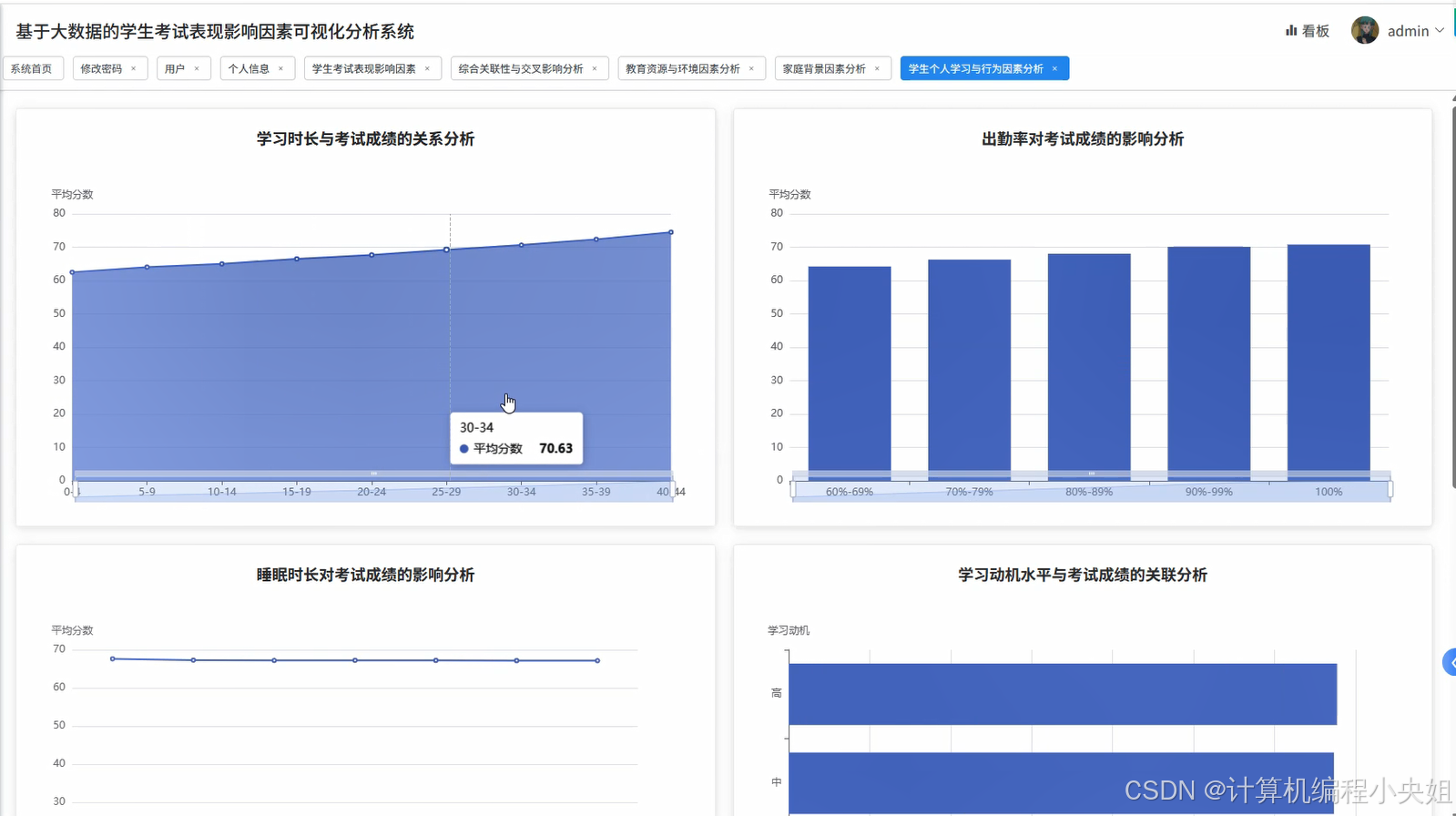
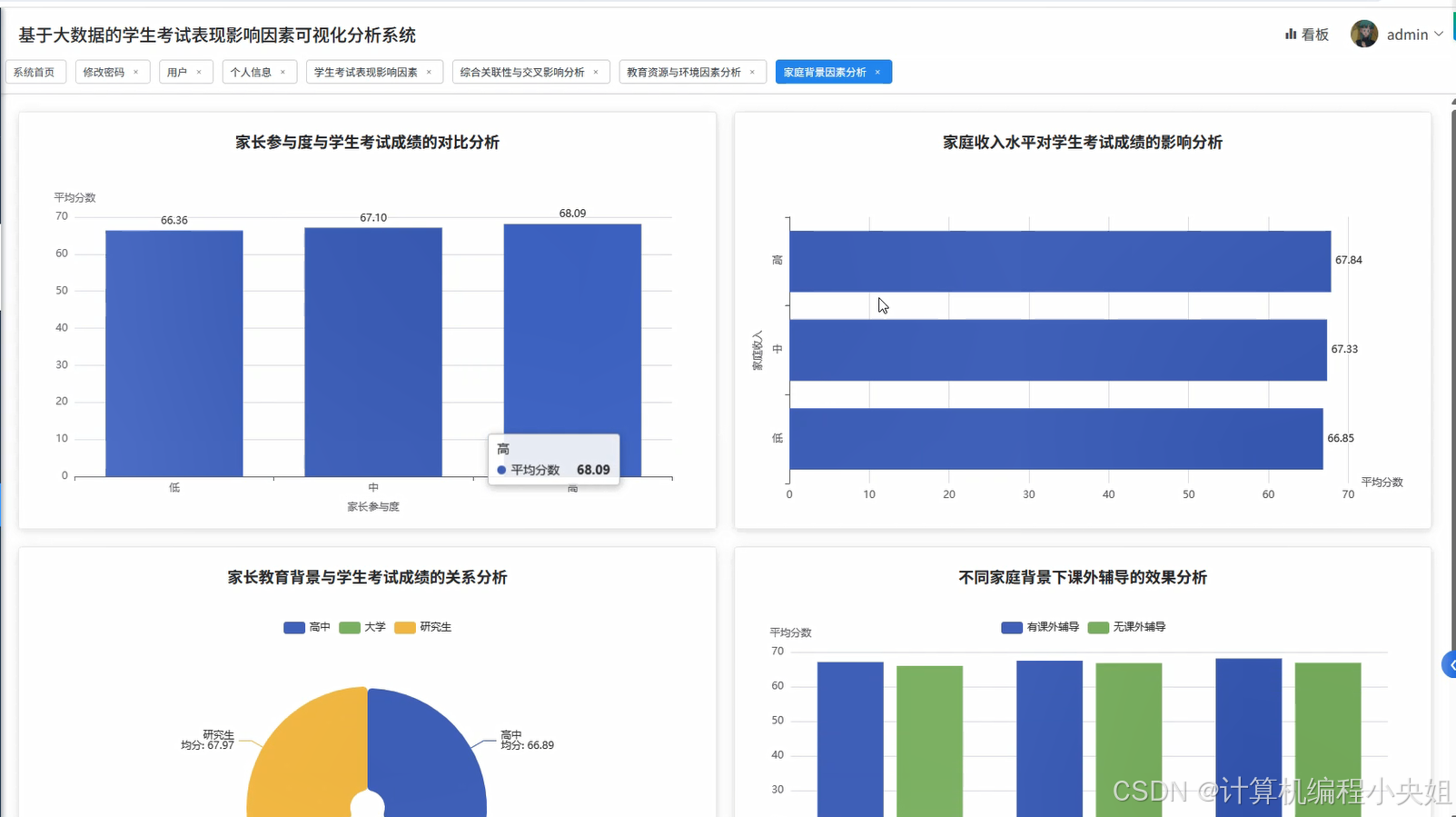
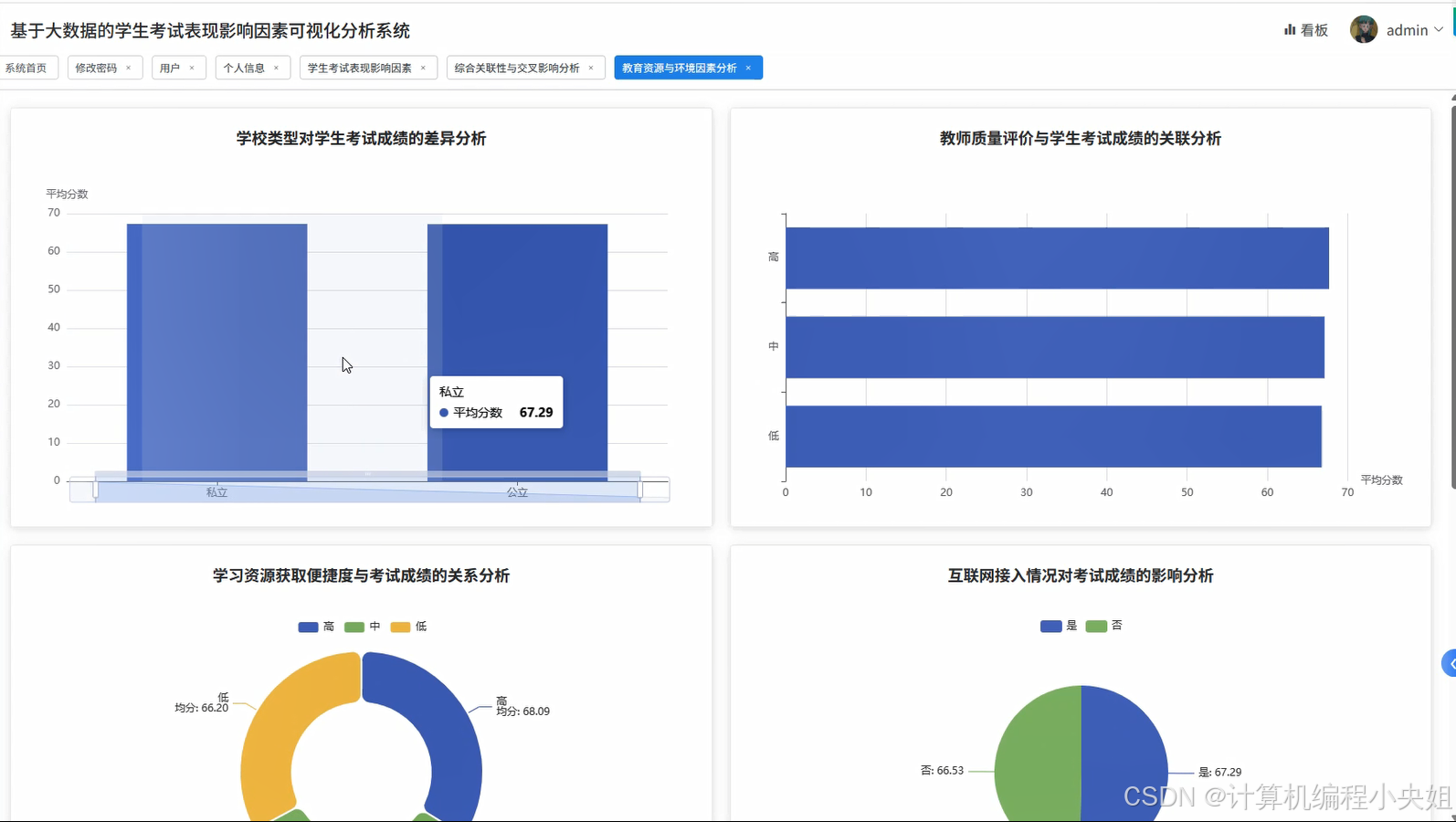
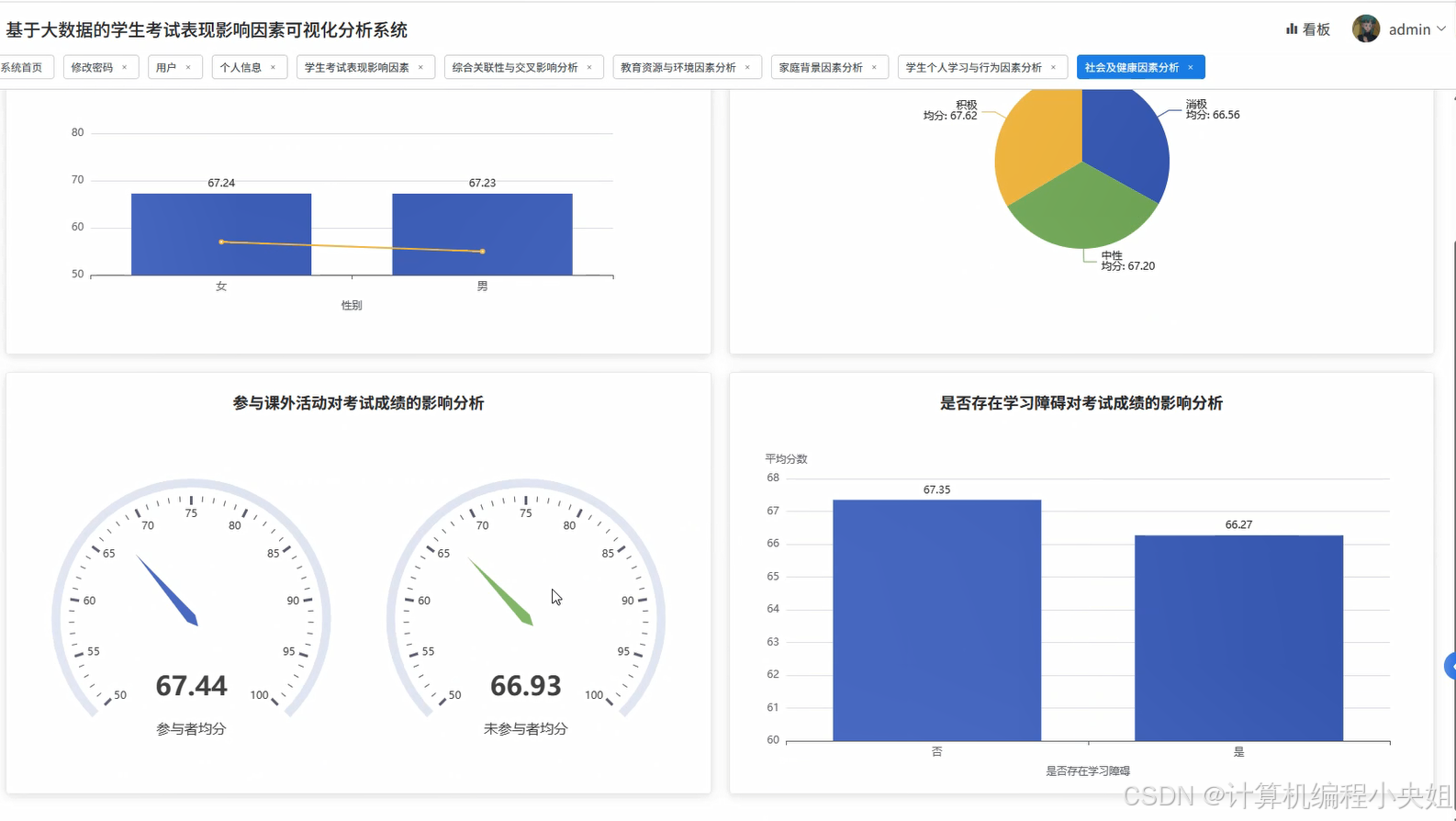
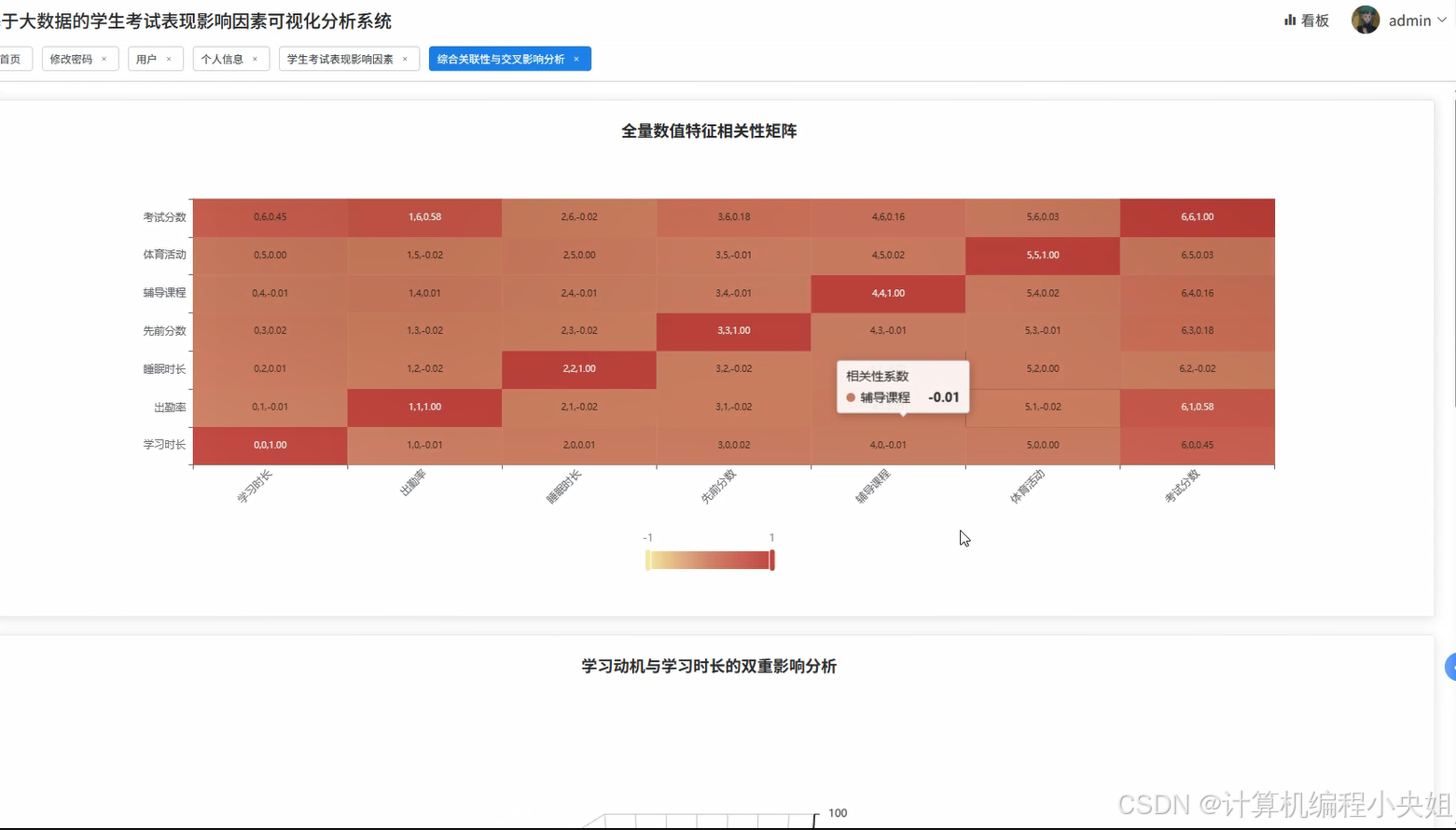
学生考试表现影响因素Hadoop+Spark实现方案-系统部分代码
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, count, corr, when
import pandas as pd
import numpy as np
from django.http import JsonResponse
spark = SparkSession.builder.appName("StudentExamAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def learning_time_performance_analysis(request):
student_df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/student_exam_db").option("dbtable", "student_data").option("user", "root").option("password", "password").load()
student_df.createOrReplaceTempView("students")
time_ranges = spark.sql("SELECT CASE WHEN Hours_Studied < 2 THEN '0-2小时' WHEN Hours_Studied < 4 THEN '2-4小时' WHEN Hours_Studied < 6 THEN '4-6小时' WHEN Hours_Studied < 8 THEN '6-8小时' ELSE '8小时以上' END as time_range, Hours_Studied, Exam_Score FROM students")
time_ranges.createOrReplaceTempView("time_categorized")
