提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
-
目录
[1. String(字符串)类型的内部实现](#1. String(字符串)类型的内部实现)
[2. Hash(哈希)](#2. Hash(哈希))
[3. List(列表)](#3. List(列表))
[4. Set(集合)](#4. Set(集合))
[5. Sorted Set(有序集合,ZSet)](#5. Sorted Set(有序集合,ZSet))
前言
作为一名Java开发人员,我们一定了解数据库MySQL,MySQL 是基于磁盘的关系型数据库,适合存储结构化数据,支持复杂查询和事务,侧重数据持久化与一致性,但速度较慢;所以我们引进了一款非关系型数据库------Redis, Redis 是基于内存的非关系型键值数据库,支持多种数据结构,读写极快,适合缓存、高频操作场景,内存存储为主,持久化是辅助。两者之间经常结合使用(如 Redis 缓存减轻 MySQL 压力)。所以今天我们就来了解一下Redis这个基于内存的数据库常用的五种数据类型,Redis 提供了丰富的数据类型,其中五种最常用的基础数据类型分别是:String(字符串)、Hash(哈希)、List(列表)、Set(集合)、Sorted Set(有序集合,简称 ZSet)。它们各自适用于不同的业务场景以及其底层逻辑。
五种常见的数据类型的数据结构如下如所示:
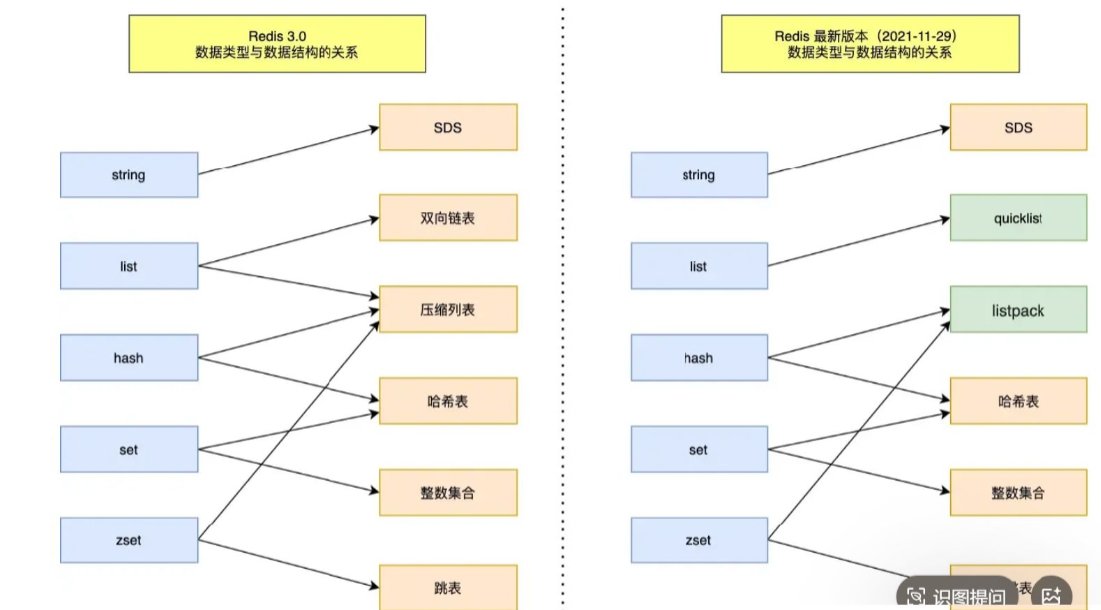
一、Redis数据存储格式
redis 数据存储格式 redis 自身是一个 Map,其中所有的数据都是采用 key : value 的形式存储 我们所说的数据类型其实指的是存储的数据的类型,也就是 value 部分的类型,key 部分永远都是字符串 key的语法。
在一个项目中,key最好使用统一的命名模式 key区分大小写 key不要太长,尽量不要超过1024字节。不仅消耗内存,也会降低查找的效率 key不要太短,太短可读性会降低
-
string String
-
hash HashMap
-
list LinkedList
-
set HashSet
-
sorted_set TreeSet
二、各数据类型的内部实现
1. String(字符串)类型的内部实现
String类型的底层的数据结构实现主要是SDS(简单动态字符串)。SDS和我们认识的C字符串不太一样,之所以没有使用C语言的字符串表示,因为SDS相比于C的原生字符串:
:SDS不仅可以保存文本数据,还可以保存二进制数据。因为SDS使用len属性的值而不是空字符串来判断字符串是否结束,并且SDS的所有API都会一处理二进制的方式来处理SDS存放在buf\[\]数组里的数据,所以SDS不光能存放文本数据,而且能保存照片、音频、压缩文件这样的二进制数据;
: SDS获取字符串的时间复杂度是O(1)。因为C语言的字符串并不记录 自身长度,所以获取长度的复杂度为O(n);而SDS结构里用len 属性记录了字符串长度,所以复杂度为O(1);
: Redis 的SDS API是最安全的,拼接字符串不会造成缓冲区溢出,因为SDS在拼接字符串之前会检查SDS空间是否满足要求,如果空间不够就会自动扩容,所以不会导致缓冲区溢出的问题。
常用命令:
SET key value:设置键值对GET key:获取值INCR key:对数值型 value 自增 1(若 value 非数字则报错)DECR key:对数值型 value 自减 1APPEND key str:在 value 后追加字符串
应用场景:
- 缓存:存储热点数据(如用户信息、商品详情)。
- 计数器:如文章阅读量、视频播放量(用
INCR原子操作)。 - 分布式锁:用
SET key value NX PX 过期时间实现。 - 存储简单信息:如验证码、token 等。
2. Hash(哈希)
Hash类型的底层数据结构是由压缩列表或哈希表实现的:
·如果哈希类型元素个数小于512个(默认值,可由hash-max-ziplist-entries配置),所有值小于64字节(默认值,可由hash-max-ziplist-value配置)的话,Redis会使用压缩列表作为 Hash类型
的底层数据结构;
·如果哈希类型元素不满足上面条件,Redis会使用哈希表作为Hash类型的底层数据结构。
在Redis7.0中,压缩列表数据结构已经废弃了,交由listpack数据结构来实现了。
特点 :
类似 Java 中的 HashMap 或 Python 中的字典,是一个键值对集合(key -> field -> value)。适合存储结构化数据(如对象),每个 Hash 最多可存储 2^32-1 个键值对。
常用命令:
HSET key field value:设置哈希表中指定字段的值HGET key field:获取哈希表中指定字段的值HGETALL key:获取哈希表中所有字段和值HDEL key field:删除哈希表中指定字段HLEN key:获取哈希表中字段的数量
应用场景:
- 存储对象:如用户信息(
user:1001作为 key,name、age、phone作为 field),相比 String 更节省键空间,且可单独修改某个字段(无需整体更新)。 - 购物车:如
cart:user:1001作为 key,商品 ID 作为 field,数量作为 value。
3. List(列表)
List类型的底层数据结构是由双向链表或压缩列表实现的:
· 如果列表的元素个数小于512个(默认值,可由list-max-ziplist-entries配置),列表每个元素的值都小于64字节(默认值,可由list-max-ziplist-value配置),Redis会使用压缩列表作为List类型的底层数据结构;
·如果列表的元素不满足上面的条件,Redis会使用双向链表作为List类型的底层数据结构;
但是在Redis3.2版本之后,List数据类型底层数据结构就只由quicklist实现了,替代了双向链表和压
缩列表。
特点 :
有序的字符串列表(允许重复元素),底层是双向链表(或压缩列表,当数据量小时),支持从两端高效操作元素。元素插入后按顺序排列,可模拟栈、队列、阻塞队列等结构。
常用命令:
LPUSH key value1 [value2...]:从列表左侧(头部)插入元素RPUSH key value1 [value2...]:从列表右侧(尾部)插入元素LPOP key:移除并返回列表左侧第一个元素RPOP key:移除并返回列表右侧第一个元素LLEN key:获取列表长度LRANGE key start end:获取列表中指定范围的元素(0表示第一个,-1表示最后一个)
应用场景:
- 消息队列:用
LPUSH生产消息,RPOP消费消息(结合BRPOP实现阻塞等待)。 - 最新列表:如 "最新文章""最近评论"(用
LPUSH新增,LRANGE 0 9获取前 10 条)。 - 栈 / 队列:
LPUSH + LPOP模拟栈(先进后出),LPUSH + RPOP模拟队列(先进先出)。
4. Set(集合)
Hash类型的底层数据结构是由压缩列表或哈希表实现的:
·如果哈希类型元素个数小于512个(默认值,可由hash-max-ziplist-entries配置),所有值小于64字节(默认值,可由hash-max-ziplist-value配置)的话,Redis会使用压缩列表作为 Hash类型
的底层数据结构;
·如果哈希类型元素不满足上面条件,Redis会使用哈希表作为Hash类型的底层数据结构。
在Redis7.0中,压缩列表数据结构已经废弃了,交由listpack数据结构来实现了。
特点 :
无序的字符串集合(不允许重复元素),底层是哈希表(或整数集合,当元素为整数且数量少时),支持高效的增删查和集合运算(交集、并集、差集)。
常用命令:
SADD key member1 [member2...]:向集合添加元素(重复元素会被忽略)SMEMBERS key:返回集合中所有元素SISMEMBER key member:判断元素是否在集合中SREM key member1 [member2...]:删除集合中的元素SINTER key1 key2:返回两个集合的交集(共同元素)SUNION key1 key2:返回两个集合的并集(所有元素)SDIFF key1 key2:返回两个集合的差集(key1 有而 key2 没有的元素)
应用场景:
- 去重:如 "用户浏览记录"(避免重复存储同一商品)。
- 关系存储:如 "好友列表"(
user:1001:friends存储用户 1001 的好友 ID)。 - 共同好友 / 兴趣标签:用
SINTER计算两个用户的共同好友,用SUNION合并多个标签集合。
5. Sorted Set(有序集合,ZSet)
Zset类型的底层数据结构是由压缩列表或跳表实现的:
·如果有序集合的元素个数小于128个,并且每个元素的值小于64字节时,Redis会使用压缩列表作为Zset类型的底层数据结构;
如果有序集合的元素不满足上面的条件,Redis会使用跳表作为Zset类型的底层数据结构;
在Redis7.0中,压缩列表数据结构已经废弃了,交由listpack数据结构来实现了。
特点 :
在 Set 基础上增加了 "分数(score)" 属性,元素无序但可按 score 排序(不允许重复元素,但 score 可重复)。底层是跳跃表(或压缩列表),支持按 score 范围查询、排名等操作。
常用命令:
ZADD key score1 member1 [score2 member2...]:向有序集合添加元素(指定分数)ZRANGE key start end [WITHSCORES]:按 score 升序返回指定范围的元素(带WITHSCORES显示分数)ZREVRANGE key start end:按 score 降序返回元素ZSCORE key member:获取元素的分数ZRank key member:返回元素按 score 升序的排名(从 0 开始)ZREVRANK key member:返回元素按 score 降序的排名
应用场景:
- 排行榜:如 "游戏积分排行""视频热度排行"(用
ZADD更新分数,ZREVRANGE 0 9获取前 10 名)。 - 带权重的消息队列:按 score(如时间戳)排序,优先消费高分消息。
- 范围查询:如 "查询分数在 80-100 之间的用户"(
ZRANGEBYSCORE key 80 100)。
总结
五种类型的核心区别在于 "结构特性" 和 "操作场景":
- 简单值用 String;
- 结构化对象用 Hash;
- 有序列表 / 队列用 List;
- 无序去重 / 集合运算用 Set;
- 需排序 / 排名场景用 ZSet。
根据业务需求选择合适的类型,可大幅提升 Redis 的性能和易用性。今天依旧是深蹲不写BUG,大家一起努力!!