原文链接:https://mp.weixin.qq.com/s/NlE-3sPrahHZy8p8k3Cp3w
技术解码 | WebRTC音视频延时、同步分析以及超低延时优化
导语 | 在实时音视频中,我们关注的最主要的指标是低延时、高质量和高流畅,那么这篇文章就从延时和流畅方面来介绍一下WebRTC框架中的低延时、流畅以及对于它们的优化。
一、延时
由于音频和视频包大小的不同,在WebRTC中,音频和视频的jitterbuffer也就有各自的实现。其中音频延时为playout_delay_ms和jitter_delay(NetEq接收缓存延时)。视频延时则包含jitter_delay(jitterbuffer接收缓存延时)、decode_delay和render_delay,其中decode_delay和render_delay比较稳定,对整体延时计算影响较小。不论是音频还是视频,对延时影响较大都是网络延时或者网络抖动。
1.1 音频延时
playout_delay_ms主要为播放设备延时,相对来说比较稳定,jitter delay即网络延时,音频网络延时在NetEq中计算得出,结合WebRTC源码分析一下音频延时计算:
ChannelReceive::GetDelayEstimate()->获取到音频delay(即Info结构的current_ delay_ms),该delay为playout_delay_ms_ + acm_receiver_.FilteredCurrentDelayMs()。playout_delay_ms_为ChannelReceive::UpatePlayoutTimestamp获取硬件播放延时毫秒数。- 后者为NetEq中得出:
NetEqImpl::FilteredCurrentDelayMs()具体计算为:- 首先
SyncBuffer::FutureLength()获取AudioVector(即播放缓冲区)中包的个数; - 其次在接收rtp包后,调用
DelayManager::Update更新统计信息,BufferLevelFilter::Update更新抖动延时; DecisionLogic:: GetFilteredBufferLevel()音频间隔(具体算法比较复杂,本文不做详细介绍);- 两者计算得出
delay_samples数,结合采样率计算出delay毫秒数。
- 首先
1.2 视频延时
decode_delay和render_delay比较简单,不做介绍,主要介绍下WebRTC中jitter delay。jitter delay主要由网络噪声和视频长帧造成的网络冲击造成的延时。
在WebRTC中,我们认为网络传输为一个线性系统(在WebRTC中像带宽估计、网络延时、帧延时等都作为线性系统来看,而且噪声都符合高斯分布)。在线性系统中我们很容易想到采用卡尔曼滤波来预测下一时刻的状态。
WebRTC中就是采用卡尔曼滤波来估计网络传输速率和网络排队延时。其计算过程主要依赖于当前帧大小、时间戳和当前本地时刻,以及接收过程中不断更新的最大帧大小、平均帧大小、噪声均值、传输速率、网络排队延时等状态参数。下面从WebRTC代码层面分析一下jitter delay的计算。
主要状态公式及值计算
- 帧间相对延时:
frame_delay = t(i) - t(i-1) - (T(i) - T(i-1)),其中t(i/i-1)分别为当前帧和上一帧的接收时间,T(i/i-1)分别为当前帧和上一帧的发送时间; - 帧间帧大小差:
delta_frame_size = frame_size - prev_frame_size; - 平均帧大小:
avg_frame_size = phi*avg_frame_size + (1-phi)*frame_size(采用滑动平均算法计算,phi=0.997); - 帧方差:
var_frame_size = phi*var_frame_size + (1-phi)*(frame_size - avg_frame_size)^2(这个的主要用处就是过滤过大帧、关键帧); - 观测噪声:
residual = frame_delay - (_theta[0]*delta_fs_bytes + _theta[1])(观测噪声即表示延时测量值与卡尔曼滤波估计值的偏差); - 平均噪声:
avg_noise = alpha*avg_noise + (1-alpha)*residual; - 噪声方差:
var_noise = alpha*var_noise + (1-alpha)*(residual - avg_noise)^2(初始值为4); - 概率系数:
alpha = pow(399/400, 30/fps)(该系数受帧率影响,帧率fps小时alpha变小,噪声均值和方差变大)。
由上述状态公式,计算出相应的状态变量后,通过卡尔曼滤波估计(修正)下一次延时值jitter delay。
WebRTC源代码核心流程
视频render线程轮询是否有帧播放,获取下一帧数据->
FrameBuffer::GetNextFrame()->
VCMInterFrameDelay::CalculateDelay()(该行获取帧延时frameDelay=(r(i)-r(i-1))-(s[i]-s[i-1]),即两帧的接收时间差与发送时间差的间差,发送时间差通过rtp时间戳和采样率计算得出)->
VCMJitterEstimator::UpdateEstimate()(根据上行得到的帧延时和帧长差进行卡尔曼滤波计算出传输速率_theta[0]和队列延时theta[1])->
VCMJitterEstimator::DeviationFromExpectedDelay()(计算观察误差residual)->
VCMJitterEstimator::EstimateRandomJitter()(根据观测噪声residual计算观测噪声方差和观测噪声均值)->
VCMJitterEstimator::KalmanEstimateChannel()(卡尔曼滤波更新状态变量)->
VCMJitterEstimator::GetJitterEstimate()->
VCMJitterEstimator::CalculateEstimate()
最终计算出:
jitterMS = _theta[0]*(_maxFrameSize - _avgFrameSize) + NoiseThreshold() + JITTER
其中:
JITTER为固定值10ms;_theta[0]为传输速率的倒数;_maxFrameSize为最大帧长度(这里可以看出,我们的帧应当尽可能的平稳,否则容易造成jitter delay很不稳定的情况);_avgFrameSize为平均帧长度(这里会忽略大帧、关键帧的影响,防止关键帧过分拉大均值导致jitter delay突然变较小)。
NoiseThreshold()为传输噪声,计算如下:
_noiseStdDevs * sqrt(_varNoise) - _noiseStdDevOffset
其中noiseStdDevs为噪声系数(固定值2.33,表示高斯分布99%的概率分布),varNoise为噪声方差,noiseStdDevOffset为噪音扣除值(固定为30ms)。
1.3 卡尔曼滤波
1.3.1 卡尔曼滤波公式
卡尔曼滤波公式:参考(卡尔曼滤波五个公式https://blog.csdn.net/wccsu1994/article/details/84643221)
x ^ i − = A x ^ i − 1 + B u i − 1 (卡尔曼滤波器状态预测方程) P i − = A P i − 1 A T + Q (卡尔曼滤波器协方差预测方程) K i = P i − H T H P i − H T + R (卡尔曼增益方程) x ^ i = x ^ i − + K i ( z i − H x ^ i − ) (卡尔曼滤波器状态更新方程) P i = ( I − K i H ) P i − (卡尔曼滤波器协方差更新方程) \begin{aligned} \hat{x}i^- &= A\hat{x}{i-1} + Bu_{i-1} \quad \text{(卡尔曼滤波器状态预测方程)} \\ P_i^- &= AP_{i-1}A^T + Q \quad \text{(卡尔曼滤波器协方差预测方程)} \\ K_i &= \frac{P_i^- H^T}{H P_i^- H^T + R} \quad \text{(卡尔曼增益方程)} \\ \hat{x}_i &= \hat{x}_i^- + K_i \left( z_i - H \hat{x}_i^- \right) \quad \text{(卡尔曼滤波器状态更新方程)} \\ P_i &= \left( I - K_i H \right) P_i^- \quad \text{(卡尔曼滤波器协方差更新方程)} \end{aligned} x^i−Pi−Kix^iPi=Ax^i−1+Bui−1(卡尔曼滤波器状态预测方程)=APi−1AT+Q(卡尔曼滤波器协方差预测方程)=HPi−HT+RPi−HT(卡尔曼增益方程)=x^i−+Ki(zi−Hx^i−)(卡尔曼滤波器状态更新方程)=(I−KiH)Pi−(卡尔曼滤波器协方差更新方程)
1.3.2 jitter滤波算法
由于视频传输延时抖动主要与帧大小、传输带宽、网络排队相关(即我们需要观测的值),因此建立数学模型如下:
-
状态方程 (即某一时刻的网络状态):
theta(i) = theta(i-1) + u(i-1)其中:
theta(i)为一个二维矩阵[1/C(1) m(i)]^T(C(i)为传输速率,m(i)为网络排队延时);u(i)为过程噪声(误差),是一个高斯噪声矩阵------P(u)~(0,Q)。 -
观测方程 (即某一时刻观测到的jitter delay):
d(i) = dL(i)/C(i) + m(i) + v(i)即
d(i) = H * theta(i) + v(i)其中:
d(i)为帧间测量延时;H为长度差测量矩阵[dL(i) 1](dL(i)为当前帧与上一帧的帧长差值);v(i)表示测量噪声(误差)------P(v)~(0,R)。
因此也即观测方程为:
d(i) = [dL(i) 1] * [1/C(i) m(i)]^T + v(i)
由上面的模型结合卡尔曼滤波五个公式,对应到WebRTC的定义公式为(WebRTC相关文档连接为https://datatracker.ietf.org/doc/html/draft-alvestrand-rmcat-congestion-03):
- 先验期望:
theta_hat-(i) = theta_hat(i-1); - 先验方差:
theta_cov-(i) = theta_cov-(i-1) + Q(i); - 卡尔曼增益:
K = theta_cov-(i)*H^T / (H*theta_cov-(i)*H^T + R); - 后验期望:
theta_hat(i) = theta-(i) + K*(d(i) - H*theta_hat-(i)); - 后验方差:
theta_cov(i) = (I - K*H)*theta_cov-(i)。
1.3.3 卡尔曼滤波代码分析
定义
M: _thetaCov[2][2]:为theta_cov(i)即[1/C(1) m(i)]^T协方差矩阵;Q: _Qcov[2][2]:为高斯噪声矩阵(一个对角矩阵),建议值为_Qcov[0][0] = 2.5e-10;_Qcov[1][1] = 1e-10;_Qcov[0][1] = _Qcov[1][0] = 0;(WebRTC中有不少这样的建议值)h: [deltaFSBytes 1]:即为[dL(i) 1]测量矩阵;Mh: M*h^T;hMh_sigma: h*M*h^T + R;K: M*h^T/hMh_sigma。
源码实现
cpp
void VCMJitterEstimator::KalmanEstimateChannel(int64_t frameDelayMS,
int32_t deltaFSBytes) {
double Mh[2]; //H*theta_cov-(i)
double hMh_sigma; //H*theta_cov-(i)*H^T+R
double kalmanGain[2]; //卡尔曼增益K
double measureRes; //测量误差 d(i)-H*theta_hat-(i)
double t00, t01;
// Kalman filtering
// Prediction
// M = M + Q
//先验协方差计算theta_cov-(i)=theta_cov-(i-1)+Q(i)
_thetaCov[0][0] += _Qcov[0][0];
_thetaCov[0][1] += _Qcov[0][1];
_thetaCov[1][0] += _Qcov[1][0];
_thetaCov[1][1] += _Qcov[1][1];
//Mh[2] = M[2][2]*h^T = _thetaCov[2][2]*[dL(i) 1]
Mh[0] = _thetaCov[0][0] * deltaFSBytes + _thetaCov[0][1];//表示1/C(1)协方差
Mh[1] = _thetaCov[1][0] * deltaFSBytes + _thetaCov[1][1];//表示m(i)协方差
// sigma weights measurements with a small deltaFS as noisy and
// measurements with large deltaFS as good
if (_maxFrameSize < 1.0) {
return;
}
//观测噪声协方差R计算为使用指数滤波方式,deltaFSBytes越大噪声越小
double sigma = (300.0 * exp(-fabs(static_cast<double>(deltaFSBytes)) /
(1e0 * _maxFrameSize)) +
1) *
sqrt(_varNoise);
if (sigma < 1.0) {
sigma = 1.0;
}
// hMh_sigma = h*M*h' + R = [dL(i) 1]*Mh[2] + sigma
hMh_sigma = deltaFSBytes * Mh[0] + Mh[1] + sigma;
if ((hMh_sigma < 1e-9 && hMh_sigma >= 0) ||
(hMh_sigma > -1e-9 && hMh_sigma <= 0)) {
assert(false);
return;
}
//卡尔曼增益K[2]=Mh[2]/hMh_sigma,噪声越大,则hMh_sigma越大,则卡尔曼增益越小,则目标值更接近上一次的
kalmanGain[0] = Mh[0] / hMh_sigma;
kalmanGain[1] = Mh[1] / hMh_sigma;
//修正目标值,即测量值与评估值校验出最终目标结果
//theta = theta + K*(dT - h*theta)
// = theta + K*dT - K*h*theta
// = (1 -- K*h) * theta + k*dT
//由此可见,当K接近0时,当前值更接近上一次后验期望
//计算测量误差 measureRes = d(i)-H*theta_hat-(i)
measureRes = frameDelayMS - (deltaFSBytes * _theta[0] + _theta[1]);
_theta[0] += kalmanGain[0] * measureRes;
_theta[1] += kalmanGain[1] * measureRes;
if (_theta[0] < _thetaLow) {
_theta[0] = _thetaLow;
}
// M = (I - K*h)*M
//更新(修正)theta[2][2]协方差矩阵,I[2][2]-[K0 K1]^T*[deltaFSBytes 1],其中I为2x2的单位矩阵
t00 = _thetaCov[0][0];
t01 = _thetaCov[0][1];
_thetaCov[0][0] = (1 - kalmanGain[0] * deltaFSBytes) * t00 -
kalmanGain[0] * _thetaCov[1][0];
_thetaCov[0][1] = (1 - kalmanGain[0] * deltaFSBytes) * t01 -
kalmanGain[0] * _thetaCov[1][1];
_thetaCov[1][0] = _thetaCov[1][0] * (1 - kalmanGain[1]) -
kalmanGain[1] * deltaFSBytes * t00;
_thetaCov[1][1] = _thetaCov[1][1] * (1 - kalmanGain[1]) -
kalmanGain[1] * deltaFSBytes * t01;
// Covariance matrix, must be positive semi-definite.
assert(_thetaCov[0][0] + _thetaCov[1][1] >= 0 &&
_thetaCov[0][0] * _thetaCov[1][1] -
_thetaCov[0][1] * _thetaCov[1][0] >=
0 &&
_thetaCov[0][0] >= 0);
}二、音视频同步
RtpStreamsSynchronizer::UpdateDelay()每秒更新一次同步信息,设置同步信息的流程如下:
BaseChannel::AddRecvStream_w->
WebRtcVideoChannel::AddRecvStream->
Call::CreateVideoReceiveStream->
Call::ConfigureSync->
VideoReceiveStream2::SetSync->
RtpStreamsSynchronizer::ConfigureSync
ConfigureSync中配置同步信息:如果没有音频,则不做同步,且不更新同步引入的delay的状态(audio和video自身的jitter delay还是不受影响的)。
关键参数结构(Info)
在音视频同步中,使用到一些关键参数,其中记录音视频包的发送和接收时间的Info结构为:
cpp
struct Info {
int64_t latest_receive_time_ms; //最新接收到rtp包的本地时间
uint32_t latest_received_capture_timestam; //最新接收到的rtp包的rtp时间戳
uint32_t capture_time_ntp_secs; //sr的ntp秒
uint32_t capture_time_ntp_frac; //sr的ntp毫秒
uint32_t capture_time_source_clock; //sr发送的最后rtp时间戳
int current_delay_ms; //
};同步主要依赖SenderReport,依据SenderReport中的rtp timestamp和ntp time以及本地接收时间latest_receive_time_ms作为参考。
音视频同步的关键步骤
第一步:获取音频发送端和接收端信息(audio_info)
流程如下:
ChannelReceive::GetSyncInfo()->
ModuleRtpRtcpImpl2::RemoteNTP()->
RTCPReceiver::NTP()(获取remote的sr的rtp ts、send ntp。
第二步:更新音频测量时间信息
通过获取到的audio info更新音频测量时间信息,流程如下:
RtpToNtpEstimator::UpdateMeasurements->
RtpToNtpEstimator::UpdateParameters()(该流程通过最近20个SR包中ntp和rtp时间戳计算出两者的线性关系并记录,因为不是每一个rtp时间戳都有对应SR的ntp时间戳,所以通过该线性关系,估算出每一个rtp时间戳对应的ntp时间,公式为:y=k*x+b)。
由此可得到最新接收到的rtp包的rtp时间戳、最新接收到rtp包的本地时间,以及发送端rtp时间戳和ntp时间的关系,进而计算出传输延时。
第三步:获取视频发送端和接收端信息(video_info)
流程如下:
VideoReceiveStream2::GetInfo()->
RtpVideoStreamReceiver2::GetSyncInfo()->
ModuleRtpRtcpImpl2::RemoteNTP()(内容同音频)->
VCMTiming::TargetVideoDelay()(获取到视频delay,即Info结构的current_delay_ms)。
该视频delay计算公式为:
max(min_playout_delay_ms_, jitter_delay_ms_ + RequiredDecodeTimeMs() + render_delay_ms_)
其中:
min_playout_delay_ms_:上一次同步计算得到的目标视频延时;jitter_delay_ms_:视频的传输延时时间(1.2节已介绍);render_delay_ms_:固定10ms;RequiredDecodeTimeMs():解码时间。
第四步:更新视频测量时间信息
通过获取到的video info更新视频测量时间信息,核心是计算rtp时间戳与发送端ntp时间,计算流程与音频完全一致。
第五步:计算音视频相对延时
在得到音视频的发送时间及接收时间后,通过ComputeRelativeDelay计算出视频相对于音频的延时relative_delay_ms(该值可正、可负、可等于0,用于表示视频与音频的延时差异):
- 当
relative_delay_ms > 0:视频慢(视频延时大于音频)。此时将视频延时与基准base_target_delay_ms(默认0)比较:- 若
video_delay_.extra_ms > base_target_delay_ms_:减小视频延时,设置音频为基准延时; - 否则:增大音频延时,设置视频为基准延时。
- 若
- 当
relative_delay_ms < 0:音频慢(音频延时大于视频)。此时将音频延时与基准比较:- 若
audio_delay_.extra_ms > base_target_delay_ms_:减小音频延时,设置视频为基准; - 否则:增加视频延时,设置音频为基准延时。
- 若
第六步:计算音视频目标延时
通过StreamSynchronization::ComputeDelays计算音频和视频的目标延时,核心规则如下:
- 若音视频相对延时小于30ms:忽略同步操作,音频和视频按自身延时播放;
- 若相对延时过大:以最大80ms的速度进行快进或减速(避免延时变化过大导致频繁同步问题);
- 延时收敛逻辑:若视频延时大于音频,减小视频延时并增加音频延时(让音频播放更慢);反之则调整音频延时并增加视频延时,在保证流畅的同时降低整体延时。
第七步:设置目标延时到播放线程
将第六步计算出的音频和视频目标延时,分别设置到各自的播放线程,设备按设定延时播放音视频。
三、延时优化
通过前文对音视频延时的分析及同步实现的拆解可知:在固定网络条件和音视频码率下,要实现更低延时,需从音视频同步机制和延时算法两方面切入,核心优化方向如下。
3.1 取消音/视频SenderReport
