随着大语言模型在复杂任务处理中的应用日益广泛,如何提高Agent系统的执行效率和降低计算成本成为了关键挑战。本文介绍了LLMCompiler架构的实现,创新Agent设计,旨在通过并行执行任务和减少冗余的LLM调用来提升性能。我们使用LangGraph框架完整实现了这一架构,并通过多个实际案例验证了其有效性。
1. 引言
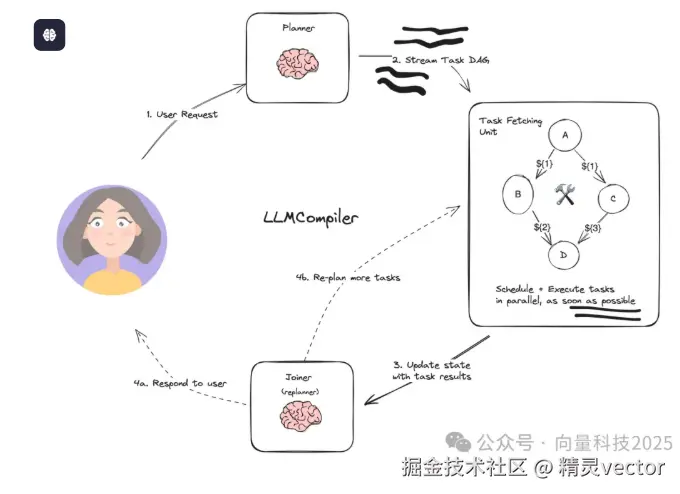
传统的AI Agent系统往往采用串行执行方式,每个任务必须等待前一个任务完成才能开始执行。这种设计不仅导致了执行时间的延长,还产生了大量的冗余计算成本。LLMCompiler通过引入有向无环图(DAG)的任务调度机制,实现了任务的并行化执行,显著提升了系统性能。
2. LLMCompiler架构概述
LLMCompiler架构包含三个核心组件:
2.1 规划器(Planner)
规划器负责将用户查询转换为可执行的任务DAG。它分析查询需求,识别可以并行执行的任务,并生成结构化的执行计划。
2.2 任务获取单元(Task Fetching Unit)
任务获取单元负责任务的调度和执行。一旦任务的依赖关系得到满足,它就会立即开始执行相应的任务,从而实现最大程度的并行化。
2.3 连接器(Joiner)
连接器处理任务执行的结果,决定是直接向用户提供最终答案,还是需要触发新一轮的规划和执行。
3. 系统实现
3.1 环境配置与工具定义
首先,我们需要安装必要的依赖包并配置API密钥:
python
%%capture --no-stderr
%pip install -U --quiet langchain_openai langsmith langgraph langchain numexpr
import getpass
import os
def _get_pass(var: str):
if var not in os.environ:
os.environ[var] = getpass.getpass(f"{var}: ")
_get_pass("OPENAI_API_KEY")
_get_pass("TAVILY_API_KEY")接下来定义系统使用的核心工具:
python
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_openai import ChatOpenAI
from math_tools import get_math_tool
# 创建数学计算工具
calculate = get_math_tool(ChatOpenAI(model="gpt-4o"))
# 创建搜索工具
search = TavilySearchResults(
max_results=1,
description='tavily_search_results_json(query="the search query") - a search engine.',
)
tools = [search, calculate]
# 测试数学工具
calculate.invoke(
{
"problem": "What's the temp of sf + 5?",
"context": ["The temperature of sf is 32 degrees"],
}
)
# 输出: '37'系统使用了两个核心工具:Tavily搜索引擎用于信息检索,数学计算工具用于处理数值计算任务。这种工具组合为系统提供了处理复杂查询的基础能力。
3.2 规划器实现
规划器采用了专门设计的提示模板,能够将用户查询解析为标准化的任务序列。首先导入必要的模块:
python
from typing import Sequence
from langchain import hub
from langchain_core.language_models import BaseChatModel
from langchain_core.messages import (
BaseMessage,
FunctionMessage,
HumanMessage,
SystemMessage,
)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableBranch
from langchain_core.tools import BaseTool
from langchain_openai import ChatOpenAI
from output_parser import LLMCompilerPlanParser, Task获取并检查提示模板:
python
prompt = hub.pull("wfh/llm-compiler")
print(prompt.pretty_print())
# 输出显示提示模板的内容,包含系统消息和任务格式说明创建规划器函数的完整实现:
python
def create_planner(
llm: BaseChatModel, tools: Sequence[BaseTool], base_prompt: ChatPromptTemplate
):
tool_descriptions = "\n".join(
f"{i + 1}. {tool.description}\n"
for i, tool in enumerate(
tools
) # +1 to offset the 0 starting index, we want it count normally from 1.
