1. 引言:虚拟流式传输的架构本质
在数字视频工程的浩瀚领域中,"流媒体"(Streaming) 是一个被广泛使用却常被误解的概念。对于终端用户而言,流媒体意味着即点即看、随意的拖拽进度条(Seeking)以及无需等待完整下载的便捷体验。然而,从底层系统工程师的视角来看,实现这一体验的技术路径却大相径庭。
传统的流媒体协议(如 RTP/RTSP)通过服务器端的主动推送和复杂的会话控制来实现实时传输。但现代互联网视频的主流------包括 YouTube、Netflix 以及无数的各个视频网站------很大程度上依赖于基于 HTTP 的传输。这其中,一种被称为 "伪流"(Pseudo-streaming) 或 "渐进式下载"(Progressive Download) 的技术占据了核心地位。这种技术允许播放器(如基于 FFmpeg 内核的播放器)直接从一个静态的视频文件 URL 中读取数据,并精准地提取音频和视频流,甚至在未下载的文件部分进行随机跳转。
这种能力的实现,并非依靠 HTTP 协议本身的某种魔法,而是完全依赖于 视频容器格式(Container Format)的内部数据结构 与 应用层协议(HTTP Range Requests) 之间的精妙配合。FFmpeg 之所以能够 "骗过" 网络层,像操作本地磁盘文件一样操作远程 URL,其核心在于它构建了一个 "虚拟 I/O 层",并将视频文件视为一个随机存取的数据库,而非简单的线性比特流。
本报告将以底层工程师的视角,剥开 FFmpeg 处理远程 MP4 文件的每一层逻辑。我们将深入 ISO BMFF(ISO Base Media File Format)标准的骨髓,解构 moov 盒子中的索引机制,推导从时间戳到字节偏移量的数学映射,并对比 MPEG-TS、MKV 等格式的异同,最终提炼出面向工程实践的核心准则。
2. 核心概念重构:容器与编码的二元对立
在深入文件结构之前,我们必须严格区分两个常被混淆的概念:编码(Codec) 与 容器(Container)。这种区分是理解远程解复用(Demuxing)的前提。
2.1 编码流的"盲目性"
视频编码标准(如 H.264/AVC, H.265/HEVC, AV1)关注的是如何高效地压缩视觉信息。它们处理的是宏块(Macroblocks)、变换(Transforms)、量化(Quantization)和熵编码(Entropy Coding)。
一个纯粹的 H.264 基本流(Elementary Stream, ES)是一系列网络抽象层单元(NAL Units)的序列。虽然这些单元包含了重建图像所需的所有像素数据,但它们在宏观层面是 "盲目" 的:
- 缺乏全局时间观:NAL 单元内部虽有解码时间戳(DTS)和显示时间戳(PTS),但一个纯裸流通常不知道自己总共有多长,也不知总共有多少帧。
