目录
[一、Kafka 是什么](#一、Kafka 是什么)
[1. 基本组件](#1. 基本组件)
[2. 消息模型](#2. 消息模型)
[3. 消费者组(Consumer Group)](#3. 消费者组(Consumer Group))
[1. 高吞吐与可扩展性](#1. 高吞吐与可扩展性)
[2. 消息持久化](#2. 消息持久化)
[3. 消息顺序性](#3. 消息顺序性)
[4. 消费者偏移量(Offset)](#4. 消费者偏移量(Offset))
[五、为什么选择 Kafka](#五、为什么选择 Kafka)
一、Kafka 是什么
Kafka 是一个分布式流处理平台,本质上是一个高吞吐、可扩展、持久化的消息队列系统。它最初由 LinkedIn 开发,后成为 Apache 基金会的顶级项目,广泛应用于大数据、实时计算和微服务架构中。
二、核心概念
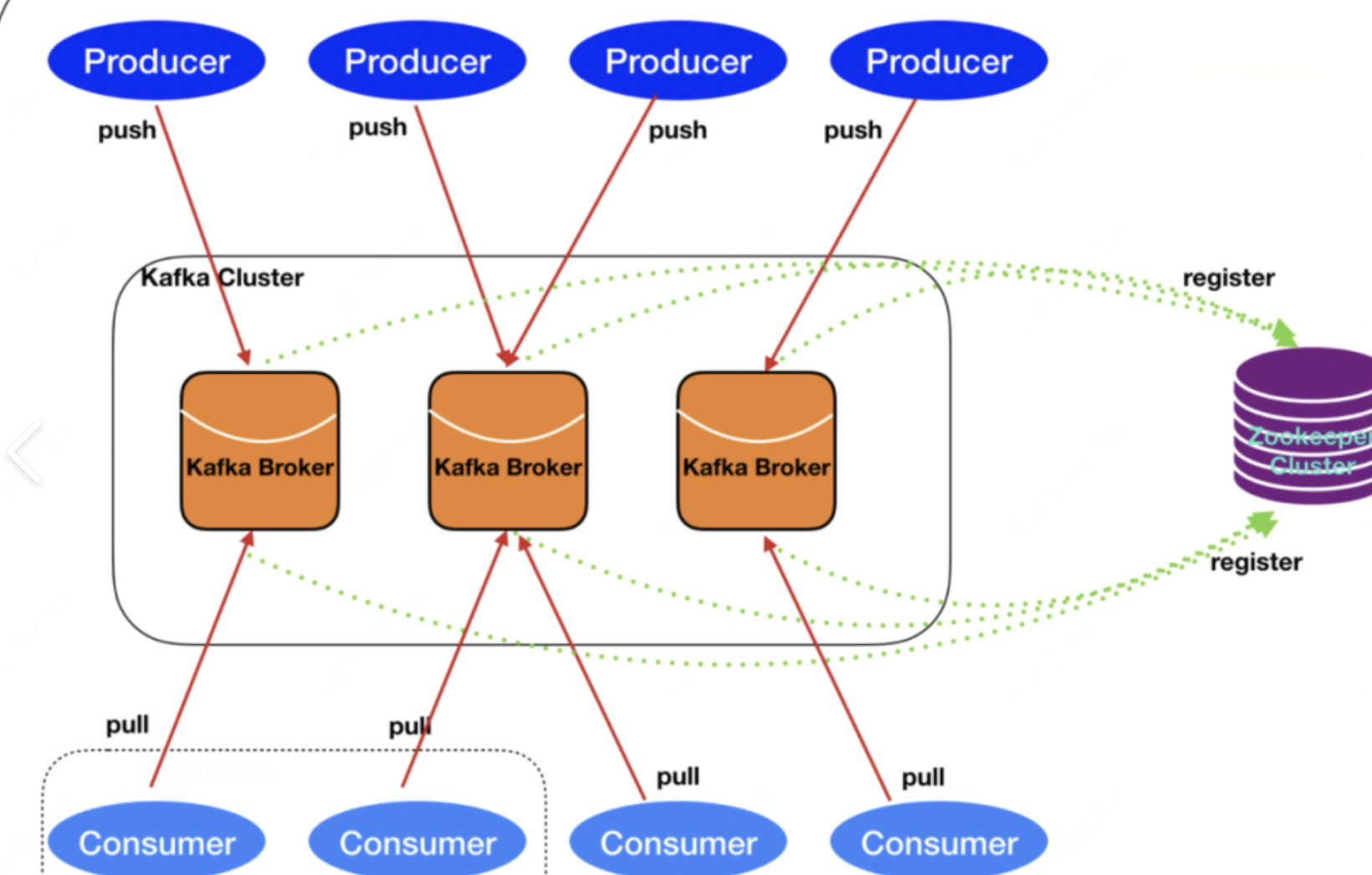
1. 基本组件
-
Producer(生产者) :负责创建消息并发送到 Kafka。
-
Consumer(消费者) :从 Kafka 读取消息并进行处理。
-
Broker(代理) :Kafka 服务器节点,负责接收、存储和传递消息。
-
Topic(主题) :消息的分类,生产者向 Topic 发送消息,消费者从 Topic 消费消息。•
-
Partition(分区):Topic 的物理分区,每个 Partition 是一个有序、不可变的消息序列,支持并行处理。
-
等等
2. 消息模型
Kafka 基于发布-订阅模型 ,采用Topic + Partition 的组织方式。一个 Topic 可以包含多个 Partition,每个 Partition 在一个 Broker 上存储,支持水平扩展。
不同的mq采用不同的消息模型,并不是所有的mq都有topic和partition的说法。
3. 消费者组(Consumer Group)
消费者通常以消费者组 的形式工作。同一个 Group 内的多个消费者共同消费一个 Topic 的消息,但每个 Partition 只能被组内的一个消费者消费,实现负载均衡和并行处理。
三、核心特性
1. 高吞吐与可扩展性
Kafka 设计初衷是处理海量数据流,单机可支持每秒数十万甚至上百万条消息的吞吐,通过增加 Broker 和 Partition 可实现水平扩展。
2. 消息持久化
消息默认持久化到磁盘,并可配置保留策略(如按时间或大小保留),即使消费者宕机,消息也不会丢失,可重新消费。
3. 消息顺序性
Kafka 保证单个 Partition 内消息的顺序性,但不保证全局顺序。因此,对于强顺序要求的场景,应确保相关消息进入同一个 Partition。
4. 消费者偏移量(Offset)
Kafka 不会自动删除已消费的消息,消费者通过 Offset 标记消费位置,可随时回溯或重放数据。Offset 由消费者管理,支持手动或自动提交。
四、典型使用场景
- 异步处理 :如用户注册后异步发送通知、日志记录等非核心流程。
- 系统解耦 :生产者和消费者无需相互感知,通过 Kafka 中间层交互,降低系统耦合度。
- 流量削峰 :应对突发流量,Kafka 作为缓冲层保护下游系统。
