目录
[一、Apache Ozone是什么?](#一、Apache Ozone是什么?)
[1. 分层架构设计](#1. 分层架构设计)
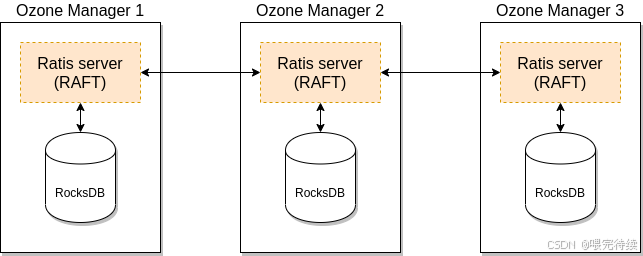
[2. Ozone Manager (OM)](#2. Ozone Manager (OM))
[3. Storage Container Manager (SCM)](#3. Storage Container Manager (SCM))
[4. DataNode](#4. DataNode)
[5. Raft协议应用](#5. Raft协议应用)
[1. 元数据管理瓶颈](#1. 元数据管理瓶颈)
[2. 小文件性能问题](#2. 小文件性能问题)
[3. 数据冗余与一致性保障](#3. 数据冗余与一致性保障)
[1. 强一致性](#1. 强一致性)
[2. 高扩展性](#2. 高扩展性)
[3. 云原生友好](#3. 云原生友好)
[4. 安全可靠](#4. 安全可靠)
[5. 多协议支持](#5. 多协议支持)
[6. 高可用性](#6. 高可用性)
[1. HDFS](#1. HDFS)
[2. Amazon S3](#2. Amazon S3)
[3. Ceph](#3. Ceph)
[1. 部署流程](#1. 部署流程)
[2. 配置优化](#2. 配置优化)
[3. 安全设置](#3. 安全设置)
[4. 使用方法](#4. 使用方法)
[5. 常见应用场景](#5. 常见应用场景)
Apache Ozone是Apache Hadoop生态中的新一代分布式对象存储系统,专为解决HDFS在扩展性和小文件处理方面的局限性而设计。作为面向技术开发人员的深度指南,本文将从基础概念到架构设计,再到实际应用,全面解析Ozone的技术特性与价值。
Apache Ozone是一个基于Hadoop的可扩展、冗余和分布式对象存储系统,设计用于处理海量小文件和对象存储需求,同时提供与HDFS兼容的文件系统接口,使大数据应用无需修改即可无缝迁移。其核心创新在于分层架构设计,将元数据管理与数据存储分离,突破了HDFS的元数据瓶颈,支持从数十亿到千亿级的对象存储能力,为现代大数据和云原生应用提供了更灵活、可扩展的存储解决方案。

一、Apache Ozone是什么?
Apache Ozone是一种分布式对象存储系统,属于Apache Hadoop项目的一部分。它最初设计是为了解决HDFS在处理海量小文件时的性能问题,但随着发展,它已成为一个独立的对象存储解决方案,支持多种协议和接口。
从存储模型来看,Ozone采用分层结构,包括Volume(卷)、Bucket(桶)和Key(键)三个层次。Volume类似于HDFS中的命名空间,由管理员创建和管理;Bucket类似于目录,用户可以在Volume下创建任意数量的Bucket;Key则类似于文件,存储实际的数据。这种分层模型使得Ozone能够高效管理海量对象,同时保持与HDFS的兼容性。
