Kafka
- 一、下载安装
-
- 1.1、目录结构
- 1.2、核心目录详解
- 1.3、服务启动
-
- [1.3.1、先启动 ZooKeeper(后台启动)](#1.3.1、先启动 ZooKeeper(后台启动))
- [1.3.2、再启动 Kafka Broker(后台启动,适配 3.9.1 版本)](#1.3.2、再启动 Kafka Broker(后台启动,适配 3.9.1 版本))
- 二、配置掌握
-
- [2.1、Kafka `server.properties` 配置详解](#2.1、Kafka
server.properties配置详解) -
- 2.1.1、基础身份配置
- 2.1.2、网络通信配置
- 2.1.3、存储配置
- 2.1.4、副本与可用性配置
- [2.1.5、ZooKeeper 配置](#2.1.5、ZooKeeper 配置)
- 2.1.6、高级性能优化配置
- 2.1.7、安全配置(可选)
- 2.1.8、配置优先级与生效方式
- 2.1.9、生产环境-配置示例
- [2.2、Kafka `consumer.properties` 配置详解](#2.2、Kafka
consumer.properties配置详解) - [2.3、Kafka `producer.properties` 配置详解](#2.3、Kafka
producer.properties配置详解)
- [2.1、Kafka `server.properties` 配置详解](#2.1、Kafka
- 三、鉴权配置
一、下载安装
下载最新3.9.1版本,目前这个版本是没有漏洞的版本,尽量不要用之前的版本。
下载链接: https://kafka.apache.org/downloads
1.1、目录结构
解压 Kafka 安装包后,根目录包含以下关键子目录和文件:
shell
kafka_2.13-3.6.1/
├── bin/ # 可执行脚本(核心工具)
├── config/ # 配置文件(Broker、消费者、生产者等)
├── libs/ # 依赖库(Kafka 核心 jar 包)
├── logs/ # 默认日志目录(Broker 运行日志)
├── site-docs/ # 官方文档(HTML 格式)
├── LICENSE # 许可证文件
├── NOTICE # 版权声明
└── README.md # 快速启动说明1.2、核心目录详解
1.2.1、bin/:执行脚本目录
存放 Kafka 所有核心工具的脚本(包含 Linux 下的 .sh 和 Windows 下的 .bat),按功能分为以下几类:
| 脚本类型 | 关键脚本 | 功能说明 |
|---|---|---|
| Broker 管理 | kafka-server-start.sh |
启动 Kafka Broker(需指定配置文件,如 config/server.properties) |
kafka-server-stop.sh |
停止 Kafka Broker | |
| Topic 管理 | kafka-topics.sh |
创建、删除、查看 Topic(如 --create --topic test --partitions 3) |
| 消费组管理 | kafka-consumer-groups.sh |
查看消费组偏移量、重置 Offset(如 --describe --group my-group) |
| 生产者工具 | kafka-console-producer.sh |
命令行生产者(测试用,发送消息到指定 Topic) |
| 消费者工具 | kafka-console-consumer.sh |
命令行消费者(测试用,从指定 Topic 消费消息) |
| 集群管理 | kafka-broker-api-versions.sh |
查看 Broker 支持的 API 版本 |
kafka-metadata-shell.sh |
查看集群元数据(如 Broker 列表、Topic 分区信息) | |
| KRaft 模式 | kafka-storage.sh |
KRaft 模式下初始化存储(替代 ZooKeeper 时使用) |
kafka-server-start.sh |
启动 KRaft 控制器(需指定 controller.properties) |
示例:启动 Broker
bash
bin/kafka-server-start.sh config/server.properties1.2.2、config/:配置文件目录
存放 Kafka 所有核心配置文件,按组件分为:
| 配置文件 | 关联组件 | 核心作用 |
|---|---|---|
server.properties |
Kafka Broker | Broker 核心配置(端口、存储路径、副本策略等,必配) |
consumer.properties |
消费者 | 命令行消费者默认配置(消费组 ID、集群地址等) |
producer.properties |
生产者 | 命令行生产者默认配置(ACK 策略、压缩方式等) |
zookeeper.properties |
内置 ZooKeeper | Kafka 自带的 ZooKeeper 配置(单节点测试用,生产环境需独立 ZooKeeper 集群) |
controller.properties |
KRaft 控制器 | KRaft 模式下的控制器配置(替代 ZooKeeper 时使用) |
connect-*.properties |
连接器(Connect) | 用于数据导入导出(如 connect-standalone.properties 单机模式配置) |
注意 :生产环境需根据集群规模修改 server.properties,并为每个 Broker 分配独立配置文件(如 server-0.properties、server-1.properties)。
1.2.3、libs/:依赖库目录
存放 Kafka 运行所需的所有 jar 包,包括:
- 核心依赖:
kafka_2.13-3.6.1.jar(Kafka 核心逻辑)、kafka-clients-3.6.1.jar(客户端 API); - 第三方依赖:ZooKeeper 客户端、JSON 解析、压缩算法(Snappy、LZ4)等;
- 日志依赖:
log4j相关 jar 包(控制日志输出)。
说明:无需手动修改,Kafka 启动时会自动加载这些依赖。
1.2.4、logs/:运行日志目录
默认存储 Kafka Broker 和内置 ZooKeeper 的运行日志,包含:
server.log:Broker 主日志(记录启动、错误、警告等信息,排查问题的核心依据);controller.log:KRaft 模式下控制器的日志;zookeeper.out:内置 ZooKeeper 的输出日志(仅单节点测试用)。
建议 :生产环境通过 log4j.properties(在 config/ 目录)修改日志路径和滚动策略,避免日志占满磁盘。
1.2.5、site-docs/:文档目录
包含 Kafka 官方 HTML 文档,涵盖:
- 快速入门指南;
- 配置参数说明;
- 客户端 API 文档;
- 架构设计说明。
用途:本地查阅 Kafka 功能和配置细节(无需联网)。
1.2.6、数据存储目录(非安装目录,需手动配置)
Kafka 的消息数据(日志)默认存储在 tmp/kafka-logs,但生产环境需通过 server.properties 的 log.dirs 配置到独立磁盘路径(如 /data/kafka-logs)。该目录结构如下:
/data/kafka-logs/
├── test-topic-0/ # Topic 名称+分区号(如 test-topic 的 0 号分区)
│ ├── 00000000000000000000.index # 索引文件(记录消息偏移量与物理位置映射)
│ ├── 00000000000000000000.log # 消息数据文件(实际存储消息内容)
│ ├── 00000000000000000000.timeindex # 时间索引(按时间查找消息)
│ └── leader-epoch-checkpoint # Leader 纪元信息(用于副本同步)
├── test-topic-1/ # 其他分区(结构同上)
└── __consumer_offsets-2/ # 内部 Topic(存储消费组的 Offset 信息)说明:
- 每个 Topic 的每个分区对应一个子目录;
- 消息按"日志段(Segment)"存储(
.log文件),满log.segment.bytes后自动滚动; - 索引文件(
.index)加速消息查找,避免全量扫描.log文件。
1.3、服务启动
以下是针对 Kafka 3.9.1 + ZooKeeper 模式 的完整后台启动流程(含 ZooKeeper 启动步骤),确保流程正确且适配你的版本:
1.3.1、先启动 ZooKeeper(后台启动)
Kafka 安装包中 自带了 ZooKeeper 组件 (路径在 kafka_2.13-3.9.1/bin/zookeeper-server-start.sh),无需额外下载独立 ZooKeeper,直接使用自带脚本启动即可。
- 后台启动 ZooKeeper 命令
bash
# 后台启动 ZooKeeper,日志输出到指定文件(替换为你的 Kafka 实际路径)
nohup /path/to/kafka_2.13-3.9.1/bin/zookeeper-server-start.sh /path/to/kafka_2.13-3.9.1/config/zookeeper.properties > /var/log/kafka/zookeeper.log 2>&1 &命令说明:
