背景意义
研究背景与意义
在计算机视觉领域,图像实例分割技术的快速发展为物体识别和分类提供了新的可能性。骰子作为一种常见的游戏工具,其点数识别在游戏自动化、智能桌游和机器人交互等应用中具有重要意义。传统的骰子点数识别方法多依赖于图像处理技术,然而,这些方法在复杂背景、光照变化和不同骰子样式下的表现往往不尽如人意。因此,基于深度学习的图像实例分割技术应运而生,能够有效提高骰子点数识别的准确性和鲁棒性。
本研究旨在基于改进的YOLOv11模型,构建一个高效的骰子点数识别图像实例分割系统。YOLO(You Only Look Once)系列模型以其快速的检测速度和较高的准确率而受到广泛关注。通过对YOLOv11进行改进,结合针对骰子特征的专门设计,可以在保证实时性的同时,提升模型对不同骰子点数的识别能力。我们使用的图像数据集包含2400张标注清晰的骰子图像,涵盖了1至6点及"lean"类别,确保了模型在多样化场景下的学习能力。
此外,数据集的多样性和丰富性为模型的训练提供了良好的基础。通过对图像进行预处理和数据增强,模型能够在多种情况下保持较高的识别性能。这不仅为骰子点数识别提供了强有力的技术支持,也为后续在更广泛的游戏和机器人应用中的推广奠定了基础。总之,本研究不仅具有重要的学术价值,也为实际应用提供了可行的解决方案,推动了智能化游戏及人机交互领域的发展。
图片效果
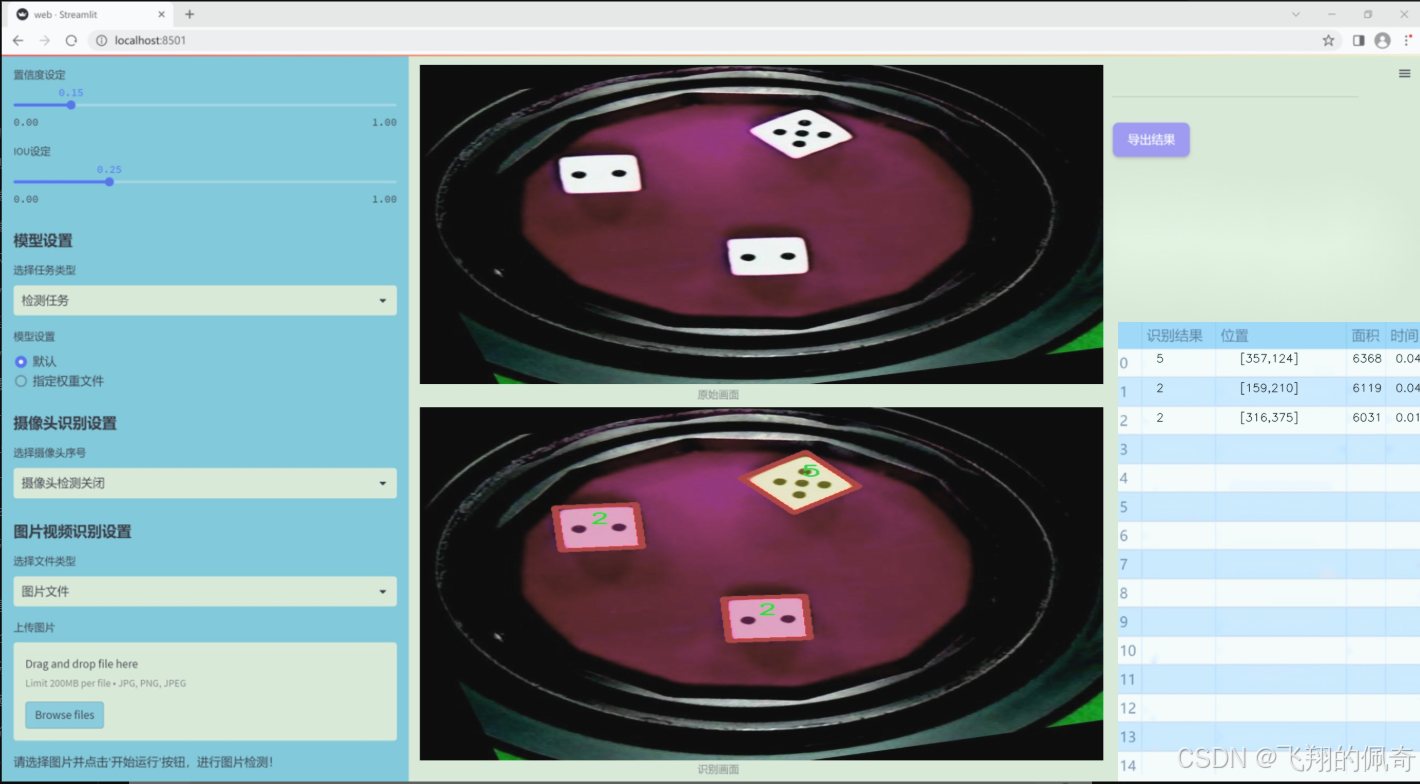
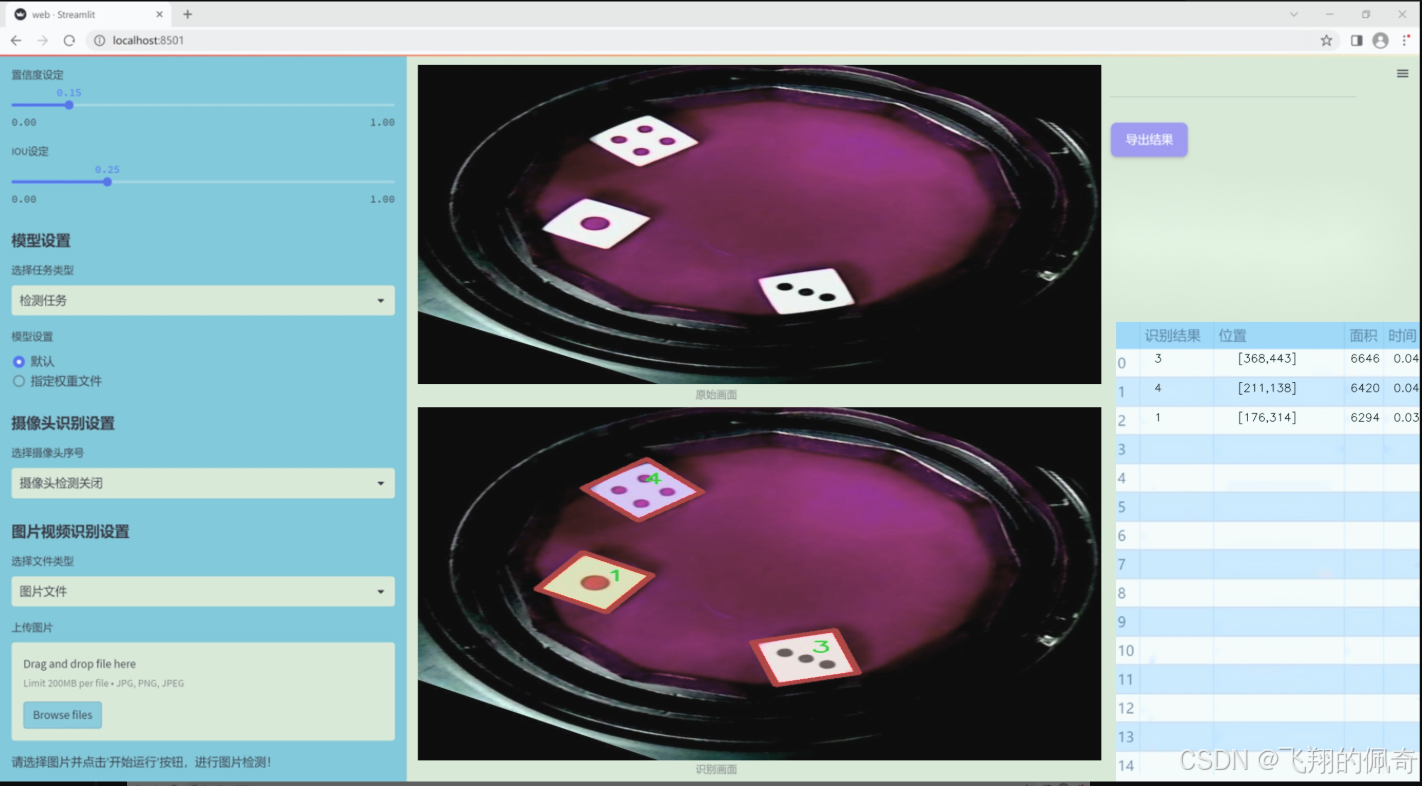
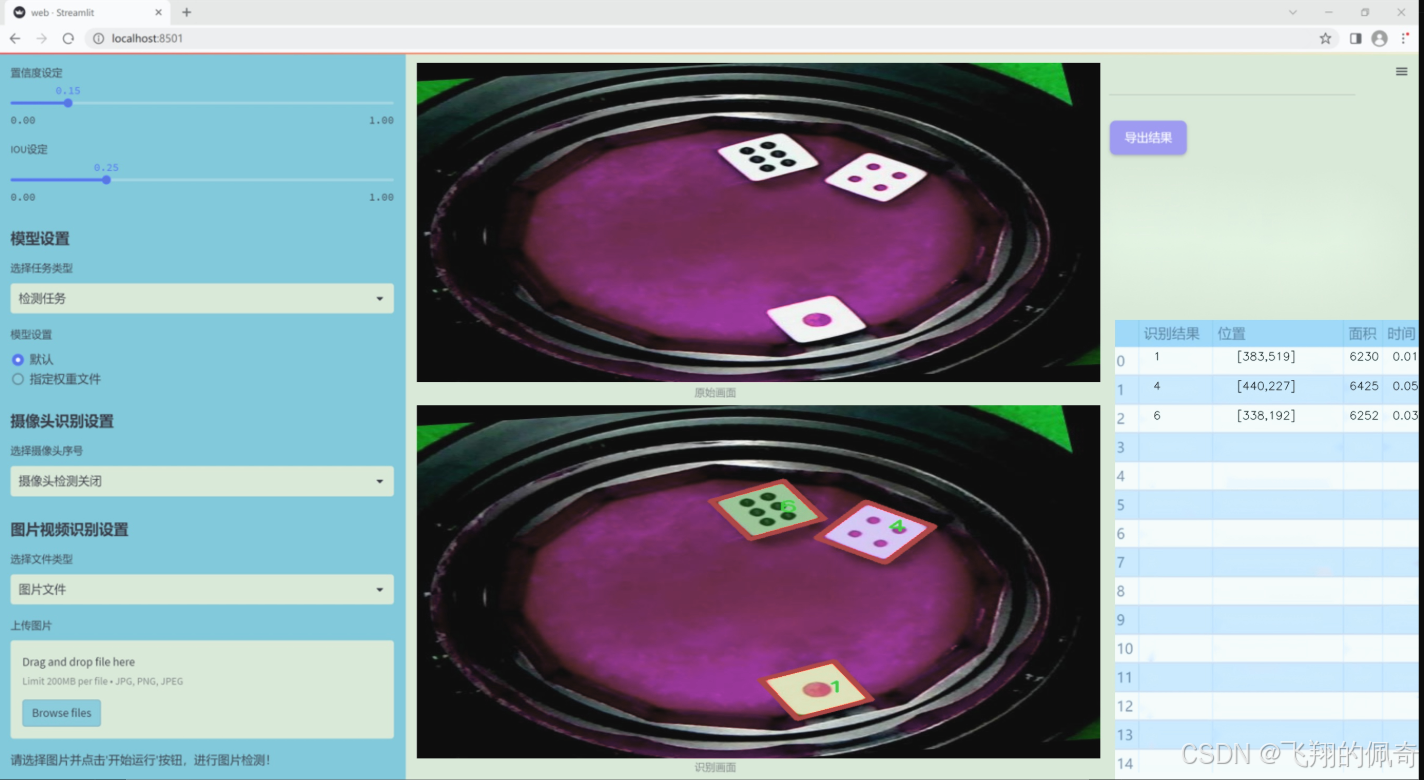
数据集信息
本项目数据集信息介绍
本项目旨在开发一个改进的YOLOv11模型,以实现骰子点数的高效识别和图像实例分割。为此,我们构建了一个专门的数据集,主题围绕"blue 2"进行设计。该数据集包含了丰富的骰子图像,涵盖了不同的骰子面和点数,旨在为模型提供多样化的训练样本,以提高其在实际应用中的准确性和鲁棒性。
数据集中共包含七个类别,分别为'1', '2', '3', '4', '5', '6'和'lean'。这些类别不仅代表了骰子的点数,还包括了一个额外的类别"lean",用于处理骰子在某些情况下可能出现的倾斜状态。这种设计使得模型能够在识别骰子点数时,考虑到可能的误差和不规则性,从而提升识别的准确度和可靠性。
在数据集的构建过程中,我们确保了图像的多样性和代表性。数据集中的图像涵盖了不同的光照条件、背景以及骰子的摆放角度,以模拟真实世界中可能遇到的各种情况。此外,为了增强模型的泛化能力,我们还引入了数据增强技术,包括旋转、缩放和颜色变换等。这些措施不仅丰富了数据集的内容,也提高了模型在面对新样本时的适应能力。
通过对该数据集的深入分析和使用,我们期望能够显著提升YOLOv11在骰子点数识别和图像实例分割任务中的表现,为相关领域的研究和应用提供有力支持。最终,我们希望通过这一系统的开发,推动骰子识别技术的进步,并为更广泛的图像处理任务提供参考和借鉴。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
