大家好,我是热爱编程,热衷分享的"一只韩非子 "。
关注微信公众号:
会编程的韩非子添加微信号:
Hanfz0712免费加入
问答群/知识交流群,一起交流技术难题与AI未来,与你在编程学习路上同行,让我们Geek起来!
Github 地址:
官方文档地址:
1.框架简介
1.1 介绍
Spring AI Alibaba(SAA) 是一款以 Spring AI 为基础,深度集成百炼平台,支持 ChatBot、工作流、多智能体应用开发模式的 AI 框架。
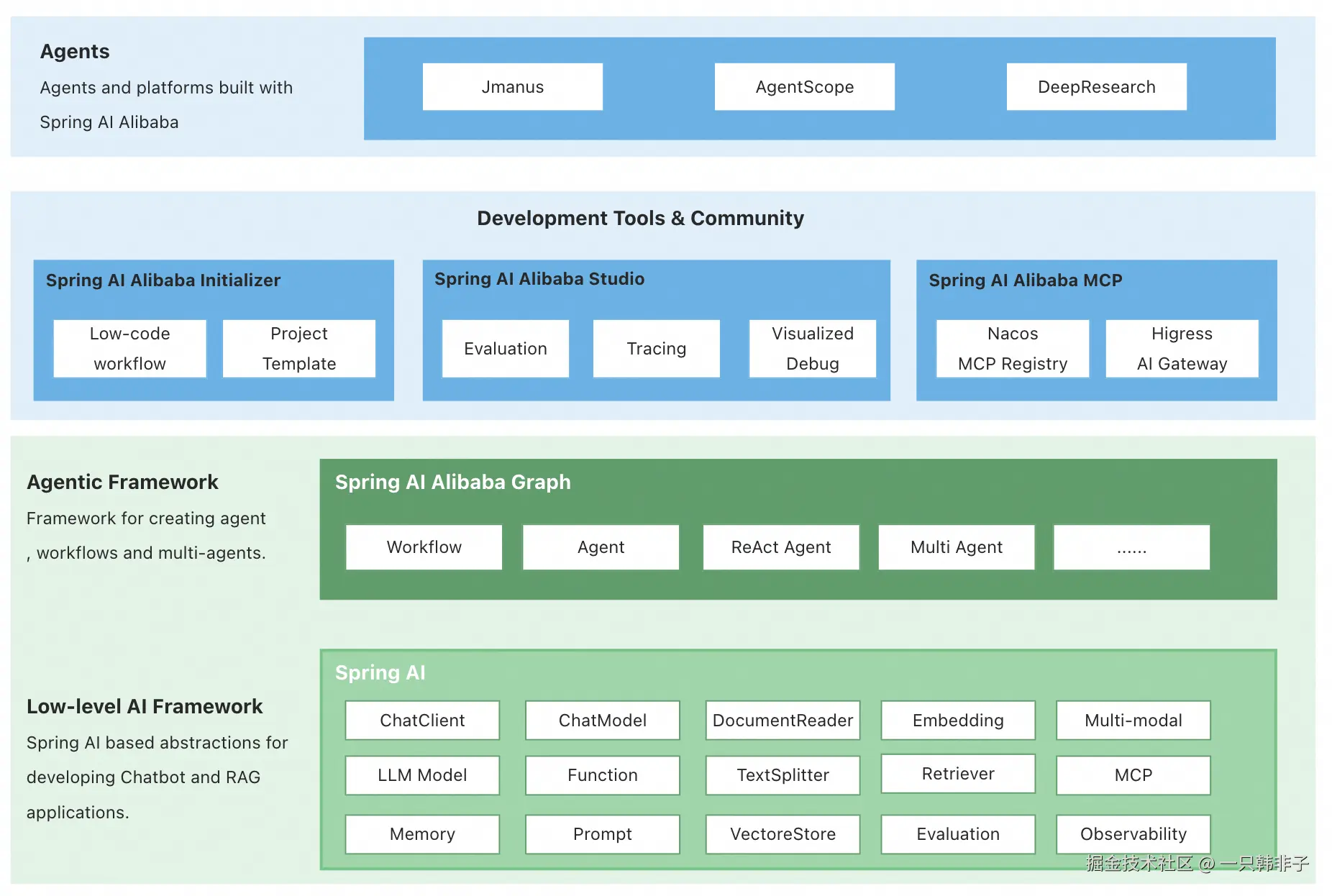
在 1.0 版本中,Spring AI Alibaba 提供以下核心能力,让开发者可以快速构建自己的 Agent、Workflow 或 Multi-agent 应用。
- Graph 多智能体框架。 基于 Spring AI Alibaba Graph 开发者可快速构建工作流、多智能体应用,无需关心流程编排、上下文记忆管理等底层实现。通过 Graph 与低代码、自规划智能体结合,为开发者提供从低代码、高代码到零代码构建智能体的更灵活选择。
- 通过 AI 生态集成,解决企业智能体落地过程中关心的痛点问题。 Spring AI Alibaba 支持与百炼平台深度集成,提供模型接入、RAG知识库解决方案;支持 ARMS、Langfuse 等可观测产品无缝接入;支持企业级的 MCP 集成,包括 Nacos MCP Registry 分布式注册与发现、自动 Router 路由等。
- 探索具备自主规划能力的通用智能体产品与平台。 社区发布了基于 Spring AI Alibaba 框架实现的 JManus 智能体,除了对标 OpenManus 的通用智能体能力外,我们的目标是基于 JManus 探索自主规划在智能体开发方向的应用,为开发者提供从低代码、高代码到零代码构建智能体的更灵活选择。
1.2 与 Spring AI 的联系与区别
Spring AI 是 Spring 官方社区维护的开源框架,最初于 2024 年 5 月发布首个 Milestone 版本,在 2025 年 5 月正式发布首个 1.0 GA 版本。Spring AI 侧重 AI 能力构建的底层原子能力抽象以及与 Spring Boot 生态的无缝集成,如模型通信(ChatModel)、提示词(Prompt)、检索增强生成(RAG)、记忆(ChatMemory)、工具(Tool)、模型上下文协议(MCP)等,帮助 Java 开发者快速构建 AI 应用。
自 2024 年 9 月正式开源以来,Spring AI Alibaba 一直与 Spring AI 社区有深度沟通合作,期间发布了多个 Milestone 版本并与很多企业客户建立的深度合作关系。在交流过程中,我们看到了低代码开发模式的优势与限制,随着业务复杂度提升客户从聊天机器人、单智能体到对多智能体架构方案的诉求,也看到了智能体开发从简单 Demo 走向生产上线过程中遇到的困难。
2.调研目的
随着公司 AI 业务的持续推进,目前已在 通用对话、上下文记忆、教案与课件生成 等场景中形成初步落地。随着业务需求日益复杂和多样化,为进一步拓展应用的深度与广度,本次调研将聚焦于 Spring AI Alibaba,并从以下几个方面展开:
- 评估 Spring AI Alibaba 在 AI 业务场景下的优势,验证其是否能提升开发效率 与系统稳定性。
- 调研 Spring AI Alibaba 在 AI 业务场景下的开发模式 ,全面了解其功能特性与能力边界,为部门后续持续推进 AI 业务提供技术参考,并支撑相关功能的快速集成落地。
- 调研基于 Spring AI Alibaba Graph 的多智能体工作流与协作能力,分析其在业务演进至 多智能体研究 阶段的支撑作用。
3.核心概念
这里介绍 Spring AI 框架使用的核心概念。建议仔细阅读,以了解框架实现背后的思想。
3.1 模型(Model)
AI 模型是旨在处理和生成信息的算法,通常模仿人类的认知功能。通过从大型数据集中学习模式和见解,这些模型可以做出预测、文本、图像或其他输出,从而增强各个行业的各种应用。
AI 模型有很多种,每种都适用于特定的用例。虽然 ChatGPT 及其生成 AI 功能通过文本输入和输出吸引了用户,但许多模型和公司都提供不同的输入和输出。在 ChatGPT 之前,许多人都对文本到图像的生成模型着迷,例如 Midjourney 和 Stable Diffusion。
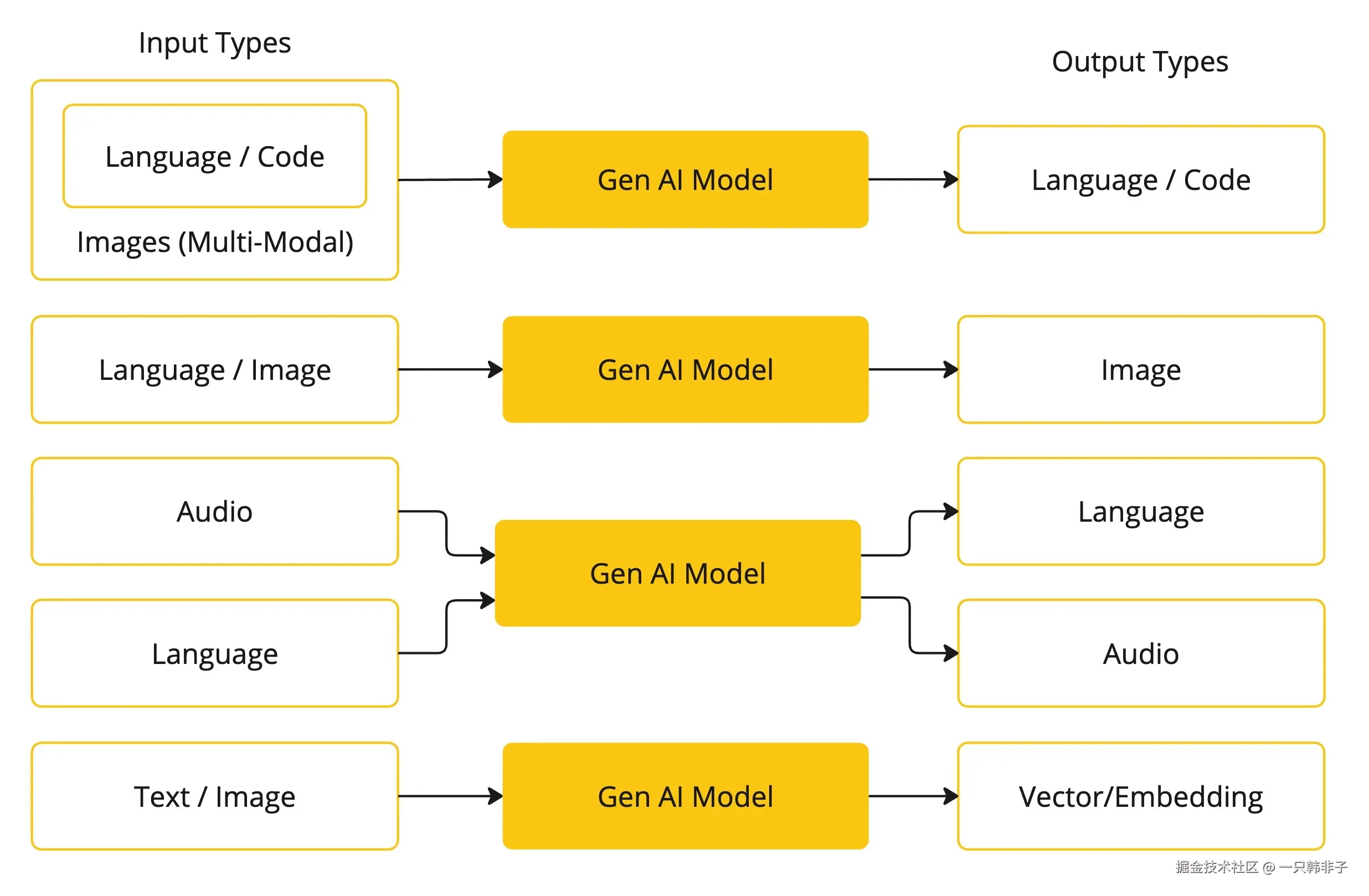
Spring AI 目前支持以语言、图像和音频形式处理输入和输出的模型。上表中的最后一行接受文本作为输入并输出数字,通常称为嵌入文本(Embedding Text),用来表示 AI 模型中使用的内部数据结构。Spring AI 提供了对 Embedding 的支持以支持开发更高级的应用场景。
GPT 等模型的独特之处在于其预训练特性,正如 GPT 中的"P"所示------Chat Generative Pre-trained Transformer。这种预训练功能将 AI 转变为通用的开发工具,开发者使用这种工具不再需要广泛的机器学习或模型训练背景。
3.2 提示(Prompt)
Prompt作为语言基础输入的基础,指导AI模型生成特定的输出。对于熟悉ChatGPT的人来说,Prompt似乎只是输入到对话框中的文本,然后发送到API。然而,它的内涵远不止于此。在许多AI模型中,Prompt的文本不仅仅是一个简单的字符串。
ChatGPT的API包含多个文本输入,每个文本输入都有其角色。例如,系统角色用于告知模型如何行为并设定交互的背景。还有用户角色,通常是来自用户的输入。
撰写有效的Prompt既是一门艺术,也是一门科学。ChatGPT旨在模拟人类对话,这与使用SQL"提问"有很大的区别。与AI模型的交流就像与另外一个人对话一样。
这种互动风格的重要性使得"Prompt工程"这一学科应运而生。现在有越来越多的技术被提出,以提高Prompt的有效性。投入时间去精心设计Prompt可以显著改善生成的输出。
分享Prompt已成为一种共同的实践,且正在进行积极的学术研究。例如,最近的一篇研究论文发现,最有效的Prompt之一可以以"深呼吸一下,分步进行此任务"开头。这表明语言的重要性之高。我们尚未完全了解如何充分利用这一技术的前几代版本,例如ChatGPT 3.5,更不用说正在开发的新版本了。
提示词模板(Prompt Template)
创建有效的Prompt涉及建立请求的上下文,并用用户输入的特定值替换请求的部分内容。这个过程使用传统的基于文本的模板引擎来进行Prompt的创建和管理。Spring AI采用开源库StringTemplate来实现这一目的。
例如,考虑以下简单的Prompt模板:
css
Tell me a {adjective} joke about {content}.在Spring AI中,Prompt模板可以类比于Spring MVC架构中的"视图"。一个模型对象,通常是java.util.Map,提供给Template,以填充模板中的占位符。渲染后的字符串成为传递给AI模型的Prompt的内容。
传递给模型的Prompt在具体数据格式上有相当大的变化。从最初的简单字符串开始,Prompt逐渐演变为包含多条消息的格式,其中每条消息中的每个字符串代表模型的不同角色。
3.3 嵌入(Embedding)
嵌入(Embedding)是文本、图像或视频的数值表示,能够捕捉输入之间的关系,Embedding通过将文本、图像和视频转换为称为向量(Vector)的浮点数数组来工作。这些向量旨在捕捉文本、图像和视频的含义,Embedding数组的长度称为向量的维度。
通过计算两个文本片段的向量表示之间的数值距离,应用程序可以确定用于生成嵌入向量的对象之间的相似性。
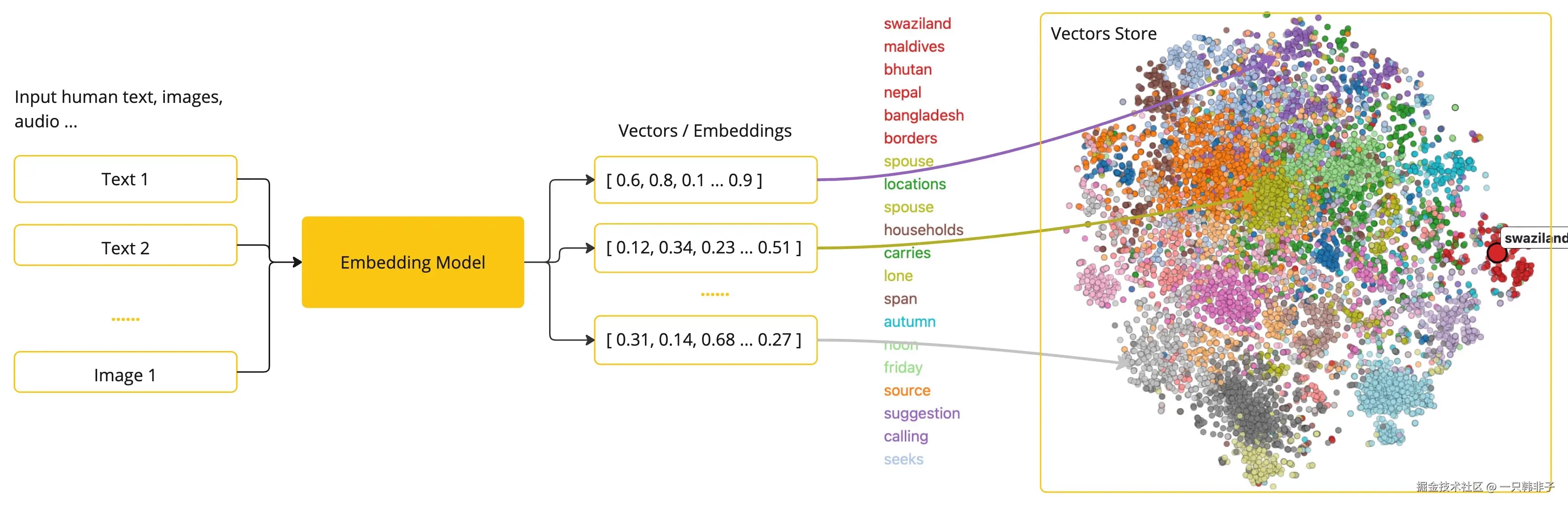
作为一名探索人工智能的Java开发者,理解这些向量表示背后的复杂数学理论或具体实现并不是必需的。对它们在人工智能系统中的作用和功能有基本的了解就足够了,尤其是在将人工智能功能集成到您的应用程序中时。
Embedding在实际应用中,特别是在检索增强生成(RAG)模式中,具有重要意义。它们使数据能够在语义空间中表示为点,这类似于欧几里得几何的二维空间,但在更高的维度中。这意味着,就像欧几里得几何中平面上的点可以根据其坐标的远近关系而接近或远离一样,在语义空间中,点的接近程度反映了意义的相似性。关于相似主题的句子在这个多维空间中的位置较近,就像图表上彼此靠近的点。这种接近性有助于文本分类、语义搜索,甚至产品推荐等任务,因为它允许人工智能根据这些点在扩展的语义空间中的"位置"来辨别和分组相关概念。
您可以将这个语义空间视为一个向量。
3.4 Token
token是 AI 模型工作原理的基石。输入时,模型将单词转换为token。输出时,它们将token转换回单词。
在英语中,一个token大约对应一个单词的 75%。作为参考,莎士比亚的全集总共约 90 万个单词,翻译过来大约有 120 万个token。

也许更重要的是 "token = 金钱"。在托管 AI 模型的背景下,您的费用由使用的token数量决定。输入和输出都会影响总token数量。
此外,模型还受到 token 限制,这会限制单个 API 调用中处理的文本量。此阈值通常称为"上下文窗口"。模型不会处理超出此限制的任何文本。
例如,ChatGPT3 的token限制为 4K,而 GPT4 则提供不同的选项,例如 8K、16K 和 32K。Anthropic 的 Claude AI 模型的token限制为 100K,而 Meta 的最新研究则产生了 1M token限制模型。
要使用 GPT4 总结莎士比亚全集,您需要制定软件工程策略来切分数据并在模型的上下文窗口限制内呈现数据。Spring AI 项目可以帮助您完成此任务。
3.5 结构化输出(Structured Output)
即使您要求回复为 JSON ,AI 模型的输出通常也会以 java.lang.String 的形式出现。它可能是正确的 JSON,但它可能并不是你想要的 JSON 数据结构,它只是一个字符串。此外,在提示词 Prompt 中要求 "返回JSON" 并非 100% 准确。
这种复杂性导致了一个专门领域的出现,涉及创建 Prompt 以产生预期的输出,然后将生成的简单字符串转换为可用于应用程序集成的数据结构。
结构化输出转换采用精心设计的提示,通常需要与模型进行多次交互才能实现所需的格式。
3.6 将您的数据和 API 引入 AI 模型
如何让人工智能模型与不在训练集中的数据一同工作?
请注意,GPT 3.5/4.0 数据集仅支持截止到 2021 年 9 月之前的数据。因此,该模型表示它不知道该日期之后的知识,因此它无法很好的应对需要用最新知识才能回答的问题。一个有趣的小知识是,这个数据集大约有 650GB。
有三种技术可以定制 AI 模型以整合您的数据:
Fine Tuning微调:这种传统的机器学习技术涉及定制模型并更改其内部权重。然而,即使对于机器学习专家来说,这是一个具有挑战性的过程,而且由于 GPT 等模型的大小,它极其耗费资源。此外,有些模型可能不提供此选项。Prompt Stuffing提示词填充:一种更实用的替代方案是将您的数据嵌入到提供给模型的提示中。考虑到模型的令牌限制,我们需要具备过滤相关数据的能力,并将过滤出的数据填充到在模型交互的上下文窗口中,这种方法俗称"提示词填充"。Spring AI 库可帮助您基于"提示词填充" 技术,也称为检索增强生成 (RAG) 实现解决方案。
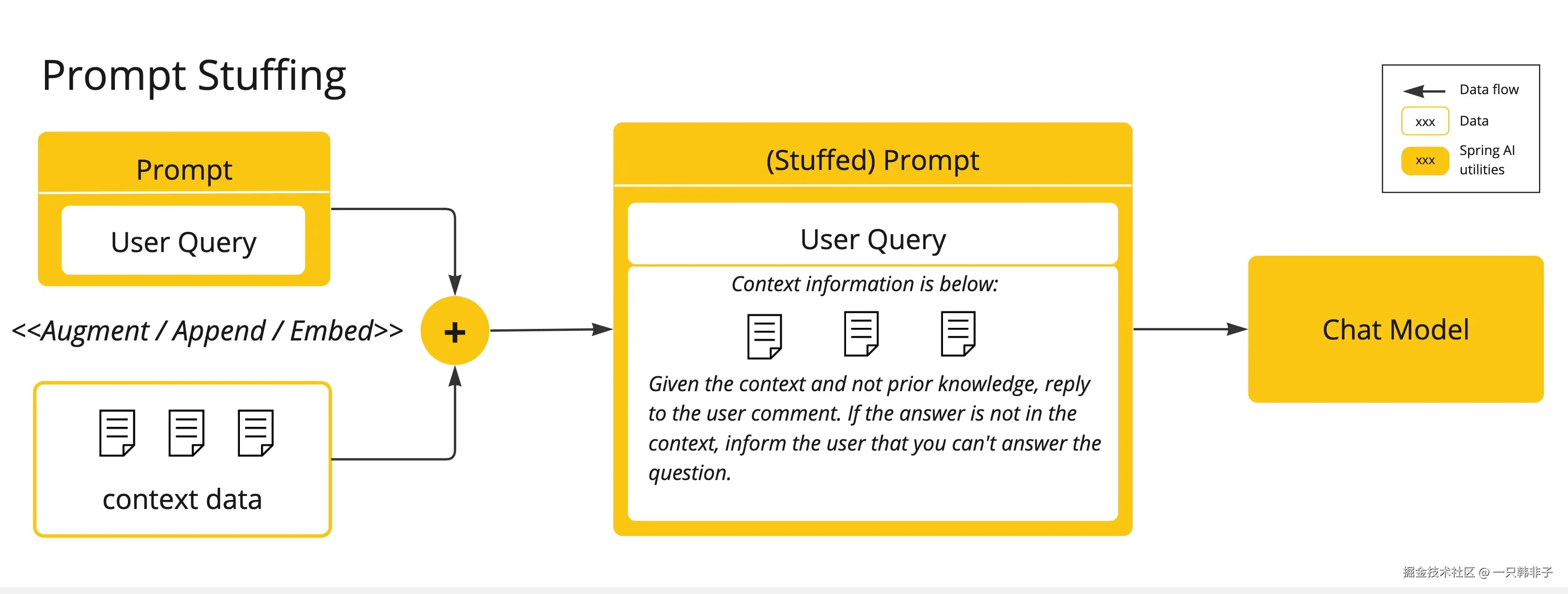
- Function Calling :此技术允许注册自定义的用户函数,将大型语言模型连接到外部系统的 API。Spring AI 大大简化了支持函数调用所需编写的代码。
3.6.1 检索增强生成(RAG)
一种称为检索增强生成 (RAG) 的技术已经出现,旨在解决为 AI 模型提供额外的知识输入,以辅助模型更好的回答问题。
该方法涉及批处理式的编程模型,其中涉及到:从文档中读取非结构化数据、对其进行转换、然后将其写入矢量数据库。从高层次上讲,这是一个 ETL(提取、转换和加载)管道。矢量数据库则用于 RAG 技术的检索部分。
