2106.11959 Revisiting Deep Learning Models for Tabular Data(论文链接)
https://github.com/yandex-research/tabular-dl-revisiting-models(代码链接)
这篇论文主要讲的是:
-
现在很多研究人员提出了各种新的深度学习方法来处理表格数据(像 Excel 里的那种数据)。
-
这些方法都说自己效果不错,但问题是:大家用的实验数据集和测试方法都不一样,所以根本没法直接比较,谁更好也不清楚。
-
此外,目前还缺少一些"简单又好用"的基准模型(baseline),让别人能方便地拿来对比。
于是,作者做了两件事:
-
总结梳理了现有的主要深度学习方法,看看它们的思路和优缺点。
-
提出了两个简单但效果很强的模型:
-
第一个是类似 ResNet 的结构(在图像识别里很常见),结果发现它在表格数据上也能作为一个强有力的基线模型。
-
第二个是稍微改造过的 Transformer,用来处理表格数据,效果比很多其他模型都好。
-
他们用统一的实验流程,把这些模型在很多任务上做了公平比较。最后还把深度学习模型和"梯度提升树"(一种传统但很强的机器学习方法,比如 XGBoost)做对比,结论是:
👉 目前还没有一个方法能在所有情况下一直是最优的。
Introduction
研究背景
-
深度学习在图像、语音、文本等领域非常成功,所以大家很想把它用到表格数据上(比如工业生产里的传感器数据、金融数据、医疗数据、比赛里的数据表)。
-
在表格数据任务里,深度学习的主要对手是 梯度提升决策树(GBDT,比如 XGBoost、LightGBM、CatBoost),它们已经很强大了。
-
如果深度学习能在表格数据上表现好,还有一个额外的好处:它可以和图像、语音等数据结合,做成"多模态"的端到端模型,用梯度优化一起训练,非常方便。
目前的问题
-
已经有很多研究提出了新的深度学习模型来处理表格数据,但大家用的数据集和实验流程都不一样。
-
这就导致:
-
论文之间没法公平比较,不知道到底哪个模型更好。
-
也不清楚深度学习是否真的比 GBDT 更强。
-
-
此外,虽然模型很多,但还缺少一些 既简单又稳定的"基准模型",能让大家更容易对比和复现。现在大家常用的 MLP(多层感知机)太弱,根本挑战不到其他模型。
作者的思路
-
他们怀疑:其实一些在图像和 NLP 里已经验证过的经典深度学习模块,在表格任务上可能被忽视了。
-
所以,他们尝试把这些"成熟的架构"改造一下用在表格数据上,结果提出了两个简单的模型:
-
ResNet-like(残差网络的变体)
-
FT-Transformer(他们改造过的 Transformer)
-
论文主要贡献
-
系统地评估了各种表格数据的深度学习模型。
-
发现 ResNet-like 是一个很强的基线,推荐以后大家用它做比较。
-
提出了 FT-Transformer,一个简单但强大的新方案。
-
最后确认,目前没有任何模型能在所有任务上完全超越 GBDT。
Related work
传统方法:决策树集成(GBDT)
目前在表格数据任务里,GBDT(梯度提升树) 是最常用、最强的"浅层"方法。有三个非常流行的库:XGBoost、LightGBM、CatBoost,它们在细节上有区别,但在大多数任务上性能差不多。所以,GBDT 一直是机器学习比赛和工业界的首选。
深度学习方法:主要有三大类
可微分的树
传统的树模型不能通过梯度下降训练(因为分裂是"硬"的,没法求导)。有些研究者就把树的分裂函数"平滑化",让树也能用梯度优化,方便和深度学习结合。这些方法在部分任务上能超过 GBDT,但作者的实验发现,它们并不比一个调好参数的 ResNet 稳定。
基于注意力的模型
因为注意力机制(Transformer)在图像、文本等领域大获成功,有人也尝试把它用在表格数据上。结果表明:虽然一些注意力模型表现还行,但经过精调的 ResNet 依然更强。不过,作者提出了一种更合适的 Transformer 改造版本(FT-Transformer),在大多数任务上超过了 ResNet。
显示建模特征交叉
在推荐系统和点击率预测中,很多人批评 MLP(多层感知机),因为它不擅长表达特征之间的"乘积关系"(比如"年龄 × 收入"这种交互)。有些工作尝试在 MLP 里加上"特征乘积"的模块。但作者的实验发现,这些方法并不比调好的基线模型更好。
其他杂项模型
还有一些方法不能明确归类到上面三类,比如一些比较特殊的架构设计,但效果也没有形成统一结论。
Models for tabular data
研究目标
找出简单但好用的深度学习基线模型,而不是复杂又难调的架构。尽量使用大家熟悉的深度学习"积木"(比如 MLP、ResNet、Transformer)来搭建模型。这样模型更容易理解、实现,也更容易调出好结果。
统一任务设定
数据集包含数值型特征(numerical)和类别型特征(categorical)。数据被分成 训练集(train)、验证集(val)、测试集(test)。任务分为三类:二分类、多分类和回归。
三种主要模型
MLP(多层感知机)
-
最基础的深度学习模型。
-
结构:
线性层 → ReLU → Dropout → 线性层 → ... → 输出。 -
简单易用,但在表格数据任务里,往往不是最优解。
ResNet(残差网络改造版)
-
原本 ResNet 在图像识别很成功(解决了"深层网络难训练"的问题)。
-
作者尝试在表格数据上用一个简化版 ResNet。
-
核心思想:在每一层里,加一个"捷径连接"(skip connection),让输入可以直接绕过部分计算流向输出。
-
这样有助于训练,能学到更深层次的特征。
-
作者认为它会比 MLP 更适合一些需要"深层表达"的任务,其实就是在原来MLP的基础上加上残差链接。
FT-Transformer(特征标记器 + Transformer)
-
这是作者的创新点。
-
步骤:
-
把每个特征(数值/类别)先转换成embedding(向量表示)。
-
让 Transformer 模型处理这些特征向量(像处理句子里的词一样)。
-
最后用
[CLS]token 的输出作为整体表示,再做预测。
-
-
好处:Transformer 的自注意力机制可以自动学到特征之间的关系,特别适合表格这种"混合信息"的数据。
-
作者发现,这个方法在多数任务上能超过 ResNet。
Experiments
作者想回答两个核心问题:
-
不同的深度学习(DL)架构在表格数据上的真实表现差别有多大?