zookeeper-server-start.sh:Kafka 自带的 ZooKeeper 启动脚本;zookeeper.properties:ZooKeeper 默认配置文件(Kafka 安装包config目录下自带),默认端口2181;> /var/log/kafka/zookeeper.log:将 ZooKeeper 日志单独输出(避免与 Kafka 日志混淆,便于排查);- 末尾
&确保进程在后台运行。
- 验证 ZooKeeper 启动成功
bash
# 方式1:查看进程(存在 "QuorumPeerMain" 表示启动成功)
ps -ef | grep zookeeper | grep -v grep
# 方式2:查看日志(无报错且出现 "Started" 表示正常)
tail -f /var/log/kafka/zookeeper.log
# 日志中出现类似 "Started QuorumPeerMain" 或 "Binding to port 0.0.0.0/0.0.0.0:2181" 即成功1.3.2、再启动 Kafka Broker(后台启动,适配 3.9.1 版本)
ZooKeeper 启动成功后,再启动 Kafka,确保 Kafka 能连接到 ZooKeeper 注册元数据。
- 确认 Kafka 配置(关键:关联 ZooKeeper)
先检查 config/server.properties 中 ZooKeeper 连接配置是否正确(3.9.1 版本默认仍包含此配置):
properties
# 打开 server.properties 文件
vim /path/to/kafka_2.13-3.9.1/config/server.properties
# 确认 ZooKeeper 连接地址(默认值如下,无需修改,除非调整过 ZooKeeper 端口)
zookeeper.connect=localhost:2181
# 可选:ZooKeeper 会话超时时间(默认 18000ms,无需修改)
zookeeper.connection.timeout.ms=18000
# Broker 监听的网络地址列表,下面这两个没有配置,只能本机连接
listeners=PLAINTEXT://:9092
# 与 listeners 相同 对外暴露的监听地址(客户端实际连接的地址)
advertised.listeners=PLAINTEXT://192.168.223.232:9092- 后台启动 Kafka Broker
bash
# 后台启动 Kafka,日志输出到指定文件(替换为你的实际路径)
nohup /path/to/kafka_2.13-3.9.1/bin/kafka-server-start.sh /path/to/kafka_2.13-3.9.1/config/server.properties > /var/log/kafka/kafka-server.log 2>&1 &- 验证 Kafka 启动成功
bash
# 方式1:查看进程(存在 "kafka.Kafka" 表示启动成功)
ps -ef | grep kafka | grep -v grep
# 方式2:查看日志(关键看是否连接上 ZooKeeper 并完成启动)
tail -f /var/log/kafka/kafka-server.log
# 日志中出现类似 "[KafkaServer id=0] started (kafka.server.KafkaServer)" 即成功
# 同时会有 "Connected to ZooKeeper" 相关日志,说明与 ZooKeeper 连接正常二、配置掌握
2.1、Kafka server.properties 配置详解
server.properties 是 Kafka Broker(服务器节点)的核心配置文件,用于定义 Broker 的身份、网络通信、存储、日志、副本机制、安全等关键行为。每个 Broker 必须有独立的配置文件(若单机部署多 Broker,需为每个实例分配不同端口和存储路径)。以下按 功能模块 拆解核心配置,结合场景说明其作用与默认值(基于 Kafka 3.x 版本)。
2.1.1、基础身份配置
定义 Broker 在 Kafka 集群中的唯一标识和集群关联信息,是 Broker 启动的基础。
| 配置项 | 默认值 | 功能说明 | 注意事项 |
|---|---|---|---|
broker.id |
0 |
Broker 的 唯一身份ID (整数),集群内所有 Broker 的 broker.id 必须不同。 |
1. 若配置 broker.id.generation.enable=true,可自动生成 ID(无需手动指定); 2. 手动配置时建议按节点顺序编号(如 0、1、2),便于运维。 |
broker.id.generation.enable |
true |
是否允许 Broker 自动生成 broker.id(基于 log.dirs 路径的哈希值)。 |
仅在未手动指定 broker.id 时生效,适合动态扩容场景(避免 ID 冲突)。 |
cluster.id |
无(需手动指定) | Kafka 集群的唯一标识,用于区分不同集群(如测试集群、生产集群)。 | 同一集群内所有 Broker 必须配置相同的 cluster.id,否则会被视为独立集群。 |
2.1.2、网络通信配置
控制 Broker 的网络监听、连接限制、数据传输参数,直接影响客户端(Producer/Consumer)与 Broker 的交互效率。
- 监听地址与端口
| 配置项 | 默认值 | 功能说明 | 场景示例 |
|---|---|---|---|
listeners |
无(必须配置) | Broker 监听的网络地址列表,格式为 协议://主机:端口,支持多协议(如 PLAINTEXT、SSL)。 |
- 单机测试:PLAINTEXT://localhost:9092(仅本地可访问); - 集群部署:PLAINTEXT://0.0.0.0:9092(允许所有主机访问); - 多协议:PLAINTEXT://0.0.0.0:9092,SSL://0.0.0.0:9093(同时支持明文和加密)。 |
advertised.listeners |
与 listeners 相同 |
对外暴露的监听地址(客户端实际连接的地址),适用于 Broker 部署在 NAT 或容器环境(如 Docker、K8s)。 | 若 Broker 内网地址为 192.168.1.100:9092,外网地址为 203.0.113.10:8080,则配置: advertised.listeners=PLAINTEXT://203.0.113.10:8080。 |
listener.security.protocol.map |
PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL |
映射 listeners 中的协议名称到实际安全协议,默认无需修改。 |
仅在自定义协议名称时调整(如简化协议标识)。 |
port |
9092 |
若 listeners 未指定端口,默认使用此端口(建议优先通过 listeners 明确配置)。 |
低优先级配置,仅当 listeners 未定义时生效。 |
- 网络连接限制
| 配置项 | 默认值 | 功能说明 | 优化建议 |
|---|---|---|---|
num.network.threads |
3 |
处理网络请求的线程数(接收客户端连接、读取请求数据)。 | 高并发场景(如每秒万级请求)可增至 5-10,避免线程瓶颈。 |
num.io.threads |
8 |
处理 I/O 操作的线程数(写入磁盘、发送响应给客户端)。 | 与磁盘性能匹配,若使用 SSD 可增至 12-16,机械硬盘建议不超过 10。 |
socket.send.buffer.bytes |
102400(100KB) |
socket 发送缓冲区大小,用于批量传输数据。 | 大消息场景(如单条消息 10KB+)可增至 262144(256KB),减少网络往返。 |
socket.receive.buffer.bytes |
102400(100KB) |
socket 接收缓冲区大小,用于缓存客户端请求数据。 | 与 socket.send.buffer.bytes 配合调整,避免缓冲区溢出。 |
socket.request.max.bytes |
104857600(100MB) |
单个请求的最大字节数(防止超大请求压垮 Broker)。 | 若业务需传输超大消息(如 200MB),需同步调整 Producer 的 生产者单个请求最大值max.request.size=10485760 (10MB 10×1024×1024)和 Consumer 的消费者单次拉取最大值fetch.max.bytes=10485760 (10MB 10×1024×1024)。 |
2.1.3、存储配置
定义 Kafka 日志(消息数据)的存储路径、分区大小、清理策略,直接影响数据可靠性和磁盘利用率。
- 日志存储路径
| 配置项 | 默认值 | 功能说明 | 注意事项 |
|---|---|---|---|
log.dirs |
/tmp/kafka-logs |
日志文件的存储目录(可配置多个路径,用逗号分隔)。 | 1. 生产环境必须修改 (/tmp 目录重启后会清空); 2. 多目录配置时,Kafka 会轮询分配分区(负载均衡磁盘压力); 3. 建议使用独立磁盘(如 /data/kafka-logs-1,/data/kafka-logs-2),避免与系统盘混用。 |
log.dir |
无 | 单日志目录配置(已过时,优先使用 log.dirs)。 |
若同时配置 log.dirs 和 log.dir,log.dirs 优先级更高。 |
- 日志保留与清理
Kafka 消息默认不会永久存储,需通过配置控制保留策略(按时间或大小),避免磁盘占满。
| 配置项 | 默认值 | 功能说明 | 场景建议 |
|---|---|---|---|
log.retention.hours |
168(7天) |