avg_scores = spark.sql("SELECT time_range, AVG(Exam_Score) as avg_score, COUNT(*) as student_count, MIN(Exam_Score) as min_score, MAX(Exam_Score) as max_score FROM time_categorized GROUP BY time_range ORDER BY avg_score DESC")
correlation_result = student_df.select(corr("Hours_Studied", "Exam_Score").alias("correlation"))
correlation_value = correlation_result.collect()[0]["correlation"]
time_score_trend = spark.sql("SELECT Hours_Studied, AVG(Exam_Score) as avg_score FROM students WHERE Hours_Studied IS NOT NULL GROUP BY Hours_Studied ORDER BY Hours_Studied")
score_distribution = spark.sql("SELECT time_range, CASE WHEN Exam_Score >= 90 THEN '优秀' WHEN Exam_Score >= 80 THEN '良好' WHEN Exam_Score >= 70 THEN '中等' WHEN Exam_Score >= 60 THEN '及格' ELSE '不及格' END as grade_level, COUNT(*) as count FROM time_categorized GROUP BY time_range, CASE WHEN Exam_Score >= 90 THEN '优秀' WHEN Exam_Score >= 80 THEN '良好' WHEN Exam_Score >= 70 THEN '中等' WHEN Exam_Score >= 60 THEN '及格' ELSE '不及格' END")
efficiency_analysis = spark.sql("SELECT time_range, AVG(Exam_Score/Hours_Studied) as learning_efficiency FROM time_categorized WHERE Hours_Studied > 0 GROUP BY time_range ORDER BY learning_efficiency DESC")
result_data = {
'avg_scores': avg_scores.toPandas().to_dict('records'),
'correlation': round(correlation_value, 4),
