MHA(Master HA)是一款开源的 MySQL 的高可用程序,它为 MySQL 主从复制架构提供了 automating master failover 功能。MHA 在监控到 master 节点故障时,会提升其中拥有最新数据的 slave 节点成为新的master 节点,在此期间,MHA 会通过于其它从节点获取额外信息来避免一致性方面的问题。MHA 还提供了 master 节点的在线切换功能,即按需切换 master/slave 节点。 MHA 是由日本人 yoshinorim(原就职于DeNA现就职于FaceBook)开发的比较成熟的 MySQL 高可用方案。MHA 能够在30秒内实现故障切换,并能在故障切换中,最大可能的保证数据一致性。目前淘宝也正在开发相似产品 TMHA, 目前已支持一主一从。
一、MHA的组成
(一)MHA中的角色
MHA 服务有两种角色, MHA Manager(管理节点)和 MHA Node(数据节点):
Node 节点(执行层,含 Master/Slave)
Node 节点是 MySQL 数据存储与复制的载体,同时提供 MHA 切换所需的数据修复、binlog 管理工具,核心工具及功能如下:
-
MHA Manager:通常单独部署在一台独立机器上管理多个 master/slave 集群(组),每个master/slave 集群称作一个application,用来管理统筹整个集群。
-
MHA Node:运行在每台 MySQL 服务器上(master/slave/manager),它通过监控具备解析和清理 logs 功能的脚本来加快故障转移。主要是接收管理节点所发出指令的代理,代理需要运行在每一个 mysql 节点上。简单讲node就是用来收集从节点服务器上所生成的bin-log。对比打算提升为新的主节点之上的从节点的是否拥有并完成操作,如果没有发给新主节点在本地应用后提升为主节点。
(二)MHA提供的工具
MHA(Master High Availability)是 MySQL 高可用解决方案,通过 Manager 节点(管理节点)和 Node 节点(数据节点,含 Master、Slave)协同工作,实现 MySQL 主从集群的故障检测、自动切换与数据一致性保障,两者依赖不同工具完成核心任务,具体如下:
Manager 节点(控制中心)
Manager 节点是 MHA 的调度核心,负责监控集群、检测故障、触发切换,核心工具及功能如下:
-
masterha_manager :MHA 主进程,是 Manager 节点的 "心脏"。持续监控 Master/Slave 存活状态(通过 SSH 心跳 + MySQL 连接)、主从复制延迟,发现 Master 故障后自动触发切换流程,同时将监控日志输出到指定路径(如
/var/log/mha)。 -
masterha_check_ssh:部署前必执行工具,检查 Manager 与所有 Node 节点的 SSH 免密登录连通性。只有确保 Manager 能无密码访问所有 Node,后续切换时才能远程操作 Node 节点,避免 SSH 问题导致切换失败。
-
masterha_check_repl:检查 MySQL 主从复制健康状态,包括复制链路是否通畅、Slave 延迟是否过大、binlog 一致性等。可用于部署前验证复制正常性,也可在日常维护中排查复制异常(如 Slave 报错)。
-
masterha_master_switch:手动触发主从切换,支持 "故障切换"(Master 宕机后指定新 Master)和 "在线切换"(Master 正常时主动切换角色,如主节点升级)两种模式。
-
masterha_conf_host :动态修改 MHA 配置文件,支持在线添加 / 删除 Slave 节点、更新复制参数,无需停止
masterha_manager进程,适配集群动态扩容 / 缩容场景。 -
masterha_stop :停止 Manager 节点的
masterha_manager监控进程,多用于集群维护(如重启 MySQL)时临时停止监控,避免误触发切换。 -
save_binary_logs:Master 故障时,在 Master 节点(或其备份)上保存未传输的 binlog。若 Master 宕机前有 binlog 未同步到 Slave,此工具可通过 SSH 提取剩余 binlog,后续用于 Slave 数据补全,避免数据丢失。
-
apply_diff_relay_logs:在 Slave 节点修复数据差异。切换后需确保所有 Slave 数据一致,此工具会对比 Slave 中继日志与 Master 剩余 binlog,自动补全数据差异,保障新 Master 与 Slave 数据同步。
-
filter_mysqlbinlog :过滤 MySQL binlog 中的无效语句(如