音视频同步会受任意一方的网络抖动影响,进而导致整体延时增大。因此,在延时优先级高于音视频同步 的场景(如实时指挥、低延时互动)中,可禁用音视频同步机制,让音频和视频分别按自身jitter delay渲染。
⚠️ 注意:该操作仅消除音视频间的相互影响,不一定直接降低延时,需结合其他优化手段使用。
3.2 降低网络抖动
从延时计算算法可知,网络抖动是影响jitter delay的核心因素,可通过以下方式降低:
- 平滑大帧传输:在固定带宽下,视频I帧(关键帧)体积远大于普通帧,一次性发送易导致网络丢包或排队。通过"单位时间内分次发送数据包"的平滑策略,减少大帧对网络的冲击;
- 优化网络链路:通过"就近接入节点"(如CDN边缘节点)减少传输路径长度,降低网络排队延时;
- 稳定码率输出:编码器需避免码率剧烈波动(如限制I帧体积、采用恒定码率CBR),减少帧大小差异对网络的压力。
3.3 平滑发送(Pacing)
平滑发送(Pacing)的核心目标是解决大帧对网络的冲击,减少丢包、乱序、重传,以及网络排队对jitterbuffer和拥塞控制的影响。需先明确两个关键认知:
- Pacing与延时的矛盾:在有限带宽下,平滑发送需将大帧拆分到多个时间片传输,会引入一定发送延时;但同时能降低丢包率,减少重传带来的更大延时;
- WebRTC中的Pacing逻辑 :源码中Pacing发送以"目标带宽"为基础,固定带宽下,大帧会在
PaceSender中暂存,暂存时间即为Pacing延时。
基于上述认知,提供两种业务可选的Pacing方案:
- 方案一:帧间隔内完成前一帧发送
在两个视频帧的间隔(如30fps对应约33ms间隔)内,确保前一帧完全发送,既消除发送侧的额外延时,又兼顾基础平滑效果。 - 方案二:最大延时内完成发送
设定一个大于帧间隔的"最大发送延时"(如50ms),在该时长内确保所有数据包发送完毕。相比方案一,大帧有更大的平滑空间,但会引入额外发送延时。
平滑发送效果测试
针对含较大I帧的H.264视频流,在有限带宽下测试两种Pacing方案的丢包乱序优化效果,测试结果通过以下图形展示:
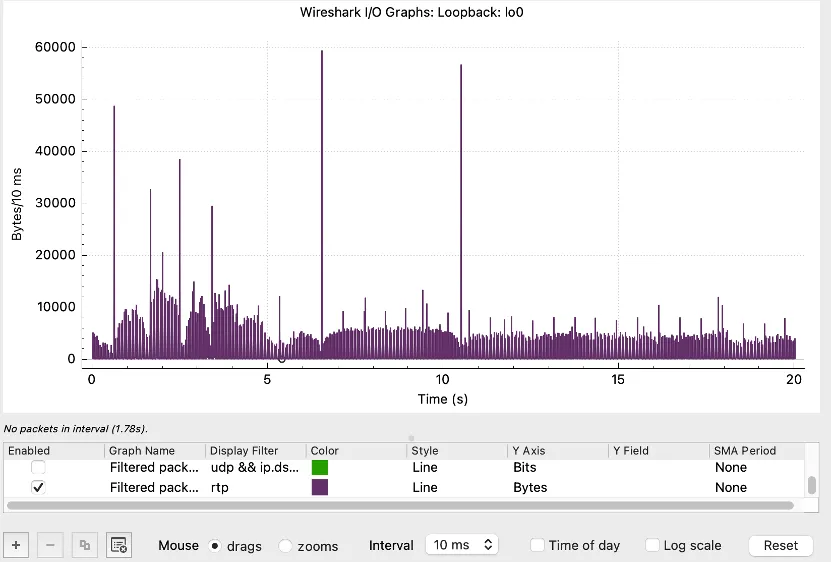
图1. 禁用pacing(丢包率高,乱序明显)

图2. 方案一(丢包率降低30%,无明显乱序)
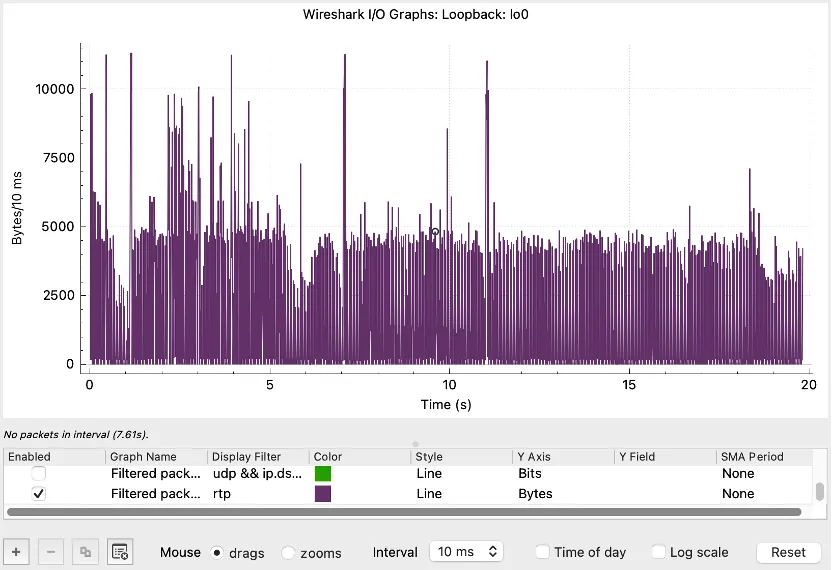
图3. 方案二(丢包率降低45%,完全无乱序,但发送延时增加10-15ms)
3.4 渲染延时
渲染延时存在优化空间(本文暂不展开细节),但需关注一个核心疑问:
"获取渲染期望时间与音视频同步时获取期望时间,为何采用不同滤波算法?"------当前实现中,渲染期望采用卡尔曼滤波,而同步期望采用线性滤波,两种算法的选择对延时稳定性的影响需进一步验证。
四、总结
本文围绕WebRTC音视频延时、同步及优化展开,仍有部分细节需深入理解(因篇幅未详细展开):
- NACK对延时的影响 :丢包越多,
jitter delay会因重传数据排队而增大; - 帧率对延时的影响 :帧率越低,概率系数
alpha越小,噪声均值和方差越大,jitter delay稳定性越差; - 卡尔曼滤波参数优化:噪声系数、大帧过滤阈值、均值加权系数(WebRTC大量采用指数加权)等参数,可根据业务场景调整以适配低延时需求。