'trend_data': time_score_trend.toPandas().to_dict('records'),
'grade_distribution': score_distribution.toPandas().to_dict('records'),
'efficiency_ranking': efficiency_analysis.toPandas().to_dict('records')
}
return JsonResponse(result_data)
def multi_factor_correlation_analysis(request):
student_df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/student_exam_db").option("dbtable", "student_data").option("user", "root").option("password", "password").load()
numeric_columns = ['Hours_Studied', 'Attendance', 'Sleep_Hours', 'Previous_Scores', 'Tutoring_Sessions', 'Physical_Activity', 'Exam_Score']
correlation_matrix = {}
for col1 in numeric_columns:
correlation_matrix[col1] = {}
for col2 in numeric_columns:
corr_value = student_df.select(corr(col1, col2).alias("correlation")).collect()[0]["correlation"]
correlation_matrix[col1][col2] = round(corr_value if corr_value is not None else 0, 4)
strong_correlations = []
for col1 in numeric_columns:
for col2 in numeric_columns:
if col1 != col2 and abs(correlation_matrix[col1][col2]) > 0.5:
strong_correlations.append({
'factor1': col1,
'factor2': col2,
'correlation': correlation_matrix[col1][col2],
'strength': '强相关' if abs(correlation_matrix[col1][col2]) > 0.7 else '中等相关'
})
student_df.createOrReplaceTempView("students")
factor_importance = spark.sql("SELECT 'Hours_Studied' as factor, ABS(CORR(Hours_Studied, Exam_Score)) as importance FROM students UNION ALL SELECT 'Attendance' as factor, ABS(CORR(Attendance, Exam_Score)) as importance FROM students UNION ALL SELECT 'Sleep_Hours' as factor, ABS(CORR(Sleep_Hours, Exam_Score)) as importance FROM students UNION ALL SELECT 'Previous_Scores' as factor, ABS(CORR(Previous_Scores, Exam_Score)) as importance FROM students UNION ALL SELECT 'Tutoring_Sessions' as factor, ABS(CORR(Tutoring_Sessions, Exam_Score)) as importance FROM students UNION ALL SELECT 'Physical_Activity' as factor, ABS(CORR(Physical_Activity, Exam_Score)) as importance FROM students ORDER BY importance DESC")
cluster_analysis = spark.sql("SELECT CASE WHEN Hours_Studied >= 6 AND Attendance >= 80 THEN '高投入组' WHEN Hours_Studied >= 4 AND Attendance >= 60 THEN '中投入组' ELSE '低投入组' END as cluster, AVG(Exam_Score) as avg_score, COUNT(*) as count FROM students GROUP BY CASE WHEN Hours_Studied >= 6 AND Attendance >= 80 THEN '高投入组' WHEN Hours_Studied >= 4 AND Attendance >= 60 THEN '中投入组' ELSE '低投入组' END")
