精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、开发环境
- 三、视频展示
- 四、项目展示
- 五、代码展示
- 六、项目文档展示
- 七、总结
-
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻)
一、项目介绍
基于Django的饮食计划推荐与交流分享平台是一个专门为用户提供个性化饮食建议和营养管理的综合性Web应用系统。该平台采用Python作为主要开发语言,结合Django框架构建稳定的后端服务架构,前端使用Vue.js配合ElementUI组件库打造现代化的用户交互界面,数据存储依托MySQL数据库确保信息的可靠性和一致性。系统设计了管理员和普通用户两种角色,管理员负责维护食物信息库、管理饮食计划模板、监控用户健康数据、发布营养建议内容、设置健康目标参数、维护健康食谱资源以及管理系统排行榜功能,还具备食物类别的智能预测能力。普通用户可以完成注册登录、浏览丰富的食物营养信息、获取个性化饮食计划推荐、查阅专业健康食谱、追踪个人健康数据变化、接受系统营养建议以及设定个人健康目标。平台通过科学的算法分析用户的健康状况和饮食偏好,为每位用户量身定制适合的饮食方案,同时提供社交分享功能促进用户间的经验交流,构建了一个集个性化推荐、营养管理、社区互动于一体的现代化饮食健康管理平台。
选题背景
随着现代生活节奏的加快和工作压力的增大,人们对健康饮食的关注度日益提升,但普遍缺乏科学的营养知识和个性化的饮食指导。传统的饮食管理方式往往依赖于标准化的营养表和通用的饮食建议,无法针对个体差异提供精准的营养方案。市面上虽然存在一些饮食管理应用,但大多功能单一,要么只提供基础的热量计算,要么仅限于食谱展示,缺乏系统性的个性化推荐机制和用户交流互动功能。同时,不同年龄段、体质状况、运动习惯的人群对营养需求存在显著差异,而现有的饮食管理工具往往采用"一刀切"的方式,难以满足用户的个性化需求。另外,缺乏专业营养师指导的普通用户在面对海量的饮食信息时容易迷失方向,需要一个智能化的平台来整合营养知识、分析个人状况并提供科学的饮食建议,这为开发一个综合性的饮食计划推荐与交流平台提供了现实需求基础。
选题意义
开发基于Django的饮食计划推荐与交流分享平台具有多方面的实际意义。从技术实现角度来看,该项目综合运用了Python编程、Django Web框架、Vue.js前端技术、MySQL数据库管理等多项技术,能够帮助开发者深入理解现代Web应用的完整开发流程,掌握前后端分离的系统架构设计方法,提升数据库设计和优化能力,为今后从事相关技术工作奠定扎实基础。从用户价值层面分析,平台能够为普通用户提供科学的营养指导和个性化的饮食建议,帮助用户建立健康的饮食习惯,在一定程度上改善生活质量。系统的交流分享功能能够促进用户间的经验交流,形成良性的健康饮食社区氛围。从社会意义角度考虑,该平台可以普及营养健康知识,提高公众的健康意识,为推动全民健康生活方式的形成贡献微薄力量。虽然作为一个毕业设计项目,其影响范围相对有限,但通过实际的系统开发和功能实现,能够验证技术方案的可行性,为后续的功能扩展和商业化应用提供参考依据。