- 缺乏随机存取能力:如果给你一个 10GB 的 H.264 裸流文件并要求 "跳转到第 1 小时",你除了从头开始扫描并计数 NAL 单元外,别无他法。这是一个 的线性搜索过程,对于远程播放是不可接受的。
- 缺乏多流同步机制:裸视频流和裸音频流(如 AAC ADTS 流)是物理隔离的,它们不知道如何对齐播放。
2.2 容器的"索引职能"
容器格式(Wrapper/Container),如 MP4 (ISO BMFF)、MKV (Matroska)、MPEG-TS,其本质是一个多媒体数据库。它不负责压缩,只负责组织。
容器解决了编码流无法解决的问题:
- 元数据存储:它记录了视频的时长、分辨率、帧率、编码类型等全局信息。
- 交错存储(Interleaving):它将音频数据块和视频数据块切碎并混合存放,确保存储介质(磁盘或网络缓冲区)在读取时能同时获取临近时刻的音视频数据,避免频繁的磁头跳转或由于缓冲区欠载导致的播放卡顿。
- 索引(Indexing) :这是本文的核心。容器建立了一套复杂的索引表,能够将 "逻辑时间"(第几分第几秒) 映射为 "物理地址"(文件中的第几个字节)。
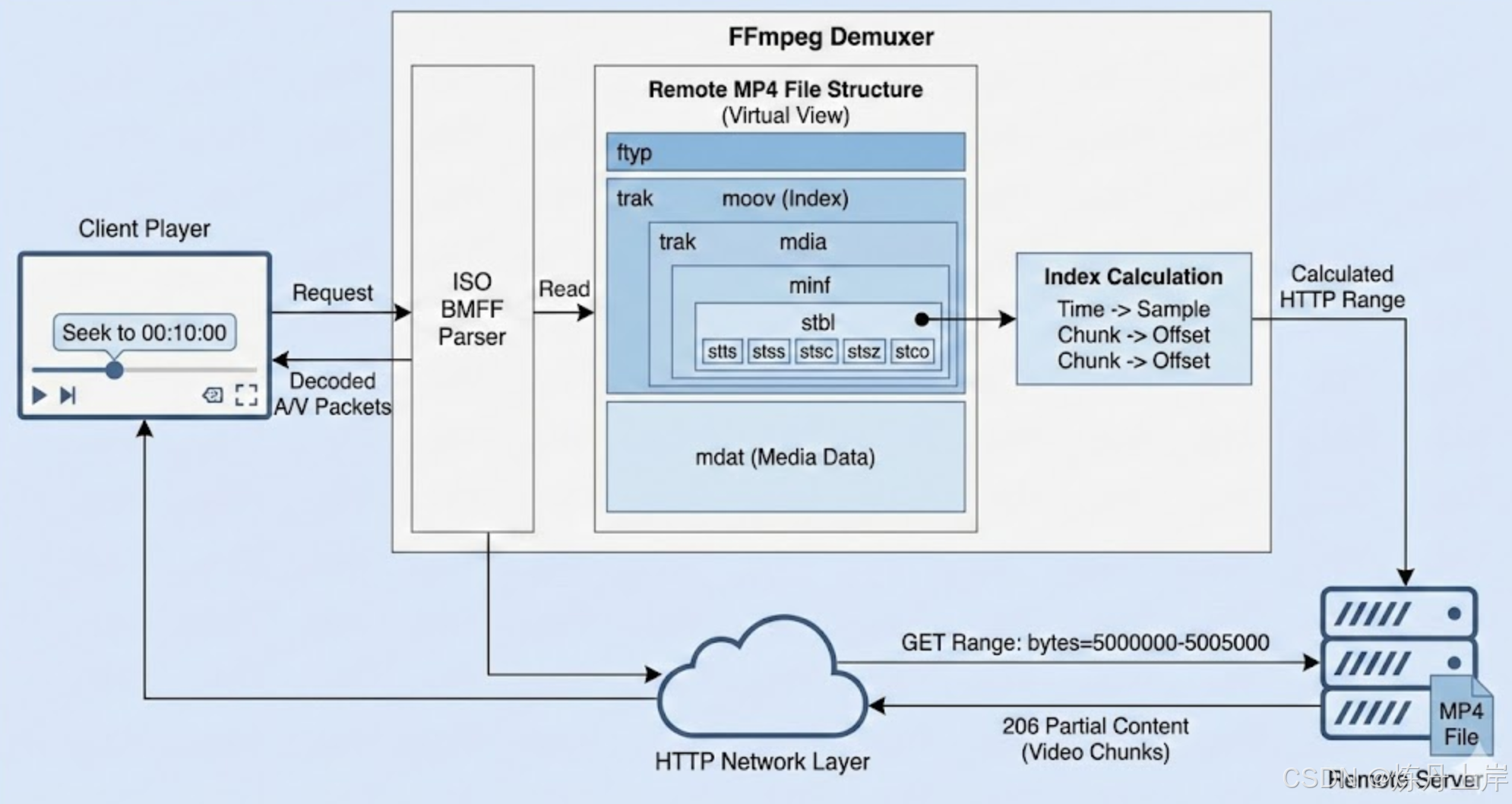
FFmpeg 的解复用器(Demuxer)本质上就是一个数据库查询引擎。当用户请求 "播放 00:10:00 的视频" 时,Demuxer 并不去下载视频数据,而是先查询容器的索引,计算出数据位于 HTTP 资源的 bytes=5000000-5005000 处,然后才发起网络请求。
3. ISO BMFF (MP4) 深度解构:盒子里的世界
MP4 文件格式(正式名称为 ISO/IEC 14496-12 ISO Base Media File Format)是目前互联网上最通用的容器格式。它源自 Apple 的 QuickTime 格式,采用了一种面向对象的、层级化的结构。
3.1 盒子(Box/Atom)模型
MP4 文件由一系列的 "盒子"(Box,QuickTime 规范中称为 Atom) 组成。每个盒子都包含两部分:
-
Header(头部):通常为 8 字节。
-
Size(4 bytes):32位整数,表示整个盒子的大小(包含 Header)。 -
Type(4 bytes):FourCC(四字符代码),如ftyp,moov,mdat,标识盒子的类型。 -
Data(数据体):盒子的具体内容,可以是二进制数据,也可以是嵌套的子盒子(Child Boxes)。
这种递归结构使得 MP4 具有极强的扩展性。解析器(如 FFmpeg)可以跳过它不认识的盒子类型,直接根据 Size 跳转到下一个盒子,这保证了向后兼容性。
3.2 顶层架构三巨头
对于远程流式读取,我们只需关注三个最关键的顶层盒子:
3.2.1 ftyp (File Type Box)