-
和传统的梯度提升树(GBDT,例如 XGBoost、CatBoost)相比,DL 模型到底有没有优势?
数据集和实验
我们使用了11 个多样化的公开数据集(详细描述见附录)。对于每个数据集,都只有一个固定的训练集--验证集--测试集划分,因此所有算法都使用相同的划分。
这些数据集包括:
-
California Housing (CA):房价预测(房地产数据,Kelley Pace 和 Barry, 1997)
-
Adult (AD):收入预测(Kohavi, 1996)
-
Helena (HE):匿名数据集(Guyon 等, 2019)
-
Jannis (JA):匿名数据集(Guyon 等, 2019)
-
Higgs (HI):模拟的物理粒子数据(Baldi 等, 2014;使用 OpenML 上的 98K 样本版本,Vanschoren 等, 2014)
-
ALOI (AL):图像数据(Geusebroek 等, 2005)
-
Epsilon (EP):模拟物理实验数据
-
Year (YE):音频特征数据(Bertin-Mahieux 等, 2011)
-
Covertype (CO):森林特征数据(Blackard 和 Dean, 2000)
-
Yahoo (YA):搜索查询数据(Chapelle 和 Chang, 2011)
-
Microsoft (MI):搜索查询数据(Qin 和 Liu, 2013)
在学习排序(learning-to-rank)任务上,我们采用逐点(pointwise)方法,并把 Microsoft 和 Yahoo 的排序问题视为回归问题来处理。
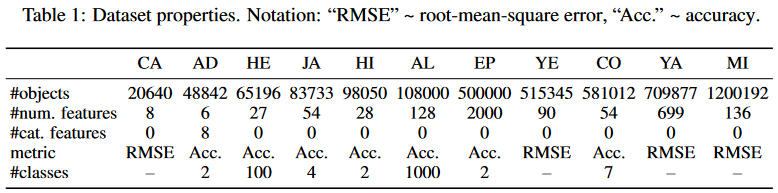

实验结果(简单总结)
-
MLP 依然能打:普通的多层感知机(MLP)经过认真调参,表现不差,是很好的基线。
-
ResNet-like 很强:在 MLP 上加残差连接,效果显著提升,变成一个强力的 baseline。
-
FT-Transformer 最稳:改造过的 Transformer(FT-T)在大多数任务上表现最好,而且在各种数据集上都很稳定。
-
NODE(树状神经网络)也不错,但结构复杂,而且在很多数据集上还是比不过 ResNet。
-
集成(Ensemble)有效果:把多个模型预测结果平均,性能更强;ResNet 和 FT-Transformer 的提升尤其明显。
Analysis
FT-Transformer 什么时候比 ResNet 更好?
作者做了一个合成实验:
-
构造一些虚拟任务,把目标值设计成 一部分像 GBDT 容易拟合的函数(fGBDT) ,另一部分像 深度学习模型容易拟合的函数(fDL)。
-
用一个参数 α 来控制这两部分的比例。
结果:
-
在更偏向 ResNet 友好的任务上(fDL 占主导),ResNet 和 FT-Transformer 表现差不多,都比 CatBoost 强。
-
但当任务更接近 GBDT 风格时,ResNet 的性能掉下去了,而 FT-Transformer 依然稳健。
结论:FT-Transformer 更"万能",既能处理 DL 友好的任务,也能处理 GBDT 擅长的任务,而 ResNet 更挑剔。
Ablation Study(消融实验)
作者测试了 FT-Transformer 的一些设计细节到底有没有用:
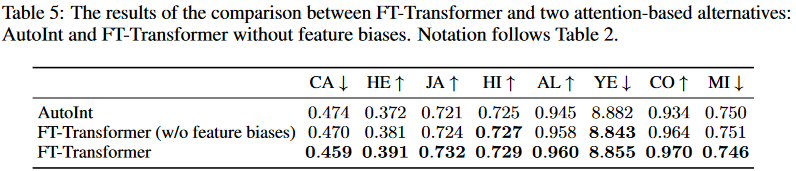
和 AutoInt 的比较
-
AutoInt 也是基于注意力的模型,但细节设计和 Transformer 不一样。
-
实验表明:FT-Transformer 的主干(标准 Transformer 结构)更强,整体优于 AutoInt。
Feature biases(特征偏置项)有没有必要?
