项目地址:https://github.com/b4rtaz/distributed-llama
本文档将指导您如何使用一个树莓派5作为Root节点和三个树莓派4作为Worker节点,共同搭建一个4节点的分布式LLM推理集群,并运行10.9GB的Qwen 3 14B模型。
中间要用到github和huggingface的,
注意
将下面的IP和端口替换为你自己的,我电脑上开启了**程序,我的电脑ip是192.168.71.70
export http_proxy="http://192.168.71.70:7890"
export https_proxy="http://192.168.71.70:7890"
集群架构概览
- Root 节点 (兼Worker) : 1 x 树莓派 5
- IP地址 :
192.168.71.84 - 职责: 加载模型和权重,分发给Worker节点,同步神经网络状态,并处理自己那一部分的计算任务。
- IP地址 :
- Worker 节点 : 3 x 树莓派 4
- IP地址 :
192.168.71.83,192.168.71.86,192.168.71.91 - 职责: 接收Root节点的指令和数据,处理分配给自己的计算任务。
- IP地址 :
1. 准备工作 (所有节点)
在开始之前,请确保您的所有4个树莓派都满足以下条件。这些步骤需要在每一台树莓派上执行。
1.1 硬件与网络
- 内存 (RAM) : 强烈建议 所有树莓派都配备 8GB RAM 。Qwen 3 14B模型大小为10.9GB,分摊到4个节点上,每个节点约需承载
10.9 / 4 ≈ 2.73 GB的模型数据。加上操作系统和程序运行所需的内存,4GB内存的设备可能会非常勉强或失败。 - 操作系统 : 安装最新版的 Raspberry Pi OS (64-bit)。64位系统对于性能和内存管理至关重要。
- 网络连接 : 简易使用有线以太网。将所有4个树莓派连接到同一个路由器或交换机。无线网络(Wi-Fi)会有较高延迟。
1.2 系统与软件
-
更新系统 :
通过SSH登录到每个树莓派,然后运行以下命令更新软件包列表和系统:
bashsudo apt update sudo apt upgrade -y -
安装依赖 :
安装
git用于克隆项目仓库,python3-pip用于安装Python包,以及build-essential用于编译C++代码。bashsudo apt install git python3-pip build-essential -y -
克隆项目仓库 :
将
Distributed Llama项目克隆到本地。bashgit clone https://github.com/bgz-io/distributed-llama.git cd distributed-llama
完成以上步骤后,您的所有节点都已准备就绪。
2. 配置并启动 Root 节点 (树莓派 5)
此步骤仅在 Root 节点 (192.168.71.84) 上执行。
-
SSH 登录 :
确保您已登录到树莓派5。
-
下载并准备模型 :
在
distributed-llama目录中,运行launch.py脚本。这将自动下载Qwen 3 14B模型、tokenizer,并完成所有必要的转换和设置。bashpython3 launch.py qwen3_14b_q40注意: 这是一个非常耗时的过程!您需要下载10.9GB的文件,并且脚本会进行一些处理。请确保您的网络连接稳定,并耐心等待其完成。完成后,模型文件将存储在本地。
3. 启动 Worker 节点 (3 x 树莓派 4)
此步骤需要在每一个 Worker 节点 (192.168.71.83, 192.168.71.86, 192.168.71.91) 上分别执行。为方便操作,您可以为每个Worker节点打开一个独立的SSH终端窗口。
在每个Worker节点的终端中,进入 distributed-llama 目录,然后运行以下命令来启动Worker进程:
bash
# 在 192.168.71.83 上运行
# 在 192.168.71.86 上运行
# 在 192.168.71.91 上运行
./dllama worker --port 9999 --nthreads 4dllama worker: 启动Worker模式。--root-addr 192.168.71.84:18666: 指定Root节点的IP地址和通信端口(18666是一个常用默认端口,如果项目有特定端口,请相应修改)。
成功运行后,每个Worker终端会显示等待连接或类似的信息。它们现在正在监听来自Root节点的指令。
4. 启动集群并开始聊天
现在,回到 Root 节点 (192.168.71.84) 的终端窗口。所有Worker都已准备就绪,可以启动主程序了。
-
运行聊天程序 :
在
distributed-llama目录中,运行dllama chat命令,并通过--worker-addrs参数告诉Root节点所有Worker的地址。bash./dllama chat --model dllama_model_qwen3_14b_q40.m --tokenizer dllama_tokenizer_qwen3.t --buffer-float-type q80 --max-seq-len 4096 --prompt "你好,世界" --steps 256 --nthreads 8 --workers 192.168.71.83:9999 192.168.71.86:9999 192.168.71.91:9999dllama chat: 启动命令行聊天界面。--worker-addrs ...: 提供一个用逗号分隔的Worker节点地址列表。18667是Worker监听的常用默认端口,请确保与Worker启动时使用的端口一致。
-
开始交互 :
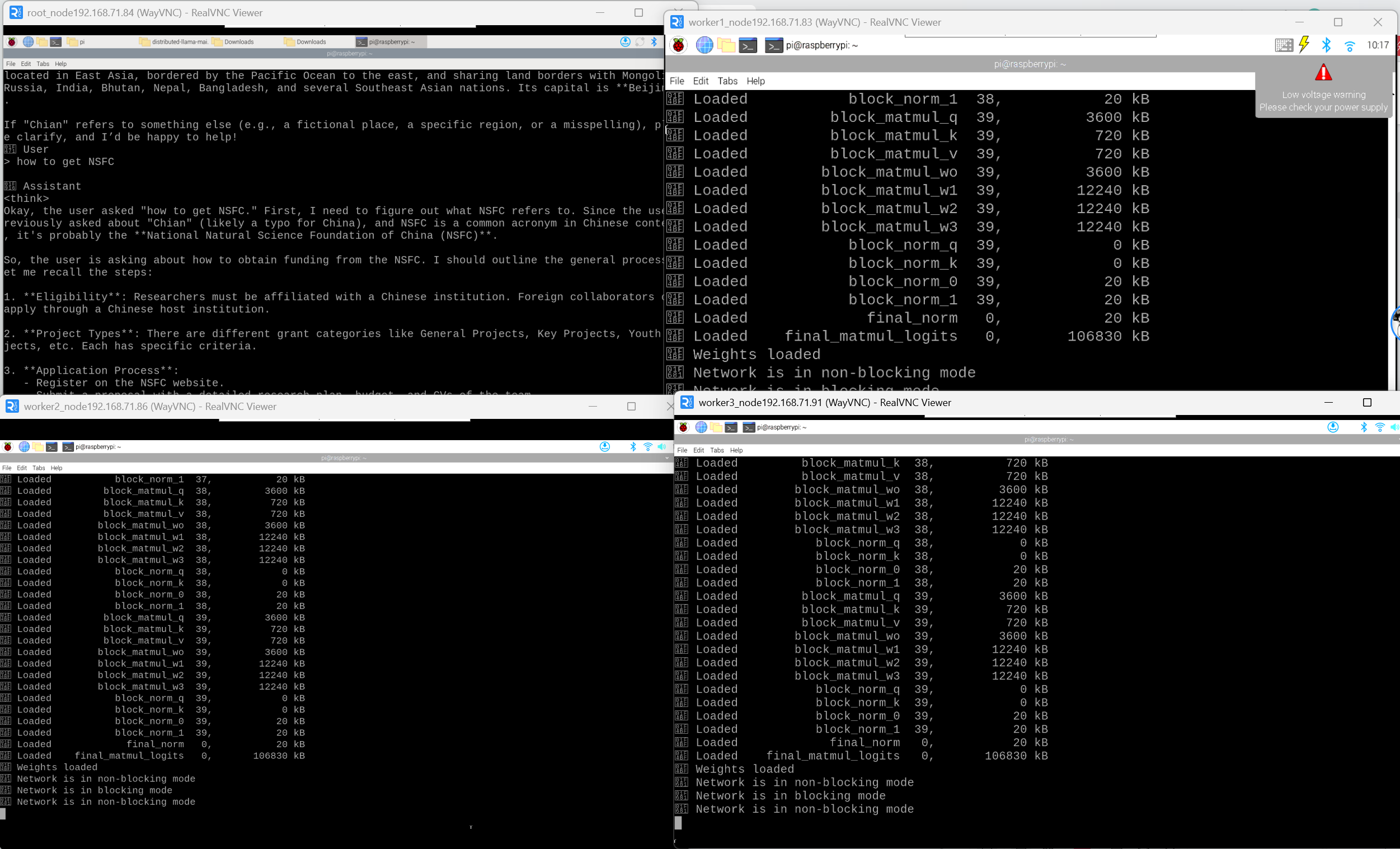
如果一切顺利,Root节点会连接到所有3个Worker节点,加载模型并分发权重。您将在终端看到一个聊天提示符,现在您可以输入问题与Qwen 3 14B模型进行交互了!
总结与注意事项
- 架构: 您已成功搭建一个4节点(1个Root + 3个Worker)的计算集群。根据项目文档,Root节点本身也参与计算,因此总计算能力是4个节点的总和。
- 性能: 树莓派的CPU性能有限,即使是集群,推理速度也无法与桌面级CPU或GPU相比。请对性能有合理的预期,它会比在单台树莓派上运行快,但仍然较慢。
- 网络是关键 : 我使用的是无线局域网,可能千兆有线以太网新能会更好。任何网络瓶颈都会严重影响整体速度。
- 防火墙 : 如果您在树莓派上启用了防火墙(如
ufw),请确保允许端口18666和18667(或您使用的任何端口) 的TCP通信。