作者:来自 Elastic Carly Richmond

你听说过 "上下文工程 - context engineering" 这个新术语,但不确定它是什么吗?来看看我们的讲解,了解它的含义,以及 RAG 与 Elasticsearch 如何提供帮助。
Elasticsearch 拥有与行业领先的 Gen AI 工具和提供商的原生集成。查看我们的网络研讨会,内容包括超越 RAG 基础,或使用 Elastic Vector Database 构建可用于生产的应用程序。
要为你的用例构建最佳搜索解决方案,现在就开始免费的云试用,或在本地机器上尝试 Elastic。
随着 AI 的快速发展,新术语和新技术层出不穷。最新的讨论之一就是上下文工程。如果你还不清楚上下文工程是什么、为什么重要、以及可以使用哪些技术来优化 agentic 系统所用的上下文,请继续阅读。
什么是上下文工程?
上下文工程是指一系列实践的集合,这些实践可以结合起来为大语言模型(LLM)提供正确的信息,帮助它们完成预期任务。确保我们在 agent 和 MCP 工具中使用的 LLM 拥有正确的信息来源非常重要,这样才能保证它们提供准确的结果,而不是产生幻觉或无法给出预期答案。我的高中数学老师总是提到 "输入垃圾,输出垃圾" 的概念,用来说明我们在计算和证明中提供的输入质量。
LLM 也是一样。如果不给它们提供正确的信息,就不能指望它们准确地提供我们所需的答案和自动化功能。正如上面 ChatGPT 的例子所示,它只能利用训练时获得的信息,或者通过后续章节所讨论的组件在上下文中提供的信息。
组件
下图展示了上下文的关键组成部分,这些部分可以用来改进由 AI agent 调用、由 MCP 工具使用的 LLM 的响应:
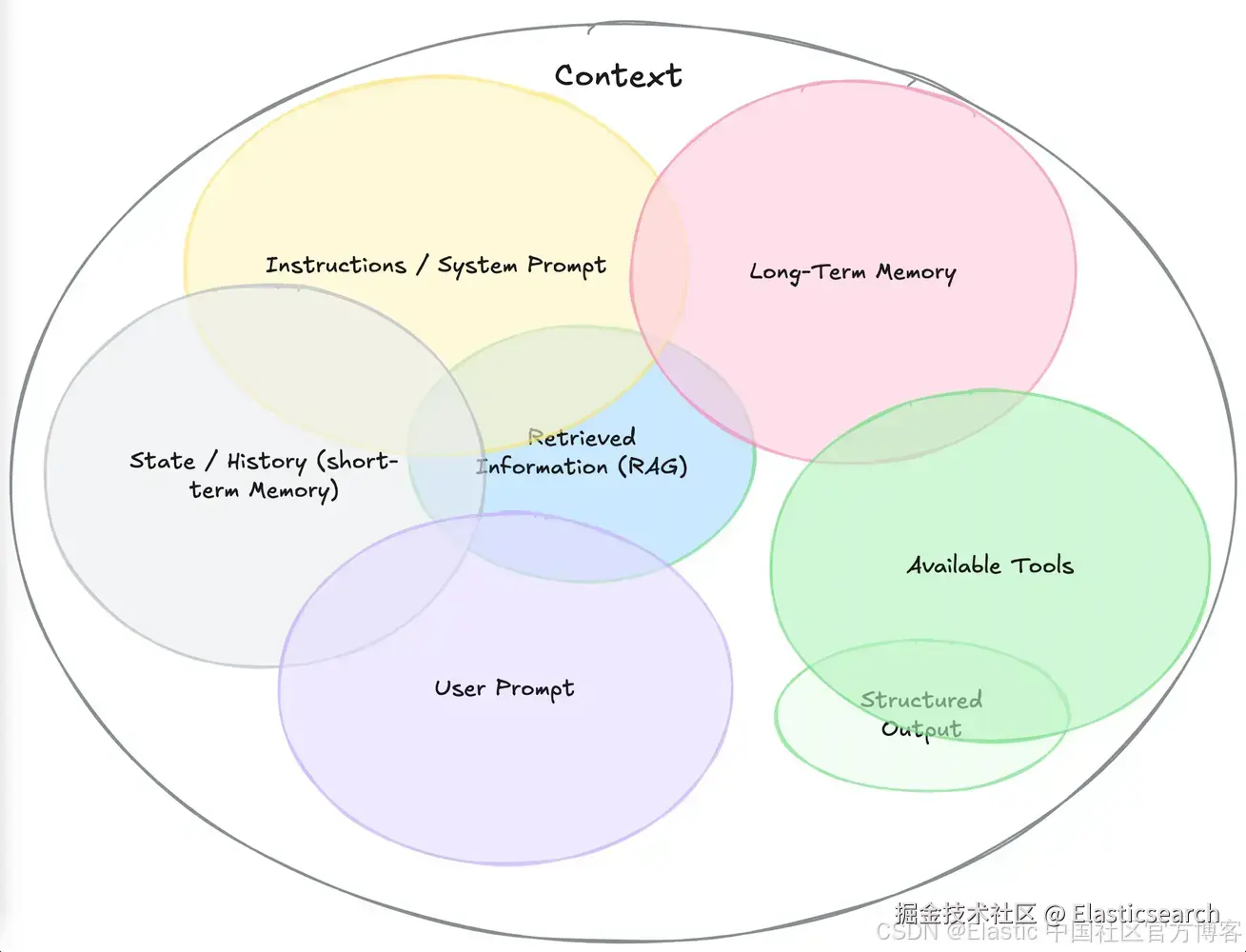 来源: www.philschmid.de/context-eng...
来源: www.philschmid.de/context-eng...
正如 Dexter Horthy 在他的 12-Factor Agents 的第三条原则中所指出的,拥有自己的上下文对于确保 LLM 能生成最佳输出至关重要。
RAG
RAG 是一种架构模式,其中来自信息检索系统(如 Elasticsearch )的数据被提供给 LLM,用于支撑和增强其生成的结果。我们在许多 Elasticsearch Labs 博客中讨论过 RAG,包括这篇提供该结构概览的文章,以及这篇介绍如何用 Python、Langchain、React 和 Elasticsearch 构建一个单一 RAG 聊天机器人的教程。
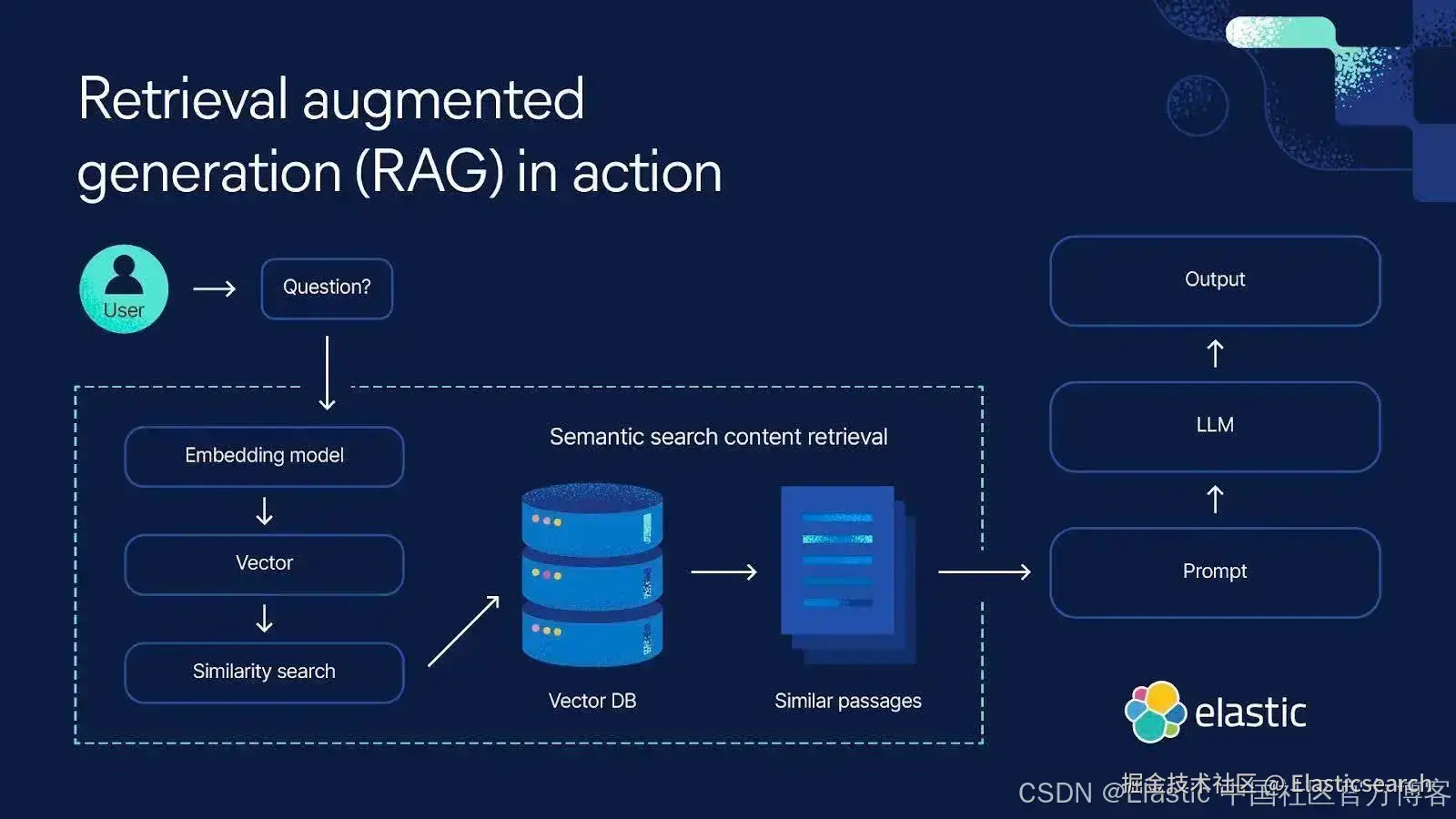
尽管有些人认为新型 LLM 不断扩展的上下文窗口大小意味着 "RAG 已死",但实际上,正如 Drew Breunig 所提到的,你可能会发现 LLM 遭遇上下文混淆问题。上下文混淆是指提供给 LLM 的信息过多,导致其输出结果次优。RAG 能帮助 LLM 指向期望的结果,因为它解决了通用 LLM 的常见限制,包括:
-
对于金融服务或工程等专业术语密集领域缺乏特定领域知识
-
模型训练完成后发生的最新信息或事件
-
幻觉,即 LLM 生成错误答案
RAG 通常涉及从数据存储中提取相关文档,并通过提示传递,或者通过 LLM 调用的专用 AI 工具实现。下面给出了一个简单示例,来自使用 Elasticsearch JavaScript 客户端的 AI SDK Travel Planner。
markdown
`
1. import { tool as createTool } from 'ai';
2. import { z } from 'zod';
4. import { Client } from '@elastic/elasticsearch';
5. import { SearchResponseBody } from '@elastic/elasticsearch/lib/api/types';
7. import { Flight } from '../model/flight.model';
9. const index: string = "upcoming-flight-data";
10. const client: Client = new Client({
11. node: process.env.ELASTIC_ENDPOINT,
12. auth: {
13. apiKey: process.env.ELASTIC_API_KEY || "",
14. },
15. });
17. function extractFlights(response: SearchResponseBody<Flight>): (Flight | undefined)[] {
18. return response.hits.hits.map(hit => { return hit._source})
19. }
21. export const flightTool = createTool({
22. description:
23. "Get flight information for a given destination from Elasticsearch, both outbound and return journeys",
24. parameters: z.object({
25. destination: z.string().describe("The destination we are flying to"),
26. origin: z
27. .string()
28. .describe(
29. "The origin we are flying from (defaults to London if not specified)"
30. ),
31. }),
32. execute: async function ({ destination, origin }) {
33. try {
34. const responses = await client.msearch({
35. searches: [
36. { index: index },
37. {
38. query: {
39. bool: {
40. must: [
41. {
42. match: {
43. origin: origin,
44. },
45. },
46. {
47. match: {
48. destination: destination,
49. },
50. },
51. ],
52. },
53. },
54. },
56. // Return leg
57. { index: index },
58. {
59. query: {
60. bool: {
61. must: [
62. {
63. match: {
64. origin: destination,
65. },
66. },
67. {
68. match: {
69. destination: origin,
70. },
71. },
72. ],
73. },
74. },
75. },
76. ],
77. });
79. if (responses.responses.length < 2) {
80. throw new Error("Unable to obtain flight data");
81. }
83. return {
84. outbound: extractFlights(responses.responses[0] as SearchResponseBody<Flight>),
85. inbound: extractFlights(responses.responses[1] as SearchResponseBody<Flight>)
86. };
87. } catch (e) {
88. console.error(e);
89. return {
90. message: "Unable to obtain flight information",
91. location: location,
92. };
93. }
94. },
95. });
`AI写代码从 Elasticsearch 或其他来源检索相关信息,甚至利用 LLM 摘要或数据聚合等技术,就像我的同事 Alex 在构建 MCP 数据以汇总和查询他的健康数据时所做的那样,可以确保 LLM 拥有提供答案所需的精确数据。然后,这些上下文可以通过新兴协议传递,如 Model Context Protocol(MCP)或 Agent2Agent Protocol(A2A)。
Prompts(提示)
提示工程可能被认为是一个更成熟的实践,但仍然是上下文工程的一个子集。提示工程指的是精炼和设计有效输入(或提示)给 LLM,以产生我们想要的结果。尽管通常以简单文本形式存在,提示也可以包含其他媒体来源,如图像和声音。Sander Schulhoff 等人在其提示工程调查中定义了提示的以下组成部分:
-
Directive(指令):作为请求主要意图的指令或问题
-
Exemplars(示例):可演示的例子,引导 LLM 完成任务
-
Output Formatting(输出格式):期望返回输出信息的格式,如 JSON 或非结构化文本。这很重要,因为根据数据来源,LLM 可能需要进行转换(例如将 Elasticsearch 查询响应的结构化 JSON 转换为另一种格式,而不是直接返回结果)
-
Style Instructions(样式指令):指导如何改变输出结构,这被视为输出格式的特定类型
-
Role(角色):LLM 需要模拟的角色以完成任务(例如旅行代理)
-
Additional Information(附加信息):完成任务所需的其他有用细节,包括来自其他来源的上下文
下面的示例具体展示了用于旅行规划 agent 的提示中每个元素的应用:

所有这些元素都可以进行调整和评估,以确保 LLM 得到最佳结果。除了这些元素外,还有许多技术可以用来结构化和优化提示,从而获得所需的答案。例如,Wei 等人在 2023 年的论文中发现,对于算术和推理任务,使用标准零样本(zero-shot)提示向 LLM 提出简单结构化问题的效果远不如链式思维(chain-of-thought)提示技术。下面的示例总结了这些差异:
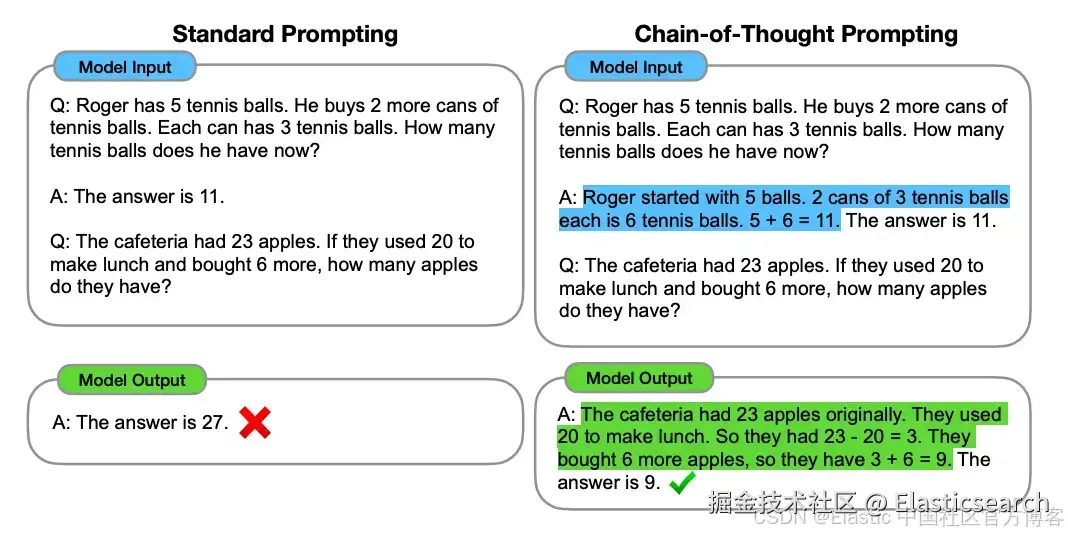 来源:
来源: 在考虑提示(prompt)格式时,你需要考虑几个因素,包括:
-
任务类型(例如简单回忆或翻译 vs 复杂算术推理)
-
任务复杂性和模糊性。模糊的请求可能导致不可预测的结果
-
你作为上下文提供的输入及其格式
-
所需输出
-
所选 LLM 的能力
-
你希望 LLM 模拟的角色
记忆(Memory)
就像人类一样,AI 应用依赖短期和长期记忆来回忆信息。在上下文工程中:
-
短期记忆,通常称为状态或聊天历史,指用户与模型在当前对话中交换的信息。这包括用户提出的初始问题和后续问题
-
长期记忆,简称记忆,指跨对话共享的信息。关键示例包括相关通用信息或近期的对话内容
以我们的 Travel Planner Agent 为例,短期记忆包括旅行日期和地点,以及用户改变主意想探索其他目的地时的任何后续消息。长期记忆可能包含用户的旅行偏好信息,以及以往行程,这些可以用于为新行程提供活动建议(例如为曾参加过葡萄酒品鉴活动的用户推荐类似活动)。
大多数 AI 框架提供管理聊天历史和记忆的能力,因为确保历史记录在上下文窗口中与其他上下文元素一起适配非常重要。例如 LangGrap 的案例,短期记忆作为 agent 状态的一部分使用 checkpointer 管理,而长期记忆则持久化到长期存储中。
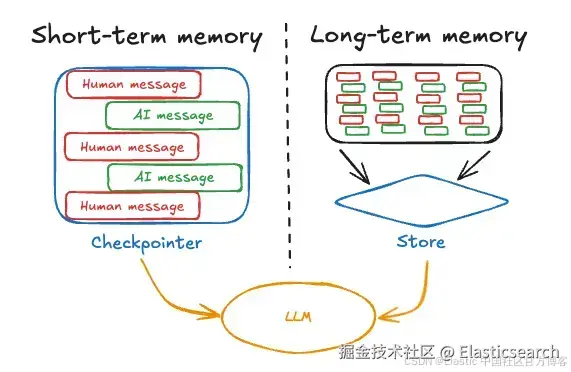 来源: https://langchain ai.github.io/langgraphjs/concepts/memory/
来源: https://langchain ai.github.io/langgraphjs/concepts/memory/
在构建多 agent 架构时,我们还需要注意记忆和上下文的分离。当在更大的流程中将任务分配给子 agent 时,每个 agent 可能需要了解其他 agent 的结果以保持同步。然而,随着时间推移,这些累积会导致上下文窗口溢出:
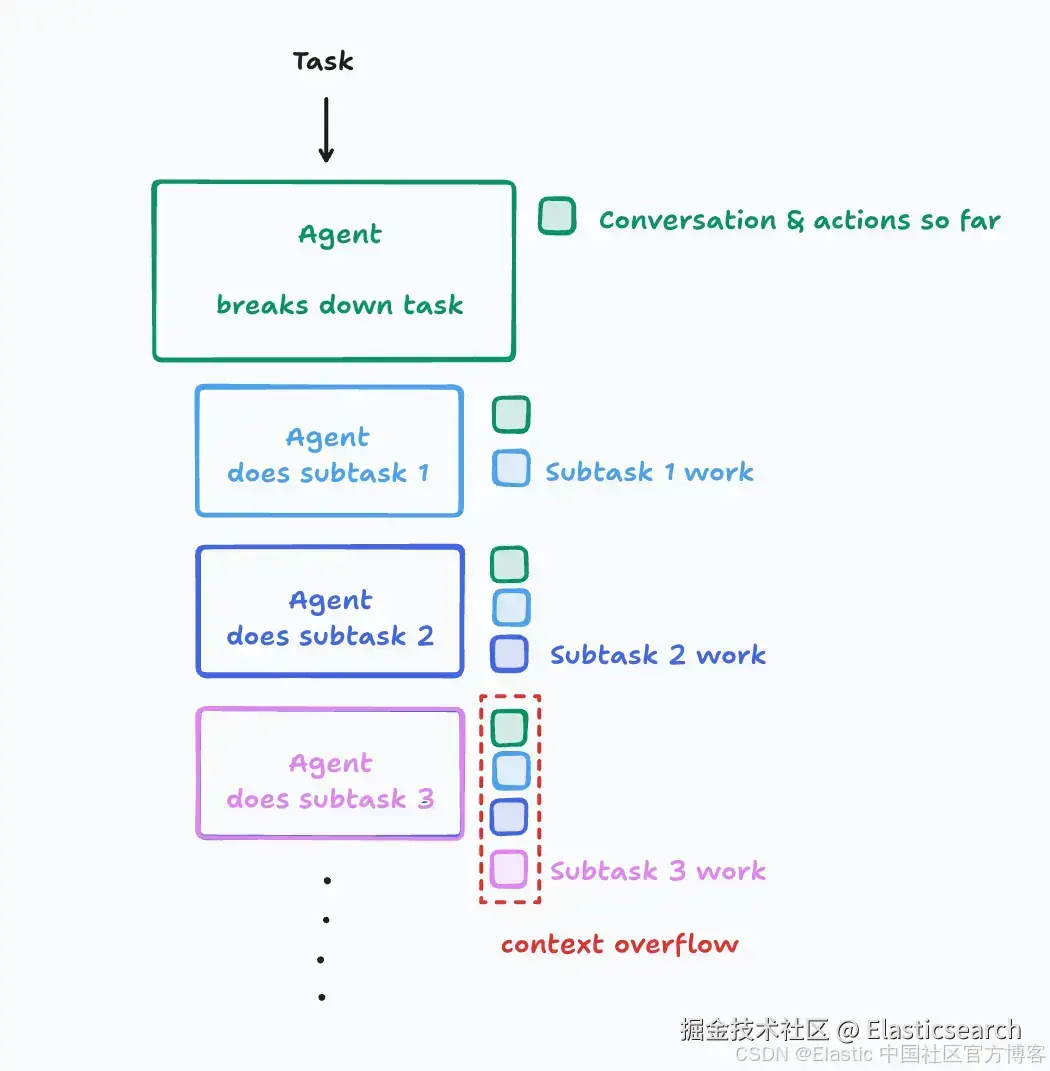 来自 Cognition | Don't Build Multi-Agents
来自 Cognition | Don't Build Multi-Agents
将上下文存储在两种类型的记忆中非常重要,以确保向 LLM 提供相关且最新的上下文。如果未做到这一点,可能会导致上下文污染(context poisoning)。这种污染可能出于恶意目的,例如 OWASP LLM 应用十大中的提示注入(prompt injection)和数据污染攻击。但它也可能因无意原因发生,例如历史记录累积导致模型分心,或者甚至出现矛盾信息引发冲突。
在 Gemini 2.5 报告中,研究人员发现一个玩 Pokémon 的 Gemini agent 倾向重复其历史中的动作,而不是形成新的方法,这意味着增长的上下文反而成为解决问题的障碍。基于这些原因,应管理聊天历史修剪、摘要以及相关检索信息。
结构化输出(Structured Outputs)
随着 AI agent 架构变得复杂,需要确保 LLM 输出遵循模式或契约,这样可以更容易解析并与其他系统和工作流集成。
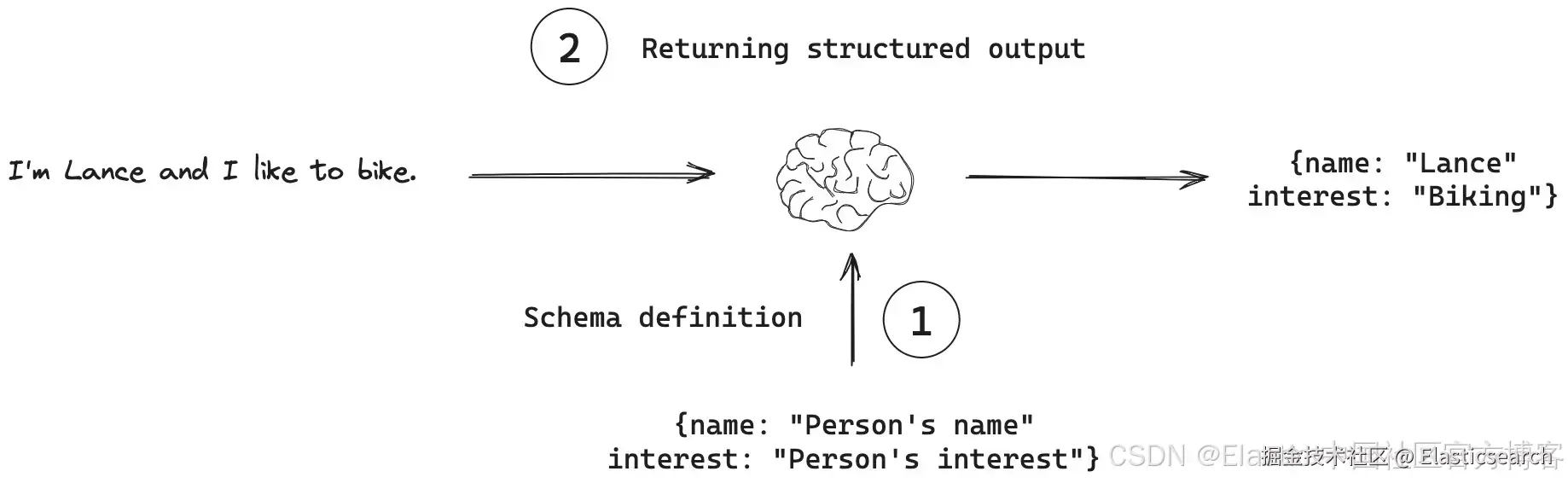 来自: js.langchain.com/docs/concep...
来自: js.langchain.com/docs/concep...
我们都习惯自由文本结果,但这些格式可能难以集成到依赖系统和 agent 中。就像设计一组 REST 接口时,不仅要遵循 OpenAPI 等最佳实践,还要遵循与其他组件兼容的契约一样,我们需要指定期望 LLM 返回的输出格式和模式。下面的示例展示了如何使用 AI SDK 指定模式以生成符合特定模式的对象:
css
`
1. import { generateObject } from 'ai';
2. import { z } from 'zod';
4. const { object } = await generateObject({
5. model: 'openai/gpt-4.1',
6. schemaName: 'Travel Itinerary',
7. schemaDescription: 'Sample travel itinerary for a trip',
8. schema: z.object({
9. title: z.string(),
10. location: z.string(),
11. hotel: z.object({name: z.string(), roomType: z.string(), amount: z.number(), checkin: z.iso.date(), checkout: z.iso.date()}),
12. flights: z.array(z.object({carrier: z.string(), flightNo: z.string().max(8), origin: z.string(), destination: z.string(), date: z.iso.datetime()})),
13. excursions: z.array(z.object({ name: z.string(), amount: z.string(), date: z.iso.datetime()}))
14. }),
15. prompt: 'Generate a travel itinerary based on the specified location',
16. });
`AI写代码为 LLM 输出引入 JSON 结构化输出是有意义的。通常需要在处理结构化和非结构化数据之间取得平衡,就像 Elasticsearch 内部处理数据一样。因此,一些模型开始支持生成符合提供的 JSON 模式的输出,包括 OpenAI 平台的 Structured Outputs 功能。当与函数调用结合使用时,这允许我们为工具之间的信息传递定义标准契约。然而,由于 LLM 生成的 JSON 可能存在语法问题,因此在处理结果时需要优雅地处理潜在错误。
可用工具(Available Tools)
上下文工程中可以使用的最后一个元素是我们提供给 LLM 的工具,用于提供数据。工具允许我们执行诸如自动化操作(例如根据行程预订旅行)、使用前文讨论的 RAG 检索数据,或提供来自其他信息源的信息。我们在上文的 flightTool 中展示了一个 RAG 工具的示例,但工具也可以用于获取其他信息来源,例如下面用 AI SDK 构建的天气工具:
javascript
``
1. import { tool as createTool } from 'ai';
2. import { z } from 'zod';
4. import { WeatherResponse } from '../model/weather.model';
6. export const weatherTool = createTool({
7. description:
8. 'Display the weather for a holiday location',
9. parameters: z.object({
10. location: z.string().describe('The location to get the weather for')
11. }),
12. execute: async function ({ location }) {
13. // While a historical forecast may be better, this example gets the next 3 days
14. const url = `https://api.weatherapi.com/v1/forecast.json?q=${location}&days=3&key=${process.env.WEATHER_API_KEY}`;
16. try {
17. const response = await fetch(url);
18. const weather : WeatherResponse = await response.json();
19. return {
20. location: location,
21. condition: weather.current.condition.text,
22. condition_image: weather.current.condition.icon,
23. temperature: Math.round(weather.current.temp_c),
24. feels_like_temperature: Math.round(weather.current.feelslike_c),
25. humidity: weather.current.humidity
26. };
27. } catch(e) {
28. console.error(e);
29. return {
30. message: 'Unable to obtain weather information',
31. location: location
32. };
33. }
34. }
35. });
``AI写代码无论使用何种框架,工具包含以下内容:
-
描述工具的功能,以告知 LLM
-
函数期望的参数及其数据类型,这里使用 Typescript 验证库 zod 定义
-
当使用工具时由 LLM 调用的函数
如果 LLM 支持工具调用,它可以选择调用一个或多个工具来解决问题。我在构建自己的多工具 AI agent 时讨论过模型选择的经验。在选择模型时,重要的是调查工具调用支持的程度,可以使用 Hugging Face Open LLM Leaderboard 或 Berkeley Function-Calling Leaderboard 等资源。问题在于,由于 LLM 决定哪些工具与目标相关,它可能会被多个工具混淆,调用无关工具,如 Drew Breunig 所讨论的。Parmanayakam 等人在 2024 年的论文中也讨论了工具混淆的概念,发现当 Llama 3.1 8b 提供更少工具(19 个 vs 46 个)时,其性能有所提升。
优化可用工具数量是一个开放的研究领域。可以通过应用 RAG 架构来应对工具混淆,例如在 MCP 中检索工具描述以优化工具选择,从而向 LLM 提供相关工具描述,获得更准确的结果。
结论
本文介绍了上下文工程的概念,并概述了上下文的关键组成部分。如果你想了解更多,请参考以下资源:
-
《The New Skill in AI is Not Prompting, It's Context Engineering》| Philipp Schmid
-
《12-Factor Agents - Principles for building reliable LLM applications》| Dexter Horthy
-
《The Prompt Report: A Systematic Survey of Prompt Engineering Techniques》| Schulhoff et al.
-
《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》| Wei et al.
-
《Less is More: Optimizing Function Calling for LLM Execution on Edge Devices》| Paramanayakam et al.