通常位于文件起始位置(Offset 0)。它向播放器声明:"我是 ISO BMFF 格式的文件,我兼容 isom, mp42, avc1 等规范"。FFmpeg 读取这个盒子后,就能确定使用 mov,mp4,m4a,3gp,3g2,mj2 Demuxer 来处理后续内容。
3.2.2 mdat (Media Data Box)
这是文件中体积最大的部分,通常占据 99% 以上的空间。它包含实际的媒体数据------即 H.264 的 NALU 和 AAC 的帧。
关键洞察 :
mdat内部的数据是无结构的。如果你只看mdat,你看到的是一堆杂乱无章的字节。你不知道第一帧视频在哪里结束,也不知道音频帧混在哪里。它是一个单纯的 "数据仓库"。如果没有索引,mdat 就是一堆废数据。
3.2.3 moov (Movie Box)
这是 MP4 文件的 "大脑" 和 "目录" 。moov 盒子本身不包含任何媒体数据,它只包含元数据(Metadata)。
- 它告诉播放器:视频有多长,由几条轨道(Track)组成。
- 它包含着至关重要的 采样表(Sample Table) ,这是解开
mdat混沌状态的唯一钥匙。 - 它就像关系型数据库中的 B+ 树索引文件,而
mdat是存储实际行记录的堆文件。
3.3 轨道(Track)的概念
在 moov 内部,媒体被组织成 "轨道"(Track)。通常包含:
- Video Track:包含视频流信息。
- Audio Track:包含音频流信息。
- Subtitle/Hint Track:包含字幕或流媒体提示信息。
每个轨道都是独立的,拥有自己的时间轴和索引表。FFmpeg 在解复用时,是并行读取这些轨道的索引,但在物理层面上,这些轨道的数据在 mdat 中通常是交错存放的(Interleaved)。
4. moov 核心解析:样本表(Sample Table)的数学奥秘
为什么 FFmpeg 能够不下载文件就提取音频?答案全在 moov -> trak -> mdia -> minf -> stbl(Sample Table Box)这个路径下。
stbl 盒子包含了一组子盒子,它们共同构成了一个精密的坐标系,用于将 时间(Time) 转换为 偏移量(Offset) 。我们需要详细解剖其中的五个关键索引表:stts, stss, stsc, stsz, stco。
为了方便解释,我们定义两个核心概念:
- Sample(样本):对于视频,一个 Sample 对应一帧(Frame);对于音频,一个 Sample 对应一个音频帧(Audio Frame)。
- Chunk(块) :一个 Chunk 是由一个或多个连续的 Sample 组成的物理存储单元。在
mdat中,数据不是一帧一帧零散存放的,而是几帧视频凑成一个 Chunk,几帧音频凑成一个 Chunk,交替存放。
4.1 stts (Time-to-Sample Box):时间到样本序号
这是时空转换的第一步。我们需要知道 "第 10 秒对应的是第几个 Sample?"
由于视频通常是固定帧率(如 24fps)或变帧率(VFR),简单地用 Time * FPS 并不可靠。stts 使用 游程编码(Run-Length Encoding) 来压缩存储每一帧的持续时间(Duration)。
结构示例:
text
Count | Duration
100 | 1000
50 | 1001- 含义:前 100 个样本,每个时长为 1000 个时间单位(Timescale);接下来的 50 个样本,每个时长为 1001 个单位。
- 算法:FFmpeg 遍历这个表,累加 Sample Delta,直到总时长超过目标时间戳 。累加过程中经过的 Sample Count 总和,就是目标 Sample Index ()。
4.2 stss (Sync Sample Box):关键帧定位
视频编码存在 I 帧、P 帧、B 帧。如果用户随机拖拽,播放器必须从最近的 关键帧(Keyframe/IDR Frame) 开始解码,不能从 P 帧或 B 帧开始。
stss 表列出了所有关键帧的 Sample Index。
- 算法 :得到目标 Sample Index () 后,FFmpeg 查阅
stss表,找到 的最大的那个 Sample Index,记为 Keyframe Sample Index ()。这就确定了我们将要读取的起始帧。
4.3 stsc (Sample-to-Chunk Box):样本到块的映射
这是最让初学者困惑的表。MP4 为了节省空间,不记录每个 Sample 的偏移量,而是记录 Chunk 的偏移量。我们需要知道:第 个 Sample 位于第几个 Chunk 中?以及它是该 Chunk 中的第几个?
stsc 同样使用游程编码:
结构示例:
text
First Chunk | Samples Per Chunk | Sample Description ID
1 | 10 | 1
50 | 8 | 1-
含义:
-
从第 1 号 Chunk 开始,每个 Chunk 包含 10 个 Sample。
-
从第 50 号 Chunk 开始,每个 Chunk 包含 8 个 Sample。
-
算法:FFmpeg 通过此表,计算出 Keyframe Sample Index () 位于 Chunk Index (),并且计算出该 Chunk 中在 之前还有多少个 Sample(记为 )。
4.4 stsz (Sample Size Box):样本尺寸
现在我们知道了目标 Sample 在 Chunk 中,且前面有 个兄弟样本。为了定位到目标 Sample 的精确字节位置,我们需要知道它前面那些兄弟样本的大小。
stsz 表记录了每一个 Sample 的字节大小(Size in Bytes)。
- 算法 :查询
stsz表,将 Chunk 中前 个 Sample 的大小累加,得到 In-Chunk Offset。
4.5 stco / co64 (Chunk Offset Box):块偏移量
这是最后一步。这个表记录了每一个 Chunk 在文件中的绝对字节偏移量(File Offset)。
stco使用 32 位整数(限制文件最大 4GB)。co64使用 64 位整数(用于大文件)。- 算法:查表得到 Chunk 的 Base Offset。
4.6 终极映射公式:从时间戳到 HTTP Range
综合以上步骤,FFmpeg 计算目标数据物理位置的逻辑链条如下:
- 输入:目标时间戳 。
stts找到对应的逻辑 Sample Index ()。stss向前修正,找到最近的 Keyframe Index ()。stsc计算 所在的 Chunk Index () 以及 Chunk 内的序数 。stco获取 Chunk 的 Base File Offset。stsz计算 Chunk 内前 个样本的大小总和 Size Sum。
结果 :目标帧的绝对文件偏移量 = Base File Offset + Size Sum。
一旦算出这个偏移量(例如 52,001,024),FFmpeg 就可以构造 HTTP 请求 Range: bytes=52001024-,直接 "空降" 到视频的中间部分开始读取数据,完全跳过前面的 50MB 数据。
5. 网络层魔法:Fast Start 与 HTTP Range
理解了 MP4 的内部索引机制,我们就能明白为什么 "Fast Start"(又称 Web Optimized)如此重要。
5.1 moov 的位置困境
在标准的视频编码流程中,编码器一边生成 mdat 中的数据,一边计算索引。当视频处理完最后一帧时,完整的索引表(stbl)才构建完成。因此,默认情况下,moov 盒子会被写在文件的末尾。
对于远程播放的灾难性后果:
- 如果
moov在文件末尾(比如一个 10GB 的文件),FFmpeg 必须先读取文件头(ftyp),发现没有moov,然后必须发起一个新的 Seek 请求到文件极末端去读取moov。 - 如果服务器支持 HTTP Range,这会产生额外的 RTT(往返延迟)。
- 最坏情况 :如果服务器不支持 HTTP Range(或者由某些不支持 Seek 的 PHP/Java 脚本输出流),FFmpeg 将别无选择,只能下载完整个 10GB 的
mdat数据,才能读到最后的moov。这就是为什么有些视频在网页上必须缓冲到 100% 才能开始播放。
5.2 Fast Start (qt-faststart)
"Fast Start" 操作(FFmpeg 中使用 -movflags +faststart)通过二次处理,将 moov 盒子从文件末尾搬移到文件开头(紧跟 ftyp 之后)。
这不仅仅是简单的内存拷贝。因为 stco 表中存储的是绝对偏移量,当 moov 被插入到前面时,后面所有的 mdat 数据都会向后位移。因此,处理程序必须遍历 stco 表,将每一个偏移量数值加上 moov 盒子的大小。
优势 :
当 moov 位于头部时,FFmpeg 只需要下载文件的前几百 KB(通常包含 ftyp 和 moov),就能瞬间将完整的索引加载到内存中。此时,无论用户想要跳转到任何时间点,播放器都能立即在内存中算好字节偏移量,发起精准的 Range 请求。这就是 "秒开" 和 "随意拖拽" 的工程基础。
5.3 HTTP Range 请求机制
FFmpeg 的网络层(libavformat/http.c)对上层解复用器隐藏了 HTTP 细节。当 MP4 Demuxer 调用 avio_seek 时:
- Buffer Check:检查目标位置是否在当前 TCP 接收缓冲区的已下载范围内。如果是,直接内存指针跳转。
- New Request:如果不在,FFmpeg 会断开当前 TCP 连接(或利用 HTTP Keep-Alive),并建立新的请求:
- 服务器响应
206 Partial Content,并从指定字节流出数据。
6. 横向对比:MPEG-TS, MKV 与 HLS 的流式哲学
为了更深刻理解 MP4 的设计哲学,我们需要将其与其他的容器格式进行对比。
6.1 MPEG-TS (Transport Stream):流的混沌
MPEG-TS 设计之初是为了有损信道(如卫星广播、有线电视)。它将数据切分为固定的 188 字节包。
- 无全局索引 :TS 流没有类似
moov的全局索引头。它依赖周期性重复的 PAT/PMT 表来告诉解码器当前的 PID 是什么。 - 二分法 Seeking :由于没有索引,FFmpeg 在远程读取 TS 文件进行 Seek 时,无法计算偏移量。它必须使用 二分查找法(Binary Search)。它会尝试读取文件的中间位置,解析 PCR(程序时钟参考),判断时间是早了还是晚了,然后再折半查找。
- 网络代价:这种 "盲人摸象" 式的 Seek 会导致大量的 HTTP 请求碎片。为了定位一个时间点,可能需要 10-20 次 HTTP 请求,产生巨大的延迟。因此,MPEG-TS 并不适合单文件 HTTP 伪流播放。
6.2 MKV (Matroska):健壮的折中
MKV 使用 EBML(二进制 XML)结构。
- Cues 元素 :MKV 有一个类似
stbl的索引结构叫Cues。 - Cluster :媒体数据被组织在 Cluster 中,
Cues记录了时间戳到 Cluster 的映射。 - SeekHead :MKV 通常在文件头放置
SeekHead,指向Cues的位置(通常在文件尾)。 - 流式对比 :MKV 的流式能力与 MP4 类似,只要
Cues能够被快速读取。但 MKV 的容错性更强,即使索引损坏,FFmpeg 也可以通过线性扫描 Cluster 来恢复播放,而 MP4 丢失moov则彻底报废。
6.3 HLS / DASH (Fragmented MP4):彻底的碎片化
HLS (HTTP Live Streaming) 和 DASH 采用了完全不同的思路:分片(Segmentation)。
- 外部索引 :索引不再放在视频文件内部,而是放在外部的文本文件(
.m3u8或.mpdManifest)中。 - 物理切分 :视频被切成无数个 5-10 秒的小文件(
.ts或.m4s)。 - 流式优势:Seek 操作变成了 "下载第 N 个小文件"。这完全避免了单文件 Seek 的复杂性,对 CDN 极其友好,但增加了文件管理的复杂度。
7. 工程实践总结:FFmpeg 流式解复用的黄金法则
对于底层工程师,理解原理是为了更好地应用。在处理远程流式输入时,应遵循以下工程准则:
7.1 必须启用 Fast Start
在服务端转码或处理 MP4 时,务必加上 -movflags +faststart。这是通过 HTTP 播放 MP4 的性能基石。可以使用 qt-faststart 工具检查或修复现有的 MP4 文件。
7.2 优化 probesize 和 analyzeduration
当 FFmpeg 打开远程 URL 时(avformat_open_input),它会尝试读取一段数据来分析流信息(Codec Parameters)。
- 问题 :如果
moov很大(例如 4K 长视频,索引可能几十 MB),或者moov在文件尾部,默认的 probe 逻辑可能会导致长时间的阻塞或大量的无效数据下载。 - 调优 :在代码中显式设置
probesize(探测数据大小)和analyzeduration(探测时长)。对于已知编码格式的场景,甚至可以设得很小,强制 FFmpeg 信任moov中的描述而不去预读mdat。
7.3 避免 avformat_find_stream_info 的滥用
这个函数极其昂贵。在远程模式下,它可能会尝试解码几帧视频来获取精确的 FPS 或 Profile。如果工程场景中已知视频格式(如统一转码后的库),应尽量跳过此步骤,或手动解析 extradata。
7.4 缓冲区管理
FFmpeg 的 avio 层有内部缓冲区。在网络不稳定的情况下,增大 -rw_timeout 和缓冲区大小可以减少因网络抖动导致的 Seek 失败或播放中断。
7.5 预读与并发
在高级播放器开发中,不要完全依赖 FFmpeg 的同步读取。应在应用层实现 预读缓存(Pre-cache) ,利用空闲带宽预先下载 stbl 计算出的下一个 Chunk,平滑网络波动。
8. 结语
FFmpeg 之所以能像手术刀一样精准地从远程服务器切取视频片段,并非偶得,而是建立在 ISO BMFF 标准严谨的索引结构 与 HTTP 协议灵活的范围请求机制 之上的工程奇迹。
moov 盒子将时间空间化,stbl 索引表将逻辑映射为物理,而 HTTP Range 将本地 IO 扩展至网络。理解了这一条链路,我们也就理解了现代流媒体技术的基石。对于工程师而言,掌握这些底层原理,是优化播放体验、排查加载延迟、设计高效转码管线的必由之路。