)
planner_prompt = base_prompt.partial(
replan="",
num_tools=len(tools)
+ 1, # Add one because we're adding the join() tool at the end.
tool_descriptions=tool_descriptions,
)
replanner_prompt = base_prompt.partial(
replan=' - You are given "Previous Plan" which is the plan that the previous agent created along with the execution results '
"(given as Observation) of each plan and a general thought (given as Thought) about the executed results."
'You MUST use these information to create the next plan under "Current Plan".\n'
' - When starting the Current Plan, you should start with "Thought" that outlines the strategy for the next plan.\n'
" - In the Current Plan, you should NEVER repeat the actions that are already executed in the Previous Plan.\n"
" - You must continue the task index from the end of the previous one. Do not repeat task indices.",
num_tools=len(tools) + 1,
tool_descriptions=tool_descriptions,
)
def should_replan(state: list):
# Context is passed as a system message
return isinstance(state[-1], SystemMessage)
def wrap_messages(state: list):
return {"messages": state}
def wrap_and_get_last_index(state: list):
next_task = 0
for message in state[::-1]:
if isinstance(message, FunctionMessage):
next_task = message.additional_kwargs["idx"] + 1
break
state[-1].content = state[-1].content + f" - Begin counting at : {next_task}"
return {"messages": state}
return (
RunnableBranch(
(should_replan, wrap_and_get_last_index | replanner_prompt),
wrap_messages | planner_prompt,
)
| llm
| LLMCompilerPlanParser(tools=tools)
)
# 创建规划器实例
llm = ChatOpenAI(model="gpt-4-turbo-preview")
planner = create_planner(llm, tools, prompt)测试规划器功能:
python
example_question = "What's the temperature in SF raised to the 3rd power?"
for task in planner.stream([HumanMessage(content=example_question)]):
print(task["tool"], task["args"])
print("---")
# 输出:
# description='tavily_search_results_json(query="the search query") - a search engine.' max_results=1 {'query': 'current temperature in San Francisco'}
# ---
# name='math' description='math(problem: str, context: Optional[list[str]]) -> float:...' {'problem': 'x ** 3', 'context': ['$1']}
# ---
# join ()
# ---任务格式如下:
vbnet
1. tool_1(arg1="arg1", arg2=3.5, ...)