result_data = {
'correlation_matrix': correlation_matrix,
'strong_correlations': strong_correlations,
'factor_importance': factor_importance.toPandas().to_dict('records'),
'cluster_performance': cluster_analysis.toPandas().to_dict('records'),
'analysis_summary': f"共发现{len(strong_correlations)}对强相关因素"
}
return JsonResponse(result_data)
def family_education_impact_analysis(request):
student_df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/student_exam_db").option("dbtable", "student_data").option("user", "root").option("password", "password").load()
student_df.createOrReplaceTempView("students")
parental_involvement_analysis = spark.sql("SELECT Parental_Involvement, AVG(Exam_Score) as avg_score, COUNT(*) as student_count, STDDEV(Exam_Score) as score_stddev FROM students GROUP BY Parental_Involvement ORDER BY avg_score DESC")
family_income_analysis = spark.sql("SELECT Family_Income, AVG(Exam_Score) as avg_score, COUNT(*) as student_count, MIN(Exam_Score) as min_score, MAX(Exam_Score) as max_score FROM students GROUP BY Family_Income ORDER BY avg_score DESC")
education_level_analysis = spark.sql("SELECT Parental_Education_Level, AVG(Exam_Score) as avg_score, COUNT(*) as student_count FROM students GROUP BY Parental_Education_Level ORDER BY avg_score DESC")
cross_factor_analysis = spark.sql("SELECT Parental_Involvement, Family_Income, AVG(Exam_Score) as avg_score, COUNT(*) as count FROM students GROUP BY Parental_Involvement, Family_Income HAVING COUNT(*) >= 5 ORDER BY avg_score DESC")
tutoring_effectiveness = spark.sql("SELECT Family_Income, CASE WHEN Tutoring_Sessions > 0 THEN '有辅导' ELSE '无辅导' END as tutoring_status, AVG(Exam_Score) as avg_score, COUNT(*) as count FROM students GROUP BY Family_Income, CASE WHEN Tutoring_Sessions > 0 THEN '有辅导' ELSE '无辅导' END ORDER BY Family_Income, tutoring_status")
resource_access_impact = spark.sql("SELECT Access_to_Resources, Parental_Education_Level, AVG(Exam_Score) as avg_score FROM students GROUP BY Access_to_Resources, Parental_Education_Level ORDER BY avg_score DESC")
family_support_score = spark.sql("SELECT Student_ID, Parental_Involvement, Family_Income, Parental_Education_Level, CASE WHEN Parental_Involvement = 'High' THEN 3 WHEN Parental_Involvement = 'Medium' THEN 2 ELSE 1 END + CASE WHEN Family_Income = 'High' THEN 3 WHEN Family_Income = 'Medium' THEN 2 ELSE 1 END + CASE WHEN Parental_Education_Level = 'Postgraduate' THEN 4 WHEN Parental_Education_Level = 'Graduate' THEN 3 WHEN Parental_Education_Level = 'High School' THEN 2 ELSE 1 END as family_support_index, Exam_Score FROM students")
family_support_score.createOrReplaceTempView("family_support")
support_performance_correlation = spark.sql("SELECT family_support_index, AVG(Exam_Score) as avg_score, COUNT(*) as count FROM family_support GROUP BY family_support_index ORDER BY family_support_index")
result_data = {
'parental_involvement': parental_involvement_analysis.toPandas().to_dict('records'),
'family_income_impact': family_income_analysis.toPandas().to_dict('records'),
'education_level_impact': education_level_analysis.toPandas().to_dict('records'),
'cross_analysis': cross_factor_analysis.toPandas().to_dict('records'),
'tutoring_effectiveness': tutoring_effectiveness.toPandas().to_dict('records'),
'resource_education_matrix': resource_access_impact.toPandas().to_dict('records'),
'family_support_correlation': support_performance_correlation.toPandas().to_dict('records')
}
return JsonResponse(result_data)学生考试表现影响因素Hadoop+Spark实现方案-结语
💟💟如果大家有任何疑虑,欢迎在下方位置详细交流。