一、概述
在高级编程语言的世界中,开发者始终与 【object/struct】 这类高度抽象的数据结构打交道。然而在分布式架构下,任何服务进程都不是数据孤岛------跨进程数据交换是必然需求。
以Java为例,业务逻辑的输入输出都是 【object】 。但在RPC场景中,这些对象必须经由网络传输。这里出现了一个根本性矛盾:网络介质(网线/光纤)对面向对象编程(OOP)一无所知,它们只会用光和电忠实地传输扁平化 的字节流(byte\[\] )。

软件工程经典的分层理论驱使我们去添加一个转换层。
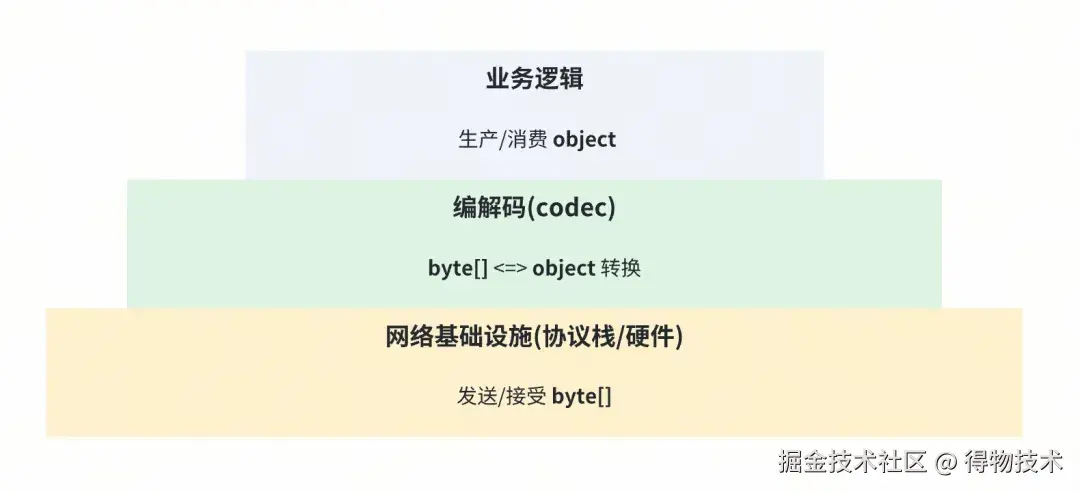
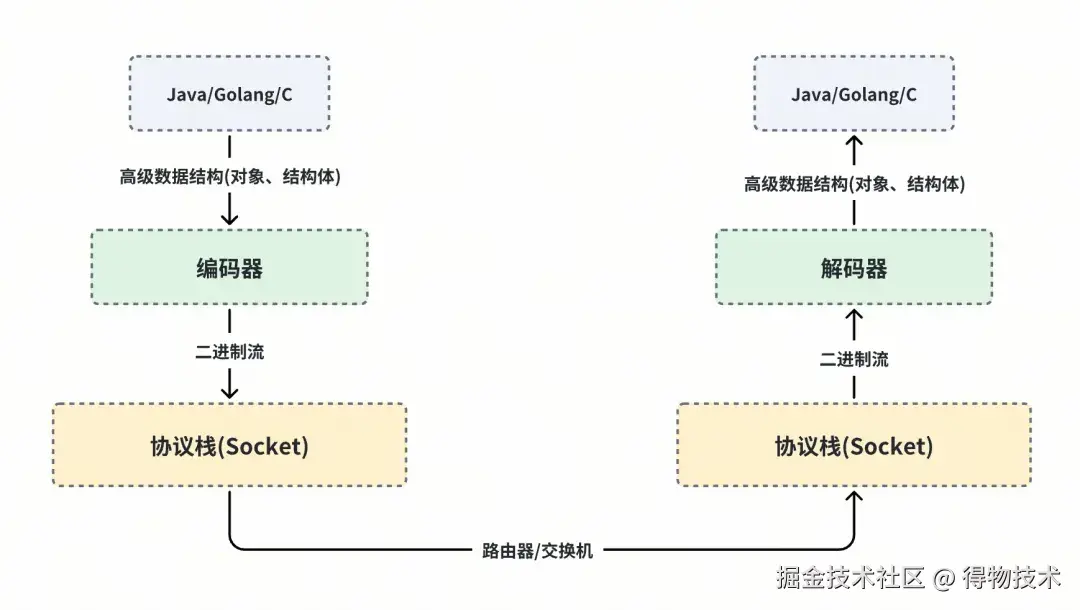
我们需要有个工具或者组件来协助进行 【object】 和 【byte\[\]】 之间的双向转换。这个过程包含两个对称的流程:
- 【object 】->【byte\[\] 】:业界一般称为序列化/serialize ,但是那个单词念起来很拗口,本文我们都叫它【编码/encode】好了。
- 【byte\[\] 】->【object 】:业界一般称为反序列化/deserialize ,但是那个单词念起来很拗口,本文我们都叫它【解码/decode】好了。
Hessian作为Java生态中久经考验的对象编解码器,相较于同类产品具有以下两大核心优势:
- 深度Java生态适配 :与JSON、Protobuf等语言中立的通用协议不同,Hessian专为Java深度优化,对泛型、多态等Java特有语言特性提供原生支持。
- 高效二进制协议:相较JSON等文本协议,Hessian采用精心设计的二进制编码方案,在编解码效率和数据压缩率方面表现更优。
需要强调的是,软件工程没有银弹------业务场景的差异决定了编解码器的选择必然需要权衡取舍。但就Java RPC而言,Hessian应该是经过广泛实践验证的稳健选择。
本文将系统解析Hessian的编码流程,重点揭示其实现【object 】->【byte\[\] 】转换的核心机制。
二、基础编码原理
对象编码过程主要包含如下两大核心:
- 对象图遍历:遍历高级数据结构
-
- 通过反射或元编程技术遍历对象图(Object Graph)。
- 是同类产品的通用逻辑,不管jackson、fastjson、hessian都需要用不同的方式做类似的事情。
- 编码格式 :将高级数据结构按协议拍平放到byte\[\]
-
- 同类产品百家争鸣,各有各的思路。
- 是同类产品的竞技场,各个产品在这里体现差异化的竞争力。
- 设计权衡包括:
-
- 二进制效率 vs 可读性(如Hessian二进制 vs JSON文本)
- 编码紧凑性 vs 扩展灵活性
- 跨语言支持 vs 语言特性深度优化
对象图遍历 决定了编码能力的下限(能否正确处理对象结构),而编码格式决定了编码能力的上限(传输效率、兼容性等)。
对象图遍历

对象图遍历的本质是按深度优先 进行对象属性导航。
举个例子:

宏观来看,A类型的对象其实是一棵树(或图) ,如果脑补不出来的话,我给你画个图:
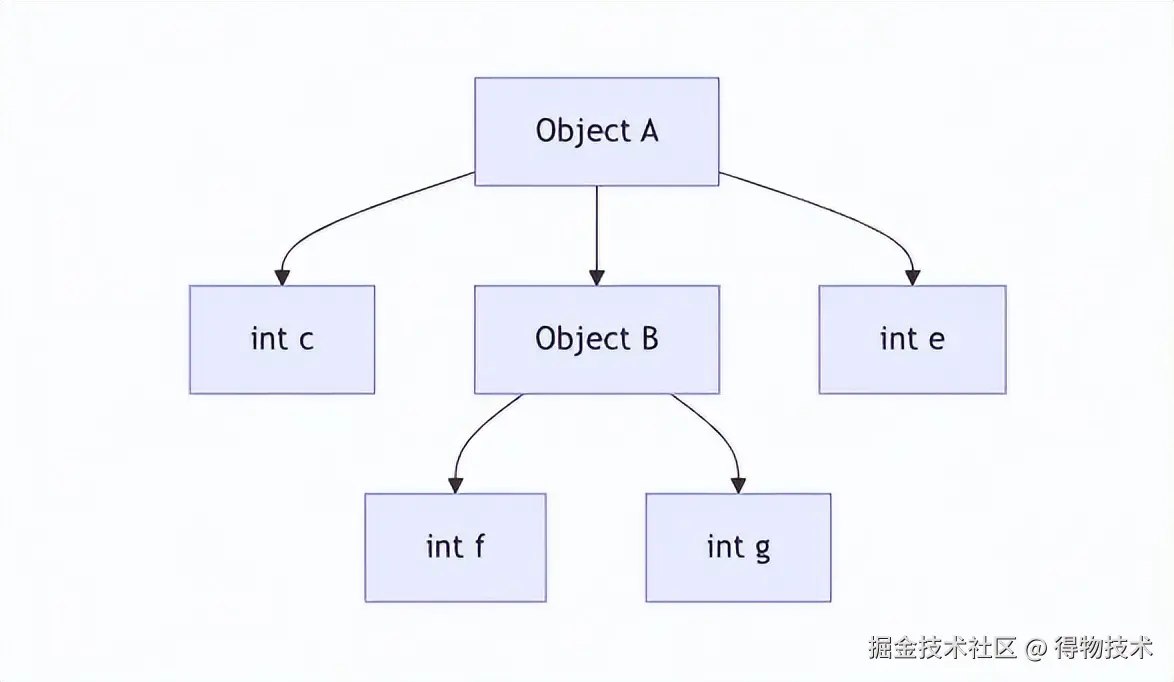
可以看到这棵树的叶子结点都一定是Java内置的基本数据类型。换句话说,Java的8种基础数据类型 和他们的数组变体,支撑了Java丰富的预定义/自定义数据结构。
八股文:Java的8种基础数据类型是哪些?String算不算基础数据类型?