在将非结构化数据加载到矢量数据库的过程中,最重要的转换之一是将原始文档拆分成较小的部分。将原始文档拆分成较小部分的过程有两个重要步骤:
- 将文档拆分成几部分,同时保留内容的语义边界。例如,对于包含段落和表格的文档,应避免在段落或表格中间拆分文档;对于代码,应避免在方法实现的中间拆分代码。
- 将文档的各部分进一步拆分成大小仅为 AI 模型令牌 token 限制的一小部分的部分。
RAG 的下一个阶段是处理用户输入。当用户的问题需要由 AI 模型回答时,问题和所有"类似"的文档片段都会被放入发送给 AI 模型的提示中。这就是使用矢量数据库的原因,它非常擅长查找具有一定相似度的"类似"内容。
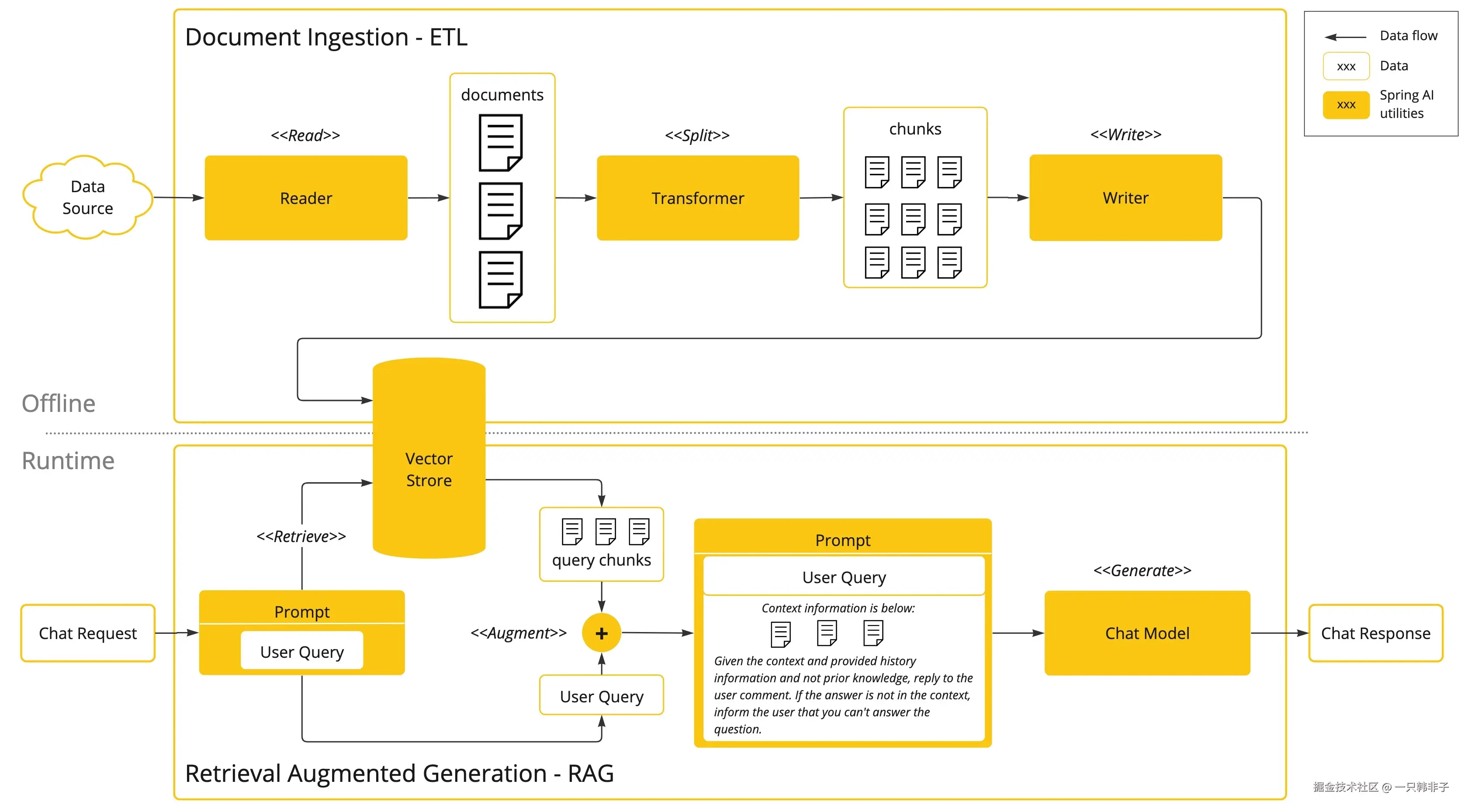
- ETL 管道 提供了有关协调从数据源提取数据并将其存储在结构化向量存储中的流程的更多信息,确保在将数据传递给 AI 模型时数据具有最佳的检索格式。
- ChatClient - RAG 解释了如何使用
QuestionAnswerAdvisorAdvisor 在您的应用程序中启用 RAG 功能。
3.6.2 函数调用(Function Calling)
大型语言模型 (LLM) 在训练后即被冻结,导致知识陈旧,并且无法访问或修改外部数据。
Function Calling 机制解决了这些缺点,它允许您注册自己的函数,以将大型语言模型连接到外部系统的 API。这些系统可以为 LLM 提供实时数据并代表它们执行数据处理操作。
Spring AI 大大简化了您需要编写的代码以支持函数调用。它为您处理函数调用对话。您可以将函数作为提供,@Bean然后在提示选项中提供该函数的 bean 名称以激活该函数。此外,您可以在单个提示中定义和引用多个函数。
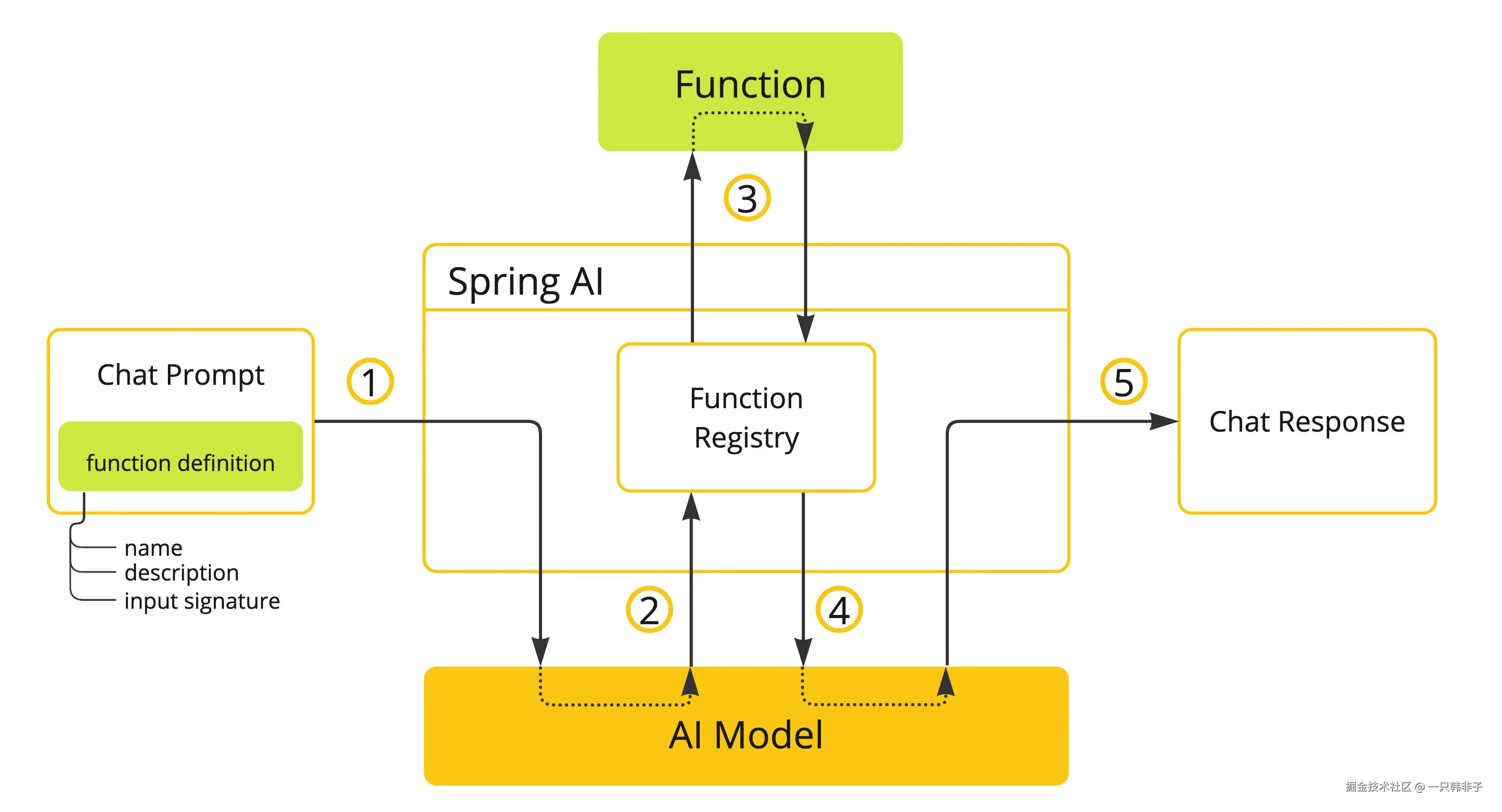
- (1)执行聊天请求并发送函数定义信息。后者提供
name(description例如,解释模型何时应调用该函数)和input parameters(例如,函数的输入参数模式)。 - (2)当模型决定调用该函数时,它将使用输入参数调用该函数,并将输出返回给模型。
- (3)Spring AI 为您处理此对话。它将函数调用分派给适当的函数,并将结果返回给模型。
- (4)模型可以执行多个函数调用来检索所需的所有信息。
- (5)一旦获取了所有需要的信息,模型就会生成响应。
请关注函数调用文档以获取有关如何在不同 AI 模型中使用此功能的更多信息。
3.7 评估人工智能的回答(Evaluation)
有效评估人工智能系统回答的正确性,对于确保最终应用程序的准确性和实用性非常重要,一些新兴技术使得预训练模型本身能够用于此目的。
Evaluation 评估过程涉及分析响应是否符合用户的意图、与查询的上下文强相关,一些指标如相关性、连贯性和事实正确性等都被用于衡量 AI 生成的响应的质量。
一种方法是把用户的请求、模型的响应一同作为输入给到模型服务,对比模型给的响应或回答是否与提供的响应数据一致。
此外,利用矢量数据库(Vector Database)中存储的信息作为补充数据可以增强评估过程,有助于确定响应的相关性。
4.功能清单
4.1 支持 Spring AI 所有核心功能:
- 提示(Prompt)
- 模型增强(The Augmented LLM)
- 顾问(Advisors)
- 检索(Retrieval)
- 记忆(ChatMemory)
- 工具(Tool)
- 评估(Evaluation)
- 可观测性(Observability)
- 模型上下文协议(MCP)
4.2 Spring AI Alibaba Graph 多智能体框架
Spring AI Alibaba Graph 是社区核心实现之一,也是整个框架在设计理念上区别于 Spring AI 只做底层原子抽象的地方,Spring AI Alibaba 期望帮助开发者更容易的构建智能体应用。基于 Graph 开发者可以构建工作流、多智能体应用。Spring AI Alibaba Graph 在设计理念上借鉴 Langgraph,因此在一定程度上可以理解为是 Java 版的 Langgraph 实现,社区在此基础上增加了大量预置 Node、简化了 State 定义过程等,让开发者更容易编写对等低代码平台的工作流、多智能体等。
Spring AI Alibaba Graph 核心能力:
- 支持 Multi-agent,内置 ReAct Agent、Supervisor 等常规智能体模式
- 支持工作流,内置工作流节点,与主流低代码平台对齐
- 原生支持 Streaming
- Human-in-the-loop,通过人类确认节点,支持修改状态、恢复执行
- 支持记忆与持久存储
- 支持流程快照
- 支持嵌套分支、并行分支
- PlantUML、Mermaid 可视化导出
5.使用教程
5.1 ChatClient
5.1.1 ChatClient 简介
ChatClient 提供了与 AI 模型通信的 Fluent API,它支持同步和反应式(Reactive)编程模型。与 ChatModel、Message、ChatMemory 等原子 API 相比,使用 ChatClient 可以将与 LLM 及其他组件交互的复杂性隐藏在背后,因为基于 LLM 的应用程序通常要多个组件协同工作(例如,提示词模板、聊天记忆、LLM Model、输出解析器、RAG 组件:嵌入模型和存储),并且通常涉及多个交互,因此协调它们会让编码变得繁琐。当然使用 ChatModel 等原子 API 可以为应用程序带来更多的灵活性,成本就是您需要编写大量样板代码。
ChatClient 类似于应用程序开发中的服务层,它为应用程序直接提供 AI 服务,开发者可以使用 ChatClient Fluent API 快速完成一整套 AI 交互流程的组装。
包括一些基础功能,如:
- 定制和组装模型的输入(Prompt)
- 格式化解析模型的输出(Structured Output)
- 调整模型交互参数(ChatOptions)
还支持更多高级功能:
- 聊天记忆(Chat Memory)
- 工具/函数调用(Function Calling)
- RAG
5.1.2 ChatClient 创建
5.1.2.1 使用自动配置的
如果你的应用中只会用到一个模型,那么就可以只用自动配置的,不需要手动去创建。
第一步导入依赖文件
你需要导入 spring-ai-alibaba 的 bom 文件和对应模型的依赖。
以阿里云百炼平台中的模型为例:
xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 阿里云百炼平台模型依赖 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>1.0.0.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>第二步编辑配置文件
yaml
spring:
ai:
dashscope:
api-key: 你的apiKey
chat:
options:
model: qwen-plus这里我们需要获取 阿里云百炼平台的 apiKey 和对应模型名称
**获取 apiKey 的地址:
如何获取API Key_大模型服务平台百炼(Model Studio)-阿里云帮助中心
****获取模型名称的地址:
**模型列表与价格_大模型服务平台百炼(Model Studio)-阿里云帮助中心
第三步使用
kotlin
@RestController
public class ChatController {
private final ChatClient chatClient;
public ChatController(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@GetMapping("/chat")
public String chat(String input) {
return this.chatClient.prompt()
.user(input)
.call()
.content();
}
}第四步查看效果

至此,我们已经完成了第一次 ChatClient 的使用,并且使用的是阿里云百炼平台的模型,如果你想使用其他厂商的模型,如 DeepSeek 官方模型,那么可以按照下面的方式使用:
第一步,你需要导入 spirng-ai 的 bom,以及对应厂商的模型
xml
<dependencies>
其他配置......
<!-- DeepSeek模型依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!-- Spring-ai-bom -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>1.0.0.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>第二步,配置对应的配置文件
yaml
spring:
ai:
deepseek:
base-url: https://api.deepseek.com
api-key: 你的apiKey
chat:
options:
model: deepseek-chat需要去对应厂商文档中获取 baseUrl、apiKey、model
DeepSeek 获取 baseUrl 的地址为:
获取 apiKey 的地址为:
platform.deepseek.com/api_keys
获取 model 的地址为:
api-docs.deepseek.com/zh-cn/quick...
第三步、第四步使用就和之前的一致了
5.1.2.2 使用编程方式创建的
如果你的应用中存在多个模型共同调用,就需要手动创建 ChatClient 了。
首先需要设置属性 spring.ai.chat.client.enabled=false 来禁用 ChatClient.Builder bean 的自动配置。然后以编程方式创建 ChatClient.Builder,这样可以为每个聊天模型创建一个实例 ChatModel:
kotlin
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.deepseek.DeepSeekChatModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatController {
private final ChatClient dashScopeChatClient;
private final ChatClient deepSeekChatClient;
public ChatController(DashScopeChatModel dashScopeChatModel, DeepSeekChatModel deepSeekChatModel) {
this.dashScopeChatClient = ChatClient.builder(dashScopeChatModel).build();
this.deepSeekChatClient = ChatClient.builder(deepSeekChatModel).build();
}
@GetMapping(value = "/dash-scope", name = "dashScope客户端")
public String chatByDashScope(String input) {
return this.dashScopeChatClient.prompt()
.user(input)
.call()
.content();
}
@GetMapping(value = "/deep-seek", name = "deepSeek客户端")
public String chatByDeepSeek(String input) {
return this.deepSeekChatClient.prompt()
.user(input)
.call()