二、开发环境
开发语言:Python
数据库:MySQL
系统架构:B/S
后端框架:Django
前端:Vue+ElementUI
开发工具:PyCharm
三、视频展示
Python毕业设计推荐:基于Django的饮食计划推荐与交流分享平台 饮食健康系统 健康食谱计划系统
四、项目展示
登录模块:
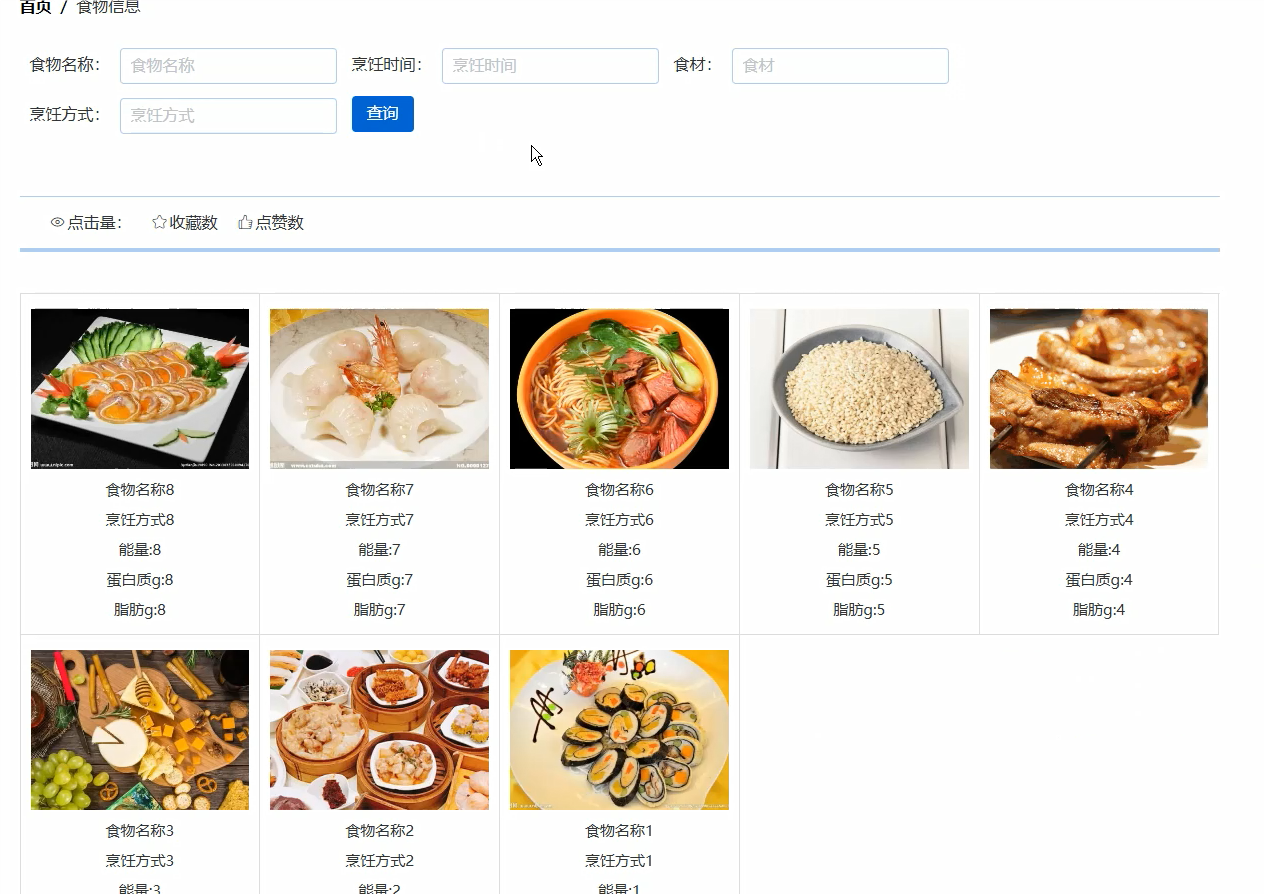
首页模块:
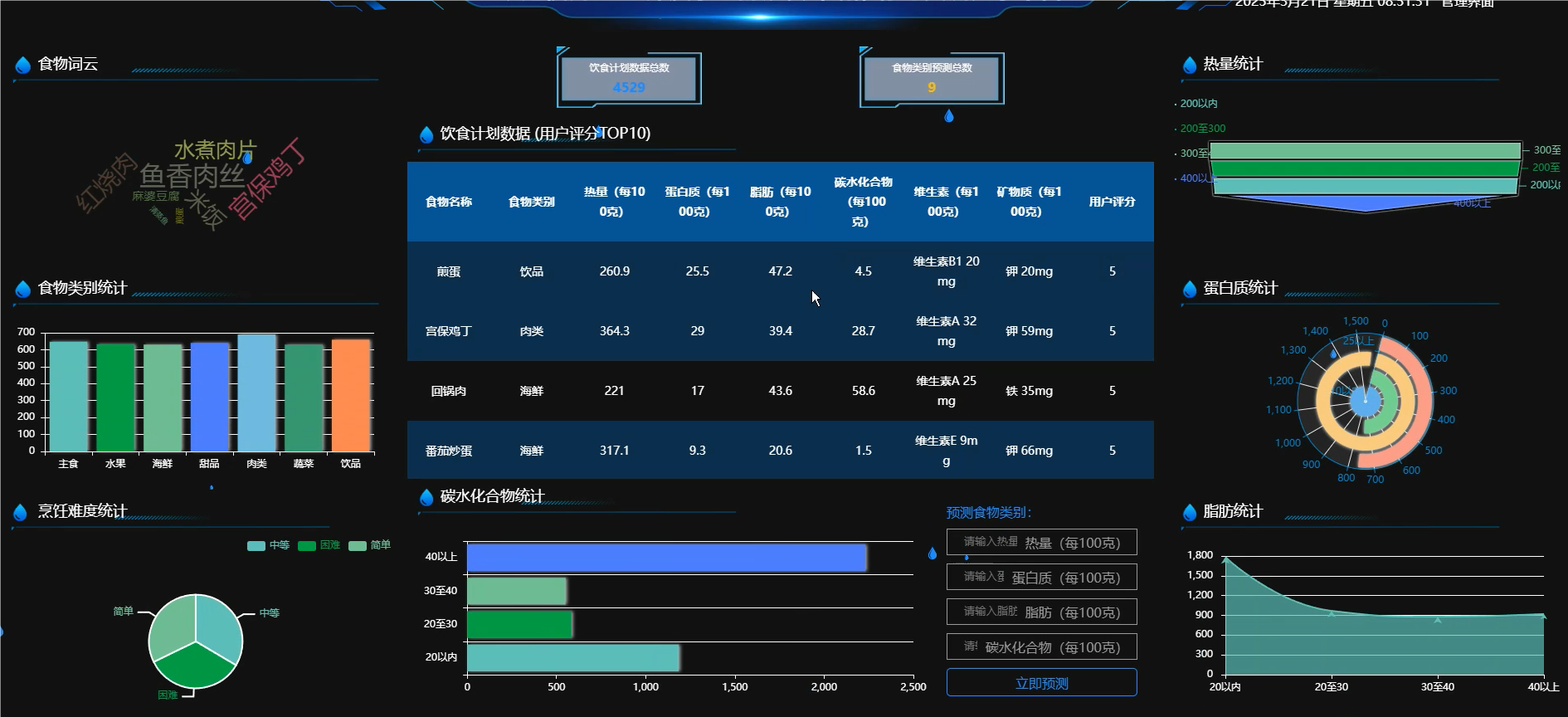
管理模块:
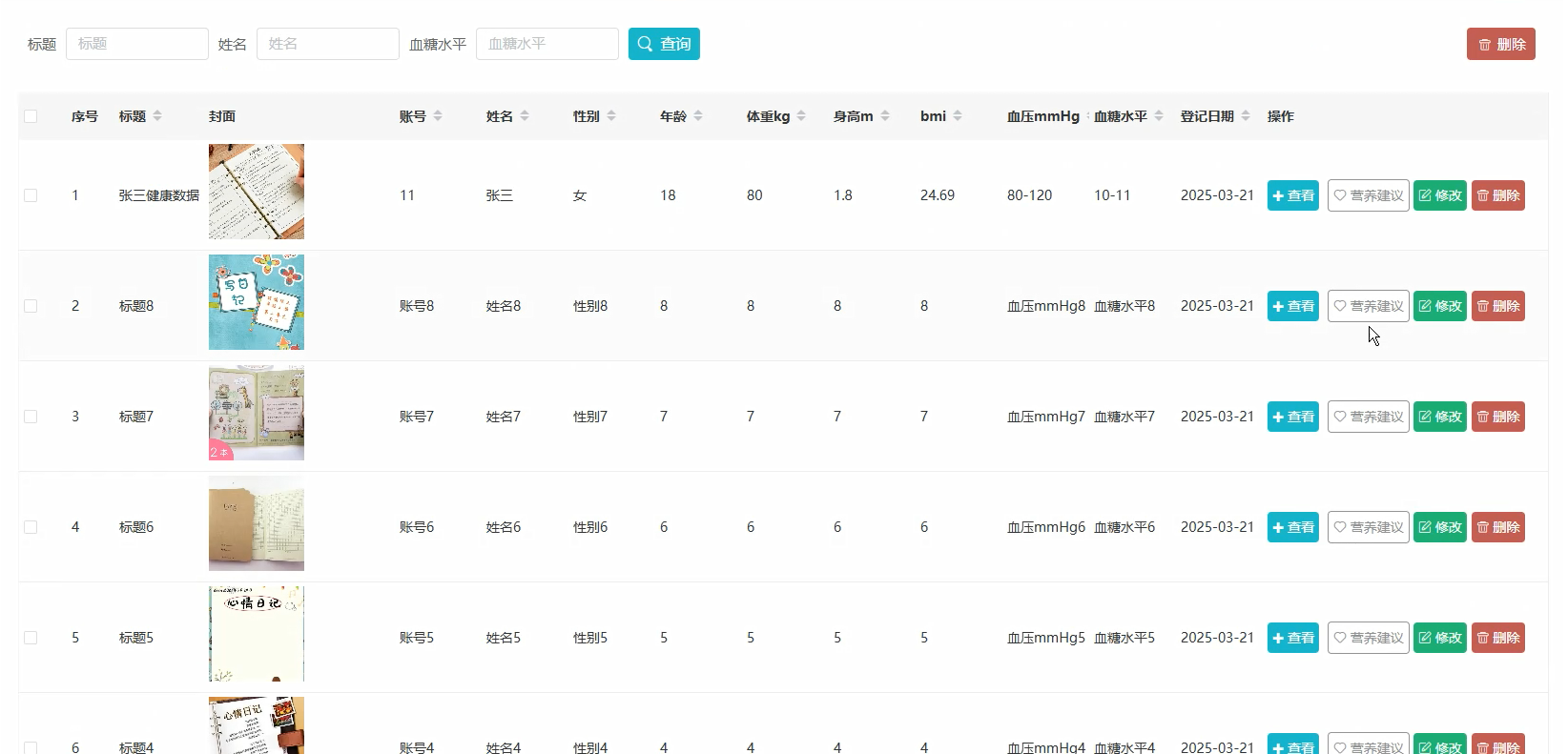
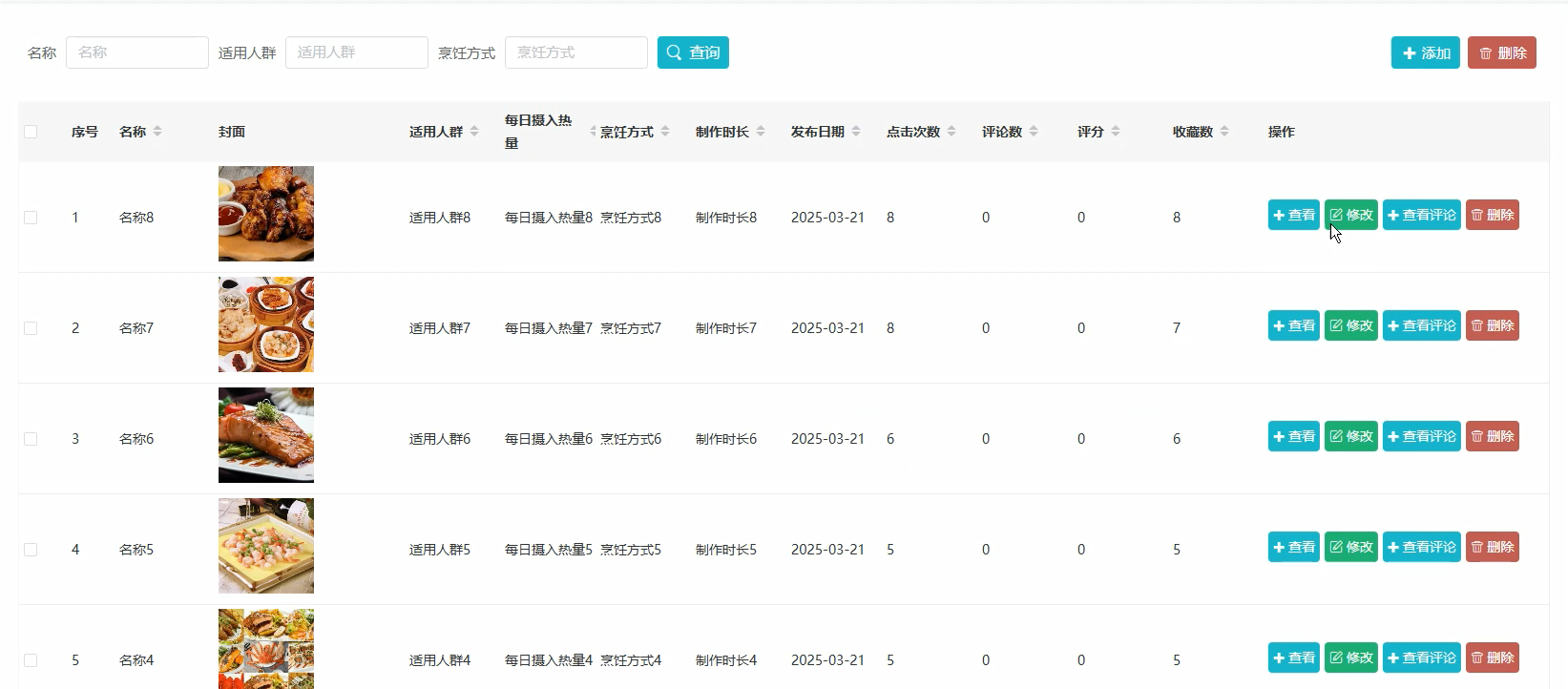
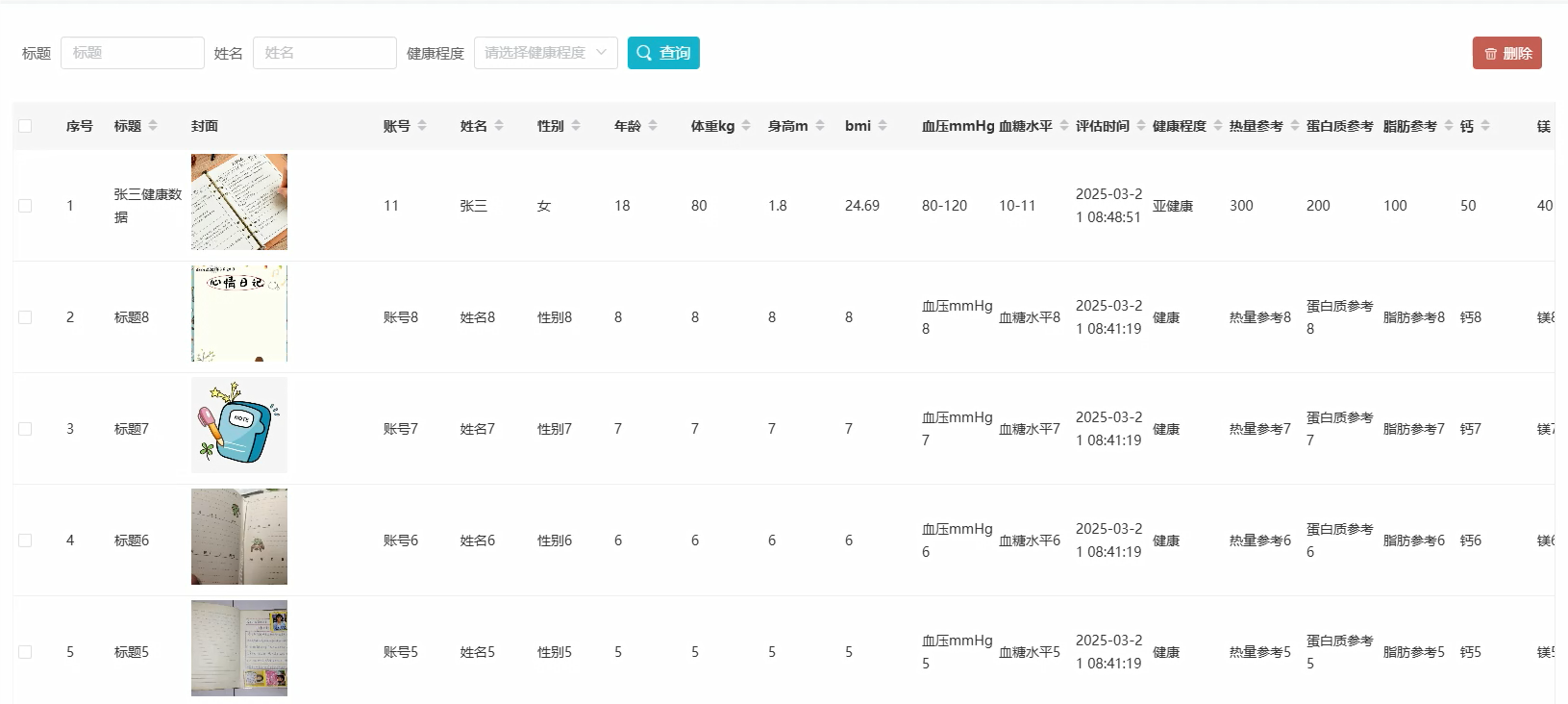
五、代码展示
bash
from pyspark.sql import SparkSession
from django.shortcuts import render, get_object_or_404
from django.http import JsonResponse
from django.contrib.auth.decorators import login_required
from django.views.decorators.csrf import csrf_exempt
from django.db.models import Q, Avg
from .models import FoodInfo, DietPlan, UserHealthData, NutritionSuggestion
import json
import numpy as np
from sklearn.cluster import KMeans
from datetime import datetime, timedelta
spark = SparkSession.builder.appName("DietRecommendation").getOrCreate()
@login_required
@csrf_exempt
def generate_personalized_diet_plan(request):
if request.method == 'POST':
user = request.user
data = json.loads(request.body)
user_weight = data.get('weight', 70)
user_height = data.get('height', 170)
activity_level = data.get('activity_level', 'moderate')
health_goal = data.get('health_goal', 'maintain')