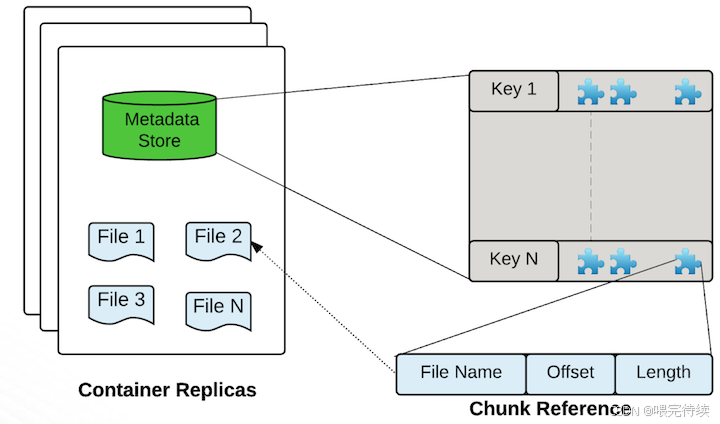
Ozone的核心存储单元是Container(容器),默认大小为5GB,可以包含多个Block(块),而每个Block又由多个Chunk(块碎片)组成。这种设计使得Ozone能够在管理大量小文件时,减少元数据开销,提高系统性能。
二、Ozone的诞生背景
Ozone的诞生源于HDFS在扩展性和小文件处理方面的局限性。HDFS作为Hadoop生态系统的核心组件,虽然在处理大文件时表现出色,但在面对海量小文件时却面临严重挑战。
HDFS的元数据管理采用集中式架构,所有元数据都存储在NameNode的内存中,这导致了两个主要问题:首先,文件数量受到Java堆内存的限制,通常最多只能支持4亿到5亿个文件;其次,NameNode的单点故障风险较高,难以实现真正的高可用。
随着大数据应用的发展,尤其是日志、事件流、元数据等场景的普及,存储系统需要处理越来越多的小文件,而HDFS在这种场景下性能显著下降。此外,Hadoop生态系统的扩展需求也促使社区寻找更灵活、可扩展的存储解决方案。
Ozone正是在这一背景下诞生,它通过分层架构设计,将元数据管理与数据存储分离,解决了HDFS的元数据瓶颈问题,同时提供对象存储接口,满足了云原生应用的需求。
三、Ozone的架构设计
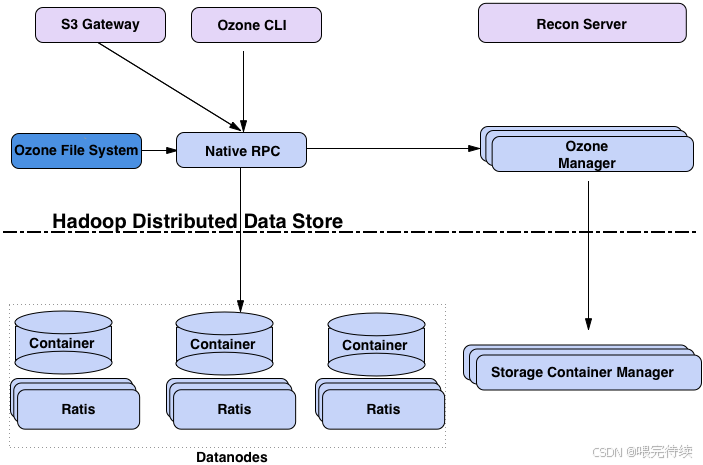
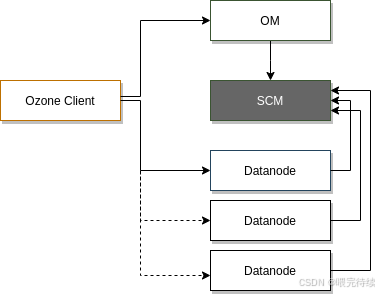
Apache Ozone采用分层架构设计,主要包括协议层、元数据层和数据层,这种设计使得系统能够独立扩展不同组件,满足大规模存储需求。
- 分层架构设计
Ozone的分层架构可以分为以下三个层次:
协议层:提供多种访问协议,包括S3、NFS和POSIX等,使Ozone能够与各种应用程序集成。S3 Gateway支持Amazon S3 API,使Ozone能够与AWS生态兼容;而OzoneFileSystem则提供与HDFS兼容的API,使Hadoop应用无需修改即可使用Ozone。
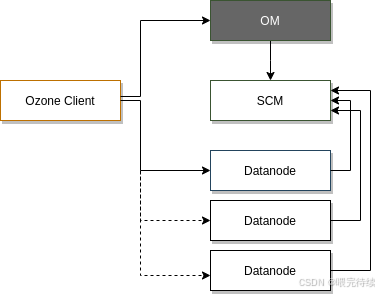
元数据层:包括Ozone Manager(OM)和Storage Container Manager(SCM)两个组件,分别负责管理对象存储元数据和容器生命周期。
数据层:由DataNode组成,负责存储实际数据。DataNode通过Raft协议(由Apache Ratis实现)管理数据副本的一致性,确保数据的高可用性和强一致性。
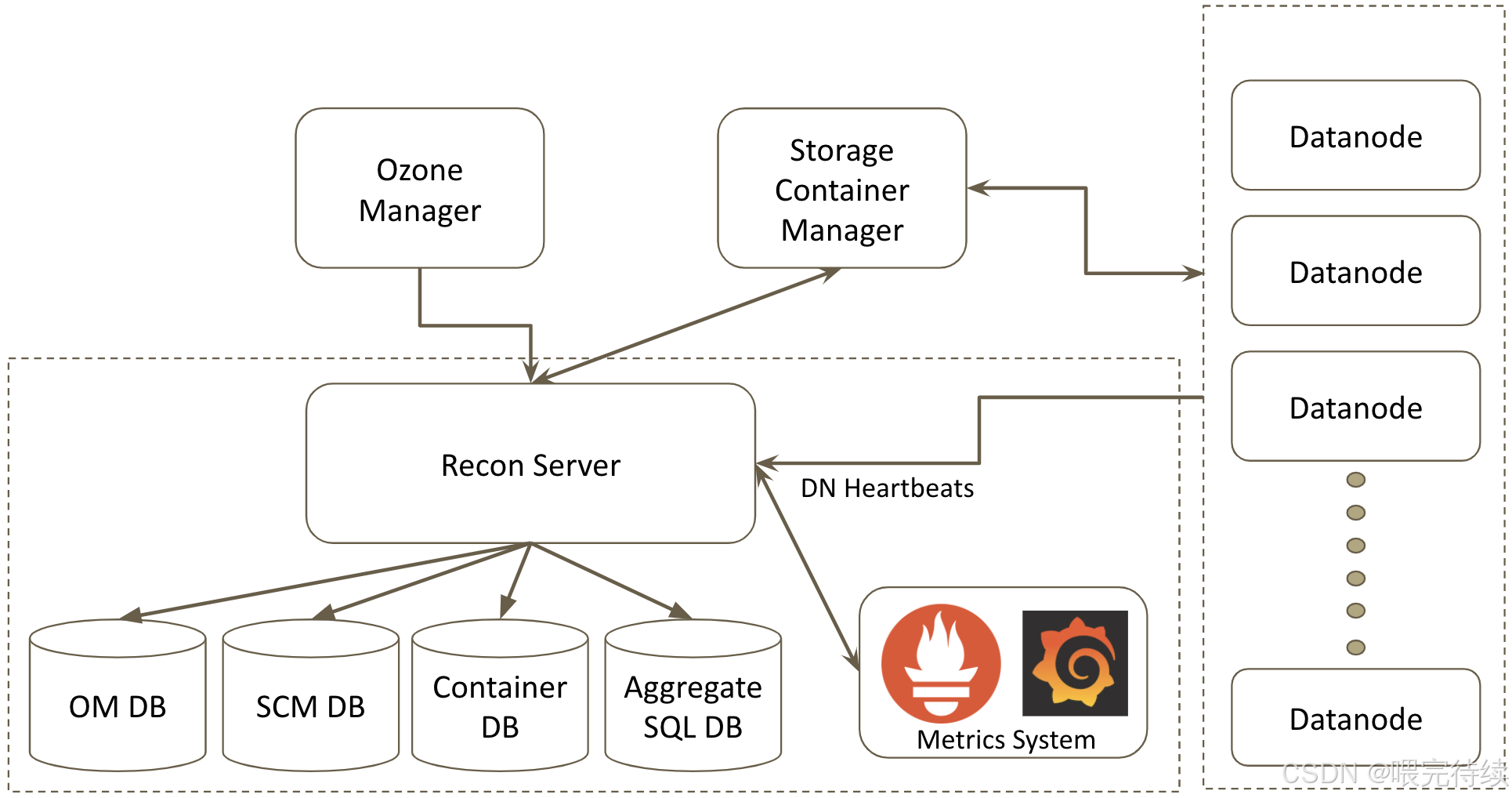
此外,Ozone还包含Recon Server作为监控和管理组件,用于集群健康监控、元数据修复和性能分析。
- Ozone Manager (OM)
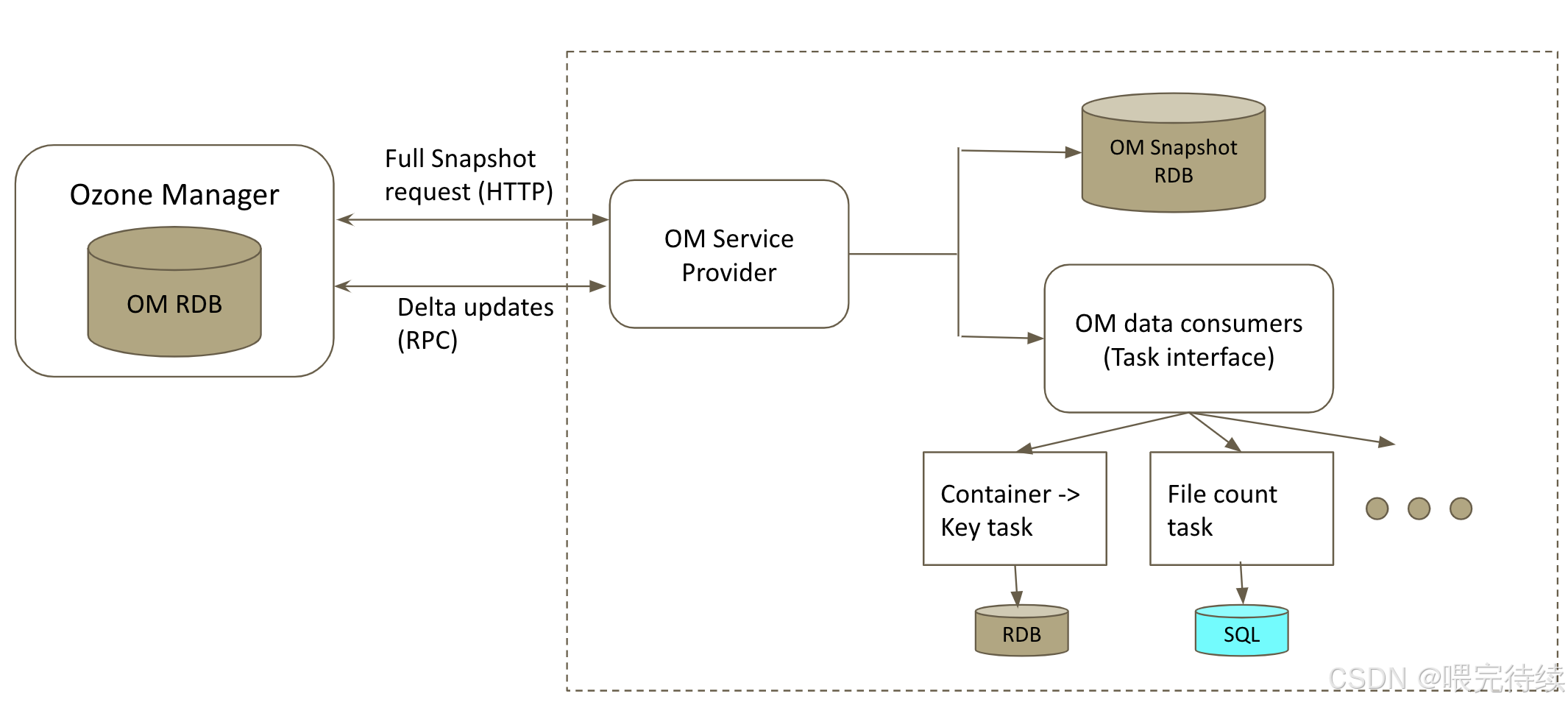
