1 Redis 7 有哪些数据结构?
-
Redis 7 的数据结构,可分为核心版和扩展版两类;
-
核心版数据结构(9 种)
-
Bitmap(位图):本质是按位存储的数组,可对二进制位进行操作,常用于统计用户在线状态、签到情况等场景,能高效地进行位级别的查询与修改;
-
Geospatial indices(地理空间索引):支持存储地理位置信息,可实现诸如计算两点间距离、查找指定范围内的地理位置等功能,适用于地图类应用等场景;
-
Hash(哈希):用于存储键值对集合,每个哈希可以存储多个字段和值的映射,适合表示对象类的数据,比如存储用户信息,每个用户的不同属性作为字段和对应值;
-
HyperLogLog:是一种概率数据结构,用于近似计算集合的基数(元素数量),能以极小的空间开销统计大量数据的数量;
-
List(列表):是有序的字符串列表,支持在两端进行元素的插入和删除操作,可用于实现消息队列、最新内容展示等功能;
-
Set(集合):是无序且不重复的字符串集合,支持集合的交集、并集、差集等操作,可用于实现好友关系、标签等功能;
-
Sorted set(有序集合):类似集合,但每个元素都关联一个分数,元素会根据分数进行排序,可用于实现排行榜等功能;
-
Stream(流):是一种持久化的消息队列数据结构,支持消息的追加、消费组等功能,适用于需要可靠消息传递的场景;
-
String(字符串):是最基本的数据结构,可存储字符串、数字等类型的数据,支持常见的增删改查等操作;
-
-
扩展版数据结构
-
Bloom filter(布隆过滤器):是一种空间效率很高的概率型数据结构,用于判断一个元素是否在集合中,存在一定的误判率,但能大大减少对实际数据的查询次数;
-
Cuckoo filter(布谷鸟过滤器):是布隆过滤器的改进版,支持删除操作,在空间效率和查询性能上也有不错的表现;
-
Count - min sketch(计数型概略图):用于频率统计,能以较小的空间开销估计元素的出现频率;
-
JSON:支持对 JSON 格式数据的存储和操作,方便处理复杂的结构化数据;
-
Search and query(搜索与查询):提供了强大的搜索和查询能力,可对数据进行复杂的检索操作;
-
Auto - suggest(自动建议):用于实现自动补全、推荐等功能,提升用户体验;
-
T - digest:用于高效地计算数据的分位数,在大数据量的统计分析场景中很有用;
-
Time series(时间序列):专门用于存储和处理时间序列数据,如监控数据、传感器数据等,支持按时间范围的查询等操作;
-
Top - k:用于快速获取出现频率最高的前 k 个元素,适用于热点数据统计等场景。
-
2 help指令

help @<group>:可以获取指定命令组(<group>)中的命令列表;help <command>:能获取关于特定命令(<command>)的帮助内容;help <tab>:按下Tab键,会得到可能的帮助主题列表;quit:输入该命令,可退出 Redis 命令行界面。
3 String 结构
-
字符串常用操作:
SET key value:存入字符串键值对,用于将指定的value与key关联存储;MSET key value [key value ...]:批量存储多个字符串键值对,可一次性设置多组key - value;SETNX key value:存入一个不存在的字符串键值对,只有当key不存在时,才会设置key的值;GET key:获取一个字符串键值,根据key获取对应的value;MGET key [key ...]:批量获取多个字符串键值,可一次性获取多个key对应的value;DEL key [key ...]:删除一个或多个键,将指定的key从 Redis 中删除;EXPIRE key seconds:设置一个键的过期时间(单位为秒),经过指定秒数后,key会自动失效;
-
原子加减:
INCR key:将key中储存的数字值加 1,若key对应的值不是数字或不存在,会有相应处理(如初始为 0 再加 1);DECR key:将key中储存的数字值减 1,类似INCR但为减法操作;INCRBY key increment:将key所储存的值加上increment,可指定增加的数值;DECRBY key decrement:将key所储存的值减去decrement,可指定减少的数值;