class DySnakeConv(nn.Module):
def init (self, inc, ouc, k=3) -> None:
super().init()
# 初始化三个卷积层
self.conv_0 = Conv(inc, ouc, k) # 标准卷积
self.conv_x = DSConv(inc, ouc, 0, k) # 沿x轴的动态蛇形卷积
self.conv_y = DSConv(inc, ouc, 1, k) # 沿y轴的动态蛇形卷积
def forward(self, x):
# 将三个卷积的输出在通道维度上拼接
return torch.cat([self.conv_0(x), self.conv_x(x), self.conv_y(x)], dim=1)class DSConv(nn.Module):
def init (self, in_ch, out_ch, morph, kernel_size=3, if_offset=True, extend_scope=1):
"""
动态蛇形卷积
:param in_ch: 输入通道数
:param out_ch: 输出通道数
:param kernel_size: 卷积核大小
:param extend_scope: 扩展范围(默认1)
:param morph: 卷积核的形态,分为沿x轴(0)和y轴(1)
:param if_offset: 是否需要偏移,如果为False,则为标准卷积
"""
super(DSConv, self).init ()
用于学习可变形偏移的卷积层
self.offset_conv = nn.Conv2d(in_ch, 2 * kernel_size, 3, padding=1)
self.bn = nn.BatchNorm2d(2 * kernel_size) # 批归一化
self.kernel_size = kernel_size
# 定义沿x轴和y轴的动态蛇形卷积
self.dsc_conv_x = nn.Conv2d(
in_ch,
out_ch,
kernel_size=(kernel_size, 1),
stride=(kernel_size, 1),
padding=0,
)
self.dsc_conv_y = nn.Conv2d(
in_ch,
out_ch,
kernel_size=(1, kernel_size),
stride=(1, kernel_size),
padding=0,
)
self.gn = nn.GroupNorm(out_ch // 4, out_ch) # 组归一化
self.act = Conv.default_act # 默认激活函数
self.extend_scope = extend_scope
self.morph = morph
