文章目录
前言
ElasticSearch 简称 es,是一个开源的高扩展的分布式全文检索引擎。它可以近乎实时的存储、检索数据,且其扩展性很好,ElasticSearch 是企业级应用中较为常见的检索技术。
下面主要记录学习 ElasticSearch7.x 的一些基本结构、在 Spring Boot 项目里基本应用的过程,在这里与大家作分享交流。
一、概述
1.1基本认识
ElasticSearch 是基于 Lucene 实现的开源、分布式、RESTful 接口的全文搜索引擎。
Elasticsearch 还是一个分布式文档数据库,其中每个字段均是被索引的数据且可被搜索,它能够扩展至数以百计的服务器存储以及处理PB级的数据。
Elasticsearch 可以通过简单的 RESTful 风格 API 来隐藏 Lucene 的复杂性,让搜索变得更加简单。
1.2核心概念
Elasticsearch 的核心概念是 Elasticsearch 搜索的过程,在搜索的过程中,Elasticsearch 的存储过程、数据结构都会有所涉及。
表1

- Elasticsearch (集群)中可以包含多个 indices(对应库),每个索引中可以包含多个 types(对应表),每个types下面又包含多个 documents(对应行记录),每个 documents 中又含有多个fields(对应字段)。
- Elasticsearch 中一切数据的格式都是 JSON,一条数据就是一个文档。
- 这里 types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个type,Elasticsearch 7.X 中 Type 的概念已经被删除了。
- Elasticsearch 中的索引是一个非常大的文档集合,存储了映射类型的字段和其它设置,被存储在各个分片上。
1.3倒排索引
Elasticsearch 使用一种名为倒排索引的结构进行搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
传统数据库的搜索结构一般以 id 为主,可以一一对应数据库中的所有内容,即 key-value 的形式。
而倒排索引则与之相反,以内容为主,将所有不重复的内容记录按照匹配的程度(阈值)进行展示,即 value-key 的形式。
以下举两个例子来进行说明。
在关系型数据库中,数据是按照id的顺序进行约定的,记录的id具有唯一性,方便人们使用 id 去确定内容,如表2所示:
表2

在 ElasticSearch 中使用倒排索引:数据是按照不重复的内容进行约定的,不重复的内容具有唯一性,这样可以快速地找出符合内容的记录 ,再根据匹配的阈值去进行展示。
即:id为1和2的行都含有关键字内容 Java、id为3和4的行都含有关键字 Python。如表3所示:
表3

1.4了解ELK
ELK 是 ElasticSearch、Logstash、Kibana这三大开源框架首字母大写简称。