CREATE DATABASE、DROP TABLE等)。在数据修复过程中排除无需同步的操作,避免 Slave 执行无效语句报错。 -
purge_relay_logs:清理 Slave 节点的中继日志(relay log)。按配置自动保留指定时间 / 大小的中继日志,兼顾数据安全性(避免误删有用日志)和磁盘利用率(防止日志占满磁盘)。
二、MHA的工作原理
-
从宕机崩溃的master保存二进制日志事件(binlog events);
-
识别含有最新更新的 slave ;
-
应用差异的中继日志(relay log) 到其他 slave ;
-
应用从 master 保存的二进制日志事件(binlog events);
-
提升一个 slave 为新 master ;
-
使用其他的 slave 连接新的 master 进行复制。
三、部署MHA
(一)准备实验环境
-
三台主机:master、slave1、slave2
-
操作系统:CentOS
-
配置主机名(/etc/hosts)
-
配置免密码登录
-
每台主机安装MySQL
(二)搭建主从环境
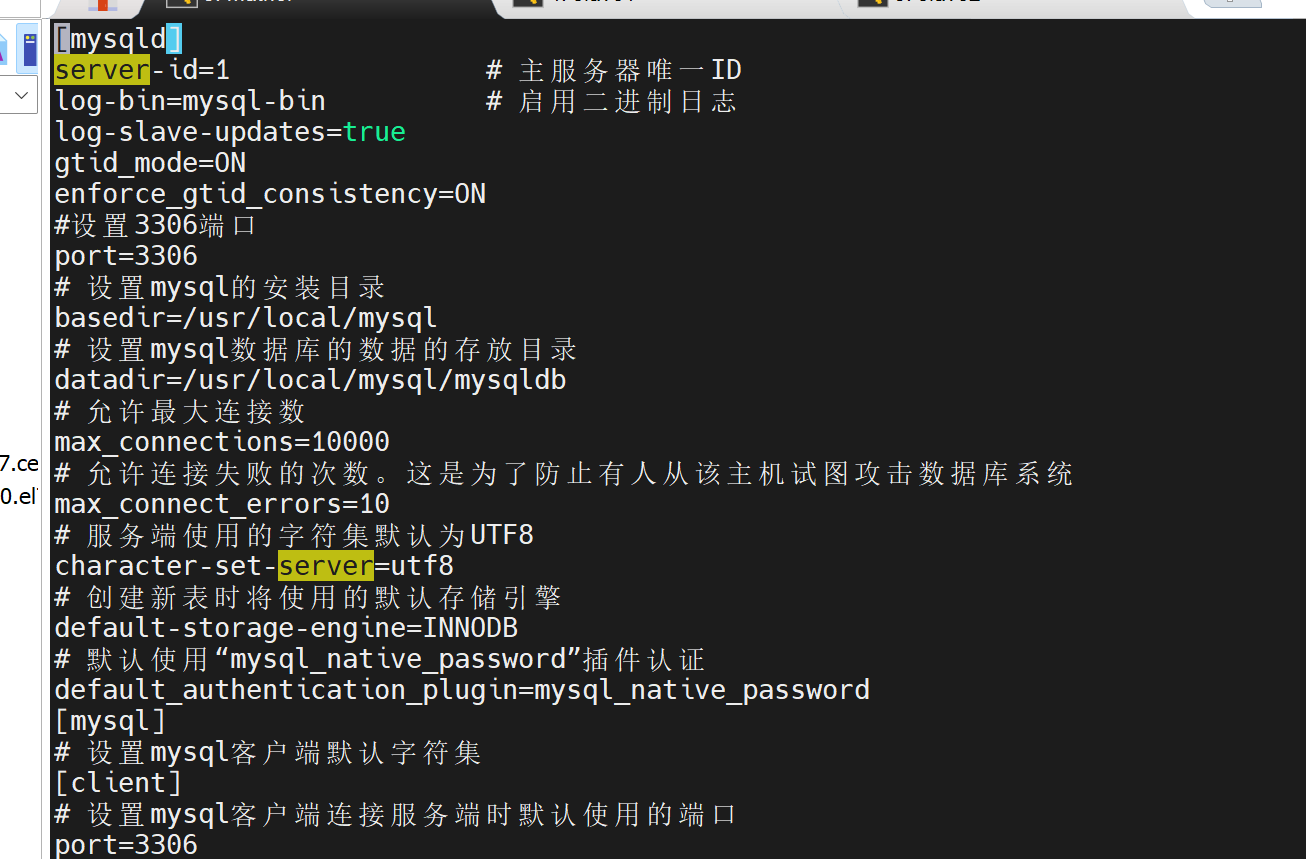
- 每台MySQL开启binlog,设置server-id
vi /etc/my.cnf
mysqld
server-id=1 # 注意:每台MySQL设置不同的server-id
log-bin=mysql-bin # 启用二进制日志
log-slave-updates=true
gtid_mode=ON
enforce_gtid_consistency=ON
#设置3306端口
port=3306
设置mysql的安装目录
basedir=/usr/local/mysql
设置mysql数据库的数据的存放目录
datadir=/usr/local/mysql/mysqldb
允许最大连接数
max_connections=10000
允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统
max_connect_errors=10
服务端使用的字符集默认为UTF8
character-set-server=utf8
创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
默认使用"mysql_native_password"插件认证
default_authentication_plugin=mysql_native_password
mysql
设置mysql客户端默认字符集
client
设置mysql客户端连接服务端时默认使用的端口
port=3306
- 在所有机器上,创建主从复制的账号
create user 'repl'@'10.1.1.%' identified by 'master';
grant replication slave on *.* to 'repl'@'10.1.1.%';
flush privileges;
- 在所有机器上,创建管理账号
create user 'myadmin'@'10.1.1.%' identified by 'master';
grant all privileges on *.* to 'myadmin'@'10.1.1.%';
flush privileges;
- 在主库和从库上,启用GTID
set @@GLOBAL.ENFORCE_GTID_CONSISTENCY = ON;
set @@GLOBAL.GTID_MODE = OFF_PERMISSIVE;
set @@GLOBAL.GTID_MODE = ON_PERMISSIVE;
set @@GLOBAL.GTID_MODE = ON;
参数说明: GTID是MySQL 5.6引入的新特性,其全称是Global Transaction Identifier,可简化MySQL的主从切换以及Failover。GTID用于在binlog中唯一标识一个事务。当事务提交时,MySQL Server在写binlog的时候,会先写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID,然后再写事务的Binlog。主从同步时GTID_Event和事务的Binlog都会传递到从库,从库在执行的时候也是用同样的GTID写binlog,这样主从同步以后,就可通过GTID确定从库同步到的位置了。也就是说,无论是级联情况,还是一主多从情况,都可以通过GTID自动找点儿,而无需像之前那样通过File_name和File_position找点儿了。
- 在从库上分别配置主从复制命令并开启主从同步
change master to master_host='master',master_user='repl',\
master_password='123456',master_auto_position=1;
start slave;
- 在从库上查看主从复制的状态
show slave status\G;
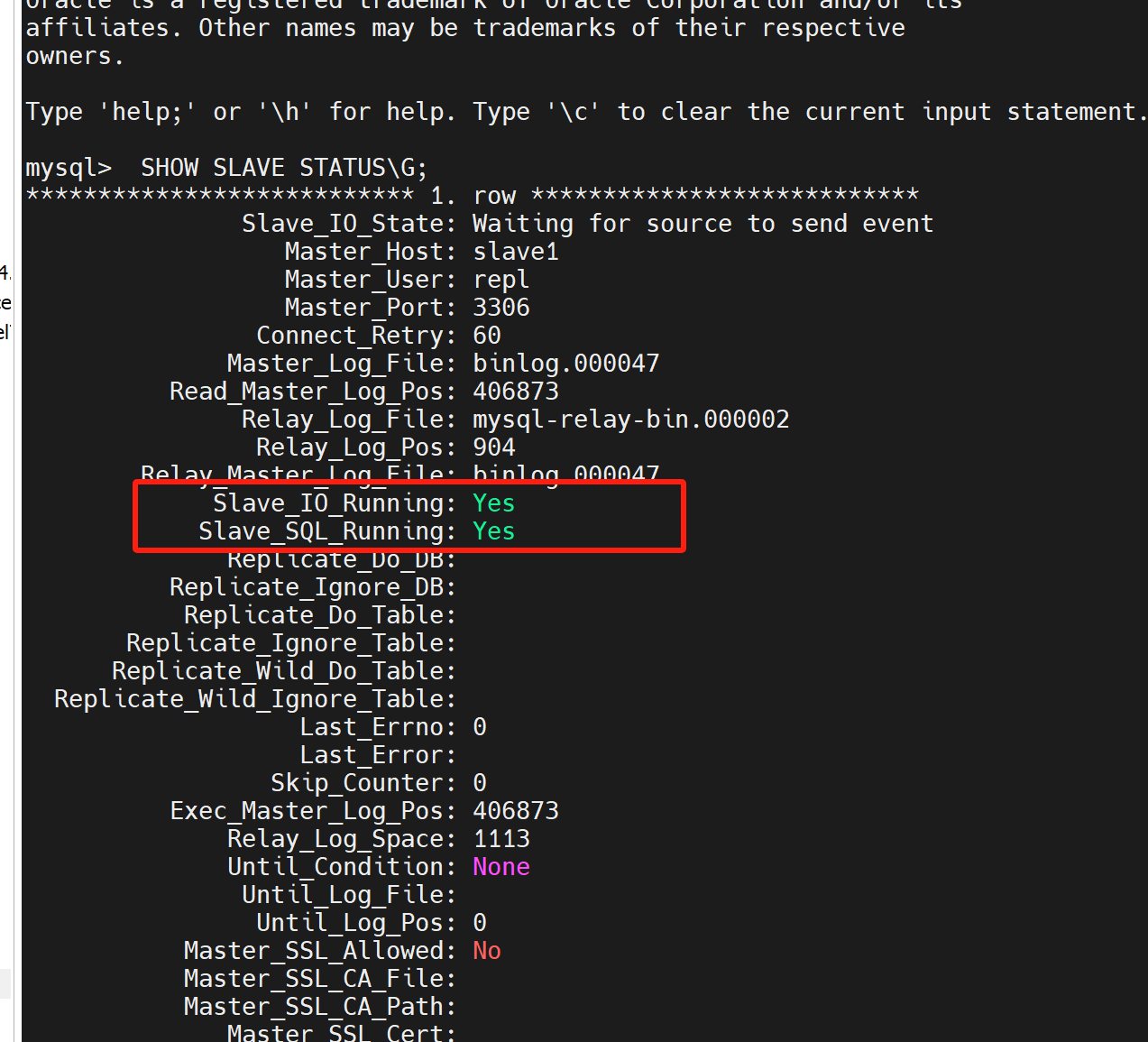
- 测试主从复制
(三)安装MHA
- 所有节点安装node软件依赖包和node软件
yum -y install perl-DBD-MySQL
rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
- 在master上安装安装manager软件依赖包
yum install -y perl-Config-Tiny
yum install -y epel-release
yum install -y perl-Log-Dispatch
yum install -y perl-Parallel-ForkManager
yum install -y perl-Time-HiRes
- 在master上安装安装manager软件
rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
#创建配置文件目录、日志目录
mkdir -p /etc/mha
mkdir -p /var/log/mha/log
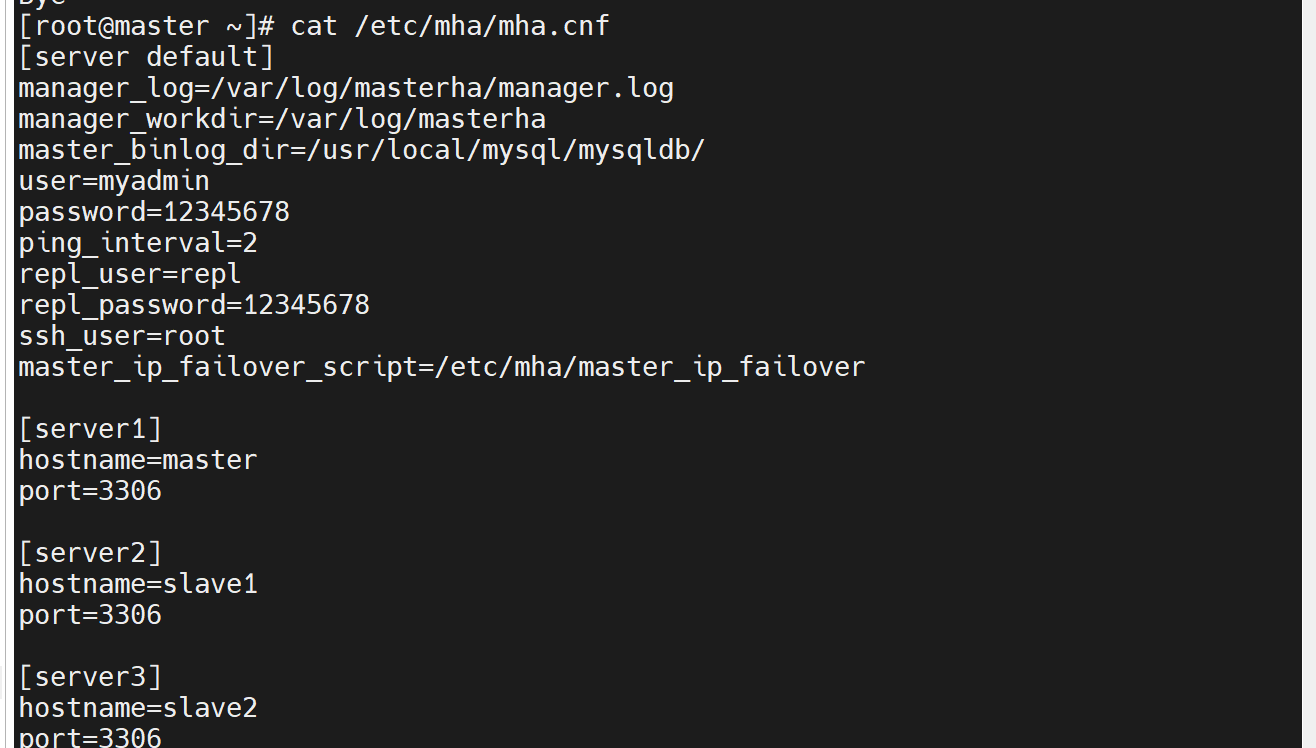
#编辑mha配置文件 vi /etc/mha/mha.cnf
server default
manager_log=/var/log/masterha/manager.log
manager_workdir=/var/log/masterha
master_binlog_dir=/usr/local/mysql/mysqldb/
user=myadmin
password=12345678
ping_interval=2
repl_user=repl
repl_password=12345678
ssh_user=root
master_ip_failover_script=/etc/mha/master_ip_failover
server1
hostname=master
port=3306
server2
hostname=slave1
port=3306
server3
hostname=slave2
port=3306
(五)检查状态,并开启MHA
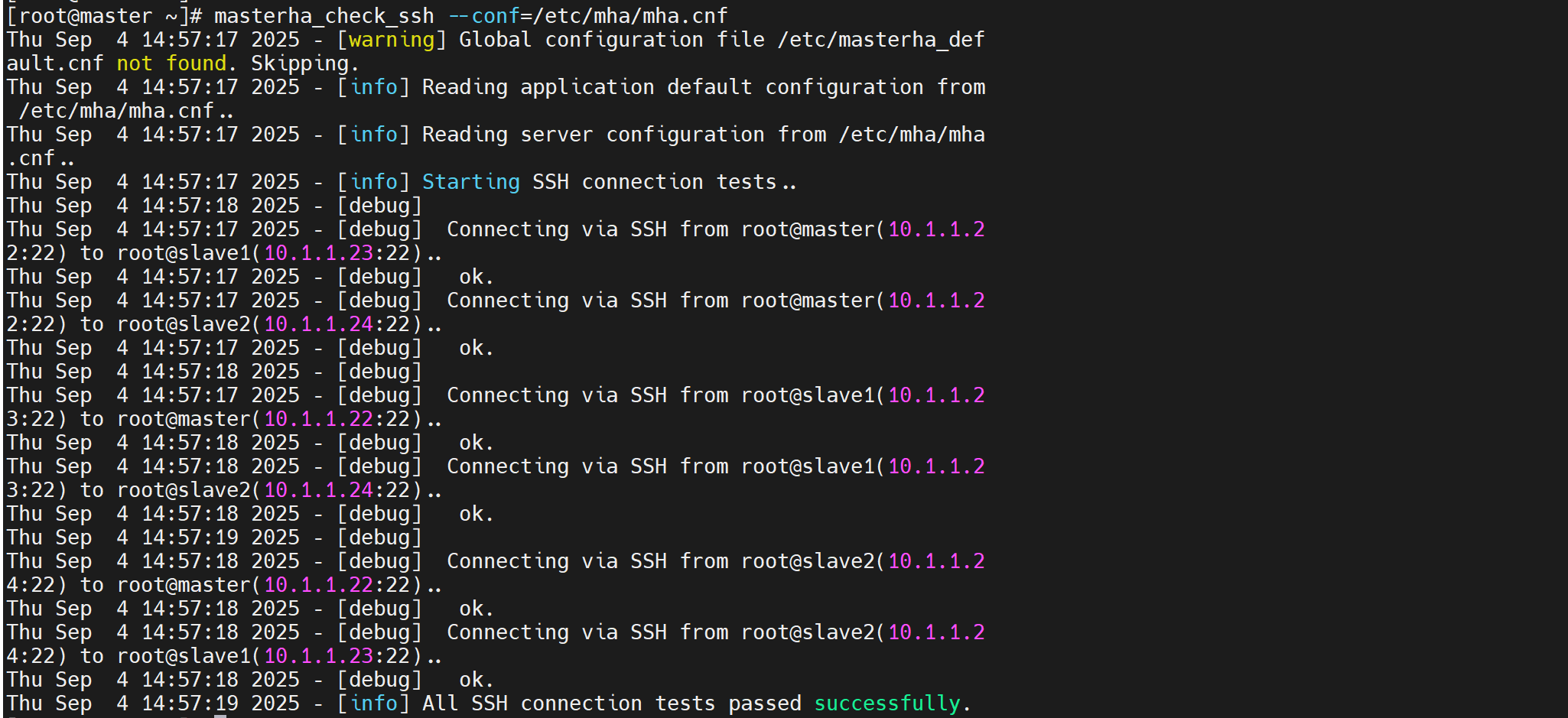
- 检查互信
masterha_check_ssh --conf=/etc/mha/mha.cnf
- 检查主从复制状态
masterha_check_repl --conf=/etc/mha/mha.cnf
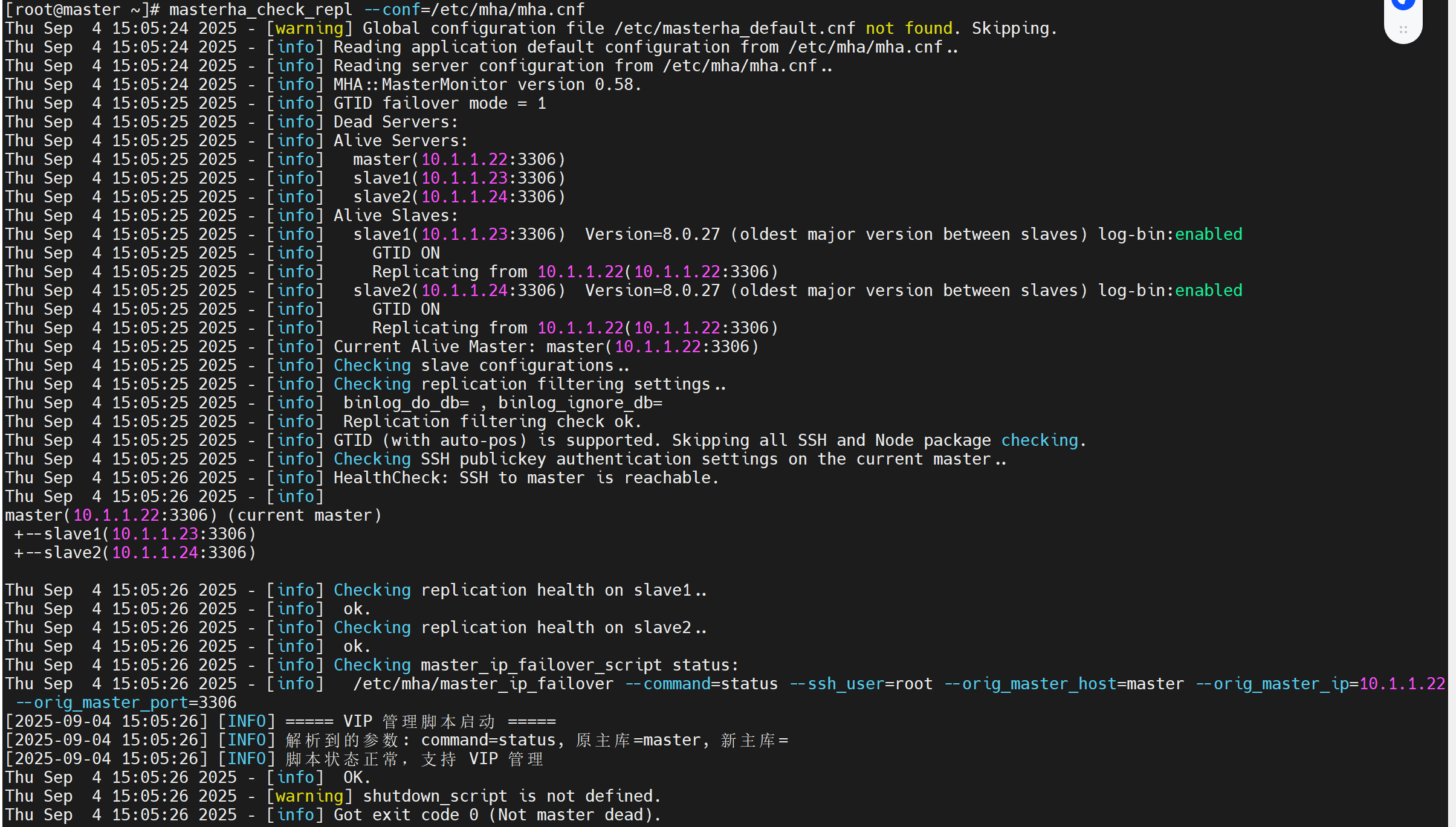
出现的问题:
1、需要注释三台主机中my.cnf中 client下的字符配置;
2、配置三台主机中MySQL的环境变量;
3、如果之前测试过故障自动转移,需要将/var/log/mha/log文件夹下的对应的 complete文件删除
以上处理完成之后再进行检测集群是否健康。
- 开启MHA-manager
nohup masterha_manager --conf=/etc/mha/mha.cnf > /var/log/mha/log/manager.log < /dev/null 2>&1 &
- 查看MHA状态
masterha_check_status --conf=/etc/mha/mha.cnf

- 测试HA高可用的自动切换
在master上,执行shutdown操作
mysqladmin -uroot -p12345678 shutdown
MHA会自动进行主从切换。切换完成后,MHA进程会自动停止运行。
在slave1和slave2上观察,执行下面的语句:
show slave status\G;
四、MHA + VIP 部署
(一)修改mha.cnf配置文件
vim /etc/mha/mha.cnf
在server-default下添加如下代码
master_ip_failover_script=/etc/mha/master_ip_failover
(二) master_ip_failover代码如下:
#!/bin/bash
完整的 MHA VIP 管理脚本(支持自动切换 VIP)
配置参数
VIP="10.1.1.26" # VIP 地址
NETMASK="24" # 子网掩码
INTERFACE="ens33" # 网络接口(修正拼写错误:end33 → ens33)
ARPING_COUNT=3 # ARP 广播次数
LOG_FILE="/var/log/mha/vip_scripts.log"
SSH_OPTS="-o StrictHostKeyChecking=no -o ConnectTimeout=10" # SSH 选项
解析参数
command=""
ssh_user=""
orig_master_host=""
orig_master_ip=""
orig_master_port=""
new_master_host=""
new_master_ip=""
new_master_port=""
while \[ $# -gt 0 ]; do
case "$1" in
--command=*)
command="${1#*=}"
shift
;;
--ssh_user=*)
ssh_user="${1#*=}"
shift
;;
--orig_master_host=*)
orig_master_host="${1#*=}"
shift
;;
--orig_master_ip=*)
orig_master_ip="${1#*=}"
shift
;;
--orig_master_port=*)
orig_master_port="${1#*=}"
shift
;;
--new_master_host=*)
new_master_host="${1#*=}"
shift
;;
--new_master_ip=*)
new_master_ip="${1#*=}"
shift
;;
--new_master_port=*)
new_master_port="${1#*=}"
shift
;;
*)
shift
;;
esac
done
日志函数
log() {
local level=$1
local message=$2
local timestamp=$(date '+%Y-%m-%d %H:%M:%S')
echo "timestamp \[level] message" \>\> "LOG_FILE"
同时输出到控制台(便于调试)
echo -e "$timestamp $level $message"
}
执行 SSH 命令并返回结果
ssh_exec() {
local host=$1
local cmd=$2
log "INFO" "在 host 执行命令: cmd"
执行 SSH 命令并捕获输出和退出码
local output=(ssh SSH_OPTS "ssh_user@host" "$cmd" 2>&1)
local exit_code=$?
if $exit_code -ne 0 ; then
log "ERROR" "SSH 命令执行失败(host): output"
else
log "INFO" "SSH 命令执行成功(host): output"
fi
return $exit_code
}
添加 VIP 到新主库
add_vip() {
local host=$1
log "INFO" "开始在新主库 host 添加 VIP: VIP/$NETMASK"
1. 检查网络接口是否存在
local check_interface="ip link show $INTERFACE > /dev/null 2>&1"
if ! ssh_exec "host" "check_interface"; then
log "ERROR" "网络接口 INTERFACE 在 host 上不存在"
return 1
fi
2. 添加 VIP
local add_cmd="ip addr add VIP/NETMASK dev INTERFACE label {INTERFACE}:0"
if ! ssh_exec "host" "add_cmd"; then
log "ERROR" "在 $host 上添加 VIP 失败"
return 1
fi
3. 发送 ARP 广播(更新网络缓存)
local arp_cmd="arping -c ARPING_COUNT -A -I INTERFACE $VIP > /dev/null 2>&1"
if ! ssh_exec "host" "arp_cmd"; then
log "WARN" "ARP 广播发送失败,但 VIP 已添加"
fi
log "INFO" "VIP 已成功添加到 $host"
return 0
}
从原主库移除 VIP
remove_vip() {
local host=$1
log "INFO" "开始从原主库 host 移除 VIP: VIP"
1. 检查 VIP 是否存在
local check_vip="ip addr show INTERFACE \| grep -q 'VIP/$NETMASK'"
if ! ssh_exec "host" "check_vip"; then
log "WARN" "VIP VIP 在 host 上不存在,跳过移除"
return 0
fi
2. 移除 VIP
local del_cmd="ip addr del VIP/NETMASK dev $INTERFACE"
if ! ssh_exec "host" "del_cmd"; then
log "ERROR" "从 $host 上移除 VIP 失败"
return 1
fi
3. 发送 ARP 广播(通知网络更新)
local arp_cmd="arping -c ARPING_COUNT -A -I INTERFACE $VIP > /dev/null 2>&1"
ssh_exec "host" "arp_cmd"
log "INFO" "VIP 已成功从 $host 移除"
return 0
}
主逻辑
main() {
初始化日志目录
mkdir -p "(dirname "LOG_FILE")"
log "INFO" "===== VIP 管理脚本启动 ====="
log "INFO" "解析到的参数: command=command, 原主库=orig_master_host, 新主库=$new_master_host"
case "$command" in
"start")
新主库启动 VIP
if -z "$new_master_host" ; then
log "ERROR" "start 命令缺少新主库参数"
exit 1
fi
if add_vip "$new_master_host"; then
log "INFO" "VIP 切换到新主库 $new_master_host 成功"
exit 0
else
log "ERROR" "VIP 切换到新主库 $new_master_host 失败"
exit 1
fi
;;
"stop"|"stopssh")
从原主库移除 VIP
if -z "$orig_master_host" ; then
log "ERROR" "stop 命令缺少原主库参数"
exit 1
fi
if remove_vip "$orig_master_host"; then
log "INFO" "从原主库 $orig_master_host 移除 VIP 成功"
exit 0
else
log "ERROR" "从原主库 $orig_master_host 移除 VIP 失败"
exit 1
fi
;;
"status")
MHA 状态检查(必须返回 0)
log "INFO" "脚本状态正常,支持 VIP 管理"
exit 0
;;
*)
log "ERROR" "未知命令: $command(支持的命令: start/stop/stopssh/status)"
exit 1
;;
esac
}
执行主函数
main "$@"
注意:
1.需要修改master_ip_failover的权限:chmod +x master_ip_failover
2.注意虚拟IP的网段:10.1.1.26需要根据自己的IP网段修改
(三)测试
测试状态检查(应返回成功)
/etc/mha/master_ip_failover --command=status --ssh_user=root
测试添加 VIP 到 slave1
/etc/mha/master_ip_failover --command=start --ssh_user=root --new_master_host=slave1
测试从 slave1 移除 VIP
/etc/mha/master_ip_failover --command=stop --ssh_user=root --orig_master_host=slave1
其他:
添加虚拟IP:
ifconfig ens33:0 110.1.1.26/24
删除虚拟IP:
ip addr del 10.1.1.26/24 dev ens33