消息保留的 默认时间(超过此时间的消息会被清理)。 | - 实时业务(如监控数据):保留 24-48 小时; - 离线分析(如用户行为):保留 7-30 天。 |
log.retention.minutes |
无 | 消息保留时间(分钟级),优先级高于 log.retention.hours。 |
需更精细的保留控制时使用(如保留 30 分钟:log.retention.minutes=30)。 |
log.retention.ms |
无 | 消息保留时间(毫秒级),优先级最高(覆盖小时/分钟配置)。 | 毫秒级精度场景(如金融实时数据保留 5 分钟:log.retention.ms=300000)。 |
log.retention.bytes |
-1(无限制) |
单个分区的 最大保留大小(超过此大小会删除旧消息),优先级低于时间策略。 | 磁盘有限时配置(如单个分区保留 10GB:log.retention.bytes=10737418240),需结合分区数估算总磁盘占用。 |
log.segment.bytes |
1073741824(1GB) |
单个日志段(Segment)的最大大小(Kafka 按段存储日志,便于清理)。 | 1. 段越小,清理速度越快,但会生成更多小文件(影响性能); 2. 建议保持默认 1GB,或调整为 512MB(小消息场景)、2GB(大消息场景)。 |
log.segment.ms |
604800000(7天) |
日志段的 滚动时间 (即使未达到 log.segment.bytes,超过此时间也会生成新段)。 |
配合清理策略,避免单个段过大导致清理延迟(如配置 1 天:log.segment.ms=86400000)。 |
log.cleanup.policy |
delete |
日志清理策略: - delete:删除过期消息; - compact:按 Key 压缩(保留每个 Key 的最新消息,适用于更新型数据如用户画像)。 |
1. 普通消息队列用 delete; 2. 键值型数据(如变更日志)用 compact,需同时配置 log.cleaner.enable=true。 |
log.cleaner.enable |
true |
是否启用日志清理器(仅对 compact 策略生效)。 |
若使用 compact 策略,必须确保此配置为 true。 |
2.1.4、副本与可用性配置
Kafka 通过 副本机制 保证数据可靠性(多副本存储),以下配置控制副本的同步、选举和故障转移行为。
| 配置项 | 默认值 | 功能说明 | 关键原理 |
|---|---|---|---|
default.replication.factor |
1 |
新创建 Topic 时的 默认副本数 (建议生产环境设为 2-3)。 |
副本数越多,可靠性越高,但会增加磁盘占用和网络同步开销(推荐 3 副本:容忍 2 个节点故障)。 |
min.insync.replicas |
1 |
生产者发送消息时,必须同步成功的最小副本数 (与 Producer 的 acks 配合)。 |
1. 若 acks=-1(Producer 等待所有副本确认),且 min.insync.replicas=2,则至少 2 个副本同步成功才返回成功; 2. 生产环境建议设为 2(避免单副本故障导致数据丢失)。 |
replica.lag.time.max.ms |
30000(30秒) |
副本同步滞后的最大容忍时间:若从节点(Follower)超过此时间未与主节点(Leader)同步,会被标记为"下线"。 | 防止从节点长期滞后导致数据不一致,超时后 Leader 会剔除该从节点,不再向其同步数据。 |
replica.lag.max.messages |
-1(无限制) |
副本同步滞后的最大消息数(已过时,优先使用 replica.lag.time.max.ms)。 |
建议保持默认 -1,避免因消息量波动误判副本下线。 |
unclean.leader.election.enable |
false |
是否允许"非同步副本"(未跟上 Leader 的 Follower)成为新 Leader。 | 1. true:可用性优先(故障时快速选举 Leader,但可能丢失数据); 2. false:可靠性优先(仅允许同步副本成为 Leader,无数据丢失,但选举可能延迟); 3. 生产环境强烈建议设为 false。 |
num.replica.fetchers |
1 |
从节点(Follower)从 Leader 拉取消息的线程数。 | 多副本场景(如 3 副本)可增至 2-3,提升同步速度,避免副本滞后。 |
2.1.5、ZooKeeper 配置
Kafka 3.x 之前依赖 ZooKeeper 存储集群元数据(如 Broker 列表、Topic 分区信息),3.x 开始支持 KRaft 模式(无 ZooKeeper),但仍兼容 ZooKeeper 配置。
| 配置项 | 默认值 | 功能说明 | 注意事项 |
|---|---|---|---|
zookeeper.connect |
localhost:2181 |
ZooKeeper 集群地址,格式为 主机1:端口1,主机2:端口2,.../kafka(/kafka 为命名空间,避免与其他应用冲突)。 |
1. 若 ZooKeeper 集群有 3 个节点,配置:zk1:2181,zk2:2181,zk3:2181/kafka; 2. 若使用 KRaft 模式,需删除此配置,改用 process.roles 等 KRaft 相关配置。 |
zookeeper.connection.timeout.ms |
18000(18秒) |
与 ZooKeeper 建立连接的超时时间。 | 网络不稳定时可增至 30000(30秒),避免频繁断开连接。 |
2.1.6、高级性能优化配置
针对高并发、大流量场景,调整以下配置提升 Broker 吞吐量和稳定性。
| 配置项 | 默认值 | 功能说明 | 优化建议 |
|---|---|---|---|
log.flush.interval.messages |
-1(无限制) |
触发日志刷盘的 消息数量阈值(-1 表示由操作系统控制刷盘)。 | 不建议手动配置(依赖 OS 页缓存更高效),强制刷盘会降低吞吐量。 |
log.flush.interval.ms |
-1(无限制) |
触发日志刷盘的 时间阈值(-1 表示由操作系统控制)。 | 同上,保持默认即可(Kafka 依赖 OS 缓存和磁盘自身缓存保证性能)。 |
compression.type |
producer |
Broker 对消息的压缩方式: - producer:保留 Producer 发送的压缩格式; - gzip/snappy/lz4:强制重压缩(需权衡 CPU 与带宽)。 |
若 Producer 未压缩,可配置 snappy(CPU 开销小,压缩比适中),减少磁盘和网络开销。 |
num.partitions |
1 |
新创建 Topic 时的 默认分区数(决定并发处理能力)。 | 1. 分区数越多,Consumer 可并行消费的线程数越多(吞吐量越高); 2. 建议按"峰值吞吐量/单分区吞吐量"估算(如单分区每秒处理 1000 条消息,峰值 5000 条则设为 5 个分区)。 |
auto.create.topics.enable |
true |
是否允许客户端自动创建 Topic(如 Producer 发送消息到不存在的 Topic 时)。 | 生产环境建议设为 false,避免误创建无用 Topic,需通过运维手动创建 Topic。 |
2.1.7、安全配置(可选)
若需保障数据传输和访问安全,需配置 SSL/TLS 加密、SASL 认证等(默认不启用安全机制)。
| 配置项 | 示例值 | 功能说明 |
|---|---|---|
listeners |
SSL://0.0.0.0:9093 |
启用 SSL 加密监听(替换 PLAINTEXT)。 |
ssl.keystore.location |
/etc/kafka/ssl/server.keystore.jks |
Broker 证书库路径(存储自身证书)。 |
ssl.keystore.password |
123456 |
证书库密码。 |
ssl.truststore.location |
/etc/kafka/ssl/server.truststore.jks |
信任库路径(存储客户端信任的证书)。 |
ssl.truststore.password |
123456 |
信任库密码。 |
sasl.enabled.mechanisms |
PLAIN |
启用 SASL 认证机制(如 PLAIN、SCRAM-SHA-256)。 |
sasl.mechanism.inter.broker.protocol |
PLAIN |
Broker 之间通信的 SASL 机制。 |
2.1.8、配置优先级与生效方式
- 优先级顺序 :
命令行参数(如--broker.id=1) >server.properties配置 > Kafka 默认值。 - 生效方式 :
- 大部分配置(如
listeners、log.dirs)修改后需 重启 Broker 生效; - 部分动态配置(如
log.retention.hours、min.insync.replicas)可通过 Kafka 命令行工具修改,无需重启(需开启动态配置支持)。
- 大部分配置(如
通过合理配置 server.properties,可平衡 Kafka 的 可靠性、吞吐量、延迟 三大核心指标。生产环境需结合业务场景(如消息大小、并发量、数据保留需求)和硬件资源(CPU、内存、磁盘、网络)动态调整,避免直接使用默认配置。
2.1.9、生产环境-配置示例
shell
# ================ 基础身份配置 ================
broker.id=0 # 每个Broker唯一,依次递增(0,1,2...)