Thought: I then want to find out Y by using tool_2
2. tool_2(arg1="", arg2="${1}")
3. join()<END_OF_PLAN>其中${#}占位符用于表示任务间的依赖关系,实现了任务输出的自动路由。
这个例子展示了规划器如何识别任务间的依赖关系,并生成合适的执行序列。
3.3 任务调度与执行系统
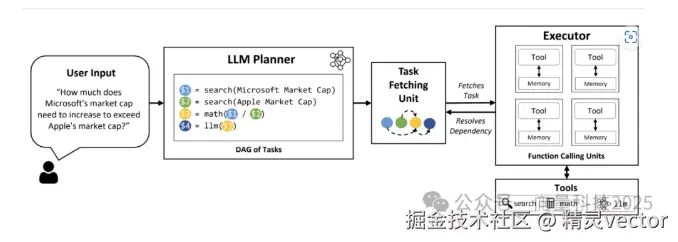
任务调度系统是LLMCompiler的核心创新之一。它使用多线程技术实现任务的并发执行,一旦任务的依赖条件满足就立即开始执行。
首先导入必要的模块:
python
import re
import time
from concurrent.futures import ThreadPoolExecutor, wait
from typing import Any, Dict, Iterable, List, Union
from langchain_core.runnables import (
chain as as_runnable,
)
from typing_extensions import TypedDict定义核心数据结构和辅助函数:
python
def _get_observations(messages: List[BaseMessage]) -> Dict[int, Any]:
# Get all previous tool responses
results = {}
for message in messages[::-1]:
if isinstance(message, FunctionMessage):
results[int(message.additional_kwargs["idx"])] = message.content
return results
class SchedulerInput(TypedDict):
messages: List[BaseMessage]
tasks: Iterable[Task]实现任务执行函数:
python
def _execute_task(task, observations, config):
tool_to_use = task["tool"]
if isinstance(tool_to_use, str):
return tool_to_use
args = task["args"]
try:
if isinstance(args, str):
resolved_args = _resolve_arg(args, observations)
elif isinstance(args, dict):
resolved_args = {
key: _resolve_arg(val, observations) for key, val in args.items()
}
else:
# This will likely fail
resolved_args = args
except Exception as e:
return (
f"ERROR(Failed to call {tool_to_use.name} with args {args}.)"
f" Args could not be resolved. Error: {repr(e)}"
)
try:
return tool_to_use.invoke(resolved_args, config)
except Exception as e:
return (
f"ERROR(Failed to call {tool_to_use.name} with args {args}."
+ f" Args resolved to {resolved_args}. Error: {repr(e)})"
)
def _resolve_arg(arg: Union[str, Any], observations: Dict[int, Any]):
# $1 or ${1} -> 1
ID_PATTERN = r"\$\{?(\d+)\}?"
def replace_match(match):
# If the string is ${123}, match.group(0) is ${123}, and match.group(1) is 123.
# Return the match group, in this case the index, from the string. This is the index
# number we get back.
idx = int(match.group(1))
return str(observations.get(idx, match.group(0)))
# For dependencies on other tasks
if isinstance(arg, str):
return re.sub(ID_PATTERN, replace_match, arg)
elif isinstance(arg, list):
return [_resolve_arg(a, observations) for a in arg]
else:
return str(arg)实现任务调度函数:
python
@as_runnable
def schedule_task(task_inputs, config):
task: Task = task_inputs["task"]
observations: Dict[int, Any] = task_inputs["observations"]
try:
observation = _execute_task(task, observations, config)
except Exception:
import traceback
observation = traceback.format_exception() # repr(e) +
observations[task["idx"]] = observation
def schedule_pending_task(
task: Task, observations: Dict[int, Any], retry_after: float = 0.2
):
while True:
deps = task["dependencies"]
if deps and (any([dep not in observations for dep in deps])):
# Dependencies not yet satisfied
time.sleep(retry_after)
continue
schedule_task.invoke({"task": task, "observations": observations})
break
@as_runnable
def schedule_tasks(scheduler_input: SchedulerInput) -> List[FunctionMessage]:
"""Group the tasks into a DAG schedule."""
tasks = scheduler_input["tasks"]
args_for_tasks = {}
messages = scheduler_input["messages"]
# If we are re-planning, we may have calls that depend on previous
# plans. Start with those.
observations = _get_observations(messages)
task_names = {}
originals = set(observations)
