本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发及AI算法学习视频及资料,尽在聚客AI学院
多模态学习模拟人类认知过程------例如描述电影时,我们不会孤立地评价画面或音乐,而是综合视觉、听觉和剧情信息形成整体感受。但是,这要求模型从单模态处理(如仅分析图像或文本)进化到多模态协同,能同时理解和关联图像、文字、声音等异构数据。今天我将深入解析要实现多模态学习的两大核心难题:多模态对齐和多模态融合,如果对你有所帮助,记得告诉身边有需要的朋友。
一、多模态对齐:建立跨模态的对应关系
多模态对齐的核心是让AI识别不同模态间的语义对应,例如图像中的一只橙色猫与文本描述"一只可爱的橘猫在晒太阳"建立等价关系。这涉及将图像(像素矩阵)、文字(符号序列)和声音(波形)等异构数据映射到统一理解层面。
难点在于模态表示的异构性:图像以像素值(如255, 128, 64表示橙色)编码,文字以离散符号(如"橘猫")呈现,声音则依赖频率振幅。这种差异类似中英文交流的障碍,需寻找共同"语言"来实现匹配。
核心方法包括对比学习和共享表征空间:
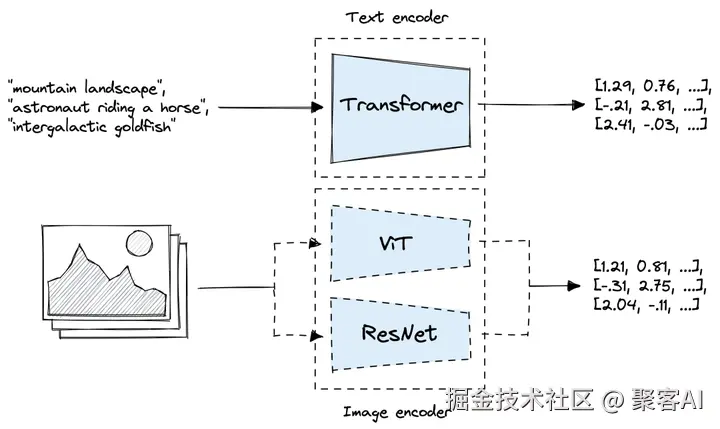
- 对比学习(如CLIP模型):通过大规模配对数据训练,模型学习正负样本的相似度。例如,猫图片与"一只猫"文本配对时提升相似度,而与"一条狗"文本配对时降低相似度。经过数千万次迭代,AI学会将不同模态"翻译"为内部一致表示。
- 共享表征空间:将原始模态数据投影到统一向量空间。图像特征(如像素1, 像素2, ...)和文本特征(如词1, 词2, ...)被映射为数字向量(如0.2, 0.8, ...),确保相关内容(如图片猫和文字"猫")在空间中邻近,无关内容远离。
ps:由于文章篇幅有限,这里再补充一个知识点,关于CLIP 模型的训练,我之前有整理过一个详细的技术文档,感兴趣的粉丝自行领取:《CLIP 模型训练与实战》 (wcnolv4zdyoz.feishu.cn/wiki/O77Wwr...)
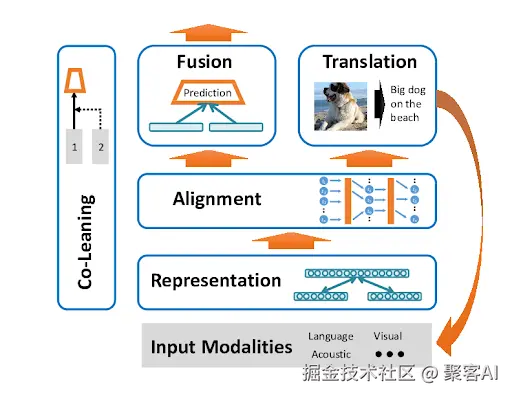
二、多模态融合:整合信息的策略与技术
多模态对齐解决"对应关系"后,融合则关注"如何结合"。这类似于烹饪:对齐提供食材(模态数据),融合决定搭配方式(整合策略)。其目标是利用模态互补性,生成稳定全面的多模态表征。融合策略分为三类,各具优劣。
三种融合策略及其应用:
- 早期融合(直接混合):在特征提取阶段直接拼接不同模态数据。例如,图像特征1, 2, 3, 4与文本特征5, 6, 7, 8拼接为1, 2, 3, 4, 5, 6, 7, 8。优点在于捕捉底层交互,但单模态噪声会污染整体。应用案例:视频理解系统,将视频帧序列与对应音频窗口特征拼接,学习视听觉同步以支持视频分类或情感分析。
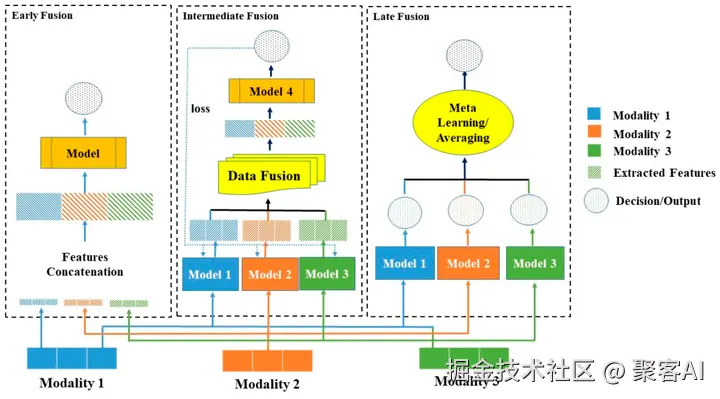
- 晚期融合(独立处理再结合):各模态独立处理,结果在决策层综合。例如,图像分析输出"这是一只猫",文本分析输出"描述了宠物",最终融合为"图片中的猫与文字一致"。优点是对噪声鲁棒,但可能忽略模态间深层关联。应用案例:医疗诊断中,影像AI和文本AI独立分析后综合;金融风控中,图像识别与文本分析并行评估风险;内容审核中,视觉和文本审核独立判定合规性。
- 交叉融合(动态交互):模态间实时交互,使用注意力机制互相查询。例如,图像处理时询问文字"有描述动物的词吗?",文字响应"猫"后更新图像理解。优点在于捕捉复杂关系,效果最优,但计算资源密集。实现机制依赖交叉注意力网络:文本输入经BERT编码后与图像特征(来自CNN/ViT)在注意力层交互,彼此增强。
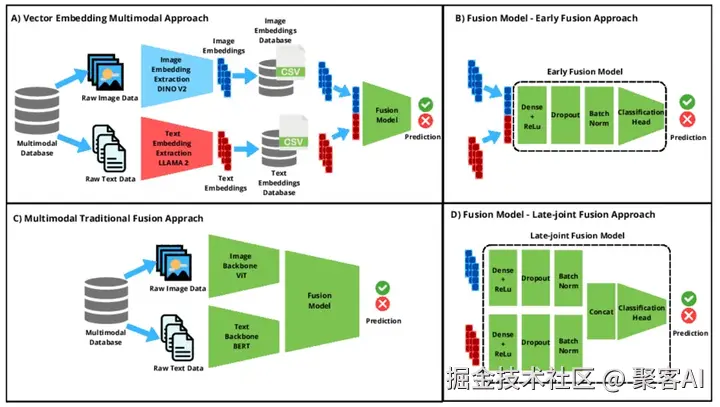
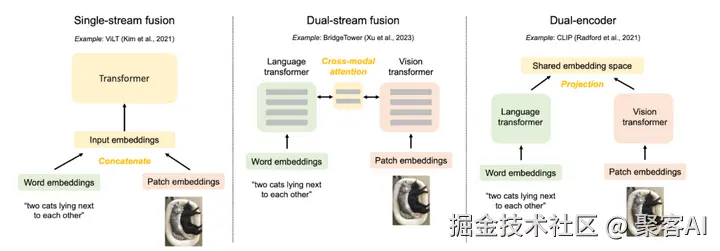
三、统一架构:Transformer的多模态优势
Transformer架构为多模态学习提供理想框架,通过统一处理机制解决对齐与融合问题。其核心优势在于:
- 统一Token表示:所有模态数据被转换为"token"序列。文字"我喜欢这只猫"token化为我喜欢这只猫;图像切分为小块,如图块1图块2...图块196。输入序列可拼接为图块1, 图块2, ..., 图块196, 我, 喜欢, 这只, 猫,实现模态统一编码。
- 自注意力机制实现动态交互:每个token能"关注"其他模态token。例如,处理"猫"文字时,注意力机制聚焦图像中猫的头部和身体图块,忽略无关背景,实现跨模态语义融合。
- 位置编码处理异构顺序:文字依赖时序(如"我→喜欢→猫"),图像依赖空间位置(如左上→右下),音频依赖时间序列。位置编码统一处理这些排列,确保结构一致性。
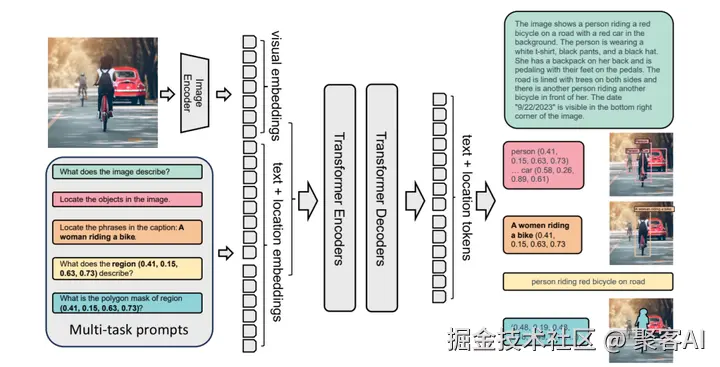
以GPT-4V为例的工作流程:
- 统一Token化:输入图像被分割为patch序列(如patch1, patch2, ..., patch196),文本被token化为这张, 图片, 里, 有, 什么, ?。
- 序列拼接:输入序列组合为patch1, patch2, ..., patch196, 这张, 图片, 里, 有, 什么, ?。
- Transformer处理:多层自注意力机制中,图像patch与文字token交互(如patch"看到"文字"图片"和"有什么"),逐步建立跨模态关联。
- 生成响应:基于融合理解,模型输出文字回答,如"图片中有一只猫"。

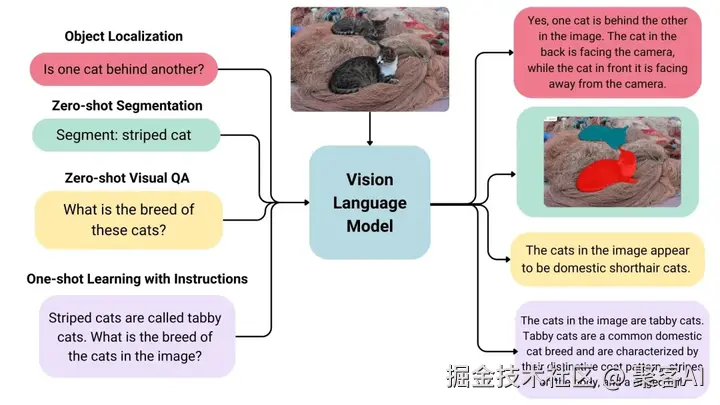
作者总结
多模态学习的核心是让AI具备"多感官协同"能力,其技术演进从简单对齐(如CLIP的对比学习)向深度融合(如交叉注意力)转变。Transformer的统一建模框架(统一Token化、自注意力、位置编码)成为主流,推动GPT-4V等模型突破。未来趋势强调语义级理解,从特征拼接转向动态交互,为视觉-语言模型(VLM)开辟广阔应用场景。这一领域持续进化,要求工程师不断深化模型架构优化,以实现更自然的AI多模态智能。