引入
近年来,随着端到端自动驾驶技术的快速发展,吸引了来自工业界和学术界的广泛关注。此外,随着人类专家驾驶数据的逐渐积累,从大规模数据中学习类人的驾驶策略具有巨大的发展潜力。
尽管端到端自动驾驶技术取得了不少令人满意的成绩,但在处理长尾驾驶场景时性能会显著下降。目前,已经有一些方法试图利用视觉-语言模型中嵌入的广泛世界知识来缓解这一问题,即视觉-语言-动作模型。该模型以视频数据作为输入,直接输出驾驶轨迹和动作,如图1所示。
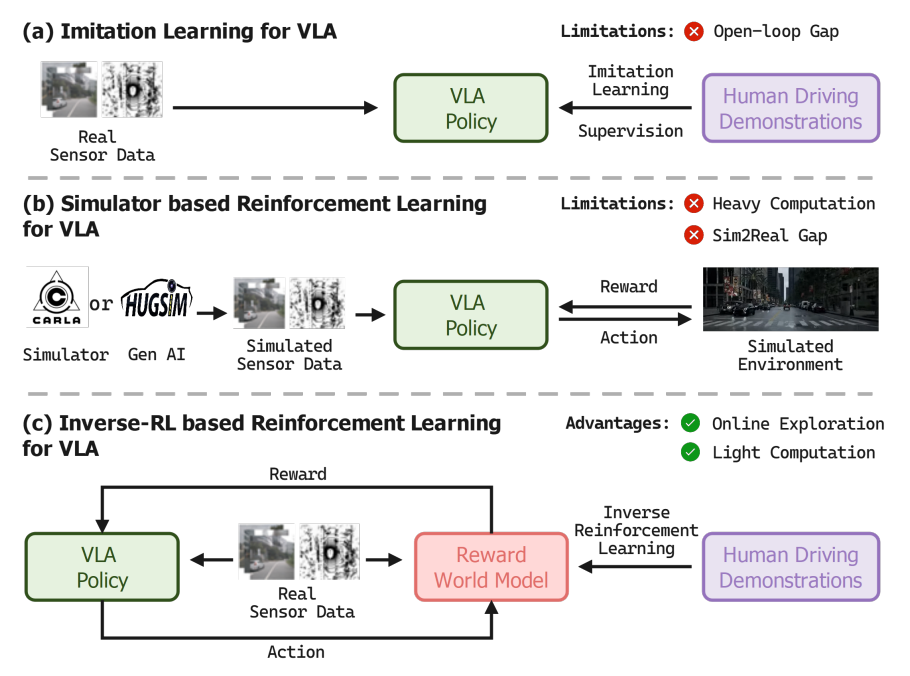
图1|VLA自动驾驶框架的不同范式
图1(a)采用了模仿学习的方法实现了出色的性能,但由于开环框架内的模仿学习倾向于复制数据集中记录的行为,导致模型的全部潜力仍未得到充分挖掘。
图1(b)让模型在模拟环境中进行自主的探索,模拟在现实世界中观察到的体验式学习过程,但仍存在现实和仿真之间的领域差异以及巨大的计算开销。
针对上述提到的相关问题和挑战,本文提出了一种基于逆向强化学习的新型闭环强化学习框架IRL-VLA。本文提出的方法在NAVSIM v2端到端自动驾驶基准测试中取得了SOTA的性能。
本文的主要贡献如下:
● 本文提出了IRL-VLA,一个专为VLA模型设计的基于模拟器反馈进行强化学习的框架。为了取代计算成本高昂的基于模拟器的奖励计算,本文引入了一种基于逆向强化学习的高效奖励世界模型,从而实现可扩展且有效的奖励估计
● 本文提出了一种新颖的VLA模型,该模型在模仿学习和强化学习环境中均表现出色,能够在不同的训练范式中实现最佳性能
● 该框架在CVPR2025挑战赛的NAVSIM v2端到端驾驶基准测试中取得了优异的表现。这些结果证明了本文方法的有效性和通用性

本文提出的IRL-VLA算法模型的整体网络架构如图2所示。
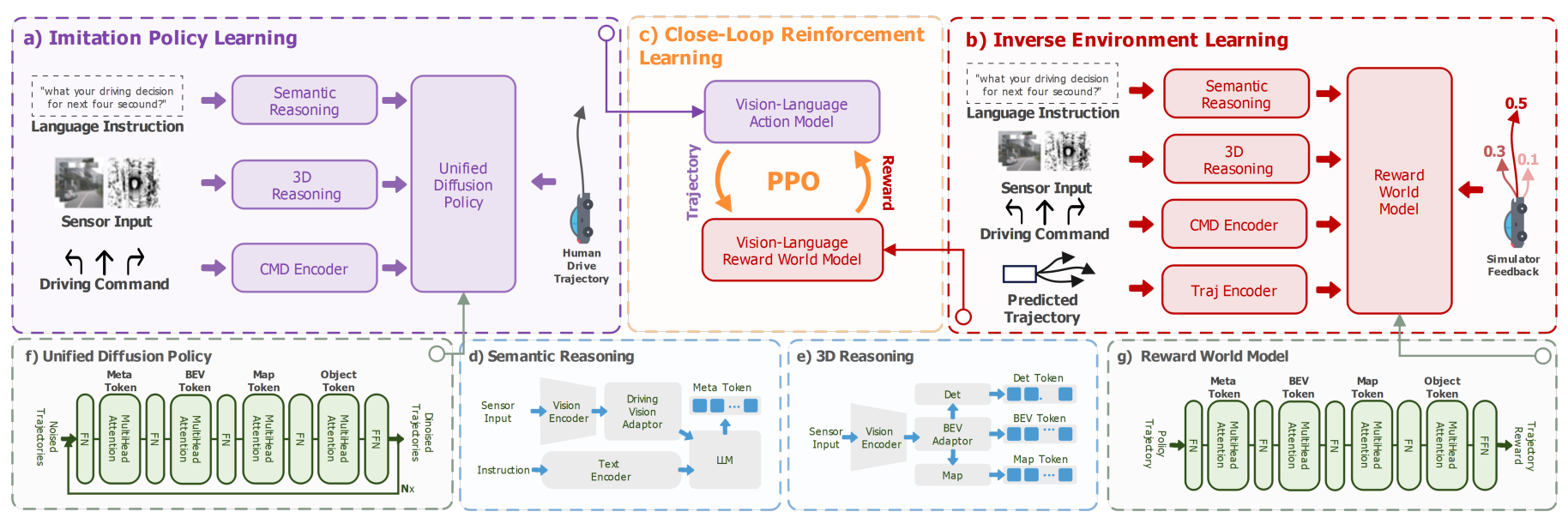
图2|IRL-VLA算法模型框架图
模仿策略学习
受具身智能领域的启发,本文提出了一种高效的自动驾驶VLA模型,该模型包含三个不同的模块,分别是语义推理模块、3D推理模块以及统一扩散规划器
● 语义推理:本文提出了VLM命令引导模块。该模块基于Senna-VLM框架构建,利用多图像编码策略和多视图提示机制,实现高效、全面的场景理解
● 3D推理:本文使用BEV视觉编码器和适配器将多视角图像编码为BEV空间中的特征图。然后,利用一组检测标记和地图标记从BEV特征空间中学习矢量化的地图元素和代理运动信息
● 统一扩散规划器:为了生成多样化且信息丰富的未来轨迹分布,本文采用基于扩散的方法,处理带有高斯噪声的锚点提议轨迹
逆环境学习
● 奖励数据收集:要开发有效的奖励世界模型,全面的数据集至关重要。为了增强得分和轨迹的多样性并确保模型的泛化能力,本文采用了三种策略。首先,本文记录扩散过程每个时间戳的轨迹及对应的EPDM得分。然后,采用K均值聚类从人类驾驶数据中采集多种轨迹模式。最后,在NAVSIM数据集的每个场景的模拟过程中应用多个自车的位姿,生成多样化的样本
● 奖励世界模型:本文提出了一个奖励世界模型,作为传统模拟器的轻量级、数据驱动的替代方案,它能够通过逆向强化学习,对自动驾驶系统进行闭环评估,并收集下游驾驶统计数据,例如碰撞率、交通规则合规性和驾驶舒适度
● 奖励世界模型优化:训练奖励世界模型的目标是最小化预测指标得分与真实指标得分之间的差距。损失函数的计算如下:
带有奖励世界模型的强化学习
本文在奖励世界模型中采用了PPO策略,整个策略优化过程包括从VLA策略中迭代采样轨迹,并更新策略参数以最大化预期累计奖励。整个过程如图3所示。

图3|在RWM中使用PPO进行策略优化
本文的扩散策略从高斯噪声开始,逐步去噪,从而产生一系列的动作。基于这一规则,本文生成一组轨迹,并记录他们的完整扩散过程。对于单个轨迹而言,扩散过程定义如下:
RWM使用多标准评分系统评估每条轨迹,将舒适度指标与安全性指标相结合。这些指标被汇总为基于EPDMS的得分。在后续的扩散过程中,每个条件转换都有高斯策略进行建模
因此,该扩散策略下整个轨迹的联合对数似然可以表示为
对于策略优化,本文采用基于PPO算法的强化学习。强化学习损失公式如下

IRL-VLA模型采用V2-99主干网络,并且处理分辨率大小为256×704的多视角图像。在模仿学习阶段,采用AdamW优化器训练100个epoch。奖励世界模型采用逆强化学习进行训练,并且使用交叉熵损失函数对EPDMS中的指标进行训练。对于强化学习阶段,本文采用了PPO优化策略。
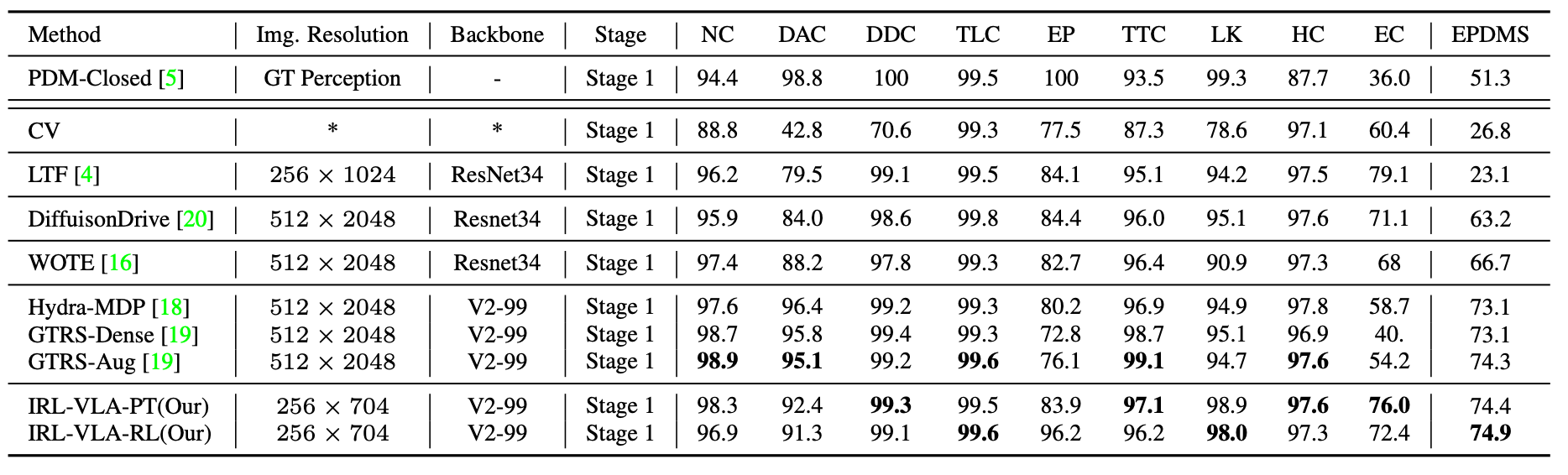
图4|不同算法模型在Navhard测试基准上的实验结果
图4展示了IRL-VLA与Navhard基准上的其他算法模型的性能比较结果。通过实验结果可以看出预训练模型在多个指标上均取得了具有竞争力的结果,进一步表明了本文提出的VLA架构在不依赖明确评分机制的情况下,能够同时优化安全性和舒适性。
此外,本文还进行了两项消融实验研究,用于评估所提出的技术和实施细节如何影响 IRL-VLA的表现性能。图5展示了本文提出的IRL-VLA分层推理扩散VLA代理的消融研究。

图5|分层推理扩散VLA代理的消融实验结果
通过实验结果可以看出,当仅使用3D推理的人类驾驶演示数据进行训练时,模型实现了70.0的EPDMS。将语义推理与高级驾驶命令查询相结合后,EPDMS提高了1.4。引入扩散规划器进行连续轨迹预测,EPDMS达到了74.4。实验结果证明了分层推理扩散VLA方案在实现更安全、更舒适的驾驶行为方面具有强大的性能。

本文提出了一种基于奖励世界模型的闭环强化学习框架IRL-VLA,适用于端到端自动驾驶中的视觉-语言-动作模型。目前,IRL-VLA是首个结合传感器输入且不依赖模拟器的闭环VLA方法,并且在NAVSIM v2基准测试中取得了SOTA的表现性能。