-
常见应用场景
-
单值缓存:
- 使用
SET key value,直接存储单个键值对,进行单值的缓存; - 使用
APPEND key value,可在已有的key对应的字符串后追加内容;
- 使用
-
对象缓存:有两种方式
- 一种是将对象序列化为一个字符串,用
SET存储,如set user:1 '{"name":"roy","balance":1888}'; - 另一种是将对象的各个字段分别存储,用
MSET批量设置,再用MGET批量获取,如MSET user:1:name roy user:1:balance 1888,然后MGET user:1:name user:1:balance;
- 一种是将对象序列化为一个字符串,用
-
分布式锁:
- 利用
SETNX命令,SETNX product:10001 true,当返回 1 时代表获取锁成功,返回 0 代表获取锁失败; - 获取锁后执行业务操作,完成后用
DEL product:10001释放锁; - 还可以用
SET product:10001 true ex 10 nx这种方式,设置锁的同时指定过期时间(10 秒),防止程序意外终止导致死锁,确保锁能自动释放。
- 利用
-
4 Hash 结构
-
Hash 结构是通过
key关联多个field - value对,就像一个包含多个键值对的小字典: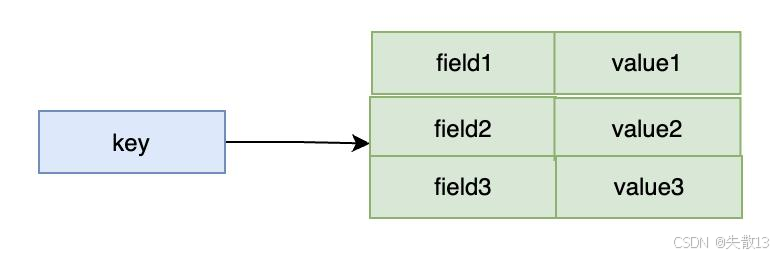
-
常用操作如下:
-
HSET key field value:存储一个哈希表key下的field - value键值对; -
HSETNX key field value:仅当哈希表key中不存在field时,才存储该field - value; -
HMSET key field value [field value ...]:在一个哈希表key中批量存储多个field - value键值对; -
HGET key field:获取哈希表key中对应field的值; -
HMGET key field [field ...]:批量获取哈希表key中多个field的值; -
HDEL key field [field ...]:删除哈希表key中的一个或多个field键值; -
HLEN key:返回哈希表key中field的数量; -
HGETALL key:返回哈希表key中所有的field - value键值对; -
HINCRBY key field increment:为哈希表key中field键的值加上增量increment(若值为数字);
-
-
应用场景
-
对象缓存:
-
可将对象的多个属性作为
field,对应属性值作为value存储在哈希表中; -
比如存储用户信息,用
HSET user:1 name roy balance 1888存储用户1的姓名和余额,再用HMGET user:1 name balance获取这些信息;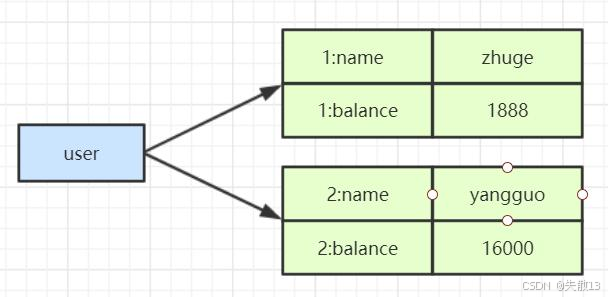
-
也可以用类似
user 1:name这样的field更细致区分;
-
-
电商购物车:
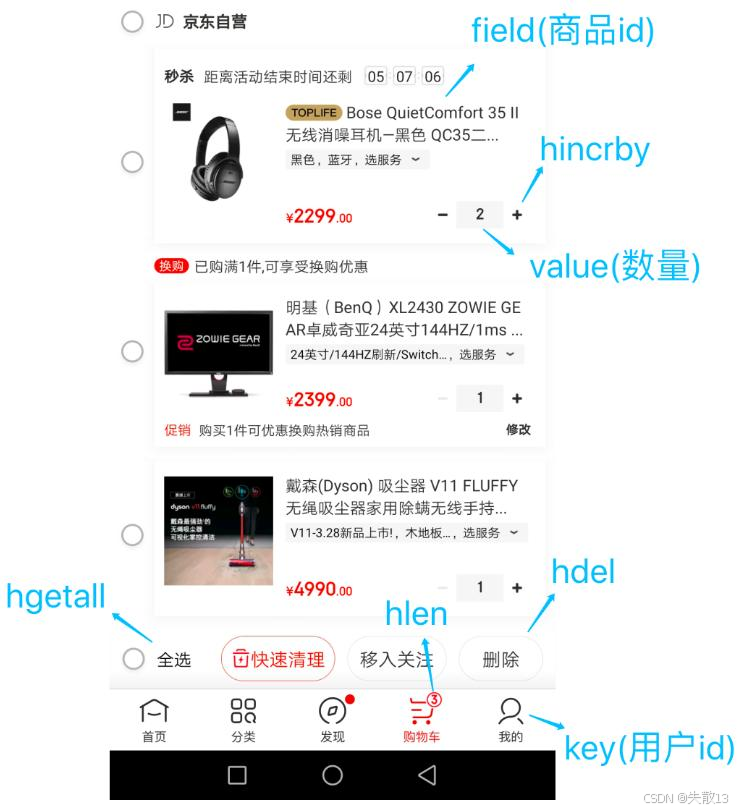
- 以用户
id为key,商品id为field,商品数量为value; - 购物车操作:
- 添加商品:
hset cart:1001 10088 1,表示用户1001的购物车中添加商品10088,数量为1; - 增加数量:
hincrby cart:1001 10088 1,将用户1001购物车中商品10088的数量加1; - 商品总数:
hlen cart:1001,获取用户1001购物车中商品的总数(即field的数量); - 删除商品:
hdel cart:1001 10088,删除用户1001购物车中商品10088; - 获取购物车所有商品:
hgetall cart:1001,获取用户1001购物车中所有商品的field - value(商品id - 数量);
- 添加商品:
- 以用户
-
-
Hash 结构优缺点
-
优点:
- 同类数据归类整合存储,方便数据管理,比如将对象的多个属性集中在一个哈希表中;
