
CVPR-2023
github:https://github.com/David-Zhao-1997/High-frequency-Stereo-Matching-Network
文章目录
- [1、Background and Motivation](#1、Background and Motivation)
- [2、Related Work](#2、Related Work)
- [3、Advantages / Contributions](#3、Advantages / Contributions)
- 4、Method
-
- [4.1、Channel-Attention Transformer extractor](#4.1、Channel-Attention Transformer extractor)
- [4.2、Multiscale Decouple LSTM Regularization](#4.2、Multiscale Decouple LSTM Regularization)
- [4.3、Disparity Normalization Refinement](#4.3、Disparity Normalization Refinement)
- [4.4、Loss Function](#4.4、Loss Function)
- 5、Experiments
-
- [5.1、Datasets and Metrics](#5.1、Datasets and Metrics)
- 5.2、Middlebury
- 5.3、KITTI-2015
- 5.4、Ablations
- [5.5、Performance and Inference Speed](#5.5、Performance and Inference Speed)
- [5.6、Evaluation on Multi-View Stereo](#5.6、Evaluation on Multi-View Stereo)
- [6、Conclusion(own) / Future work](#6、Conclusion(own) / Future work)
1、Background and Motivation
双目立体匹配是计算机视觉中的基础任务之一,旨在从一对经过校正的左右图像中估计每个像素的视差(disparity),进而推导出场景的深度信息。在自动驾驶、机器人导航、增强现实(AR)、虚拟现实(VR)等三维感知系统中扮演着关键角色。
传统方法(如SGBM)通常基于局部或全局优化策略(solve the optimization problem by minimizing the objective function containing the data(global information) and smoothing(local information) terms, while),在纹理丰富区域表现良好,但在弱纹理、重复纹理或遮挡区域容易失败。
随着深度学习的发展,基于学习的方法(如 PSMNet、RAFT-Stereo、CREStereo)显著提升了整体精度,尤其在挑战性区域取得了突破。
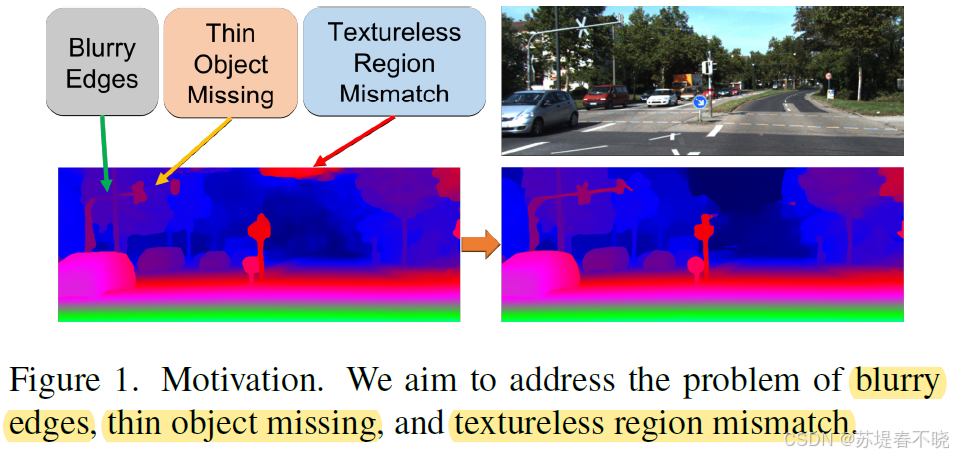
然而,现有方法仍面临两个核心问题:
-
边缘模糊
-
细节丢失
迭代式立体匹配方法(如 RAFT-Stereo)采用 GRU 结构进行视差图的逐步细化。用于生成视差更新量的隐藏状态与跨迭代传递的语义信息高度耦合。这种耦合导致在多次迭代后,高频细节(如边缘、细线)难以保留------Decouple LSTM
此外,大多数方法在低分辨率(如 1/4 原图)下进行迭代优化,虽节省计算资源,但牺牲了细节。后续的上采样模块若未考虑不同数据集间视差范围的巨大差异(如 KITTI 视差大,Middlebury 视差小),则泛化能力受限,甚至在微调时失效------Disparity Normalization strategy.
最后,特征提取器长期沿用 ResNet-like 结构,其感受野有限且难以建模长距离依赖,已成为性能瓶颈------ transformer 主干 with channel-wise self-attention
作者提出 Decouple LSTM and Normalization Refinement) 缓解上述问题
2、Related Work
Learning-based Approaches
- PSMNet (2018)
- AANet (2020)
- HITNet (2021)
Iterative Approaches
- RAFT
- RAFT-Stereo (2021)
the current iterative units are too simple, which limits the accuracy of iterative updates(信息耦合严重,限制了细节保留能力)
3、Advantages / Contributions
提出 DLNR(Decouple LSTM and Normalization Refinement)
-
通道注意力 Transformer 特征提取器(Channel-Attention Transformer Extractor):引入多尺度、多阶段设计,结合通道自注意力机制(CWSA)与 Pixel Unshuffle 下采样,在保留高频信息的同时建模长距离依赖。
-
解耦 LSTM(Decouple LSTM)模块:将 GRU 中用于生成视差更新量的隐藏状态与用于跨迭代传递语义信息的状态解耦,显著提升高频细节保留能力。
-
视差归一化精炼(Normalization Refinement)模块:在 cost volume aggregation 阶段将视差图归一化为图像宽度的比例,有效缓解跨域泛化问题,提升边缘锐度。
-
性能突破:Middlebury V3 排行榜第 1 名,超越第二名 13.04%。KITTI-2015 D1-fg 指标 SOTA(截至论文提交时)。
4、Method
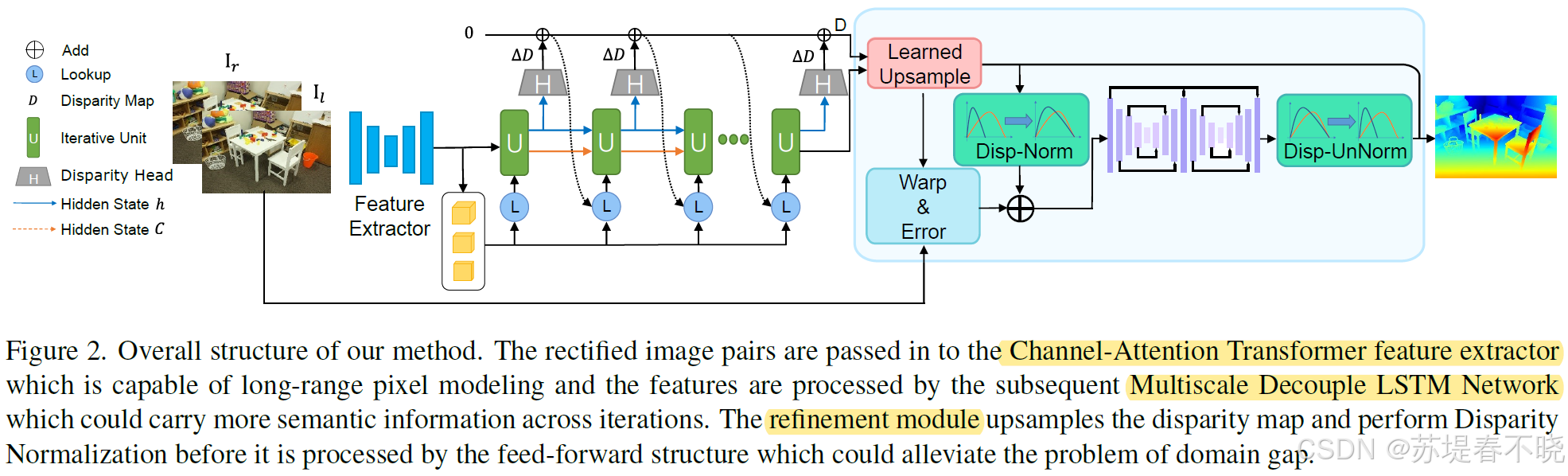
allow features containing subtle details to transfer across the iterations
整体 pipeline
python
class DLNR(nn.Module):
def __init__(self, args):
super().__init__()
self.args = args
context_dims = args.hidden_dims
self.extractor = Channel_Attention_Transformer_Extractor() #
self.update_block = LSTMMultiUpdateBlock(self.args, hidden_dims=args.hidden_dims)
self.bias_convs = nn.ModuleList(
[nn.Conv2d(context_dims[i], args.hidden_dims[i] * 4, 3, padding=3 // 2) for i in
range(self.args.n_gru_layers)])
self.volume_conv = nn.Sequential(
ResidualBlock(128, 128, 'instance', stride=1),
nn.Conv2d(128, 256, 3, padding=1))
self.normalizationRefinement = NormalizationRefinement()
def freeze_bn(self):
for m in self.modules():
if isinstance(m, nn.BatchNorm2d):
m.eval()
def initialize_flow(self, img):
N, _, H, W = img.shape
coords0 = coords_grid(N, H, W).to(img.device)
coords1 = coords_grid(N, H, W).to(img.device)
return coords0, coords1
def upsample_flow(self, flow, mask):
N, D, H, W = flow.shape
factor = 2 ** self.args.n_downsample
mask = mask.view(N, 1, 9, factor, factor, H, W)
mask = torch.softmax(mask, dim=2)
up_flow = F.unfold(factor * flow, [3, 3], padding=1)
up_flow = up_flow.view(N, D, 9, 1, 1, H, W)
up_flow = torch.sum(mask * up_flow, dim=2)
up_flow = up_flow.permute(0, 1, 4, 2, 5, 3)
return up_flow.reshape(N, D, factor * H, factor * W)
def forward(self, image1, image2, iters=12, flow_init=None, test_mode=False):
image1 = (2 * (image1 / 255.0) - 1.0).contiguous()
image2 = (2 * (image2 / 255.0) - 1.0).contiguous()
with autocast(enabled=self.args.mixed_precision):
*cnet_list, x = self.extractor(torch.cat((image1, image2), dim=0)) # cnet_list = [[1/4,1/4],[1/8,1/8],[1/16,1/16]] x = [1/4]
fmap1, fmap2 = self.volume_conv(x).split(dim=0, split_size=x.shape[0] // 2) # 1/4 torch.Size([4, 128, 96, 184]) -> torch.Size([2, 256, 96, 184])
net_h = [torch.tanh(x[0]) for x in cnet_list] # hidden state [1/4, 1/8, 1/16] c = 128
net_ext = [torch.relu(x[1]) for x in cnet_list] # lstm input [1/4, 1/8, 1/16] c = 128
net_ext = [list(conv(i).split(split_size=conv.out_channels // 4, dim=1)) for i, conv in
zip(net_ext, self.bias_convs)] # 分成了 4 份
# [1/4, 1/4, 1/4, 1/4] [1/8, 1/8, 1/8, 1/8] [1/16 1/16 1/16 1/16] c =128
if self.args.corr_implementation == "reg": # Default
corr_block = CorrBlock1D
fmap1, fmap2 = fmap1.float(), fmap2.float()
elif self.args.corr_implementation == "reg_cuda":
corr_block = CorrBlockFast1D
corr_fn = corr_block(fmap1, fmap2, radius=self.args.corr_radius, num_levels=self.args.corr_levels) # __init__
coords0, coords1 = self.initialize_flow(net_h[0]) # torch.Size([2, 2, 96, 184])
if flow_init is not None:
coords1 = coords1 + flow_init
flow_predictions = []
cnt = 0
for itr in range(iters):
coords1 = coords1.detach()
corr = corr_fn(coords1) # __call__ # torch.Size([2, 36, 96, 184]) 每个像素位置有 36 维相关特征(4 个尺度 × 9 个偏移),
flow = coords1 - coords0 # 初始化为 0
with autocast(enabled=self.args.mixed_precision):
if cnt == 0:
netC = net_h # [1/4, 1/8, 1/16] C=128
cnt = 1
netC, net_h, up_mask, delta_flow = self.update_block(netC, net_h, net_ext, corr, flow,
iter32=self.args.n_gru_layers == 3,
iter16=self.args.n_gru_layers >= 2)
# netC 和 net_h 均为 [1/4, 1/8, 1/16] C=128, up_mask ([2, 144, 96, 184]) delta_flow ([2, 2, 96, 184])
delta_flow[:, 1] = 0.0
coords1 = coords1 + delta_flow
if test_mode and itr < iters - 1:
continue
if up_mask is None:
disp_fullres = upflow(coords1 - coords0)
else:
disp_fullres = self.upsample_flow(coords1 - coords0, up_mask) # torch.Size([2, 2, 384, 736])
disp_fullres = disp_fullres[:, :1] # torch.Size([2, 1, 384, 736])
if itr == iters - 1:
# flow_predictions.append(disp_fullres)
# refine_value = self.normalizationRefinement(disp_fullres, image1, image2)
# disp_fullres = disp_fullres + refine_value
if disp_fullres.max() < 0:
flow_predictions.append(disp_fullres)
refine_value = self.normalizationRefinement(disp_fullres, image1, image2) # # torch.Size([2, 1, 384, 736])
disp_fullres = disp_fullres + refine_value
else:
pass
flow_predictions.append(disp_fullres)
if test_mode:
return coords1 - coords0, disp_fullres
return flow_predictionsKITTI2015,bs = 2 为例,输入 torch.Size([2, 3, 384, 736]),标签 torch.Size([2, 1, 384, 736]),剖析下细节过程
4.1、Channel-Attention Transformer extractor
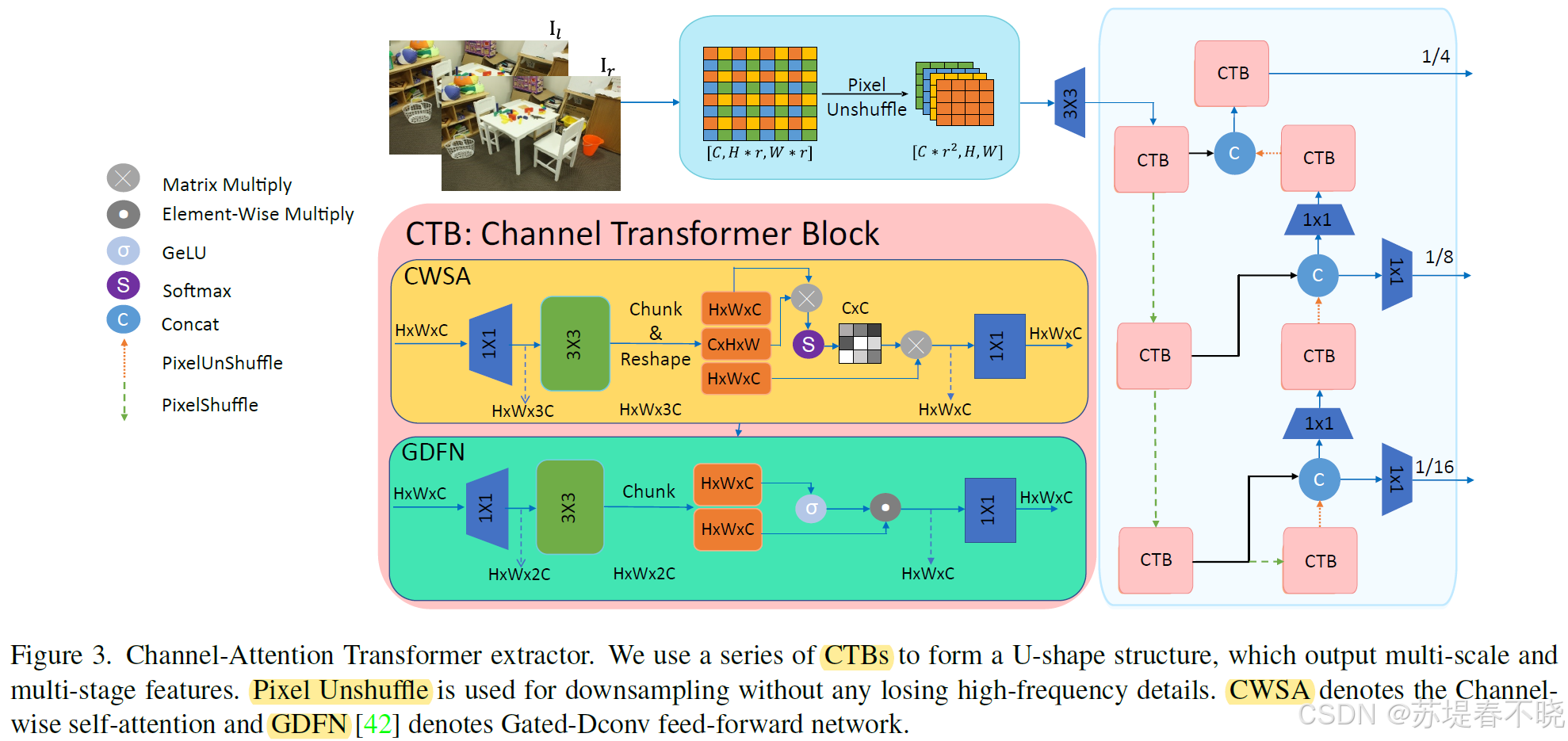
摒弃了 ResNet-like feature extractors,改用了 multi-stage and multi-scale Channel-Attention Transformer
- capture long-range pixel dependencies
- preserve as much high-frequency information as possible(通过 pixel unshuffle 操作)
python
*cnet_list, x = self.extractor(torch.cat((image1, image2), dim=0)) # cnet_list = [[1/4,1/4],[1/8,1/8],[1/16,1/16]] x = [1/4]输入原图,输出 LSTM iterations 的特征金字塔(1/4,1/8,1/16),一个 hidden state,一个 input state
还有个 1/4 会 split 为左右特征,做 all-pairs correlation
self.extractor 对应 Channel_Attention_Transformer_Extractor
python
class Channel_Attention_Transformer_Extractor(nn.Module):
def __init__(self,
inp_channels=3,
out_channels=3,
dim=64,
num_blocks=[4, 6, 6, 8],
num_refinement_blocks=4,
heads=[1, 2, 4, 8],
ffn_expansion_factor=2.66,
bias=False,
LayerNorm_type='WithBias',
dual_pixel_task=False
):
super(Channel_Attention_Transformer_Extractor, self).__init__()
self.pixelUnShuffle = nn.PixelUnshuffle(4)
self.patch_embed = OverlapPatchEmbed(48, dim)
self.encoder_level1 = nn.Sequential(*[
TransformerBlock(dim=dim, num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias,
LayerNorm_type=LayerNorm_type) for i in range(num_blocks[0])])
self.down1_2 = Downsample(dim)
self.encoder_level2 = nn.Sequential(*[
TransformerBlock(dim=int(dim * 2 ** 1), num_heads=heads[1], ffn_expansion_factor=ffn_expansion_factor,
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[1])])
self.down2_3 = Downsample(int(dim * 2 ** 1))
self.encoder_level3 = nn.Sequential(*[
TransformerBlock(dim=int(dim * 2 ** 2), num_heads=heads[2], ffn_expansion_factor=ffn_expansion_factor,
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[2])])
self.down3_4 = Downsample(int(dim * 2 ** 2))
self.latent = nn.Sequential(*[
TransformerBlock(dim=int(dim * 2 ** 3), num_heads=heads[3], ffn_expansion_factor=ffn_expansion_factor,
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[3])])
self.up4_3 = Upsample(int(dim * 2 ** 3))
self.reduce_chan_level3 = nn.Conv2d(int(dim * 2 ** 3), int(dim * 2 ** 2), kernel_size=1, bias=bias)
self.decoder_level3 = nn.Sequential(*[
TransformerBlock(dim=int(dim * 2 ** 2), num_heads=heads[2], ffn_expansion_factor=ffn_expansion_factor,
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[2])])
self.up3_2 = Upsample(int(dim * 2 ** 2))
self.reduce_chan_level2 = nn.Conv2d(int(dim * 2 ** 2), int(dim * 2 ** 1), kernel_size=1, bias=bias)
self.reduce_chan_level2_copy = nn.Conv2d(int(dim * 2 ** 2), int(dim * 2 ** 1), kernel_size=1, bias=bias)
self.decoder_level2 = nn.Sequential(*[
TransformerBlock(dim=int(dim * 2 ** 1), num_heads=heads[1], ffn_expansion_factor=ffn_expansion_factor,
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[1])])
self.up2_1 = Upsample(int(dim * 2 ** 1))
self.decoder_level1 = nn.Sequential(*[
TransformerBlock(dim=int(dim * 2 ** 1), num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor,
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[0])])
self.decoder_level1_copy = nn.Sequential(*[
TransformerBlock(dim=int(dim * 2 ** 1), num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor,