OM是Ozone的元数据管理组件,主要负责管理Volume、Bucket和Key的命名空间元数据。与HDFS的NameNode不同,OM不将所有元数据加载到内存中,而是使用RocksDB作为持久化存储,仅将高频访问的元数据缓存在内存中,大大提高了元数据的管理能力和扩展性。
OM的核心功能包括:
- Volume和Bucket的创建、删除和管理
- Key的元数据管理,如大小、创建时间等
- 与客户端交互,处理对象存储请求
OM的高可用性可以通过多实例+ZooKeeper实现,确保元数据管理的容灾能力。
- Storage Container Manager (SCM)
SCM是Ozone的容器管理组件,主要负责管理Container、Block和副本,以及数据节点的生命周期。SCM作为证书颁发机构(CA),为集群中的每个服务颁发身份证书,支持网络层的双向认证(mTLS)。
SCM的核心功能包括:
- 创建和管理Container
- 将Block分配给适当的数据节点
- 跟踪所有Block的副本状态
- 当数据节点或磁盘故障时,启动副本修复
- 为集群组件颁发证书
SCM的高可用性通常通过部署多个SCM节点实现,建议在生产环境中部署三个SCM节点,以提高系统的容错能力。
- DataNode
DataNode是Ozone的数据存储组件,负责存储实际数据。与HDFS的DataNode类似,Ozone的DataNode也负责处理数据的读写请求,但有所不同的是,Ozone的DataNode以Container为单位上报状态,而不是每个Block,大大减少了心跳和复制管理的开销。
DataNode的核心功能包括:
- 存储和管理Container中的数据
- 处理客户端的读写请求
- 参与Raft协议,确保数据副本的一致性
- 上报容器和节点状态给SCM
- Raft协议应用
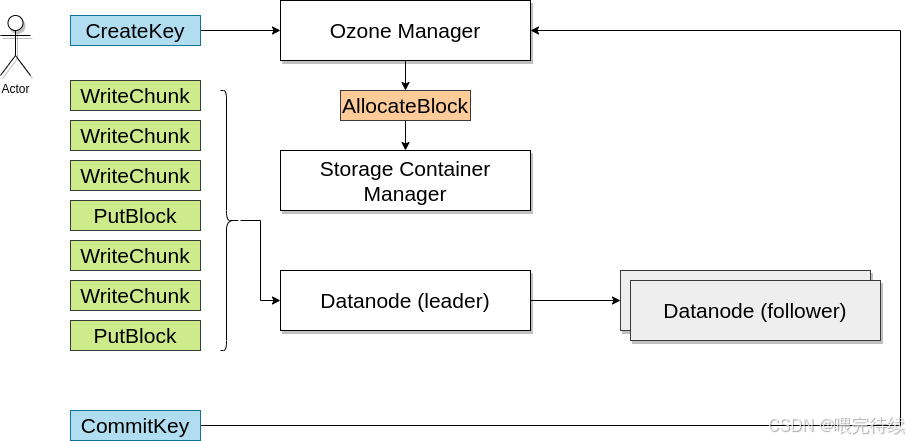
Ozone使用Apache Ratis实现的Raft协议来保证数据的一致性和高可用性。Raft协议是一种分布式一致性算法,用于管理多个节点之间的数据同步。
在Ozone中,Raft协议应用于数据层的Pipeline(即容器副本间的复制)。每个Container的副本分布在不同的DataNode上,形成一个Raft Group。当客户端写入数据时,数据首先写入Leader节点,然后同步到Follower节点,只有当大多数副本成功写入后,客户端才会收到写入成功的响应,从而保证数据的强一致性。
Raft协议的三个角色------Leader、Follower和Candidate------确保了在节点故障时能够快速选举新的Leader,维持系统的可用性。
四、Ozone解决的关键问题
Apache Ozone主要解决了HDFS在以下方面的局限性:
- 元数据管理瓶颈
HDFS的NameNode将所有元数据加载到内存中,导致文件数量受到Java堆内存的限制,通常最多只能支持4亿到5亿个文件。而Ozone通过将元数据管理分层,OM管理Volume、Bucket和Key的命名空间元数据,SCM管理Container、Block和副本的元数据,大大提高了元数据的管理能力和扩展性。
此外,Ozone使用RocksDB作为持久化存储,而不是将所有元数据加载到内存中,进一步提高了系统的扩展性。OM仅将高频访问的元数据缓存在内存中,减少了内存压力。
- 小文件性能问题
HDFS在处理小文件时性能显著下降,主要原因是每个文件对应一个或多个Block,每个Block都需要元数据管理。当文件数量激增时,NameNode的元数据管理能力成为瓶颈。
Ozone通过引入Container作为存储单元,将多个Block聚合到一个Container中,减少了元数据管理的开销。DataNode以Container为单位上报状态,而不是每个Block,大大降低了心跳和复制管理的开销。
- 数据冗余与一致性保障
Ozone通过SCM管理数据副本,确保数据的冗余存储和高可用性。当数据节点或磁盘故障时,SCM能够检测到并启动相应的数据节点复制缺失的块,以确保数据的完整性。
Ozone使用Raft协议保证数据的一致性,确保客户端在写入数据时,数据能够同步到大多数副本中,从而保证数据的强一致性和高可用性。
五、Ozone的关键特性
Apache Ozone具有以下关键特性,使其成为处理海量数据的理想选择:
- 强一致性
Ozone提供强一致性的分布式存储,通过Raft协议确保数据在多个副本之间同步。这种一致性保证简化了应用程序的设计,避免了数据不一致带来的复杂问题。
- 高扩展性
Ozone采用分层架构设计,可以独立扩展元数据层和数据层,支持从数十亿到千亿级的对象存储能力。这种扩展性使得Ozone能够适应不断增长的数据存储需求。
- 云原生友好
Ozone原生支持S3 API,能够与AWS生态兼容,同时也能在容器化环境(如Kubernetes和YARN)中高效运行。这种云原生友好性使得Ozone能够适应现代微服务架构的需求。
- 安全可靠
Ozone与Kerberos基础设施集成,提供细粒度的权限控制。SCM作为证书颁发机构,为集群中的每个服务颁发身份证书,支持网络层的双向认证(mTLS)。Ozone还支持透明数据加密(TDE)和网络加密,确保数据的安全性。
- 多协议支持
Ozone提供多种访问协议,包括S3、HDFS、NFS和POSIX等,使各种应用程序能够无缝集成。这种多协议支持使得Ozone能够在不改变现有应用程序的情况下,提供更灵活、可扩展的存储解决方案。
- 高可用性
Ozone通过多实例+ZooKeeper实现OM的高可用性,同时建议部署多个SCM节点(通常三个)来提高系统的容错能力。这种高可用性设计确保了即使在节点故障的情况下,系统仍然能够正常运行。
六、与同类产品的对比
在大数据存储领域,Apache Ozone与以下产品有相似之处,但也有其独特优势:
- HDFS
HDFS是Hadoop生态中的传统文件系统,与Ozone相比,有以下区别:
| 特性 | HDFS | Ozone |
|---|---|---|
| 元数据管理 | NameNode内存存储 | OM(RocksDB)+ SCM分离管理 |
| 文件数量上限 | 约4-5亿 | 百亿到千亿级 |
| 小文件性能 | 差 | 好 |
| 接口支持 | HDFS API | S3 API + HDFS API |
| 扩展性 | 受NameNode限制 | 分层架构独立扩展 |
HDFS的元数据管理采用集中式架构,所有元数据都存储在NameNode的内存中,导致文件数量受到限制。而Ozone通过分层架构和持久化存储,突破了这一限制,支持更海量的对象存储。
- Amazon S3
Amazon S3是AWS提供的对象存储服务,与Ozone相比,有以下区别:
| 特性 | Amazon S3 | Ozone |
|---|---|---|
| 部署环境 | 云环境 | Hadoop生态 + 云原生 |
| 兼容性 | S3 API | S3 API + HDFS API |
| 数据一致性 | 最终一致性 | 强一致性 |
| 集群管理 | AWS托管 | 需要自行管理 |
| 成本 | 按使用付费 | 自建集群成本 |
Amazon S3是云原生的对象存储服务,提供最终一致性的数据访问,适合云环境下的大规模数据存储。而Ozone则更注重强一致性和与Hadoop生态的兼容性,适合需要与Hadoop应用深度集成的场景。
- Ceph
Ceph是开源的分布式存储系统,与Ozone相比,有以下区别:
| 特性 | Ceph | Ozone |
|---|---|---|
| 存储模型 | 对象、块、文件 | 对象(Volume/Bucket/Key) |
| 元数据管理 | 元数据与数据混合存储 | OM(RocksDB)+ SCM分离管理 |
| 与Hadoop生态集成 | 需要适配 | 原生支持 |
| 数据一致性 | 最终一致性 | 强一致性 |
| 集群管理 | Ceph管理层 | HDDS管理层 |
Ceph是一个通用的分布式存储系统,支持对象、块和文件三种存储模型,但需要额外的适配才能与Hadoop生态集成。而Ozone则专为Hadoop生态设计,原生支持HDFS API,使得Hadoop应用可以无缝迁移。
七、Ozone的部署与使用指南
- 部署流程
部署Apache Ozone需要以下步骤:
首先,准备环境。确保所有节点已安装Java JDK(8或更高版本),并配置好网络环境。
然后,安装Ozone。可以从Apache官网下载最新版本的Ozone二进制包,并解压到指定目录:
wget https://dl.apache.org/ozone/ozone-<version>.tar.gz
tar zxvf ozone-<version>.tar.gz
cd ozone-<version>接下来,生成配置文件。使用ozone genconf命令生成基础配置文件:
bin/ozone genconf etc/hadoop然后,配置ozone-site.xml。根据集群需求,设置以下关键参数:
<property>
<name>ozone.om.address</name>
<value><OM主机IP></value>
<tag>OM, REQUIRED</tag>
</property>
<property>
<name>ozone.metadata.dirs</name>
<value><元数据存储路径></value>
<tag>OZONE, OM, SCM, CONTAINER, STORAGE, REQUIRED</tag>
</property>
<property>
<name>ozone.scm.client.address</name>
<value><SCM主机IP>:9860</value>
<tag>OZONE, SCM, REQUIRED</tag>
</property>
<property>
<name>ozone.scm.datanode.id.dir</name>
<value><数据节点存储路径></value>
</property>最后,启动服务。使用ozone.sh start all命令启动所有服务 :
bin/ozone.sh start all- 配置优化
在生产环境中,Ozone的性能可以通过以下参数优化:
容器大小 :ozone.scm.container.size默认为5GB,可以根据小文件场景调整为更小的值,如2GB或1GB,以减少寻址开销。
块大小 :ozone.scm.block.size默认为256MB,对于小文件密集的场景,可以适当减小块大小,如64MB或32MB。
安全模式节点数 :hdds.scm.safemode.min.datanode设置安全模式所需的最小数据节点数,默认为3,可以根据集群规模调整。
SCM心跳间隔:默认为30秒,可以根据网络状况和负载情况调整,如增加到60秒以减少网络开销。
JVM参数调优:为OM和SCM设置适当的堆大小和垃圾回收算法:
export OZONE_OM_heapsize=8192m
export SCM_heapsize=4096m
export OZONE_JVM_FLAGS="$OZONE_JVM_FLAGS -XX:+UseG1GC"
export OZONE_JVM_FLAGS="$OZONE_JVM_FLAGS -Xlog:gc*:file=/var/log/ozone/gc.log:time,uptime,pid,tid"- 安全设置
Ozone的安全设置主要包括Kerberos认证和证书管理:
首先,配置Kerberos环境。在ozone-site.xml中设置以下参数:
<property>
<name:ozone.security.enabled</name>
<value>TRUE</value>
</property>
<property>
<name:hadoop.security authentication</name>
<value>kerberos</value>
</property>然后,为每个组件创建Kerberos Principal和Keytab文件:
kadmin.local -q "addprinc ozone/om@REALM"
kadmin.local -q "addprinc ozone/s cm@REALM"
kadmin.local -q "addprinc ozone/datanode@REALM"最后,配置krb5.conf文件,确保所有组件能够正确解析Kerberos Principal。
- 使用方法
Ozone可以通过多种方式使用:
命令行接口 :使用ozone命令行工具创建Volume、Bucket和Key:
ozone sh volume create /volume
ozone sh bucket create /volume/bucket
ozone sh key create /volume/bucket/keyS3 API:通过Ozone S3 Gateway访问Ozone,使用AWS SDK或命令行工具:
aws s3 mb s3://bucket.volume --region us-east-1
aws s3 cp /local/file s3://bucket.volume/HDFS API:将Ozone作为HDFS的替代品使用,无需修改现有Hadoop应用:
<property>
<name>fs.o3fs.impl</name>
<value>org.apache.hadoop fs.ozone.OzoneFileSystem</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>o3fs://bucket.volume</value>
</property>Java客户端:使用Hadoop API操作Ozon
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "o3fs://bucket.volume");
FileSystem fs =FileSystem.get(conf);
Path path = new Path("o3fs://bucket.volume/test");
fs开创性地CreateNewFile(path);Python客户端:使用pyarrow操作Ozone:
import pyarrow as pa
# 配置Ozone连接信息
ozone_config = {
"ozoneomaddress": "<OM主机IP>:9861",
"ozonebucketname": "bucket",
"ozonevolumename": "volume"
}
# 创建Ozone文件系统
fs = paarrow fs.OzoneFileSystem(ozone_config)