- 相比 String 操作,消耗的内存与 CPU 更小,因为对哈希表的操作更集中,减少了键的数量等因素;
- 相比 String 存储更节省空间,能更高效地利用内存存储多组键值对;
-
缺点:
- 过期功能只能用在
key上,不能单独对field设置过期时间,若需要部分字段过期,无法直接实现; - 在 Redis 集群架构下不适合大规模使用,因为哈希表的
key分布等问题,可能不利于集群的高效运作。
- 过期功能只能用在
-
5 List 类型
-
常用操作:
-
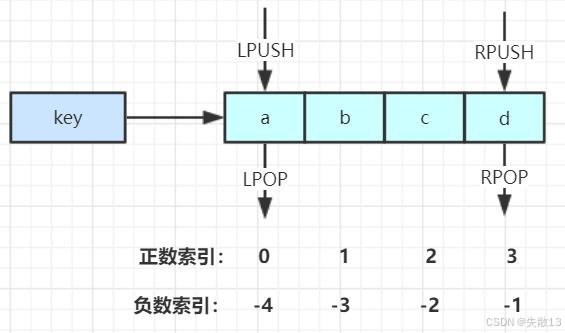
LPUSH key value [value ...]:将一个或多个值value插入到key列表的表头(最左边); -
RPUSH key value [value ...]:将一个或多个值value插入到key列表的表尾(最右边); -
LPOP key:移除并返回key列表的表头元素; -
RPOP key:移除并返回key列表的表尾元素; -
LRANGE key start stop:返回列表key中指定区间内的元素,区间以偏移量start和stop指定; -
BLPOP key [key ...] timeout:从key列表表头弹出一个元素,若列表中没有元素,阻塞等待timeout秒;如果timeout = 0,则一直阻塞等待; -
BRPOP key [key ...] timeout:从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待timeout秒;如果timeout = 0,则一直阻塞等待;
-
-
常用数据结构:
- Stack(栈) :通过
LPUSH(表头插入)和LPOP(表头弹出),实现后进先出(LIFO)的栈结构; - Queue(队列) :利用
LPUSH(表头插入)和RPOP(表尾弹出),实现先进先出(FIFO)的队列结构; - Blocking MQ(阻塞队列) :借助
LPUSH(表头插入)和BRPOP(表尾阻塞弹出),实现带有阻塞等待功能的队列,适用于消息队列等场景,当队列无消息时,消费者会阻塞等待;
- Stack(栈) :通过
-
常见应用场景:可用于视频列表(按顺序存储视频标识等)、签到列表(记录用户签到顺序)、排队机(管理排队顺序)以及简化版的消息队列(MQ)等场景;
-
注意:
-
一个
list的容量是 (2^{32}-1) 个元素,大概 40 多亿,但在实际应用时,要注意大key问题,大key可能会影响 Redis 的性能,比如占用过多内存、导致操作延迟等; -
list的底层是一个双向链表,对双端(表头和表尾)的操作性能很高,因为只需要操作链表的头尾节点。但通过索引下标直接操作某一个中间节点的性能就会比较低,因为需要从链表头或尾遍历到目标节点,遍历过程会带来额外的时间开销;
-
6 Set 类型
-
常用操作:
- 基本操作 :
SADD key member [member ...]:往集合key中存入元素,若元素已存在则忽略,若key不存在则新建集合;SREM key member [member ...]:从集合key中删除指定元素;SMEMBERS key:获取集合key中所有元素;SCARD key:获取集合key的元素个数;SISMEMBER key member:判断member元素是否存在于集合key中;SRANDMEMBER key [count]:从集合key中选出count个元素,元素不从key中删除;SPOP key [count]:从集合key中选出count个元素,元素从key中删除;
- 集合运算 :
SINTER key [key ...]:对多个集合进行交集运算,得到共同元素组成的集合;SINTERSTORE destination key [key ...]:将交集运算结果存入新集合destination中;SUNION key [key ...]:对多个集合进行并集运算,得到所有元素组成的集合(无重复);SUNIONSTORE destination key [key ...]:将并集运算结果存入新集合destination中;SDIFF key [key ...]:对多个集合进行差集运算,得到在第一个集合中但不在其他集合中的元素组成的集合;SDIFFSTORE destination key [key ...]:将差集运算结果存入新集合destination中;