# ^^ We assume each task inserts a different key above to
# avoid race conditions...
futures = []
retry_after = 0.25 # Retry every quarter second
with ThreadPoolExecutor() as executor:
for task in tasks:
deps = task["dependencies"]
task_names[task["idx"]] = (
task["tool"] if isinstance(task["tool"], str) else task["tool"].name
)
args_for_tasks[task["idx"]] = task["args"]
if (
# Depends on other tasks
deps and (any([dep not in observations for dep in deps]))
):
futures.append(
executor.submit(
schedule_pending_task, task, observations, retry_after
)
)
else:
# No deps or all deps satisfied
# can schedule now
schedule_task.invoke(dict(task=task, observations=observations))
# All tasks have been submitted or enqueued
# Wait for them to complete
wait(futures)
# Convert observations to new tool messages to add to the state
new_observations = {
k: (task_names[k], args_for_tasks[k], observations[k])
for k in sorted(observations.keys() - originals)
}
tool_messages = [
FunctionMessage(
name=name,
content=str(obs),
additional_kwargs={"idx": k, "args": task_args},
tool_call_id=k,
)
for k, (name, task_args, obs) in new_observations.items()
]
return tool_messages创建计划和调度的组合函数:
python
import itertools
@as_runnable
def plan_and_schedule(state):
messages = state["messages"]
tasks = planner.stream(messages)
# Begin executing the planner immediately
try:
tasks = itertools.chain([next(tasks)], tasks)
except StopIteration:
# Handle the case where tasks is empty.
tasks = iter([])
scheduled_tasks = schedule_tasks.invoke(
{
"messages": messages,
"tasks": tasks,
}
)
return {"messages": scheduled_tasks}测试执行示例:
python
tool_messages = plan_and_schedule.invoke(
{"messages": [HumanMessage(content=example_question)]}
)["messages"]
# 输出示例:
# [FunctionMessage(content="[{'url': '...', 'content': '...'}]", additional_kwargs={'idx': 1, 'args': {'query': 'current temperature in San Francisco'}}, response_metadata={}, name='tavily_search_results_json', tool_call_id=1),
# FunctionMessage(content='ValueError(...)', additional_kwargs={'idx': 2, 'args': {'problem': 'x^3', 'context': ['$1']}}, response_metadata={}, name='math', tool_call_id=2),
# FunctionMessage(content='join', additional_kwargs={'idx': 3, 'args': ()}, response_metadata={}, name='join', tool_call_id=3)]系统的调度逻辑包括:
持续监控任务依赖关系的满足情况,使用ThreadPoolExecutor实现真正的并行处理,统一收集和管理任务执行结果。
在我们编写的上述温度计算示例中,系统实际执行了以下操作:搜索任务返回了旧金山的天气信息,数学计算任务由于缺乏具体的温度数值而失败, join操作识别到执行失败的情况
3.4 连接器与重规划机制
连接器使用结构化输出来决定下一步行动。首先定义必要的数据模型:
python
from langchain_core.messages import AIMessage
from pydantic import BaseModel, Field
from typing import Union
class FinalResponse(BaseModel):
"""最终响应"""
response: str
class Replan(BaseModel):
"""重新规划"""
feedback: str = Field(
description="Analysis of the previous attempts and recommendations on what needs to be fixed."
)
class JoinOutputs(BaseModel):
"""Decide whether to replan or whether you can return the final response."""
thought: str = Field(
description="The chain of thought reasoning for the selected action"
)
action: Union[FinalResponse, Replan]创建连接器的核心组件:
python
joiner_prompt = hub.pull("wfh/llm-compiler-joiner").partial(
examples=""
) # You can optionally add examples
llm = ChatOpenAI(model="gpt-4o")
runnable = joiner_prompt | llm.with_structured_output(
JoinOutputs, method="function_calling"
)实现连接器的辅助函数:
python
def _parse_joiner_output(decision: JoinOutputs) -> List[BaseMessage]:
response = [AIMessage(content=f"Thought: {decision.thought}")]
if isinstance(decision.action, Replan):
return {
"messages": response
+ [
SystemMessage(
content=f"Context from last attempt: {decision.action.feedback}"
)
]
}
else:
return {"messages": response + [AIMessage(content=decision.action.response)]}
def select_recent_messages(state) -> dict:
messages = state["messages"]
selected = []
for msg in messages[::-1]:
selected.append(msg)
if isinstance(msg, HumanMessage):
break
return {"messages": selected[::-1]}
# 组合连接器
joiner = select_recent_messages | runnable | _parse_joiner_output测试连接器功能:
python
input_messages = [HumanMessage(content=example_question)] + tool_messages
result = joiner.invoke({"messages": input_messages})
# 输出示例:
# {'messages': [AIMessage(content='Thought: Since the temperature in San Francisco was not provided, I cannot calculate its value raised to the 3rd power. The search result did not include specific temperature information, and the subsequent action to calculate the power raised the error due to lack of numerical input.', additional_kwargs={}, response_metadata={}),
# SystemMessage(content="Context from last attempt: To answer the user's question, we need the current temperature in San Francisco. Please include a step to find the current temperature in San Francisco and then calculate its value raised to the 3rd power.", additional_kwargs={}, response_metadata={})]}当初次执行失败时,连接器会分析失败原因并触发重规划:
由于搜索结果没有提供具体的温度数值,无法进行数学计算。
需要找到旧金山的具体当前温度,然后计算其三次方。
4. 完整系统集成
使用LangGraph框架,我们将各个组件整合为一个状态图。首先导入必要的模块:
python
from langgraph.graph import END, StateGraph, START
from langgraph.graph.message import add_messages
from typing import Annotated
class State(TypedDict):
messages: Annotated[list, add_messages]构建完整的系统图:
python
graph_builder = StateGraph(State)
# 1. Define vertices
# We defined plan_and_schedule above already
# Assign each node to a state variable to update
graph_builder.add_node("plan_and_schedule", plan_and_schedule)
graph_builder.add_node("join", joiner)
## Define edges
graph_builder.add_edge("plan_and_schedule", "join")
### This condition determines looping logic
def should_continue(state):
messages = state["messages"]
if isinstance(messages[-1], AIMessage):
return END
return "plan_and_schedule"
graph_builder.add_conditional_edges(
"join",
# Next, we pass in the function that will determine which node is called next.
should_continue,
)
graph_builder.add_edge(START, "plan_and_schedule")
# 编译完整的执行链
chain = graph_builder.compile()系统的循环逻辑通过条件边来实现,确保在需要时能够自动触发重规划。当连接器返回SystemMessage时,系统会重新进入规划和调度阶段;当返回AIMessage时,系统结束执行。
5. 实验验证
5.1 简单查询处理
查询 :"What's the GDP of New York?"
python
for step in chain.stream(
{"messages": [HumanMessage(content="What's the GDP of New York?")]}
):
print(step)
print("---")
# 输出:
# {'plan_and_schedule': {'messages': [FunctionMessage(content="[{'url': 'https://www.investopedia.com/articles/investing/011516/new-yorks-economy-6-industries-driving-gdp-growth.asp', 'content': 'The manufacturing sector is a leader in railroad rolling stock, as many of the earliest railroads were financed or founded in New York; garments, as New York City is the fashion capital of the U.S.; elevator parts; glass; and many other products.\\n Educational Services\\nThough not typically thought of as a leading industry, the educational sector in New York nonetheless has a substantial impact on the state and its residents, and in attracting new talent that eventually enters the New York business scene. New York has seen a large uptick in college attendees, both young and old, over the 21st century, and an increasing number of new employees in other New York sectors were educated in the state. New York City is the leading job hub for banking, finance, and communication in the U.S. New York is also a major manufacturing center and shipping port, and it has a thriving technological sector.\\n The state of New York has the third-largest economy in the United States with a gross domestic product (GDP) of $1.7 trillion, trailing only Texas and California.'}]", additional_kwargs={'idx': 1, 'args': {'query': 'GDP of New York'}}, response_metadata={}, name='tavily_search_results_json', tool_call_id=1)]}}
# ---
# {'join': {'messages': [AIMessage(content='Thought: The search result provides the specific information requested. It states that the state of New York has the third-largest economy in the United States with a GDP of $1.7 trillion.', additional_kwargs={}, response_metadata={}, id='63af07a6-f931-43e9-8fdc-4f2b8c7b7663'), AIMessage(content='The GDP of New York is $1.7 trillion.', additional_kwargs={}, response_metadata={}, id='7cfc50e6-e041-4985-a5f4-ebf2e097826e')]}}
# ---
# Final answer
print(step["join"]["messages"][-1].content)
# The GDP of New York is $1.7 trillion.执行过程:
-
系统执行搜索任务获取纽约GDP信息
-
搜索结果显示纽约州GDP为1.7万亿美元
-
连接器直接提供最终答案
结果 :"The GDP of New York is $1.7 trillion."
这个例子展示了系统处理单步查询的高效性。
5.2 多条查询处理
查询 :"What's the oldest parrot alive, and how much longer is that than the average?"
python
steps = chain.stream(
{
"messages": [
HumanMessage(
content="What's the oldest parrot alive, and how much longer is that than the average?"
)
]
},
{
"recursion_limit": 100,
},
)
for step in steps:
print(step)
print("---")
# 输出:
# {'plan_and_schedule': {'messages': [FunctionMessage(content='[{\'url\': \'https://en.wikipedia.org/wiki/Cookie_(cockatoo)\', \'content\': \'He was one of the longest-lived birds on record[4] and was recognised by the Guinness World Records as the oldest living parrot in the world.[5]\\nThe next-oldest pink cockatoo to be found in a zoological setting was a 31-year-old female bird located at Paradise Wildlife Sanctuary, England.[3] Information published by the World Parrot Trust states longevity for Cookie\\\'s species in captivity is on average 40--60 years.[6]\\nLife[edit]\\nCookie was Brookfield Zoo\\\'s oldest resident and the last surviving member of the animal collection from the time of the zoo\\\'s opening in 1934, having arrived from Taronga Zoo of Sydney, New South Wales, Australia, in the same year and judged to be one year old at the time.[7]\\nIn the 1950s an attempt was made to introduce Cookie to a female pink cockatoo, but Cookie rejected her as "she was not nice to him".[8]\\n In 2007, Cookie was diagnosed with, and placed on medication and nutritional supplements for, osteoarthritis and osteoporosis\\xa0-- medical conditions which occur commonly in aging animals and humans alike,[7] although it is believed that the latter may also have been brought on as a result of being fed a seed-only diet for the first 40 years of his life, in the years before the dietary requirements of his species were fully understood.[9]\\nCookie was "retired" from exhibition at the zoo in 2009 (following a few months of weekend-only appearances) in order to preserve his health, after it was noticed by staff that his appetite, demeanor and stress levels improved markedly when not on public display. age.[11] A memorial at the zoo was unveiled in September 2017.[12]\\nIn 2020, Cookie became the subject of a poetry collection by Barbara Gregorich entitled Cookie the Cockatoo: Everything Changes.[13]\\nSee also[edit]\\nReferences[edit]\\nExternal links[edit] He was believed to be the oldest member of his species alive in captivity, at the age of 82 in June 2015,[1][2] having significantly exceeded the average lifespan for his kind.[3] He was moved to a permanent residence in the keepers\\\' office of the zoo\\\'s Perching Bird House, although he made occasional appearances for special events, such as his birthday celebration, which was held each June.[3]\'}]', additional_kwargs={'idx': 1, 'args': {'query': 'oldest parrot alive'}}, response_metadata={}, name='tavily_search_results_json', tool_call_id=1), FunctionMessage(content="[{'url': 'https://www.birdzilla.com/learn/how-long-do-parrots-live/', 'content': 'In captivity, they can easily live to be ten or even 18 years of age. In general, most wild parrot species live only half the numbers of years they would live in captivity. For example, adopted African Gray Parrots might live to be 60, whereas wild birds have an average lifespan of 30 or 40 at the very most.'}]", additional_kwargs={'idx': 2, 'args': {'query': 'average lifespan of a parrot'}}, response_metadata={}, name='tavily_search_results_json', tool_call_id=2), FunctionMessage(content='join', additional_kwargs={'idx': 3, 'args': ()}, response_metadata={}, name='join', tool_call_id=3)]}}
# ---
# {'join': {'messages': [AIMessage(content="Thought: The information from Wikipedia about Cookie, the cockatoo, indicates that he was recognized as the oldest living parrot, reaching the age of 82. This significantly exceeds the average lifespan for his species, which is noted to be 40-60 years in captivity. The information from Birdzilla provides a more general perspective on parrot lifespans, indicating that, in captivity, parrots can easily live to be ten or even 18 years of age, with some species like the African Gray Parrot potentially living up to 60 years. However, it does not provide a specific average lifespan for all parrot species, making it challenging to provide a precise comparison for Cookie's age beyond his species' average lifespan.", additional_kwargs={}, response_metadata={}, id='f00a464e-c273-42b9-8d1b-edd27bde8687'), AIMessage(content="Cookie the cockatoo was recognized as the oldest living parrot, reaching the age of 82, which is significantly beyond the average lifespan for his species, noted to be between 40-60 years in captivity. While general information for parrots suggests varying lifespans with some capable of living up to 60 years in captivity, Cookie's age far exceeded these averages, highlighting his exceptional longevity.", additional_kwargs={}, response_metadata={}, id='dc62a826-5528-446e-8797-6854abdeb94c')]}}
# ---
# Final answer
print(step["join"]["messages"][-1].content)
# Cookie the cockatoo was recognized as the oldest living parrot, reaching the age of 82, which is significantly beyond the average lifespan for his species, noted to be between 40-60 years in captivity. While general information for parrots suggests varying lifespans with some capable of living up to 60 years in captivity, Cookie's age far exceeded these averages, highlighting his exceptional longevity.执行过程:
-
并行执行两个搜索任务:
-
搜索最老的鹦鹉
-
搜索鹦鹉平均寿命
-
-
获得Cookie鹦鹉(82岁)和平均寿命(40-60年)的信息
-
连接器综合分析两个结果提供完整答案
结果:系统成功识别出Cookie鹦鹉的异常长寿,并与同类平均寿命进行了比较分析。
5.3 多步数学计算
查询 :"What's ((3*(4+5)/0.5)+3245) + 8? What's 32/4.23? What's the sum of those two values?"
执行过程:
-
并行执行两个数学计算任务:
-
第一个表达式:结果为3307.0
-
第二个表达式:结果为7.565011820330969
-
-
系统自动识别需要将两个结果相加
-
连接器提供包含所有计算步骤的完整答案
结果 :"The sum of those two values is 3307.0 + 7.57 = approximately 3314.57."
5.4 复杂重规划示例
查询 :"Find the current temperature in Tokyo, then, respond with a flashcard summarizing this information"
执行过程:
-
搜索东京当前温度:84°F,部分晴朗
-
连接器识别到需要创建闪卡格式的总结
-
生成结构化的闪卡响应
最终输出:
markdown
**Flashcard: Current Temperature in Tokyo**
- **Temperature:** 84 °F
- **Weather Conditions:** Partly sunny
*Note: This information is based on the latest available data and may change.*6. 性能分析与优势
6.1 并行化优势
通过DAG调度,系统能够同时执行多个独立的任务,显著减少了总体执行时间。在多步查询中,这种优势尤为明显。
6.2 成本优化
系统通过减少不必要的LLM调用来降低计算成本。任务只在其依赖满足时才执行,避免了冗余计算。
6.3 可扩展性
模块化的设计使得系统可以轻松添加新的工具和能力,满足不同应用场景的需求。
7. 局限性与改进方向
7.1 已知局限性
当前的规划器输出格式在处理多参数函数时可能不够稳定,变量替换机制需要更鲁棒的实现在多轮重规划中,状态可能变得过长
7.2 改进建议
对于上面这里也有一些改进建议,可以使用流式工具调用来改善输出解析的稳定性,采用更鲁棒的语法解析器(如Lark)来处理变量替换,实现消息压缩机制来管理长状态序列。
8. 结论
在本文我们成功实现了基于LangGraph的LLMCompiler架构,展示了其在处理复杂查询任务中的显著优势。通过并行化执行和智能重规划机制,系统不仅提高了执行效率,还降低了计算成本。实验结果表明,该架构在处理从简单查询到复杂多步推理的各种任务中都表现出色。
未来的工作将重点关注提高系统的鲁棒性和处理更复杂查询的能力,使其能够在更广泛的实际应用场景中发挥作用。LLMCompiler架构为构建高效、可扩展的AI Agent系统提供了有价值的参考框架。