self.if_offset = if_offset
def forward(self, f):
# 计算偏移
offset = self.offset_conv(f)
offset = self.bn(offset)
offset = torch.tanh(offset) # 将偏移限制在[-1, 1]之间
# 获取输入特征的形状
input_shape = f.shape
dsc = DSC(input_shape, self.kernel_size, self.extend_scope, self.morph) # 创建DSC对象
deformed_feature = dsc.deform_conv(f, offset, self.if_offset) # 进行可变形卷积
# 根据形态选择相应的卷积
if self.morph == 0:
x = self.dsc_conv_x(deformed_feature.type(f.dtype))
else:
x = self.dsc_conv_y(deformed_feature.type(f.dtype))
x = self.gn(x) # 归一化
x = self.act(x) # 激活
return xclass DSC(object):
def init (self, input_shape, kernel_size, extend_scope, morph):
self.num_points = kernel_size # 卷积核的点数
self.width = input_shape2 # 输入特征图的宽度
self.height = input_shape3 # 输入特征图的高度
self.morph = morph # 卷积核形态
self.extend_scope = extend_scope # 偏移范围
# 定义特征图的形状
self.num_batch = input_shape[0] # 批次大小
self.num_channels = input_shape[1] # 通道数
def deform_conv(self, input, offset, if_offset):
# 计算坐标图
y, x = self._coordinate_map_3D(offset, if_offset)
# 进行双线性插值,得到变形后的特征图
deformed_feature = self._bilinear_interpolate_3D(input, y, x)
return deformed_feature
# 其他辅助函数(如坐标图计算和双线性插值)省略代码核心部分解释:
DySnakeConv 类:这是一个动态蛇形卷积的主要模块,包含了三个卷积层:标准卷积和两个动态蛇形卷积(分别沿x轴和y轴)。在前向传播中,将三个卷积的输出在通道维度上拼接。
DSConv 类:实现了动态蛇形卷积的逻辑,能够根据输入特征图和偏移量进行卷积操作。通过学习偏移量,能够实现特征图的变形卷积。