dietary_restrictions = data.get('dietary_restrictions', [])
bmi = user_weight / ((user_height / 100) ** 2)
if bmi < 18.5:
calorie_multiplier = 1.2
elif bmi > 25:
calorie_multiplier = 0.8
else:
calorie_multiplier = 1.0
base_calorie = 1800 if user.profile.gender == 'female' else 2200
if activity_level == 'low':
activity_multiplier = 0.9
elif activity_level == 'high':
activity_multiplier = 1.3
else:
activity_multiplier = 1.0
target_calories = int(base_calorie * calorie_multiplier * activity_multiplier)
available_foods = FoodInfo.objects.exclude(name__in=dietary_restrictions)
breakfast_foods = available_foods.filter(meal_type='breakfast')
lunch_foods = available_foods.filter(meal_type='lunch')
dinner_foods = available_foods.filter(meal_type='dinner')
snack_foods = available_foods.filter(meal_type='snack')
breakfast_selection = breakfast_foods.order_by('?')[:3]
lunch_selection = lunch_foods.order_by('?')[:4]
dinner_selection = dinner_foods.order_by('?')[:4]
snack_selection = snack_foods.order_by('?')[:2]
total_protein = sum([food.protein_per_100g * 1.5 for food in breakfast_selection])
total_protein += sum([food.protein_per_100g * 2.0 for food in lunch_selection])
total_protein += sum([food.protein_per_100g * 2.0 for food in dinner_selection])
