引言
看到一则报道1,重组后的Meta实验室在9月1号发布了一篇关于提升RAG解码效率的论文,提出的思路有点启发作用,于是把原文下载下来仔细看下。
论文标题:REFRAG: Rethinking RAG based Decoding
论文地址:https://arxiv.org/pdf/2509.01092
1. 动机
通过将外部知识检索结果与用户问题拼接后输入模型,检索增强生成(RAG)已成为提升模型回答质量的重要途径。
然而,这种机制的代价极其高昂:拼接的上下文通常包含数千甚至上万 Token,其中只有少数段落与问题密切相关,其余则是冗余信息。对于解码器而言,这意味着需要维护线性增长的 KV Cache,同时在预填充阶段进行近似二次复杂度的注意力计算,导致**首 Token 延迟(TTFT)**大幅增加,吞吐量下降。
现有的长上下文优化方法大多从稀疏注意力或高效缓存角度出发,但这些方案往往面向一般长文本任务,而未能利用 RAG 特有的"块对块低相关性"结构性特征。于是,REFRAG 的提出正是为了填补这一空白,它将 RAG 的解码过程重新设计为一个压缩、感知与扩展的动态过程,从而显著降低延迟与计算成本。
2. 框架
REFRAG 的核心思路是将检索得到的长上下文从 Token 级别提升到 Chunk 级别表示。
具检索文档会被切分为固定大小的块,每个块通过轻量级编码器(如 RoBERTa)生成一个压缩后的向量表示,再通过投影层映射到解码器可理解的 Token 空间。
这样,原本需要处理数千 Token 的解码器输入被压缩为几百个 Chunk Embedding,输入规模大幅缩短,注意力计算也随之减少。
并且,REFRAG 并未牺牲自回归生成的特性,Chunk Embedding 可以插入在任意位置,与原始 Token 并存,从而保持方法的普适性。
为了避免"一刀切"压缩带来的信息损失,REFRAG 还引入了一个轻量的强化学习策略,动态决定哪些 Chunk 必须保留原文 Token,哪些可以以压缩表示替代。这一机制使得模型能够在有限算力预算下,把计算资源分配到最关键的上下文部分。
整体流程如下图所示。

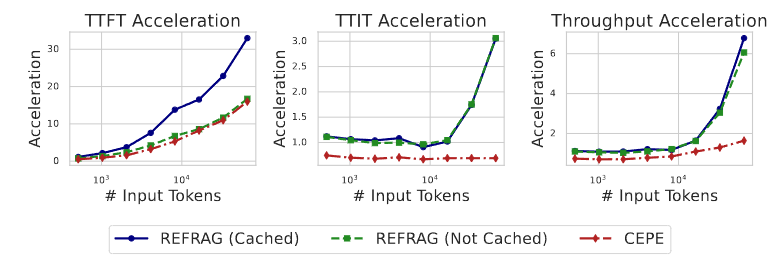
下图展示了REFRAG和其它方法在以下三个指标上的加速效果:
- TTFT (Time to First Token): 首词元生成延迟,指的是模型接收到输入指令后,生成并输出第一个词元(token,可以理解为一个单词或一个汉字)所花费的时间。这个指标衡量的是模型的"反应速度"。
- TTIT (Time to Iterative Token): 迭代词元生成时间,指的是在生成第一个词元之后,生成每一个后续词元所花费的时间。这个指标衡量的是模型生成连续文本的"输出速度"。
- Throughput: 吞吐量,指的是单位时间内(通常是每秒)模型能够生成的总词元数量。这个指标是衡量模型整体处理效率和性能的关键指标,综合了启动延迟和生成速度。
3. 具体方法
在 REFRAG 的方法论中,核心挑战是:如何让解码器能够"理解"由编码器生成的块级压缩表示,并在必要时动态选择哪些块需要恢复为原始 Token,从而保证生成质量。
为此,作者提出了一套 分阶段训练流程,具体流程如下:
3.1 编码器与解码器对齐:持续预训练(CPT)