cluster.id=prod-kafka-cluster # 集群唯一标识
broker.id.generation.enable=false # 禁用自动生成Broker ID(生产环境建议固定ID)
# ================ 网络通信配置 ================
listeners=PLAINTEXT://0.0.0.0:9092 # 监听地址(生产环境建议用SSL加密)
advertised.listeners=PLAINTEXT://192.168.1.100:9092 # 对外暴露的地址(替换为实际IP)
num.network.threads=6 # 处理网络请求的线程数(CPU核心数的1-1.5倍)
num.io.threads=12 # 处理I/O的线程数(CPU核心数的2-3倍)
socket.send.buffer.bytes=131072 # 发送缓冲区(128KB)
socket.receive.buffer.bytes=131072 # 接收缓冲区(128KB)
socket.request.max.bytes=104857600 # 单个请求最大100MB(需大于生产者max.request.size)
# ================ 存储配置 ================
log.dirs=/data/kafka-logs-1,/data/kafka-logs-2 # 多磁盘路径(避免/tmp)
log.retention.hours=48 # 消息保留48小时(根据业务调整)
log.segment.bytes=1073741824 # 单个日志段1GB
log.segment.ms=86400000 # 日志段滚动时间24小时
log.cleanup.policy=delete # 清理策略(默认删除,变更日志用compact)
log.flush.scheduler.interval.ms=300000 # 刷盘调度间隔5分钟(依赖OS缓存)
# ================ 副本与可用性配置 ================
default.replication.factor=3 # 默认副本数3(容忍2节点故障)
min.insync.replicas=2 # 至少2个副本同步成功才确认消息(配合acks=-1)
unclean.leader.election.enable=false # 禁止非同步副本成为Leader(优先可靠性)
replica.lag.time.max.ms=30000 # 副本同步超时30秒
num.replica.fetchers=2 # 副本同步线程数
replica.fetch.max.bytes=10485760 # 副本同步最大消息10MB
# ================ 性能优化配置 ================
num.partitions=8 # 默认分区数8(根据吞吐量估算)
auto.create.topics.enable=false # 禁用自动创建Topic(需手动管理)
compression.type=snappy # 启用Snappy压缩(平衡CPU和带宽)
log.message.format.version=3.0 # 消息格式版本(与Kafka版本一致)
# ================ ZooKeeper配置(若使用) ================
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181/kafka # ZK集群地址+命名空间
zookeeper.connection.timeout.ms=30000 # ZK连接超时30秒
# ================ 动态配置支持 ================
dynamic.config.sync.interval.ms=60000 # 动态配置同步间隔1分钟2.2、Kafka consumer.properties 配置详解
consumer.properties 是 Kafka 消费者(Consumer)的核心配置文件,用于定义消费者与 Broker 的连接方式、消费行为、数据拉取策略、偏移量(Offset)管理等关键特性。以下按功能模块拆解核心配置,结合使用场景说明其作用与最佳实践(基于 Kafka 3.x 版本)。
通常将 Kafka 消费者配置写入自己服务的配置文件(如 Spring Boot 的application.yml),与服务的其他配置统一管理。以下配置用于熟悉和了解
2.2.1、基础身份与集群连接配置
定义消费者所属的消费组、连接的 Kafka 集群地址等基础信息,是消费者启动的前提。
| 配置项 | 默认值 | 功能说明 | 注意事项 |
|---|---|---|---|
bootstrap.servers |
无(必须配置) | Kafka 集群 Broker 地址列表,格式为 host1:port1,host2:port2。 |
1. 只需配置部分 Broker 地址(消费者会自动发现集群中所有节点); 2. 示例:bootstrap.servers=broker1:9092,broker2:9092,broker3:9092。 |
group.id |
无(建议配置) | 消费者所属的 消费组 ID,用于实现消息的负载均衡和偏移量共享。 | 1. 同一消费组内的消费者共同消费 Topic 分区(每个分区仅被组内一个消费者消费); 2. 不同消费组可独立消费同一 Topic(互不影响)。 |
client.id |
自动生成(如 consumer-1) |
消费者的客户端标识(用于 Broker 日志和监控区分不同客户端)。 | 建议手动配置有业务含义的名称(如 order-service-consumer),便于问题排查。 |
2.2.2、数据拉取与消费策略
控制消费者从 Broker 拉取消息的频率、数量、大小等,直接影响消费效率和性能。
- 拉取参数配置
| 配置项 | 默认值 | 功能说明 | 优化建议 |
|---|---|---|---|
fetch.min.bytes |
1 |
消费者单次拉取的 最小字节数:若 Broker 数据不足,会等待直到满足条件或超时。 | 1. 低延迟场景(如实时监控):保持默认 1(有数据就拉取); 2. 高吞吐量场景:设为 102400(100KB),减少请求次数(需配合 fetch.max.wait.ms)。 |
fetch.max.bytes |
52428800(50MB) |
消费者单次拉取的 最大字节数(包含所有分区的消息总和)。 | 1. 必须 ≥ 可能遇到的最大单条消息大小(否则无法消费大消息); 2. 与 Broker 端 socket.request.max.bytes 和 Producer 端 max.request.size 协调(建议为最大消息的 2-3 倍)。 |
fetch.max.wait.ms |
500(500毫秒) |
等待 fetch.min.bytes 满足的 最长时间(超时后即使数据不足也返回)。 |
与 fetch.min.bytes 配合使用,例如:fetch.min.bytes=100KB + fetch.max.wait.ms=1000(最多等1秒)。 |
max.partition.fetch.bytes |
1048576(1MB) |
消费者从 单个分区 拉取的最大字节数(优先级高于 fetch.max.bytes)。 |
1. 限制单个分区的拉取量,避免某分区数据过大占用全部带宽; 2. 若单条消息超过此值,需调大(如 5MB 消息对应 5242880)。 |
- 消费并行度配置
| 配置项 | 默认值 | 功能说明 | 关键原理 |
|---|---|---|---|
max.poll.records |
500 |
单次 poll() 调用返回的 最大消息数(控制批量消费的数量)。 |
1. 数值越大,单次处理的消息越多,但会增加内存占用和处理延迟; 2. 结合业务处理能力调整(如每秒能处理 1000 条,则设为 1000)。 |
max.poll.interval.ms |
300000(5分钟) |
两次 poll() 调用的 最大间隔时间:超过此时间,消费组会认为该消费者失效并触发重平衡(Rebalance)。 |
1. 若业务处理消息耗时较长(如5分钟以上),需调大此值(如 3600000 即1小时); 2. 过小会导致频繁重平衡,影响消费稳定性。 |
2.1.3、偏移量(Offset)管理
Offset 是消费者已消费消息的位置标识,以下配置控制 Offset 的提交方式、初始位置等,直接影响消息的可靠性(是否漏消费或重复消费)。
- Offset 提交策略
| 配置项 | 默认值 | 功能说明 | 场景选择 |
|---|---|---|---|
enable.auto.commit |
true |