.content();
}
}5.1.3 处理 ChatClient 的响应
ChatClient API 提供了多种方法来格式化来自 AI 模型的响应。
5.1.3.1 返回 ChatResponse
AI 模型的响应是一种由ChatResponse类型定义的丰富结构。它包含响应生成相关的元数据,同时它还可以包含多个子响应(称为Generation),每个子响应都有自己的元数据。元数据包括用于创建响应的令牌(token)数量信息(在英文中,每个令牌大约为一个单词的 3/4),了解令牌信息很重要,因为 AI 模型根据每个请求使用的令牌数量收费。
下面的代码段显示了通过调用 chatResponse() 返回 ChatResponse 的示例,相比于调用 content() 方法,这里在调用 call() 方法之后调用 chatResponse()。
scss
ChatResponse chatResponse = chatClient.prompt()
.user("你是谁")
.call()
.chatResponse();5.1.3.2 返回实体类(Entity)
您经常希望返回一个预先定义好的实体类型响应,Spring AI 框架可以自动替我们完成从 String 到实体类的转换,调用entity() 方法可完成响应数据转换。
例如,给定 Java record(POJO)定义:
arduino
record ActorFilms(String title, String author, Integer year) {
}您可以使用该 entity 方法轻松地将 AI 模型的输出映射到 ActorFilms 类型,如下所示:
scss
ActorFilms actorFilms = chatClient.prompt()
.user("推荐一本计算机专业最推荐的书")
.call()
.entity(ActorFilms.class);entity 还有一种带有参数的重载方法 entity(ParameterizedTypeReference<T> type),可让您指定如泛型 List 等类型:
scss
List<ActorFilms> actorFilms = chatClient.prompt()
.user("Generate the filmography of 5 movies for Tom Hanks and Bill Murray.")
.call()
.entity(new ParameterizedTypeReference<List<ActorFilms>>() {
});5.1.3.3 流式响应
stream 方法是一种异步的、持续的获得模型响应的方式:
scss
Flux<String> output = chatClient.prompt()
.user("你是谁")
.stream()
.content();相比于上面的 Flux<String>,您还可以使用 Flux<ChatResponse> chatResponse() 方法获得 ChatResponse 响应数据流。
5.1.4 定制 ChatClient 默认值
5.1.4.1 设置默认 System Message
我们可以创建一个配置类,构建对应的 ChatClient,构建的时候指定 defaultSystem,然后构建出来的类交给 Bean 管理,这样子就可以直接引用这个 Bean,并使用默认的设置。
kotlin
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.deepseek.DeepSeekChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ChatBuilderConfig {
@Bean
public ChatClient deepChatClient(DeepSeekChatModel deepSeekChatModel) {
return ChatClient.builder(deepSeekChatModel)
.defaultSystem("以海盗风格回答所有问题")
.build();
}
}使用这个 Bean
less
@RestController
@RequestMapping("/default")
public class DefaultChatController {
@Resource
private ChatClient deepChatClient;
@GetMapping("/chat")
public String chat(String input) {
return deepChatClient.prompt()
.user(input)
.call()
.content();
}
}查看效果

如果你的提示词中需要传递一些参数也是可以的。如:
在设置默认 defaultSystem 的时候,用{}挖空
kotlin
@Configuration
public class ChatBuilderConfig {
@Bean
public ChatClient deepChatClient(DeepSeekChatModel deepSeekChatModel) {
return ChatClient.builder(deepSeekChatModel)
.defaultSystem("以海盗风格回答所有问题,你的角色是{role}")
.build();
}
}使用的时候传递参数
less
@RestController
@RequestMapping("/default")
public class DefaultChatController {
@Resource
private ChatClient deepChatClient;
@GetMapping("/chat")
public String chat(String input) {
return deepChatClient.prompt()
.system(sys -> sys.param("role", "杰克船长"))
.user(input)
.call()
.content();
}
}查看效果

5.1.4.2 其他设置
除了 defaultSystem 之外,您还可以在 ChatClient.Builder 级别上指定其他默认提示。
defaultOptions(ChatOptions chatOptions):传入ChatOptions类中定义的可移植选项或特定于模型实现的如DashScopeChatOptions选项。有关特定于模型的ChatOptions实现的更多信息,请参阅 JavaDocs。defaultFunction(String name, String description, java.util.function.Function<I, O> function):name用于在用户文本中引用该函数,description解释该函数的用途并帮助 AI 模型选择正确的函数以获得准确的响应,参数function是模型将在必要时执行的 Java 函数实例。defaultFunctions(String... functionNames):应用程序上下文中定义的 java.util.Function 的 bean 名称。defaultUser(String text)、defaultUser(Resource text)、defaultUser(Consumer<UserSpec> userSpecConsumer)这些方法允许您定义用户消息输入,Consumer<UserSpec>允许您使用 lambda 指定用户消息输入和任何默认参数。defaultAdvisors(RequestResponseAdvisor... advisor):Advisors 允许修改用于创建Prompt的数据,QuestionAnswerAdvisor实现通过在 Prompt 中附加与用户文本相关的上下文信息来实现Retrieval Augmented Generation模式。defaultAdvisors(Consumer<AdvisorSpec> advisorSpecConsumer):此方法允许您定义一个Consumer并使用AdvisorSpec配置多个 Advisor,Advisor 可以修改用于创建Prompt的最终数据,Consumer<AdvisorSpec>允许您指定 lambda 来添加 Advisor 例如QuestionAnswerAdvisor。
您可以在运行时使用 ChatClient 提供的不带 default 前缀的相应方法覆盖这些默认值。
options(ChatOptions chatOptions)function(String name, String description, java.util.function.Function<I, O> function)functions(String... functionNames)user(String text)、user(Resource text)、user(Consumer<UserSpec> userSpecConsumer)advisors(RequestResponseAdvisor... advisor)advisors(Consumer<AdvisorSpec> advisorSpecConsumer)
5.1.5 检索增强生成(RAG)
向量数据库存储的是 AI 模型不知道的数据,当用户问题被发送到 AI 模型时,QuestionAnswerAdvisor 会在向量数据库中查询与用户问题相关的文档。
来自向量数据库的响应被附加到用户消息 Prompt 中,为 AI 模型生成响应提供上下文。
假设您已将数据加载到中 VectorStore,则可以通过向 ChatClient 提供 QuestionAnswerAdvisor 实例来执行检索增强生成 (RAG ) 。
scss
ChatResponse response = ChatClient.builder(chatModel)
.build().prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults()))
.user(userText)
.call()
.chatResponse();在此示例中,SearchRequest.defaults() 将对 Vector 向量数据库中的所有文档执行相似性搜索。为了限制要搜索的文档类型,SearchRequest 采用了可移植到任意向量数据库中的类似 SQL 筛选表达式。
动态过滤表达式
SearchRequest 使用 FILTER_EXPRESSION Advisor 上下文参数在运行时更新过滤表达式:
scss
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults()))
.build();
// Update filter expression at runtime
String content = chatClient.prompt()
.user("Please answer my question XYZ")
.advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "type == 'Spring'"))
.call()
.content();该 FILTER_EXPRESSION 参数允许您根据提供的表达式动态过滤搜索结果。
5.1.6 日志记录
SimpleLoggerAdvisor 是一个用于记录 ChatClient 的 request 和 response 数据 Advisor,这对于调试和监控您的 AI 交互非常有用。
要启用日志记录,请在创建 ChatClient 时将 SimpleLoggerAdvisor 添加到 Advisor 链中。建议将其添加到链的末尾:
scss
ChatResponse response = ChatClient.create(chatModel).prompt()
.advisors(new SimpleLoggerAdvisor())
.user("Tell me a joke?")