编码的本质就是深度优先的遍历这棵树,拍平它,然后放到byte\[\] 里。
我举个例子吧。
伪代码
为降低伪代码复杂度,我们假设Java只有1种基础数据类型int,也就是说Java里只有int和只包含int字段的自定义POJO。
我们定义POJO指的是用于传输、存储使用的简单Java Bean或者常说的DTO。
从某种意义上来说,Integer也是基于int封装的自定义POJO。
字节流抽象
我们使用标准库里的java.io.DataOutput来进行伪代码说理,这个类提供了一些语义化的编码function。
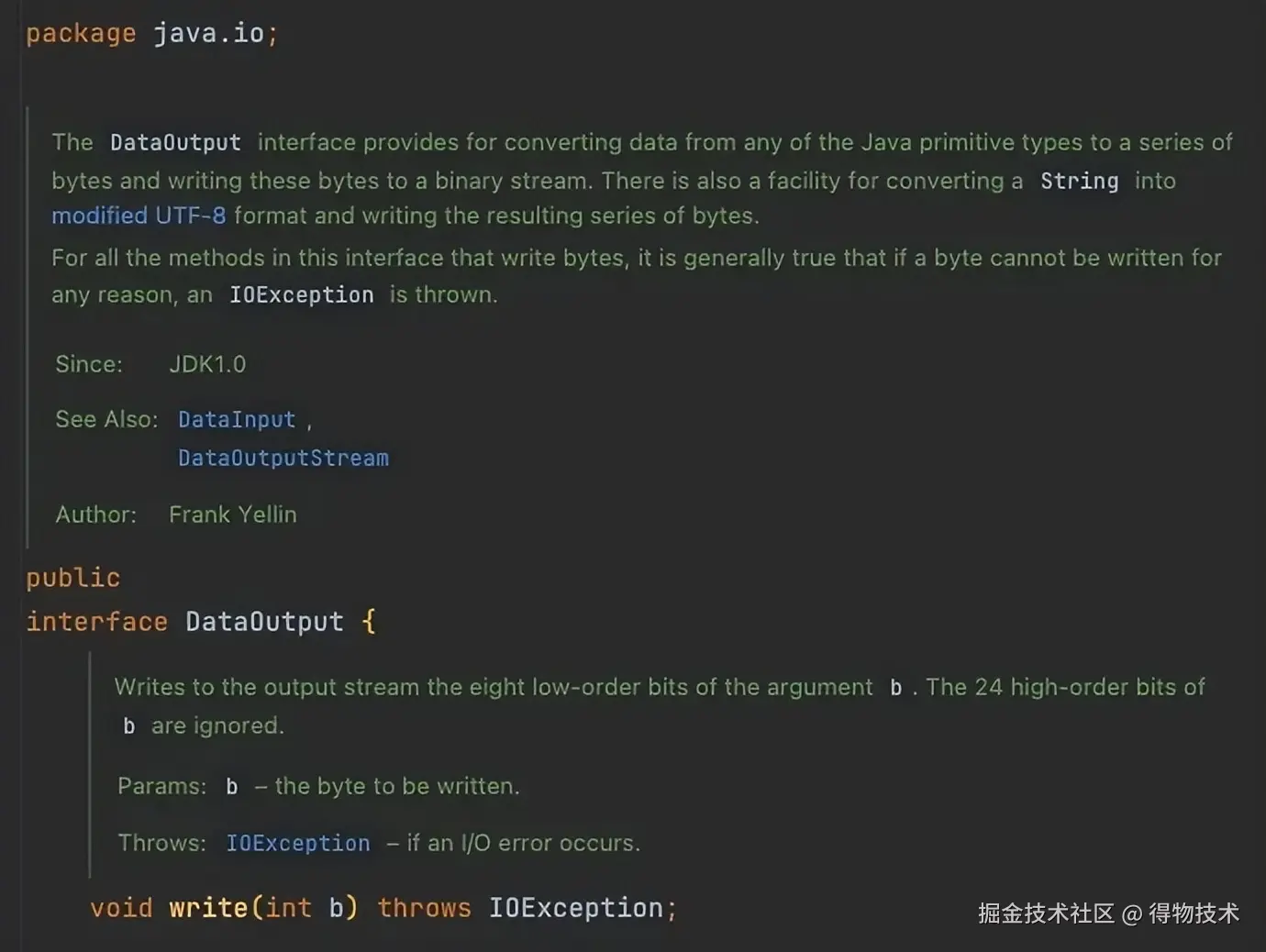
java.io.DataOutput
对象图遍历
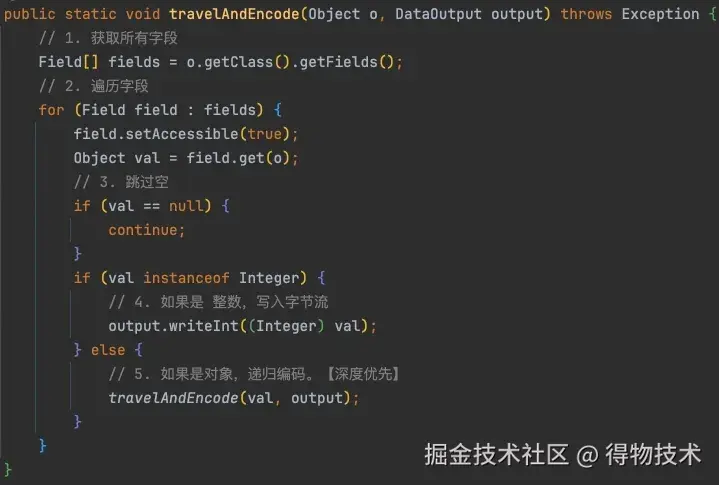
字节流布局
最终呈现出来的字节流层面的数据布局会是这样:
看起来没毛病,唯一的问题就是不好解码。
当解码端收到一个16字节的字节流以后,它分不清哪块数据是A对象的,哪块数据是B对象的。甚至都分不清这到底是4个int32还是2个int64。
这个问题需要编码格式来解决。
编码格式
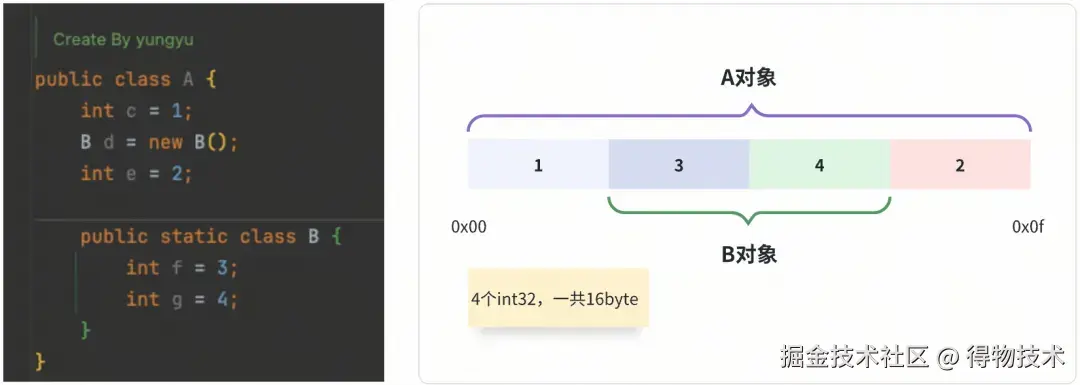
上面遗留的问题,聪明的你肯定想到了答案。
就是因为编码产物太太太简陋了,整个过程中只是一股脑的把树拍平,把叶子节点的值写入字节流,缺少结构元数据。
最最最重要的结构元数据就是数据块的边界,上述4个数据块,最起码应该添加3个边界标识。
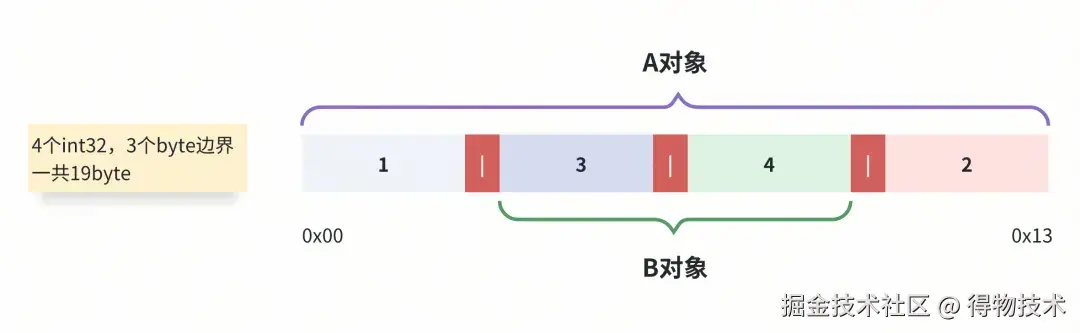