Logstash 是中央数据流引擎,用于从不同目标(文件/数据存储/MQ)中收集不同的数据格式,经过过滤后支持输送到不同的目的地(文件/MQ/Redis/Elasticsearch/kafka 等)。
Kibana 可以将 ElasticSearch 的数据通过友好的可视化界面展示出来,且提供实时分析的功能。
ELK一般来说是一个日志分析架构技术栈的总称,但实际上 ELK 不仅仅适用于日志分析,它还可以支持任何其它数据分析和收集的场景,日志的分析和收集只是更具有代表性,并非 ELK 的唯一用途。
二、安装(基于 CentOS)
2.1安装声明
- 适用于 JDK1.8 及以上版本
- 界面工具 Kibana 应与 ElasticSearch 版本一致
- ElasticSearch 版本与 Maven 依赖版本对应
2.2 使用 Docker 安装
-
步骤一:拉取镜像
bashdocker pull elasticsearch:7.6.1 -
步骤二:启动镜像
bash# 这是一整行命令,不是两行 docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d elasticsearch:7.6.1 -
步骤三:浏览器访问 http://你的公网ip:9200,即可得到以下json格式的数据,表明已经安装且启动成功,如图1所示:
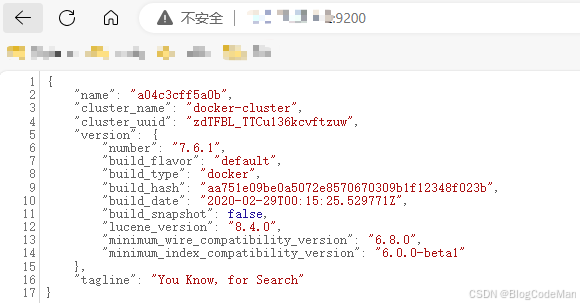
图1
-
步骤四:修改配置,解决跨域访问:
bash#依次执行以下命令 docker exec -it elasticsearch /bin/bash #1、进入容器 cd /usr/share/elasticsearch/config/ #2、cd到config目录 vi elasticsearch.yml #3、编辑elasticsearch.yml 文件添加以下内容到末尾,,保存并退出:
bashhttp.cors.enabled: true http.cors.allow-origin: "*"退出容器:
bashexit重启容器:
bashdocker restart elasticsearch
2.3安装使用 Kibana
Kibana是一个针对 ElasticSearch 的开源分析、可视化平台,用于搜索、查看交互存储在 ElasticSearch 中的数据。
注意事项:Kibana 版本需要和 ElasticSearch 的版本保持一致。
安装步骤如下:
-
步骤一:拉取镜像
bashdocker pull kibana:7.6.1 -
步骤二:启动镜像
bashdocker run --name kibana --link=elasticsearch:test -p 5601:5601 -d kibana:7.6.1 -
步骤三:浏览器打开 http://你的公网ip:5601 进入 Kibana 界面,如图2所示:
图2
2.4安装使用 IK 分词器