total_carbs = sum([food.carb_per_100g * 1.5 for food in breakfast_selection])
total_carbs += sum([food.carb_per_100g * 2.0 for food in lunch_selection])
total_carbs += sum([food.carb_per_100g * 2.0 for food in dinner_selection])
if health_goal == 'lose_weight' and total_calories > target_calories:
portion_adjustment = target_calories / total_calories * 0.9
elif health_goal == 'gain_weight' and total_calories < target_calories:
portion_adjustment = target_calories / total_calories * 1.1
else:
portion_adjustment = 1.0
diet_plan = DietPlan.objects.create(
user=user,
target_calories=target_calories,
breakfast_foods=','.join([str(f.id) for f in breakfast_selection]),
lunch_foods=','.join([str(f.id) for f in lunch_selection]),
dinner_foods=','.join([str(f.id) for f in dinner_selection]),
snack_foods=','.join([str(f.id) for f in snack_selection]),
portion_adjustment=portion_adjustment,
created_date=datetime.now()
)
return JsonResponse({
'status': 'success',
'diet_plan_id': diet_plan.id,
'target_calories': target_calories,
'breakfast_items': len(breakfast_selection),
'lunch_items': len(lunch_selection),
'dinner_items': len(dinner_selection),
'estimated_protein': round(total_protein * portion_adjustment, 1),
'estimated_carbs': round(total_carbs * portion_adjustment, 1)
})
@login_required
@csrf_exempt
def analyze_user_health_data(request):
if request.method == 'POST':
user = request.user
data = json.loads(request.body)
weight = data.get('weight')
blood_pressure_systolic = data.get('bp_systolic')
blood_pressure_diastolic = data.get('bp_diastolic')
heart_rate = data.get('heart_rate')
sleep_hours = data.get('sleep_hours')
exercise_minutes = data.get('exercise_minutes')
water_intake = data.get('water_intake', 2000)
recent_data = UserHealthData.objects.filter(
user=user,
record_date__gte=datetime.now() - timedelta(days=30)
).order_by('-record_date')
health_score = 100
if blood_pressure_systolic > 140 or blood_pressure_diastolic > 90:
health_score -= 15
elif blood_pressure_systolic > 130 or blood_pressure_diastolic > 85:
health_score -= 8
if heart_rate > 100 or heart_rate < 60:
health_score -= 10
if sleep_hours < 7:
health_score -= (7 - sleep_hours) * 5
elif sleep_hours > 9:
health_score -= (sleep_hours - 9) * 3
if exercise_minutes < 150:
health_score -= (150 - exercise_minutes) / 10
if water_intake < 1500:
health_score -= (1500 - water_intake) / 100
elif water_intake > 3000:
health_score -= (water_intake - 3000) / 200
if recent_data.count() >= 5:
weight_trend = []
for record in recent_data[:5]:
weight_trend.append(record.weight)
weight_variance = np.var(weight_trend)
if weight_variance > 4:
health_score -= 5