- 日志聚合 :收集分布式系统中的日志、指标等数据,统一处理与分析。
- 事件驱动架构 :作为事件总线,支撑微服务间基于事件的通信。
我举个例子哈 ,就是比如我写的一个项目,是校园招聘平台,求职者投递岗位,需要发送信息给招聘者,但是主要的一个流程是处理这个人的简历存入数据库等操作。发送消息给招聘者、生成日志等操作虽然重要但是不要求高实时性,可以放到后面操作,不用占用主线程的时间,就可以用kafka来操作"送消息给招聘者、生成日志"等操作。
但是需要注意的是,kafka一般用于分布式系统的不同服务间的通信和异步操作。对于单体应用进行异步操作可以使用CompletableFuture (Java 提供的 本地异步编程工具,用于 当前 JVM 内部的异步任务)。
| 对比项 | Kafka | CompletableFuture |
|---|---|---|
| 作用范围 | 跨服务 / 分布式 | 单个应用 / JVM 内部 |
| 通信方式 | 异步消息队列 | Future / 回调 / Promise |
| 延迟 | 有一定延迟(消息堆积可能发生) | 几乎实时 |
| 适用场景 | 系统解耦、流量削峰、微服务通信 | 单体应用内异步任务、并发控制 |
| 顺序保证 | 分区内有序 | 无特殊顺序保证 |
| 复杂度 | 较高,需部署维护 | 简单,Java 原生支持 |
五、为什么选择 Kafka
- 高并发与高吞吐 :适合大数据场景下的海量消息处理。
- 分布式架构 :支持多 Broker 集群,具备高可用和容错能力。
对于Broker集群,你可以理解为,一个kafka不够用了,配置多个broker,每一个broker都是一个kafka实例。
- 数据持久化与重放 :消息长期存储,支持多次消费与数据分析。
- 灵活的扩展能力 :通过增加 Partition 和 Broker 实现水平扩展
六、在本地开发中的使用建议
Kafka 本身设计上更适用于 Linux 服务器环境,但在 Windows 系统上也可以运行,只是相比 Linux 来说性能与稳定性稍逊,且配置管理相对复杂。
在 Windows 环境下,建议通过 Docker 快速启动 Kafka 环境,避免复杂的原生安装与配置。使用 Docker Compose 可一键启动 Kafka 与 ZooKeeper,同时将服务端口映射到本地,方便 Spring Boot 等应用连接测试。
七,全文精华,可以直接看这个
Kafka 是一个分布式消息队列系统(也可以称为分布式流平台) ,主要用于实现异步通信 和系统解耦 。在 Kafka 中,有几个核心概念: **Topic(主题)**是消息的分类,生产者(Producer)将消息发送到指定的 Topic,消费者(Consumer)则从 Topic 中订阅并消费消息。我可以为不同的业务逻辑创建不同的 Topic,实现职责分离和消息分类管理。
一个 Topic 可以分成多个 Partition(分区) ,目的是为了提高并发处理能力和吞吐量。Kafka 只保证单个分区内消息的顺序性 ,并且同一分区在同一时刻只能被同一个消费者组(Consumer Group)中的一个消费者实例消费 ,但不同的分区可以被不同的消费者并行消费,从而提升整体的消费速度和扩展性。
Kafka 适合用来做异步处理,比如在一个求职系统中,用户提交了岗位投递后,系统不需要立即通知招聘者,可以将"发送投递通知"这个非核心、允许延迟的操作交给 Kafka 异步处理,主线程快速响应用户,而消费者服务在后台异步处理真正的通知逻辑,比如发邮件、记录行为日志等。这种异步方式可以让系统更高效、更健壮,同时提升用户体验。
相比于 Java 中的 CompletableFuture,Kafka 的适用场景更偏向于分布式系统间的异步通信与解耦 ,而 CompletableFuture 更适合用在单个应用或 JVM 内部的异步任务处理 。对于单体应用而言,如果只是简单的异步逻辑,使用 CompletableFuture 可能更轻便,但如果涉及到多个服务之间的消息传递、事件驱动、或者需要削峰填谷、流量控制,Kafka 是更合适的选择。而且 Kafka 的异步处理不要求立即返回处理结果,更强调消息的可靠投递与后续处理。
Kafka 通常用于分布式架构下多个服务之间的通信与协调 ,因此它天然支持集群模式,可以部署多个 Broker(代理/服务器节点) ,每个 Broker 是一个 Kafka 实例,它们共同组成一个 Kafka 集群,实现数据的高可用、负载均衡与横向扩展。当单个 Broker 的处理能力不足时,可以通过增加 Broker 来扩展整个 Kafka 集群,提升系统的整体吞吐量和容错能力。
虽然 Kafka 本身设计上更适用于 Linux 服务器环境,但在 Windows 系统上也可以运行,只是相比 Linux 来说性能与稳定性稍逊,且配置管理相对复杂。对于本地开发、学习或测试场景 ,推荐使用 Docker 来快速启动 Kafka 环境 ,通过拉取别人已经配置好的 Kafka + ZooKeeper 镜像,可以避免手动安装和配置的繁琐过程,实现一键启动、环境隔离、轻量高效,而且这种方式也更贴近生产环境中的实际部署方式(因为生产环境通常也是运行在 Linux 上的)。
此外,Kafka 的消息是持久化存储的,默认会保存一段时间(比如 7 天或更久),即使消费者暂时离线,之后重新启动也能消费到历史消息(只要未过期)。Kafka 还支持多种消息可靠性配置,比如通过 Producer 的 Ack 机制(如 acks=all)来保证消息不丢失,也可以对消息的消费进度(offset)进行管理,实现精确一次、至少一次或至多一次的语义。
Kafka 中的消息在 Producer 发送并成功写入 Topic 后,会持久化存储在 Broker 中。这些消息并不会自动或立即推送给消费者 ,而是由消费者通过主动拉取(poll)的方式,根据自身逻辑和节奏,在需要的时候从 Kafka 获取并处理。消息的处理时机、速度、顺序,完全由消费者控制,Kafka 只负责可靠地存储和传递。
总的来说,Kafka 不仅仅是一个简单的消息队列,它是一个功能强大、扩展性极高的分布式流处理平台,适用于高并发、分布式、异步解耦的各种业务场景,比如事件驱动架构、日志收集、实时数据处理、微服务通信等。对于开发者来说,理解 Kafka 的核心概念(如 Topic、Partition、Consumer Group、Broker、Offset 等)以及它在分布式系统中的作用,是构建高可用、高并发、松耦合系统的重要基础。