在深度学习领域,PyTorch 以动态图机制和简洁易用的特性,成为科研与工程落地的热门框架。本文围绕《PyTorch》展开,从基础操作切入,通过 numpy 与 tensor 实例演示数据处理核心逻辑,深入解析 Torchvision 数据加载、图像处理及常用功能。结合卷积原理、损失函数设计、梯度计算等关键模块,详解网络构建与优化方法,搭配可视化工具与分布式训练技巧,为读者呈现从基础语法到高阶应用的完整知识图谱,助力快速掌握 PyTorch 核心技术栈。
基本操作
安装

numpy 的一些例子
- Creating NumPy Arrays
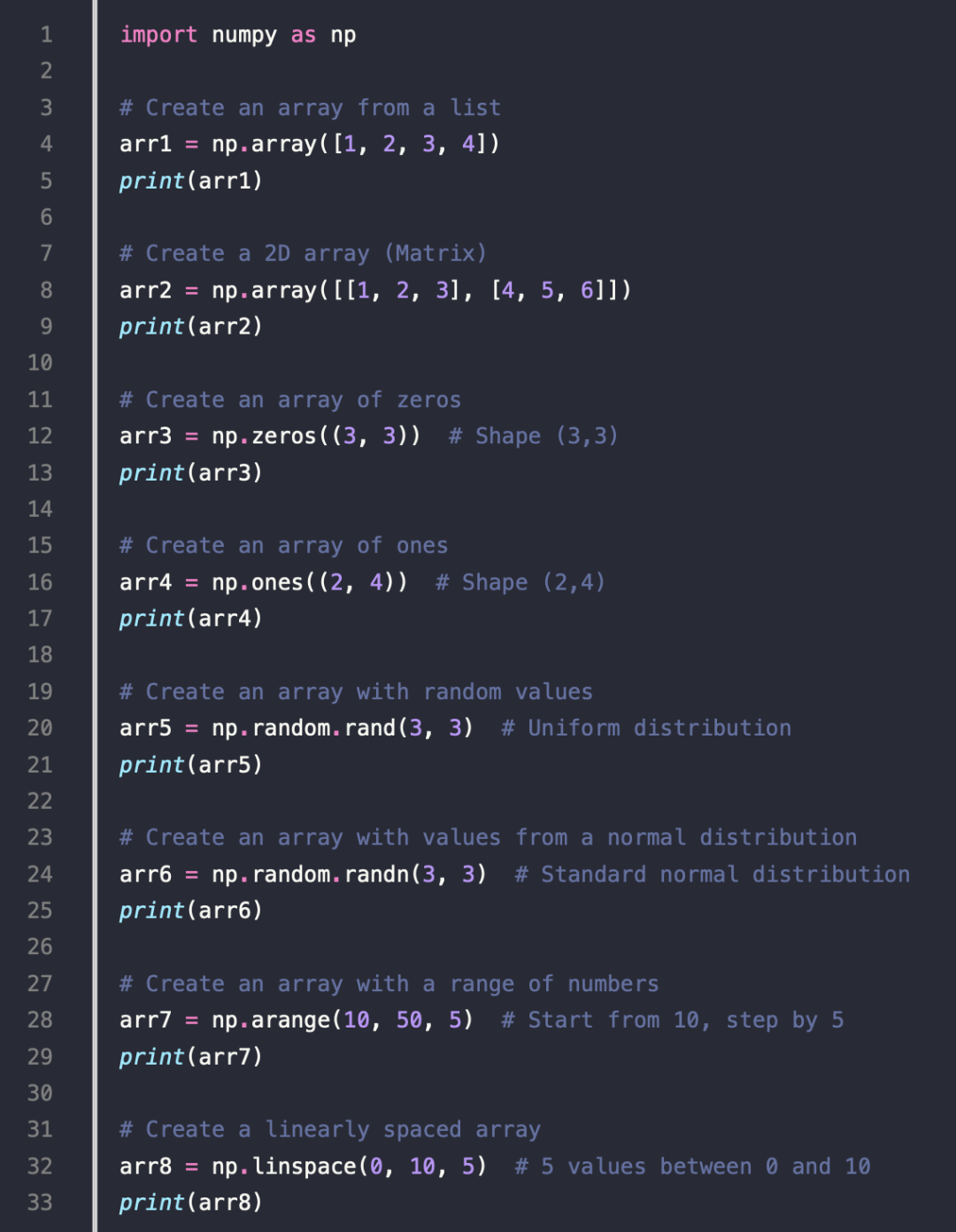
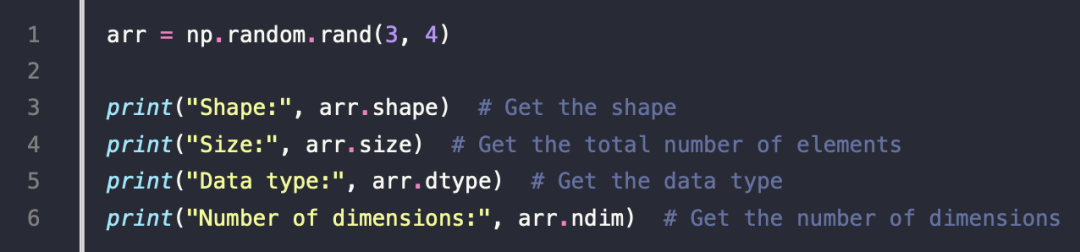
2.Checking Properties of an Array
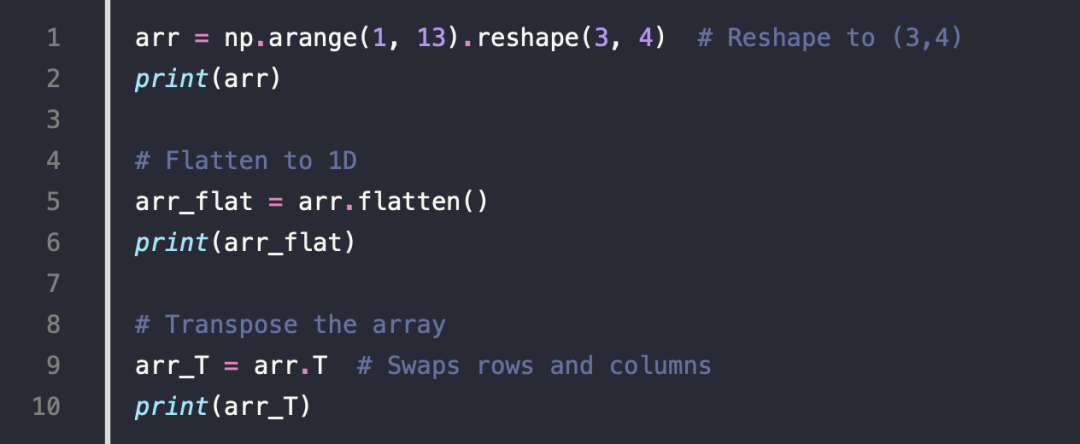
3.Reshaping and Flattening
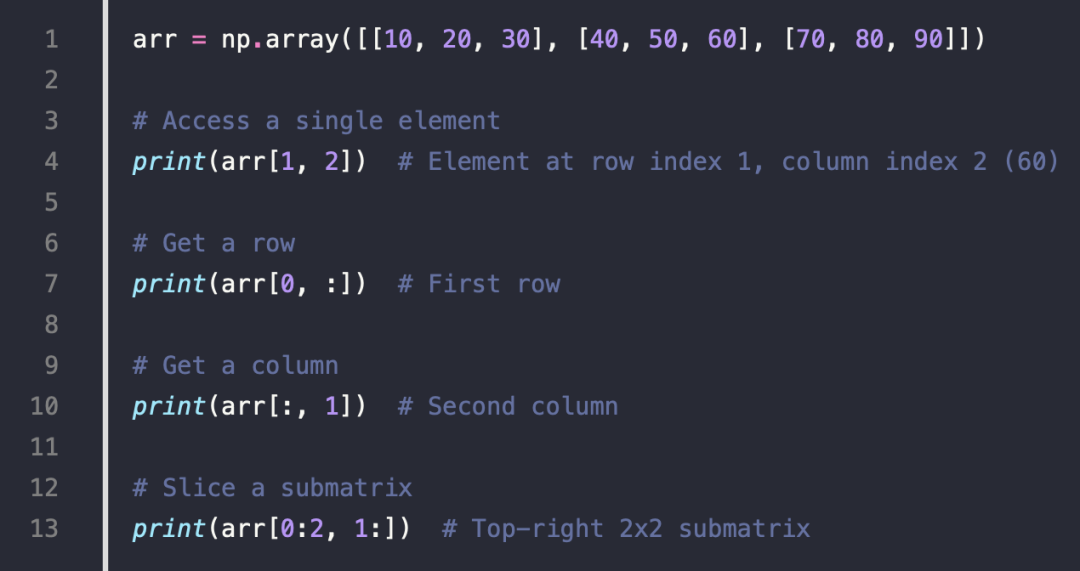
4.Indexing and Slicing
5.Mathematical Operations
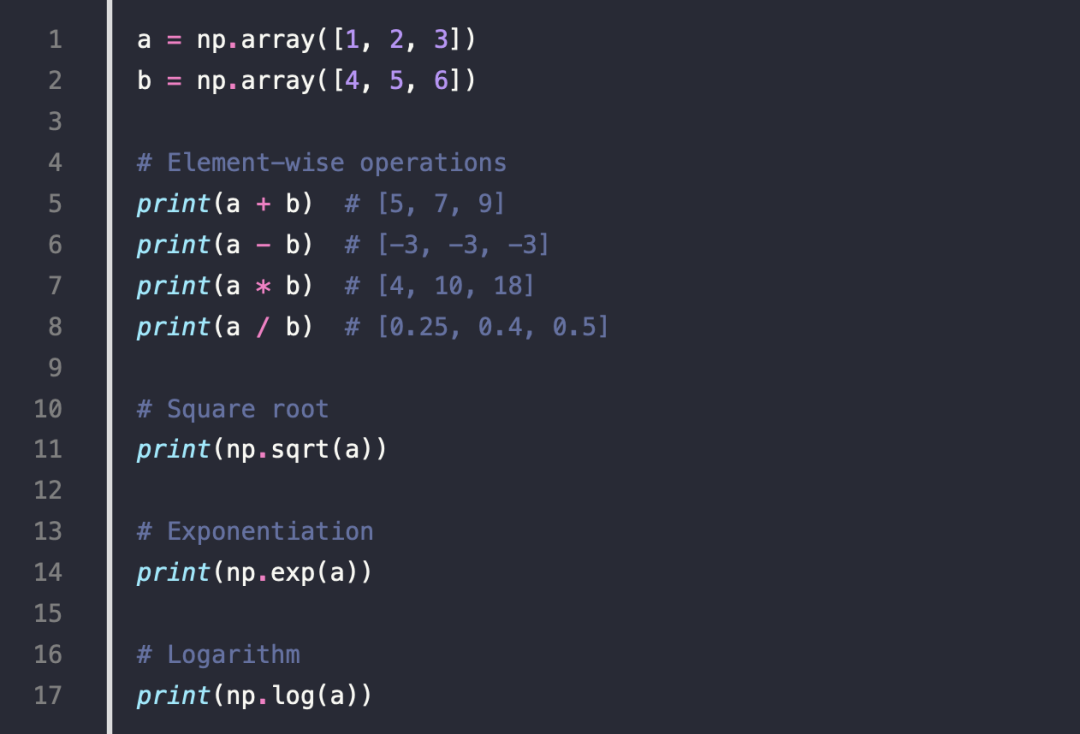
6.Matrix Multiplication
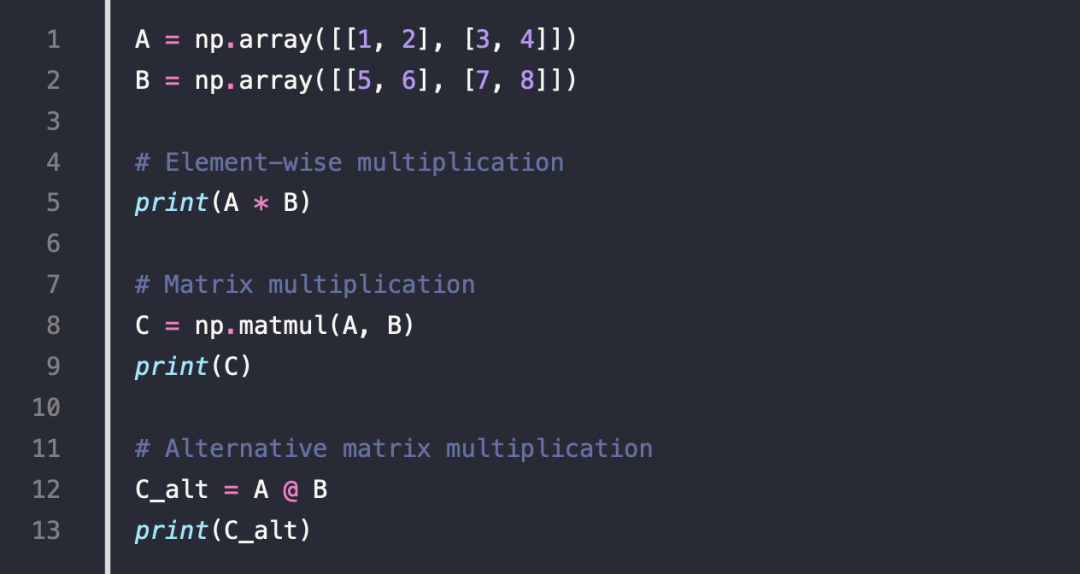
7.Statistical Operations

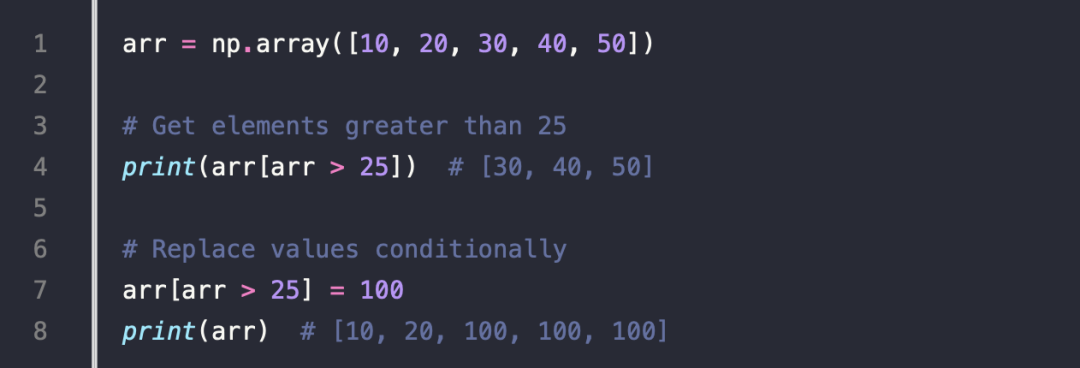
8.Boolean Masking
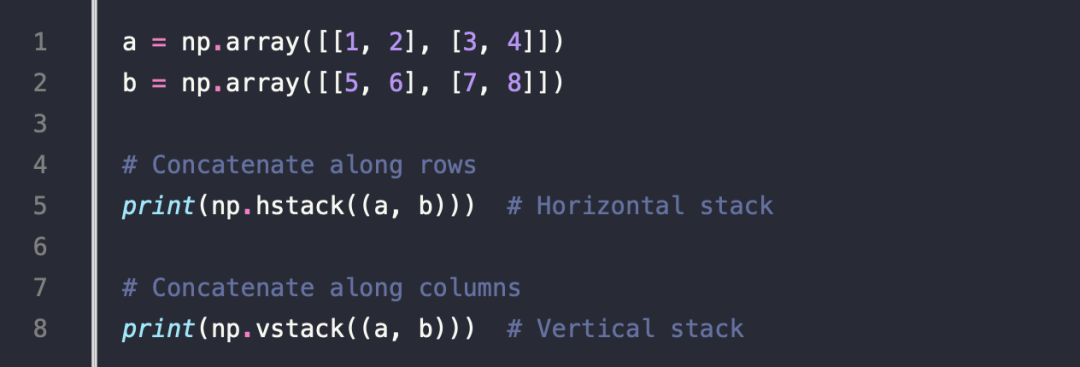
9.Stacking and Concatenation
10.Saving and Loading Data
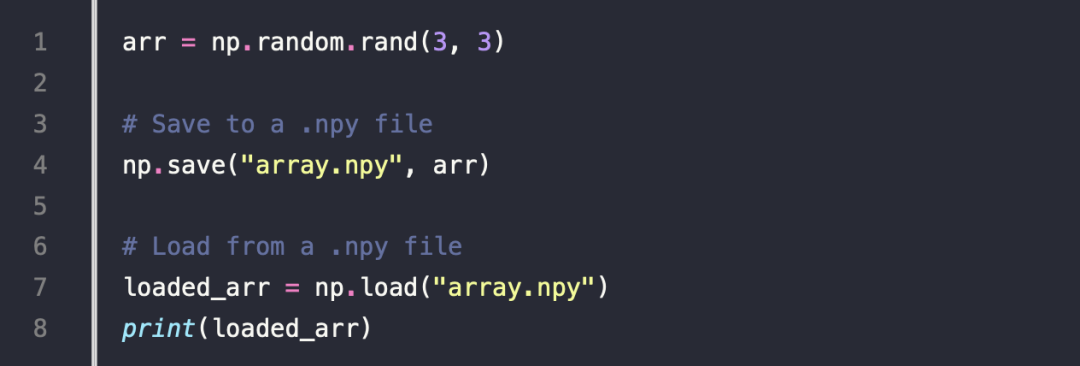
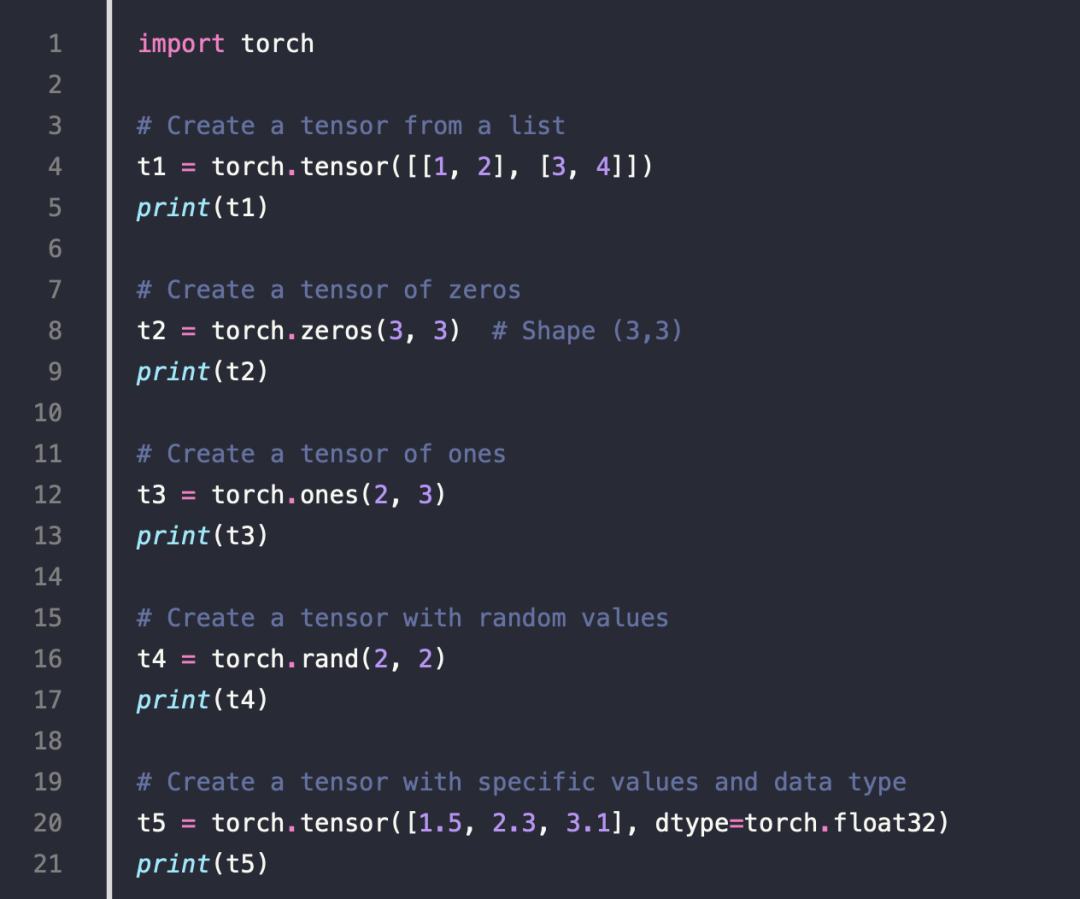
ten sor 的一些例子
- Creating Tensors
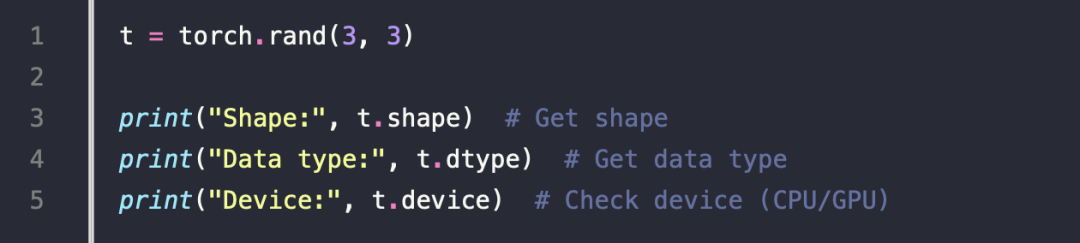
2.Checking Tensor Properties
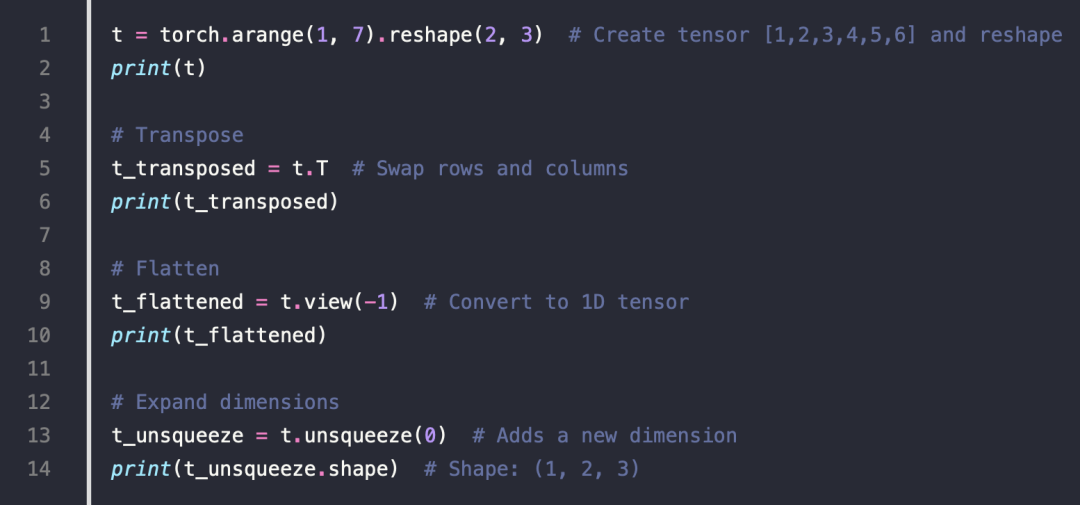
3.Reshaping and Manipulating Tensors
4.Basic Math Operations
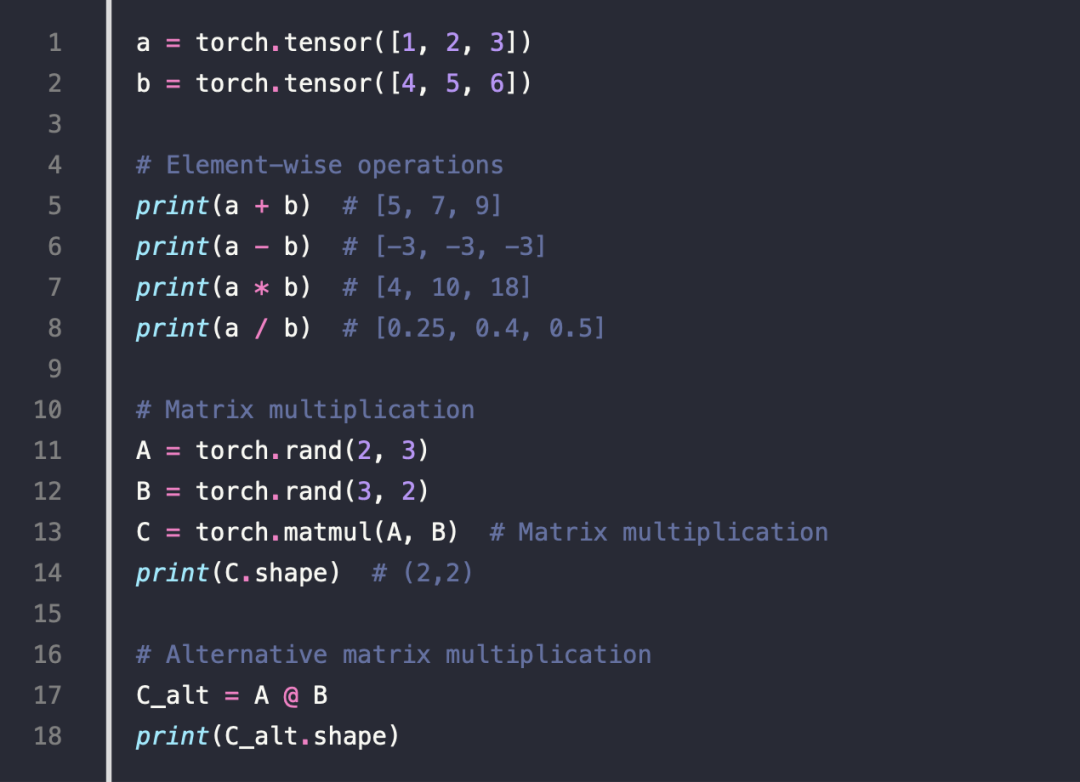
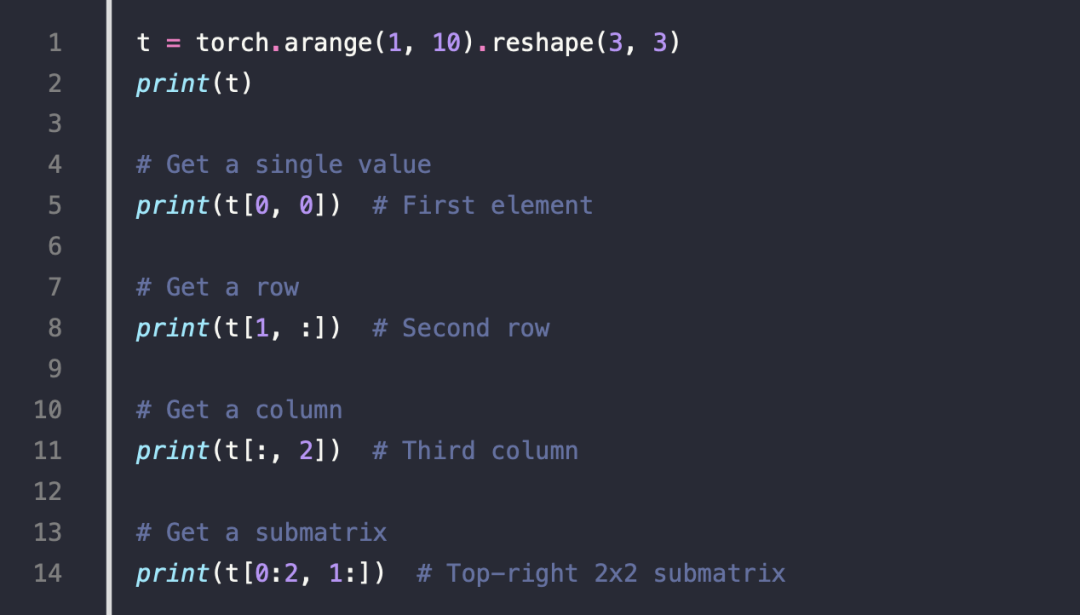
5.Tensor Indexing & Slicing
6.Moving Tensors to GPU

7.Creating Tensors for Deep Learning

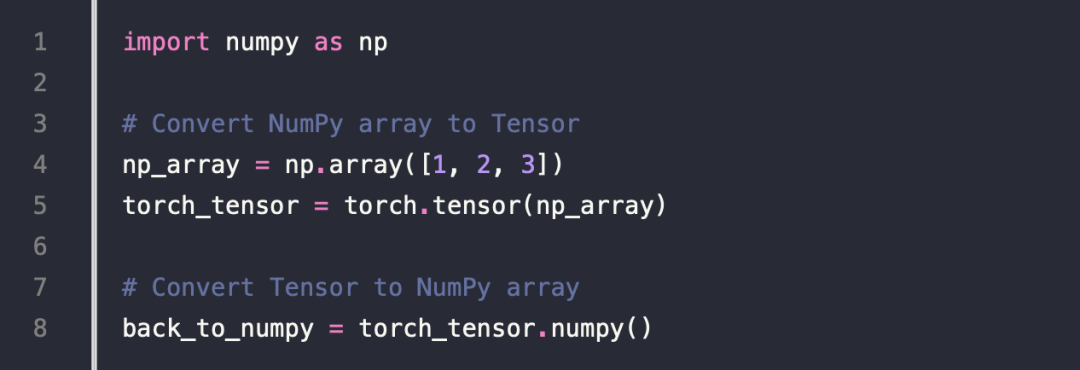
8.Converting Between NumPy & Tensor

一个例子
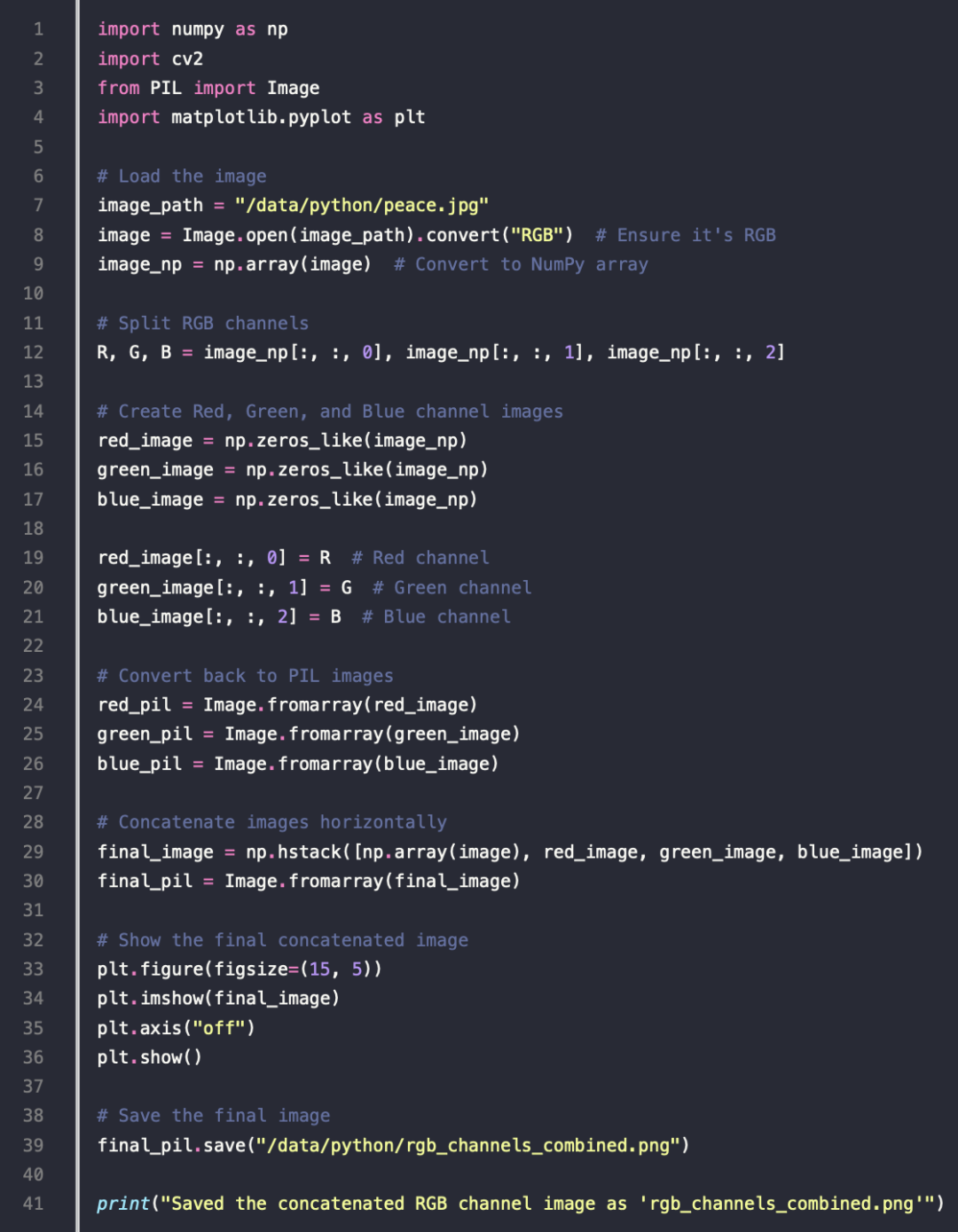
原图

转换后的 RGB 拼接的结果

深入
启动

Torchvision 读取和训练
安装
相关 API
介绍
-
torchvision.datasets这个包本身并不包含数据集的文件本身
-
它的工作方式是先从网络上把数据集下载到用户指定目录
-
然后再用它的加载器把数据集加载到内存中。最后,把这个加载后的数据集作为对象返回给用户
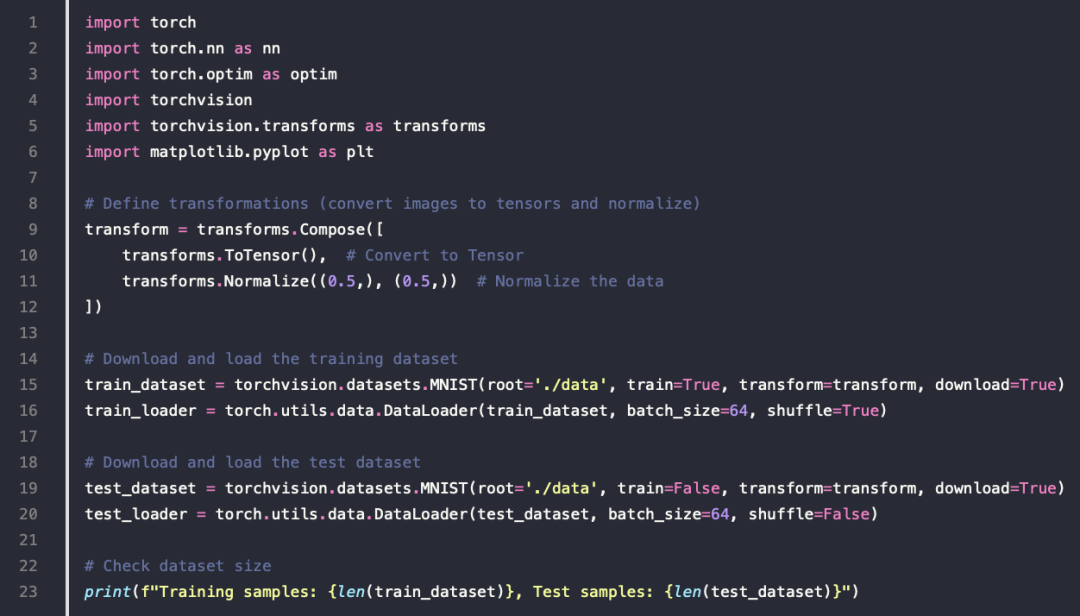
MNIST
- MNIST 数据集是一个著名的手写数字数据集
例子
定义
Define Loss Function and Optimizer

Train the Model
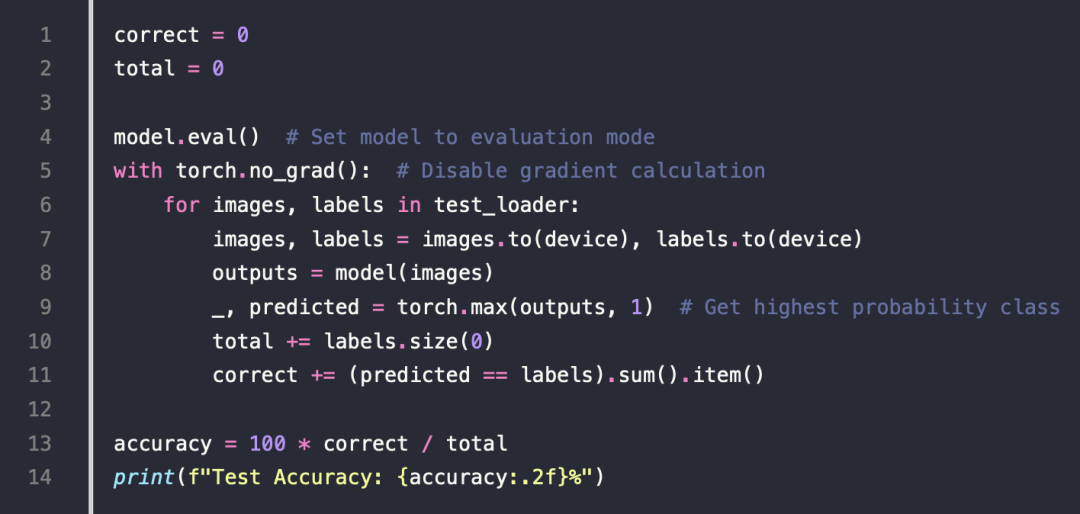
Evaluate the Model
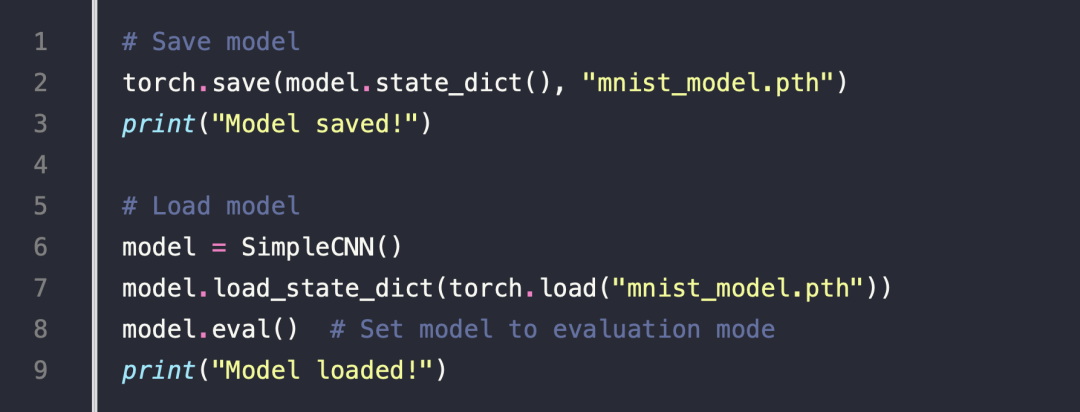
Save and Load the Model
Visualize Sample Predictions
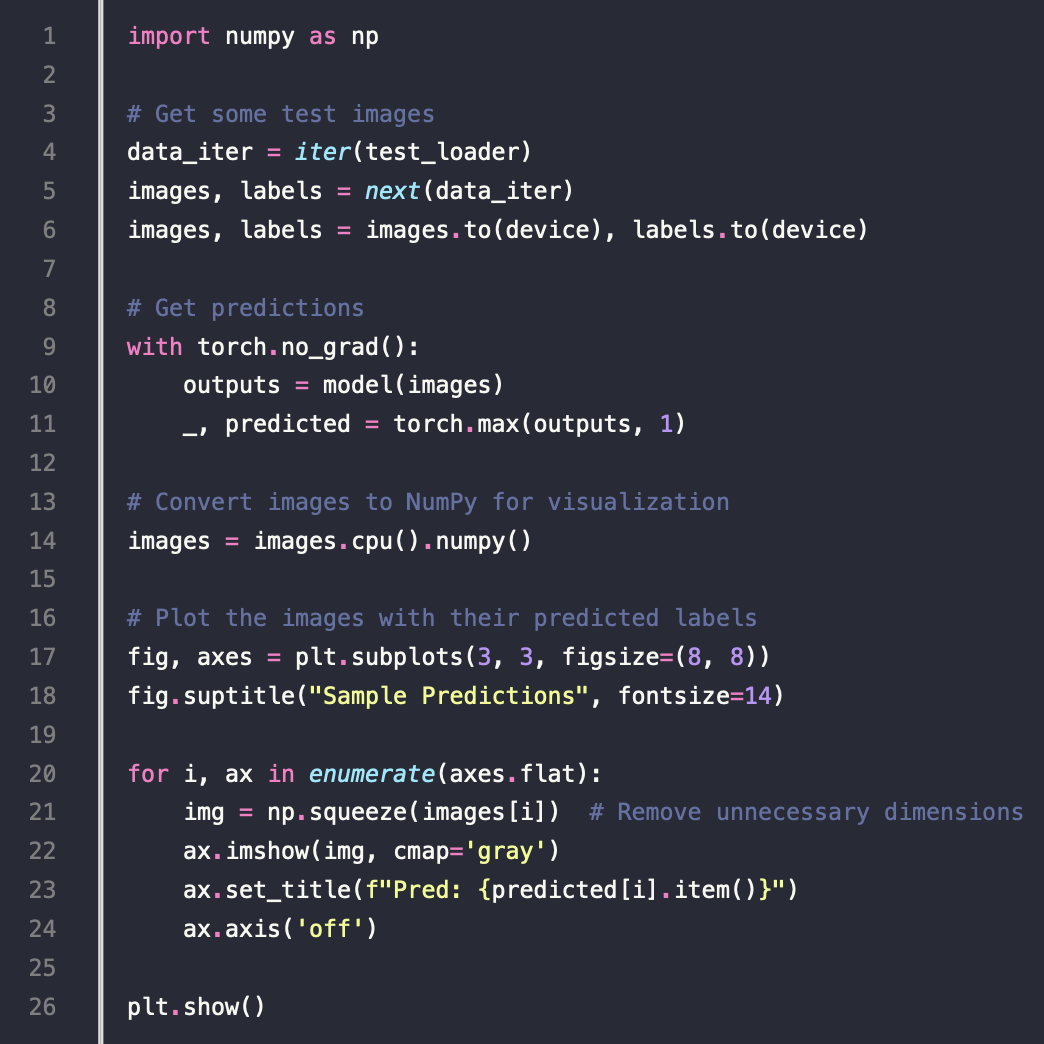
显示的结果

图像处理
图像裁剪代码
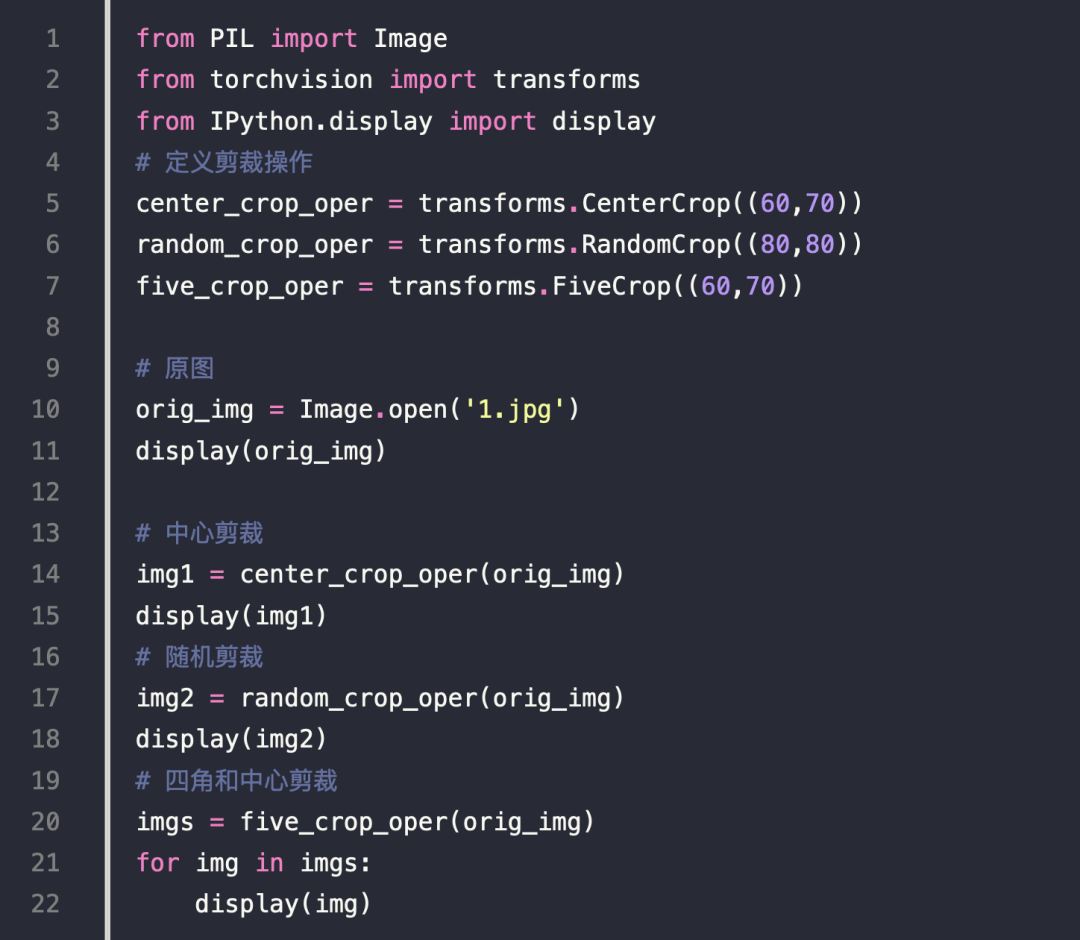
结果

图像翻转
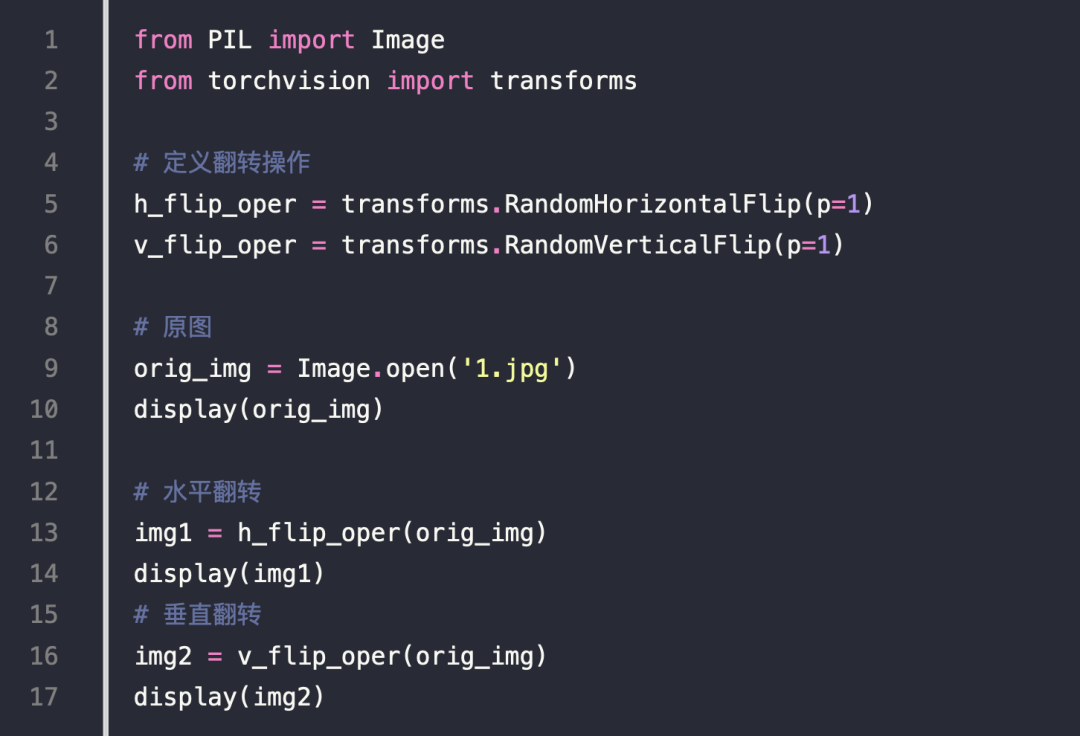
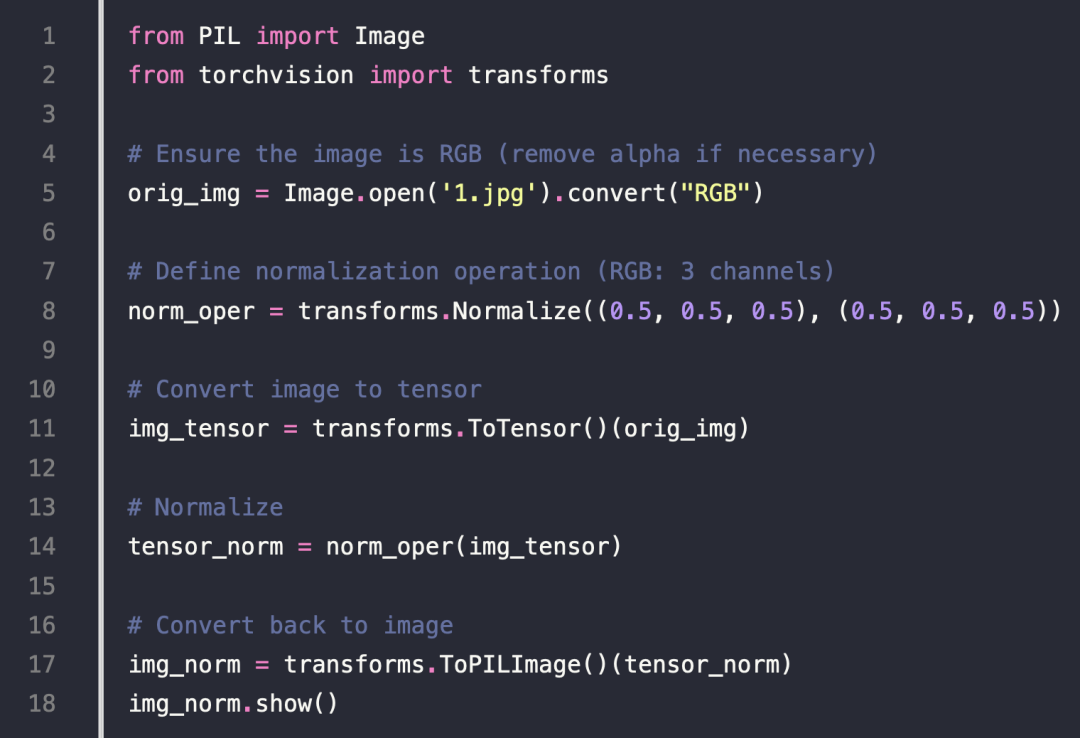
像素取平均值
Torchvision 的常用功能
torchvision.models 模块包括了一些唱功模型
-
图像分类
-
图像分割
-
物体检测
-
视频分类
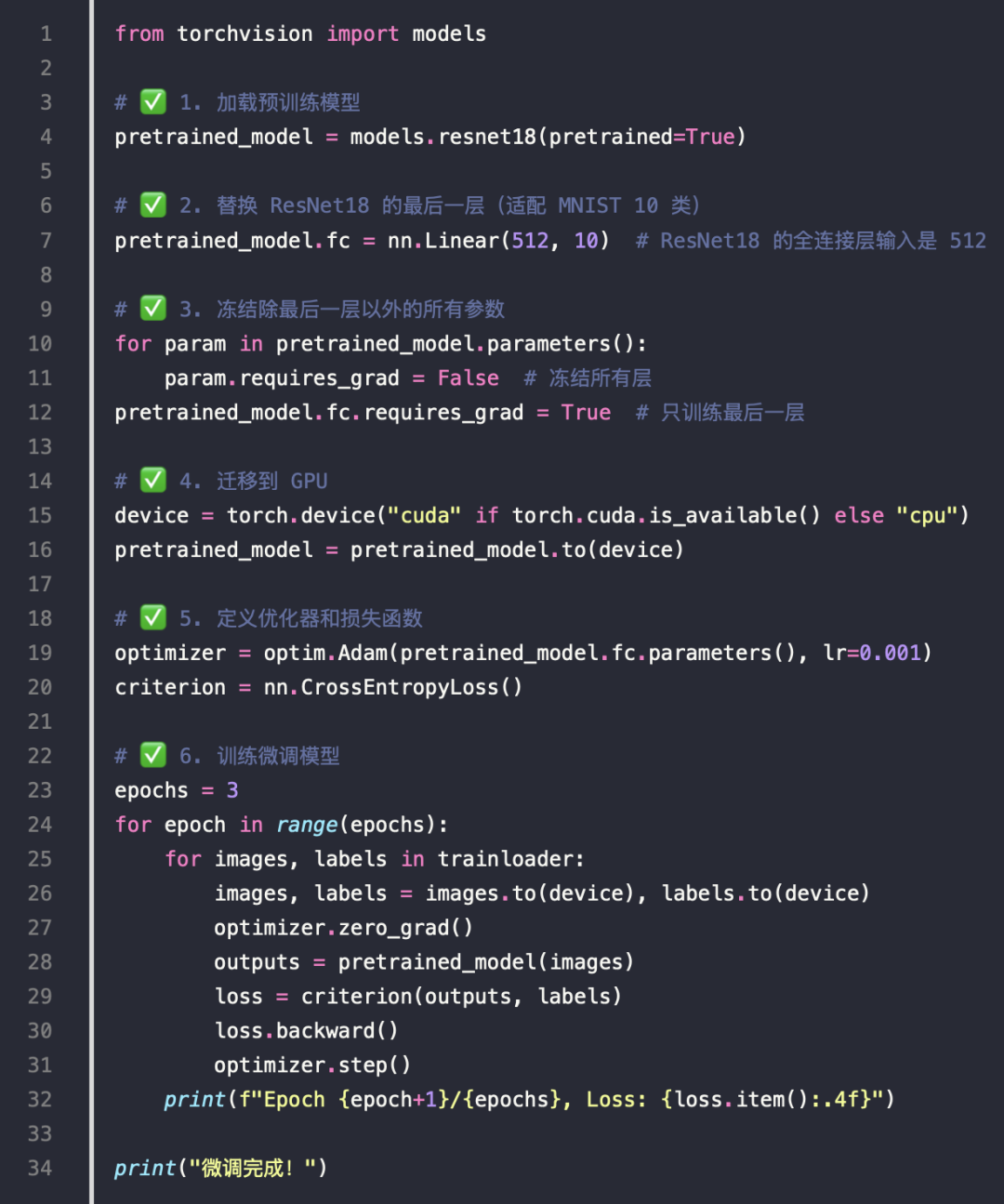
基于已有的模型,做微调
-
Load Pretrained Model (ResNet-18)
-
Modify Last Layer for Custom Classes
-
Freeze Other Layers to Use Pretrained Weights
-
Train Only the New Layer (fc)
-
Evaluate on Validation Set
-
Save & Load Model
-
Visualize Predictions
微调代码

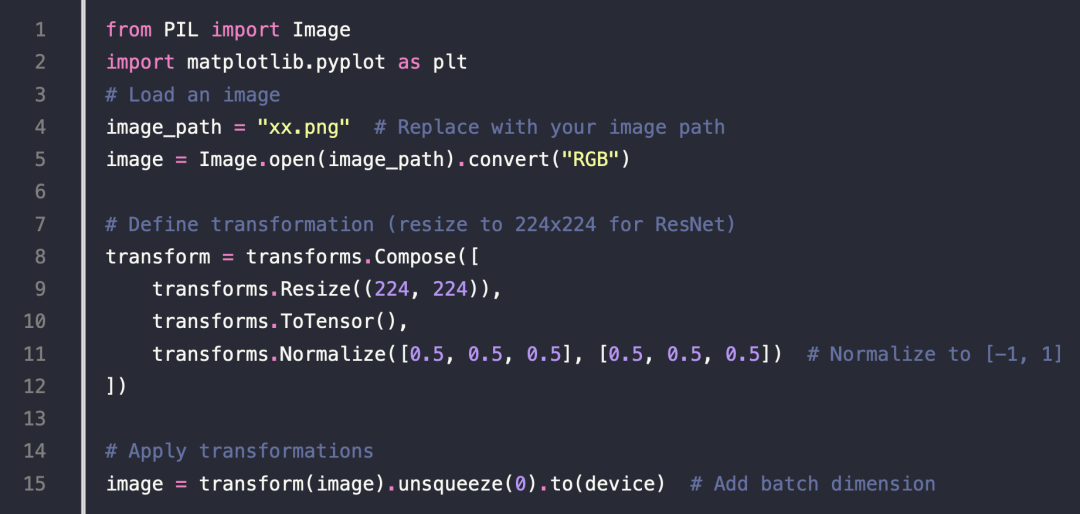
Load and Preprocess a Single Image
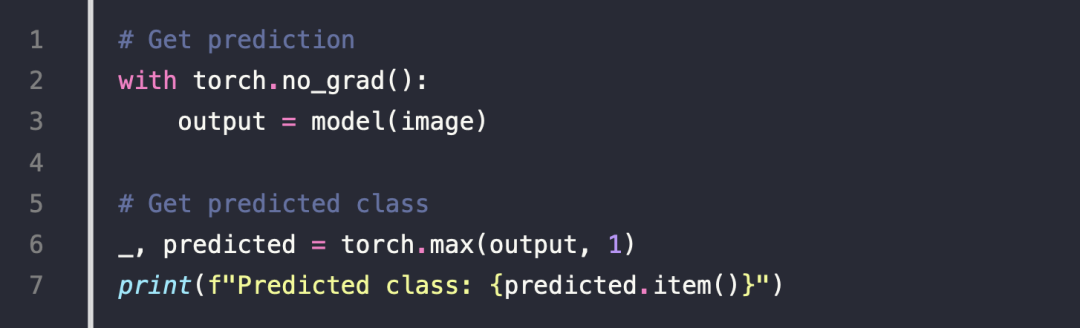
Perform Inference
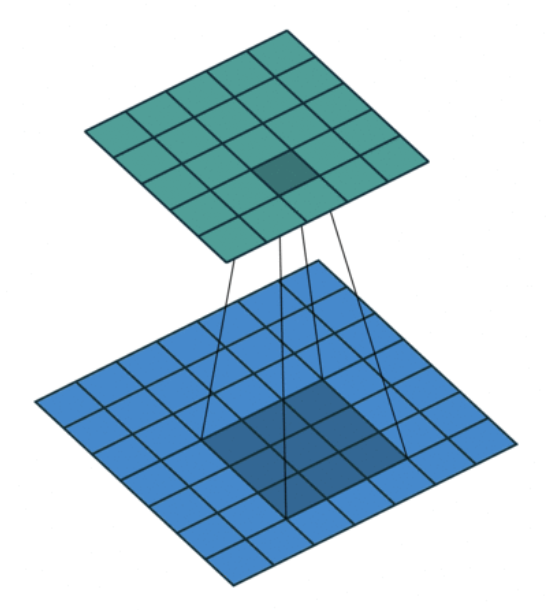
卷积
工作原理
-
将大的 tensor 跟小 tensor 的卷积做计算
-
卷积的初始值是随机产生的
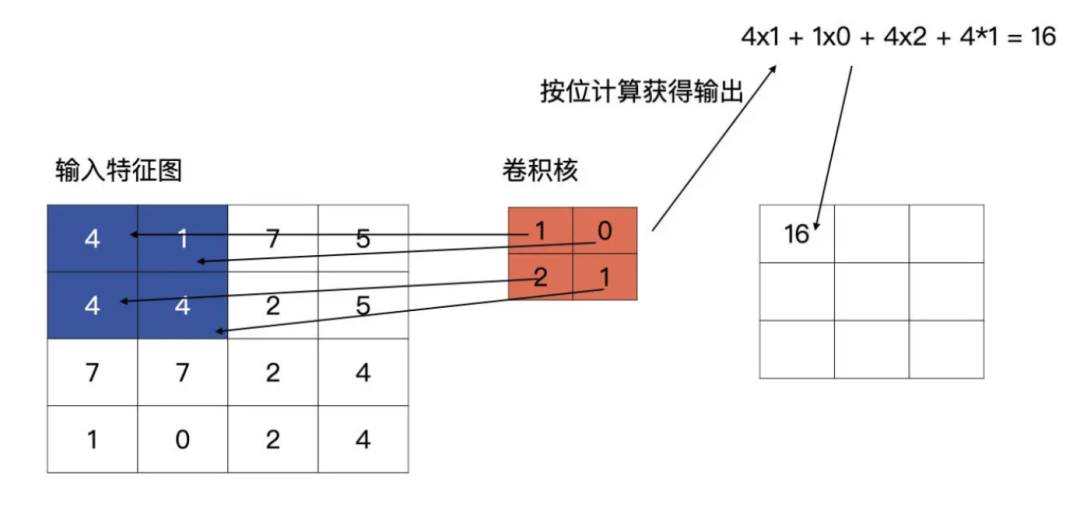
标准的卷积
-
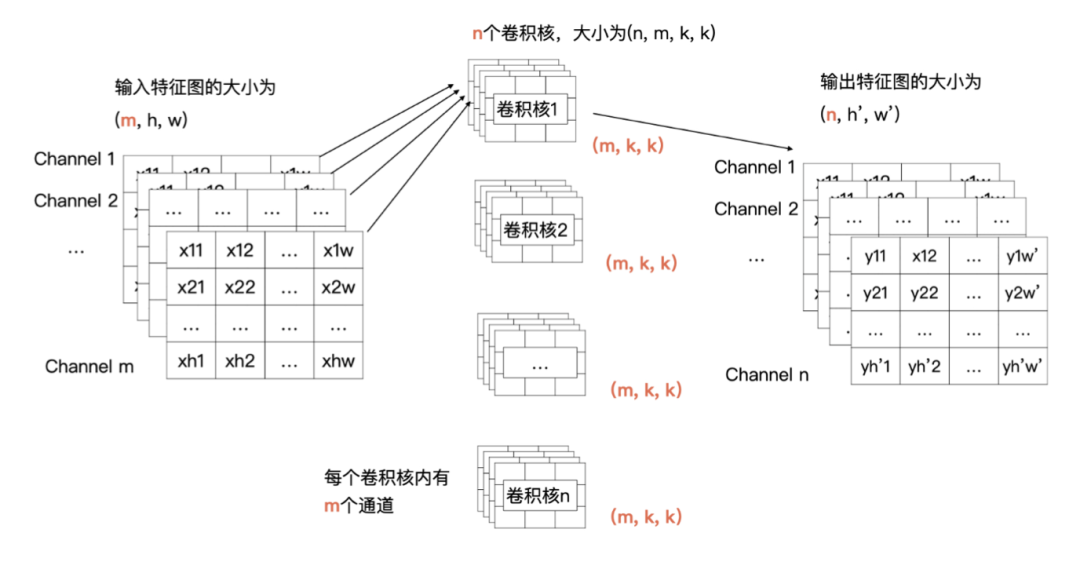
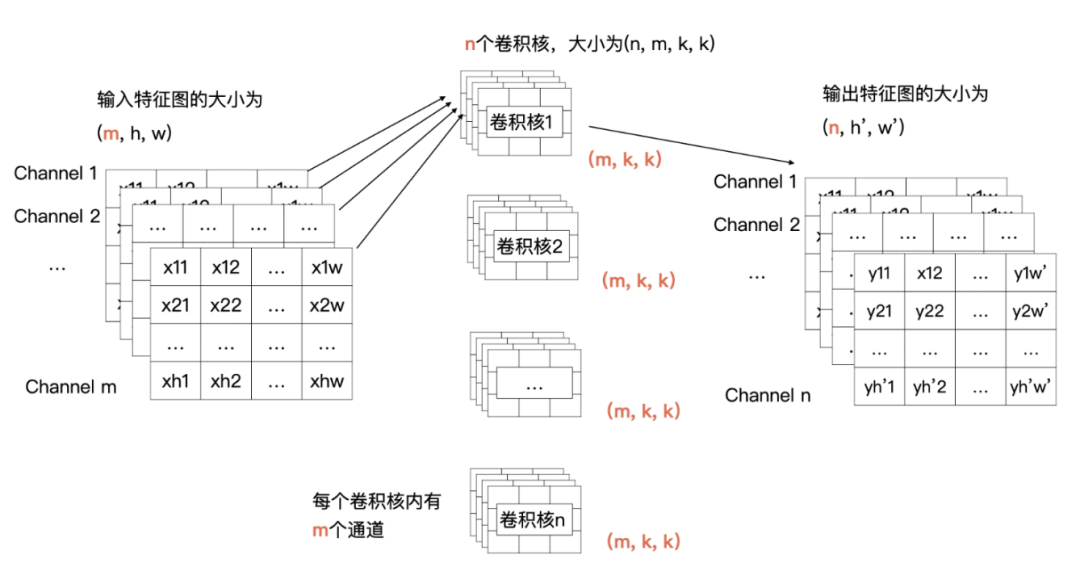
每一个通道与卷积核中对应通道的数据做计算
-
输入特征图中第 i 个特征图与卷积核中的第 i 个通道的数据进行卷积
-
最后会产生 m 个特征图,将这 m 个特征图求和,就是最终结果
-
channel 1、2、3 跟卷积1 做计算,生产结果特征 1
-
n 个特征做求和就是最终特征
Padding
- 宽度高度不一致时,可以补 0
Padding
- 宽度高度不一致时,可以补 0
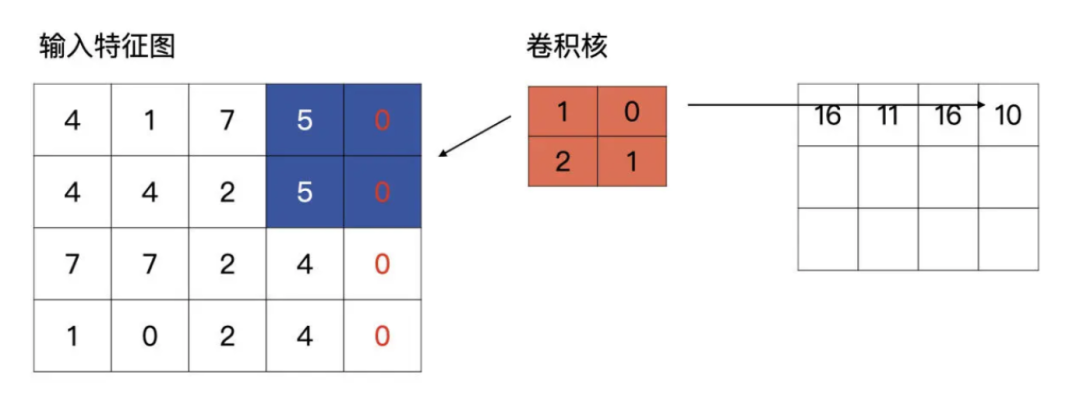
一段卷积的例子
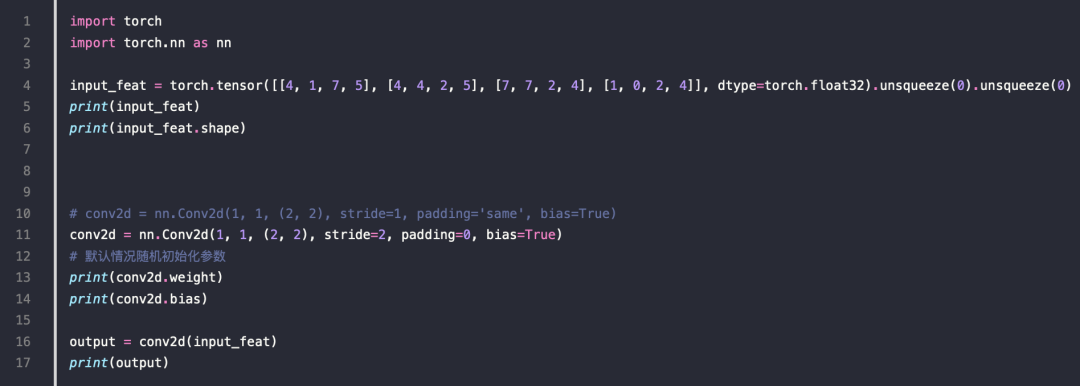
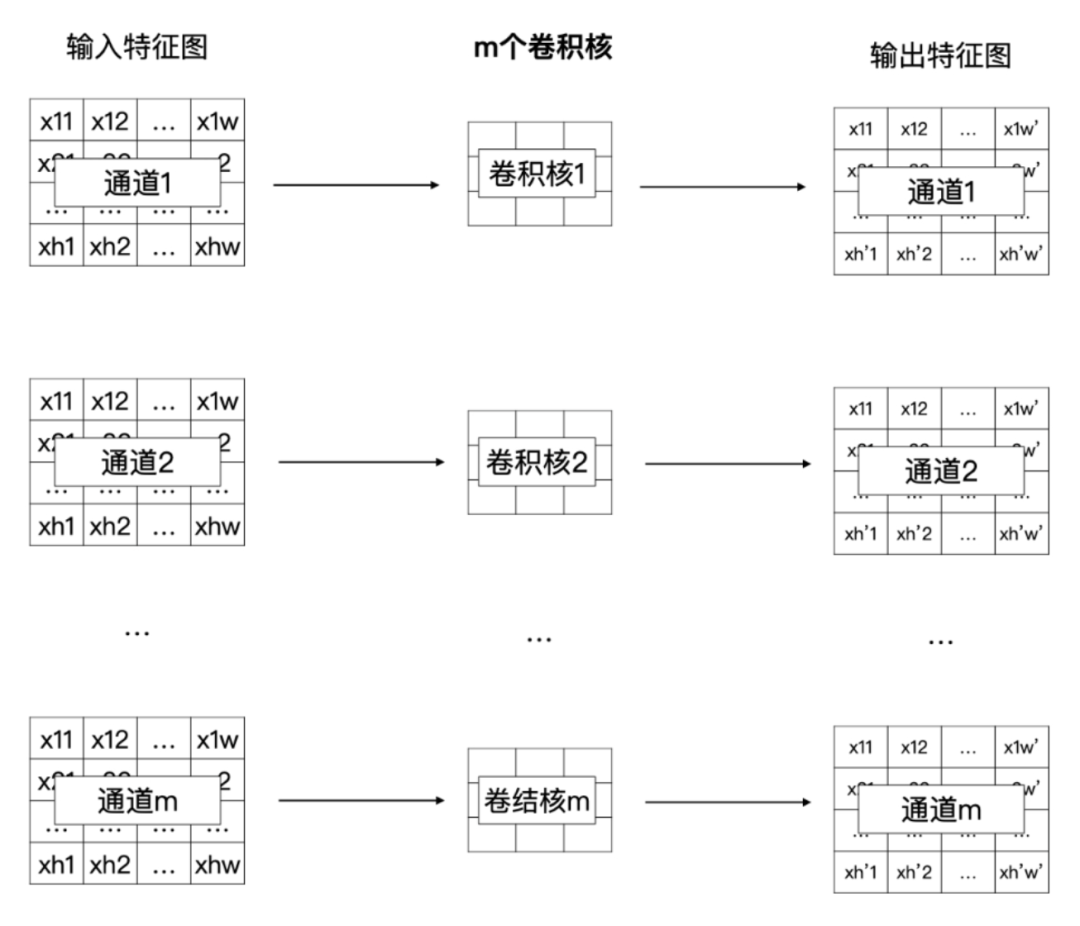
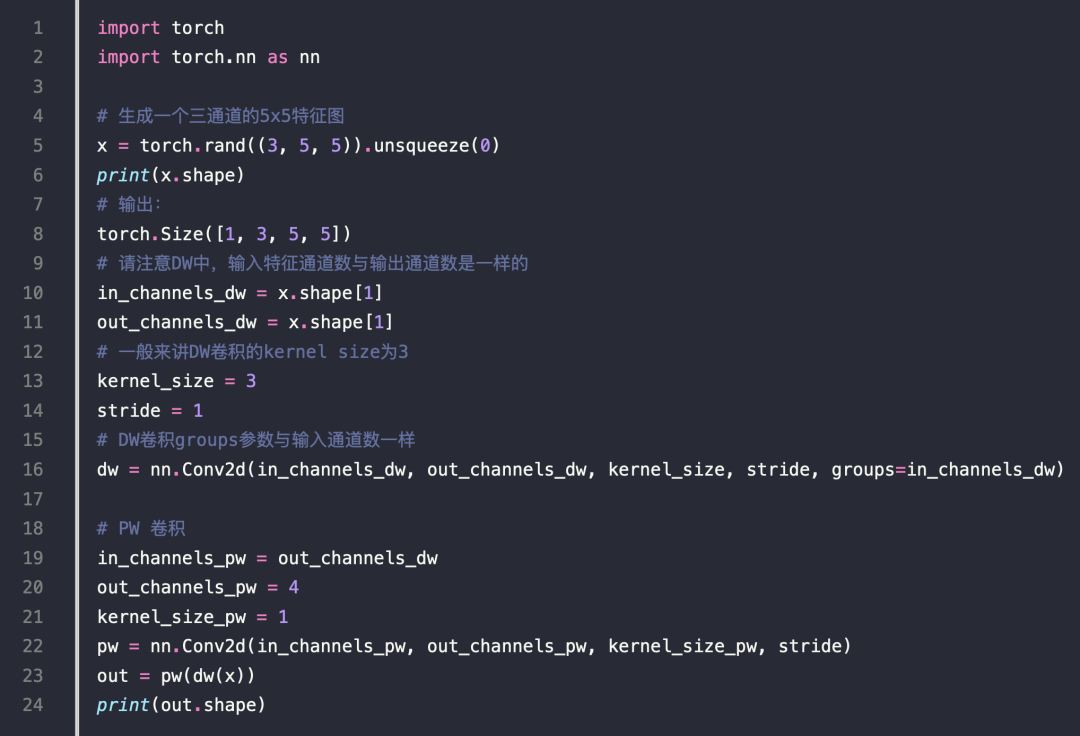
Depthwise(DW)卷积
-
减少计算量,在移动设备上也可以计算
-
DW 卷积就是有 m 个卷积核的卷积,每个卷积核中的通道数为 1
-
这 m 个卷积核分别与输入特征图对应的通道数据做卷积运算
-
所以 DW 卷积的输出是有 m 个通道的特征图
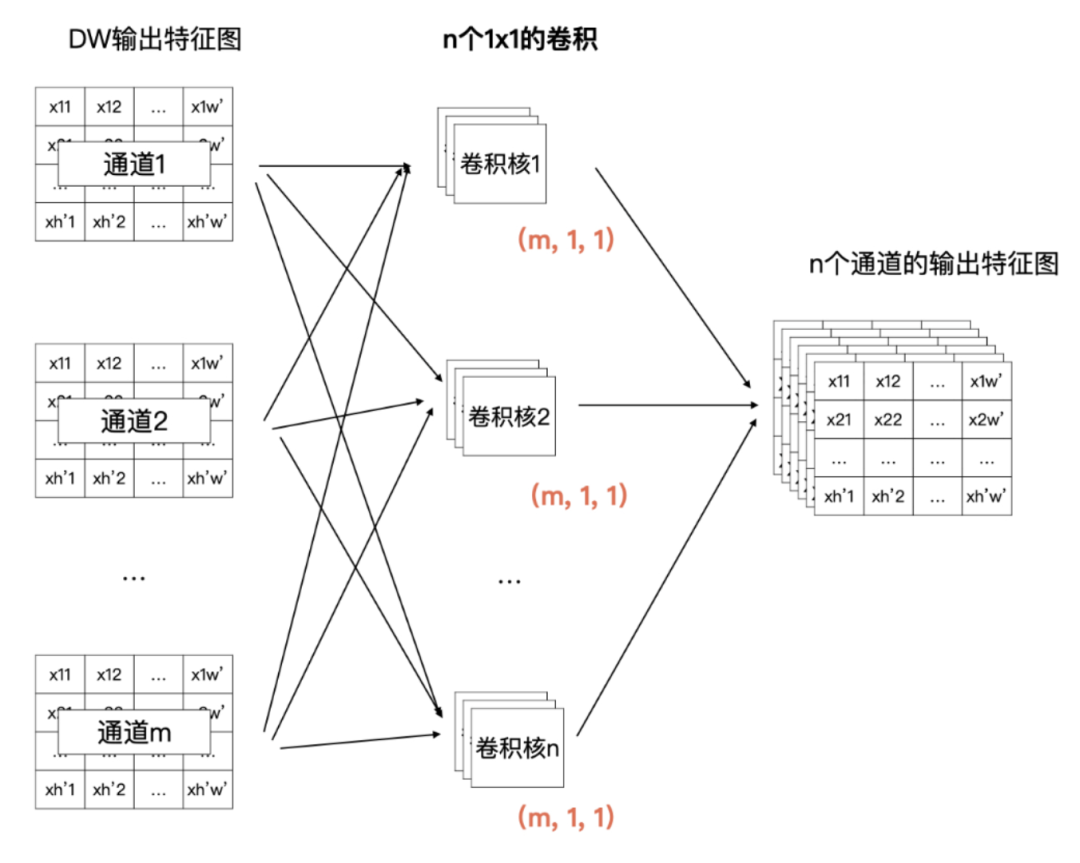
Pointwise(PW)卷积
-
也是一个 n * m 的计算矩阵
-
但是他是根据 DW 的输出来计算的,所以总体的计算量要小很多
深度可分离卷积的计算量大约为普通卷积计算量的
1k2
例子
空洞卷积
-
用来处理图像分割任务
-
感受野 会更大
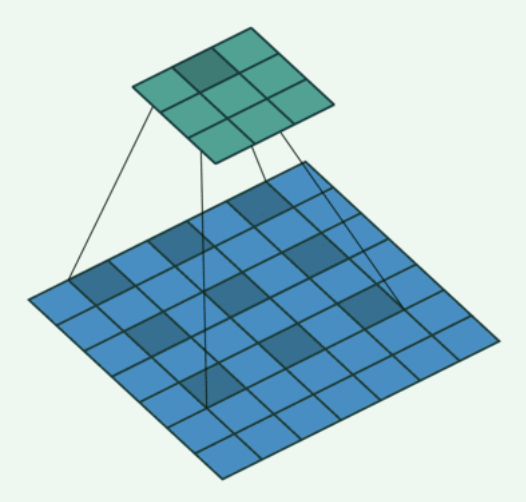
对比一下普通卷积
损失函数
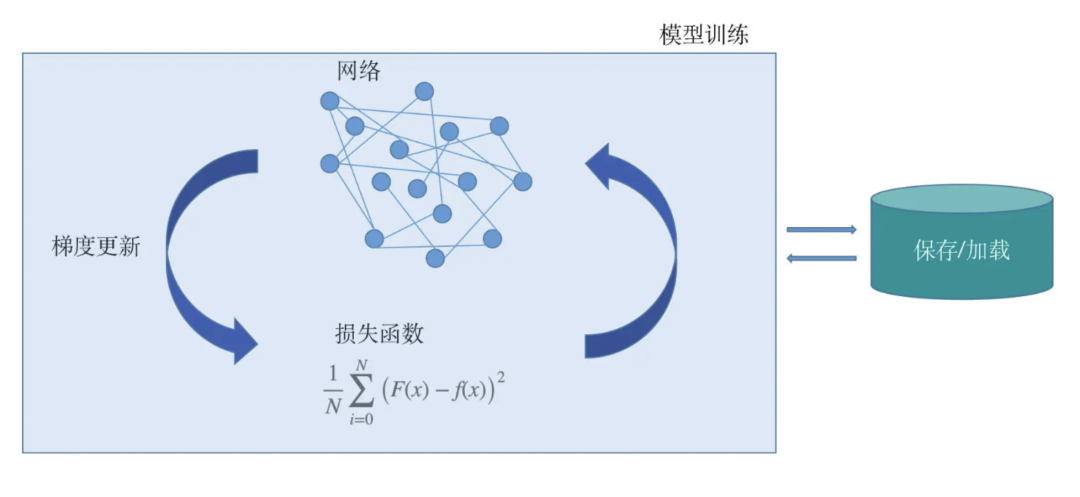
一个深度学习项目包括了
-
模型的设计
-
损失函数的设计
-
梯度更新的方法
-
模型的保存与加载
-
模型的训练过程等
损失函数(loss fuction)
-
损失函数越小,拟合函数对于真实情况的拟合效果就越好
-
把集合所有的点对应的拟合误差做平均,就会得到如下公式
-
损失函数是单个样本点的误差,代价函数是所有样本点的误差
-
1N∑Ni=0(F(x)−f(x))2
0-1 损失函数
L(F(x),f(x))={0if F(x)=f(x)1if F(x)≠f(x)
Mean Squared Error (MSE),均方误差MSE=∑ni=1(si−ypi)2n
Mean Absolute Error (MAE),平均绝对误差损失函数MAE=∑ni=1|yi−ypi|n
信息熵的公式化可以表示为
HS=−∑ip(xi)logp(xi)
交叉熵损失函数
-
p(x)表示真实概率分布
-
q(x) 表示预测概率分布。这个函数就是交叉熵损失函数(Cross entropy loss)
-
这个公式同时衡量了真实概率分布和预测概率分布两方面
-
所以,这个函数实际上就是通过衡量并不断去尝试缩小两个概率分布的误差,使预测的概率分布尽可能达到真实概率分布
−n∑i=1p(xi)logq(xi)
softmax 损失函数
Sj=eaj∑Tk=1eak
Weighted Log Probability Sum
- 它是交叉熵损失函数的一个特例n∑i=1p(xi)log(Si)
对于模型来说
-
损失函数就是一个衡量其效果表现的尺子
-
有了这把尺子,模型就知道了自己在学习过程中是否有偏差,以及偏差到底有多大
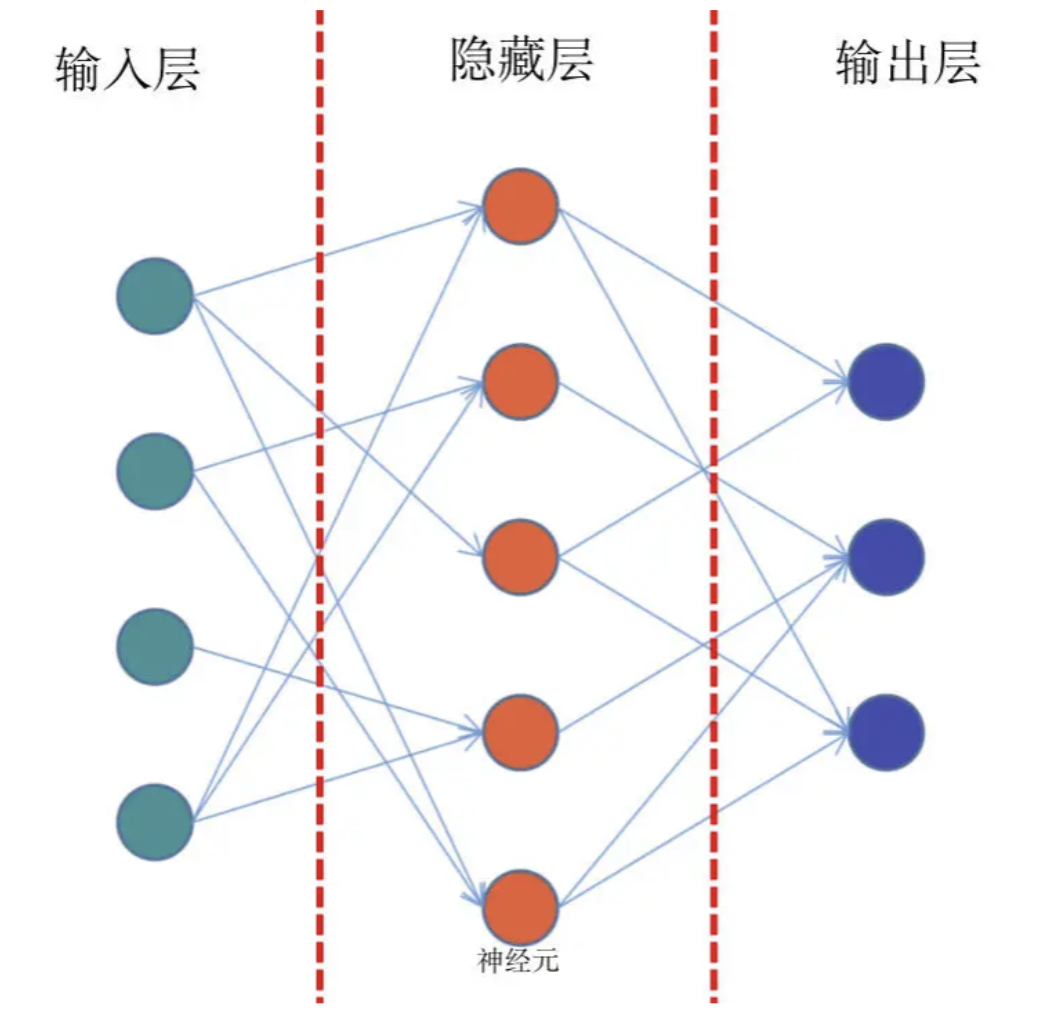
计算梯度
前馈网络
- 从输入层、隐藏层、再到输出层
导数
-
当函数值增量Δy 与变量 x 的增量Δx 的比值,在Δx 趋近于 0 时
-
如果极限 a 存在,我们就称 a 为函数 F(x) 在 x 处的导数
-
Δx 一定要趋近于 0,而且极限 a 是要存在的
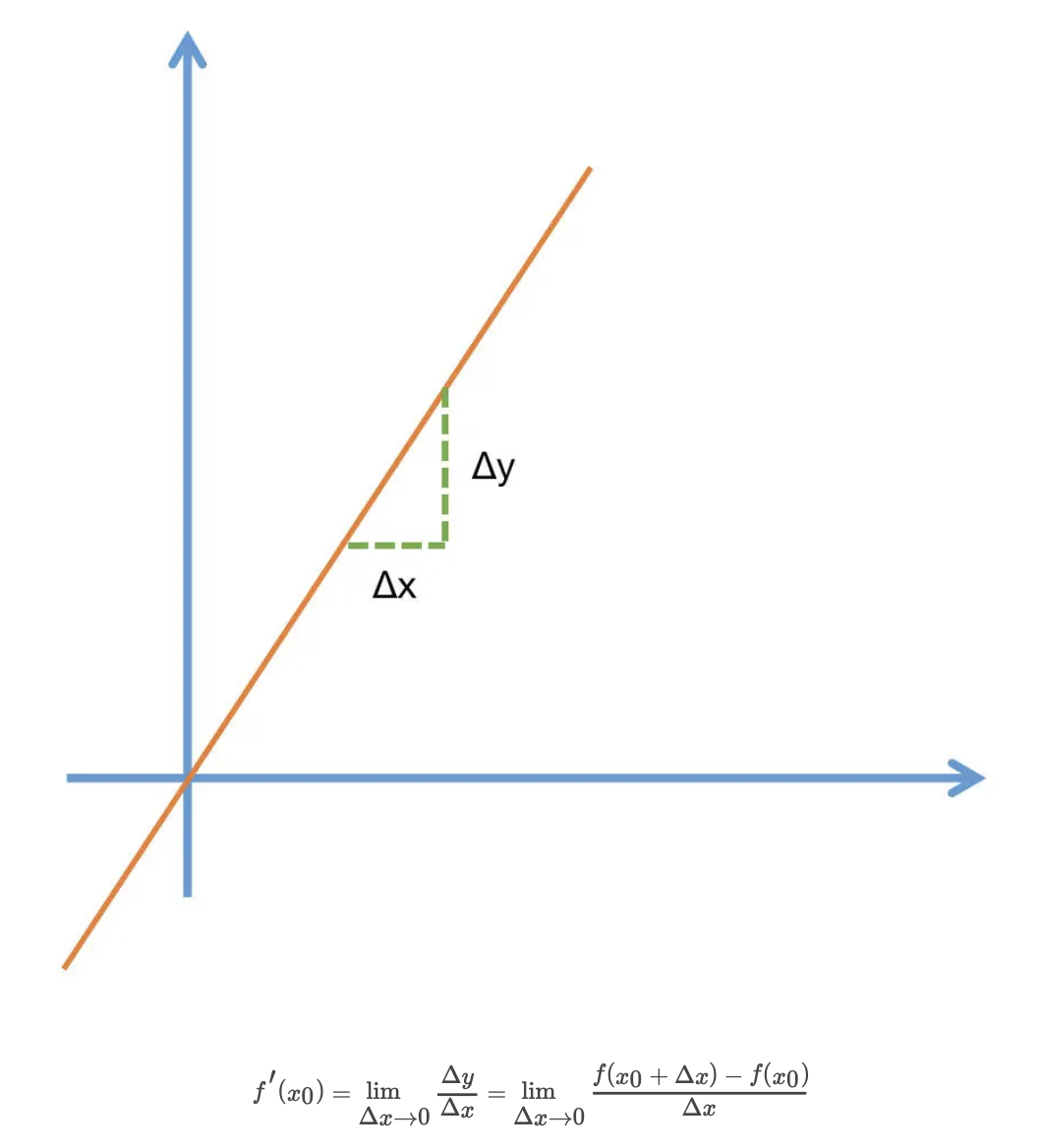
f′(x0)=limΔx→0ΔyΔx=limΔx→0f(x0+Δx)−f(x0)Δx
偏导数
- 偏导数其实就是保持一个变量变化,而所有其他变量恒定不变的求导过程
∂∂xjf(x0,x1,...,xn)=limΔx→0ΔyΔx=limΔx→0f(x0,...,xj+Δx,...,xn)−f(x0,...,xj,...,xn)Δx
梯度
-
梯度向量的方向即为函数值增长最快的方向
-
模型就是通过不断地减小损失函数值的方式来进行学习的
-
让损失函数最小化,通常就要采用梯度下降的方式
-
每一次给模型的权重进行更新的时候,都要按照梯度的反方向进行
-
模型通过梯度下降的方式,在梯度方向的反方向上不断减小损失函数值,从而进行学习
∇f(x)=∂f∂x1,∂f∂x2,...,∂f∂xi
链式法则
- 两个函数组合起来的复合函数,导数等于里面函数代入外函数值的导数,乘以里面函数之导数
反向传播
-
前向传播:数据从输入层经过隐藏层最后输出,其过程和之前讲过的前馈网络基本一致。
-
计算误差并传播:计算模型输出结果和真实结果之间的误差,并将这种误差通过某种方式反向传播,即从输出层向隐藏层传递并最后到达输入层
-
迭代:在反向传播的过程中,根据误差不断地调整模型的参数值,并不断地迭代前面两个步骤,直到达到模型结束训练的条件
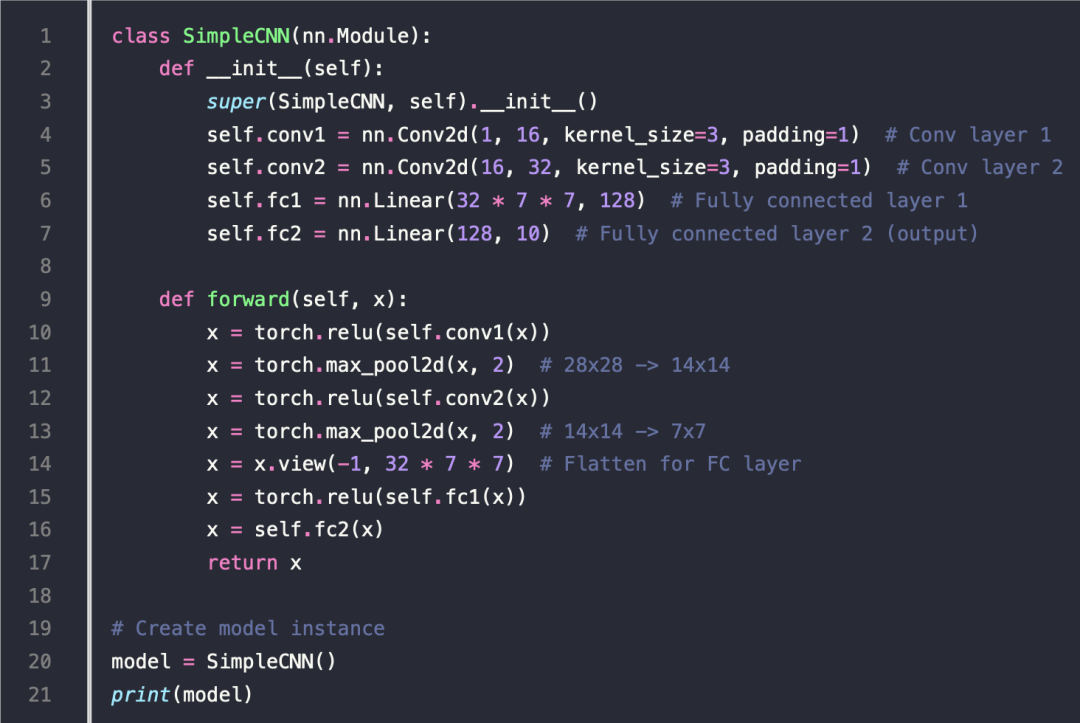
构建网络
自定义 nn.Module 网络
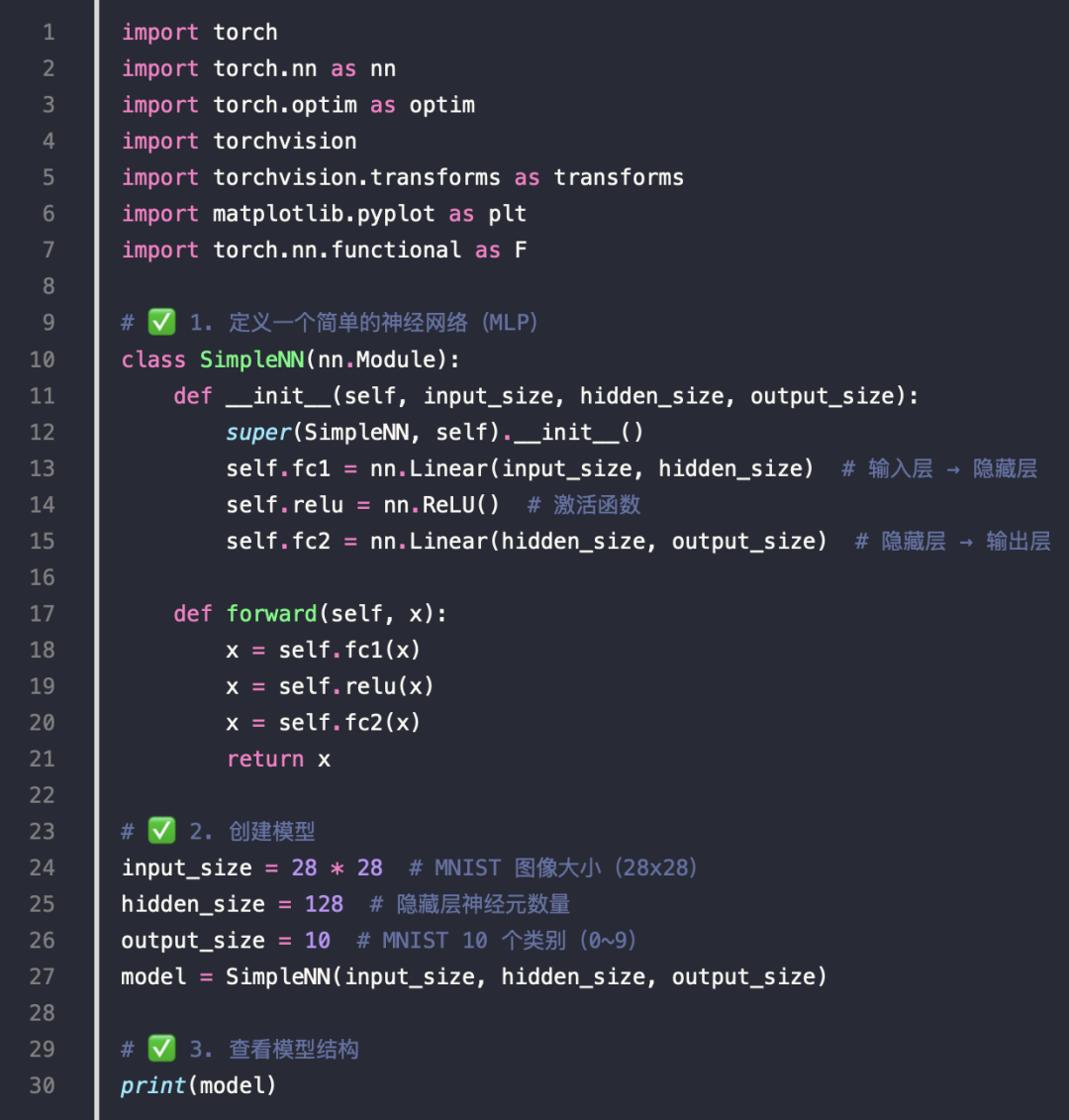
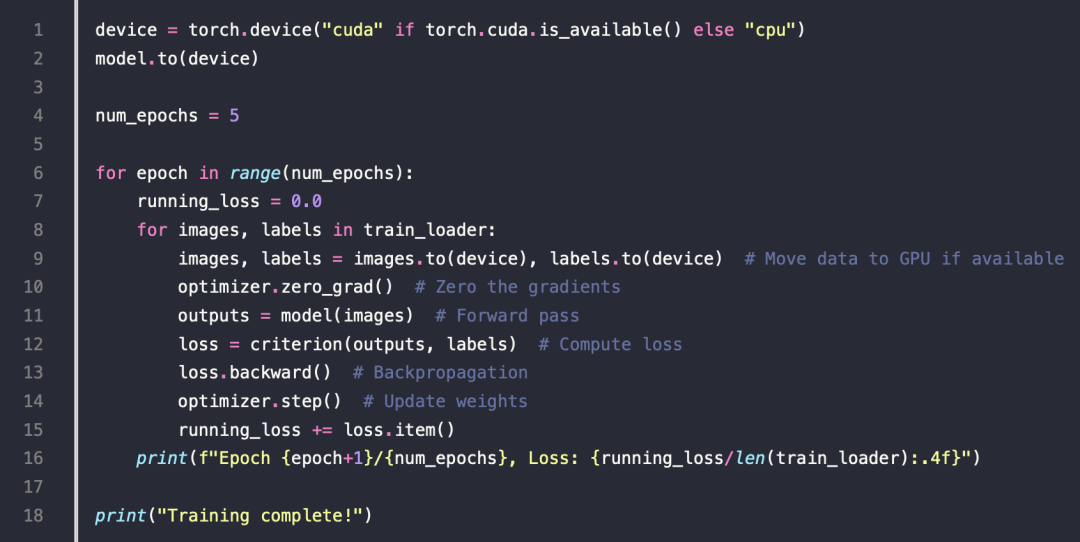
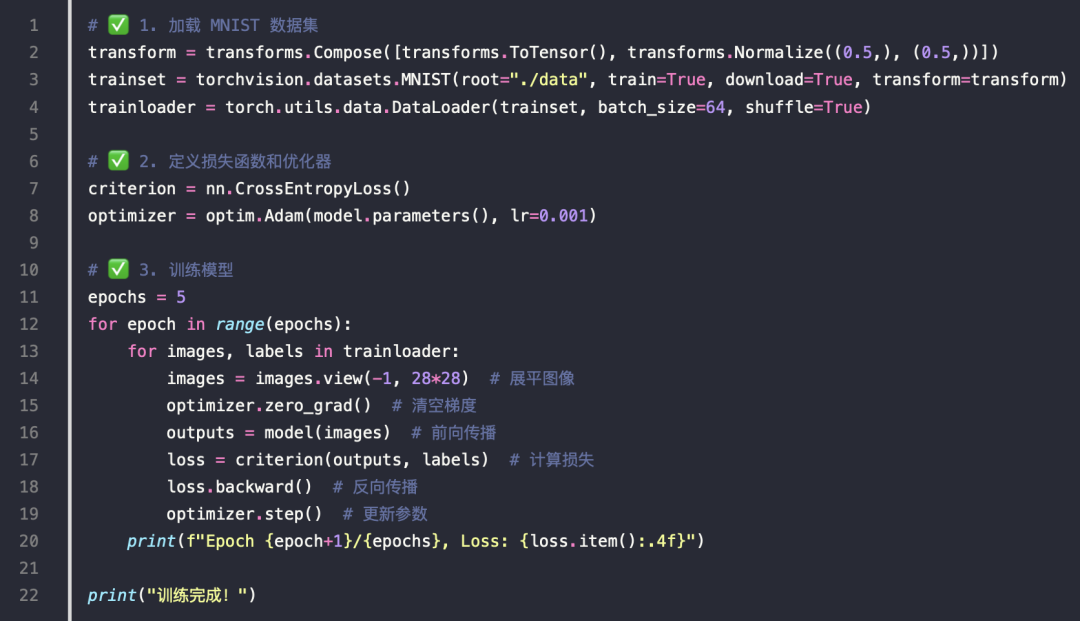
训练模型
微调 ResNet18
优化方法
优化方法
-
目的就是找到能够使得 f(x) 的值达到最小值对应的权重
-
优化过程就是找到一个状态,这个状态能够让模型的损失函数最小,而这个状态就是模型的权重
-
梯度向量的方向即为函数值增长最快的方向,梯度的反方向则是函数减小最快的方向
梯度下降 vs 贪心
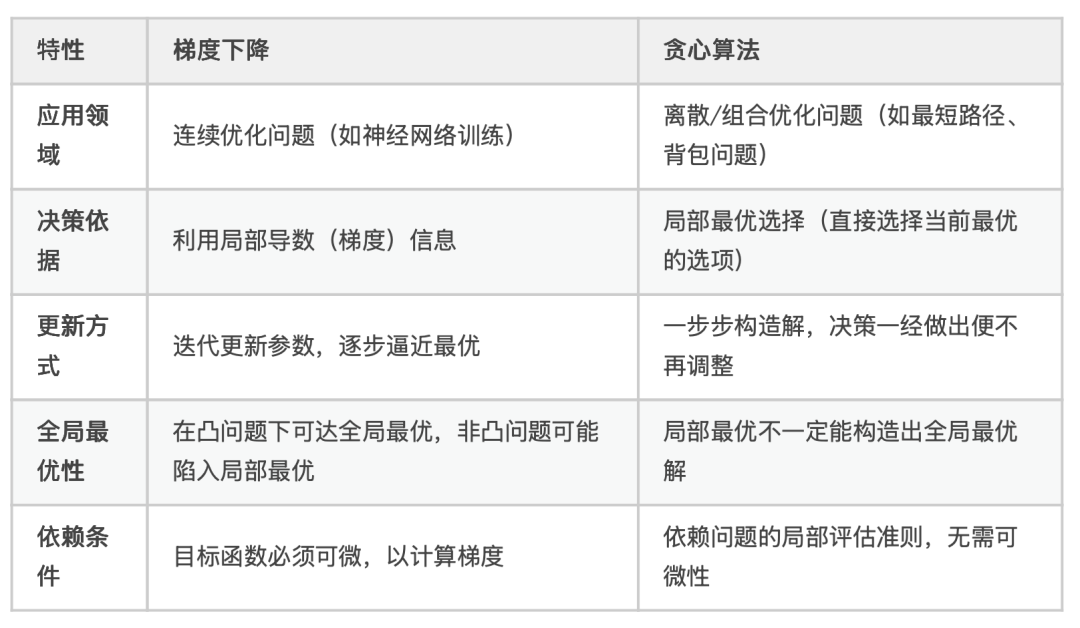
常见的梯度下降方法
-
批量梯度下降法(Batch Gradient Descent,BGD)
-
随机梯度下降(Stochastic Gradient Descent,SGD)
-
随机梯度下降方法选择了用损失很小的一部分精确度和增加一定数量的迭代次数为代价,换取了最终总体的优化效率的提高
-
小批量梯度下降(Mini-Batch Gradient Descent, MBGD)
为了得到最小的损失函数,我们要用梯度下降的方法使其达到最小值
要点:模型之所以使用梯度下降,其实是通过优化方法不断地去修正模型和真实数据的拟合差距

范围
-
人工智能,最大
-
机器学习,中间
-
深度学习,最小
机器学习开发的几个步骤
-
数据处理:主要包括数据清理、数据预处理、数据增强等。总之,就是构建让模型使用的训练集与验证集
-
模型训练:确定网络结构,确定损失函数与设置优化方法
-
模型评估:使用各种评估指标来评估模型的好坏
可视化工具
安装

测试
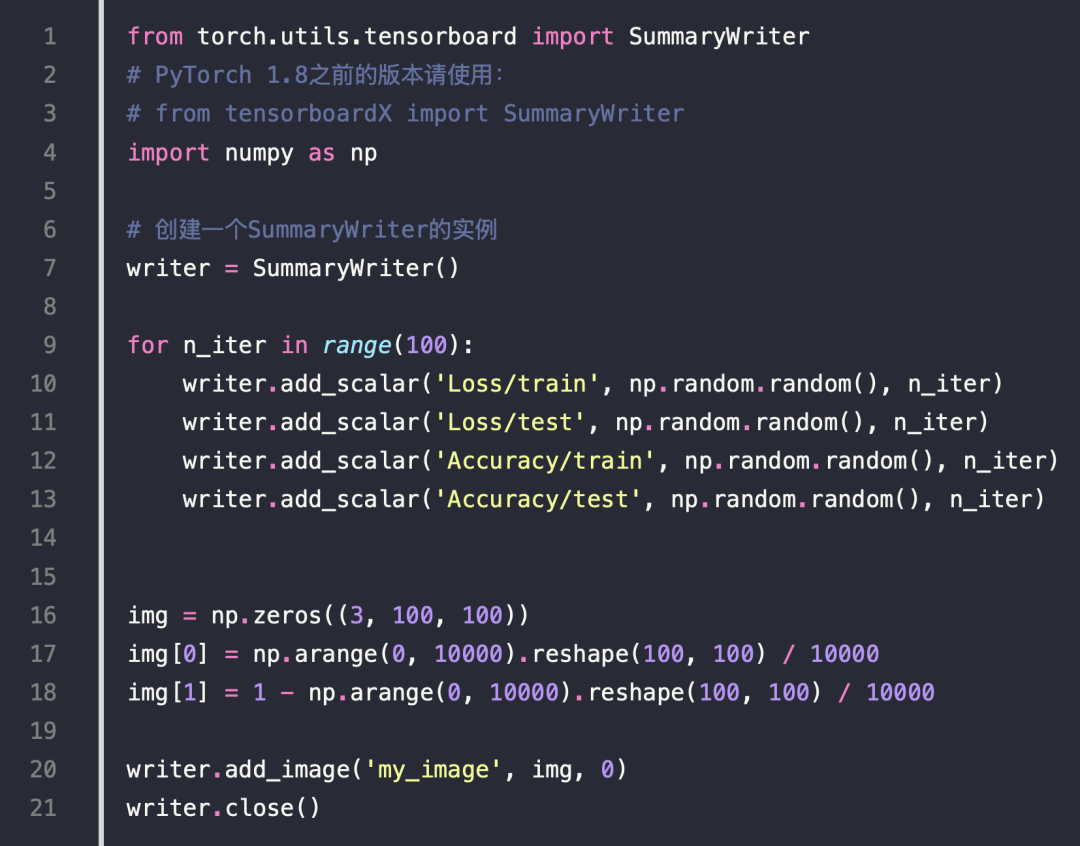
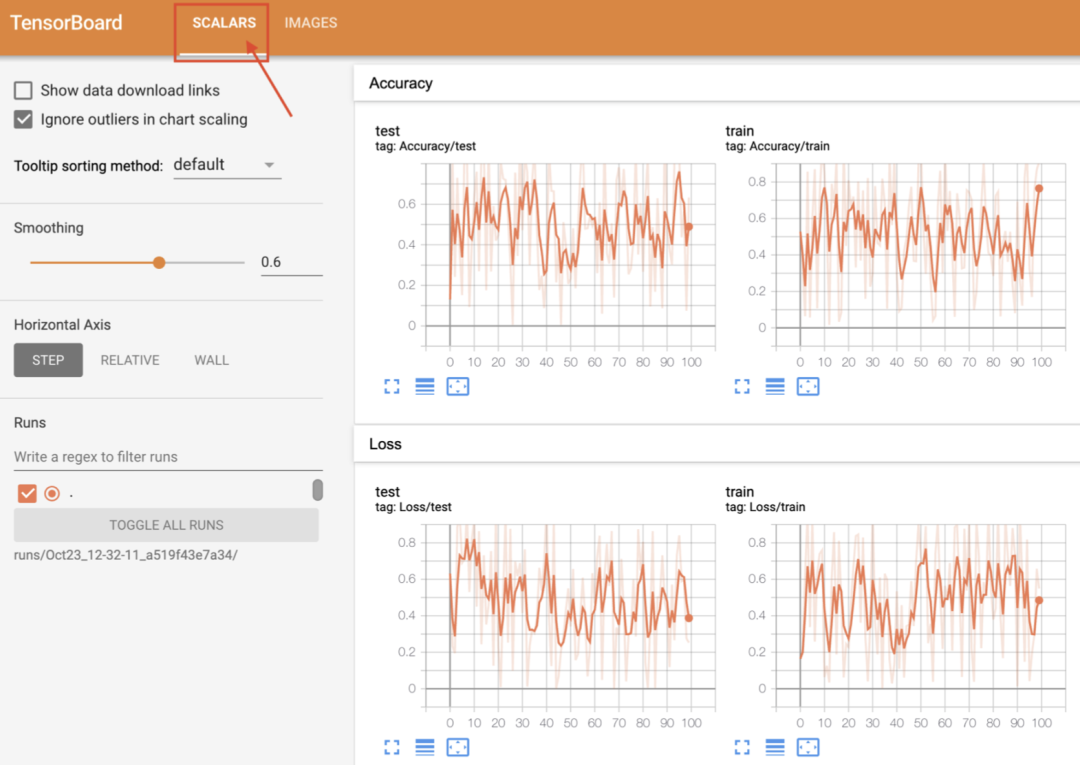
在当前目录下会生成 run,之后执行

Visdom

运行

测试代码
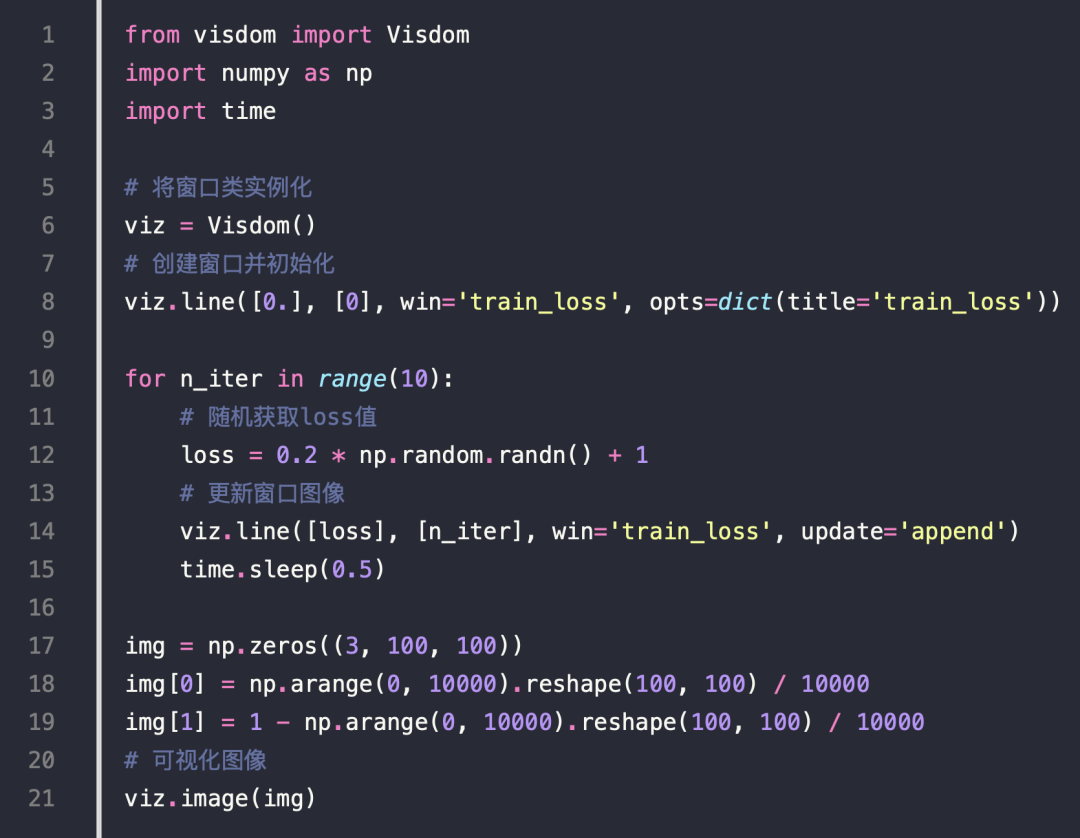
实时更新状态
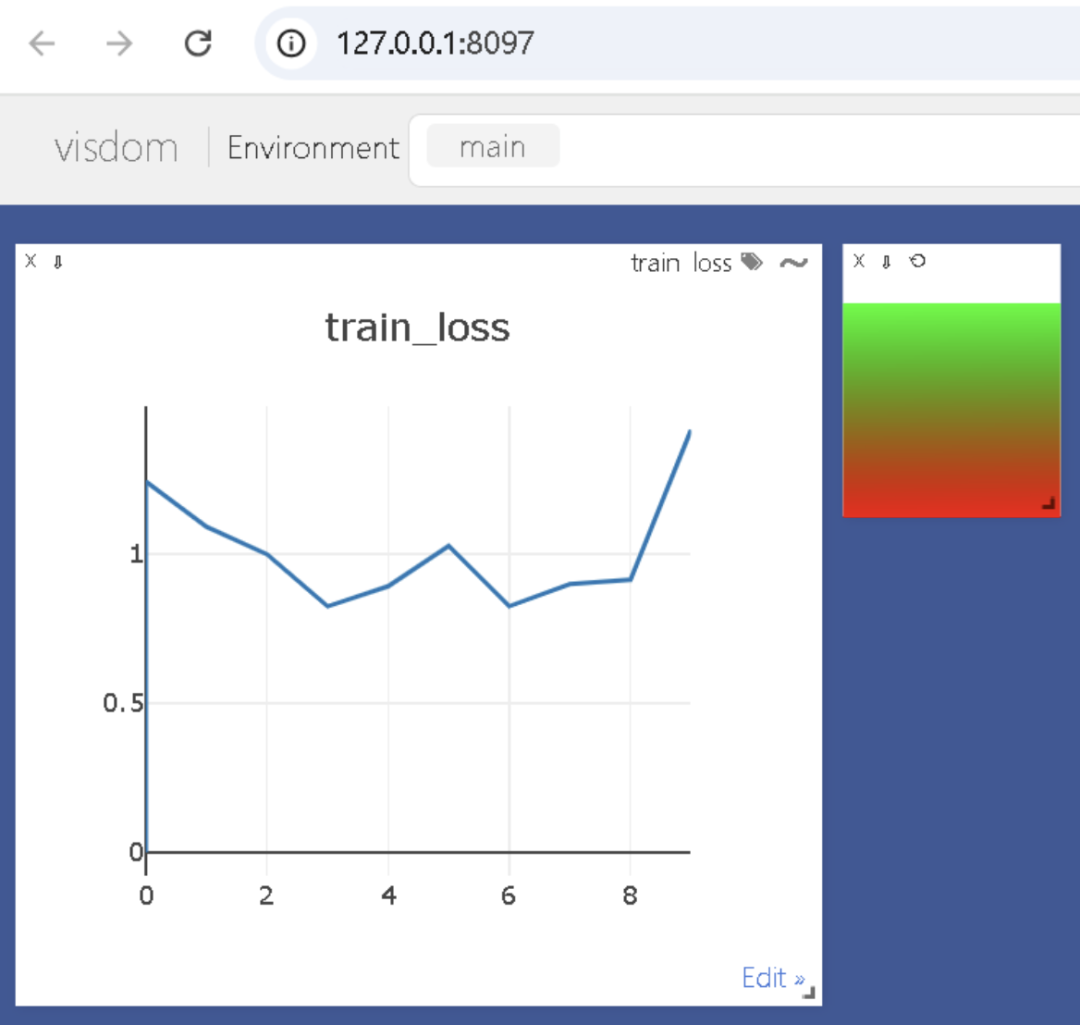
分布式训练
测试
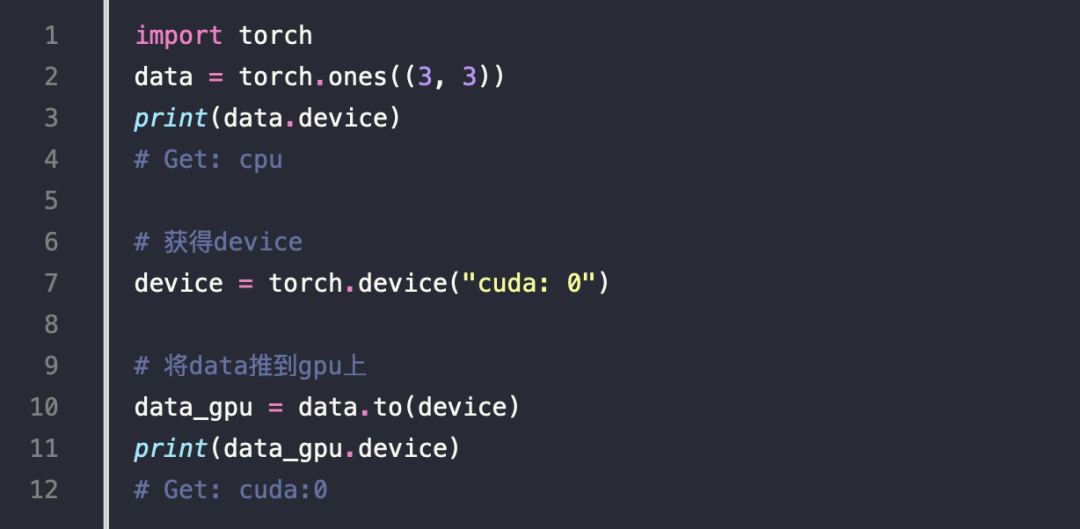
单机并行化

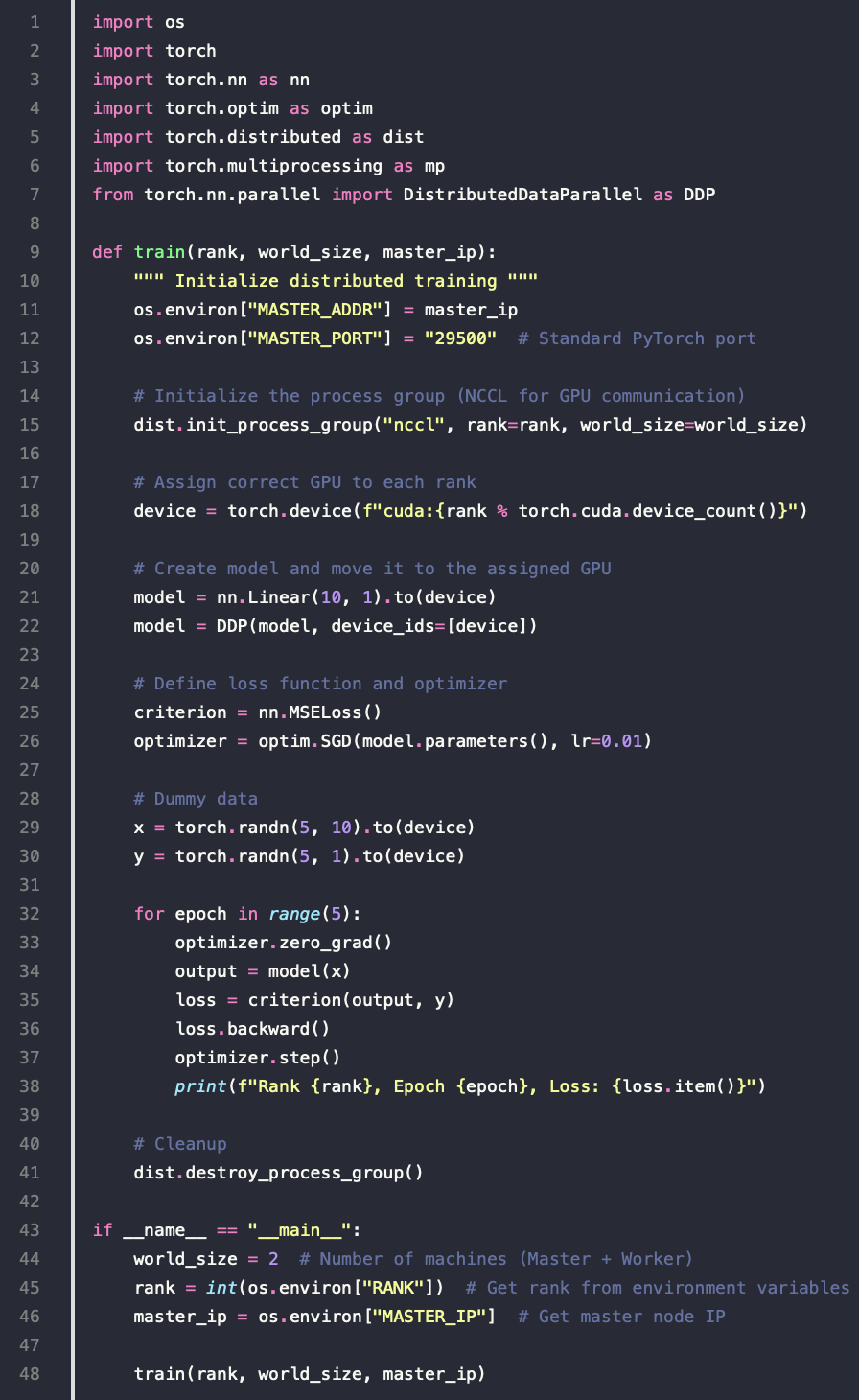
多机多卡
DistributedDataParallel
-
实现多机多卡的关键 API
-
既可用于单机多卡也可用于多机多卡
例子
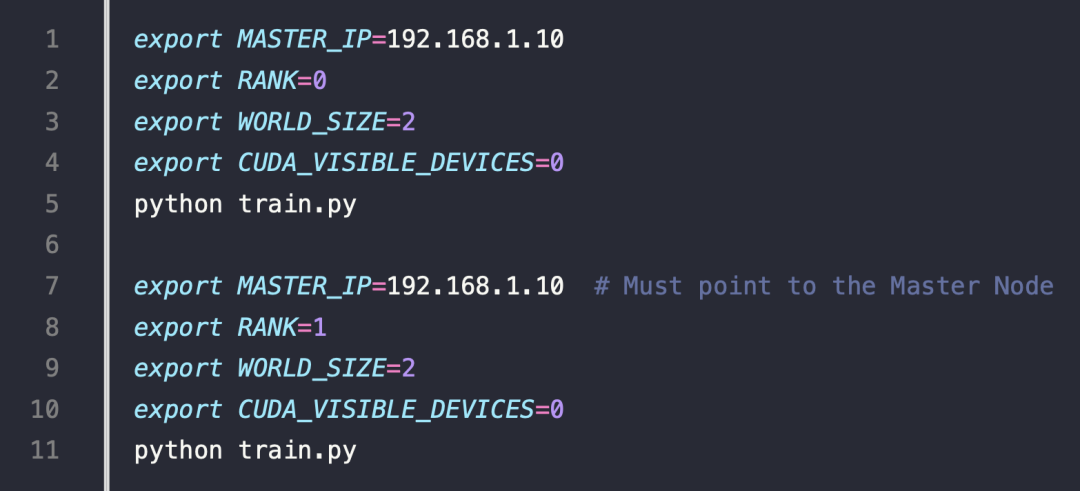
两台机器的启动参数
参考
-
numpy
-
Jupyter Notebook
-
PyTorch
-
TensorFlow
-
Models and pre-trained weights
-
OpenCV 教程
-
Convolution arithmetic 图形展示
-
torch.utils.tensorboard文档
-
tensorboardX 可视化监控
-
visdom 可视化监控
-
官方的 ImageNet 的示例