health_data = UserHealthData.objects.create(
user=user,
weight=weight,
blood_pressure_systolic=blood_pressure_systolic,
blood_pressure_diastolic=blood_pressure_diastolic,
heart_rate=heart_rate,
sleep_hours=sleep_hours,
exercise_minutes=exercise_minutes,
water_intake=water_intake,
health_score=health_score,
record_date=datetime.now()
)
risk_factors = []
if health_score < 70:
risk_factors.append('整体健康状况需要关注')
if blood_pressure_systolic > 130:
risk_factors.append('血压偏高,建议减少钠盐摄入')
if sleep_hours < 7:
risk_factors.append('睡眠不足,影响新陈代谢')
if exercise_minutes < 100:
risk_factors.append('运动量不足,建议增加有氧运动')
return JsonResponse({
'status': 'success',
'health_score': health_score,
'risk_factors': risk_factors,
'trend_analysis': '数据已记录,建议持续监测',
'recommendations': generate_health_recommendations(health_score, recent_data)
})
@login_required
def intelligent_food_category_prediction(request):
user = request.user
user_preferences = DietPlan.objects.filter(user=user).values_list('breakfast_foods', 'lunch_foods', 'dinner_foods')
all_food_preferences = []
for pref in user_preferences:
breakfast_ids = pref[0].split(',') if pref[0] else []
lunch_ids = pref[1].split(',') if pref[1] else []
dinner_ids = pref[2].split(',') if pref[2] else []
all_food_preferences.extend(breakfast_ids + lunch_ids + dinner_ids)
preferred_food_objects = FoodInfo.objects.filter(id__in=all_food_preferences)
category_features = []
for food in preferred_food_objects:
features = [
food.calories_per_100g / 100,
food.protein_per_100g / 50,
food.carb_per_100g / 100,
food.fat_per_100g / 50,
1 if food.is_vegetarian else 0,
1 if food.is_low_sodium else 0,
1 if food.is_high_fiber else 0
]
category_features.append(features)
if len(category_features) >= 3:
kmeans = KMeans(n_clusters=min(3, len(category_features)), random_state=42)
clusters = kmeans.fit_predict(category_features)
cluster_centers = kmeans.cluster_centers_
all_foods = FoodInfo.objects.all()
recommendations = []
for food in all_foods:
if food.id not in [int(x) for x in all_food_preferences if x.isdigit()]:
food_features = np.array([
food.calories_per_100g / 100,
food.protein_per_100g / 50,
food.carb_per_100g / 100,
food.fat_per_100g / 50,
1 if food.is_vegetarian else 0,
1 if food.is_low_sodium else 0,
1 if food.is_high_fiber else 0
])
distances = [np.linalg.norm(food_features - center) for center in cluster_centers]
min_distance = min(distances)
if min_distance < 0.5:
similarity_score = (1 - min_distance) * 100
recommendations.append({
'food_id': food.id,
'food_name': food.name,
'category': food.category,
'similarity_score': round(similarity_score, 2),