DSC 类:负责处理坐标图的生成和双线性插值,计算变形后的特征图。这个类的主要功能是根据偏移量计算新的坐标,并对输入特征图进行插值。
以上是代码的核心部分和详细注释,提供了对动态蛇形卷积的基本理解。
这个程序文件定义了一个动态蛇形卷积(Dynamic Snake Convolution)模块,主要由两个类构成:DySnakeConv 和 DSConv,以及一个辅助类 DSC。该模块的设计旨在实现一种具有动态形变能力的卷积操作,能够在图像处理和计算机视觉任务中提供更好的特征提取能力。
首先,DySnakeConv 类是一个神经网络模块,继承自 nn.Module。在初始化方法中,它接受输入通道数 inc、输出通道数 ouc 和卷积核大小 k 作为参数。该类创建了三个卷积层:conv_0 是标准卷积,conv_x 和 conv_y 是动态蛇形卷积,分别沿 x 轴和 y 轴进行操作。在前向传播方法中,输入 x 会经过这三个卷积层,最后将它们的输出在通道维度上进行拼接。
接下来,DSConv 类实现了动态蛇形卷积的具体逻辑。它的构造函数接受输入通道数、输出通道数、卷积核大小、形态参数、是否需要偏移等参数。该类首先定义了一个用于学习偏移量的卷积层 offset_conv,然后定义了两个卷积层 dsc_conv_x 和 dsc_conv_y,分别用于处理 x 轴和 y 轴的动态卷积。前向传播方法中,首先通过 offset_conv 计算出偏移量,然后利用 DSC 类中的方法进行坐标映射和双线性插值,最终得到变形后的特征图。
DSC 类负责处理动态卷积的核心逻辑。它包含了计算坐标映射和进行双线性插值的功能。通过 _coordinate_map_3D 方法,程序生成了根据偏移量调整后的坐标图,支持在 x 轴和 y 轴的动态形变。 _bilinear_interpolate_3D 方法则实现了对输入特征图进行双线性插值,以得到变形后的特征图。
总体来说,这个程序实现了一种灵活的卷积操作,能够根据输入特征图的内容动态调整卷积核的位置,从而增强模型对形状和结构变化的适应能力。这种方法在处理复杂的图像特征时,能够提供更丰富的信息,提升模型的表现。
10.3 mamba_vss.py
以下是保留的核心代码部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SS2D(nn.Module):
def init (self, d_model, d_state=16, d_conv=3, expand=2, dropout=0.):
super().init ()
self.d_model = d_model # 输入特征的维度
self.d_state = d_state # 状态的维度
self.d_conv = d_conv # 卷积核的大小
self.expand = expand # 扩展因子
self.d_inner = int(self.expand * self.d_model) # 内部特征维度
# 输入线性变换,将输入特征映射到内部特征空间
self.in_proj = nn.Linear(self.d_model, self.d_inner * 2)
# 2D卷积层
self.conv2d = nn.Conv2d(
in_channels=self.d_inner,
out_channels=self.d_inner,
groups=self.d_inner,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
)
self.act = nn.SiLU() # 激活函数
# 输出线性变换
self.out_proj = nn.Linear(self.d_inner, self.d_model)
self.dropout = nn.Dropout(dropout) if dropout > 0. else None # Dropout层
def forward(self, x: torch.Tensor):
# 前向传播函数
B, H, W, C = x.shape # 获取输入的批次大小、高度、宽度和通道数
# 输入通过线性变换
xz = self.in_proj(x)
x, z = xz.chunk(2, dim=-1) # 将输入分为两部分
# 进行卷积操作
x = x.permute(0, 3, 1, 2).contiguous() # 调整维度顺序
x = self.act(self.conv2d(x)) # 卷积后激活
# 输出处理
y = self.out_proj(x) # 线性变换
if self.dropout is not None:
out = self.dropout(y) # 应用Dropout
return outclass VSSBlock(nn.Module):
def init (self, hidden_dim: int = 0, drop_path: float = 0.2):
super().init ()
self.ln_1 = nn.LayerNorm(hidden_dim) # 归一化层
self.self_attention = SS2D(d_model=hidden_dim, dropout=drop_path) # 自注意力机制
self.drop_path = nn.Dropout(drop_path) # DropPath层
def forward(self, input: torch.Tensor):
# 前向传播函数
input = input.permute((0, 2, 3, 1)) # 调整输入维度
x = input + self.drop_path(self.self_attention(self.ln_1(input))) # 残差连接
return x.permute((0, 3, 1, 2)) # 调整输出维度示例代码
if name == 'main ':
inputs = torch.randn((1, 64, 32, 32)).cuda() # 创建随机输入
model = VSSBlock(64).cuda() # 实例化VSSBlock
pred = model(inputs) # 前向传播
print(pred.size()) # 输出预测的尺寸
代码说明:
SS2D类:实现了一个自注意力机制模块,包含输入线性变换、卷积层和输出线性变换。通过调整输入特征的维度来实现特征提取。
VSSBlock类:使用了SS2D作为自注意力机制,结合了LayerNorm和DropPath。通过残差连接来增强模型的学习能力。
前向传播:在forward方法中,输入数据经过线性变换、卷积和激活函数处理,最后输出经过Dropout的结果。
注意事项:
代码中省略了一些辅助函数和类的实现,以突出核心部分。
具体的参数和超参数可以根据实际需求进行调整。
这个程序文件 mamba_vss.py 实现了一个基于深度学习的模块,主要包括两个类:SS2D 和 VSSBlock,以及一个继承自 VSSBlock 的类 Mamba2Block。这些模块主要用于构建神经网络中的自注意力机制和卷积操作,适用于处理图像数据。
首先,SS2D 类是一个自定义的神经网络模块,继承自 nn.Module。它的构造函数接受多个参数,包括模型的维度、状态维度、卷积核大小、扩展因子等。该类内部定义了多个层,包括线性层、卷积层和激活函数。SS2D 的核心功能是通过一系列的线性变换和卷积操作来处理输入数据,并在 forward 方法中实现前向传播。
在 forward 方法中,输入数据首先通过一个线性层进行投影,然后进行卷积操作。接着,数据被送入 forward_core 方法,该方法实现了核心的自注意力机制。这里使用了选择性扫描的函数 selective_scan_fn,用于高效地处理序列数据。最终,经过一系列的变换后,输出结果经过层归一化和线性变换,返回最终的输出。
接下来,VSSBlock 类同样继承自 nn.Module,它的构造函数初始化了一个归一化层和一个自注意力层(即 SS2D 实例)。在 forward 方法中,输入数据经过归一化处理后,传递给自注意力层,并与原始输入进行残差连接,最后返回结果。
Mamba2Block 类是 VSSBlock 的一个扩展,主要是将自注意力层替换为 Mamba2Simple,这个类可能是另一个自定义的模块,专注于实现特定的自注意力机制。Mamba2Block 的 forward 方法与 VSSBlock 类似,处理输入数据并返回结果。
在文件的最后部分,包含了一个简单的测试代码块,用于验证模型的功能。它创建了随机输入数据,并实例化 VSSBlock 和 Mamba2Block,然后通过模型进行前向传播,输出预测结果的尺寸。
总体而言,这个程序文件展示了如何构建复杂的神经网络模块,结合了自注意力机制和卷积操作,适用于处理图像数据的任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式👇🏻