.call()
.chatResponse();要查看日志,请将 Advisor 包的日志记录级别设置为 DEBUG:
ini
org.springframework.ai.chat.client.advisor=DEBUG将其添加到您的 application.properties 或 application.yaml 文件中。
您可以使用以下构造函数自定义如何使用 SimpleLoggerAdvisor 记录来自 AdvisedRequest 和 ChatResponse 的数据:
javascript
SimpleLoggerAdvisor(
Function<AdvisedRequest, String> requestToString,
Function<ChatResponse, String> responseToString
)使用示例:
vbscript
javaCopySimpleLoggerAdvisor customLogger = new SimpleLoggerAdvisor(
request -> "Custom request: " + request.userText,
response -> "Custom response: " + response.getResult()
);这使得您可以根据您的特定需求定制需要记录的信息。
5.2 对话记忆
大型语言模型(LLMs)是无状态的,这意味着它们不会保留关于先前交互的信息。当你希望跨多个交互维护上下文或状态时,这可能是一个限制。为了解决这个问题,Spring AI 提供了聊天记忆功能,允许你跨多个与 LLM 的交互存储和检索信息。
ChatMemory 框架允许你实现各种类型的记忆来支持不同的使用场景。消息的底层存储由 ChatMemoryRepository 处理,其唯一职责是存储和检索消息。具体保留哪些消息以及何时移除它们,则取决于 ChatMemory 的实现。策略示例可能包括保留最后 N 条消息、保留特定时间段的消息,或保留达到特定 token 限制的消息。
在选择内存类型之前,理解聊天内存和聊天历史之间的区别至关重要。
- Chat Memory。大型语言模型在整个对话过程中保留并使用的信息,以维持上下文意识。
- 聊天记录 ****。整个对话历史,包括用户和模型之间交换的所有消息。
ChatMemory 抽象是为了管理 聊天记忆 而设计的。它允许你存储和检索与当前对话上下文相关的消息。然而,它并不是存储 聊天历史 的最佳选择。如果你需要维护所有交换消息的完整记录,你应该考虑使用不同的方法,例如依靠 Spring Data 来高效地存储和检索完整的聊天历史。
5.3 多模态
人类能够同时处理多种数据输入模式的知识。我们的学习方式和经验都是多模态的。我们拥有的不仅仅是视觉、听觉和文本。
与这些原则相反,机器学习通常专注于为处理单一模态而定制的专用模型。例如,我们开发了用于文本转语音或语音转文本等任务的音频模型,以及用于对象检测和分类等任务的计算机视觉模型。
多模态性是指模型同时理解和处理来自各种来源的信息的能力,包括文本、图像、音频和其他数据格式。
Spring AI Message API 提供了支持多模式 LLM 所需的所有抽象。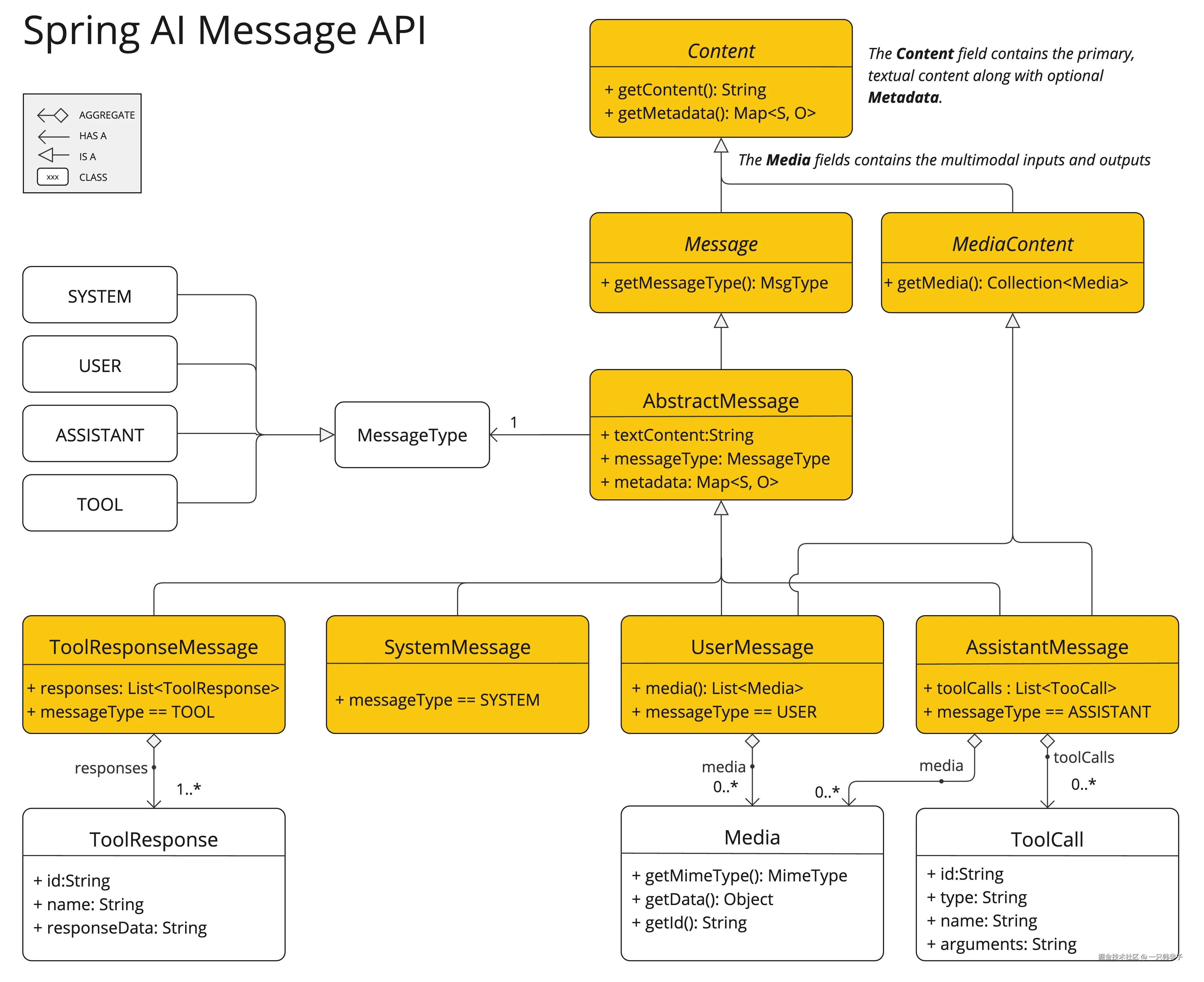
UserMessage 的 content 字段主要用于文本输入,而可选的 media 字段允许添加一个或多个不同模态的附加内容,例如图像、音频和视频。MimeType 指定模态类型。根据所使用的 LLM,Media 数据字段可以是作为资源对象的原始媒体内容,也可以是指向该内容的 URI。
media 字段目前仅适用于用户输入消息(例如 UserMessage)。它对系统消息无效。包含 LLM 响应的 AssistantMessage 仅提供文本内容。要生成非文本媒体输出,您应该使用专用的单模态模型。
例如,我们可以将下图(multimodal.test.png)作为输入,并要求 LLM 解释它所看到的内容。

对于大多数多模式 LLM,Spring AI 代码看起来像这样:
java
var imageResource = new ClassPathResource("/multimodal.test.png");
var userMessage = new UserMessage(
"Explain what do you see in this picture?",
new Media(MimeTypeUtils.IMAGE_PNG, this.imageResource));
ChatResponse response = chatModel.call(new Prompt(this.userMessage));或者使用流畅的ChatClient API:
scss
String response = ChatClient.create(chatModel).prompt()
.user(u -> u.text("Explain what do you see on this picture?")
.media(MimeTypeUtils.IMAGE_PNG, new ClassPathResource("/multimodal.test.png")))
.call()
.content();并产生如下响应:
这幅图是一个设计简约的水果碗。碗由金属制成,边缘由弯曲的金属丝构成,形成一个开放式结构,使水果从各个角度都能清晰可见。碗内,两根黄色的香蕉放在一个看起来像红色苹果的东西上面。香蕉皮上的棕色斑点表明它们略微熟透了。碗的顶部有一个金属环,可能是用作提手的。碗被放置在一个平面上,背景为中性色,可以清晰地看到里面的水果。
5.4 MCP
型上下文协议(MCP)是一种标准化协议,使 AI 模型能够以结构化的方式与外部工具和资源交互。它支持多种传输机制,以在不同环境中提供灵活性。
MCP Java SDK 提供了模型上下文协议的 Java 实现,通过同步和异步通信模式,实现与 AI 模型和工具的标准化交互。
5.4.1 MCP Java SDK 架构

- 客户端/服务器层 ****:McpClient 处理客户端操作,而 McpServer 管理服务器端协议操作。两者都使用 McpSession 进行通信管理。
- 会话层(McpSession) :通过 McpClientSession 和 McpServerSession 实现管理通信模式和状态。
- 传输层(McpTransport) :处理 JSON-RPC 消息的序列化和反序列化,支持多种传输实现。
5.4.1.2 MCP Client
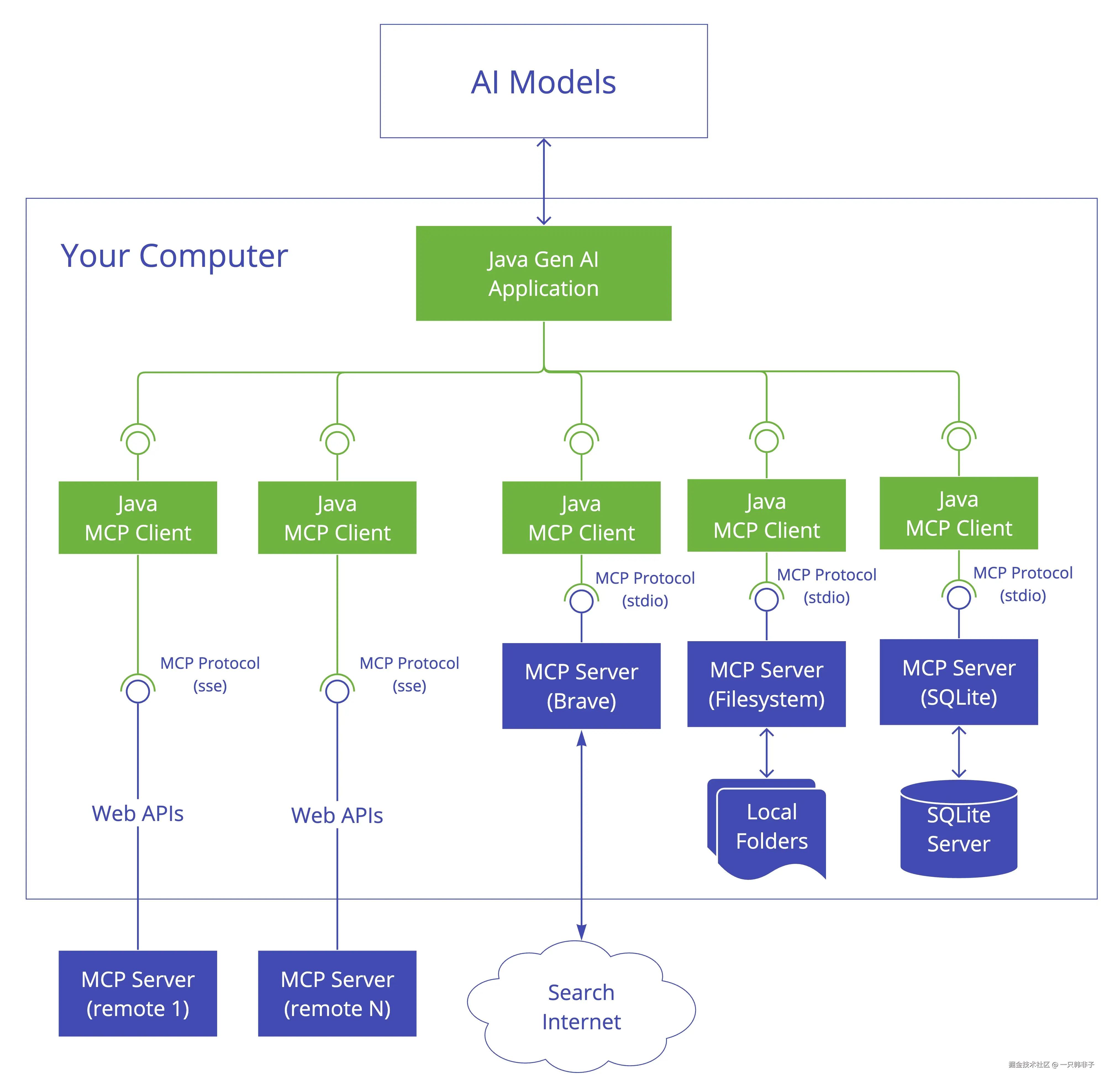
MCP 客户端是模型上下文协议(MCP)架构中的一个关键组件,负责与 MCP 服务器建立和管理连接。它实现了协议的客户端部分,处理以下内容:
- 协议版本协商以确保与服务器兼容
- 功能协商以确定可用特性
- 消息传输和 JSON-RPC 通信
- 工具发现和执行
- 资源访问和管理
- 提示系统交互
- 可选功能:
-
- 根管理
- 采样支持
- 同步和异步操作
- 传输选项:
-
- 基于标准输入输出的传输方式,用于进程间通信
- 基于 Java HttpClient 的 SSE 客户端传输
- 用于反应式 HTTP 流媒体的 WebFlux SSE 客户端传输
5.4.1.2 MCP Server
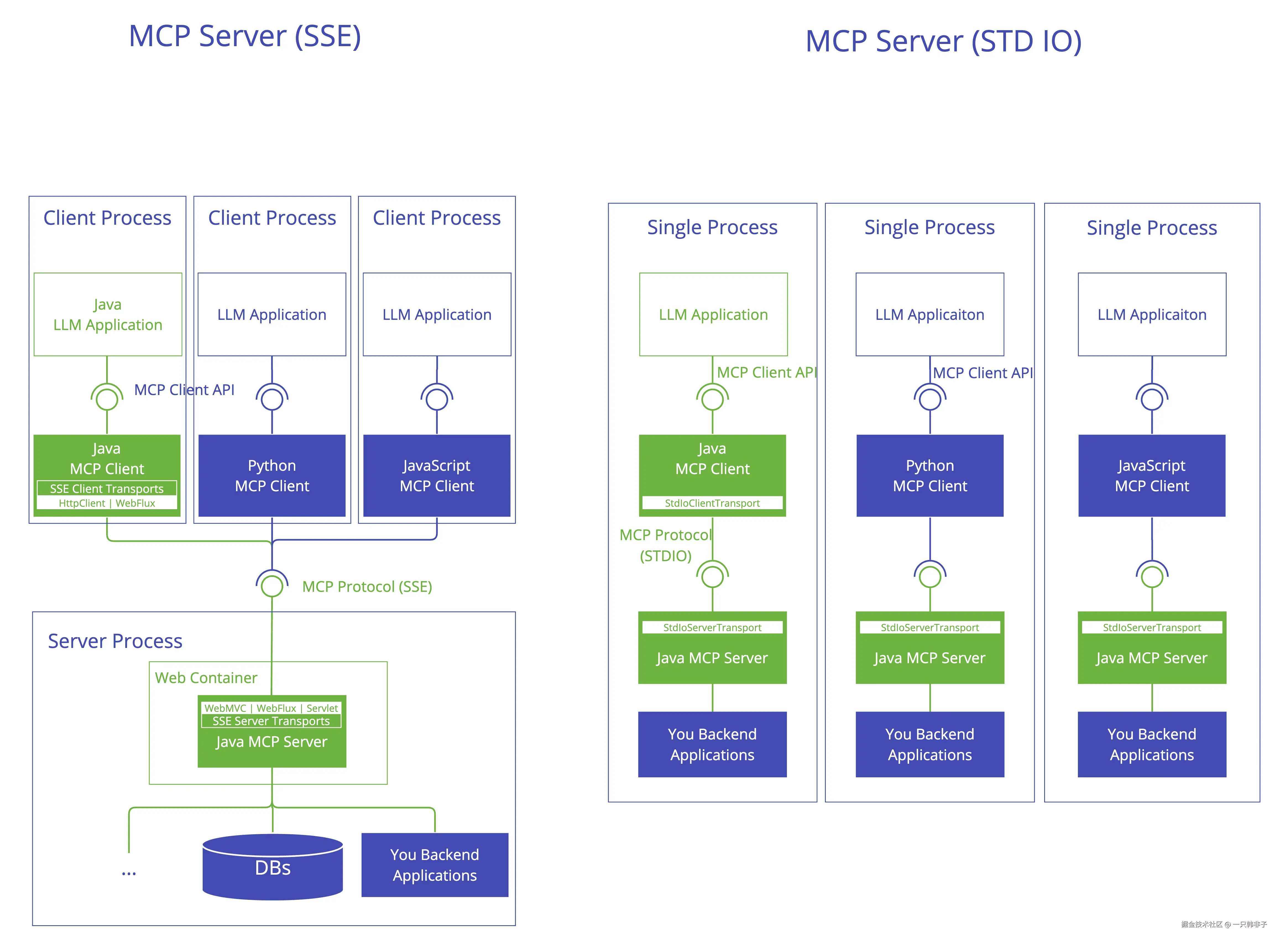
MCP 服务器是模型上下文协议(MCP)架构中的一个基础组件,为客户端提供工具、资源和功能。它实现了协议的服务器端,负责:
- 服务器端协议操作实现
-
- 工具的暴露和发现
- 基于 URI 的资源管理
- 提示模板的提供和处理
- 与客户端的协商能力
- 结构化日志记录和通知
- 并发客户端连接管理
- 同步和异步 API 支持
- 传输实现:
-
- 基于标准输入输出的传输方式,用于进程间通信
- 基于 Servlet 的 SSE 服务器传输
- WebFlux SSE 服务器传输,用于响应式 HTTP 流
- 基于 Servlet 的 HTTP 流式传输的 WebMVC SSE 服务器传输
5.4.2 搭建 MCP Server
第一步,引入依赖
构建 MCP Server 的传输方式一共有三种、分别是:STDIO、WebMVC、WebFlux。这里我们选择 WebMVC。
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
</dependency>第二 步,配置文件
yaml
# Using spring-ai-starter-mcp-server-webmvc
spring:
ai:
mcp:
server:
name: webmvc-mcp-server
version: 1.0.0
type: SYNC
instructions: "This server provides weather information tools and resources"
sse-message-endpoint: /mcp/messages
sse-endpoint: /sse
capabilities:
tool: true
resource: true
prompt: true
completion: true第三步,写一个 MCP 服务
less
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Service;
@Service
public class WeatherService {
@Tool(description = "根据城市名称获取天气")
public String getWeather(@ToolParam(description = "城市名称") String city, @ToolParam(description = "日期") String date) {
return """
日期:%s
地点:%s
天气状况:晴天转冰雹
""".formatted(city, date);
}
}第四步,将你的服务注入
typescript
import com.hanfz.service.WeatherService;
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.ai.tool.method.MethodToolCallbackProvider;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
public class SpringAiApplication {
public static void main(String[] args) {
SpringApplication.run(SpringAiApplication.class, args);
}
@Bean
public ToolCallbackProvider weatherTools(WeatherService weatherService) {
return MethodToolCallbackProvider.builder().toolObjects(weatherService).build();
}
}完成上述四步你就得到了一个 MCP Server,接下来我们用 Cursor 充当 MCP Client 来验证一下。
配置指向我们的 Server
json
{
"mcpServers": {
"getWeather": {
"url": "http://localhost:8080/sse"
}
}
}问个问题验证一下,注意使用的时候需要选择 agent 模式:
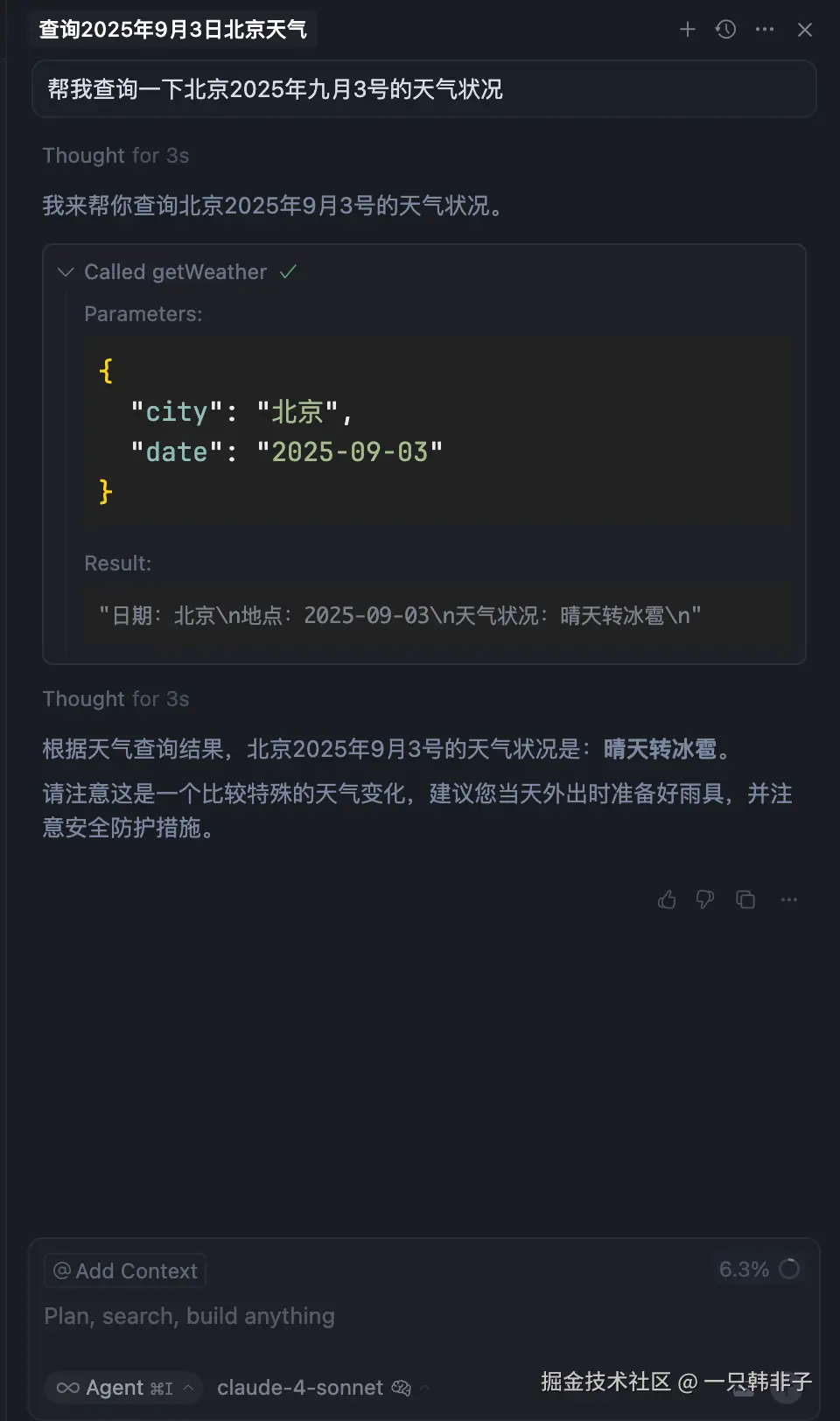
自此我们就完成了一个 MCP Server 服务的开发
5.4.3 搭建 MCP Client
第一步,引入依赖
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
</dependency>第二步,配置文件
增加 mcp.client 的相关配置,这里我们配置 sse
yaml
spring:
ai:
chat:
client:
# 如果有多个模型配置,就要设置自动配置为false
enabled: false
dashscope:
api-key: 你的key
chat:
options:
model: qwen-plus
deepseek:
base-url: https://api.deepseek.com
api-key: 你的key
chat:
options:
model: deepseek-chat
mcp:
client:
toolcallback:
enabled: true
enabled: true
name: my-mcp-client
version: 1.0.0
request-timeout: 30s
type: SYNC # or ASYNC for reactive applications
sse:
connections:
server1:
url: http://localhost:8080
sse-endpoint: /sse第三步,给 ChatClient 添加工具列表
kotlin
@Configuration
public class ChatBuilderConfig {
@Bean
public ChatClient dashScopeChatClient(DashScopeChatModel dashScopeChatModel, SyncMcpToolCallbackProvider toolCallbackProvider) {
return ChatClient.builder(dashScopeChatModel)
.defaultToolCallbacks(toolCallbackProvider.getToolCallbacks())
.build();
}
}第四步,使用
正常使用即可,会自动再请求的时候携带工具列表
less
@RestController
@RequestMapping("/mcp")
public class MCPController {
@Resource
private ChatClient dashScopeChatClient;
@GetMapping("/mcp-chat")
public String chat(String userInput) {
return dashScopeChatClient.prompt()
.user(userInput)
.call()
.content();
}
}第五步,查看效果

自此我们就用 Sping AI 中的功能开发了一个 MCP Client 服务,可以添加各种第三方的或我们自己开发的 Sevver 进行调用
5.5 智能体
我们把基于 Spring AI ChatClient 开发的 AI 应用叫做单智能体应用。
对于一些复杂的 AI 应用场景,开发者可以使用 Spring AI Alibaba Graph 开发多智能体应用。Spring AI Alibaba Graph 既可以用于开发工作流应用,也可以用于开发多智能体应用。相比于工作流模式,多智能体模式虽也遵循特定的流程,但是在整个决策、执行流程上具备更多的自主性和灵活性。
社区基于 Spring AI Alibaba Graph 开发了多款具备自主规划能力的智能体产品与平台,目前已经发布的包括 JManus、DeepResearch、ChatBI(NL2SQL) 三款产品。
相关智能体产品链接如下,开发者可直接部署应用或在此基础上进行适配改造:
- JManus,一款基于 Java 实现的,包含良好的前端 UI 交互界面的通用智能体产品;
- DeepResearch,一款基于 Spring AI Alibaba Graph 实现的 DeepResearch 产品;
- ChatBI(NL2SQL),一款轻量、高效、可扩展的 NL2SQL 智能体框架,让 Java 程序员可以快速构建基于自然语言的数据查询系统。
5.5.1 什么是 Spring AI Alibaba Graph:
Spring AI Alibaba Graph 是社区核心实现之一,也是整个框架在设计理念上区别于 Spring AI 只做底层原子抽象的地方,Spring AI Alibaba 期望帮助开发者更容易的构建智能体应用。基于 Graph 开发者可以构建工作流、多智能体应用。Spring AI Alibaba Graph 在设计理念上借鉴 Langgraph,因此在一定程度上可以理解为是 Java 版的 Langgraph 实现,社区在此基础上增加了大量预置 Node、简化了 State 定义过程等,让开发者更容易编写对等低代码平台的工作流、多智能体等。
Graph 速览:
框架核心概念包括:StateGraph (状态图,用于定义节点和边)、Node (节点,封装具体操作或模型调用)、Edge (边,表示节点间的跳转关系)以及 OverAllState(全局状态,贯穿流程共享数据)。这些设计使开发者能够方便地管理工作流中的状态和逻辑流转。
以下代码片段是使用 Graph 开发的一个多智能体架构示例(摘自 Spring AI Alibaba DeepResearch 实际实现):
css
StateGraph stateGraph = new StateGraph("deep research", keyStrategyFactory, new DeepResearchStateSerializer(OverAllState::new))
.addNode("coordinator", node_async(new CoordinatorNode(chatClientBuilder)))
.addNode("background_investigator", node_async(new BackgroundInvestigationNode(tavilySearchService)))
.addNode("planner", node_async((new PlannerNode(chatClientBuilder))))
.addNode("human_feedback", node_async(new HumanFeedbackNode()))
.addNode("research_team", node_async(new ResearchTeamNode()))
.addNode("researcher", node_async(new ResearcherNode(researchAgent)))
.addNode("coder", node_async(new CoderNode(coderAgent)))
.addNode("reporter", node_async((new ReporterNode(chatClientBuilder))))
.addEdge(START, "coordinator")
.addConditionalEdges("coordinator", edge_async(new CoordinatorDispatcher()),
Map.of("background_investigator", "background_investigator", "planner", "planner", END, END))
.addEdge("background_investigator", "planner")
.addConditionalEdges("planner", edge_async(new PlannerDispatcher()),
Map.of("reporter", "reporter", "human_feedback", "human_feedback", "planner", "planner",
"research_team", "research_team", END, END))
.addConditionalEdges("human_feedback", edge_async(new HumanFeedbackDispatcher()),
Map.of("planner", "planner", "research_team", "research_team", END, END))
.addConditionalEdges("research_team", edge_async(new ResearchTeamDispatcher()),
Map.of("reporter", "reporter", "researcher", "researcher", "coder", "coder"))
.addConditionalEdges("researcher", edge_async(new ResearcherDispatcher()),
Map.of("research_team", "research_team"))
.addConditionalEdges("coder", edge_async(new CoderDispatcher()), Map.of("research_team", "research_team"))
.addEdge("reporter", END);核心功能:
- 支持 Multi-agent,内置 ReAct Agent、Supervisor 等常规智能体模式
- 支持工作流,内置工作流节点,与主流低代码平台对齐
- 原生支持 Streaming
- Human-in-the-loop,通过人类确认节点,支持修改状态、恢复执行
- 支持记忆与持久存储
- 支持流程快照
- 支持嵌套分支、并行分支
- PlantUML、Mermaid 可视化导出
5.5.2 从聊天机器人、工作流到多智能体
5.5.2.1 聊天机器人
AI 应用开发不止是无状态大模型的 API 调用过程,由于大模型预训练的特性,AI 应用还需要具备领域数据检索(RAG)、会话记忆(Memory)、工具调用(Tool)等集成能力,这些对外集成统称为模型增强模式(The Augmented LLM),它允许开发者将自己的数据和外部 API 直接带入模型的推理过程。
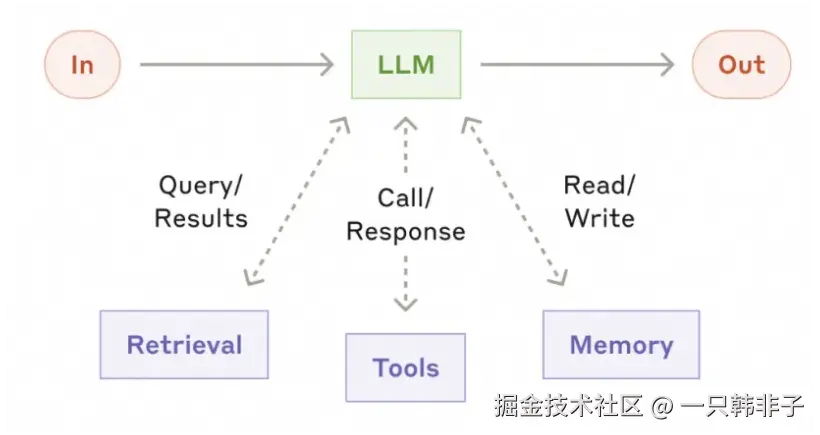
ChatClient 是 Spring AI 中最核心的组件,开发者可以使用 ChatClient 开发自己的聊天机器人或智能体应用,ChatClient 支持模型增强模式,为模型调用挂载 Retrieval、Tools、Memory 等外部数据与服务。
scss
Flux<String> response = chatClient.prompt(query)
.tools(toolCallbacks)
.advisors(new QuestionAnswerAdvisor())
.stream()
.content();我们这里把 ChatClient 开发的 AI 应用叫做单智能体应用,这可能是我们最理想的智能体开发模式,它足够简单直接,即把所有的工具、上下文信息等给到模型,由模型持续决策、迭代直到最终完成任务解答。然而,事情远没有那么简单,模型的能力还远未达到我们想要的效果,当我们给模型的上下文、工具过多时,整体效果就会变差,有时事情的走向会严重偏离我们的预期。因此,我们考虑把复杂的问题拆解开来,当前有两种常用模式:工作流和多智能体。
5.5.2.2 工作流
工作流是以相对固化的模式来人为的拆解任务,将一个大的任务拆解为一个固化的有多个分支的流程。工作流的优势是确定性强,模型作为流程中的一个结点起到的更多是一个分类决策的职责,因此它更适合意图识别等类别属性强的应用场景。工作流也有明显的劣势,它要求开发人员对业务流程有深刻的理解,整个流程是由人绘制的,模型在其中更多的只是内容生成、总结、分类识别的作用,并不能最大化利用模型的推理能力,因此很多人诟病这种模式是不够智能的。
用 Spring AI Alibaba Graph 可以轻松开发工作流,声明不同的结点,并将结点串联成一个流程图。
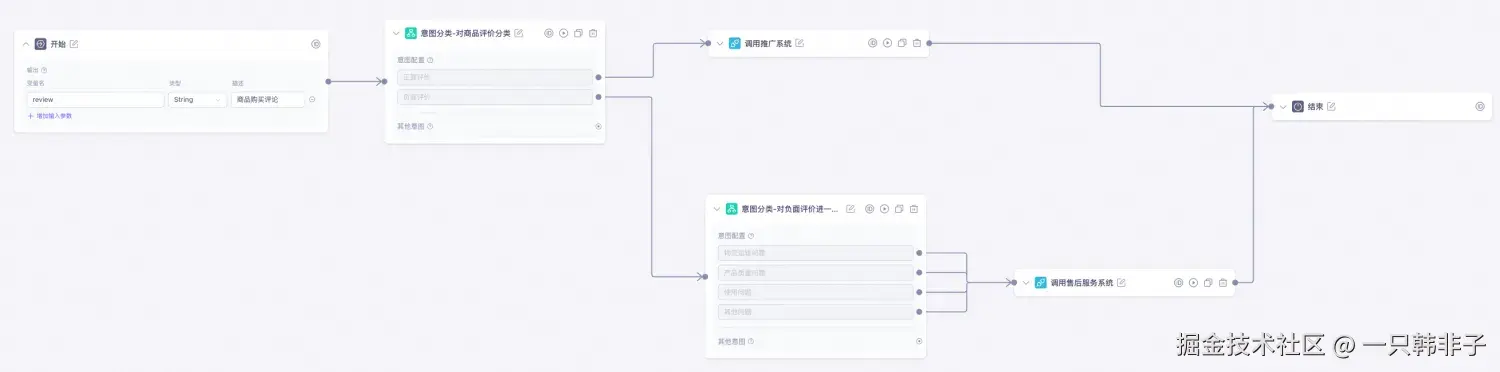
值得注意的是,Spring AI Alibaba Graph 中提供大量预置结点,这些结点可以对标到市面上主流的如 Dify、百炼等低代码平台,典型结点包括 LlmNode(大模型节点)、QuestionClassifierNode(问题分类结点)、ToolNode(工具结点)等,为用户免去重复开发定义负担,只需要专注流程串联。
如以上是一个可视化绘制的"用户评价分类系统"工作流,对应 Spring AI Alibaba Graph 代码如下所示:
less
StateGraph stateGraph = new StateGraph("Consumer Service Workflow Demo", stateFactory)
.addNode("feedback_classifier", node_async(feedbackClassifier))
.addNode("specific_question_classifier", node_async(specificQuestionClassifier))