在使用中文进行搜索时,我们会对要搜索的信息进行分词:将一段中文分成一个个的词语或者句子,然后将分出的词进行搜索。
默认的中文分词是一个汉字一个词,如:"你好世界",会被分成:"你","好","世","界"。但这样的分词方式显然并不全面,比如还可以分成:"你好","世界"。
ik 分词器就解决了默认分词不全面的问题,可以将中文进行不重复的分词。
ik 分词器提供了两种算法:ik_smart(最少切分)以及 ik_max_word(最细颗粒度划分)。
-
步骤一:进入容器内部
bashdocker exec -it elasticsearch /bin/bash -
步骤二:在线下载并安装(这是一整行命令,不是两行)
bash./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.1/elasticsearch-analysis-ik-7.6.1.zip -
步骤三:退出容器并重启:
bash# 退出容器 exit # 重启容器 docker restart elasticsearch -
步骤四:点击 kibana 主界面左侧边栏的的 Dev Tools 工具,输入测试命令,效果如图3所示:
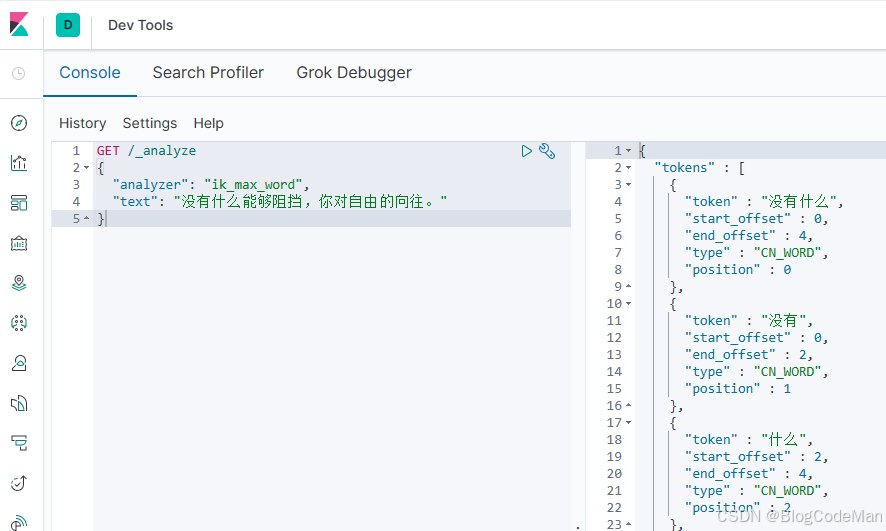
图3
三、RESTful 操作
ElasticSearch 支持使用 RESTful 风格来进行一系列操作,使用的是标准的 HTTP 方法,比如 GET、PUT、POST 和 DELETE。
3.1索引操作
以下关于索引的操作,可以在 postman 或者 Kibana 上操作。postman 要带上你的公网ip:端口,kibana 要注明是 GET 或者 PUT,其它操作都是一样的。
- 创建索引
json
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "article"
}- 查看单个索引信息
json
{
"article": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"creation_date": "1700029085972",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "4rVnVk22SnGURHF5tCvPkQ",
"version": {
"created": "7060199"
},
"provided_name": "article"
}
}
}
}- 查看所有索引信息
txt
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .security-7 2xUWUkq1Soyg0ydewEKrew 1 0 42 0 109.1kb 109.1kb
green open .kibana_task_manager_1 Q53d13THSeKzauDGgDGv2Q 1 0 2 0 26.2kb 26.2kb
green open .apm-agent-configuration cbMuzKXGQReJyEa9CDCZlw 1 0 0 0 283b 283b
green open .kibana_1 hShl-bvbTpqm9Y9ih-sO5w 1 0 13 4 32.8kb 32.8kb
yellow open article 4rVnVk22SnGURHF5tCvPkQ 1 1 0 0 283b 283b- 删除索引
json
{
"acknowledged": true
}3.2文档操作
documents 可以看作是数据库中的一行行记录,数据格式为 JSON 格式。由于没有了表的概念,所以看作所有的 documents 都是直接存在 index 里的。
以下使用可视化工具 Kibana 来进行操作。
-
新增文档数据
-
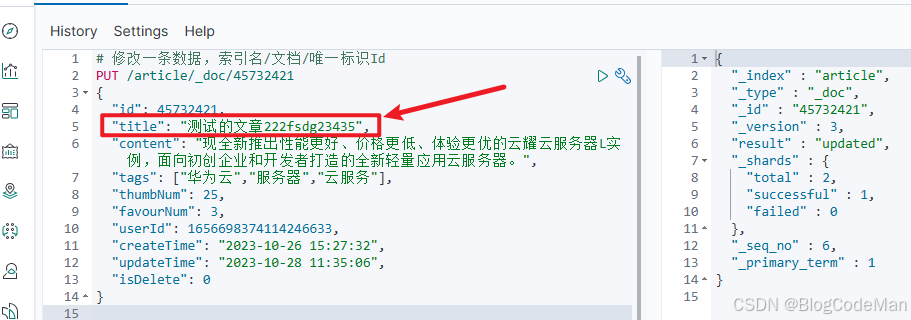
更新文档数据
和新增文档一样,输入语句,如果请求体的值有变化,会将原有的数据内容覆盖:
-
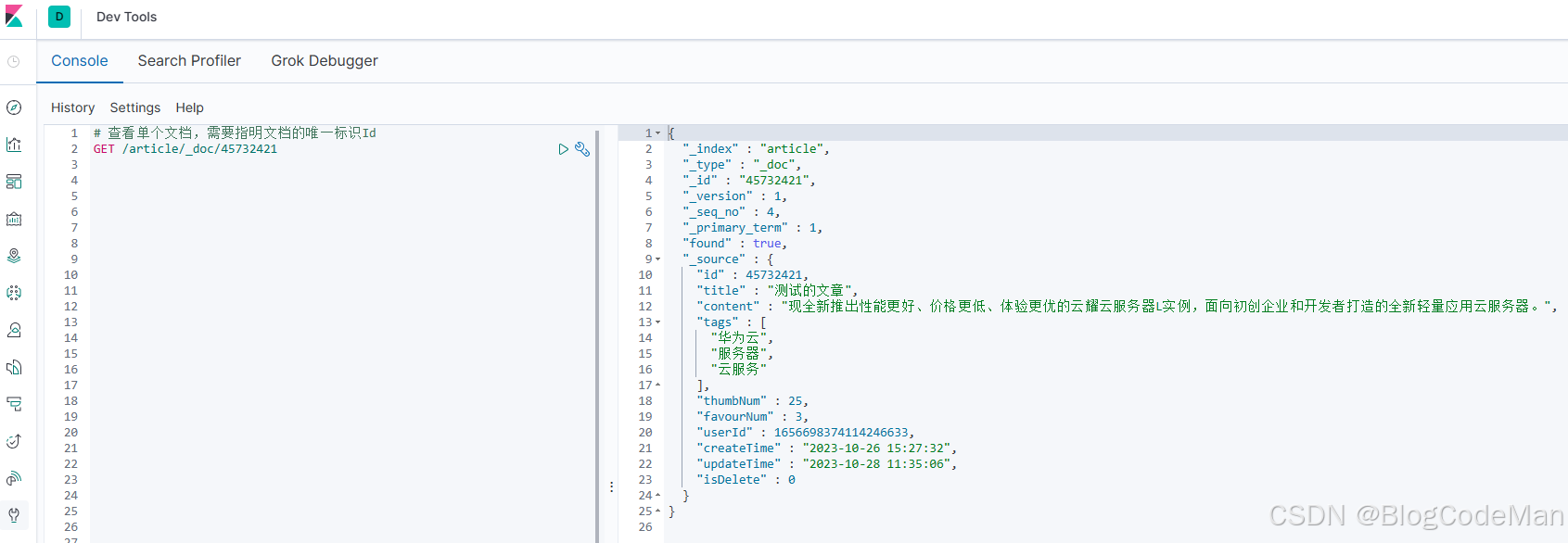
查看单个文档
-
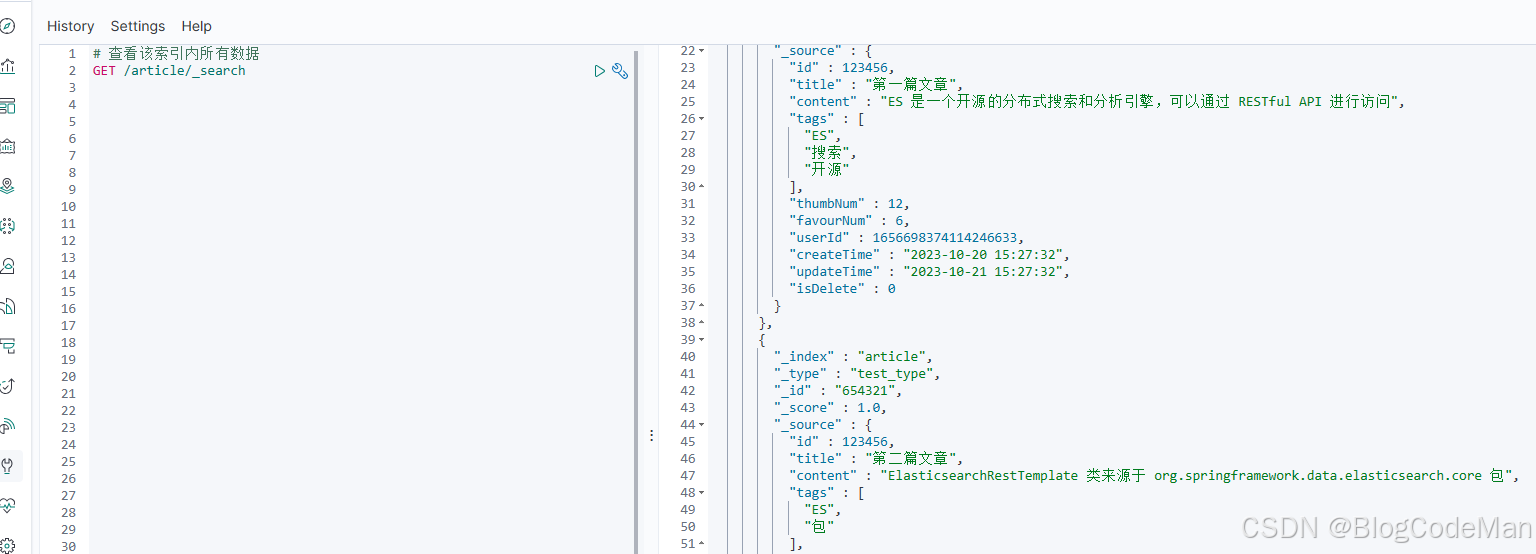
查看所有文档
-
简单条件查询
- match 匹配类型查询,会先对查询条件进行分词,然后进行查询:
json# 查看该索引内所有数据,条件是匹配对 title 分词后包含"文章"的 documents GET /article/_search { "query": { "match":{ "title":"文章" } } }- multi_match 与 match 类似,不同的是它可以在多个字段中查询:
json# 查看该索引内所有数据,条件是对输入的 query 内容使用 ik_max_word 分词,然后分别对 title、content 字段的内容做匹配 GET /article/_search { "query": { "multi_match":{ "query": "文章的", "fields": ["title","content"], "analyzer": "ik_max_word" } } }上述的简单条件查询操作在企业级应用开发中一般不会单独使用,更多地还是结合复杂查询实现业务,对于复杂查询的操作在第四章会详细介绍。
-
删除 documents 数据
一般删除数据都是根据文档的唯一性标识进行删除。实际操作时,也可以根据条件对多条数据进行删除。
json# 根据条件删除,即删除可以匹配到 favourNum 内容为 6 的所有文档 POST /article/_delete_by_query { "query":{ "match":{ "favourNum":6 } } }
3.3映射操作
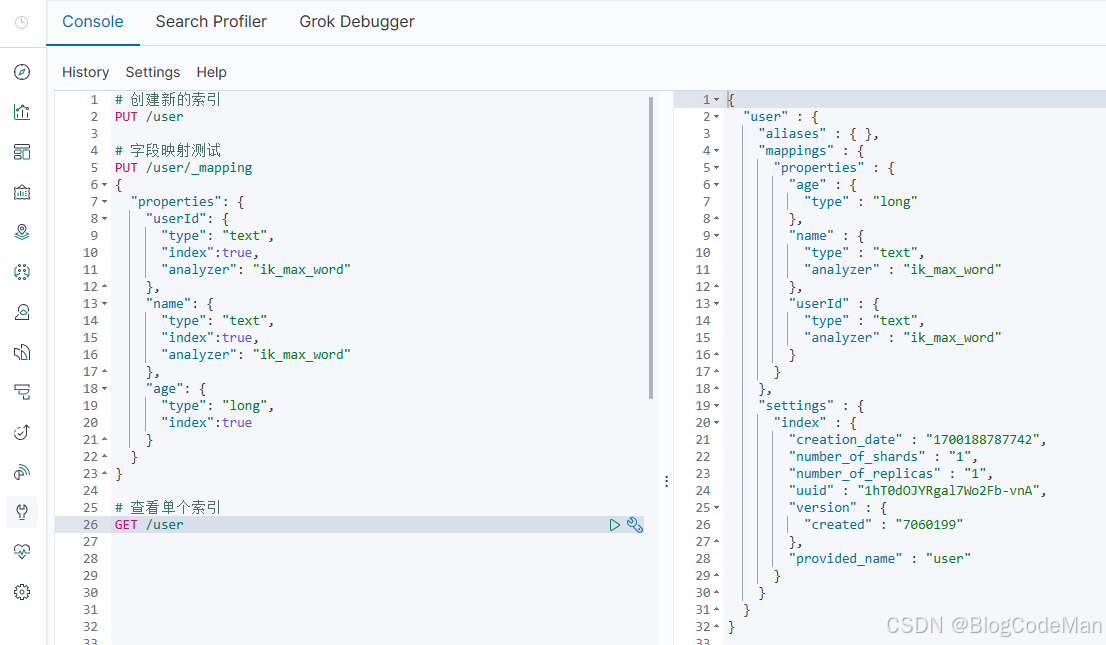
我们知道,ES 的索引相当于传统数据库中的 Database,那么建索引(index)中的映射就类似于数据库(Database)中的表结构(Table)。
设计表需要设置:字段名、类型、长度、约束等,索引也一样,需要知道这个文档中有哪些字段,每个字段有哪些约束信息,这个过程就是创建映射(mapping)。
其实在 Spring Boot 中新建 ES 实体类的时候,使用 @Document 注解、@Field 注解就可以对字段做映射,详情可以看我的另一篇关于 ES 的博文。
四、复杂查询详解
ElasticSearch 引擎首先分析需要查询的 query 参数内容,未提前声明不分词的情况下,都会根据分词器规则进行分词,然后根据查询条件进行结果匹配返回。
4.1关键字介绍
4.1.1通用概念
- Query :将需要查询的 JSON 参数体进行包裹,声明这是一条查询语句,通常其字段类型为 String 字符串。
- keyword :keyword 代表一种关键词的分词类型,表明该字段的值不会被分词器所分词。
- score:字段内容与词条的匹配程度,分数越高表明匹配度越高,就越符合查询结果,默认也会按照分数值排序返回结果。
- hits:对应 Java 代码中的 hit 对象,包含了索引和文档信息,包括查询结果总数,查询出来的 documents 内容(一串 JSON)、分数(score)等。
- source:需要展示的内容字段,默认是展示索引的所有字段,也可以自定义条件指定需要展示的字段。
4.1.2布尔查询(BoolQueryBuilder)
- must :在 must 中的内容都是必须执行的内容,在 must 中可以创建多条语句;多条语句需同时满足条件才能执行,作用相当于 SQL 语句中的 AND 。
- should :在 should 关键字里的内容只要满足其中一项就可以执行,作用相当于 SQL 语句中的 OR 。
- must_not :类似于 Java 中的 != 作用,即展示查询内容之外的内容。
- filter:根据指定的条件来过滤掉不符合要求的文档,倾向于"当前文档和查询的条件是不是相符",且不会对结果做相关性得分计算;filter 子句内还可包含 bool 子句,以实现更复杂的逻辑。
- minimum_should_match:用来控制查询精度,如果 bool 语句有至少一个 should 子语句则默认值为1,表示 should 语句中的条件起码要满足一个;如果 bool 语句中包含有 must 或 filter 子句,则其默认值为0,即表示 should 子句可以不满足任何条件。
小结:BoolQueryBuilder 的子句只有 must、should、must_not 和 filter 这4种 ,其中只有 must 和 should 子句会计算相关性评分。
4.1.3基本查询(QueryBuilders)
-
match :作用是对某个字段的匹配查询,首先输入的参数会经过分词器的分词,分词后的结果与字段的值进行匹配,最后再执行 match 查询。
默认情况下:字段内容必须完整地匹配到任意一个词条(分词后),才会有返回结果。如果需要查询的词有多个,可以用空格隔开。
-
multi_match:在 match 的基础进行了一些加强,不同的是它可以在多个字段中查询,将符合的结果返回。
-
match_all:没有任何条件,是一种检索所有数据的全量查询,一般配合使用分页使用。
-
match_phrase:会对输入的查询参数做分词,但是需要结果中也包含所有的分词,并且顺序要求一致。这个条件比较苛刻,一般的业务可能用不到。
-
term:精确查询关键字,使用 term 时首先不会对需要查询的输入参数进行分词,只有精确地匹配到一模一样的内容才会返回结果。
-
terms:与 term 类似,但它允许指定多个值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档就满足条件,作用类似于 MySQL的 in。
-
includes:默认情况 ES 会返回 _source 里的全部字段,includes 可以用来指定想要显示的字段;
-
excludes:是 includes 的取反,可以用来指定不想显示的字段。
-
range:查询在指定区间范围内的数字或者时间,使用 gt(大于)、gte(大于等于)、lt(小于)和 lte (小于等于)来作为条件。
-
fuzzy:模糊查询,要与 match 区别开来,fuzzy 会在指定的编辑距离内创建一组搜索词的所有可能的变体或扩展,通过 fuzziness 修改编辑距离。
-
highlight :进行关键字搜索时,搜索出的内容中的关键字部分会显示不同的颜色;可以配合使用 match 查询时,加上一个 highlight 属性。
4.1.4分页查询(PageRequest)
-
PageRequest
javaPageRequest pageRequest = PageRequest.of((int) current, (int) pageSize);
4.1.5排序(SortBuilder)
- sort:按照指定的字段进行排序,并且通过 order 指定排序的方式:desc 降序,asc 升序;也可多字段排序,先排字段1,如字段1相等,再根据字段2排。
4.1.6聚合查询
- 聚合允许对 ES 的文档进行统计分析,类似与关系型数据库中的 Group By,它要更强大和灵活,当然还有很多其它的聚合,例如取最大值、平均值等。
五、文章小结
ES 的核心是索引和其结构,不同与B+树,这是检索速度快的根本原因,同时其 Json 结构也适合放入大量的文档内容。
至于其索引和文档 API 的操作,可以参考官方文档的例子在 postman 或者 Kibana上操作,直至熟练为止。其查询语句是应用的核心,常用语句和语法的学习,可以结合 Spring Boot 项目来进一步实践,从参数判断、查询构造、数据同步等方面探究,相信读者会有不一样的收获。
最后,本文的分享到此结束了,如有错误和不足,期待大家的指正和交流。
参考文档: