点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月08日更新到: Java-118 深入浅出 MySQL ShardingSphere 分片剖析:SQL 支持范围、限制与优化实践 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节完成的内容如下:
- RDD容错机制
- RDD分区机制
- RDD分区器
- RDD自定义分区器

广播变量
基本介绍
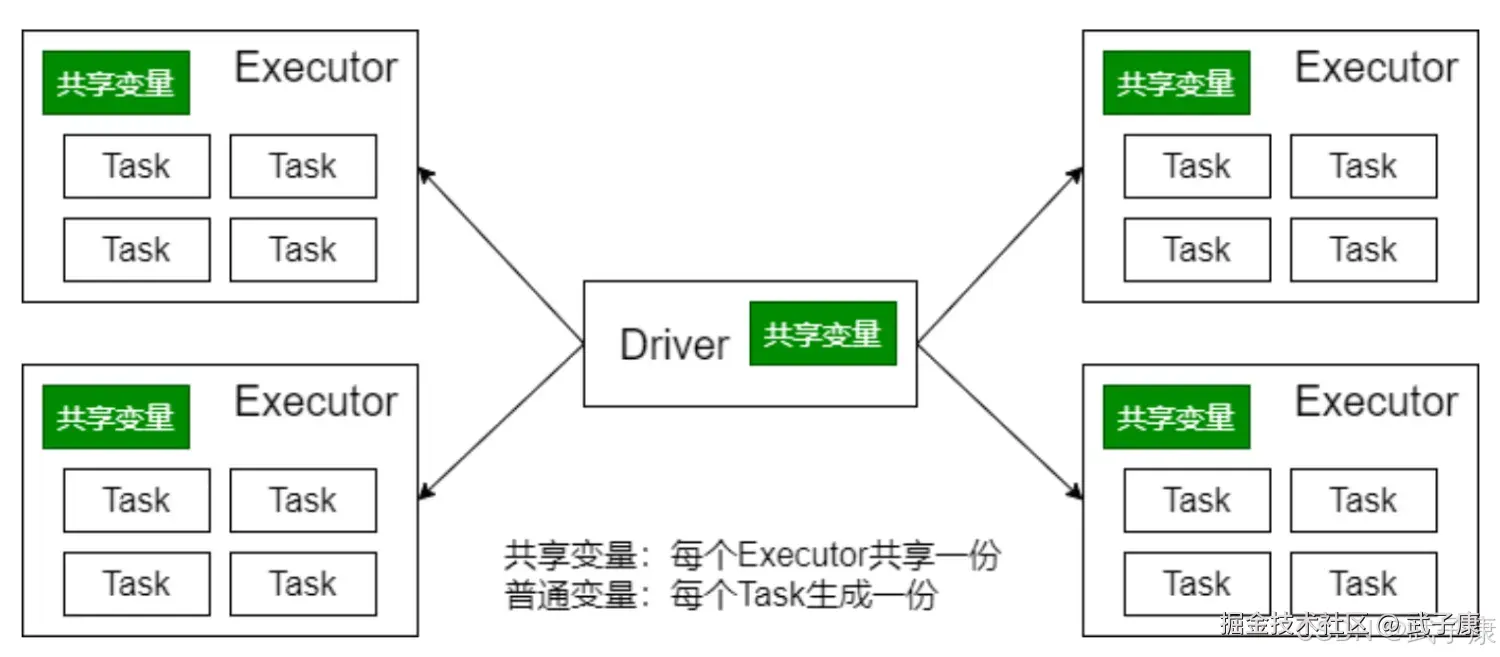
在分布式计算环境中,经常需要在多个任务之间共享变量,或者在任务(Task)和驱动程序(Driver Program)之间传递共享数据。为了满足这个需求并优化Spark程序的性能,Spark提供了两种特殊类型的共享变量机制:
- 广播变量(Broadcast Variables)
- 累加器(Accumulators)
广播变量详解
广播变量的主要设计目的是为了高效地在集群中的各个Executor之间共享较大的只读数据。其工作原理是:由Driver程序将变量值广播到所有工作节点(Executor),每个Executor只需要接收一次该变量的副本,之后所有任务都可以访问这个只读值。
典型应用场景:
- 共享大型的查找表或字典数据
- 分发机器学习模型参数
- 传递配置信息给所有任务
- 在join操作中优化小表的传输
详细使用步骤:
- 创建广播变量(Driver端):
python
# 假设有一个大型字典需要共享
lookup_table = {"key1": "value1", "key2": "value2", ...}
# 创建广播变量
broadcast_var = sc.broadcast(lookup_table)- 访问广播变量(Executor端):
python
# 在任务中通过value属性访问
def process_record(record):
# 获取广播变量的值
table = broadcast_var.value
# 使用广播数据进行处理
return table.get(record.key, default_value)- 广播变量的特点 :
- 只读性:一旦广播后,不能被修改
- 高效传输:使用高效的广播算法(如BitTorrent-like协议)减少网络开销
- 自动清理:当不再需要时,可以调用
unpersist()方法释放资源 - 内存管理:广播变量会存储在Executor的内存中,直到应用程序结束或显式删除
性能优化建议:
- 只广播真正需要共享的数据
- 广播变量的总大小应该控制在GB级别以下
- 对于频繁使用的数据才考虑广播
- 广播前可以考虑压缩数据
示例场景:
假设我们要处理用户日志数据,需要根据用户ID查询用户信息:
python
# Driver端
user_info = {"u001": {"name": "Alice", "age": 25},
"u002": {"name": "Bob", "age": 30}}
broadcast_user = sc.broadcast(user_info)
# 在RDD操作中使用
logs = sc.textFile("user_logs.txt")
enhanced_logs = logs.map(lambda log: {
"log": log,
"user_info": broadcast_user.value.get(extract_user_id(log), {})
})广播变量通过减少数据的重复传输,显著提高了分布式计算的效率,特别是在需要频繁访问共享数据的场景下效果尤为明显。
 广播变量的相关参数详解:
广播变量的相关参数详解:
-
spark.broadcast.blockSize(缺省值:4m)
- 功能说明:控制广播变量在传输过程中被分割成的块大小
- 取值范围:支持k(千字节)、m(兆字节)、g(千兆字节)等单位
- 应用场景:当广播较大数据(如超过1GB的查找表)时,可考虑增大此值以减少网络开销
- 示例:设置为"8m"可提高大变量传输效率,但会占用更多内存
-
spark.broadcast.checksum(缺省值:true)
- 功能说明:是否启用广播变量的校验和检查
- 工作原理:在传输过程中计算校验和来确保数据完整性
- 性能影响:启用后会增加少量CPU开销(约1-3%)
- 使用建议:在可靠网络环境中可设为false以获得更高性能
-
spark.broadcast.compress(缺省值:true)
- 功能说明:控制是否压缩广播变量
- 压缩算法:默认使用Snappy压缩
- 压缩效果:对文本数据通常可减少50-70%体积
- 典型用例:当广播大型数据集(如机器学习特征映射表)时特别有效
- 注意事项:对已压缩数据(如JPEG图像)可能适得其反
最佳实践建议:
- 对于小于100MB的数据,保持默认参数即可
- 对于GB级数据,可考虑:
- 增大blockSize到16m-32m
- 保持checksum为true以确保数据可靠性
- 对结构化数据保持compress开启
变量应用
普通JOIN
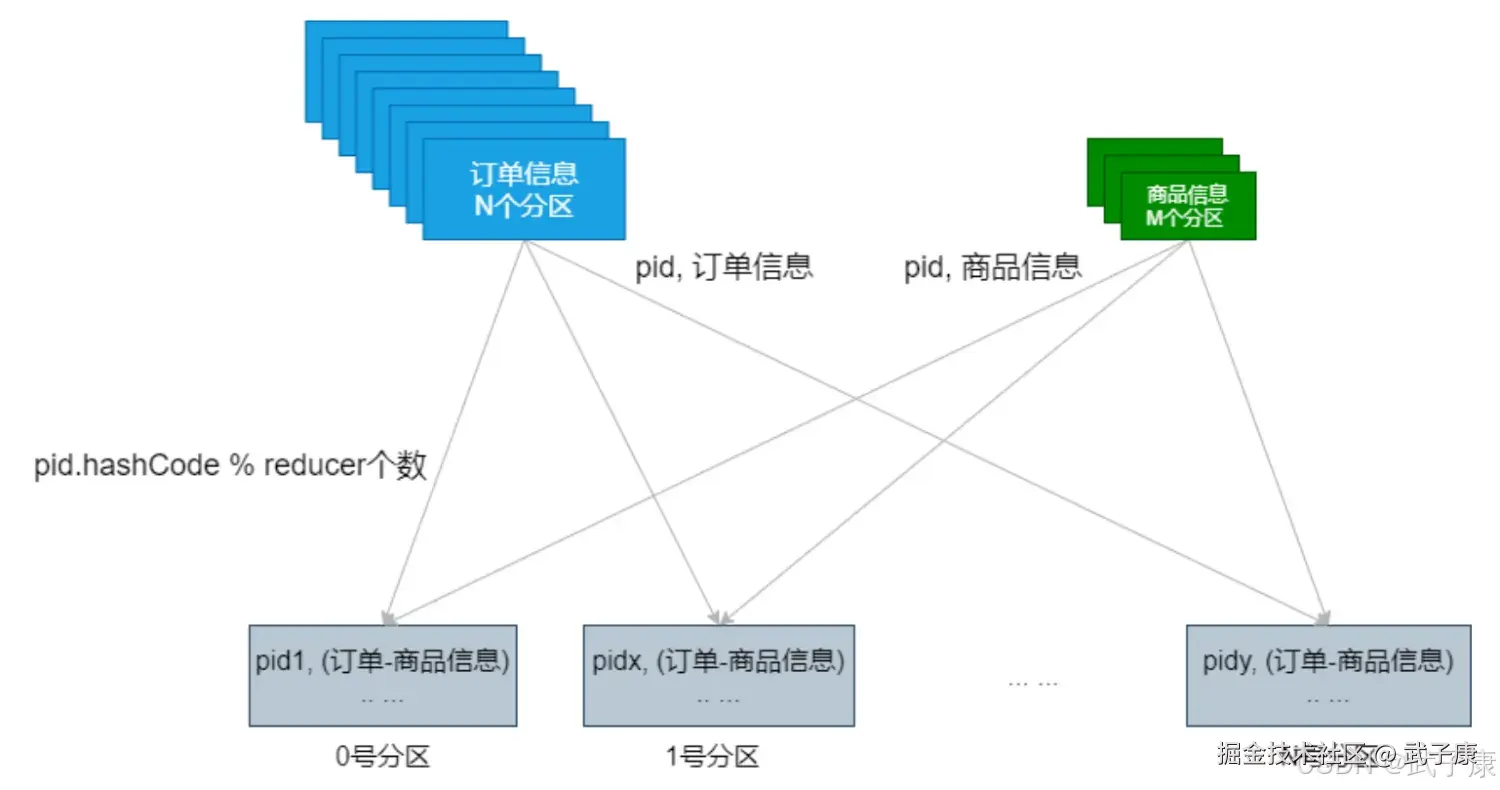
MapSideJoin
生成数据 test_spark_01.txt
shell
1000;商品1
1001;商品2
1002;商品3
1003;商品4
1004;商品5
1005;商品6
1006;商品7
1007;商品8
1008;商品9生成数据格式如下: 
生成数据 test_spark_02.txt
shell
10000;订单1;1000
10001;订单2;1001
10002;订单3;1002
10003;订单4;1003
10004;订单5;1004
10005;订单6;1005
10006;订单7;1006
10007;订单8;1007
10008;订单9;1008生成的数据格式如下: 
编写代码1
我们编写代码进行测试
scala
package icu.wzk
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object JoinDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("JoinDemo")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.hadoopConfiguration.setLong("fs.local.block.size", 128 * 1024 * 1024)
val productRDD: RDD[(String, String)] = sc
.textFile("data/test_spark_01.txt")
.map {
line => val fields = line.split(";")
(fields(0), line)
}
val orderRDD: RDD[(String, String)] = sc
.textFile("data/test_spark_02.txt", 8)
.map {
line => val fields = line.split(";")
(fields(2), line)
}
val resultRDD = productRDD.join(orderRDD)
println(resultRDD.count())
Thread.sleep(100000)
sc.stop()
}
}编译打包1
shell
mvn clean package并上传到服务器,准备运行 
运行测试1
shell
spark-submit --master local[*] --class icu.wzk.JoinDemo spark-wordcount-1.0-SNAPSHOT.jar提交任务并执行,注意数据的路径,查看下图:  运行结果可以查看到,运行了: 2.203100 秒 (取决于你的数据量的多少)
运行结果可以查看到,运行了: 2.203100 秒 (取决于你的数据量的多少) 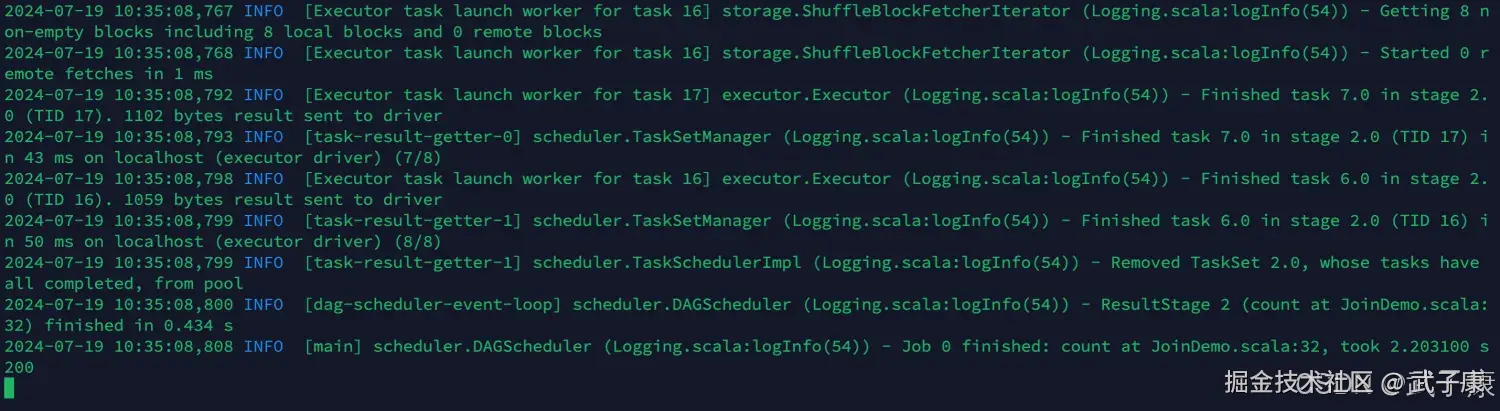
shell
2024-07-19 10:35:08,808 INFO [main] scheduler.DAGScheduler (Logging.scala:logInfo(54)) - Job 0 finished: count at JoinDemo.scala:32, took 2.203100 s
200编写代码2
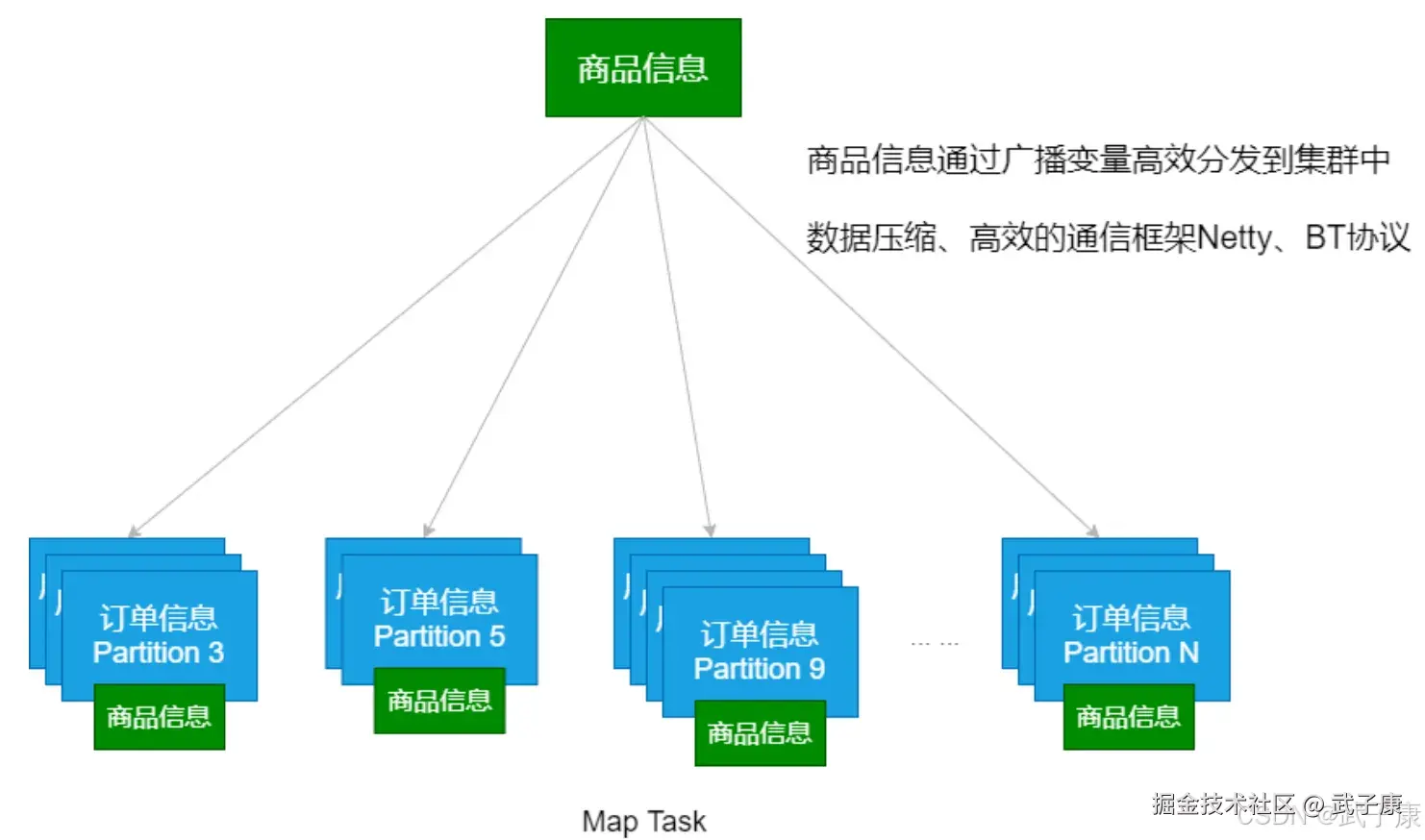
接下来,我们对比使用 MapSideJoin 的方式
scala
package icu.wzk
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object MapSideJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("MapSideJoin")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.hadoopConfiguration.setLong("fs.local.block.size", 128 * 1024 * 1024)
val productRDD: RDD[(String, String)] = sc
.textFile("data/test_spark_01.txt")
.map {
line => val fields = line.split(";")
(fields(0), line)
}
val productBC = sc.broadcast(productRDD.collectAsMap())
val orderRDD: RDD[(String, String)] = sc
.textFile("data/test_spark_02.txt")
.map {
line => val fields = line.split(";")
(fields(2), line)
}
val resultRDD = orderRDD
.map {
case (pid, orderInfo) =>
val productInfo = productBC.value
(pid, (orderInfo, productInfo.getOrElse(pid, null)))
}
println(resultRDD.count())
sc.stop()
}
}编译打包2
shell
mvn clean package编译后上传到服务器准备执行: 
运行测试2
shell
spark-submit --master local[*] --class icu.wzk.MapSideJoin spark-wordcount-1.0-SNAPSHOT.jar启动我们的程序,并观察结果  我们可以观察到,这次只用了 0.10078 秒就完成了任务:
我们可以观察到,这次只用了 0.10078 秒就完成了任务: 
累加器
基本介绍
累加器的作用:可以实现一个变量在不同的Executor端能保持状态的累加。 累加器在Driver端定义、读取,在Executor中完成累加。 累加器也是Lazy的,需要Action触发:Action触发一次,执行一次;触发多次,执行多次。
Spark内置了三种类型的累加器,分别是:
- LongAccumulator 用来累加整数型
- DoubleAccumulator 用来累加浮点型
- CollectionAccumulator 用来累加集合元素
运行测试
我们可以在 SparkShell 中进行一些简单的测试,目前我在 h122 节点上,启动SparkShell
shell
spark-shell --master local[*]启动的主界面如下:  写入如下的内容进行测试:
写入如下的内容进行测试:
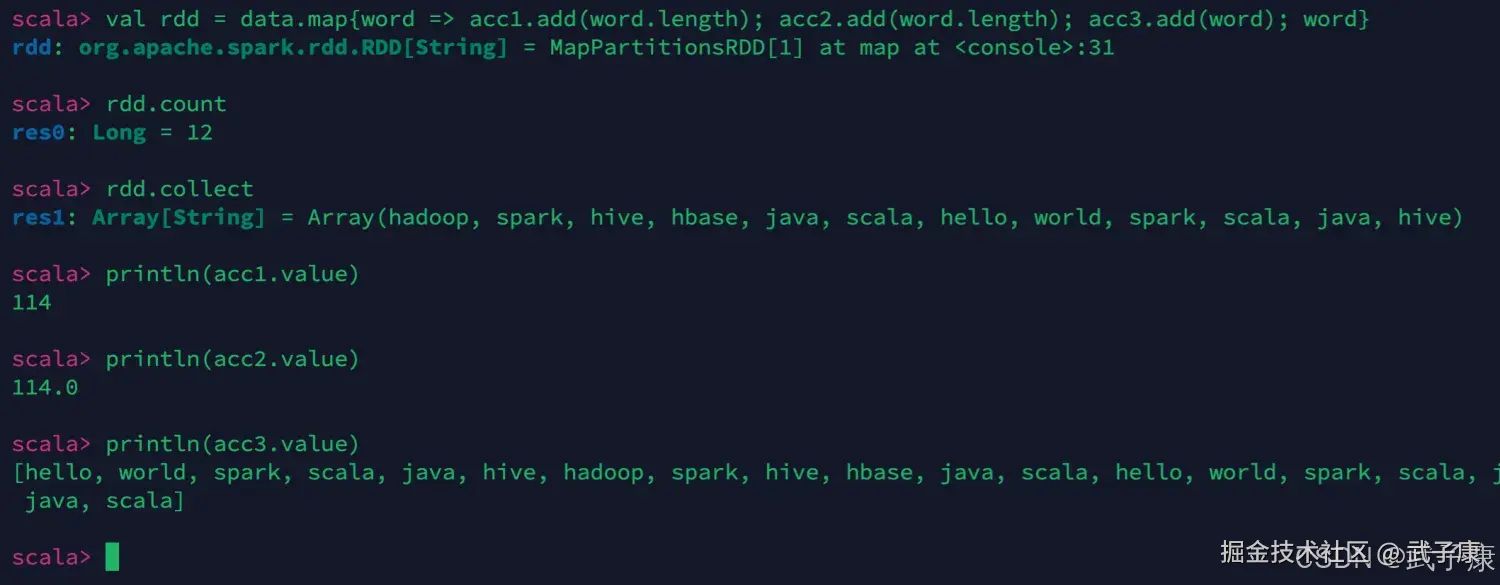
shell
val data = sc.makeRDD("hadoop spark hive hbase java scala hello world spark scala java hive".split("\\s+"))
val acc1 = sc.longAccumulator("totalNum1")
val acc2 = sc.doubleAccumulator("totalNum2")
val acc3 = sc.collectionAccumulator[String]("allwords")我们进行测试的结果如下图所示: 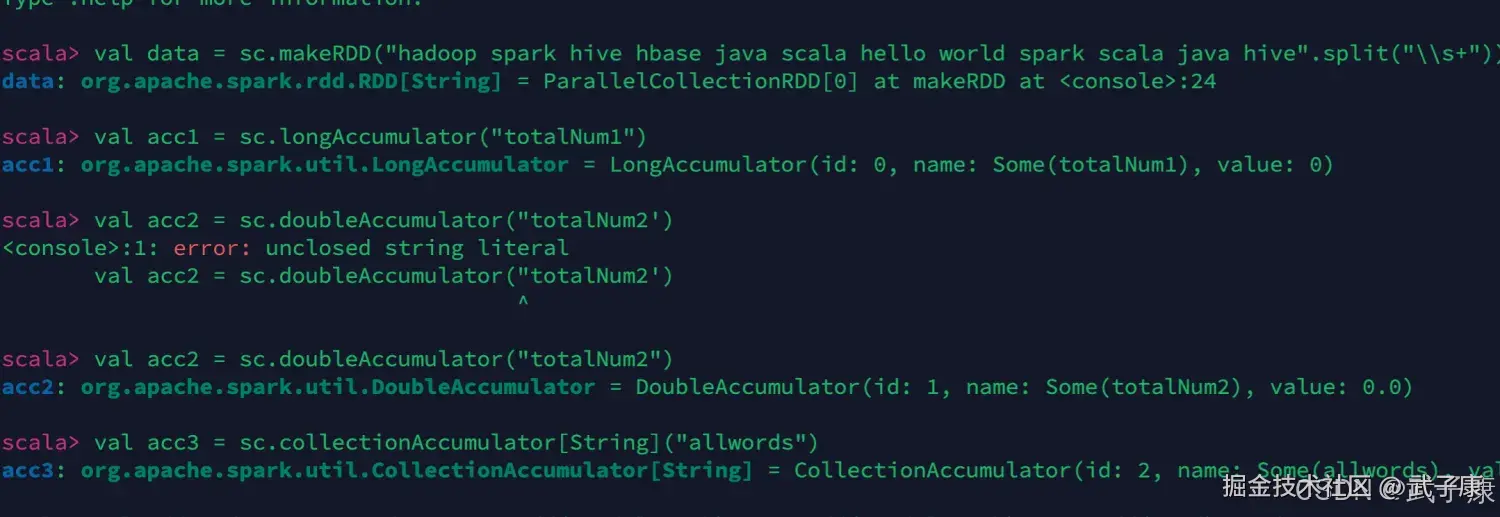 继续编写一段进行测试:
继续编写一段进行测试:
shell
val rdd = data.map{word => acc1.add(word.length); acc2.add(word.length); acc3.add(word); word}
rdd.count
rdd.collect
println(acc1.value)
println(acc2.value)
println(acc3.value)我们进行测试的结果如下: