上一章: 机器学习07------贝叶斯分类器
下一章: 机器学习09------聚类
机器学习实战项目: 【从 0 到 1 落地】机器学习实操项目目录:覆盖入门到进阶,大学生就业 / 竞赛必备
文章目录
一、集成学习的基本概念(个体与集成)
集成学习通过构建并结合多个个体学习器提升性能,核心是让个体学习器"好而不同"------既要有一定准确性,又要具备多样性(预测存在差异)。
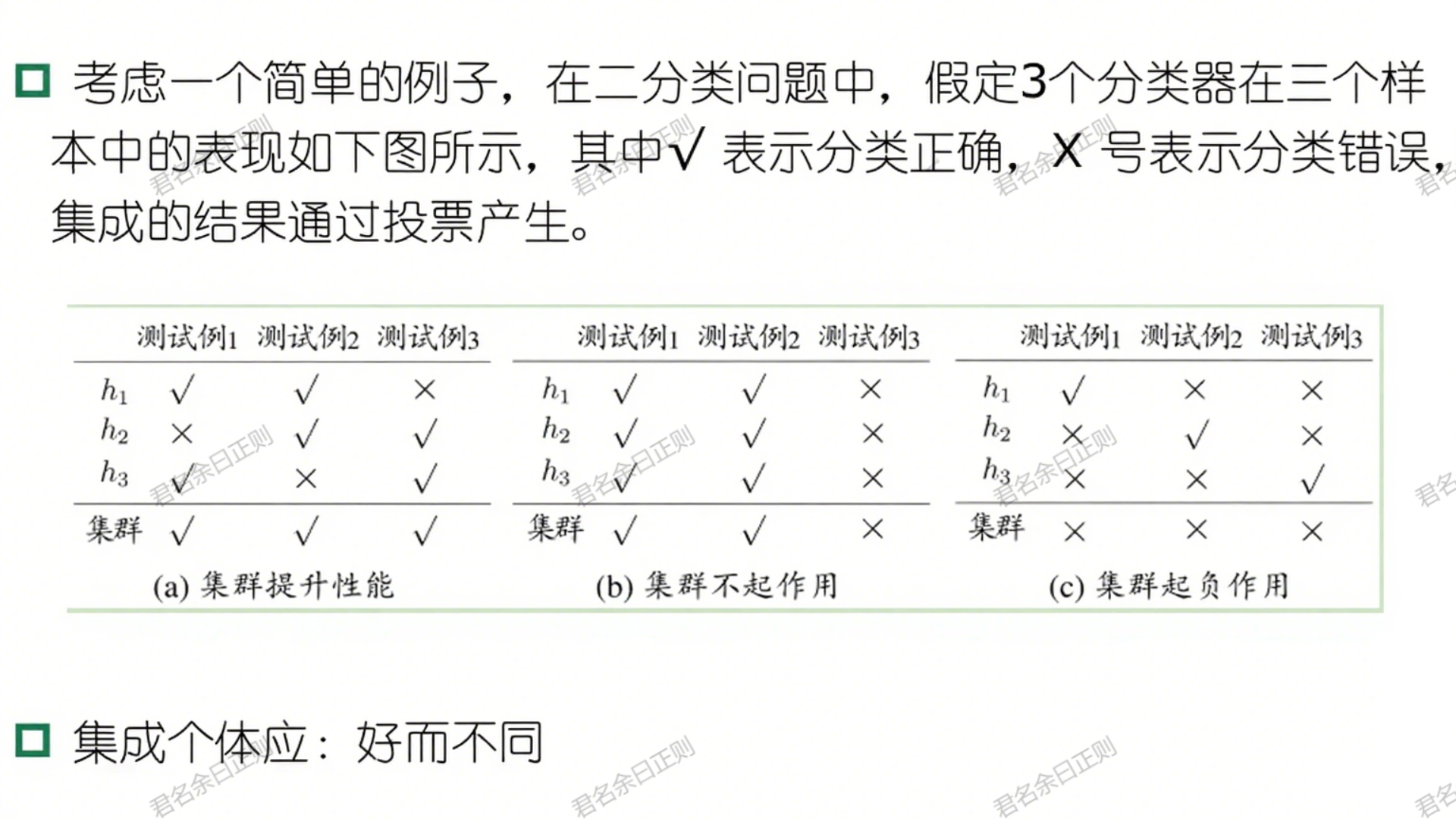
(一)集成的基本原理
- 工作流程:多个个体学习器并行或串行生成,通过结合模块(如投票、平均)输出最终结果。
- 效果示例:在二分类任务中,3个基分类器通过投票可纠正单个分类器的错误(如2个正确、1个错误时,集成结果正确)。
- 理论分析 :假设基分类器错误率为 ϵ \epsilon ϵ,且相互独立,通过简单投票法(超过半数正确则集成正确),集成错误率可由Hoeffding不等式约束为:
P ( H ( x ) ≠ f ( x ) ) ≤ exp ( − 1 2 T ( 1 − 2 ϵ ) 2 ) P(H(x) \neq f(x)) \leq \exp\left(-\frac{1}{2}T(1-2\epsilon)^2\right) P(H(x)=f(x))≤exp(−21T(1−2ϵ)2)
随个体学习器数量 T T T增加,集成错误率呈指数下降。但现实中基分类器难以完全独立,因此"准确性"与"多样性"的平衡是关键。
二、Boosting(串行集成方法)
Boosting通过串行生成个体学习器,每个学习器聚焦于前序学习器误分的样本,逐步提升集成性能,典型代表为AdaBoost。
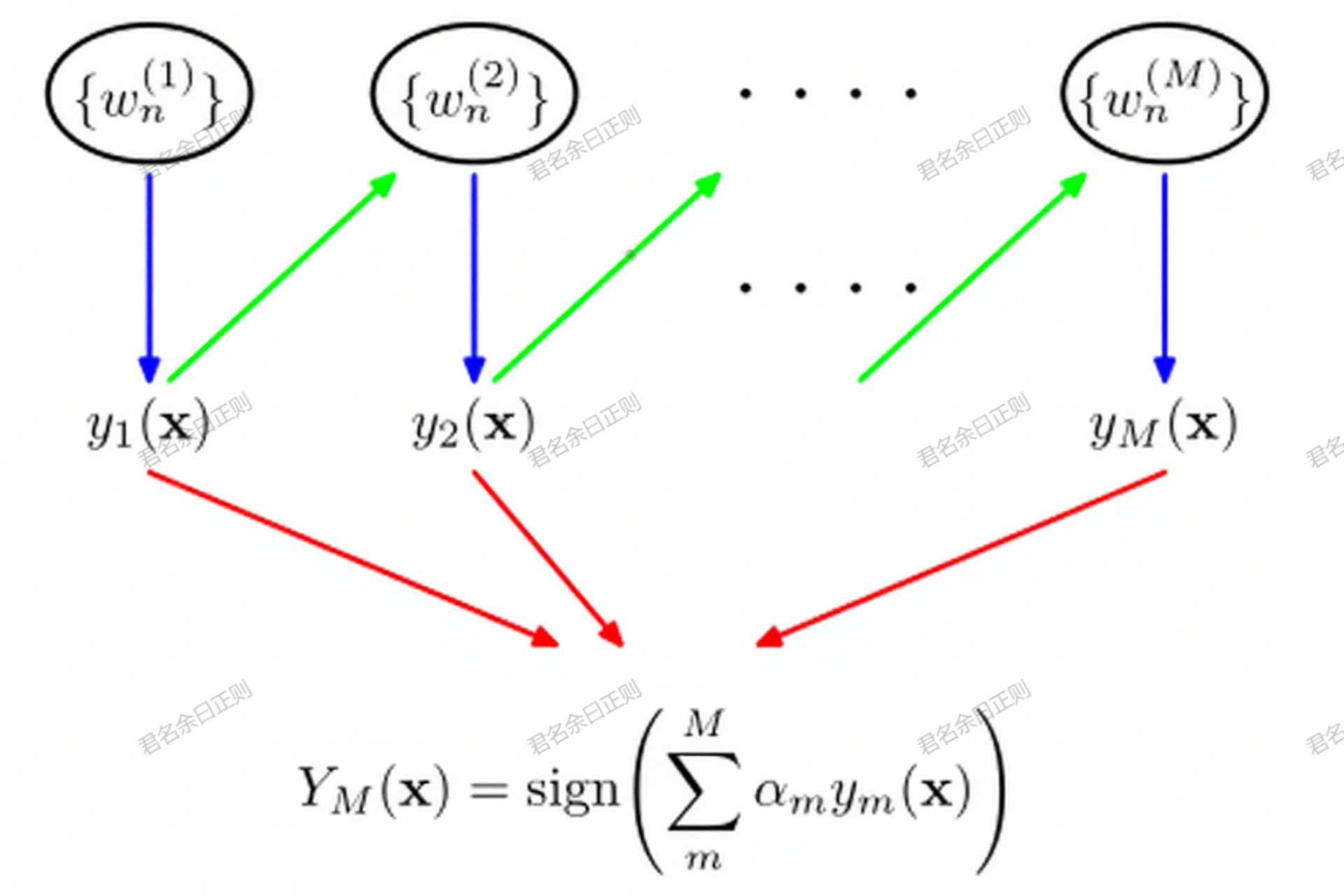
(一)AdaBoost算法流程
- 初始化 :样本分布 D 1 ( x ) = 1 / m \mathcal{D}_1(x) = 1/m D1(x)=1/m(均匀分布);
- 迭代训练( t = 1 , 2 , . . . , T t=1,2,...,T t=1,2,...,T) :
- 基于分布 D t \mathcal{D}_t Dt训练基学习器 h t h_t ht;
- 计算 h t h_t ht的错误率 ϵ t = P x ∼ D t ( h t ( x ) ≠ f ( x ) ) \epsilon_t = P_{x \sim \mathcal{D}_t}(h_t(x) \neq f(x)) ϵt=Px∼Dt(ht(x)=f(x)),若 ϵ t > 0.5 \epsilon_t > 0.5 ϵt>0.5则停止;
- 计算 h t h_t ht的权重 α t = 1 2 ln ( 1 − ϵ t ϵ t ) \alpha_t = \frac{1}{2}\ln\left(\frac{1-\epsilon_t}{\epsilon_t}\right) αt=21ln(ϵt1−ϵt)(错误率越低,权重越大);
- 更新样本分布:
D t + 1 ( x ) = D t ( x ) exp ( − α t f ( x ) h t ( x ) ) Z t \mathcal{D}_{t+1}(x) = \frac{\mathcal{D}_t(x) \exp(-\alpha_t f(x) h_t(x))}{Z_t} Dt+1(x)=ZtDt(x)exp(−αtf(x)ht(x))
( Z t Z_t Zt为归一化因子,误分样本权重增加,正确样本权重减少);
- 输出集成结果 :
H ( x ) = sign ( ∑ t = 1 T α t h t ( x ) ) H(x) = \text{sign}\left(\sum_{t=1}^T \alpha_t h_t(x)\right) H(x)=sign(t=1∑Tαtht(x))
(二)核心机制
- 损失函数 :通过最小化指数损失函数 ℓ exp ( H ∣ D ) = E x ∼ D e − f ( x ) H ( x ) \ell_{\exp}(H|\mathcal{D}) = \mathbb{E}_{x \sim \mathcal{D}}e\^{-f(x)H(x)} ℓexp(H∣D)=Ex∼De−f(x)H(x)实现优化,该损失是0/1损失的一致替代函数;
- 偏差降低:通过聚焦难分样本,逐步纠正错误,主要降低集成的偏差,即使基学习器性能较弱(如决策树桩),也能构建强集成。
三、Bagging与随机森林(并行集成方法)
Bagging通过并行生成个体学习器,利用自助采样增加多样性;随机森林是Bagging的扩展,进一步引入属性选择随机性。
(一)Bagging算法
-
自助采样 :对训练集 D D D进行 T T T次有放回采样,得到 T T T个不同的训练集 D 1 , . . . , D T D_1,...,D_T D1,...,DT;
-
并行训练 :基于每个 D t D_t Dt训练基学习器 h t h_t ht;
-
结合策略 :分类任务用简单投票,回归任务用简单平均:
H ( x ) = argmax y ∈ Y ∑ t = 1 T I ( h t ( x ) = y ) H(x) = \underset{y \in \mathcal{Y}}{\text{argmax}} \sum_{t=1}^T \mathbb{I}(h_t(x) = y) H(x)=y∈Yargmaxt=1∑TI(ht(x)=y) -
优势:
- 包外估计:未被采样的样本(包外样本)可用于评估泛化误差,无需单独验证集;
- 方差降低:通过多个学习器的平均,降低对训练样本波动的敏感性,适用于高方差模型(如未剪枝决策树)。
(二)随机森林(RF)
- 扩展机制 :在Bagging基础上,每个决策树节点分裂时,从所有属性中随机选择 K K K个属性,仅基于这 K K K个属性选择最优分裂点(通常 K = log 2 d K = \log_2 d K=log2d, d d d为属性数);
- 多样性增强:通过属性随机选择,进一步降低个体学习器的相关性,提升集成性能;
- 特点:训练效率高(可并行),泛化能力强,是实践中常用的集成方法。
四、结合策略(集成输出的融合方式)
结合策略决定如何整合个体学习器的输出,常见方法包括平均法、投票法和学习法。
(一)平均法(适用于回归)
- 简单平均 : H ( x ) = 1 T ∑ t = 1 T h t ( x ) H(x) = \frac{1}{T}\sum_{t=1}^T h_t(x) H(x)=T1∑t=1Tht(x),计算简单,在个体性能相近时有效;
- 加权平均 : H ( x ) = ∑ t = 1 T w t h t ( x ) H(x) = \sum_{t=1}^T w_t h_t(x) H(x)=∑t=1Twtht(x)( w t ≥ 0 w_t \geq 0 wt≥0, ∑ w t = 1 \sum w_t = 1 ∑wt=1),权重可通过交叉验证优化,但未必优于简单平均。
(二)投票法(适用于分类)
- 绝对多数投票:得票超过半数则输出该类,否则拒绝;
- 相对多数投票:得票最多的类为输出;
- 加权投票 : H ( x ) = argmax y ∈ Y ∑ t = 1 T w t I ( h t ( x ) = y ) H(x) = \underset{y \in \mathcal{Y}}{\text{argmax}} \sum_{t=1}^T w_t \mathbb{I}(h_t(x) = y) H(x)=y∈Yargmax∑t=1TwtI(ht(x)=y),考虑个体学习器的权重。
(三)学习法(元学习)
- Stacking :用初级学习器的输出作为次级学习器的输入,训练次级学习器整合结果:
- 初级学习器 h 1 , . . . , h T h_1,...,h_T h1,...,hT在训练集 D D D上训练;
- 生成新数据集 D ′ = { ( h 1 ( x i ) , . . . , h T ( x i ) , y i ) ∣ ( x i , y i ) ∈ D } D' = \{(h_1(x_i),...,h_T(x_i), y_i) | (x_i,y_i) \in D\} D′={(h1(xi),...,hT(xi),yi)∣(xi,yi)∈D};
- 次级学习器 h ′ h' h′在 D ′ D' D′上训练,输出 H ( x ) = h ′ ( h 1 ( x ) , . . . , h T ( x ) ) H(x) = h'(h_1(x),...,h_T(x)) H(x)=h′(h1(x),...,hT(x));
- 常用次级学习器:多响应线性回归(MLR)、逻辑回归等。
五、多样性(集成性能的关键)
多样性指个体学习器之间的差异,是集成性能提升的核心,可通过误差-分歧分解分析其作用。
(一)误差-分歧分解(回归任务)
- 分歧 :个体学习器与集成的差异, A ( h i ∣ x ) = ( h i ( x ) − H ( x ) ) 2 A(h_i|x) = (h_i(x) - H(x))^2 A(hi∣x)=(hi(x)−H(x))2,加权分歧 A ˉ = ∑ w i A i \bar{A} = \sum w_i A_i Aˉ=∑wiAi;
- 关系 :集成泛化误差 E = E ˉ − A ˉ E = \bar{E} - \bar{A} E=Eˉ−Aˉ,其中 E ˉ \bar{E} Eˉ是个体学习器泛化误差的加权均值。即:个体准确性越高( E ˉ \bar{E} Eˉ小)、多样性越大( A ˉ \bar{A} Aˉ大),集成性能越好。
(二)多样性增强方法
- 数据扰动:如自助采样(Bagging)、样本权重调整(Boosting);
- 属性扰动:随机选择属性子集(随机森林);
- 输出扰动:对类别标记稍作调整;
- 算法参数扰动:如对决策树调整深度、对神经网络调整学习率等。
总结
集成学习通过结合多个"好而不同"的个体学习器提升性能,Boosting(如AdaBoost)串行生成,聚焦偏差降低;Bagging与随机森林并行生成,聚焦方差降低。结合策略需根据任务类型选择,多样性是集成效果的关键,可通过多种扰动方法增强。
上一章: 机器学习07------贝叶斯分类器
下一章: 机器学习09------聚类
机器学习实战项目: 【从 0 到 1 落地】机器学习实操项目目录:覆盖入门到进阶,大学生就业 / 竞赛必备