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[0])])
self.refinement = nn.Sequential(*[
TransformerBlock(dim=int(dim * 2 ** 1), num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor,
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_refinement_blocks)])
self.output16 = nn.Conv2d(int(dim * 2 ** 2), int(dim * 2 ** 1), kernel_size=1, bias=bias)
self.outputs16 = nn.ModuleList((self.output16, self.output16)) # 这么写权重共享的
self.outputs08 = nn.ModuleList((self.reduce_chan_level2, self.reduce_chan_level2_copy))
self.outputs04 = nn.ModuleList((self.decoder_level1, self.decoder_level1_copy))
self.dual_pixel_task = dual_pixel_task
if self.dual_pixel_task:
self.skip_conv = nn.Conv2d(dim, int(dim * 2 ** 1), kernel_size=1, bias=bias)
self.output = nn.Conv2d(int(dim * 2 ** 1), out_channels, kernel_size=3, stride=1, padding=1, bias=bias)
def forward(self, inp_img):
downsampled_img = self.pixelUnShuffle(inp_img) # torch.Size([4, 3, 384, 736]) -> 1/4 torch.Size([4, 48, 96, 184])
inp_enc_level1 = self.patch_embed(downsampled_img) # 1/4 torch.Size([4, 64, 96, 184])
out_enc_level1 = self.encoder_level1(inp_enc_level1) # 1/4 torch.Size([4, 64, 96, 184]), 4 次 self-attention
inp_enc_level2 = self.down1_2(out_enc_level1) # 1/8 torch.Size([4, 128, 48, 92]), 先 conv c//2,再 pixel unshuffle 4*c, 最终 2c
out_enc_level2 = self.encoder_level2(inp_enc_level2) # 1/8 torch.Size([4, 128, 48, 92]), 6 次 self-attention
inp_enc_level3 = self.down2_3(out_enc_level2) # 1/16 torch.Size([4, 256, 24, 46])
out_enc_level3 = self.encoder_level3(inp_enc_level3) # # 1/16 torch.Size([4, 256, 24, 46]), 6 次 self-attention
inp_enc_level4 = self.down3_4(out_enc_level3) # 1/32 torch.Size([4, 512, 12, 23])
latent = self.latent(inp_enc_level4) # 1/32 torch.Size([4, 512, 12, 23]), 8 次 self-attention
inp_dec_level3 = self.up4_3(latent) # 1/16 torch.Size([4, 256, 24, 46]) 先 conv 2c, 再 PixelShuffle 1/4c,最终 1/2c
inp_dec_level3 = torch.cat([inp_dec_level3, out_enc_level3], 1) # 1/16 torch.Size([4, 512, 24, 46])
inp_dec_level3 = self.reduce_chan_level3(inp_dec_level3) # 1/16 torch.Size([4, 256, 24, 46])
inp_dec_level3_copy = inp_dec_level3[:(inp_dec_level3.shape[0] // 2)] # 1/16 torch.Size([2, 256, 24, 46])
outputs16 = [f(inp_dec_level3_copy) for f in self.outputs16] # [1/16, 1/16] torch.Size([2, 128, 24, 46])
out_dec_level3 = self.decoder_level3(inp_dec_level3) # 1/16 torch.Size([4, 256, 24, 46]), 6 次 self-attention
inp_dec_level2 = self.up3_2(out_dec_level3) # 1/8 torch.Size([4, 128, 48, 92])
inp_dec_level2 = torch.cat([inp_dec_level2, out_enc_level2], 1) # 1/8 torch.Size([4, 256, 48, 92])
inp_dec_level2_copy = inp_dec_level2[:(inp_dec_level2.shape[0] // 2)] # 1/8 torch.Size([2, 256, 48, 92])
outputs08 = [f(inp_dec_level2_copy) for f in self.outputs08] # (1/8, 1/8) torch.Size([2, 128, 48, 92])
inp_dec_level2 = self.reduce_chan_level2(inp_dec_level2) # 1/8 torch.Size([4, 128, 48, 92])
out_dec_level2 = self.decoder_level2(inp_dec_level2) # 1/8 torch.Size([4, 128, 48, 92]), 6 次 self-attention
inp_dec_level1 = self.up2_1(out_dec_level2) # 1/4 torch.Size([4, 64, 96, 184])
inp_dec_level1 = torch.cat([inp_dec_level1, out_enc_level1], 1) # 1/4 torch.Size([4, 128, 96, 184])
v = inp_dec_level1 # 1/4 torch.Size([4, 128, 96, 184])
inp_dec_level1_copy = inp_dec_level1[:(inp_dec_level1.shape[0] // 2)] # 1/4 torch.Size([2, 128, 96, 184])
outputs04 = [f(inp_dec_level1_copy) for f in self.outputs04] # (1/4, 1/4) torch.Size([2, 128, 96, 184])
return outputs04, outputs08, outputs16, v
# 返回三个尺度的左图特征(双份),以及完整的 1/4 特征图 v
# 1/4, 1/4 torch.Size([2, 128, 96, 184])
# 1/8, 1/8 torch.Size([2, 128, 48, 92])
# 1/16, 1/16 torch.Size([2, 128, 24, 46])
# 1/4 torch.Size([4, 128, 96, 184])核心就是 channel-wise self-attention,以及 pixel unshuffle 下采样和 pixel shuffle 上采样,后续会介绍
(1)Preserving high-frequency information
下采样的时候采用 pixel unshuffle 操作,而不是简单的 pooling,避免传统卷积下采样导致的高频信息损失。
好处是保留了 high-frequency information,缺点就是计算量明显增大
例如,将 C, H×2, W×2 重排为 C×4, H, W,无信息丢失。
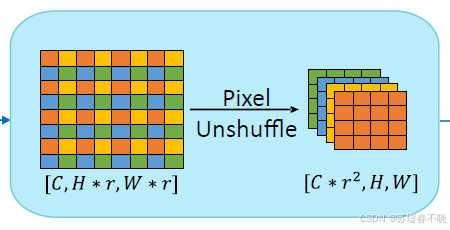
对应代码 nn.PixelUnshuffle(2),其中 2 表示下采样 2 倍
上采样则为 nn.PixelShuffle(2),其中 2 表示上采样 2 倍
python
class Downsample(nn.Module):
def __init__(self, n_feat):
super(Downsample, self).__init__()
self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat // 2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelUnshuffle(2))
def forward(self, x):
return self.body(x)
class Upsample(nn.Module):
def __init__(self, n_feat):
super(Upsample, self).__init__()
self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat * 2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelShuffle(2))
def forward(self, x):
return self.body(x)(2)Channel Attention Mechanism
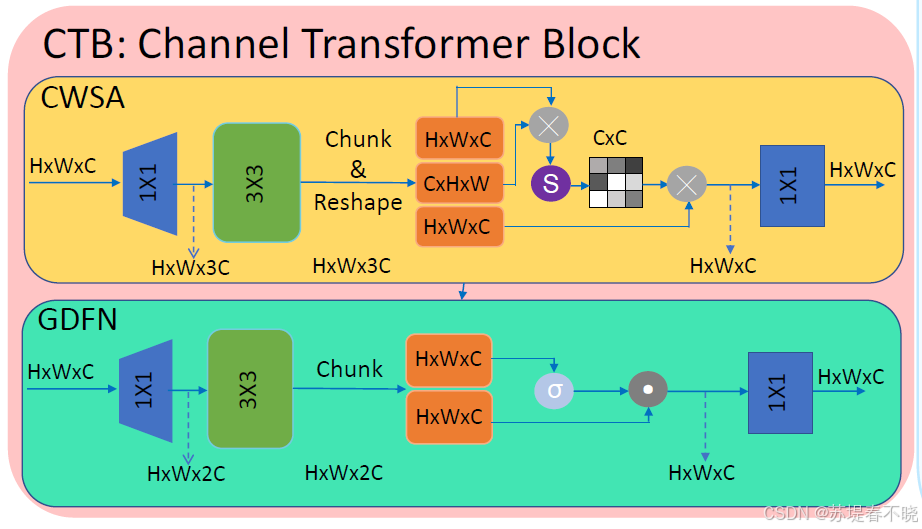
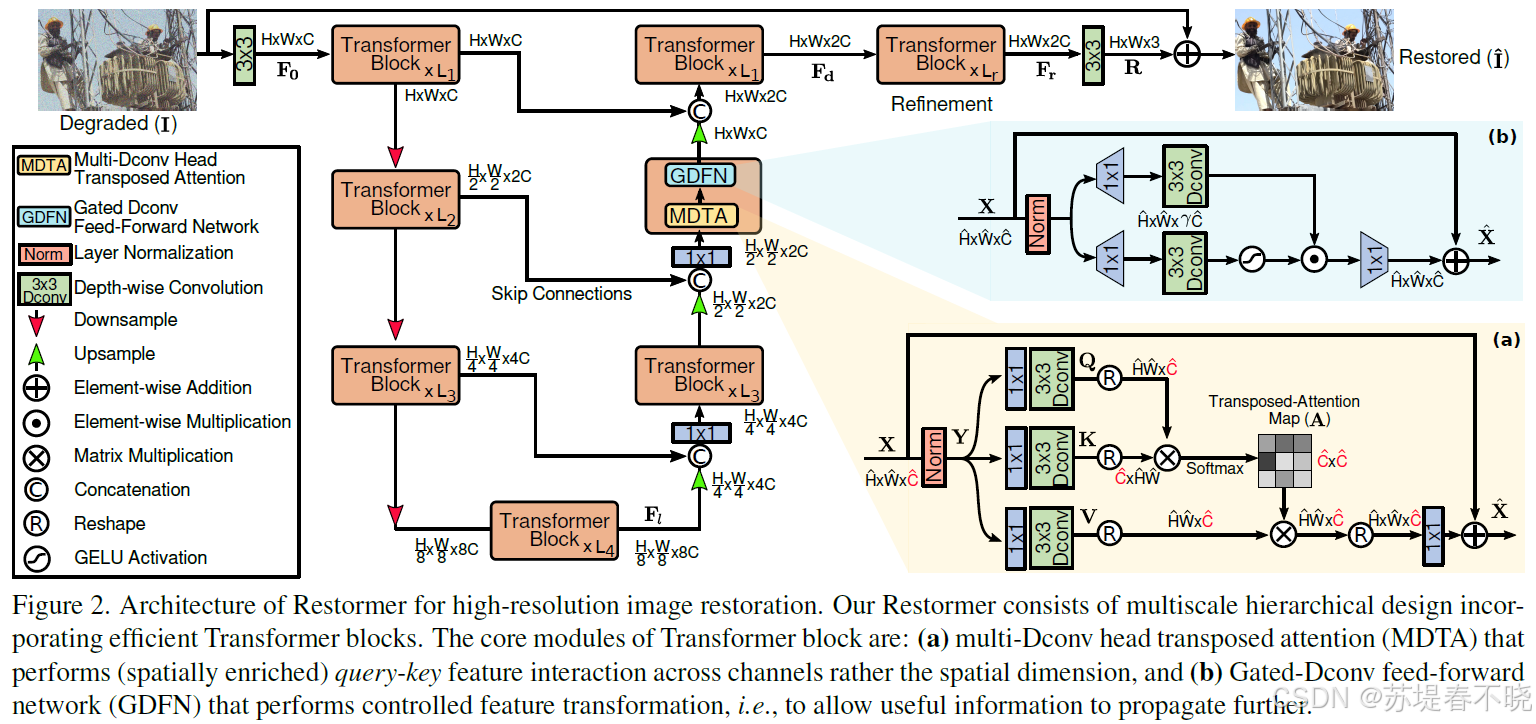
优化了原来的 self-attention with linear complexity(computes on the channel dimension)
来自于
Zamir S W, Arora A, Khan S, et al. Restormer: Efficient transformer for high-resolution image restorationC//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 5728-5739.
python
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1)) # 每个"头"有自己的温度,所以形状是 (num_heads, 1, 1)
# 如果 temperature 很小 → 注意力更集中(只盯一个点);如果很大 → 注意力更分散(看一片区域)。
self.qkv = nn.Conv2d(dim, dim * 3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim * 3, dim * 3, kernel_size=3, stride=1, padding=1, groups=dim * 3, bias=bias) # 让 Q、K、V 不只是"点特征",还包含局部上下文信息,提升表达能力
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x):
b, c, h, w = x.shape # torch.Size([4, 64, 96, 184])
qkv = self.qkv_dwconv(self.qkv(x)) # torch.Size([4, 192, 96, 184])
q, k, v = qkv.chunk(3, dim=1) # torch.Size([4, 64, 96, 184]), torch.Size([4, 64, 96, 184]), torch.Size([4, 64, 96, 184])
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads) # torch.Size([4, 1, 64, 17664])
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads) # torch.Size([4, 1, 64, 17664])
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads) # torch.Size([4, 1, 64, 17664])
# 对 Q 和 K 在最后一个维度(即所有像素位置)做 L2 归一化。
q = torch.nn.functional.normalize(q, dim=-1) # torch.Size([4, 1, 64, 17664])
k = torch.nn.functional.normalize(k, dim=-1) # torch.Size([4, 1, 64, 17664])
attn = (q @ k.transpose(-2, -1)) * self.temperature # torch.Size([4, 1, 64, 64])
attn = attn.softmax(dim=-1) # torch.Size([4, 1, 64, 64])
out = (attn @ v) # torch.Size([4, 1, 64, 17664])
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w) # torch.Size([4, 64, 96, 184])
out = self.project_out(out) # torch.Size([4, 64, 96, 184])
return out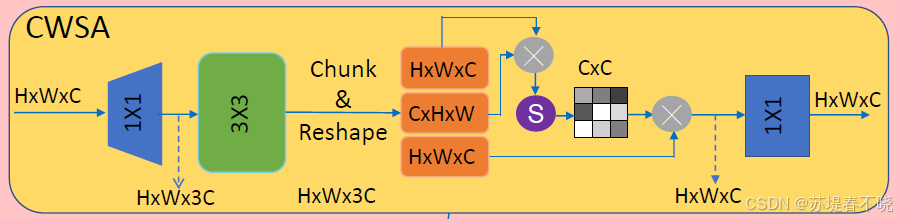
核心代码 attn = (q @ k.transpose(-2, -1)) * self.temperature
计算的是每个通道与其他通道的相关性,而不是每个像素与其他像素的相关性。 attn 的形状是 [b, head, c, c],表示"通道-通道"注意力矩阵。
不是传统的 空间自注意力(如 Vision Transformer 中每个像素关注其他像素),是通道注意力 + 局部感知的混合设计:
- 先用深度卷积 给 Q、K、V 加入局部空间信息;
- 然后在通道维度上做注意力:每个通道决定"该从哪些其他通道获取信息";
- 归一化 + 温度调节 让注意力更稳定可控;
- 多头机制让模型从多个子空间学习不同模式。
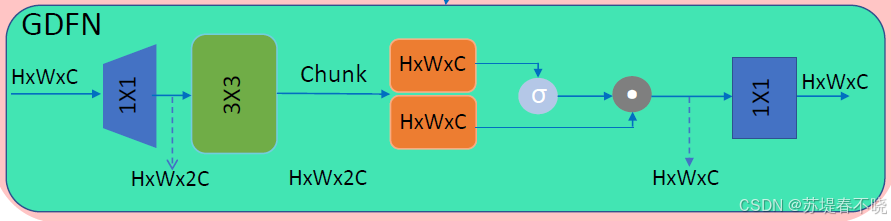
FFN
python
class FeedForward(nn.Module):
def __init__(self, dim, ffn_expansion_factor, bias):
super(FeedForward, self).__init__()
hidden_features = int(dim * ffn_expansion_factor) # (int) 2.66 * 64 = 170
self.project_in = nn.Conv2d(dim, hidden_features * 2, kernel_size=1, bias=bias)
self.dwconv = nn.Conv2d(hidden_features * 2, hidden_features * 2, kernel_size=3, stride=1, padding=1,
groups=hidden_features * 2, bias=bias)
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x):
x = self.project_in(x) # torch.Size([4, 64, 96, 184])->torch.Size([4, 340, 96, 184])
x1, x2 = self.dwconv(x).chunk(2, dim=1) # # torch.Size([4, 170, 96, 184])
x = F.gelu(x1) * x2 # torch.Size([4, 170, 96, 184])
x = self.project_out(x) # torch.Size([4, 64, 96, 184])
return x
通道扩展:提升模型容量;
深度卷积:注入局部空间上下文(适合图像!);
门控机制(GLU 变种):用 x2 动态控制 x1 的信息流,比单纯激活更智能;
高效设计:深度卷积 + 1×1 卷积,计算量可控。
4.2、Multiscale Decouple LSTM Regularization
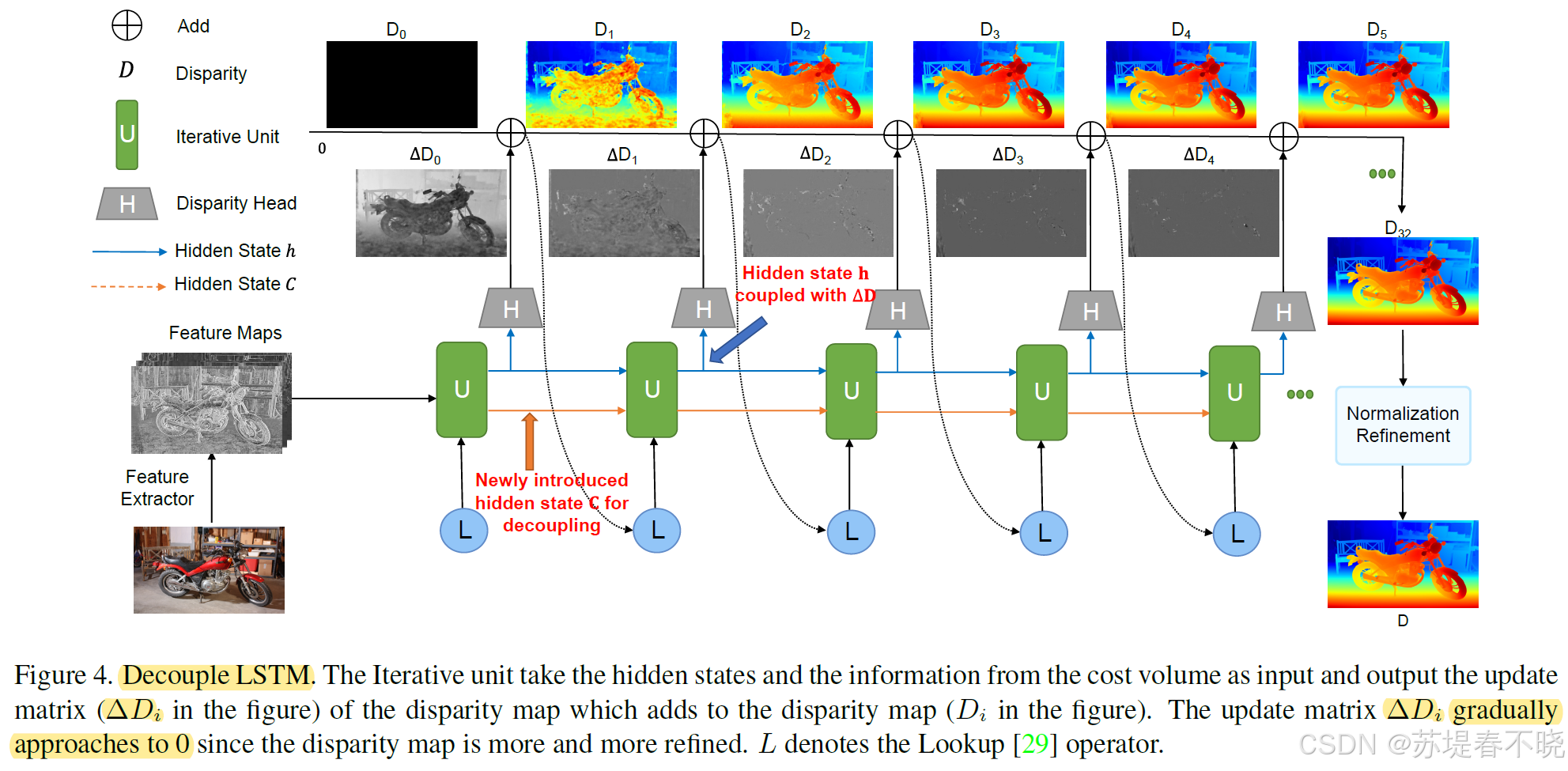
combining the multiscale and multi-stage information F l F_l Fl, F m F_m Fm and F h F_h Fh from the feature extractors,
(1)Multiscale Design
1/4,1/8,1/16 都会进入 iterations 模块
low-resolution branch better deals with the texture-less regions
high-resolution branch captures more high-frequency details
(2)Decouple Mechanism
把 iterations 模块的 GRU 替换为了 LSTM,decouple 相较于 GRU 来说的,LSTM 本身就比 GRU 多一个 cell(state C)
newly introduced hidden state C is used only for transferring information across iterations.
实验表明,C 能更好地保留边缘与细小结构
LSTM
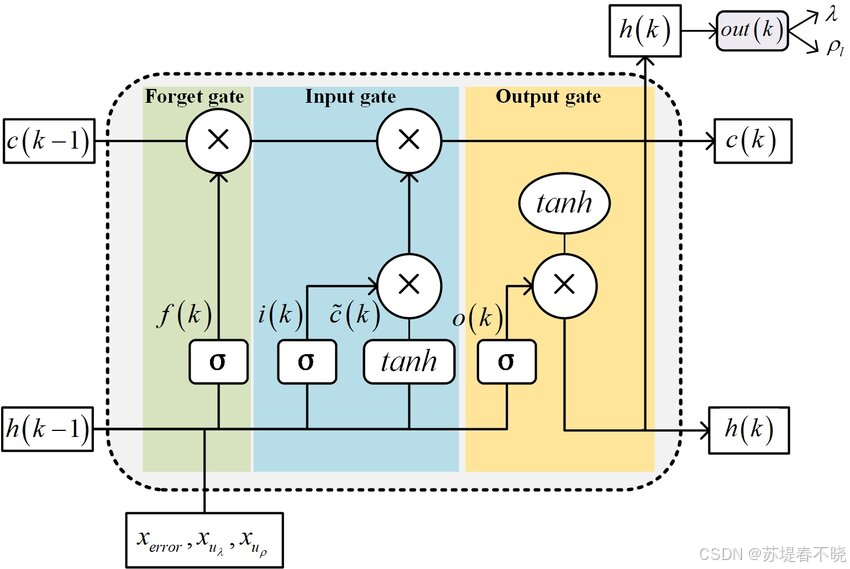
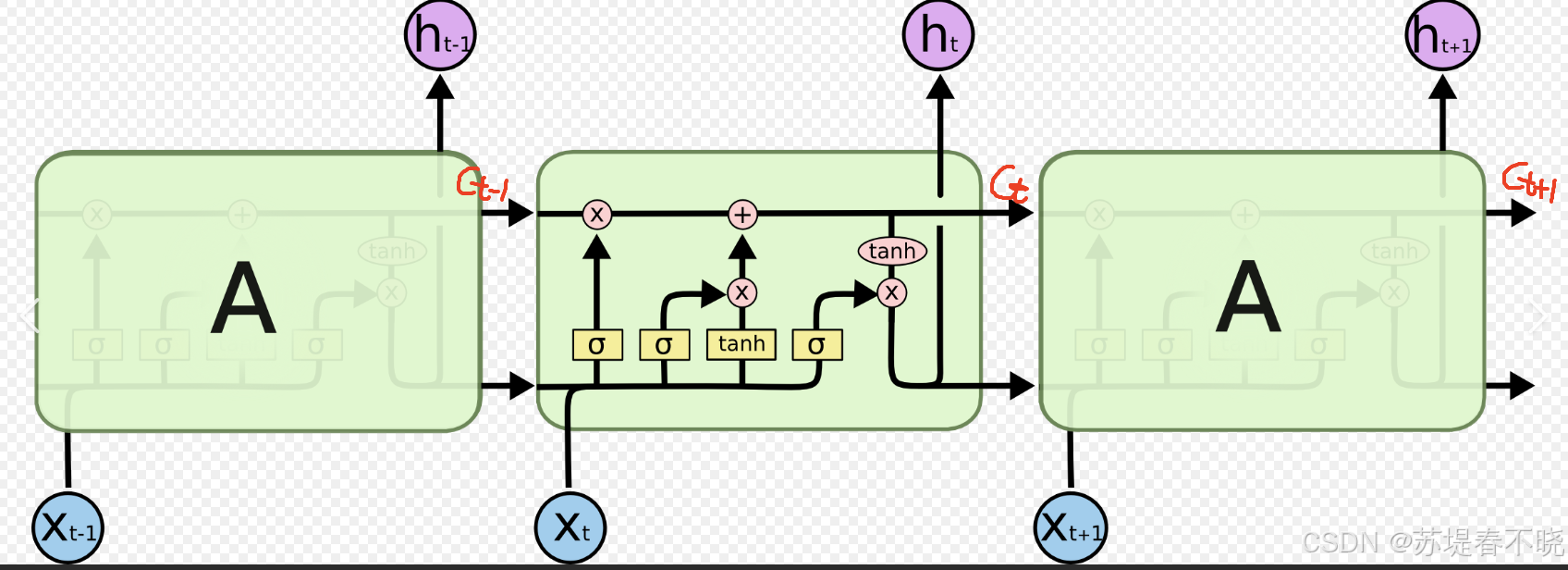
-
Cell State 是 LSTM 的"记忆内核"------稳定、持久、受保护。
-
Hidden State 是 LSTM 的"对外窗口"------灵活、可变、用于交互。
GRU
- 将 C_t 和 h_t 合并为一个状态,用重置门+更新门近似实现类似功能,但牺牲了对长期记忆的精细控制。
总结:
-
GRU 更轻量,适合短序列
-
LSTM 更强大,适合长距离依赖(如视频时序建模、文档理解)
python
netC, net_h, up_mask, delta_flow = self.update_block(netC, net_h, net_ext, corr, flow,
iter32=self.args.n_gru_layers == 3,
iter16=self.args.n_gru_layers >= 2)self.update_block 由 RATF-Stereo 中的 GRU 替换为了 LSTM,多了一个 netC 状态,也即 LSTM 中的 cell
初始化同 net_h,就是 GRU 里面的 hidden state
python
if cnt == 0:
netC = net_h # [1/4, 1/8, 1/16] C=128
cnt = 1输入中的 corr 来自于 1D correlation block,r =4 ,也即窗口大小 1x9,同 RATF-Stereo,核心就是多尺度+窗口+all-pairs+look up
python
class CorrBlock1D:
def __init__(self, fmap1, fmap2, num_levels=4, radius=4):
self.num_levels = num_levels # 4
self.radius = radius # 4
self.corr_pyramid = []
# all pairs correlation
corr = CorrBlock1D.corr(fmap1, fmap2) # 调用 corr 函数 torch.Size([2, 96, 184, 1, 184])
batch, h1, w1, dim, w2 = corr.shape # torch.Size([2, 96, 184, 1, 184])
corr = corr.reshape(batch*h1*w1, dim, 1, w2) # torch.Size([35328, 1, 1, 184])
self.corr_pyramid.append(corr)
for i in range(self.num_levels): # 构建多尺度相关金字塔(通过水平方向下采样)
corr = F.avg_pool2d(corr, [1,2], stride=[1,2])
self.corr_pyramid.append(corr) # [35328, 1, 1, 184] / [35328, 1, 1, 92] / [35328, 1, 1, 46] / [35328, 1, 1, 23] / [35328, 1, 1, 11]
def __call__(self, coords):
r = self.radius # 4
coords = coords[:, :1].permute(0, 2, 3, 1) # torch.Size([2, 96, 184, 1]) 取 x
batch, h1, w1, _ = coords.shape # torch.Size([2, 96, 184, 1])
out_pyramid = []
for i in range(self.num_levels):
corr = self.corr_pyramid[i]
dx = torch.linspace(-r, r, 2*r+1)
dx = dx.view(1, 1, 2*r+1, 1).to(coords.device) # torch.Size([1, 1, 9, 1])
x0 = dx + coords.reshape(batch*h1*w1, 1, 1, 1) / 2**i # torch.Size([35328, 1, 9, 1])
y0 = torch.zeros_like(x0) # torch.Size([35328, 1, 9, 1])
coords_lvl = torch.cat([x0,y0], dim=-1) # torch.Size([35328, 1, 9, 2])
corr = bilinear_sampler(corr, coords_lvl) # torch.Size([35328, 1, 1, 9]) 对每个查询点,在 ±r 范围内采样 9 个相关分数。
corr = corr.view(batch, h1, w1, -1) # torch.Size([2, 96, 184, 9])
out_pyramid.append(corr)
out = torch.cat(out_pyramid, dim=-1) # torch.Size([2, 96, 184, 36])
return out.permute(0, 3, 1, 2).contiguous().float() # torch.Size([2, 36, 96, 184]) 每个像素位置有 36 维相关特征(4 个尺度 × 9 个偏移),
@staticmethod
def corr(fmap1, fmap2): # 对每个 batch、每个高度行、每个左图位置 x1,计算它与右图所有 x2 位置的相似度。
B, D, H, W1 = fmap1.shape # torch.Size([2, 256, 96, 184])
_, _, _, W2 = fmap2.shape # torch.Size([2, 256, 96, 184])
fmap1 = fmap1.view(B, D, H, W1) # torch.Size([2, 256, 96, 184])
fmap2 = fmap2.view(B, D, H, W2) # torch.Size([2, 256, 96, 184])
corr = torch.einsum('aijk,aijh->ajkh', fmap1, fmap2) # torch.Size([2, 96, 184, 184]) # B x H x W1 x D * B x H x D x W2 = B x H x W1 x W2
corr = corr.reshape(B, H, W1, 1, W2).contiguous() # torch.Size([2, 96, 184, 1, 184])
return corr / torch.sqrt(torch.tensor(D).float()) # torch.Size([2, 96, 184, 1, 184])作者对这段代码进行了加速处理,需要编译才能,否则默认不加速
python
if self.args.corr_implementation == "reg": # Default
corr_block = CorrBlock1D
fmap1, fmap2 = fmap1.float(), fmap2.float()
elif self.args.corr_implementation == "reg_cuda":
corr_block = CorrBlockFast1D迭代的细节如下
python
class LSTMMultiUpdateBlock(nn.Module):
def __init__(self, args, hidden_dims=[]):
super().__init__()
self.args = args
self.encoder = BasicMotionEncoder(args)
encoder_output_dim = 128
self.lstm08 = LSTM(hidden_dims[2], encoder_output_dim + hidden_dims[1] * (args.n_gru_layers > 1))
self.lstm16 = LSTM(hidden_dims[1], hidden_dims[0] * (args.n_gru_layers == 3) + hidden_dims[2])
self.lstm32 = LSTM(hidden_dims[0], hidden_dims[1])
self.flow_head = FlowHead(hidden_dims[2], hidden_dim=256, output_dim=2)
factor = 2 ** self.args.n_downsample
self.mask = nn.Sequential(
nn.Conv2d(hidden_dims[2], 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, (factor ** 2) * 9, 1, padding=0))
def forward(self, netC, netH, inp, corr=None, flow=None, iter08=True, iter16=True, iter32=True, update=True):
if iter32:
netC[2], netH[2] = self.lstm32(netC[2], netH[2], *(inp[2]), pool2x(netH[1]))
if iter16:
if self.args.n_gru_layers > 2:
netC[1], netH[1] = self.lstm16(netC[1], netH[1], *(inp[1]), pool2x(netH[0]),
interp(netH[2], netH[1]))
else:
netC[1], netH[1] = self.lstm16(netC[1], netH[1], *(inp[1]), pool2x(netH[0]))
if iter08:
motion_features = self.encoder(flow, corr)
if self.args.n_gru_layers > 1:
netC[0], netH[0] = self.lstm08(netC[0], netH[0], *(inp[0]), motion_features,
interp(netH[1], netH[0]))
else:
netC[0], netH[0] = self.lstm08(netC[0], netH[0], *(inp[0]), motion_features)
if not update:
return netH
delta_flow = self.flow_head(netH[0])
mask = .25 * self.mask(netH[0])
return netC, netH, mask, delta_flow输出 C state 和 H state,learnable 上采样特征,以及 Δ \Delta Δ flow,multi-scale 分开更新
4.3、Disparity Normalization Refinement
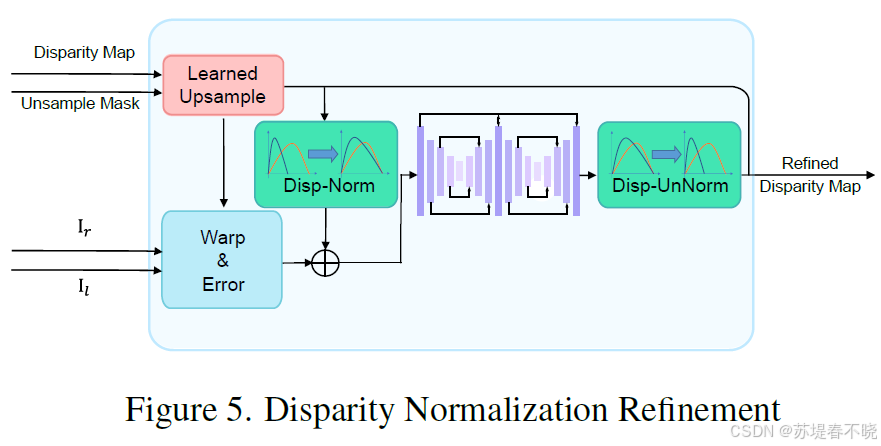
intended to capture more subtle details at full resolution
优势:归一化使精炼模块对输入视差范围不敏感(会反归一化回来),大幅提升跨数据集泛化能力。
python
class NormalizationRefinement(nn.Module):
"""Height and width need to be divided by 16"""
def __init__(self):
super(NormalizationRefinement, self).__init__()
# Left and warped error
in_channels = 6
self.conv1 = conv2d(in_channels, 16)
self.conv2 = conv2d(1, 16) # on low disparity
self.conv_start = BasicConv(32, 32, kernel_size=3, padding=2, dilation=2)
self.conv1a = BasicConv(32, 48, kernel_size=3, stride=2, padding=1)
self.conv2a = BasicConv(48, 64, kernel_size=3, stride=2, padding=1)
self.conv3a = BasicConv(64, 96, kernel_size=3, stride=2, dilation=2, padding=2)
self.conv4a = BasicConv(96, 128, kernel_size=3, stride=2, dilation=2, padding=2)
self.deconv4a = Conv2x(128, 96, deconv=True)
self.deconv3a = Conv2x(96, 64, deconv=True)
self.deconv2a = Conv2x(64, 48, deconv=True)
self.deconv1a = Conv2x(48, 32, deconv=True)
self.conv1b = Conv2x(32, 48)
self.conv2b = Conv2x(48, 64)
self.conv3b = Conv2x(64, 96, mdconv=True)
self.conv4b = Conv2x(96, 128, mdconv=True)
self.deconv4b = Conv2x(128, 96, deconv=True)
self.deconv3b = Conv2x(96, 64, deconv=True)
self.deconv2b = Conv2x(64, 48, deconv=True)
self.deconv1b = Conv2x(48, 32, deconv=True)
self.final_conv = nn.Conv2d(32, 1, 3, 1, 1)
def forward(self, low_disp, left_img, right_img):
assert low_disp.dim() == 4
low_disp = -low_disp # torch.Size([2, 1, 384, 736])
# low_disp = low_disp.unsqueeze(1) # [B, 1, H, W]
scale_factor = left_img.size(-1) / low_disp.size(-1) # 1.0
if scale_factor == 1.0:
disp = low_disp
else:
disp = F.interpolate(low_disp, size=left_img.size()[-2:], mode='bilinear', align_corners=False)
disp = disp * scale_factor
# min_disp = torch.min(disp)
# max_disp = torch.max(disp)
warped_right = disp_warp(right_img, disp)[0] # [B, C, H, W] C=3
disp = disp / disp.shape[3] * 1024 # 把视差值归一化到"以 1024 为基准"的尺度
# Warp right image to left view with current disparity
error = warped_right - left_img # [B, C, H, W]
concat1 = torch.cat((error, left_img), dim=1) # [B, 6, H, W]
conv1 = self.conv1(concat1) # [B, 16, H, W] 图像误差特征
conv2 = self.conv2(disp) # [B, 16, H, W] 视差特征
x = torch.cat((conv1, conv2), dim=1) # [B, 32, H, W]
x = self.conv_start(x)
rem0 = x
x = self.conv1a(x)
rem1 = x
x = self.conv2a(x)
rem2 = x
x = self.conv3a(x)
rem3 = x
x = self.conv4a(x) # 1/16 torch.Size([2, 128, 24, 46])
rem4 = x
x = self.deconv4a(x, rem3)
rem3 = x
x = self.deconv3a(x, rem2)
rem2 = x
x = self.deconv2a(x, rem1)
rem1 = x
x = self.deconv1a(x, rem0) # 1 torch.Size([2, 32, 384, 736])
rem0 = x
x = self.conv1b(x, rem1)
rem1 = x
x = self.conv2b(x, rem2)
rem2 = x
x = self.conv3b(x, rem3)
rem3 = x
x = self.conv4b(x, rem4)
x = self.deconv4b(x, rem3)
x = self.deconv3b(x, rem2)
x = self.deconv2b(x, rem1)
x = self.deconv1b(x, rem0) # [B, 32, H, W]
residual_disp = self.final_conv(x) # [B, 1, H, W]
new_disp = F.leaky_relu(disp + residual_disp, inplace=True) # [B, 1, H, W]
disp = new_disp / 1024 * disp.shape[3] # dtu_test_tank 把归一化的视差还原回原始尺度(乘以图像宽度 / 1024)。
return -disp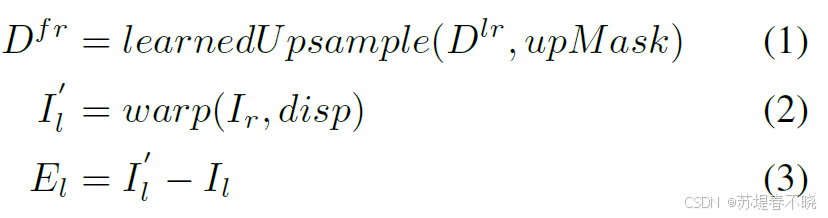
上采样预测的视差,右图+视差 warp 到左图,计算原左图和 warp 后的左图得到 error
python
assert low_disp.dim() == 4
low_disp = -low_disp # torch.Size([2, 1, 384, 736])
# low_disp = low_disp.unsqueeze(1) # [B, 1, H, W]
scale_factor = left_img.size(-1) / low_disp.size(-1) # 1.0
if scale_factor == 1.0:
disp = low_disp
else:
disp = F.interpolate(low_disp, size=left_img.size()[-2:], mode='bilinear', align_corners=False)
disp = disp * scale_factor
# min_disp = torch.min(disp)
# max_disp = torch.max(disp)
warped_right = disp_warp(right_img, disp)[0] # [B, C, H, W] C=3
# Warp right image to left view with current disparity
error = warped_right - left_img # [B, C, H, W]核心的操作 warp 源码如下
python
def disp_warp(img, disp, padding_mode='border'):
"""Warping by disparity
Args:
img: [B, 3, H, W]
disp: [B, 1, H, W], positive
padding_mode: 'zeros' or 'border'
Returns:
warped_img: [B, 3, H, W]
valid_mask: [B, 3, H, W]
"""
assert disp.min() >= 0
grid = meshgrid(img) # [B, 2, H, W] in image scale torch.Size([2, 2, 384, 736])
# Note that -disp here
offset = torch.cat((-disp, torch.zeros_like(disp)), dim=1) # [B, 2, H, W]
sample_grid = grid + offset
sample_grid = normalize_coords(sample_grid) # [B, H, W, 2] in [-1, 1]
warped_img = F.grid_sample(img, sample_grid, mode='bilinear', padding_mode=padding_mode)
mask = torch.ones_like(img)
valid_mask = F.grid_sample(mask, sample_grid, mode='bilinear', padding_mode='zeros')
valid_mask[valid_mask < 0.9999] = 0
valid_mask[valid_mask > 0] = 1
return warped_img, valid_mask注意这里的 -disp,disp≥0,同物品左图的位置相比右图是要靠右的,
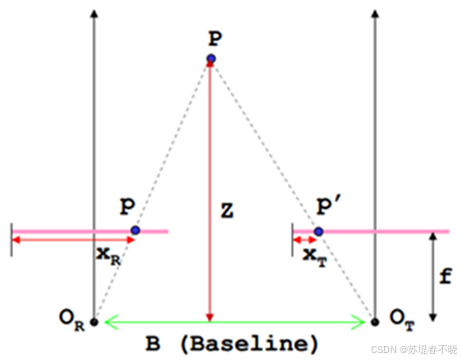
不是把右图点推到左图,而是问 "左图每个点应该从右图哪里取"(左图位置已知 → 去右图左边找 → 减 disp → 用 -disp 作为偏移)
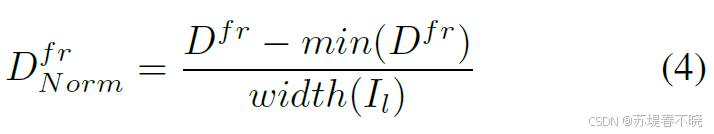
python
disp = disp / disp.shape[3] * 1024 # 把视差值归一化到"以 1024 为基准"的尺度min 默认是 0,省略了应该
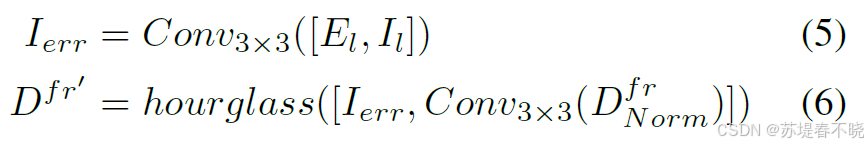
python
concat1 = torch.cat((error, left_img), dim=1) # [B, 6, H, W]
conv1 = self.conv1(concat1) # [B, 16, H, W] 图像误差特征
conv2 = self.conv2(disp) # [B, 16, H, W] 视差特征
x = torch.cat((conv1, conv2), dim=1) # [B, 32, H, W]hourglass 网络有两个
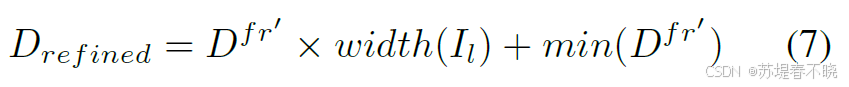
python
# dtu_test_tank 把归一化的视差还原回原始尺度(乘以图像宽度 / 1024)。
disp = new_disp / 1024 * disp.shape[3] 调用的条件
python
if itr == iters - 1:
if disp_fullres.max() < 0:
flow_predictions.append(disp_fullres)
refine_value = self.normalizationRefinement(disp_fullres, image1, image2) # # torch.Size([2, 1, 384, 736])
disp_fullres = disp_fullres + refine_value
else:
pass可以看到,最后一次迭代才会调用到 normalization refinement,会计算出一个修正值,然后加到原来的视差估计结果上
预测的视差全为负数的时候才会修正(不一定会触发吧,除非默认学出来的是光流,光流在视差场景下数值相反)
作者的解释
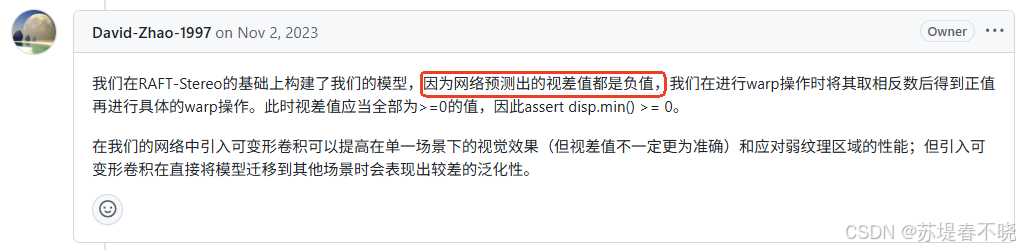
那应该就是学出来的可能是光流的关系,warp 的时候先转为视差,然后最后再转回去
早期训练不稳定的时候会触发???
4.4、Loss Function
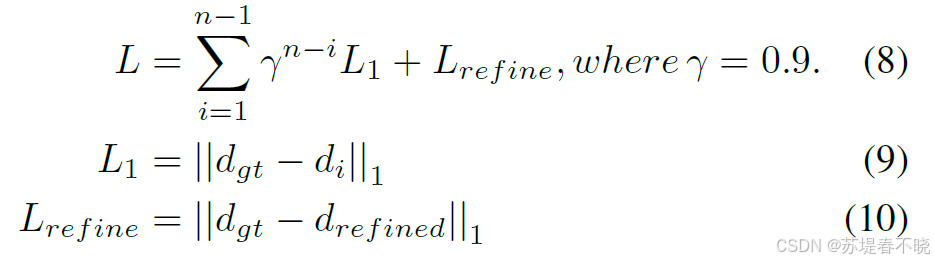
多了一个最后一次迭代的 refine 项
python
def sequence_loss(flow_preds, flow_gt, valid, loss_gamma=0.9, max_flow=700):
n_predictions = len(flow_preds)
assert n_predictions >= 1
flow_loss = 0.0
mag = torch.sum(flow_gt ** 2, dim=1).sqrt()
valid = ((valid >= 0.5) & (mag < max_flow)).unsqueeze(1)
assert valid.shape == flow_gt.shape, [valid.shape, flow_gt.shape]
assert not torch.isinf(flow_gt[valid.bool()]).any()
for i in range(n_predictions):
assert not torch.isnan(flow_preds[i]).any() and not torch.isinf(flow_preds[i]).any()
adjusted_loss_gamma = loss_gamma ** (15 / (n_predictions - 1))
i_weight = adjusted_loss_gamma ** (n_predictions - i - 1)
i_loss = (flow_preds[i] - flow_gt).abs()
assert i_loss.shape == valid.shape, [i_loss.shape, valid.shape, flow_gt.shape, flow_preds[i].shape]
flow_loss += i_weight * i_loss[valid.bool()].mean()
epe = torch.sum((flow_preds[-1] - flow_gt) ** 2, dim=1).sqrt()
epe = epe.view(-1)[valid.view(-1)]
metrics = {
'epe': epe.mean().item(),
'1px': (epe < 1).float().mean().item(),
'3px': (epe < 3).float().mean().item(),
'5px': (epe < 5).float().mean().item(),
}
return flow_loss, metrics5、Experiments
DA 包括 saturation change,image perturbance,random scales
5.1、Datasets and Metrics
- Scene Flow,训练该数据集的 parameters 同 【IGEV++】《IGEV++: Iterative Multi-range Geometry Encoding Volumes for Stereo Matching》
- Middlebury V3
- KITTI-2015
- DTU
- Tanks & Temples
metric
- bad 0.5、bad 1.0、bad 2.0、bad 4.0
- D1-all、D1-fg、D1-bg
- EPE
5.2、Middlebury
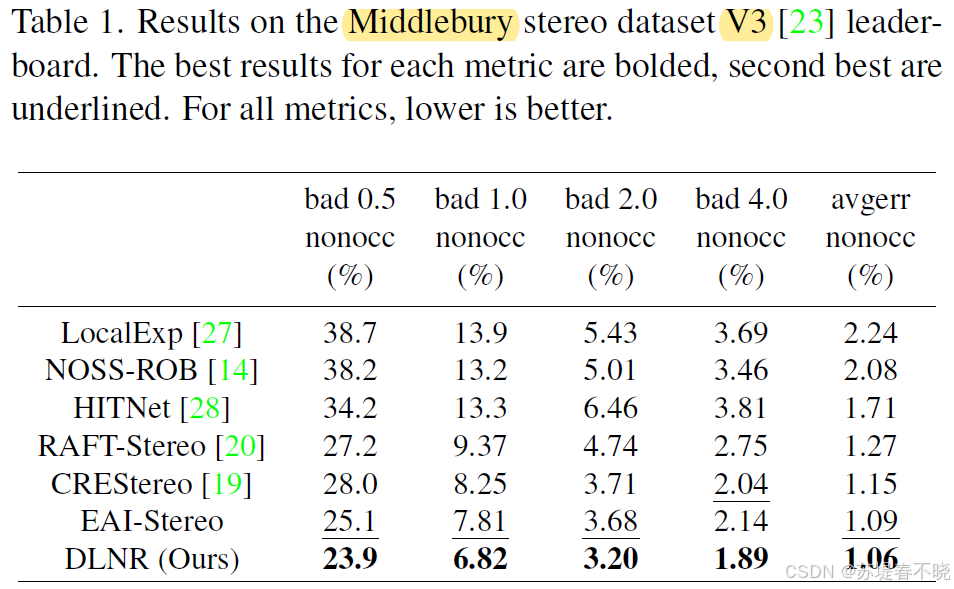
DLNR ranks 1st on the Middlebury V3 leaderboard, outperforming the next best method by 13.04%.
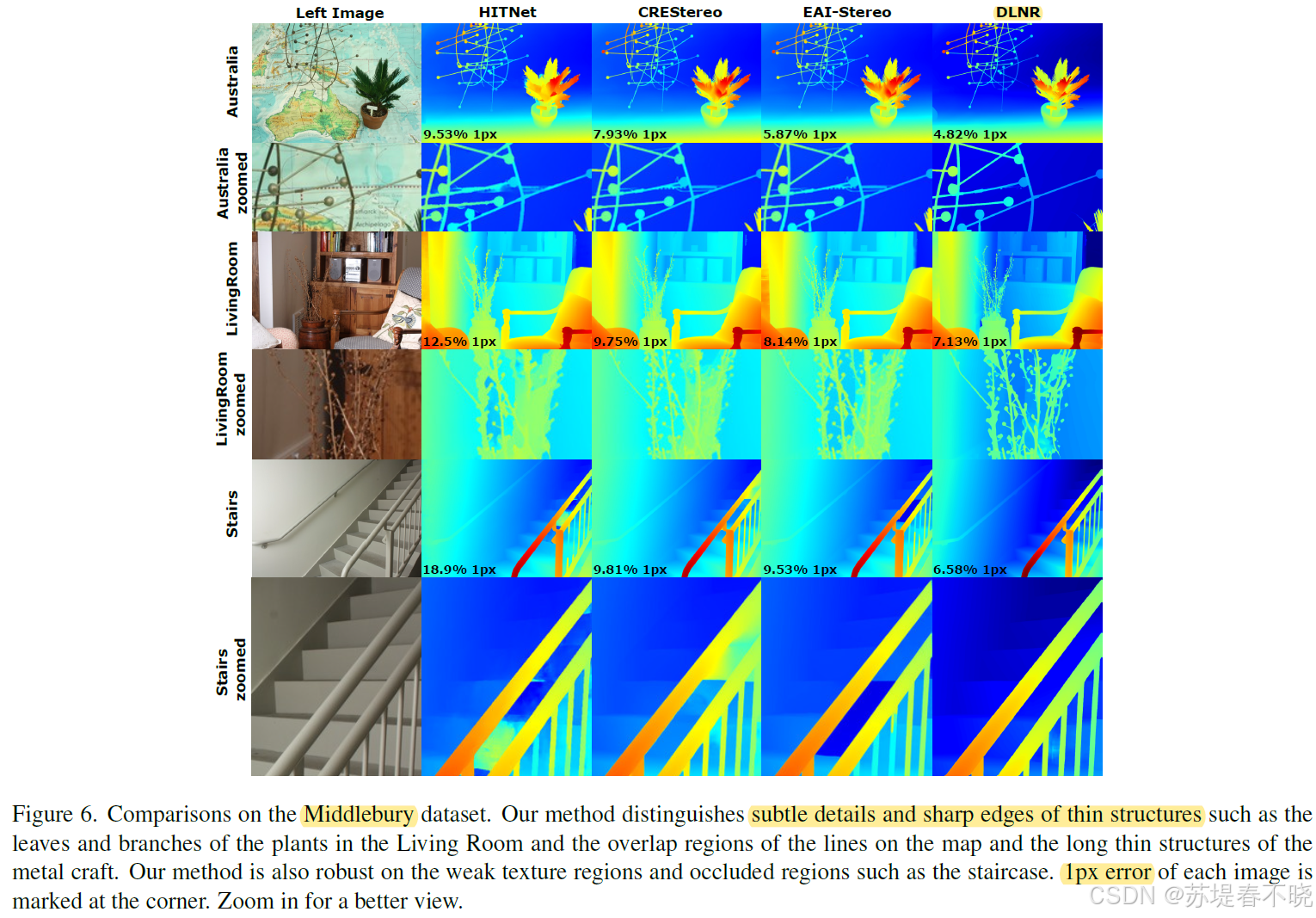
在植物叶片、金属细丝、楼梯弱纹理区域表现显著更优(distinguishes subtle details and sharp edges of thin structures)
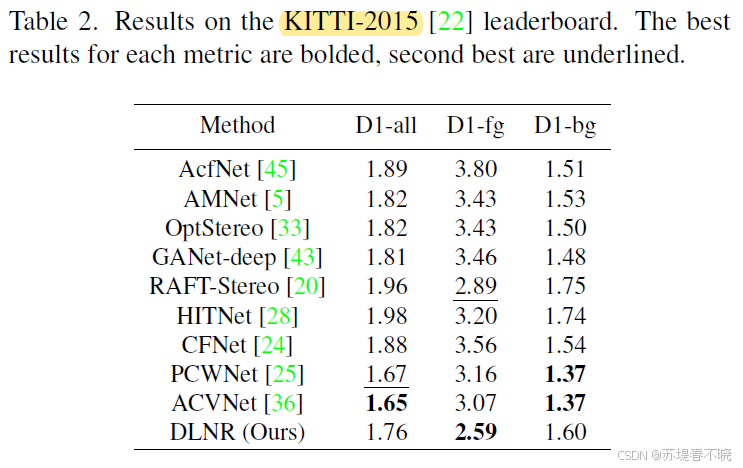
5.3、KITTI-2015
DLNR achieves SOTA performance on the KITTI-2015 D1-fg metric
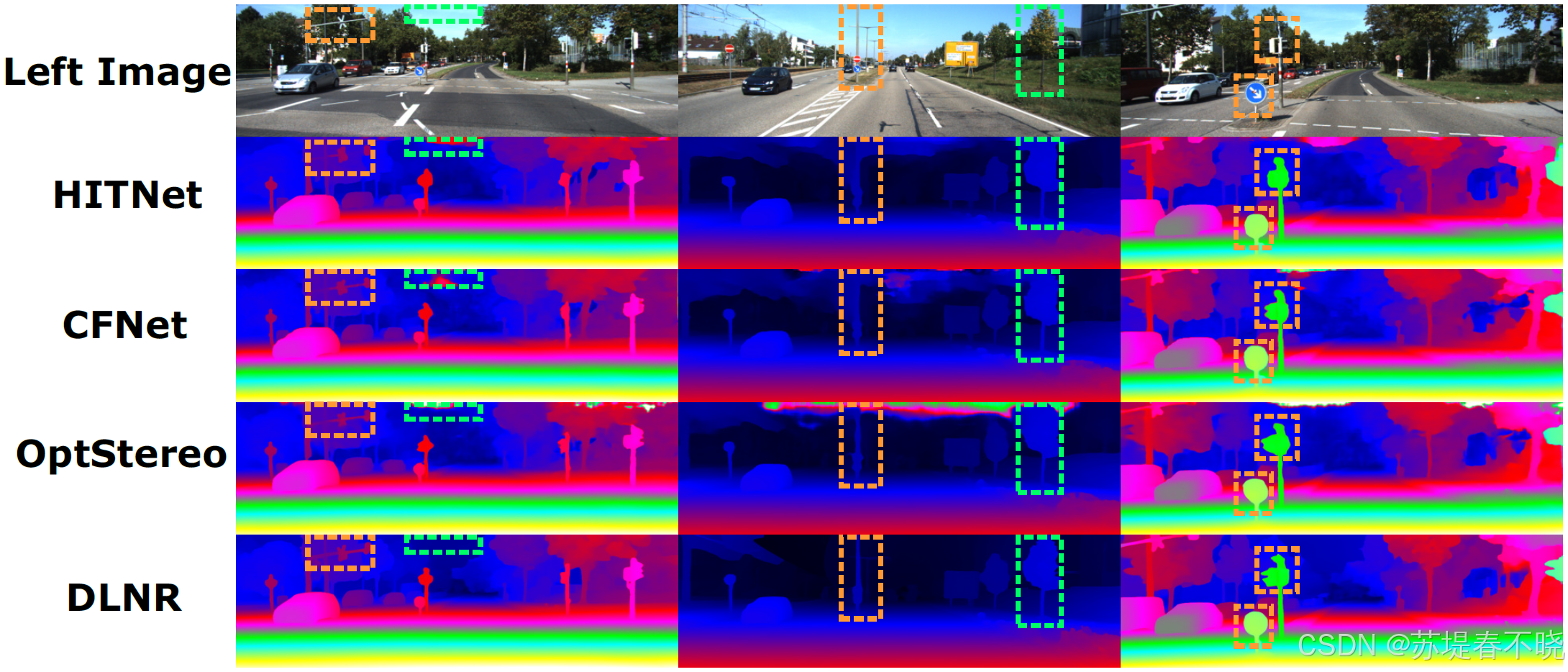

在车辆、护栏等前景物体边缘更清晰
5.4、Ablations
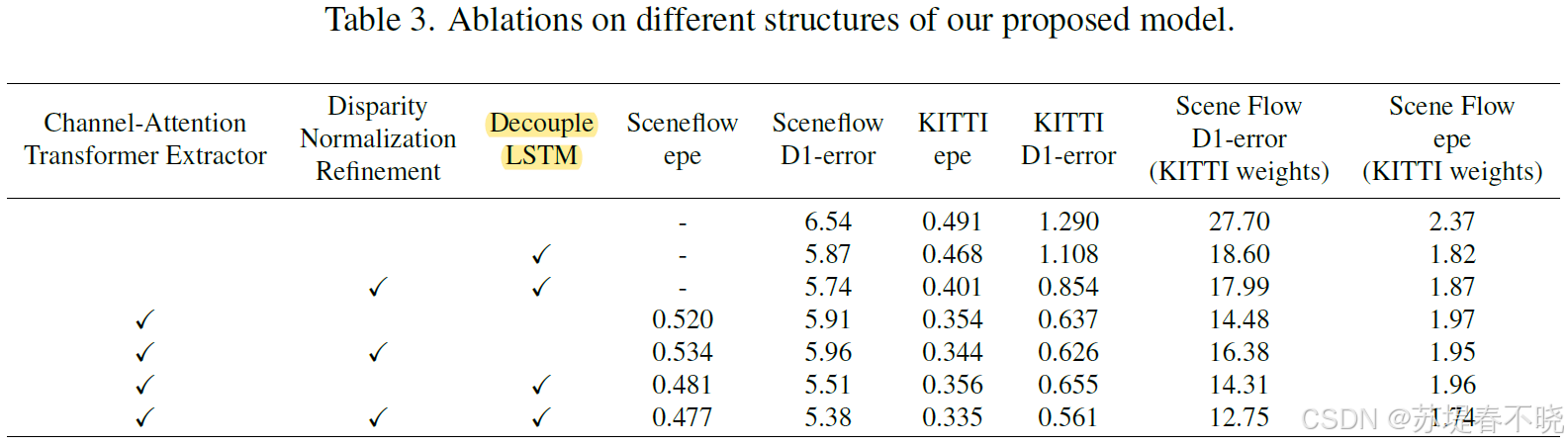
(1)Decouple LSTM
the hidden state C retains more features of the edges and more features of the thin objects, resulting in a better detail of the disparity map
现象套原理,有一点点牵强,C 能保留更多信息 ok,是不是 edges or thin 就不好说了


Decouple LSTM also shows strong cross-domain performance
table3 倒数第二列 D1-error 从 16.38 下降到了 12.75 在引入 decouple LSTM 之后
(2)Normalization Refinement
increases the generalization ability as well
table3 最后一列 1.96 下降到了 1.74
(3)Channel-Attention Transformer extractor
替换 ResNet-like extractor
table3 倒数第三列,0.854 -> 0.561
5.5、Performance and Inference Speed
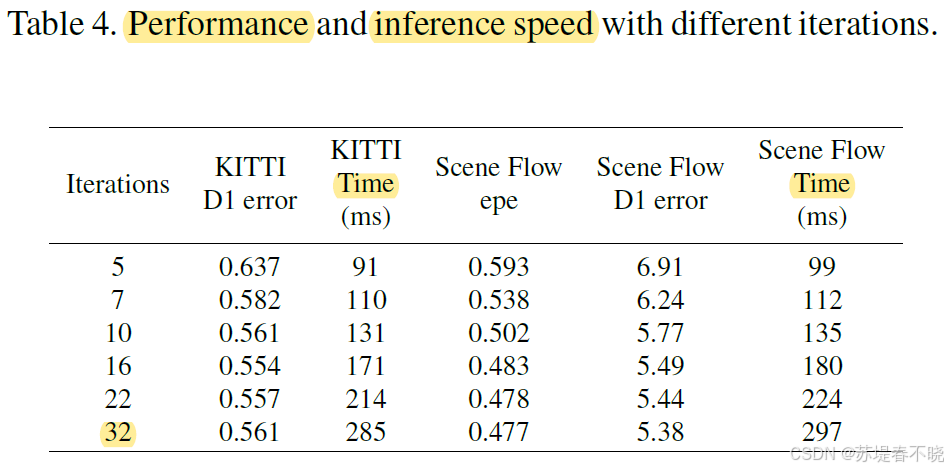
5.6、Evaluation on Multi-View Stereo
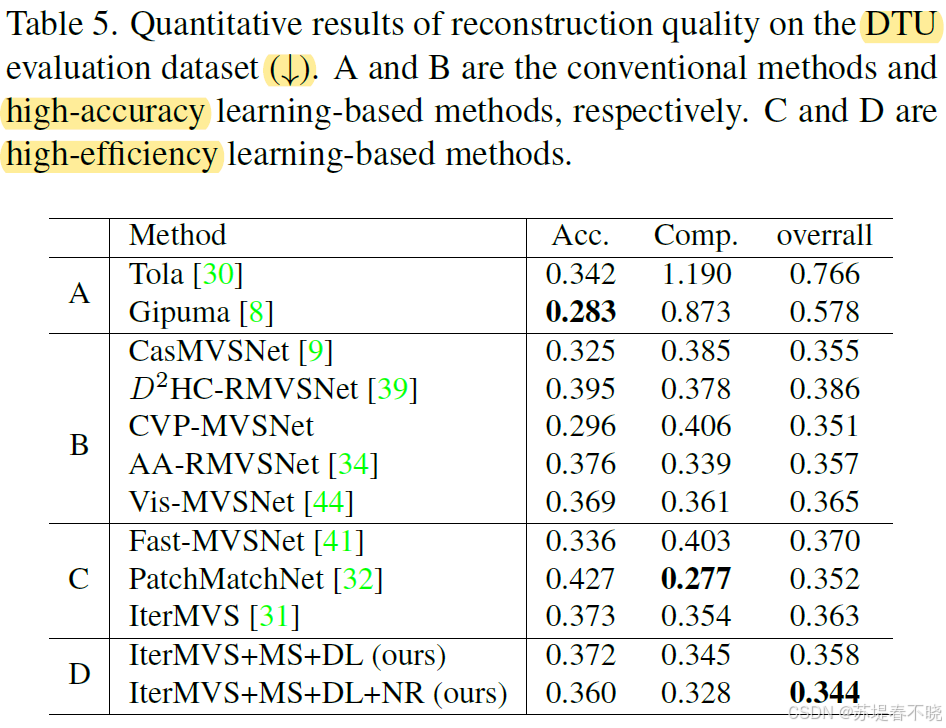
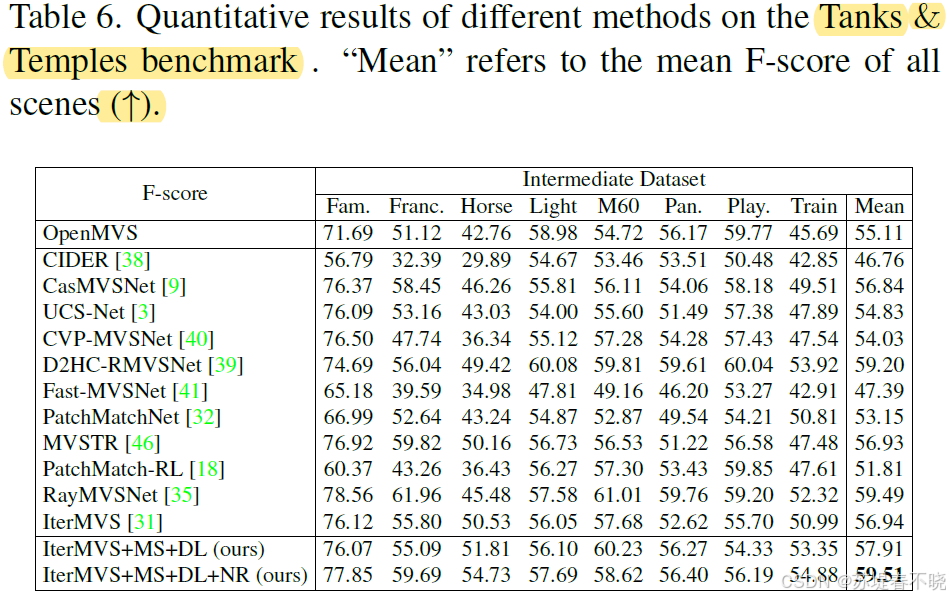


6、Conclusion(own) / Future work
- DLNR 通过三大创新------解耦迭代机制、视差归一化精炼、通道注意力特征提取------有效解决了现有立体匹配方法在边缘模糊、细节丢失、跨域泛化等方面的瓶颈。其在 Middlebury 和 KITTI 上的卓越表现证明了该方法的有效性与鲁棒性。
- Normalization Refinement module,归一化到 W = 1024,然后 hourglass aggregation,最后再映射回来,提升泛化性能,就是不知道触发的概率高不高,微调数据集初期会遇到???
- LSTM 解耦有点牵强,没有太 get 意思,只能说多了个 C hidden state,是否真的能提取 edge 和 thin 信息,仅仅找一张图展示感觉缺乏说服力
- multi-scale and multi-stage feature extractor,channel-wise self-attention mechanism,capture long-range pixel dependencies
- 主干换成 transformer,pixel unshuffle 保留高频信息,iterations 模块从 GRU 换成了 LSTM
- Q:金字塔构建的过程,1/4 特征图 all-pairs 相关,再下采样 w,和下采样特征图 fmaps2 再 all-pairs 是等价的吗?
- A:

- A:
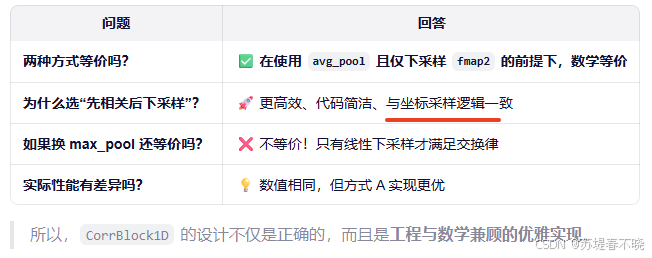
- A: 与采样逻辑天然对齐,在
__call__中,不同金字塔层级对应不同的坐标缩放(/ 2**i) 如果相关图是通过对原始相关下采样得到的,那么坐标缩放规则直接对应下采样因子
更多论文解读,请参考 【Paper Reading】