- 基本操作 :
-
应用场景:
- 微信抽奖小程序 :
- 用户点击参与抽奖时,用
SADD key [userId]将用户 ID 加入集合; - 查看参与抽奖的所有用户,使用
SMEMBERS key获取集合中所有元素(用户 ID); - 抽取
count名中奖者,可通过SRANDMEMBER key [count](抽取后元素仍在集合)或SPOP key [count](抽取后元素从集合删除)实现;
- 用户点击参与抽奖时,用
- 微信微博点赞、收藏、标签 :
- 点赞:用
SADD like:{消息ID} {用户ID}将点赞用户 ID 加入对应消息的点赞集合; - 取消点赞:通过
SREM like:{消息ID} {用户ID}从点赞集合中删除用户 ID; - 检查用户是否点过赞:利用
SISMEMBER like:{消息ID} {用户ID}判断用户 ID 是否在点赞集合中; - 获取点赞的用户列表:使用
SMEMBERS like:{消息ID}获取点赞集合中所有用户 ID; - 获取点赞用户数:通过
SCARD like:{消息ID}获取点赞集合的元素个数(即点赞人数);
- 点赞:用
- 集合操作(社交关系类) :
- 共同关注的人:对多个用户的关注集合进行
SINTER交集运算,得到共同关注的用户; - 朋友圈的人:对多个用户的相关集合进行
SUNION并集运算,得到朋友圈涉及的用户; - 推荐好友:对集合进行
SDIFF差集运算,得到可推荐的好友。
- 共同关注的人:对多个用户的关注集合进行
- 微信抽奖小程序 :
7 ZSet 类型
-
常用操作:
- 基本操作 :
ZADD key score member [[score member]...]:往有序集合key中加入带分值的元素,score为元素的分值,用于排序;ZREM key member [member ...]:从有序集合key中删除指定元素;ZSCORE key member:返回有序集合key中元素member的分值;ZINCRBY key increment member:为有序集合key中元素member的分值加上increment,可用于动态调整元素的排序权重;ZCARD key:返回有序集合key中元素的个数;ZRANGE key start stop [WITHSCORES]:正序获取有序集合key从start下标到stop下标的元素,若指定WITHSCORES,则同时返回元素的分值;ZREVRANGE key start stop [WITHSCORES]:倒序获取有序集合key从start下标到stop下标的元素,同样可指定WITHSCORES返回分值;
- 集合运算 :
ZUNIONSTORE destkey numkeys key [key ...]:对多个有序集合进行并集计算,将结果存入destkey中,numkeys指定参与并集的集合数量;ZINTERSTORE destkey numkeys key [key ...]:对多个有序集合进行交集计算,结果存入destkey中;
- 基本操作 :
-
应用场景(以实现新闻热度排行榜为例):
-
点击新闻 :当用户点击某个新闻时,使用
ZINCRBY hotNews:20190819 1 新闻名,为该新闻的分值加 1,以此记录点击热度; -
展示当日排行前十 :通过
ZREVRANGE hotNews:20190819 0 9 WITHSSCORES,倒序获取当日(hotNews:20190819是对应的日期)有序集合中前 10 名的新闻及对应的分值(热度); -
七日搜索榜单计算 :利用
ZUNIONSTORE hotNews:20190813-20190819 7 hotNews:20190813 hotNews:20190814... hotNews:20190819,对 7 天(从 20190813 到 20190819)的新闻有序集合进行并集计算,将结果存入hotNews:20190813-20190819中,合并 7 天的热度数据; -
展示七日排行前十 :使用
ZREVRANGE hotNews:20190813-20190819 0 9 WITHSSCORES,倒序获取合并后的 7 天有序集合中前 10 名的新闻及分值,展示七日热度排行。
-
8 Bitmap 类型

-
常用操作:
SETBIT key offset value:将一个二进制数组(该数组以key标识)的offset位置设置为value,其中value只能是 0 或者 1,用于标记某个位置的状态;GETBIT key offset:返回二进制数组(key对应的)offset位置的值,用于获取某个位置的状态;BITCOUNT key [start end [BYTE|BIT]]:返回二进制数组中 1 的个数,可指定范围(start和end)以及计数单位(字节BYTE或位BIT),用于统计状态为 1 的数量;BITPOS key bit [start [end [BYTE|BIT]]]:返回bitmap中第一个值为bit(0 或 1)的offset位置,可指定范围和单位,用于查找特定状态首次出现的位置;BITOP AND|OR|XOR|NOT destkey key [key ...]:对两个bitmap进行二进制的与(AND)、或(OR)、异或(XOR)、非(NOT)计算,结果存入destkey中,用于进行位图间的逻辑运算;
-
应用场景(以每日签到为例):
- 当 1 号用户第 100 天完成签到时,使用
SETBIT dailycheck:1 100 1,将dailycheck:1这个位图的第 100 位设置为 1,标记该用户当天签到; - 统计 1 号用户的签到次数,通过
BITCOUNT dailycheck:1,统计该位图中 1 的个数,即为签到次数; - 统计 1 号用户第一天签到的时间,利用
BITPOS dailycheck:1,查找该位图中第一个为 1 的offset位置,对应的就是第一天签到的天数;
- 当 1 号用户第 100 天完成签到时,使用
-
Bitmap 优点:具有快速、高效、节省空间的特点,因为位图是按位存储,能以极小的空间存储大量的布尔型状态信息,且位操作的效率很高。
9 Hyperloglog 类型
-
HyperLogLog 用于统计一个集合中不重复的元素个数。典型的应用场景是根据用户访问记录统计网站的 UV(Unique Visitor,独立访客),也就是统计有多少不同的用户访问了网站;
-
常用操作:
-
PFADD visitlog 192.168.65.111 192.168.65.112 192.168.65.111:向名为visitlog的 HyperLogLog 结构中添加用户访问记录(这里用 IP 地址模拟用户),重复的 IP 地址(如192.168.65.111)只会被统计一次; -
PFCOUNT visitlog:统计visitlog中不同的独立访客数量,也就是集合中不重复元素的个数;
-
-
其他操作 :
PFMERGE destkey [sourcekey [sourcekey ...]]:将多个 HyperLogLog 数据整合到destkey对应的一条记录中,这样可以对多个 HyperLogLog 统计的结果进行合并统计。
10 Geo 类型
-
常用操作:
-
GEOADD key [NX|XX] [CH] longitude latitude member [longitude latitude member ...]:向指定的key中添加一个或多个地理位置信息,包括经度(longitude)、纬度(latitude)以及对应的地点标识(member); -
GEOPOS key [member [member ...]]:返回key中指定地点标识(member)对应的经纬度信息; -
GEODIST key member1 member2 [M|KM|FT|MI]:计算key中两个地点(member1和member2)之间的距离,可指定距离单位(米M、千米KM、英尺FT、英里MI); -
GEORADIUS key longitude latitude radius M|KM|FT|MI [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC|DESC] [STORE key|STOREDIST key]:根据给定的经纬度(longitude、latitude)和半径(radius),查询该区域附近的地点,还可指定返回经纬度(WITHCOORD)、距离(WITHDIST)、哈希值(WITHHASH)等,以及结果的数量(COUNT)、排序(ASC升序、DESC降序)和存储方式等; -
GEOSEARCH key FROMMEMBER member|FROMLONLAT longitude latitude BYRADIUS radius M|KM|FT|MI|BYBOX width height M|KM|FT|MI [ASC|DESC] [COUNT count [ANY]] [WITHCOORD] [WITHDIST] [WITHHASH]:查询指定地点(FROMMEMBER指定member)或经纬度(FROMLONLAT指定经纬度)附近的地点,可通过半径(BYRADIUS)或矩形范围(BYBOX)来限定区域,同时也能指定返回额外信息、排序和数量等;
-
-
应用场景:
-
获取经纬度 :可以通过类似
https://api.map.baidu.com/lbsapi/getpoint/index.html这样的接口来获取地点的经纬度信息,为后续 Geo 操作提供数据基础; -
添加商家地址 :例如使用
GEOADD changsha 113.017489 28.200454 火车站 112.96903 28.201195 橘子洲 113.017031 28.199706 赛格广场 113.017004 28.197677 国储,向changsha这个key中添加长沙的火车站、橘子洲、赛格广场、国储等地点的经纬度和标识; -
查询距离 :用
GEODIST changsha 火车站 橘子洲 M可以计算长沙的火车站和橘子洲之间的距离,单位为米; -
查找附近景点 :通过
GEORADIUSBYMEMBER changsha 火车站 2 KM withdist withcoord count 4 withhash,查询长沙火车站 2 千米范围内的景点,同时返回距离、经纬度、哈希值等信息,且最多返回 4 个结果,这在类似外卖应用中查找附近商家等场景很有用。
-
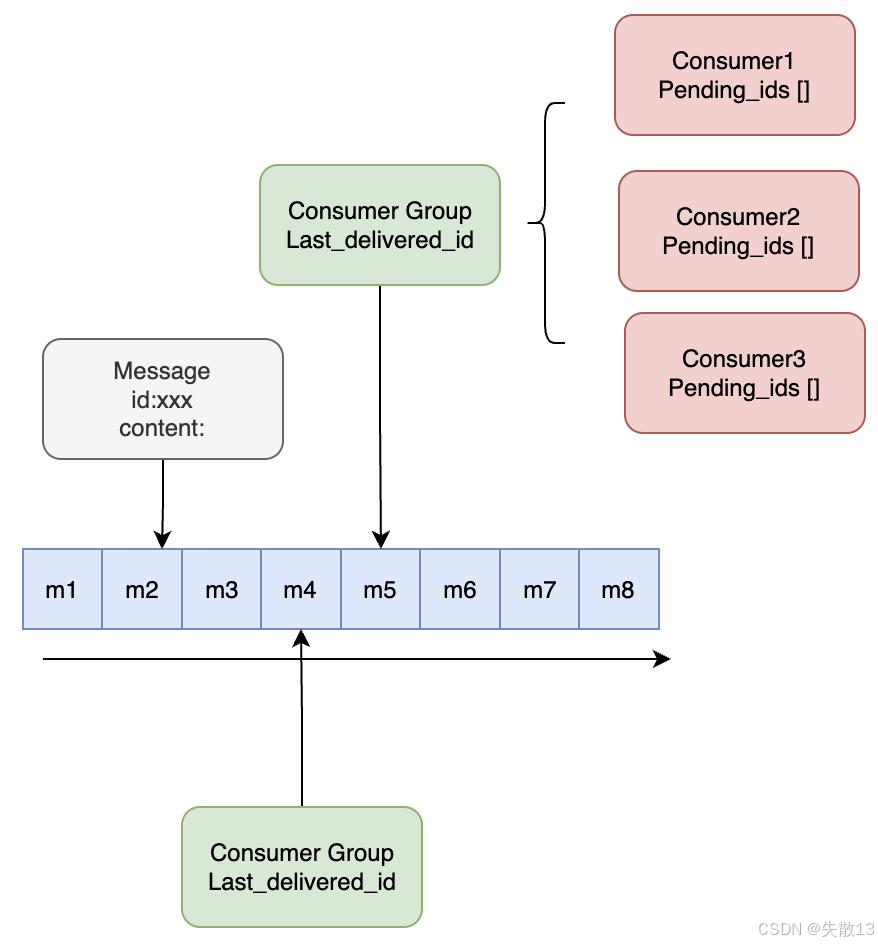
11 Stream 类型
-
Stream 是 Redis 版的消息队列(MQ),结合了阻塞队列和发布/订阅(pub/sub)的特点。不过在企业应用中相对较少,了解即可;
-
常用操作:
-
XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|id field value [field value ...]:往指定的key队列末尾发布一条消息,可设置队列长度限制等参数,*表示让系统自动生成消息 ID,也可指定id,同时携带消息的字段(field)和值(value); -
XDEL key id [id ...]:删除队列key中指定id的消息; -
XLEN key:获取队列key的长度,即消息的数量; -
XRANGE key start end [COUNT count]:查询队列key中从start到end范围内的消息,可通过COUNT指定返回消息的数量;
-
-
应用示例:
-
创建队列并添加消息 :使用
XADD mystream * name loulan name roy name admin,创建名为mystream的队列,并添加消息,*表示系统自动生成消息 ID,消息包含name字段分别为loulan、roy、admin等内容; -
查看队列消息 :通过
XRANGE mystream - +,查看mystream队列中从开头(-)到结尾(+)的所有消息; -
创建消费者组 :执行
XGROUP CREATE mystream groupA 0,创建名为groupA的消费者组,从队列头部(0表示队列头部)开始消费消息;若用$则从队列尾部开始消费; -
消费消息 :使用
XREADGROUP GROUP groupA consumer1 count 2 STREAMS mystream >,groupA消费者组中的consumer1从mystream队列中消费消息,>表示从第一条未被消费过的消息开始消费,count 2表示消费 2 条消息,也可指定具体的消息 ID 进行消费; -
查看消费者组的消费进度 :通过
XPENDING mystream groupA,查看mystream队列中groupA消费者组的消费进度,比如未确认的消息等情况。
-
12 SpringBoot 集成 Redis
-
Maven 依赖:
xml<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> -
核心配置:
yamlspring: data: redis: host: 192.168.65.214 # Redis 服务器地址 port: 6379 # Redis 服务端口,默认6379 password: 123qweasd # Redis 连接密码 ......
13 RedisTemplate 快速上手
-
首先:
RedisTemplate是 Spring 提供的用于操作 Redis 的模板类java@Resource private RedisTemplate<String,Object> redisTemplate; -
然后,可按不同的 Redis 数据类型进行操作:
javaredisTemplate.opsForValue().xxx // 操作 String 类型数据 redisTemplate.opsForSet().xxx // 操作 Set 类型数据 redisTemplate.opsForHash().xxx // 操作 Hash 类型数据 redisTemplate.opsForList().xxx // 操作 List 类型数据 redisTemplate.opsForZset().xxx // 操作 ZSet 类型数据 redisTemplate.opsForGeo().xxx // 操作 Geo 类型数据 redisTemplate.opsForHyperLogLog().xxx // 操作 HyperLogLog 类型数据 redisTemplate.opsForStream().xxx // 操作 Stream 类型数据 // 对于 Bitmap 类型,没有单独的操作类型,而是通过下面这个方法来进行操作,因为 Bitmap 本质上是基于 String 类型的位操作 redisTemplate.opsForValue().setBit()
14 RedisTemplate 中文乱码问题
-
通过自定义
RedisTemplate的序列化方式解决:javablic RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){ RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>(); // 设置连接工厂 redisTemplate.setConnectionFactory(redisConnectionFactory); // StringRedisSerializer:用于字符串序列化,避免中文乱码 StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); // GenericToStringSerializer:将对象转为字符串序列化 GenericToStringSerializer<String> genericToStringSerializer = new GenericToStringSerializer<>(String.class); // 为 RedisTemplate 的 key、value、hashKey、hashValue 指定对应的序列化器,确保数据在 Redis 中存储和读取时能正确处理中文等字符 redisTemplate.setKeySerializer(stringRedisSerializer); redisTemplate.setValueSerializer(genericToStringSerializer); redisTemplate.setHashKeySerializer(stringRedisSerializer); redisTemplate.setHashValueSerializer(stringRedisSerializer); // 使配置生效 redisTemplate.afterPropertiesSet(); // 返回配置好的 RedisTemplate Bean return redisTemplate; }