我们先用我们耳熟能详的JSON格式来理解下编码格式这个事情。
伪代码
JSON是这样解决这个问题的:
JSON协议在嵌套的POJO上用 {} 来作为边界,POJO内部的字段键值用 , 来做边界, : 拆分字段键值。
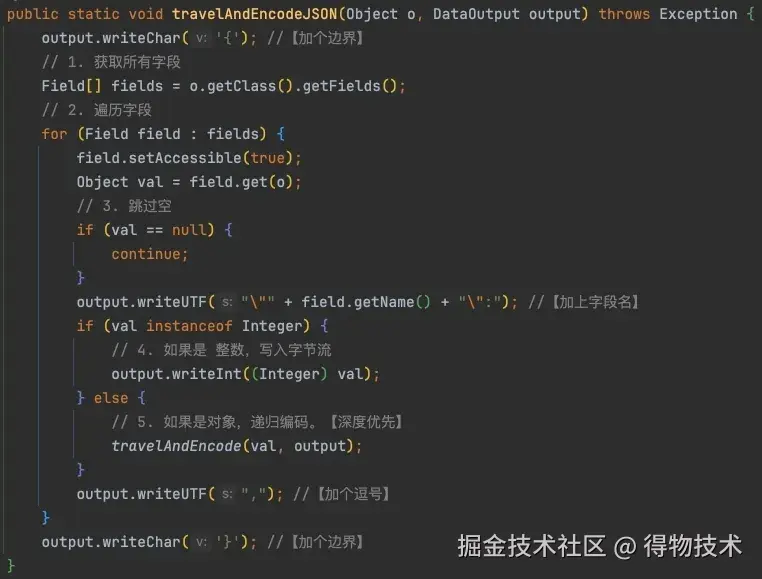
字节流布局
结果就变成这样:
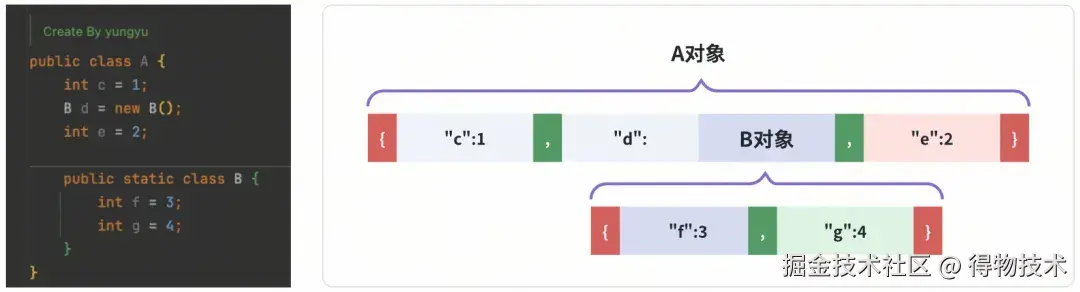
这样在解码的时候,可以通过 { 、 } 、 , 、 : 等token 来切割JSON字符串,判定数据块边界 并恢复出对象图。
三、Hessian编码格式
接下来我们可以开始介绍Hessian的编码魔法了。
需要强调的是:Hessian跟JSON不同,Hessian是二进制格式。如果一个字节流直接按字符集解码不能得到一个完整的、有意义的字符串,那它就是二进制编码数据。
Hessian在编码时,按数据块类型 为每一个数据块添加一个前缀字节(byte) 作为结构元数据,这些元数据 和数据块一起,交给解码端使用。
数据块
对象图里的每一个节点,都是一个数据块。
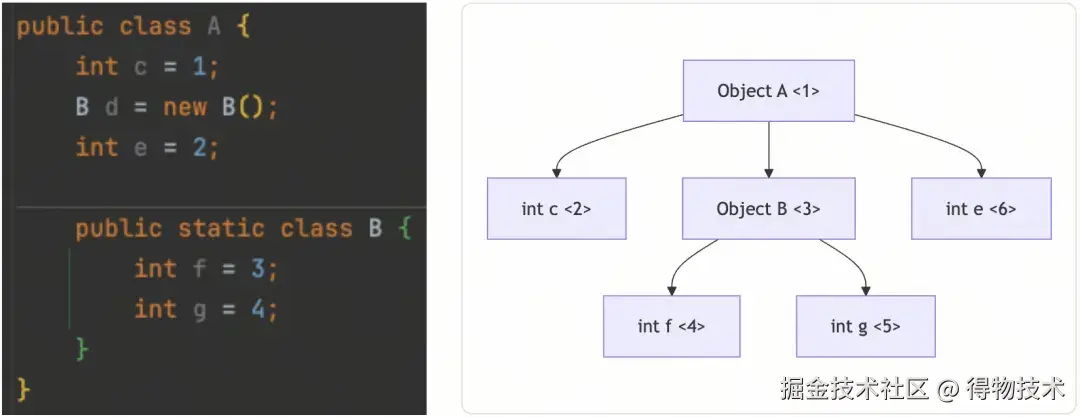
如上图所示,以A对象为根的对象图,一共有6个数据块。
数据块标签(tag)
Hessain在编码每一个数据块时,都会根据数据块的类型在字节流中写入一个前缀字节 (0-255 ),这个字节说明了数据块的语义和结构。
以int32为例,其最基础的编码格式如下:

除该基础编码格式外,int32的编码还有其他变体。
上述 I 就是整数类型的tag。解码端读取tag后,按tag值来解码数据。
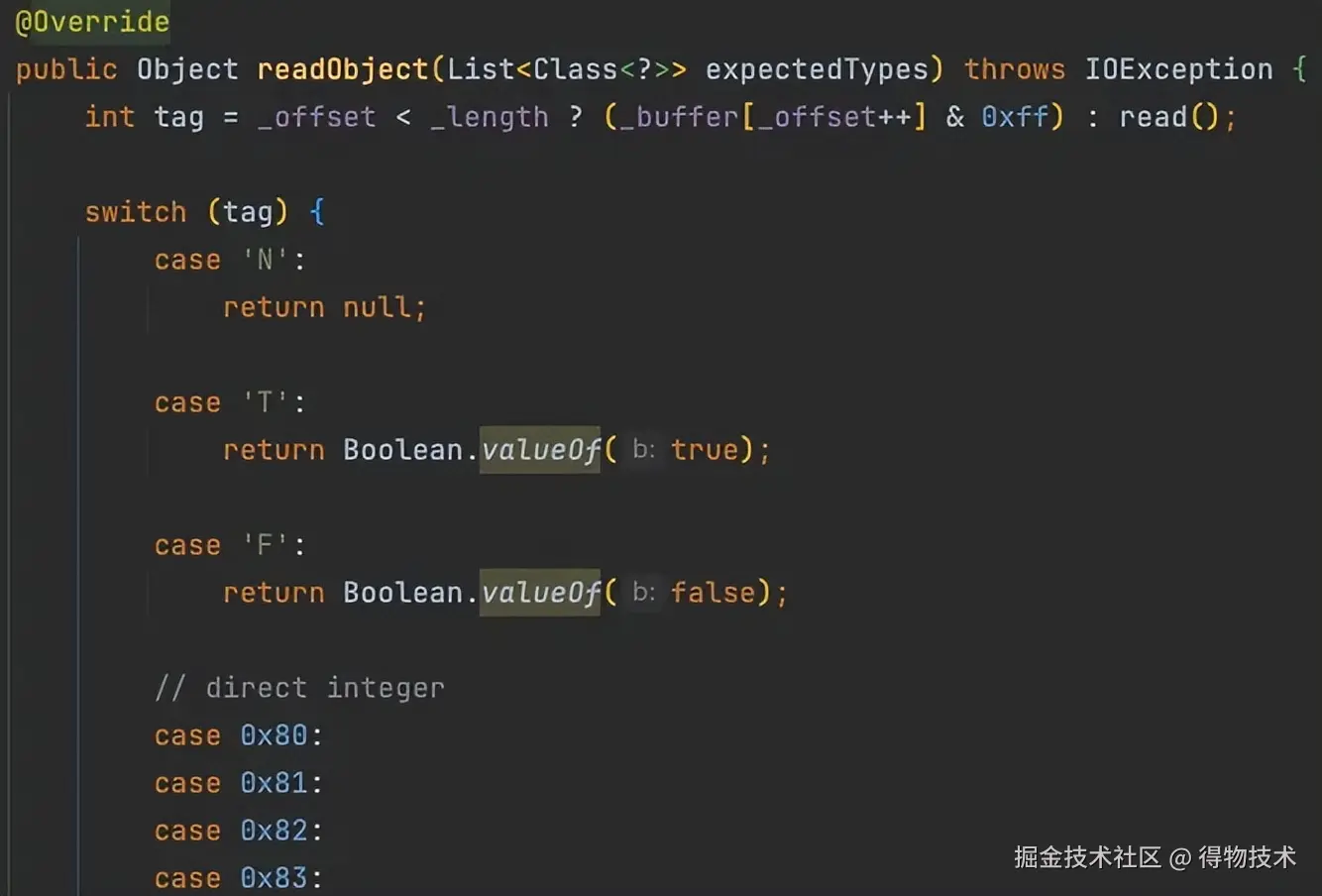
com.alibaba.com.caucho.hessian.io.Hessian2Input#readObject(java.util.List<java.lang.Class<?>>)
由此延伸、拓展,其他的数据类型都是类似的模式。常见数据类型及其对应的tag值如下:
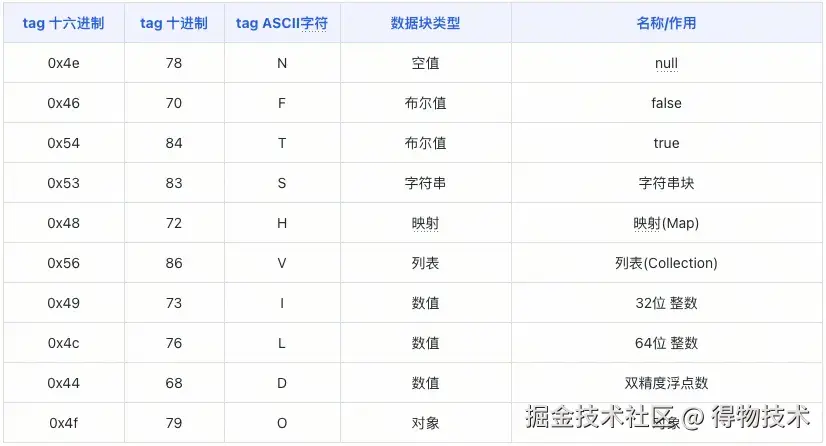
值得注意的是,N 、F 、T三个tag是自解释的,和固定值映射、绑定。
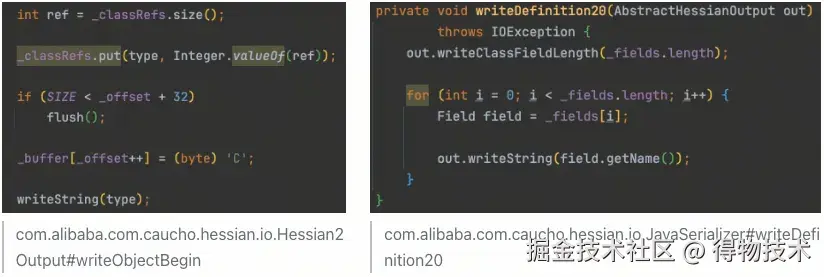
POJO编码
POJO是一种特殊的数据块 ,Hessian将POJO的结构 和值拆开,分别编码。
POJO结构编码
POJO结构 的tag为C,对照int32的编码格式,POJO结构的编码格式如下:

举个例子:

编码POJO时,Hessain会将POJO的类名、字段名列表写入字节流,供解码端使用。后续编码POJO字段值时,需要按照字段名列表 (如上述bb 、cc )的顺序来编码字段值。
POJO字段值编码
POJO字段值 的tag为O,对照int32的编码格式,POJO字段值的编码格式如下:

举个例子:

可以看到,编码POJO字段值的时候,在tag后面有一个POJO结构序号。
这是Hessian的一个数据复用的小技巧。
POJO结构复用
JSON协议有一个缺点,那就是重复数据带来的存储/传输开销。举个例子:
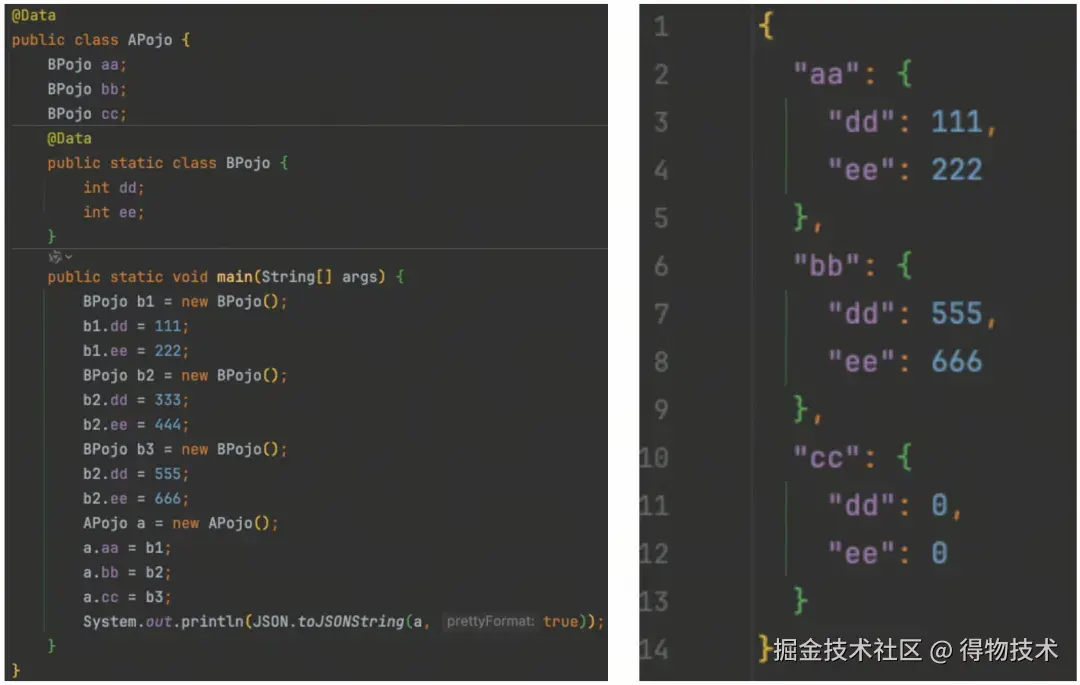
如上图,B类型的字段名(dd 、ee )在编码产物中重复出现!
Hessian希望解决这个问题,同一类型的多个POJO对象在序列化时,只需要在第一次的时候编码类名、字段名等元数据,后续可以被重复的引用、使用,无需重复编码。
如果用Hessian来编码,结果会是这样:
数据布局

数据布局详解
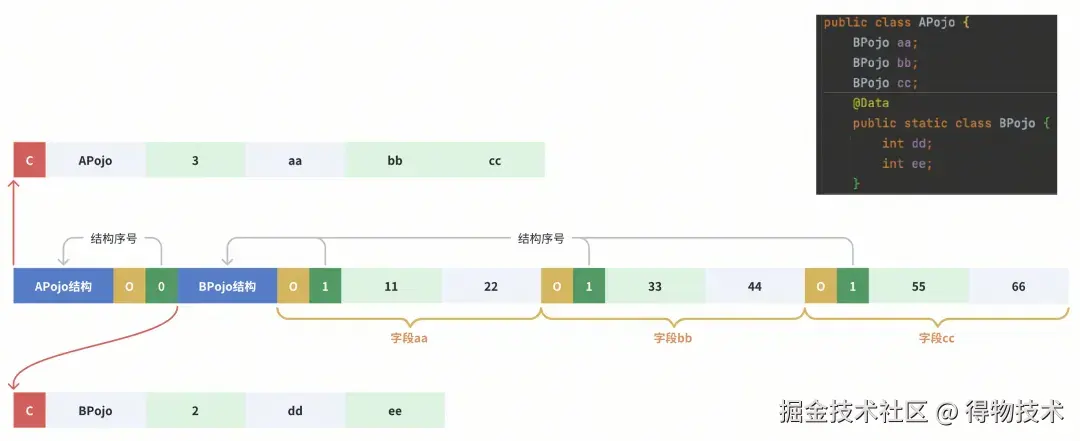
如上图,APojo、BPojo的字段名只会编码一次。多个BPojo对象在编码时会通过结构引用序号(1) 来引用它。相对JSON,Hessian避免了多次编码BPojo字段名的开销。
为什么APojo的序号是1、BPojo的序号是2?
Hessain在编码过程中,每次遇到一个新的、没有处理过的新POJO类型时,会给它分配一个从0开始、单调递增的序号。
遥相呼应的,解码侧 每次解码一个tag为C 的POJO结构数据块时,也会按解码顺序维护好其索引序号。
四、Hessian编码细节
到现在,我们已经对Hessian编码有了一个的概括性的认识,接下来我们来看看一些值得注意的细节。
重复对象复用
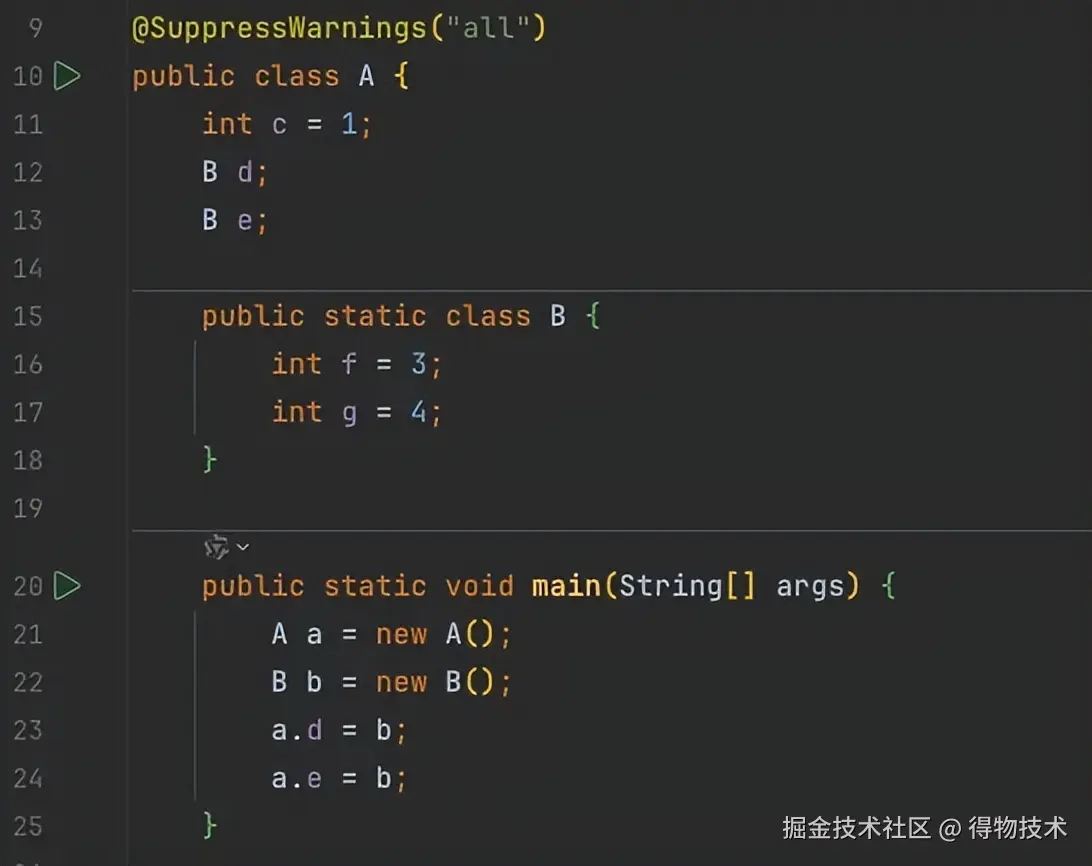
A对象里有两个字段(d、e)指向同一个对象B。如果不做处理,会因为重复编码而带来不必要的开销。
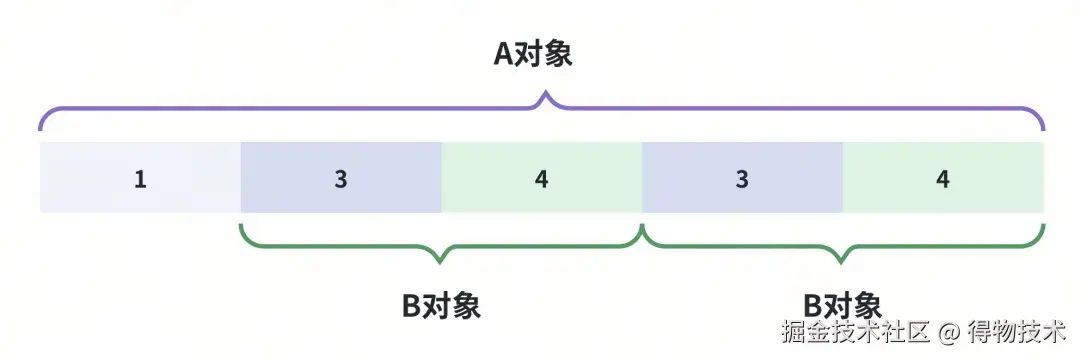
相同的一个B对象,因为被两个字段重复引用,导致2次编码 、产生2份数据空间占用!
如果只是有额外的开销,没有可用性问题那都还好。关键是在循环引用 场景下,会因为引用成环 导致递归进行对象图遍历时触发方法栈溢出!
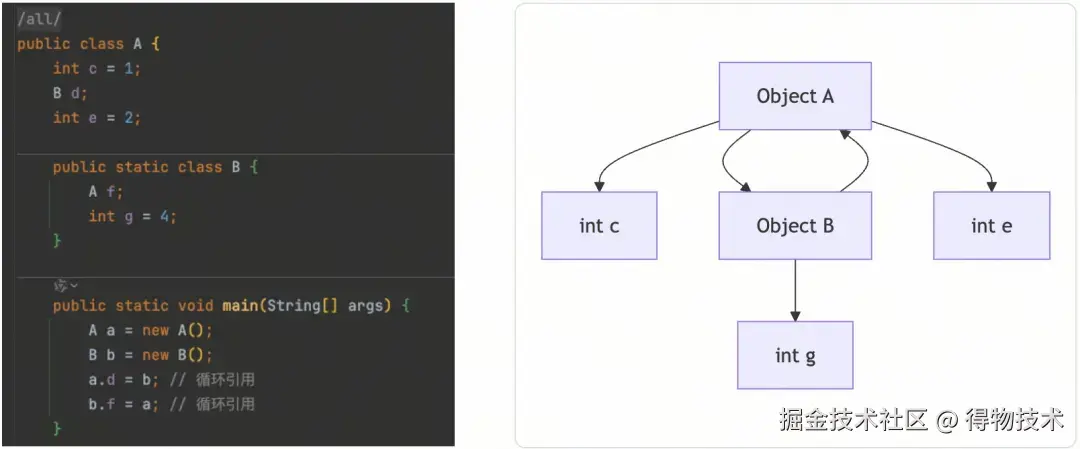
循环引用是重复引用的特例,只要将重复引用处理掉,循环引用也就没问题了。
Hessian通过对象引用 来解决这个问题。在对象图遍历过程中,遇到一个之前没有遇到过、处理过的POJO对象时,会给它分配一个从0开始、单调递增的序号。
后续再次需要序列化相同的对象时,直接跳过 编码流程,将这个对象的序号写入字节流。
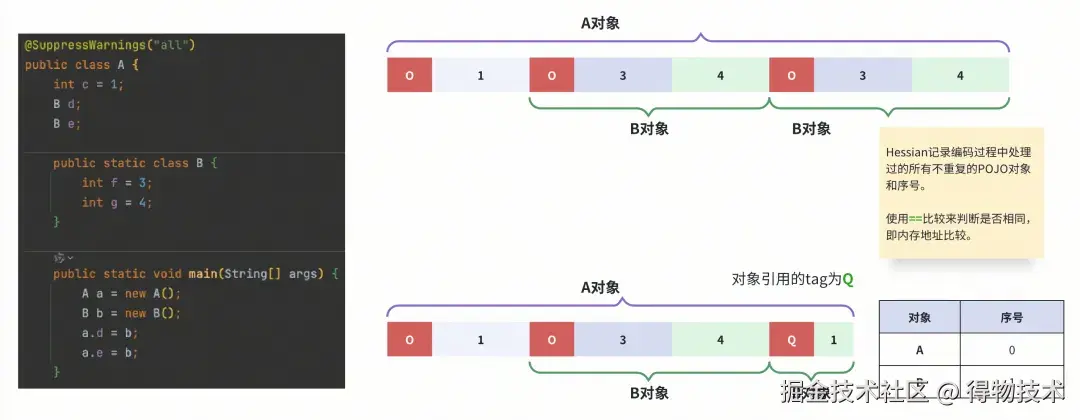
解码时,解码侧按相同的顺序来恢复出引用序号表,解码后续的对象引用。
小整数内联(direct)
很多编码类型,都需要在tag后再维护一个整数类型的字段。比如:
- POJO的编码tag O 需要一个整数来引用POJO结构引用序号。

- 类似String的变长类型需要一个整数来标识变长数据的长度。

当字符串很短,就比如 "hi" 吧,短字符串编码格式的长度字段可能比实际字符数据还大(用4字节存储长度2),效率低下。
tag分段
Hessian将一些tag值的语义富化,让它既体现数据类型,也体现小数值。
因为tag是一个byte(int8) ,取值范围是0-255 ,每个tag标识一种特定的数据类型(int、boolean等),但是这些数据类型最多几十种,取值范围内还有很大的数值区间没有被使用,其实比较浪费。那我们就可以把这些空闲的tag值,挪作他用,提升tag数值空间利用率。
我举个例子,注意这个是参考Hessian思路的一个简单示意,具体的Tag值和Hessian无关。
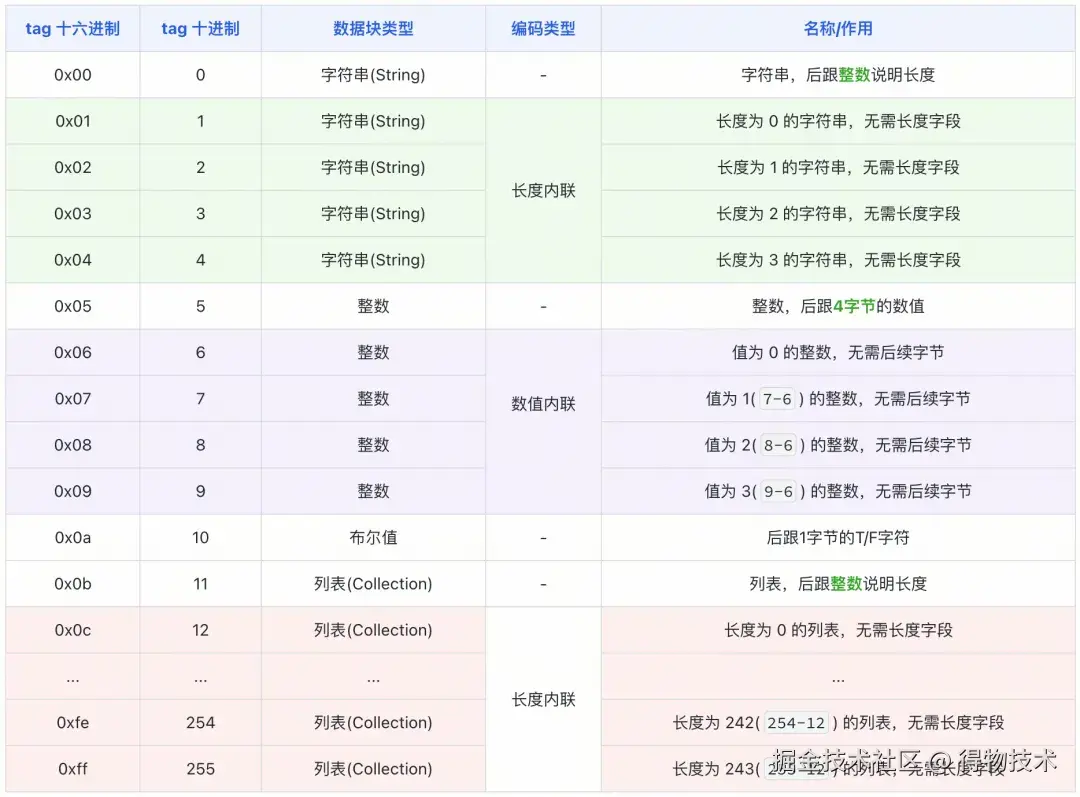
长度内联
对于长度≤31 的字符串,Hessian用tag同时编码类型和长度。
- 当0 <= tag <= 31 时,标识后续的数据块为字符串。
- tag的数值即为后续数据块的长度。
示例如下:
序号内联
当结构引用序号<=16 时,Hessain用tag同时编码类型和序号。
-
当0x60 <= tag <= 0x70 时,标识后续的数据块为POJO字段值。
-
tag - 0x60的值,即为POJO结构(类名+字段名)引用序号。
示例如下:

相关源码如下:
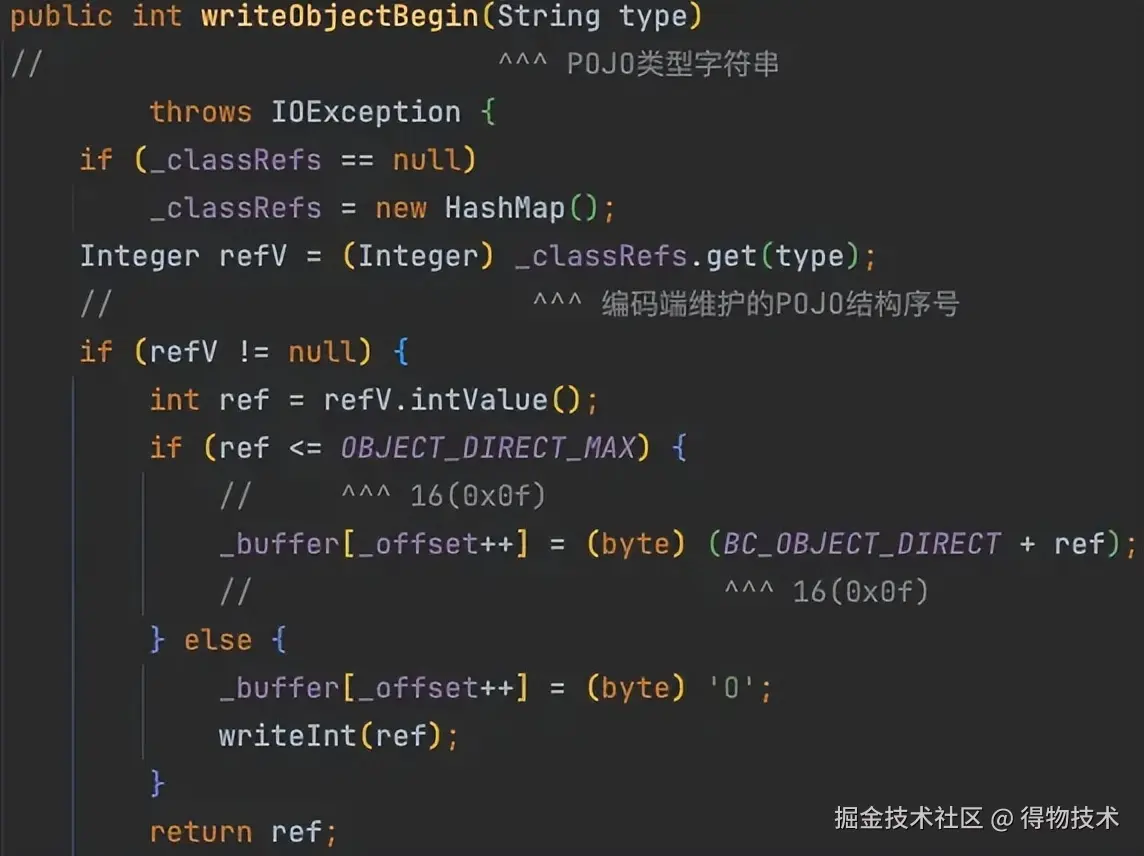
com.alibaba.com.caucho.hessian.io.Hessian2Output#writeObjectBegin
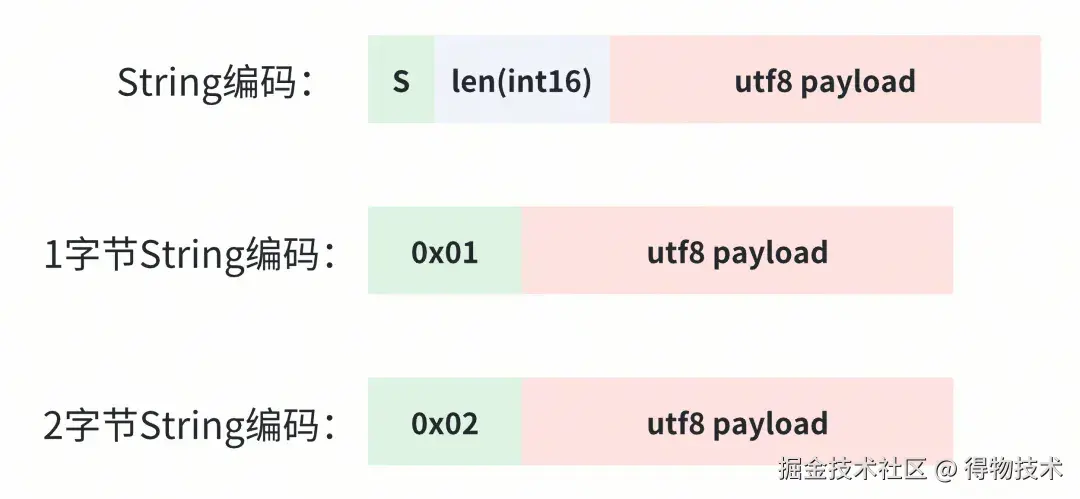
字符串编码
Hessian编码字符串的关键流程是:字符串分段+不同长度的子串使用不同的tag。
- 分段原则
字符串会被分割为若干块,每块最大长度为32768(0x8000)。前N-1块均为完整长度的子串(32768字节),使用固定tag R标识;最后一块为剩余部分,长度范围为0-32768字节,根据实际长度选择动态tag。
- 尾段tag的选择基于尾块的长度决定
-
- 长度≤31(0x1F):使用单字节tag 0x00-0x1F直接内联长度值。
- 32≤长度≤1023(0x3FF):使用tag 0 后跟1字节长度(大端序),10bit的计数空间由tag字节和长度字节共同提供。这个地方有点绕,看下代码吧。
- 长度≥1024:使用tag S后跟2字节长度(大端序)。
- 相关源码
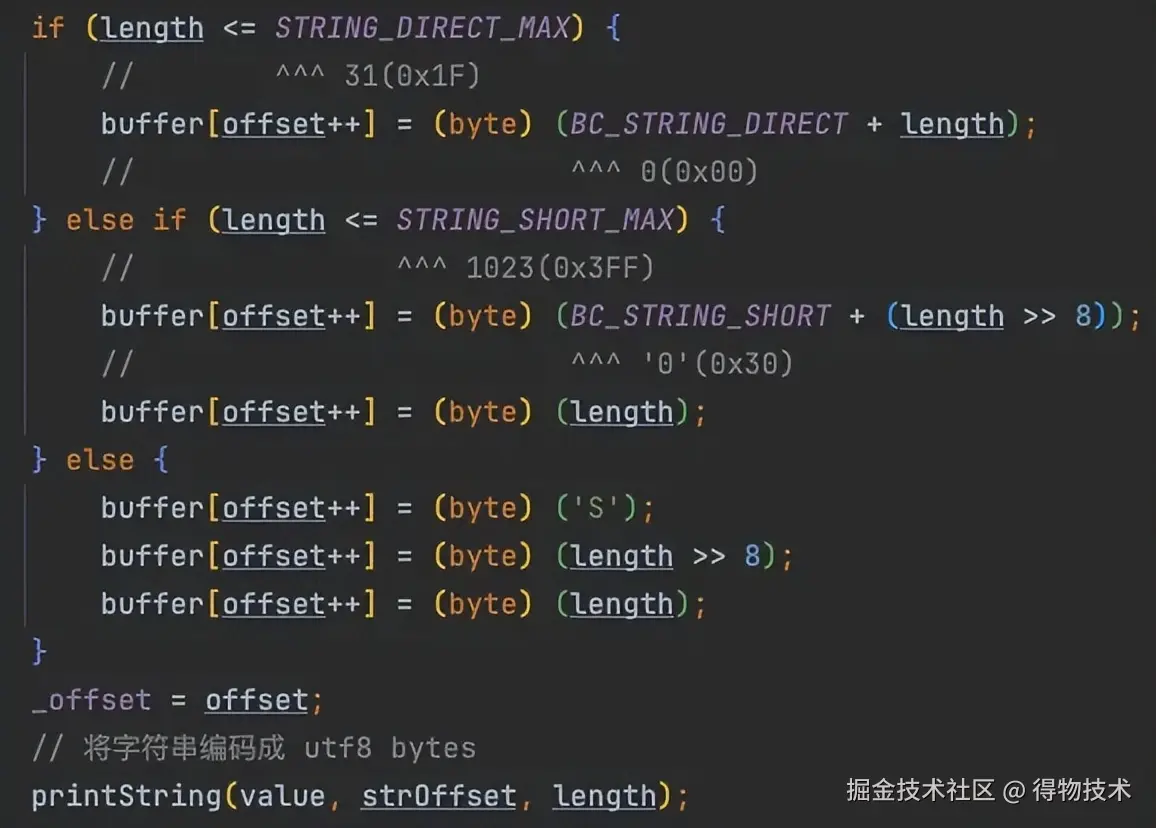
com.alibaba.com.caucho.hessian.io.Hessian2Output#writeString(java.lang.String)
这种设计通过减少长字符串的冗余长度标记,在保持兼容性的同时显著提升了编码效率。
整数压缩
基础编码
整数(int32)的的取值范围很大(-23^31 - 2^31),保守的编码格式会用4个byte来编码整数。

但是日常使用中,我们会大量使用小整数,比如1、31。这时候如果还用4字节编码就很不划算啦~
变长编码
Hessian根据整数的值范围,动态的选择不同的编码方式,且不同的编码方式有不同的tag:
- 单字节整数编码 :类似【长度压缩】,tag中直接内联数值
适用范围:-16 到 47(共64个值)
编码方式:使用单字节,值为 value + 0x90(144)
例如:0 编码为 0x90,-1 编码为 0x8f,47 编码为 0xbf
- 双字节整数编码
适用范围:-2048 到 2047
编码方式:首字节为 0xc8 + (value >> 8),后跟一个字节存储value剩下的bit。
这种编码可以表示12bit有符号整数
- 三字节整数编码
适用范围:-262144 到 262143
编码方式:首字节为 0xd4 + (value >> 16),后跟两个字节存储 value 的高8位和低8位。
这种编码可以表示19bit有符号整数。
- 五字节整数编码
适用范围:超出上述范围的所有32位整数
编码方式:以 'I' (0x49)开头,后跟4个字节表示完整的32位整数值。
- 相关源码:
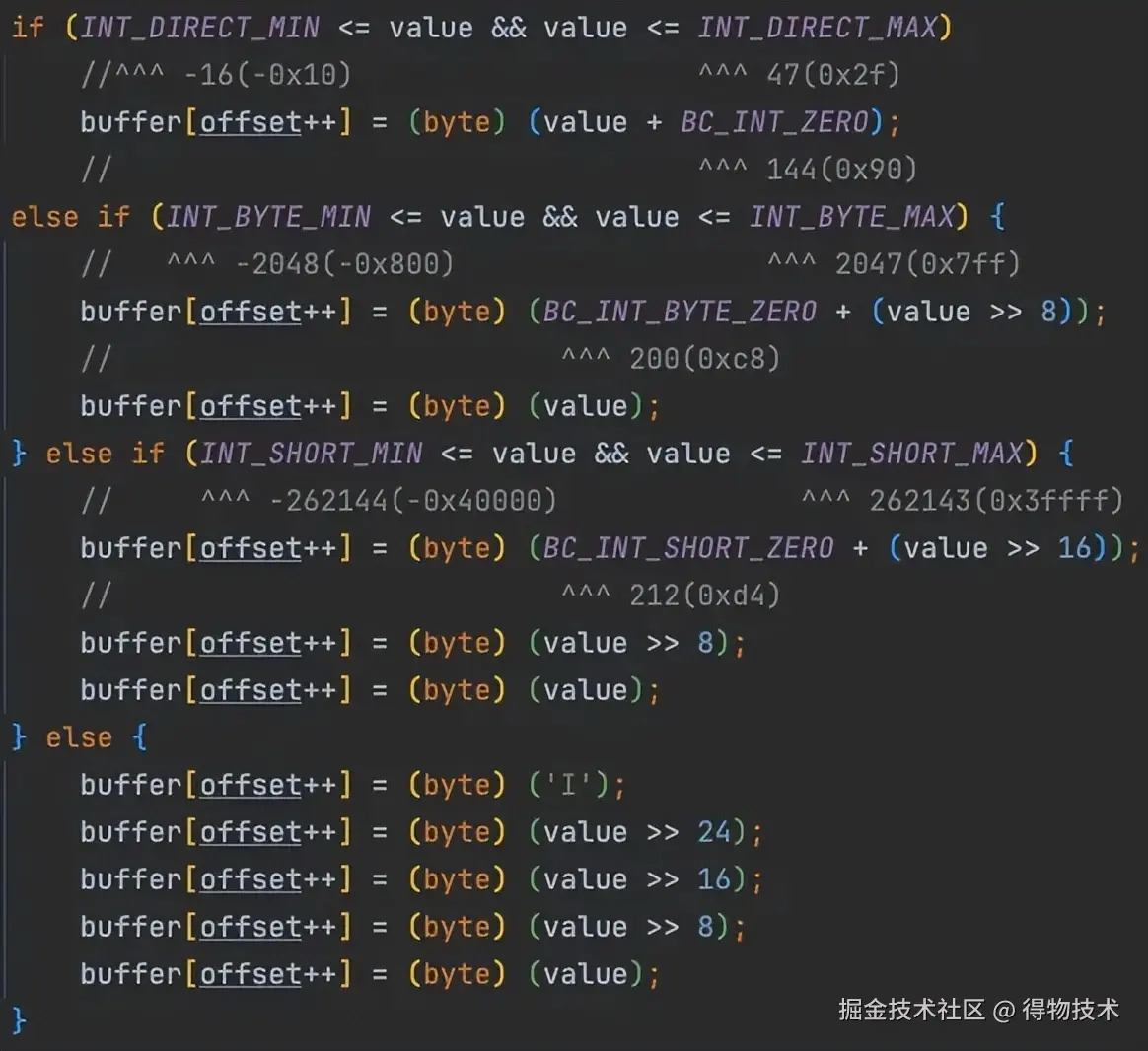
com.alibaba.com.caucho.hessian.io.Hessian2Output#writeInt
收益
- 小整数(如 0、-1)仅需 1字节 ,而传统 int32 固定4字节。
- 大整数动态扩展,避免固定长度浪费(如 1000 仅需2字节)。
其他的数值类型比如int64也有类似的机制。
五、总结
Hessian专为Java优化,采用高效二进制协议,通过对象图遍历和编码协议实现对象与字节流的转换,利用数据块标签、重复对象复用、数据压缩等机制,提升编解码效率和数据压缩率。
本文没有去展开Hessian的代码细节,而是尽可能深入浅出的介绍了Hessain的核心编码原理,以帮助读者建立对Hessian的宏观认知,从而可以更好的去理解和使用它。
尽管不同语言/生态的序列化框架选型让人眼花缭乱,但是各自需要解决的问题和解决问题的思路都大同小异;我们对Hessain原理的认识可以迁移到其他序列化框架,甚至自己写一个领域特定的序列化框架。
相关内容均为笔者走读源码整理而来,如有疏漏,欢迎指正。
参考:
- Hessian 2.0 Serialization Protocol (*hessian.caucho.com/doc/hessian...
- Hessian 2.0 序列化协议(中文版) (www.diguage.com/post/hessia...
- Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 (www.diguage.com/post/hessia... )
- Hessian 协议解释与实战(二):长整型、二进制数据与 Null (www.diguage.com/post/hessia... )
- Hessian 协议解释与实战(三):字符串 (www.diguage.com/post/hessia... )
- Hessian 协议解释与实战(四):数组与集合 (www.diguage.com/post/hessia... )
- Hessian 协议解释与实战(五):对象与映射 (www.diguage.com/post/hessia... )
- Hessian 源码分析(Java) (www.diguage.com/post/hessia... )
往期回顾
-
前端日志回捞系统的性能优化实践|得物技术
-
得物灵犀搜索推荐词分发平台演进3.0
-
R8疑难杂症分析实战:外联优化设计缺陷引起的崩溃|得物技术
-
可扩展系统设计的黄金法则与Go语言实践|得物技术
-
营销会场预览直通车实践|得物技术
文 / 羊羽
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。