-
FT-Transformer 在 embedding 层里为每个特征加了一个偏置(bias)。
-
去掉偏置再跑实验 → 性能下降。
-
说明偏置设计是有帮助的。
从注意力图获取特征重要性
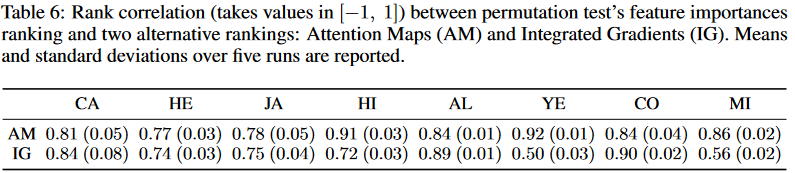
作者提出用 Transformer 的注意力图(attention maps) 来解释模型:
-
计算 CLS token 的注意力分布 → 得到每个特征的重要性分数。
-
优点:很高效,只要一次前向传播就能得到。
对比方法:
-
Integrated Gradients (IG):通用但很慢。
-
Permutation Test (PT):可靠但要做很多次前向传播(特征数 + 1)。
实验结果:
-
注意力图方法(AM)的特征重要性和 PT 的排名高度相关,效果和 IG 差不多。
-
但效率远高于 IG 和 PT。
结论 :用注意力图来解释 FT-Transformer 的特征重要性,是一种 便宜又有效的可解释性方法。
加载FT-Transformer处理表格数据
python
import torch
import torch.nn as nn
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
from torch.utils.data import Dataset, DataLoader
from rtdl_revisiting_models import FTTransformer # 注意要安装 rtdl-revisiting
# ========= 1. 加载数据 =========
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
columns = [
"age", "workclass", "fnlwgt", "education", "education-num",
"marital-status", "occupation", "relationship", "race", "sex",
"capital-gain", "capital-loss", "hours-per-week", "native-country", "income"
]
df = pd.read_csv(url, names=columns, sep=",", skipinitialspace=True)
# ========= 2. 预处理 =========
# 标签:>50K / <=50K
df["income"] = LabelEncoder().fit_transform(df["income"]) # <=50K=0, >50K=1
# 数值特征 / 类别特征
num_features = ["age", "fnlwgt", "education-num", "capital-gain", "capital-loss", "hours-per-week"]
cat_features = [col for col in df.columns if col not in num_features + ["income"]]
# 数值标准化
scaler = StandardScaler()
df[num_features] = scaler.fit_transform(df[num_features])
# 类别编码
for col in cat_features:
df[col] = LabelEncoder().fit_transform(df[col])
X = df[num_features + cat_features].values
y = df["income"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ========= 3. Dataset & Dataloader =========
class TabDataset(Dataset):
def __init__(self, X, y):
self.X = torch.tensor(X, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.long)
def __len__(self): return len(self.X)
def __getitem__(self, idx): return self.X[idx], self.y[idx]
train_loader = DataLoader(TabDataset(X_train, y_train), batch_size=256, shuffle=True)
test_loader = DataLoader(TabDataset(X_test, y_test), batch_size=256)
# ========= 4. 构建 FT-Transformer =========
device = "cuda" if torch.cuda.is_available() else "cpu"
model = FTTransformer(
d_numerical=len(num_features),
categories=[int(df[col].nunique()) for col in cat_features], # 每个类别特征的取值个数
d_token=32,
n_layers=3,
n_heads=4,
d_ffn_factor=2.0,
attention_dropout=0.1,
ffn_dropout=0.1,
residual_dropout=0.1,
d_out=2 # 二分类
).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
# ========= 5. 训练 =========
for epoch in range(5): # 演示只训练 5 轮
model.train()
for xb, yb in train_loader:
xb, yb = xb.to(device), yb.to(device)
out = model(xb)
loss = criterion(out, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1} | Loss {loss.item():.4f}")
# ========= 6. 测试 =========
model.eval()
correct, total = 0, 0
with torch.no_grad():
for xb, yb in test_loader:
xb, yb = xb.to(device), yb.to(device)
out = model(xb)
preds = out.argmax(1)
correct += (preds == yb).sum().item()
total += yb.size(0)
print(f"Test Accuracy: {correct / total:.4f}")