是否自动提交 Offset(后台定期提交)。 | 1. true:适用于对重复消费不敏感的场景(如日志收集),简化开发; 2. false:适用于严格不允许重复消费的场景(如金融交易),需手动调用 commitSync() 或 commitAsync()。 |
auto.commit.interval.ms |
5000(5秒) |
自动提交 Offset 的 间隔时间 (仅当 enable.auto.commit=true 生效)。 |
缩短间隔(如 1000 毫秒)可减少重复消费的范围,但会增加 Broker 压力。 |
- Offset 初始位置与重置策略
| 配置项 | 默认值 | 功能说明 | 适用场景 |
|---|---|---|---|
auto.offset.reset |
latest |
当消费组无初始 Offset 或 Offset 无效(如消息已被删除)时的处理策略: - latest:从最新消息开始消费(默认); - earliest:从最早消息开始消费; - none:抛出异常,不消费。 |
1. 新消费组首次消费:earliest(全量消费历史数据)或 latest(只消费新数据); 2. 数据回溯场景:需手动重置 Offset 并配合 earliest。 |
offset.metadata.max.bytes |
4096(4KB) |
存储 Offset 元数据(如自定义标识)的最大字节数。 | 若无需自定义元数据,保持默认即可;如需存储额外信息(如业务标识),可适当调大。 |
2.2.4、连接与超时配置
控制消费者与 Broker 的连接超时、会话保持等,保障网络不稳定时的可靠性。
| 配置项 | 默认值 | 功能说明 | 优化建议 |
|---|---|---|---|
session.timeout.ms |
45000(45秒) |
消费组会话超时时间:若消费者超过此时长未发送心跳,会被标记为失效并触发重平衡。 | 1. 需小于 group.initial.rebalance.delay.ms + max.poll.interval.ms; 2. 网络不稳定时可增至 60000(60秒),减少误判。 |
heartbeat.interval.ms |
3000(3秒) |
消费者向协调者(Coordinator)发送心跳的间隔时间(用于确认存活状态)。 | 建议设为 session.timeout.ms 的 1/3 ~ 1/5(如会话超时 45 秒,心跳设为 3-10 秒)。 |
connection.max.idle.ms |
540000(9分钟) |
空闲连接的最大保持时间:超过此时长会关闭连接,节省资源。 | 长连接场景(如持续消费)可适当调大(如 3600000 即1小时)。 |
request.timeout.ms |
30000(30秒) |
消费者请求(如拉取消息、提交 Offset)的超时时间。 | 网络较慢时可增至 60000(60秒),避免频繁超时重试。 |
2.2.5、消费组与重平衡配置
消费组(Consumer Group)通过重平衡(Rebalance)机制实现分区的动态分配,以下配置控制重平衡的行为。
| 配置项 | 默认值 | 功能说明 | 关键作用 |
|---|---|---|---|
group.initial.rebalance.delay.ms |
0 |
新消费者加入消费组后,延迟多久触发首次重平衡(给其他消费者足够时间加入)。 | 1. 集群扩容时,设为 10000(10秒),避免短时间内多次重平衡; 2. 快速启动场景保持默认 0。 |
partition.assignment.strategy |
[org.apache.kafka.clients.consumer.RangeAssignor, org.apache.kafka.clients.consumer.CooperativeStickyAssignor] |
分区分配策略(决定消费组内消费者如何分配 Topic 分区): - RangeAssignor:按范围分配(默认); - RoundRobinAssignor:轮询分配; - StickyAssignor:粘性分配(尽量保持原有分配,减少重平衡波动)。 |
1. 普通场景:默认策略即可; 2. 分区数多且频繁扩缩容:推荐 StickyAssignor(减少重平衡对消费的影响)。 |
2.2.6、高级功能配置
针对特殊场景(如大消息、安全认证、监控)的配置。
| 配置项 | 默认值 | 功能说明 | 适用场景 |
|---|---|---|---|
receive.buffer.bytes |
65536(64KB) |
消费者 socket 接收缓冲区大小(用于缓存从 Broker 拉取的数据)。 | 大消息场景(如单条 10MB)可增至 10485760(10MB),减少网络往返。 |
send.buffer.bytes |
131072(128KB) |
消费者 socket 发送缓冲区大小(用于发送请求到 Broker)。 | 与 receive.buffer.bytes 配合调整,避免缓冲区溢出。 |
isolation.level |
read_uncommitted |
消费隔离级别: - read_uncommitted:可消费未提交的事务消息(默认); - read_committed:仅消费已提交的事务消息。 |
事务消息场景(如分布式事务)需设为 read_committed,确保数据一致性。 |
metric.reporters |
无 | 配置指标报告器(如 Prometheus、Graphite),用于监控消费者性能。 | 生产环境建议配置,示例:metric.reporters=org.apache.kafka.common.metrics.JmxReporter(JMX 监控)。 |
2.2.7、安全配置(可选)
若 Kafka 集群启用了安全认证(如 SSL、SASL),需配置以下参数(默认不启用)。
| 配置项 | 示例值 | 功能说明 |
|---|---|---|
security.protocol |
SSL 或 SASL_PLAINTEXT |
消费者与 Broker 通信的安全协议(需与 Broker 端 listeners 匹配)。 |
ssl.truststore.location |
/etc/kafka/ssl/consumer.truststore.jks |
信任库路径(存储 Broker 证书)。 |
ssl.truststore.password |
123456 |
信任库密码。 |
sasl.mechanism |
PLAIN 或 SCRAM-SHA-256 |
SASL 认证机制(需与 Broker 端一致)。 |
sasl.jaas.config |
org.apache.kafka.common.security.plain.PlainLoginModule required username="user" password="pass"; |
SASL 认证的用户名和密码配置。 |
2.2.8、生产环境配置示例(精简版)
properties
# 基础连接
bootstrap.servers=broker1:9092,broker2:9092,broker3:9092
group.id=order-service-group
client.id=order-consumer-1
# 拉取策略
fetch.min.bytes=102400 # 100KB
fetch.max.bytes=104857600 # 100MB
fetch.max.wait.ms=1000 # 1秒
max.partition.fetch.bytes=5242880 # 5MB
# 消费并行度
max.poll.records=1000
max.poll.interval.ms=600000 # 10分钟(处理耗时较长的场景)
# Offset 管理(手动提交,确保不重复消费)
enable.auto.commit=false
auto.offset.reset=earliest # 首次消费从最早消息开始
# 连接与超时
session.timeout.ms=60000 # 60秒
heartbeat.interval.ms=10000 # 10秒
request.timeout.ms=60000 # 60秒
# 分区分配策略(优先粘性分配,减少重平衡影响)
partition.assignment.strategy=org.apache.kafka.clients.consumer.StickyAssignor2.2.9、常见问题与最佳实践
-
避免频繁重平衡
- 重平衡会导致消费暂停,需尽量减少:
- 合理设置
session.timeout.ms和max.poll.interval.ms(避免消费者被误判为失效); - 扩缩容时通过
group.initial.rebalance.delay.ms延迟重平衡; - 使用
StickyAssignor分配策略,减少重平衡时的分区迁移。
- 合理设置
- 重平衡会导致消费暂停,需尽量减少:
-
平衡消费延迟与吞吐量
- 低延迟场景:减小
fetch.min.bytes(如1)和fetch.max.wait.ms(如100毫秒); - 高吞吐量场景:增大
fetch.min.bytes(如100KB)和max.poll.records(如1000),减少请求次数。
- 低延迟场景:减小
-
Offset 提交策略选择
- 非关键业务:启用
enable.auto.commit(简化开发,容忍少量重复消费); - 关键业务(如支付):禁用自动提交,在消息处理完成后手动提交
commitSync()(确保消息仅被消费一次)。
- 非关键业务:启用
-
处理大消息
- 确保
max.partition.fetch.bytes≥ 单条消息大小; - 同步调整 Broker 端
socket.request.max.bytes和 Producer 端max.request.size。
- 确保
通过合理配置 consumer.properties,可优化消费者的性能、可靠性和资源利用率。核心原则是:结合业务场景(延迟/吞吐量需求)、消息特性(大小/频率)和集群规模动态调整。
2.2.10、生产环境-配置示例
shell
# ================ 基础连接配置 ================
bootstrap.servers=broker1:9092,broker2:9092,broker3:9092 # Broker地址列表
group.id=order-service-group # 消费组ID(业务相关命名)
client.id=order-consumer-1 # 客户端标识(便于监控)
# ================ 拉取策略配置 ================
fetch.min.bytes=102400 # 单次拉取最小100KB(减少请求次数)
fetch.max.bytes=104857600 # 单次拉取最大100MB
fetch.max.wait.ms=1000 # 最多等待1秒(平衡延迟和吞吐量)
max.partition.fetch.bytes=10485760 # 单个分区拉取最大10MB(需≥最大消息大小)
# ================ 消费并行度配置 ================
max.poll.records=1000 # 单次poll最大1000条消息(根据处理能力调整)
max.poll.interval.ms=600000 # 两次poll间隔最大10分钟(避免频繁重平衡)
# ================ Offset管理配置 ================
enable.auto.commit=ture # 开启自动提交(手动提交为false,要控制提交时机)
auto.offset.reset=latest # 生产环境稳定后可改为从最新消息消费
# auto.offset.reset=earliest # 无Offset时从最早消息开始消费(首次消费)
# ================ 连接与超时配置 ================
session.timeout.ms=60000 # 会话超时60秒
heartbeat.interval.ms=10000 # 心跳间隔10秒(约为session.timeout的1/6)
connection.max.idle.ms=3600000 # 空闲连接保持1小时
request.timeout.ms=60000 # 请求超时60秒
# ================ 重平衡与分配策略 ================
group.initial.rebalance.delay.ms=10000 # 首次重平衡延迟10秒(等待更多消费者加入)
partition.assignment.strategy=org.apache.kafka.clients.consumer.StickyAssignor # 粘性分配策略(减少重平衡波动)
# ================ 高级配置 ================
receive.buffer.bytes=65536 # 接收缓冲区64KB
send.buffer.bytes=131072 # 发送缓冲区128KB
isolation.level=read_committed # 仅消费已提交的事务消息(事务场景)2.3、Kafka producer.properties 配置详解
producer.properties 是 Kafka 生产者(Producer)的核心配置文件,用于定义生产者与 Broker 的连接方式、消息发送策略、可靠性保证、压缩方式等关键特性。以下按功能模块拆解核心配置,结合使用场景说明其作用与最佳实践(基于 Kafka 3.x 版本)。
2.3.1、基础连接配置
定义生产者连接 Kafka 集群的基础信息,是生产者启动的前提。
| 配置项 | 默认值 | 功能说明 | 注意事项 |
|---|---|---|---|
bootstrap.servers |
无(必须配置) | Kafka 集群 Broker 地址列表,格式为 host1:port1,host2:port2。 |
1. 只需配置部分 Broker 地址(生产者会自动发现集群中所有节点); 2. 示例:bootstrap.servers=broker1:9092,broker2:9092,broker3:9092。 |
client.id |
自动生成(如 producer-1) |
生产者的客户端标识(用于 Broker 日志和监控区分不同客户端)。 | 建议手动配置有业务含义的名称(如 order-service-producer),便于问题排查。 |
2.3.2、消息发送与可靠性配置
控制消息发送的确认机制、重试策略等,直接影响消息的可靠性(是否丢失)和发送延迟。
- 可靠性保证(ACK 机制)
| 配置项 | 默认值 | 功能说明 | 场景选择 |
|---|---|---|---|
acks |
1 |
消息发送的确认级别: - 0:生产者发送后不等待 Broker 确认(最快,但可能丢失消息); - 1:仅等待 Leader 分区确认接收(默认,平衡可靠性和性能); - -1 或 all:等待 Leader 和所有同步副本(ISR)确认(最可靠,但延迟最高)。 |
1. 高性能场景(如日志采集):0 或 1; 2. 高可靠场景(如金融交易):-1(需配合 Broker 的 min.insync.replicas ≥ 2)。 |
- 重试机制
| 配置项 | 默认值 | 功能说明 | 优化建议 |
|---|---|---|---|
retries |
2147483647(无限重试) |
消息发送失败时的重试次数(如网络抖动、Leader 切换导致的临时失败)。 | 1. 生产环境建议设为 10(避免无限重试导致消息积压); 2. 需配合 retry.backoff.ms 控制重试间隔。 |
retry.backoff.ms |
100(100毫秒) |
两次重试之间的等待时间(避免频繁重试给 Broker 带来压力)。 | 网络不稳定时可增至 1000(1秒),减少无效重试。 |
delivery.timeout.ms |
120000(2分钟) |
消息从发送到成功交付的最大超时时间(包含重试时间)。 | 需大于 linger.ms + (retries + 1) * retry.backoff.ms,确保重试机制生效。 |
2.3.3、性能优化配置
控制消息的批量发送、压缩方式等,直接影响生产者的吞吐量和网络带宽占用。
- 批量发送策略
| 配置项 | 默认值 | 功能说明 | 关键原理 |
|---|---|---|---|
batch.size |
16384(16KB) |
生产者批量发送的 缓冲区大小:达到此大小后会统一发送。 | 1. 增大此值(如 65536 即64KB)可提高吞吐量(减少网络请求次数),但会增加延迟; 2. 若消息体较大(如5KB),建议设为消息大小的 3-5 倍(如 20480)。 |
linger.ms |
0(立即发送) |
批量发送的 等待时间 :即使未达到 batch.size,超过此时长也会发送。 |
1. 低延迟场景:保持 0(有消息就发); 2. 高吞吐量场景:设为 5-100 毫秒(等待更多消息凑成批量)。 |
buffer.memory |
33554432(32MB) |
生产者用于缓存消息的 总内存大小(所有分区共享)。 | 若消息发送速度超过 Broker 接收速度,缓冲区满后会阻塞发送(或抛出异常,取决于 block.on.buffer.full),建议根据并发量调整(如 67108864 即64MB)。 |
- 压缩配置
| 配置项 | 默认值 | 功能说明 | 场景选择 |
|---|---|---|---|
compression.type |
none(不压缩) |
消息压缩算法: - none:不压缩; - gzip:高压缩比(CPU 开销大); - snappy:中等压缩比(CPU 开销小,推荐); - lz4:压缩速度快(适合大消息)。 |
1. 网络带宽有限时:启用 snappy 或 lz4; 2. 小消息(<1KB):压缩收益低,可保持 none; 3. 大消息(>1KB):建议压缩(减少网络传输和存储开销)。 |
2.3.4、消息大小与序列化配置
控制单条消息的最大尺寸、数据序列化方式等。
| 配置项 | 默认值 | 功能说明 | 注意事项 |
|---|---|---|---|
max.request.size |
1048576(1MB) |
单个请求的最大字节数(包含消息本身和协议头),限制单条消息的最大尺寸。 | 1. 必须 ≤ Broker 端的 socket.request.max.bytes(否则 Broker 会拒绝请求); 2. 若需发送大消息(如10MB),需同步调整为 10485760 并修改 Broker 配置。 |
key.serializer |
无(必须配置) | 消息键(Key)的序列化类(将对象转为字节数组)。 | 官方提供:org.apache.kafka.common.serialization.StringSerializer(字符串)、org.apache.kafka.common.serialization.IntegerSerializer(整数)等。 |
value.serializer |
无(必须配置) | 消息值(Value)的序列化类(同 Key 序列化逻辑)。 | 自定义对象需实现 org.apache.kafka.common.serialization.Serializer 接口。 |
2.3.5、分区策略配置
控制消息如何分配到 Topic 的不同分区(影响消费的负载均衡)。
| 配置项 | 默认值 | 功能说明 | 适用场景 |
|---|---|---|---|
partitioner.class |
org.apache.kafka.clients.producer.internals.DefaultPartitioner |
分区分配策略类: - 默认策略:指定 Key 时按 Key 哈希分配到固定分区;无 Key 时轮询分配。 - 自定义策略:需实现 org.apache.kafka.clients.producer.Partitioner 接口。 |
1. 普通场景:默认策略即可; 2. 特殊需求(如按业务标签分区):自定义分区器。 |
linger.ms |
0 |
见"批量发送策略" | 与分区策略配合,影响批量消息的分区分布。 |
2.3.6、连接与超时配置
控制生产者与 Broker 的连接超时、请求超时等,保障网络不稳定时的可靠性。
| 配置项 | 默认值 | 功能说明 | 优化建议 |
|---|---|---|---|
connections.max.idle.ms |
540000(9分钟) |
空闲连接的最大保持时间:超过此时长会关闭连接,节省资源。 | 长连接场景(如持续发送消息)可适当调大(如 3600000 即1小时)。 |
request.timeout.ms |
30000(30秒) |
生产者请求(如发送消息)的超时时间。 | 网络较慢时可增至 60000(60秒),避免频繁超时重试。 |
metadata.fetch.timeout.ms |
60000(60秒) |
获取集群元数据(如分区 Leader 信息)的超时时间。 | 集群规模大时可适当调大(如 120000 即2分钟)。 |
2.3.7、安全配置(可选)
若 Kafka 集群启用了安全认证(如 SSL、SASL),需配置以下参数(默认不启用)。
| 配置项 | 示例值 | 功能说明 |
|---|---|---|
security.protocol |
SSL 或 SASL_PLAINTEXT |
生产者与 Broker 通信的安全协议(需与 Broker 端 listeners 匹配)。 |
ssl.keystore.location |
/etc/kafka/ssl/producer.keystore.jks |
生产者证书库路径(存储自身证书)。 |
ssl.keystore.password |
123456 |
证书库密码。 |
sasl.mechanism |
PLAIN 或 SCRAM-SHA-256 |
SASL 认证机制(需与 Broker 端一致)。 |
sasl.jaas.config |
org.apache.kafka.common.security.plain.PlainLoginModule required username="user" password="pass"; |
SASL 认证的用户名和密码配置。 |
2.3.8、常见问题与最佳实践
-
平衡可靠性与性能
- 核心业务(如支付):
acks=-1+retries=10+ 同步发送(确保消息不丢失); - 非核心业务(如日志):
acks=1+ 异步发送 + 压缩(优先吞吐量)。
- 核心业务(如支付):
-
批量发送调优
- 消息量小但频繁:增大
linger.ms(如50ms),让更多消息凑成批量; - 消息量大:增大
batch.size(如64KB),减少网络请求次数。
- 消息量小但频繁:增大
-
处理大消息
- 避免发送超大消息(建议 ≤10MB),否则会降低吞吐量;
- 必须发送大消息时,同步调整:
- 生产者
max.request.size - Broker
socket.request.max.bytes - 消费者
max.partition.fetch.bytes
- 生产者
-
序列化选择
- 简单类型(字符串、整数):用官方
StringSerializer; - 复杂对象:推荐
JSON(可读性好)或Protobuf(效率高、体积小)。
- 简单类型(字符串、整数):用官方
通过合理配置 producer.properties,可在满足业务可靠性要求的同时,最大化生产者的吞吐量并降低延迟。核心原则是:根据消息特性(大小、频率)和业务对可靠性的要求动态调整。
2.3.9、生产环境-配置示例
shell
# ================ 基础连接配置 ================
# Kafka集群Broker地址列表(至少配置2个,避免单点依赖)
bootstrap.servers=broker1:9092,broker2:9092,broker3:9092
# 客户端标识(建议包含业务名称,便于监控和日志排查)
client.id=order-service-producer
# ================ 可靠性配置(核心) ================
# 消息确认级别:-1/all 表示等待Leader和所有同步副本确认(最高可靠性)
acks=-1
# 消息发送失败后的重试次数(10次足够覆盖大多数临时故障)
retries=10
# 重试间隔时间(1秒,避免频繁重试压垮Broker)
retry.backoff.ms=1000
# 消息从发送到成功交付的最大超时时间(5分钟,需大于重试总耗时)
delivery.timeout.ms=300000
# 发送缓冲区满时是否阻塞(false表示抛出异常,避免消息积压)
block.on.buffer.full=false
# ================ 性能优化配置 ================
# 批量发送缓冲区大小(64KB,平衡批量效率和延迟)
batch.size=65536
# 批量等待时间(50毫秒,等待更多消息凑成批量,提高吞吐量)
linger.ms=50
# 生产者总缓存内存(64MB,根据并发量调整,避免OOM)
buffer.memory=67108864
# 启用Snappy压缩(平衡CPU开销和网络带宽,大消息收益明显)
compression.type=snappy
# ================ 消息大小与序列化 ================
# 单个请求最大大小(10MB,支持大消息,需与Broker和Consumer配合调整)
max.request.size=10485760
# Key的序列化器(字符串类型,根据实际数据类型调整)
key.serializer=org.apache.kafka.common.serialization.StringSerializer
# Value的序列化器(字符串类型,复杂对象可替换为JSON/Protobuf序列化器)
value.serializer=org.apache.kafka.common.serialization.StringSerializer
# ================ 连接与超时配置 ================
# 空闲连接最大保持时间(1小时,长连接场景减少重连开销)
connections.max.idle.ms=3600000
# 单个请求超时时间(60秒,网络较慢时避免频繁超时)
request.timeout.ms=60000
# 元数据获取超时时间(2分钟,集群规模大时需延长)
metadata.fetch.timeout.ms=120000
# 元数据刷新间隔(5分钟,定期更新集群信息如Leader切换)
metadata.max.age.ms=300000
# ================ 分区策略(可选) ================
# 分区分配策略(默认策略:按Key哈希分区,无Key则轮询)
# partitioner.class=org.apache.kafka.clients.producer.internals.DefaultPartitioner
# ================ 安全配置(按需启用) ================
# 若集群启用SSL/SASL,取消注释并配置以下参数
# security.protocol=SASL_SSL
# sasl.mechanism=SCRAM-SHA-256
# sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="producer-user" password="producer-pass";
# ssl.truststore.location=/etc/kafka/ssl/truststore.jks
# ssl.truststore.password=truststore-pass三、鉴权配置
3.1、kafka鉴权
- 在
server.properties配置文件最下方添加配置
shell
#使用的认证协议
#security.inter.broker.protocol=SASL_PLAINTEXT
#SASL机制
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
#完成身份验证的类
authorizer.class.name=kafka.security.authorizer.AclAuthorizer
#如果没有找到ACL(访问控制列表)配置,则允许任何操作。
allow.everyone.if.no.acl.found=false
#需要开启设置超级管理员,设置visitor用户为超级管理员
super.users=User:visitor- 在同层目录新建
kafka_server_jaas.conf配置
shell
vim kafka_server_jaas.conf添加以下内容:
shell
KafkaServer{
org.apache.kafka.common.security.plain.PlainLoginModule required
username="visitor"
password="123456"
user_visitor="123456"
user_producer="123456"
user_consumer="123456";
};- 修改启动脚本
给kafka启动脚本最上方添加变量
shell
vim bin/kafka-server-start.sh
shell
export KAFKA_OPTS=" -Djava.security.auth.login.config=/path/to/kafka_2.12-3.9.1/config/kafka_server_jaas.conf"- 设置
server.properties映射端口,修改内外网连接地址端口
这时候你的内部连接kafka端口为19092,使用外网ip连接端口为29092
shell
listeners=INTERNAL://0.0.0.0:19092,EXTERNAL://0.0.0.0:29092
advertised.listeners=INTERNAL://内网ip:19092,EXTERNAL://外网ip:29092
listener.security.protocol.map=INTERNAL:SASL_PLAINTEXT,EXTERNAL:SASL_PLAINTEXT
inter.broker.listener.name=INTERNAL- 启动服务
启动ZooKeeper
shell
nohup /path/to/kafka_2.13-3.9.1/bin/zookeeper-server-start.sh /path/to/kafka_2.13-3.9.1/config/zookeeper.properties > /var/log/kafka/zookeeper.log 2>&1 &启动kafka
shell
nohup /path/to/kafka_2.12-3.9.1/bin/kafka-server-start.sh /path/to/kafka_2.12-3.9.1/config/server.properties > /path/kafka_2.12-3.9.1/log/kafka/kafka-server.log 2>&1 &- 测试
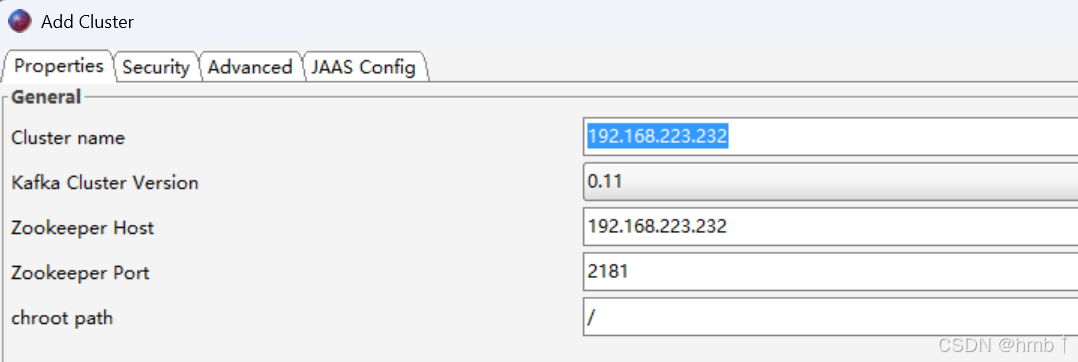
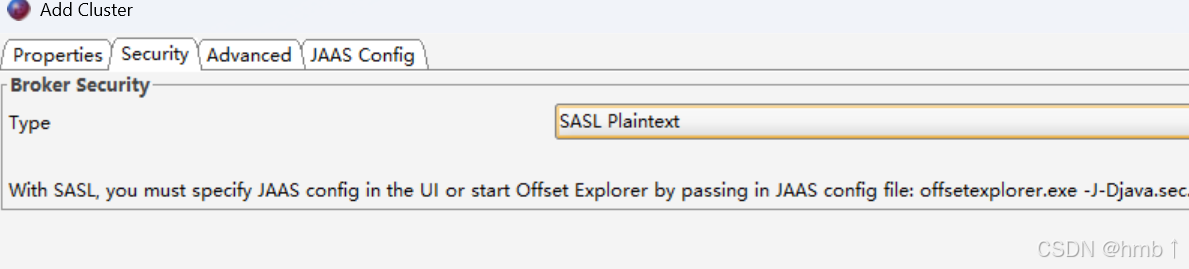
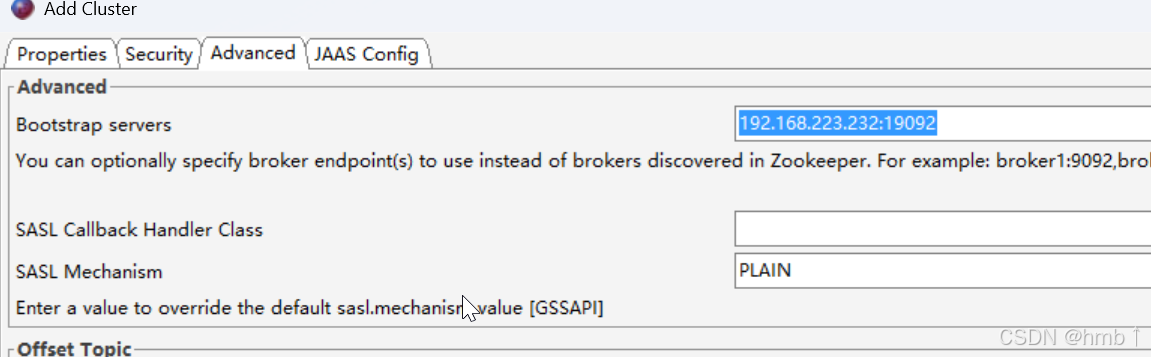
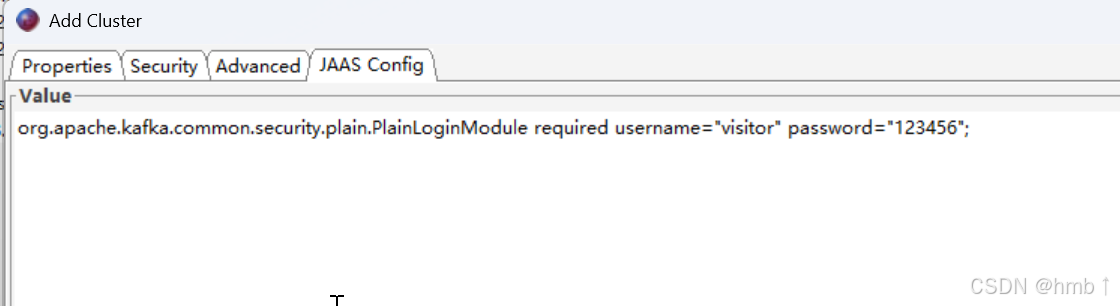
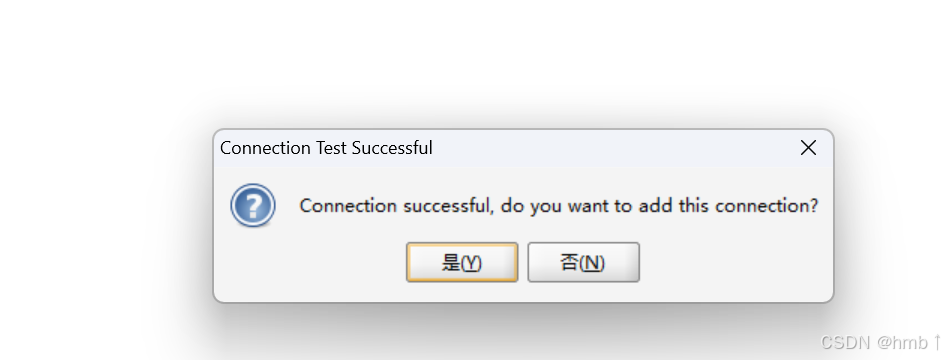
连接测试,接入成功
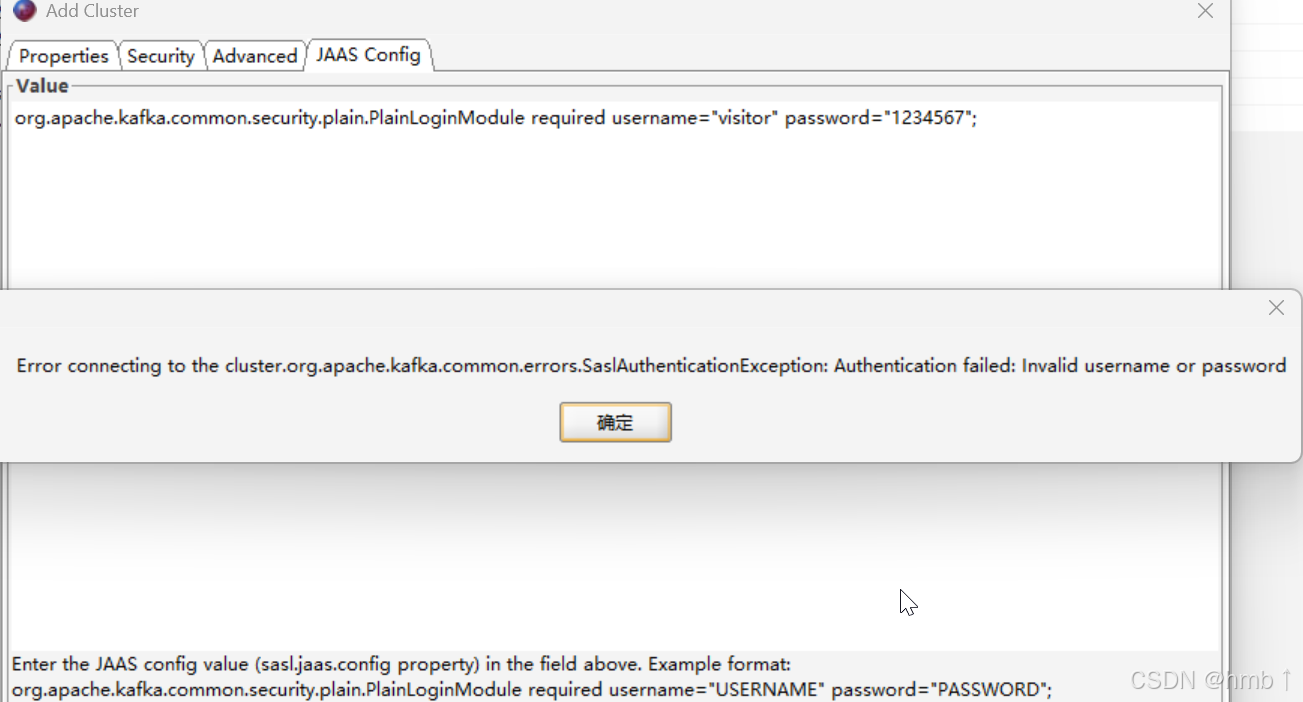
输入错误的密码,连接不上
3.2、zookeeper鉴权
ZooKeeper 默认是 "无鉴权开放状态" 的 ------ 即默认不需要任何密码就能直接访问,任何能连接到 ZooKeeper 端口(默认 2181)的客户端,都能读写数据、甚至删除关键节点。加鉴权后,未授权用户无法连接,自然无法读取这些敏感元数据。
建议上方kafka配置成功后再来配置zookeeper鉴权。
- 在
zookeeper.properties中添加以下配置(启用 SASL 认证)
bash
# 启用 SASL 认证插件(必填)
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
# 强制客户端必须使用 SASL 认证(若设为 sasl,则未认证的客户端无法连接)
requireClientAuthScheme=sasl
# SASL 登录会话的刷新时间(毫秒),建议设置为 1 小时
jaasLoginRenew=3600000- Kafka 的
server.properties需明确指定 ZooKeeper 的 SASL 机制
bash
# 启用ZooKeeper SASL客户端认证
zookeeper.sasl.client=true
# 指定SASL机制(与ZooKeeper一致)
zookeeper.sasl.client.mechanism=PLAIN
# 与ZooKeeper JAAS配置中定义的用户匹配
zookeeper.sasl.client.username=zkuser- 在同层目录(config下)新建
zookeeper_jaas.conf配置
注意注释要删掉,可能会报错
bash
Server {
org.apache.zookeeper.server.auth.DigestLoginModule required
# ZooKeeper管理员账号(用于内部操作)
username="admin"
password="admin123"
user_zkuser="zkpass123"; # Kafka连接ZooKeeper的用户(user_用户名)
};- 在kafka的鉴权配置
kafka_server_jaas.conf中,加入连接zookeeper鉴权配置
注意注释要删掉,可能会报错
bash
# 连接ZooKeeper的客户端认证配置
Client {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="zkuser" # 与ZooKeeper中定义的user_zkuser对应
password="zkpass123"; # 与ZooKeeper中user_zkuser的密码一致
};- 在zookeeper的启动文件
zookeeper-server-start.sh上方加入配置
bash
export KAFKA_OPTS="-Djava.security.auth.login.config=/path/to/zookeeper_jaas.conf" 6.启动zookeeper,此时连接就需要鉴权