REFRAG 的关键创新在于用 Chunk Embedding 替代原始 Token 嵌入。然而,解码器原本是习惯接收逐 Token 的序列表示,如果直接将压缩后的向量送入解码器,模型很难理解其中的语义。因此,需要一个 对齐过程。
具体做法是设计 下段预测(Next Paragraph Prediction)
任务:给定输入 Token 的前半部分 x1:sx_{1:s}x1:s,由编码器生成 Chunk Embedding,辅助解码器预测接下来的 Token xs+1:s+ox_{s+1:s+o}xs+1:s+o。
通过这种方式,解码器逐渐学会利用压缩表示来完成预测,形成对 Chunk Embedding 的依赖关系。这一步训练被称为 持续预训练(CPT),是连接编码器和解码器的桥梁。
3.2 重建任务:减少信息损失
仅仅通过下段预测进行对齐仍然不足,因为 Chunk Embedding 本身会丢失部分细节。为此,作者在 CPT 前额外引入了一个 重建任务(Reconstruction Task):
- 输入:原始上下文 Token 块 x1:sx_{1:s}x1:s
- 编码器:压缩为向量表示
- 解码器:尝试从压缩向量重建原始 Token 序列
在该任务中,解码器参数被冻结,只训练编码器和投影层。这相当于让编码器学会"尽可能无损地压缩",而投影层学会"把向量翻译回 Token 空间"。经过这一阶段,编码器与投影层能生成较为保真的压缩表示,解码器也能正确解读,从而为后续 CPT 奠定基础。
3.3 课程学习:缓解训练难度
当块大小 kkk 增大时,压缩任务变得极其困难,因为需要用一个定长向量表示 VkV^kVk 种 Token 组合(VVV 是词表大小)。直接训练模型去重建大块信息容易陷入困境。为解决这个优化难题,REFRAG 引入 课程学习策略:
- 从 单块重建 开始(例如只压缩 x1:kx_{1:k}x1:k 并重建它)。
- 随着训练进行,逐步增加块数(重建 2k,3k,...2k, 3k, ...2k,3k,... 的序列)。
- 在数据采样上,先以简单任务为主,逐步增加复杂任务的比例。
这种渐进式训练让模型逐步掌握压缩表示的规律,而不会在一开始就陷入高维空间的难题。
3.4 选择性压缩:强化学习策略
尽管压缩能带来效率提升,但并非所有上下文块都适合压缩。例如,一个包含关键定义或数值的段落,如果被过度压缩,可能严重影响模型输出的正确性。因此,REFRAG 引入了一个 强化学习(RL)策略网络,用来在推理时动态决定:
- 哪些块保留原始 Token(高保真但开销大);
- 哪些块替换为 Chunk Embedding(低开销但近似)。
训练方式如下:
- 奖励信号:使用预测困惑度(Perplexity)作为负奖励,即如果某块被压缩后困惑度急剧上升,说明信息损失过大,应保留原文。
- 策略机制:RL 策略在序列层面逐步做决策,以保证解码器的自回归特性不被破坏。
- 输出形式:生成一个压缩掩码(mask),指导哪些块用向量替代,哪些保留 Token。
与启发式规则(如"压缩低困惑度块")相比,RL 策略在不同任务和不同上下文规模下都能取得更优的平衡,证明了其灵活性和鲁棒性。
3.5 微调阶段(SFT)
完成 CPT 和 RL 策略学习后,REFRAG 还需要进一步在具体下游任务(如问答、对话、摘要)上进行 监督微调(SFT)。这一阶段的目标是让模型在实际应用中学会如何最优地结合压缩块与原始块,从而兼顾速度和准确性。
4. 实验
4.1 实验设置与基线
作者主要在 LLaMA-2-7B 模型上进行实验,并将其与几种典型的长上下文优化方法作对比,包括:
- LLaMA-Full Context:原始 LLaMA 模型,完整上下文输入。
- LLaMA-32K:扩展上下文窗口到 32K Token 的版本。
- LLaMA-No Context:不输入上下文,只依赖提示。
- LLaMA256:只保留最近 256 Token 上下文。
- REPLUG:优化检索器的方法。
- CEPE:基于 KV Cache 的压缩扩展方法。
- REFRAG8 / REFRAG16 / REFRAG32:分别对应压缩率为 8、16、32 的 REFRAG 模型。
训练数据采用 SlimPajama 子集 (包括 Books、ArXiv 等文档),用于持续预训练;验证与测试数据包括 PG19 (长篇小说)、ProofPile(数学推理)等,用于检验长文本理解和生成能力。
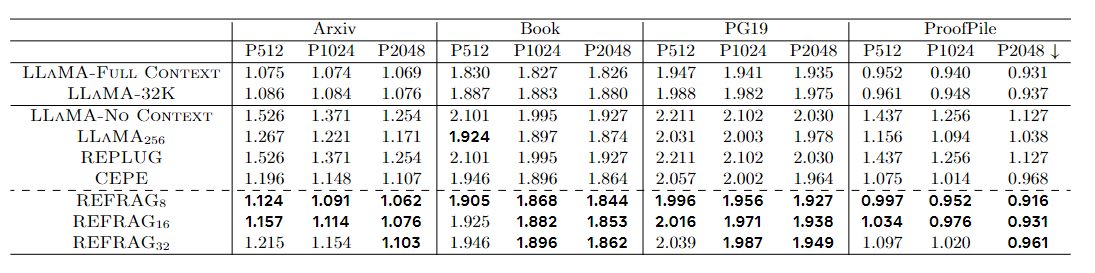
这张表的评价指标是困惑度(Perplexity),是衡量语言模型预测下一个 token 的不确定性:
- PPL 越小,说明模型越"不困惑",模型能更准确地预测下一个 token,说明语言理解/生成能力更强。
- PPL 越大,说明模型越"困惑",模型给正确词分配的概率很低,相当于"没猜对",性能差。
4.2 推理效率与加速效果
REFRAG 的最大亮点在于显著降低了 首 Token 延迟(TTFT)。
- 在 压缩率 32 的设定下,REFRAG 在 LLaMA-2-7B 上实现了 30.85× 的 TTFT 加速,吞吐率也提升了数量级。
- 相比之下,CEPE 的加速倍数仅为 3.75×,说明 REFRAG 在利用结构性稀疏性方面更高效。
- 更重要的是,这种大幅提速并未导致困惑度显著上升,说明压缩表示并未破坏模型的语义理解能力。
此外,REFRAG 的推理开销主要集中在预填充阶段,一旦完成压缩处理,后续 Token 的生成速度与原始 LLaMA 基本一致,这保证了系统在实际应用中的低延迟体验。
4.3 消融实验
作者进一步进行了消融实验,以验证各个组件的贡献:
- 无重建任务:困惑度显著上升,说明重建训练对于压缩表示的保真性至关重要。
- 无课程学习:模型难以收敛,训练过程不稳定。
- 无强化学习策略:准确率下降,说明启发式压缩无法适应不同任务和上下文复杂度。
总结
本文提出方法优势在于它是非侵入式的,即没有对下游的语言模型进行改造,理论可适配现有的语言模型,
然而,这项工作实际上只在7B参数级规模的模型上进行实验,更大参数量的语言模型的效果未可知。
并且,此方法需要训练过程是比较多的,按照文章给出的实验环境,在8个节点上进行训练(每个节点8张H100),总共64张H100,也只有meta这样的实验室有这种实验资源。
最后,本文暂未开源,一些方法细节尚未可知。
总之,整体是一个不错的想法,在提升模型响应速度和提升上下文窗口长度上,是一个新的思路。
参考
1 Meta超级智能实验室首篇论文:重新定义RAG: https://www.qbitai.com/2025/09/329342.html