'predicted_preference': 'high' if similarity_score > 80 else 'medium'
})
recommendations.sort(key=lambda x: x['similarity_score'], reverse=True)
top_recommendations = recommendations[:10]
else:
popular_foods = FoodInfo.objects.annotate(
avg_rating=Avg('dietplan__user__healthdata__health_score')
).order_by('-avg_rating')[:10]
top_recommendations = []
for food in popular_foods:
top_recommendations.append({
'food_id': food.id,
'food_name': food.name,
'category': food.category,
'similarity_score': 75.0,
'predicted_preference': 'medium'
})
return JsonResponse({
'status': 'success',
'total_analyzed_foods': len(category_features),
'recommendations': top_recommendations,
'prediction_accuracy': 'high' if len(category_features) >= 10 else 'medium',
'algorithm_used': 'k-means_clustering'
})六、项目文档展示

七、总结
基于Django的饮食计划推荐与交流分享平台项目成功地将现代Web开发技术与健康管理需求相结合,构建了一个功能完善的饮食健康管理系统。项目采用Python语言作为核心开发工具,通过Django框架搭建了稳定高效的后端服务架构,配合Vue.js和ElementUI打造了用户友好的前端交互界面,MySQL数据库确保了数据存储的可靠性和查询效率。
该平台的核心价值在于为用户提供个性化的饮食推荐服务,通过智能算法分析用户的身体状况、健康目标和饮食偏好,生成科学合理的饮食计划。系统集成了用户管理、食物信息维护、健康数据追踪、营养建议推送等多项功能模块,形成了完整的健康管理生态。特别是引入机器学习技术实现的食物类别预测功能,能够根据用户历史选择智能推荐相似食物,提升了用户体验的个性化程度。
从技术实现层面来看,项目充分体现了现代软件工程的开发理念,采用前后端分离的架构模式,确保了系统的可维护性和扩展性。通过实际的开发实践,不仅掌握了Web应用开发的核心技能,也深入理解了数据处理、算法应用和用户交互设计的重要性,为今后的技术发展奠定了坚实基础。
大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