.addNode("recorder", node_async(new RecordingNode()))
.addEdge(START, "feedback_classifier")
.addConditionalEdges("feedback_classifier",edge_async(new CustomerServiceController.FeedbackQuestionDispatcher()),Map.of("positive", "recorder", "negative", "specific_question_classifier"))
.addConditionalEdges("specific_question_classifier",edge_async(new CustomerServiceController.SpecificQuestionDispatcher()),Map.of("after-sale", "recorder", "transportation", "recorder", "quality", "recorder", "others","recorder"))
.addEdge("recorder", END);5.5.2.3 多智能体(Multi-agent)
复杂任务拆解的另一种解决方案是多智能体,相比于工作流,多智能体虽也遵循特定的流程,但是在整个决策、执行流程上具备更多的自主性和灵活性。多个子智能体间通过通信协作完成,最终完成任务解答,在业界,有多种常见的多智能体通信模型,如下图是几个典型示例:
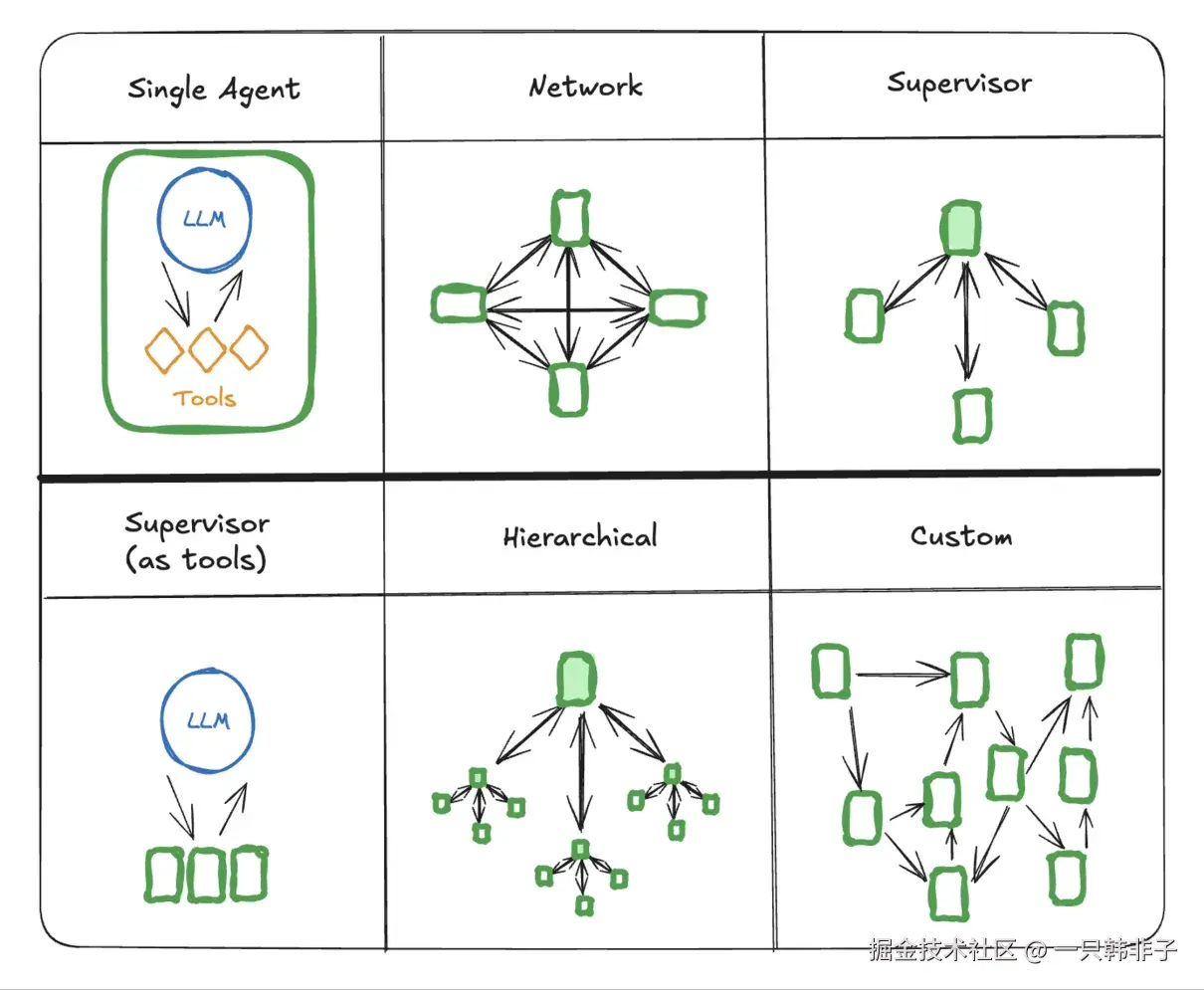
Spring AI Alibaba Graph 可用来开发各种多智能体模式。官方社区目前发布了几款基于 Spring AI Alibaba Graph 开发的智能体产品,包括通用智能体 JManus、DeepResearch 智能体、AgentScope 等。
5.5.3 打造下一代通用智能体平台
Spring AI Alibaba 定位以 ChatClient、Graph 抽象为核心的智能体框架以及围绕框架的生态集成,用来帮助用户开发快速构建企业级 AI 智能体。
随着通用智能体模式的快速发展,社区也在基于 Spring AI Alibaba 探索具备自主规划能力的智能体产品与平台,目前已经发布了 JManus、DeepResearch 两款产品,通过 JManus 等智能体产品,一方面探索智能体在解决日常生活、工作效率等开放性问题方面的无限空间;另一方面,社区也在智能体开发平台、深度搜索等垂直领域持续探索,期望在低代码平台、高代码框架之外,为开发者带来面向自然语言的零代码智能体研发体验。
5.5.3.1 JManus 智能体平台
最开始发布 JManus 之时,给它的定位是一款完全以 Java 语言为核心、彻底开源的 OpenManus 复刻实现,基于 Spring AI Alibaba 实现的通用 AI Agent 产品,包含一个设计良好的前端 UI 交互界面。
随着对于通用智能体等方向的深度探索,对于 JManus 通用智能体的终端产品定位也进行了调整。Manus 的横空出世,让通用智能体自动规划、执行规划的能力给了人们无限想象空间,它非常擅长解决开放性问题,在日常生活、工作等场景都能有广泛的应用。但在实践中人们也开始认识到,基于当前以及未来相当长的时间内模型能力,完全依赖通用智能体的自动规划模式很难解决一些确定性极强的企业场景问题。企业级业务场景的典型特点是确定性,需要定制化的工具、子agent,需要稳定而又确定性强的规划与流程,为此,期望 JManus 能成为一个智能体开发平台,让用户能以最直观、低成本的方式构建自己垂直领域的智能体实现。
当前,Jmanus 具备以下核心能力:
- 完整实现了 OpenManus 多智能体产品 JManus 完整兑现了 OpenManus 产品能力,用户可以基于 UI 界面使用产品功能,JManus 可以基于自动规划模式帮助用户完成问题解答。
- 无缝支持 MCP(Model Context Protocol)工具集成 这意味着 Agent 不仅可以调用本地或云端的大语言模型,还能与各类外部服务、API、数据库等进行深度交互,极大拓展了应用场景和能力边界。
- 原生支持 PLAN-ACT 模式 能够让 Agent 具备复杂推理、分步执行和动态调整的能力,适用于多轮对话、复杂决策、自动化流程等高阶 AI 应用场景。
- 支持通过 UI 界面配置 Agent 开发者和运维人员无需修改底层代码,只需在直观的Web管理界面上进行简单操作,就能灵活调整Agent的参数、模型和工具,还可以调整任务规划,大大提升了易用性和运维效率。
- 自动生成基于 SAA 的智能体工程
用户通过自然语言与 JManus 交互,生成规划并沉淀为特定垂直方向的固化解决方案。如果您不想将运行态限定在平台之上,我们正在探索与低代码平台、框架脚手架的深度整合,支持规划转换为具备对等能力的 Spring AI Alibaba 工程。
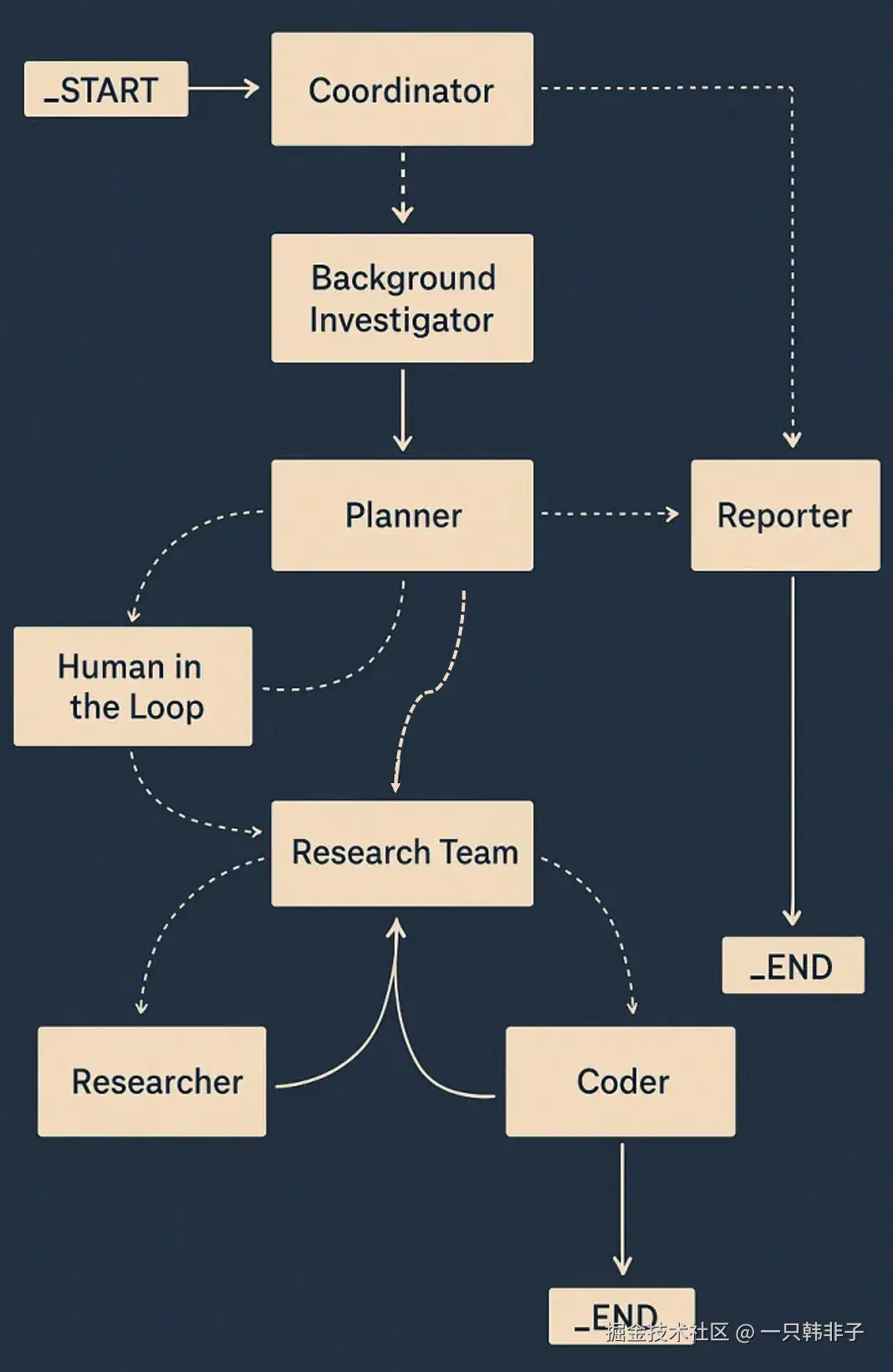
5.5.3.2 DeepResearch 智能体
DeepResearch 是一款基于 Spring AI Alibaba Graph 开发的 Deep Research 智能体, 包含完整的前端 Web UI(开发中) 和后端实现,DeepResearch 支持一系列精心设计的工具如 Web Search(网络查询)、Crawling(爬虫)、Python 脚本引擎等,可以借助大模型与工具能力,帮助用户完成各类深度调研报告。
以下是 DeepResearch 多智能体应用架构:
6.技术剖析
6.1 结构化输出
LLM 生成结构化输出的能力对于依赖可靠解析输出值的下游应用程序至关重要。开发人员希望快速将 AI 模型的结果转换为可传递给其他应用程序函数和方法的数据类型,例如 JSON、XML 或 Java 类。
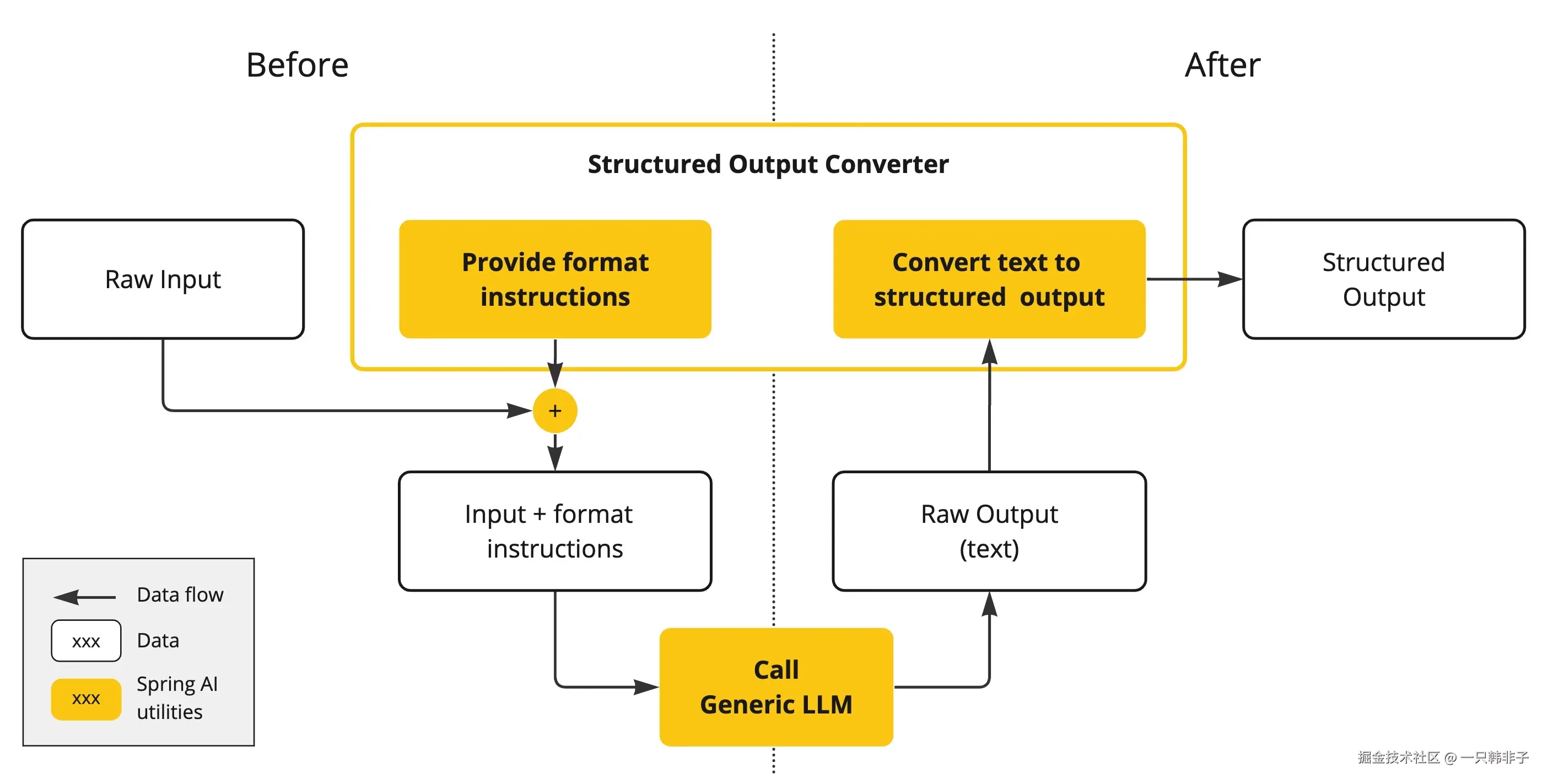
Spring AIStructured Output Converters有助于将 LLM 输出转换为结构化格式。如下图所示,此方法围绕 LLM 文本补全端点运行:
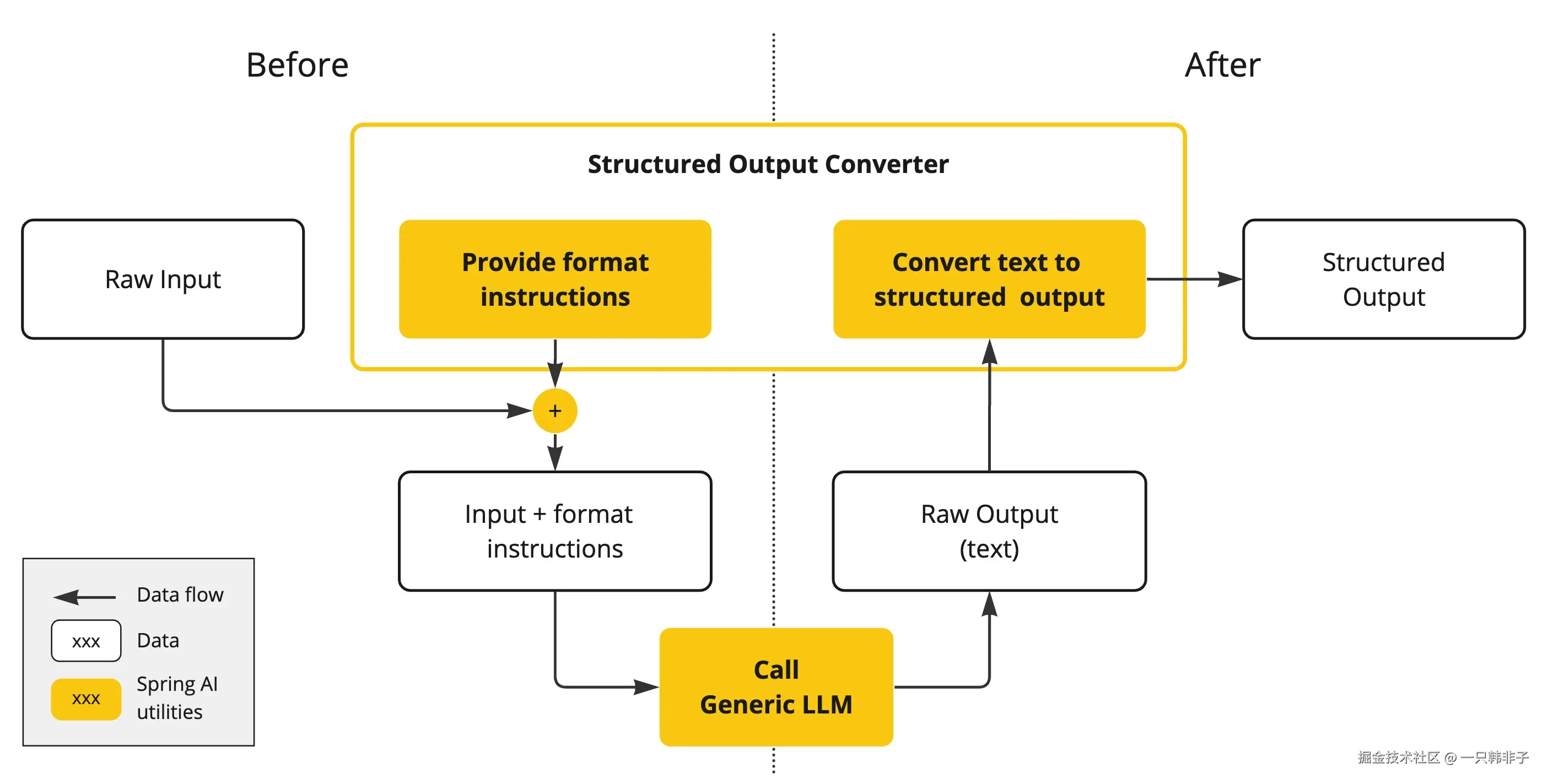
使用通用补全 API 从大型语言模型 (LLM) 生成结构化输出需要仔细处理输入和输出。结构化输出转换器在 LLM 调用前后起着至关重要的作用,确保实现所需的输出结构。
在 LLM 调用之前 ,转换器会将格式指令附加到提示中,为模型提供生成所需输出结构的明确指导。这些指令充当蓝图,塑造模型的响应以符合指定的格式。
LLM 调用后 ,转换器会获取模型的输出文本,并将其转换为结构化类型的实例。此转换过程包括解析原始文本输出并将其映射到相应的结构化数据表示形式,例如 JSON、XML 或特定于域的数据结构。
注意事项:
StructuredOutputConverter 是尽力将模型输出转换为结构化输出的最佳尝试。AI 模型不保证按请求返回结构化输出。模型可能无法理解提示或无法按请求生成结构化输出。考虑实现验证机制以确保模型输出符合预期。
6.1.1 结构化输出 Api
StructuredOutputConverter 接口允许您获取结构化输出,例如将输出映射到 Java 类或从基于文本的 AI 模型输出中获取值数组。接口定义如下:
csharp
public interface StructuredOutputConverter<T> extends Converter<String, T>, FormatProvider {
}它结合了 Spring 的 Converter<String, T> 接口和 FormatProvider 接口
csharp
public interface FormatProvider {
String getFormat();
}以下图表展示了使用结构化输出 API 时的数据流。
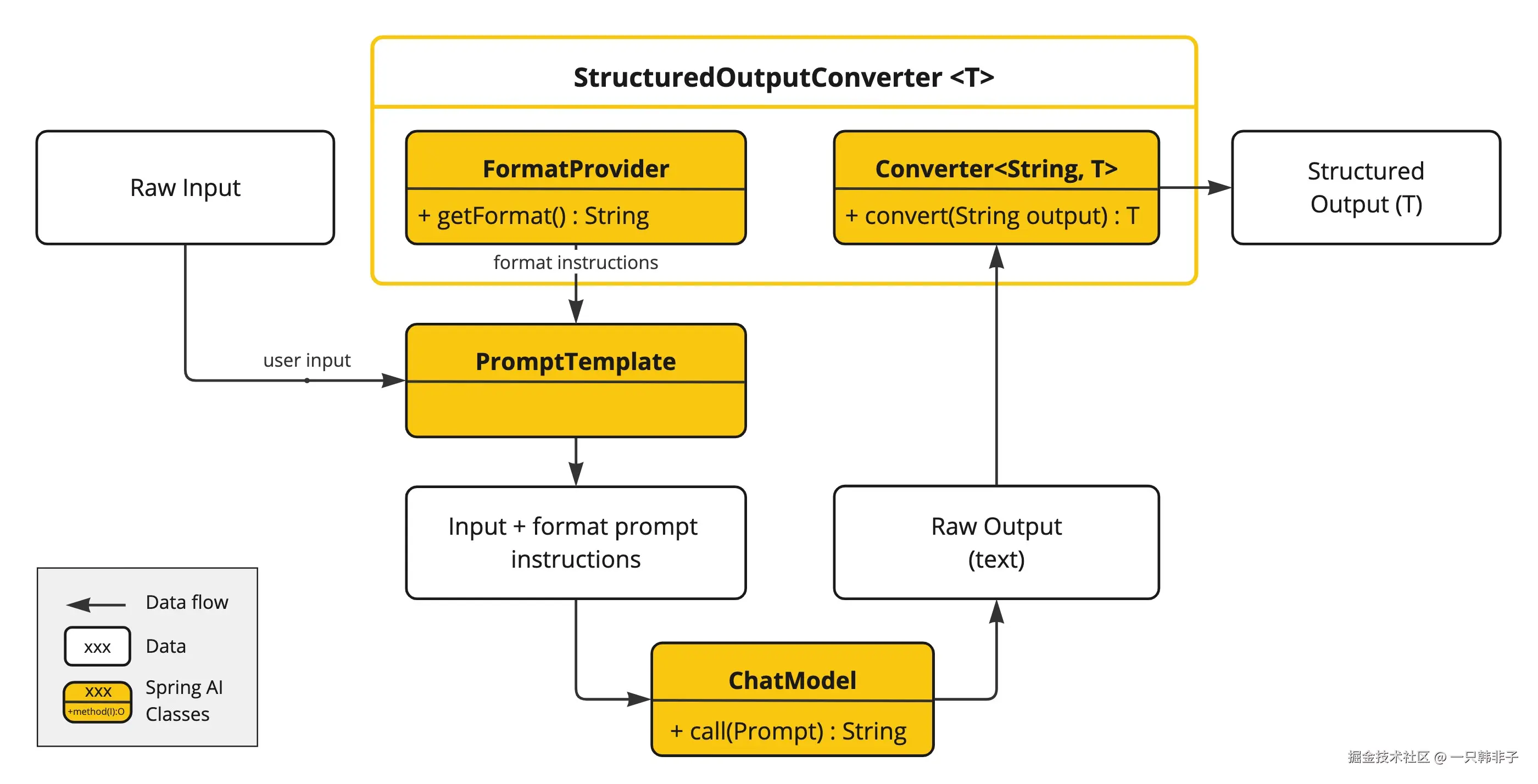
FormatProvider 向 AI 模型提供特定的格式化指南,使其能够使用 Converter 将文本输出转换为指定的目标类型 T。以下是一个这样的格式化指令示例:
typescript
Your response should be in JSON format.
The data structure for the JSON should match this Java class: java.util.HashMap
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.
译文:
你的回答必须是 JSON 格式。
JSON 的数据结构应与这个 Java 类匹配:java.util.HashMap。
不要包含任何解释,只需严格按照该格式提供一个符合 RFC8259 标准的 JSON 响应。 格式化指令通常使用 PromptTemplate 附加在用户输入的末尾,如下所示:
ini
StructuredOutputConverter outputConverter = ...
String userInputTemplate = """
... user text input ....
{format}
"""; // user input with a "format" placeholder.
Prompt prompt = new Prompt(
PromptTemplate.builder()
.template(this.userInputTemplate)
.variables(Map.of(..., "format", this.outputConverter.getFormat())) // replace the "format" placeholder with the converter's format.
.build().createMessage()
);Converter<String, T> 负责将模型输出的文本转换为指定类型 T 的实例。
6.1.2 可用转换器
目前,Spring AI 提供了 AbstractConversionServiceOutputConverter 、 AbstractMessageOutputConverter 、BeanOutputConverter、MapOutputConverter 和 ListOutputConverter 的实现:
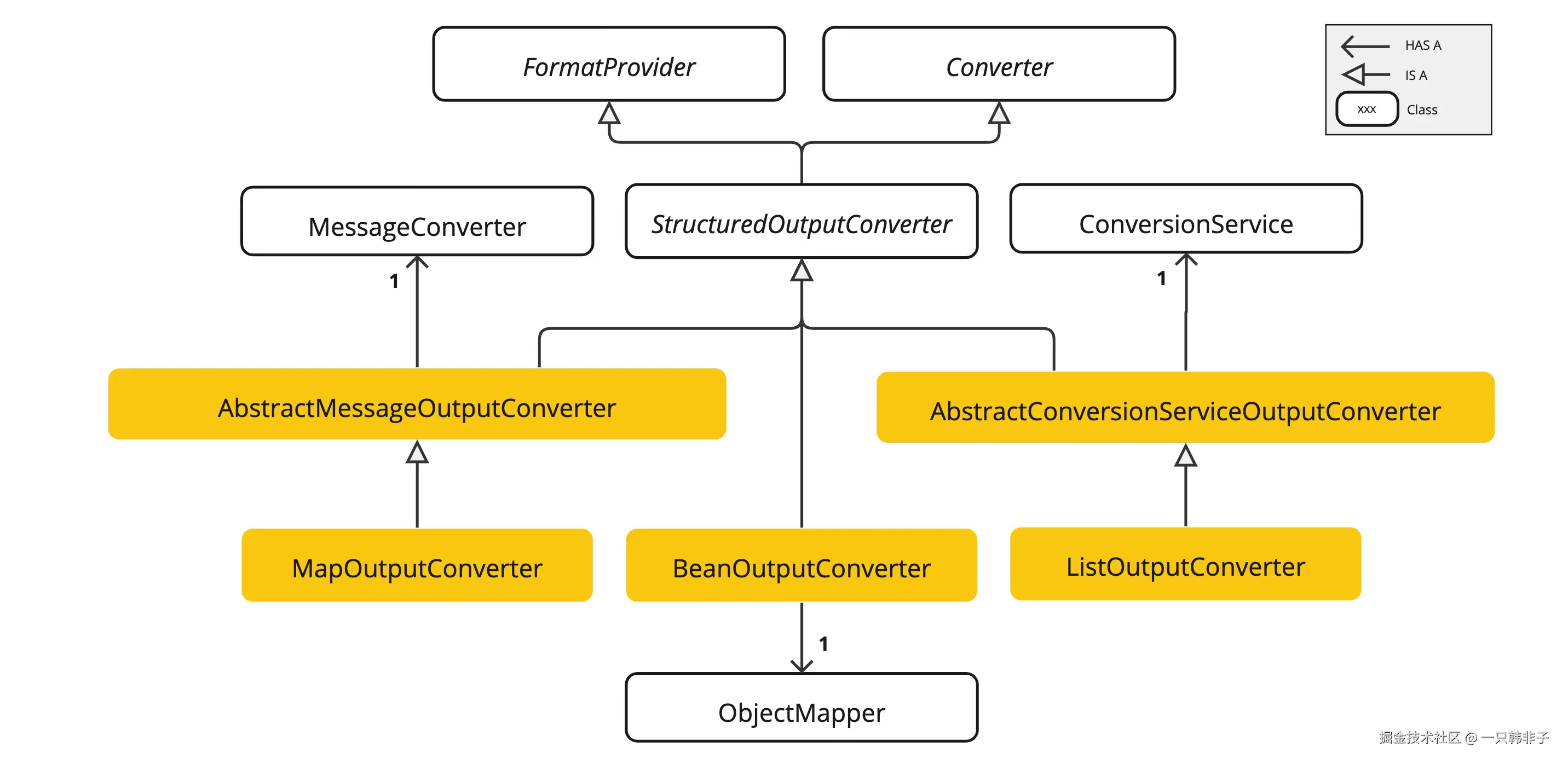
AbstractConversionServiceOutputConverter<T>- 提供了一个预配置的 GenericConversionService,用于将 LLM 输出转换为所需格式。没有提供默认的FormatProvider实现。AbstractMessageOutputConverter<T>- 提供一个预配置的 MessageConverter,用于将 LLM 输出转换为所需格式。不提供默认的FormatProvider实现。BeanOutputConverter<T>- 配置为使用指定的 Java 类(例如 Bean)或 ParameterizedTypeReference,此转换器采用FormatProvider实现,指导 AI 模型生成符合DRAFT_2020_12、JSON Schema的 JSON 响应,该 JSON Schema 源自指定的 Java 类。随后,它使用ObjectMapper将 JSON 输出反序列化为目标类的 Java 对象实例。MapOutputConverter- 扩展了AbstractMessageOutputConverter的功能,通过一个FormatProvider实现来指导 AI 模型生成符合 RFC8259 标准的 JSON 响应。此外,它还包含一个转换器实现,该实现利用提供的MessageConverter将 JSON 负载转换为java.util.Map<String, Object>实例。ListOutputConverter- 继承自AbstractConversionServiceOutputConverter,并包含一个针对逗号分隔列表输出的FormatProvider实现。转换器实现使用提供的ConversionService将模型文本输出转换为java.util.List。
6.1.3 使用转换器
6.1.3.1 Bean Output Converter
代表演员作品列表的目标记录:
arduino
record ActorsFilms(String actor, List<String> movies) {
}以下是使用高级、流畅的 ChatClient API 应用 BeanOutputConverter 的方法:
kotlin
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.deepseek.DeepSeekChatModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import java.util.List;
@RestController
public class ChatController {
private final ChatClient dashScopeChatClient;
public ChatController(DashScopeChatModel dashScopeChatModel, DeepSeekChatModel deepSeekChatModel) {
this.dashScopeChatClient = ChatClient.builder(dashScopeChatModel).build();
}
@GetMapping(value = "/dash-scope", name = "dashScope客户端")
public ActorsFilms chatByDashScope(String input) {
return this.dashScopeChatClient.prompt()
.user(u -> u.text("为 {actor} 生成包含 5 部电影的作品列表。")
.param("actor", input))
.call()
.entity(ActorsFilms.class);
}
record ActorsFilms(String actor, List<String> movies) {
}
}查看效果:
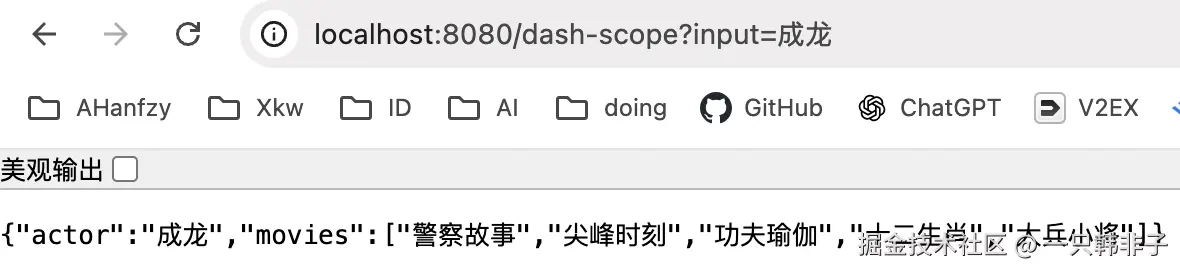
所以你会发现数据结构需要跟你的问题相对应,如果你想问一个苹果是什么好吃吗,此时再用这个数据结构就不合适了。
6.1.3.2 生成模式中的属性排序 BeanOutputConverter 通过 @JsonPropertyOrder 注解支持在生成的 JSON schema 中自定义属性排序。该注解允许您指定属性在 schema 中出现的精确顺序,而不管它们在类或记录中的声明顺序如何。
例如,为确保 ActorsFilms 记录中属性的特定顺序:
arduino
@JsonPropertyOrder({"movies","actor"})
record ActorsFilms(String actor, List<String> movies) {}这个注解适用于记录和常规的 Java 类。
通用 Bean 类型:
使用 ParameterizedTypeReference 构造函数来指定更复杂的目标类结构。例如,要表示演员及其作品列表:
scss
List<ActorsFilms> actorsFilms = ChatClient.create(chatModel).prompt()
.user("为 甄子丹 和 成龙 生成包含 5 部电影的作品列表。")
.call()
.entity(new ParameterizedTypeReference<List<ActorsFilms>>() {});查看效果:

可以看到结果中属性顺序与我们配置的一致,先展示的 movies 再展示的 actor
6.1.3.3 Map 输出转换器
以下代码片段展示了如何使用 MapOutputConverter 将模型输出转换为映射中的数字列表。
javascript
Map<String, Object> result = ChatClient.create(chatModel).prompt()
.user(u -> u.text("给我提供一个 {subject} 的列表")
.param("subject", "在键名 'numbers' 下放置一个从 1 到 9 的数字数组。"))
.call()
.entity(new ParameterizedTypeReference<Map<String, Object>>() {});查看效果:

6.1.3.4 List 输出转换器
以下代码片段展示了如何使用 ListOutputConverter 将模型输出转换为冰淇淋口味列表。
vbnet
List<String> flavors = ChatClient.create(chatModel).prompt()
.user(u -> u.text("列出五个 {subject}")
.param("subject", "冰淇淋口味"))
.call()
.entity(new ListOutputConverter(new DefaultConversionService()));查看效果:

7.产品对比
| 特性/框架 | Spring AI Alibaba | LangChain4j | JoyAgent JDGenie |
|---|---|---|---|
| 开发语言 | Java(基于 Spring AI) | Java(LangChain 的 Java 实现) | Java(JDGenie 平台) |
| 核心组件 | Spring AI Alibaba Graph、JManus、DeepResearch、NL2SQL | ChatModel、@Tool 注解、RAG 流水线、共享内存、多代理协同 | JDGenie 平台、智能任务调度、知识图谱集成 |
| 企业集成能力 | 深度集成阿里云生态(如 Bailian、ARMS、Nacos) | 支持多种 LLM 提供商(如 OpenAI、Azure、Claude) | 支持多种 LLM 提供商(如 OpenAI、Azure、Claude) |
| 模型支持 | 支持 Qwen、Deepseek、OpenAI 等模型 | 支持多种 LLM 提供商 | 支持 JDGenie 模型和自定义模型 |
| 部署与可观测性 | 支持分布式 MCP、Higress 网关、ARMS 监控 | 支持流式响应、内存管理、工具调用 | 支持任务调度、流程监控、日志追踪 |
| 适用场景 | 企业级 AI 代理、智能客服、自动化工作流 | 智能代理、文档搜索、摘要生成、对话系统 | 电商业务流程自动化、智能任务调度 |
| 开源与许可 | Apache 2.0 开源 | Apache 2.0 开源 | Apache 2.0 开源 |
8.总结
8.1 优势
- 稳定性与可持续性:基于 Spring AI 开发,继承 Spring 的稳定性与可用性,未来可直接跟进 Spring AI 的更新迭代。
- 无缝融入现有业务:坐落于 Spring 生态,能够快速、无缝集成到 Spring Boot 项目中,加速在公司业务场景的落地。
- 功能封装完善:对 AI 应用开发中的复杂场景(如大模型对话、流式输出、会话记忆、MCP、工作流、智能体等)提供现成封装,开箱即用。
- 开发体验友好:功能调用简洁,仅需少量代码即可实现核心能力,降低开发门槛。
- Graph 框架支持:提供自主灵活的 Graph 框架,便于快速构建和编排工作流和多智能体应用。
- 社区生态扩展:已开源 JManus、DeepResearch 等项目,可直接部署使用或基于其进行二次开发和业务适配。
8.2 劣势
- 依赖 Spring 生态:必须在 Spring Boot 项目中使用,对非 Spring 系统或其他语言的集成支持有限。
- 学习成本存在:虽然封装简化了使用,但对 Graph 框架、MCP 或智能体设计仍需理解 Spring AI 的特有概念。
- 功能需要模型适配:部分功能模块(如图像识别、文生图)需基于大模型自身能力进行适配。
- 文档与社区活跃度:相比 LangChain、Hugging Face 等国际社区,中文文档和案例虽有,但深度和更新速度可能不够快。
- 版本迭代依赖 Spring:若 Spring AI 核心更新与 Spring Boot 版本不兼容,可能需要额外适配工作。
- 框架高度封装:框架各流程和逻辑高度封装,需要花时间和精力去理解,问题排查较困难;相比之下,手动开发的业务更透明,排查更简单,定制化能力也更强。