# 创建文件并写入数据
with fs.open("o3fs://bucket.volume/test", "w") as f:
f.write("Hello Ozone!")- 常见应用场景
Apache Ozone适用于多种大数据存储场景:
Hadoop生态应用:如Hive、Spark、YARN/MR等大数据应用可以在不修改代码的情况下直接使用Ozone作为存储系统。Hive可以将元数据存储在Ozone中,提高元数据管理的效率。
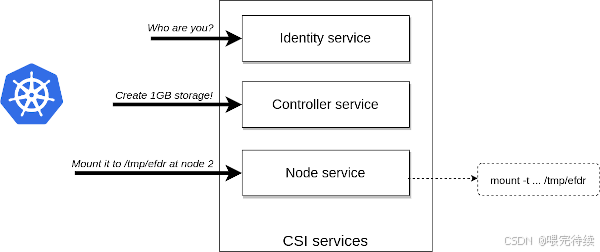
云原生应用:Ozone支持S3 API,可以与云原生应用集成。可以使用Ozone作为Kubernetes的持久化存储,通过Ozone CSI驱动实现动态卷供应。
小文件密集场景:如日志、事件流、元数据等需要存储大量小文件的场景。Ozone通过Container作为存储单元,将多个Block聚合到一个Container中,大大提高了小文件的存储效率。
混合云存储:Ozone可以部署在本地数据中心和云环境中,提供一致的存储接口和管理体验。
高可用存储:Ozone通过多实例+ZooKeeper实现OM的高可用性,同时建议部署多个SCM节点,确保数据的高可用性和一致性。
八、总结与展望
Apache Ozone作为Hadoop生态中的新一代分布式存储系统,通过分层架构设计和Raft协议应用,解决了HDFS在扩展性和小文件处理方面的局限性。它不仅提供了与HDFS兼容的文件系统接口,还支持S3等云原生接口,为大数据应用提供了更灵活、可扩展的存储解决方案。
Ozone的核心价值在于其分层架构和强一致性设计,使其能够支持从数十亿到千亿级的对象存储能力,同时保证数据的高可用性和一致性。这种设计使得Ozone成为处理海量数据的理想选择,尤其是在小文件密集的场景下。
未来,随着大数据应用的不断发展,Ozone可能会在以下方面进一步改进:
性能优化:通过Multi-Raft等技术提高数据节点的吞吐量,优化写入性能。
功能扩展:支持更多类型的存储协议和接口,如NFS和POSIX,提高与各种应用程序的兼容性。
云原生集成:进一步优化与Kubernetes等云原生平台的集成,提供更便捷的部署和管理体验。
企业级功能:增加更多企业级功能,如数据压缩、加密、备份和灾难恢复,提高系统的安全性和可靠性。
对于技术开发人员来说,Apache Ozone提供了一个强大而灵活的存储解决方案,值得深入探索和应用。无论是替换HDFS,还是作为云原生应用的存储后端,Ozone都能为大数据应用提供更高效、可扩展的存储支持。
参考资料:
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊"技术内外的那些事",让你的代码之外,更有"技术眼光"。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!
关于博主: