不是所有"下降"都值得恐慌,也不是所有"增长"都值得庆祝。
真正决定成败的,是你能否在数据异动发生的那一刻,就看清它背后的"为什么"。
智能问数时代,企业不再满足于"看到数据",更渴望"理解数据"。尤其当核心指标突然跳水、区域业绩悬殊拉大、转化率悄然滑坡......业务方的第一反应不是"查报表",而是:"到底谁动了我的奶酪?"
Aloudata Agent 最新升级的智能归因分析能力,不满足于告诉你"发生了什么",更执着于揭示"为什么发生"------而且是以一种可组合、可追溯、可解释、可复用的方式,把每一次波动、每一场对比、每一个异常,都变成一次结构化的业务诊断。
而这一切能力的基石,是 Aloudata 自主构建的------指标语义层。
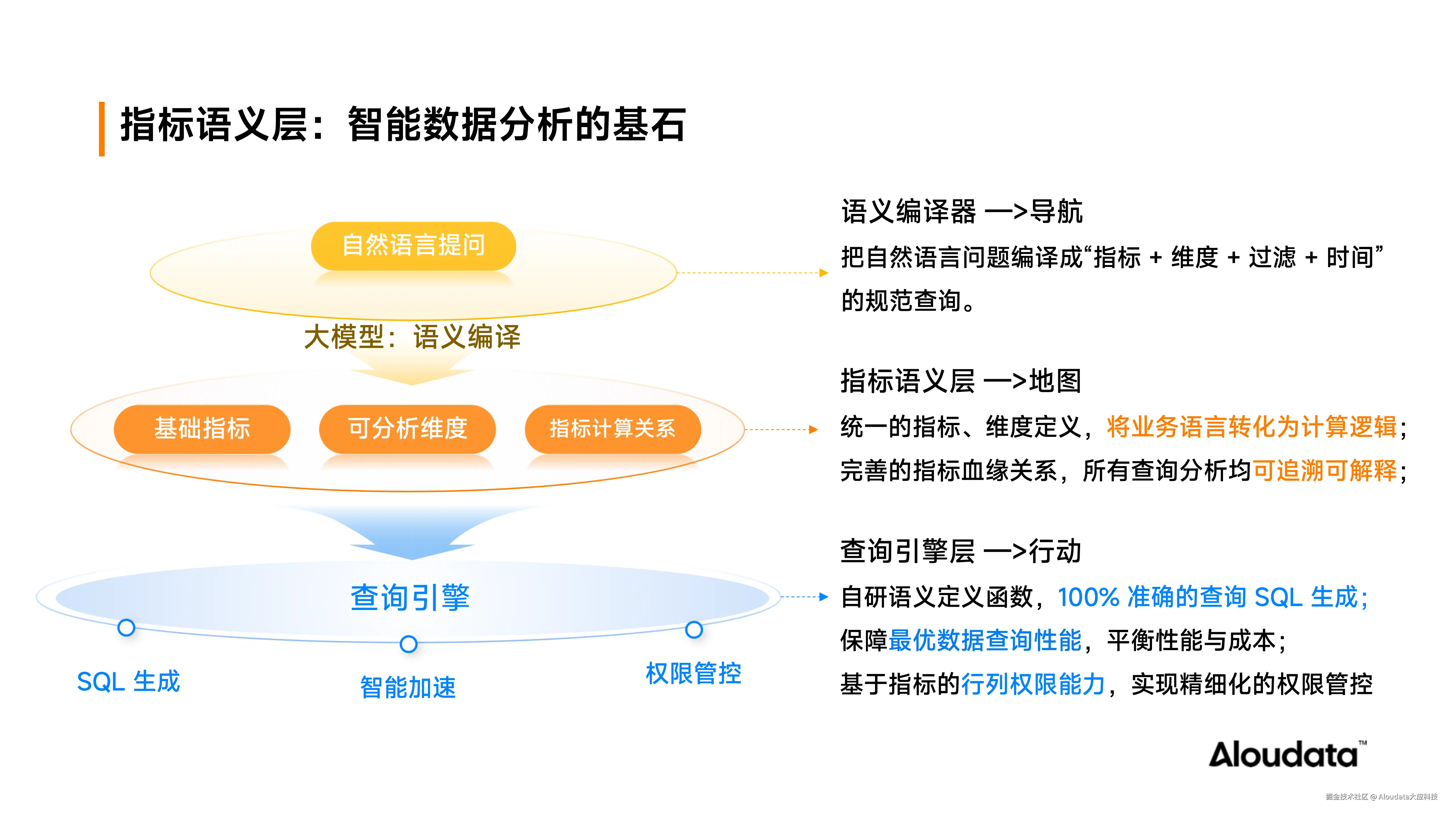
指标语义层:智能数据分析的基石
指标语义层在 Aloudata Agent 中扮演着承上启下的核心角色。它系统化管理指标、维度、业务计算逻辑及指标间的血缘关系,如同一张详尽的"业务地图",为用户和查询引擎提供统一的语义理解基础。当用户进行问数或归因提问时,大模型借助语义层的信息,能够准确识别用户意图,将其编译为包含指标、维度、过滤和时间查询等规范的查询请求(MQL),进而转化为 100% 准确的、 可执行的 SQL 语句。
这一过程不仅实现了自然语言到结构化查询的高精度转换,还通过查询引擎确保了数据权限管控与查询性能的优化。更重要的是,指标语义层具备语义纠正和口径统一的能力。例如,当用户表述的"销售额"与语义层中定义的"销售金额"存在术语差异时,语义层能够自动对齐概念,消除歧义,保障查询的准确性。
指标语义层如同丰富的地图,大模型的语义编译能力如同导航。用户凭借地图和导航,通过查询引擎层进行数据查询。这一模式具有两大优势:一是路径清晰,用户可在地图上明确每个指标和维度的业务含义,对业务用户而言具有可解释性;二是路径准确,只要大模型语义编译无误,基于地图的行动便不会出现问题。
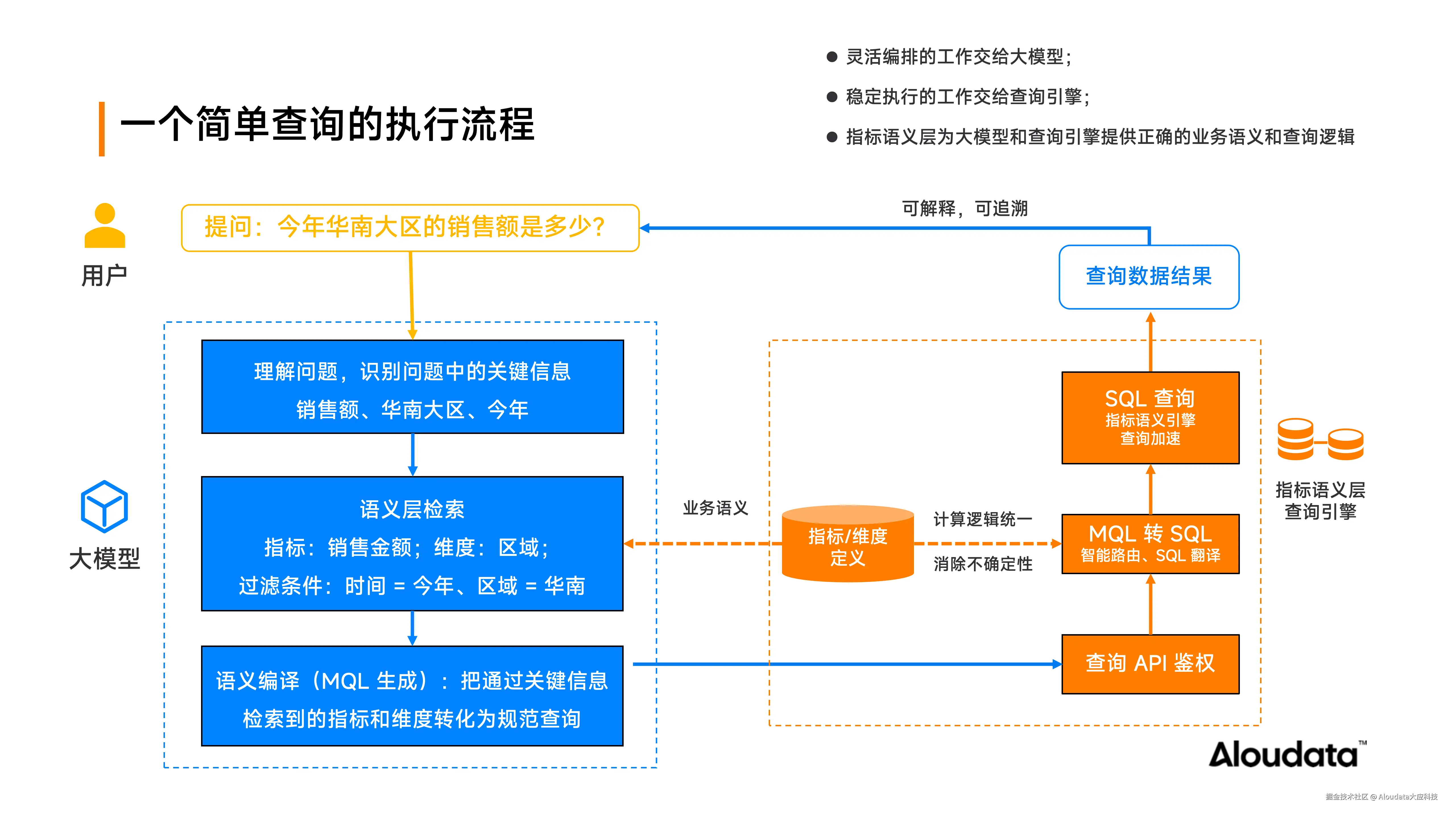
以用户提问"今年华南大区的销售额是多少"为例。首先,由大模型对自然语言进行语义解析,精准识别关键要素:目标指标("销售额")、限定维度("华南大区")及时间范围("今年")。随后在语义层进行检索,寻找指标、维度及可匹配的维值,进行准确的过滤条件拼装,完成从自然语言到机器可理解语义的转化。
在语义编译阶段,系统生成指标查询语言 MQL(Metric Query Language),并触发前置的数据权限校验机制。该机制基于用户身份,动态验证其是否具备访问"销售额"指标及"华南大区"行级数据的权限,确保数据安全合规。
权限确认后,系统依托指标语义层完成 MQL 到 SQL 的精准转换。指标语义层作为核心枢纽,预先定义了各指标的业务口径、计算逻辑、数据来源表及聚合字段,有效消除了因语义歧义或口径不一致导致的查询偏差。即便"销售额"指标横跨多个业务域,其统一语义定义亦能保障计算逻辑的一致性与可复用性。
生成 SQL 语句后由高性能查询引擎执行。引擎结合物化加速、结果命中等机制,能够实现海量数据的秒级响应。最终返回结果,前端会依据数据特征智能匹配可视化图表,直观呈现分析结果。
在整个流程中,大模型承担"智能导航与灵活编排"角色,负责语义解析与查询路径规划;查询引擎专注"稳定高效执行",保障计算的准确性与性能;而指标语义层则作为"语义中枢",为大模型和查询引擎提供正确的业务语义信息和计算逻辑信息。
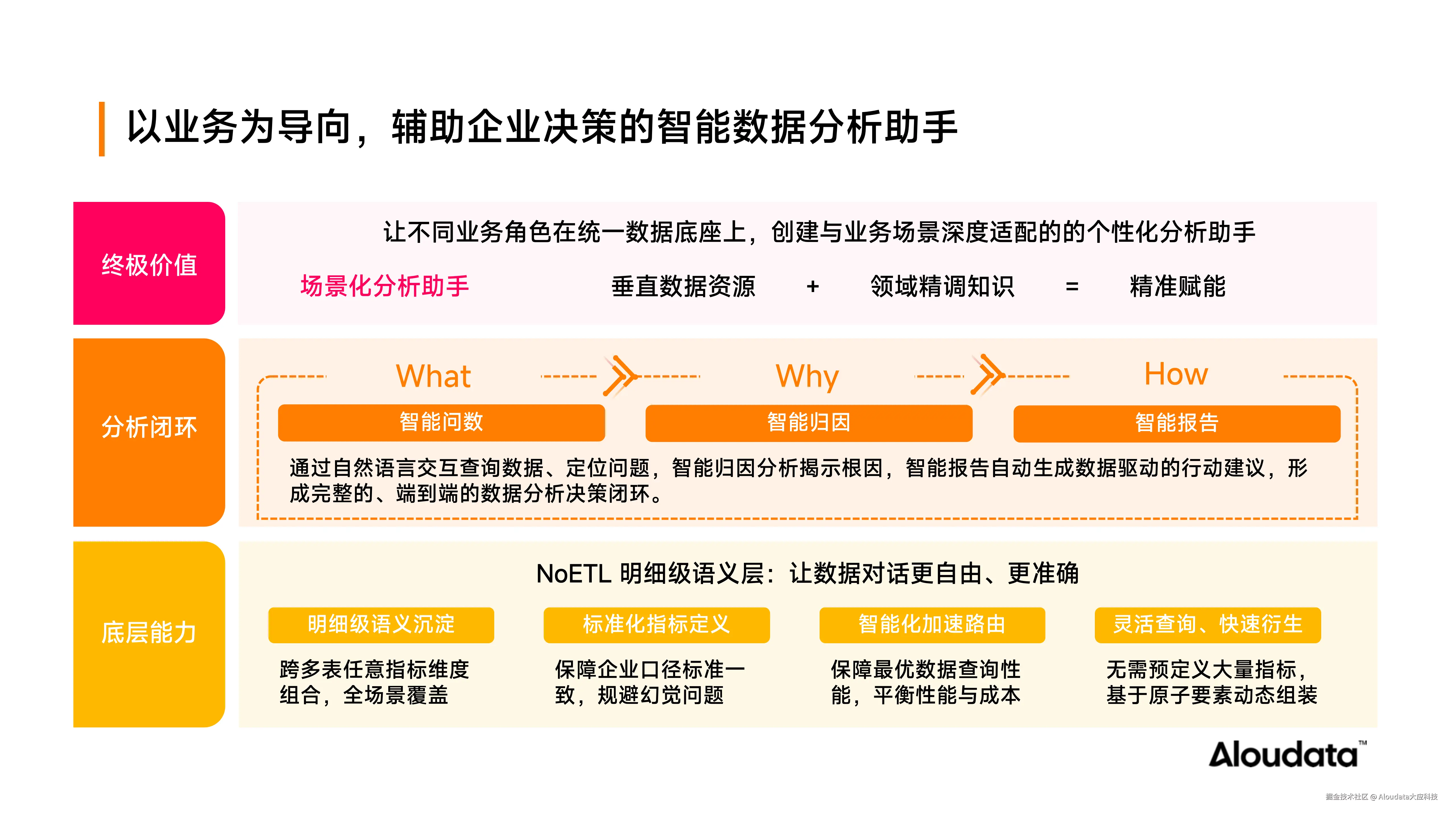
在数据分析领域,构建真正具备业务价值的智能 Agent,仅支持基础"智能问数"功能远远不够。我们以底层统一的指标语义层为核心能力基座,系统性地构建了覆盖"智能问数 → 智能归因 → 智能报告生成"的端到端闭环分析体系,实现从数据查询到洞察输出、从单点响应到完整决策支持的跃迁。
在产品架构设计上,将数据资源和领域知识以场景化助手的形式提供给用户,根据不同业务领域的知识,包装成业务领域独有的场景化分析助手,为不同业务角色提供差异化的数据分析支持。例如,将财务相关指标和知识放入财务分析助手,将人资领域相关指标和知识放入人资分析助手。不同业务人员进入 Aloudata Agent 进行归因分析和报告查询时,可使用不同的分析助手,获取精准赋能,避免不相关指标的干扰。
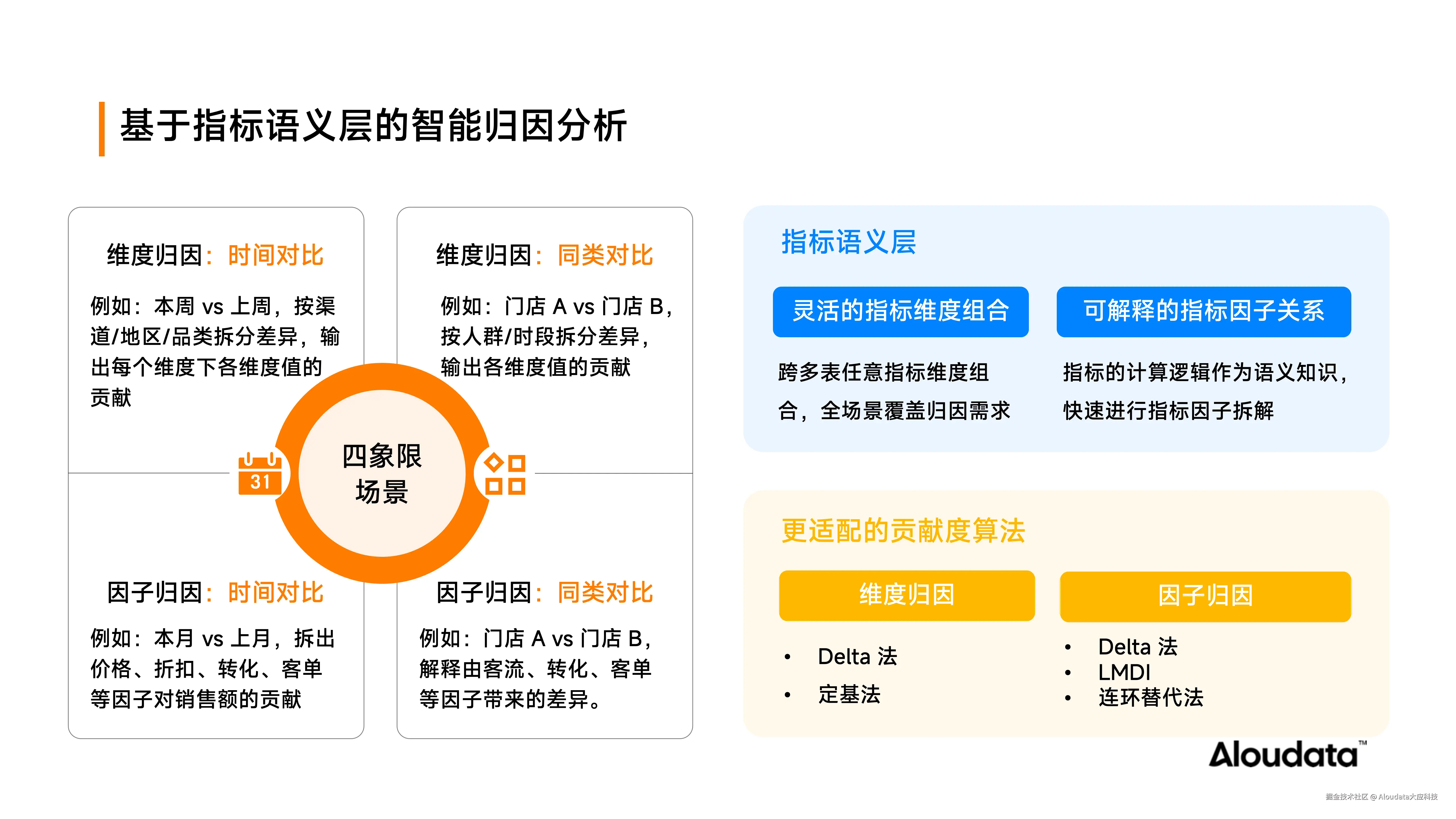
基于指标语义层的智能归因分析
Aloudata Agent 智能归因能力同样构建于统一的指标语义层之上,为业务用户提供多维度、多层次的根因洞察能力。
从归因方法论角度,智能归因可分为两大路径:
- 维度归因
识别影响目标指标变化的关键业务维度,例如渠道、区域、品类、门店等。系统通过维度下钻与贡献度计算,量化各维度对整体变化或差异的贡献权重,帮助用户锁定问题焦点。 - 因子归因
聚焦驱动目标指标变动的关联因子指标,通过指标间的计算逻辑与影响路径,系统可识别哪些前置因子的变化是导致最终结果差异的根本动因,从而提供更具操作性的改进方向。
在实际应用中,用户不仅关注时间维度上的波动归因(如"为何本月销售额下降?"),更普遍存在横向对比场景下的差异归因需求------即在整体指标表现平稳或达标的情况下,聚焦局部单元间的绩效差异,寻求可落地的优化路径。例如:大盘销售额整体稳定,但门店 A 与门店 B 业绩差距显著,究竟是哪些维度(如客群结构、促销策略、店员配置)或哪些因子指标(如进店转化率、连带销售率、坪效)导致了这一差距?
针对此类需求,在产品功能上将其区隔为四象限场景,覆盖"时间波动 vs. 横向对比 × 维度归因 vs. 因子归因"
在该框架下,指标语义层发挥三大核心作用:
1. 告别"大宽表依赖",灵活的维度归因下钻
传统归因依赖预构建的宽表,要求所有指标与维度必须物理聚合于同一张表中,限制了归因分析灵活性与扩展性。Aloudata Agent 通过指标语义层定义的指标和维度关系,无需依赖预先生成的大宽表即可实现多维归因组合。用户可自由选择分析维度,大模型自动检索指标与维度,生成对应的归因查询。这种方式极大地提升了分析灵活性,支持业务人员根据实际需求动态组合维度,快速定位影响指标变化的关键因素。
2. 计算逻辑沉淀,赋能大模型识别因子关系
对于复合指标(如 GMV、利润率等),其计算逻辑(如加减乘除关系)已在指标语义层明确定义沉淀。当用户进行因子归因分析时,大模型可自动识别指标间的计算关系,并据此识别影响因子。例如,若 GMV 定义为客单价乘以客户数,系统会自动将 GMV 变化归因于这两个因子的贡献,并通过贡献度计算各因子的影响程度。
对于非复合指标,也可以根据用户在"知识库"中预定义的指标因子树进行因子拆解归因。
3. 依据指标类型,智能匹配贡献度算法
归因分析的科学性,也取决于贡献度计算方法与指标类型的匹配度,不同指标类型需采用不同的计算方法。
- 规模型指标(如销售额、销售数量),进行维度归因时,具备可加性,其维度贡献可直接通过"各变化量 / 总体变化量"或"变化率占比"计算,逻辑直观、结果稳定;
- 比率型指标(如折扣率、利润率),指标本身的变化是其分子和分母共同作用、相互"博弈"的结果,在进行多维归因时,忽略分子分母则无法准确计算各维度对变化的具体贡献,进而无法判断指标变化背后的真实驱动因素和业务含义。
确定指标需要采用何种贡献度计算方法,需利用指标语义层信息,快速定位指标底层计算逻辑,映射到适配的贡献度算法,得到准确贡献度。
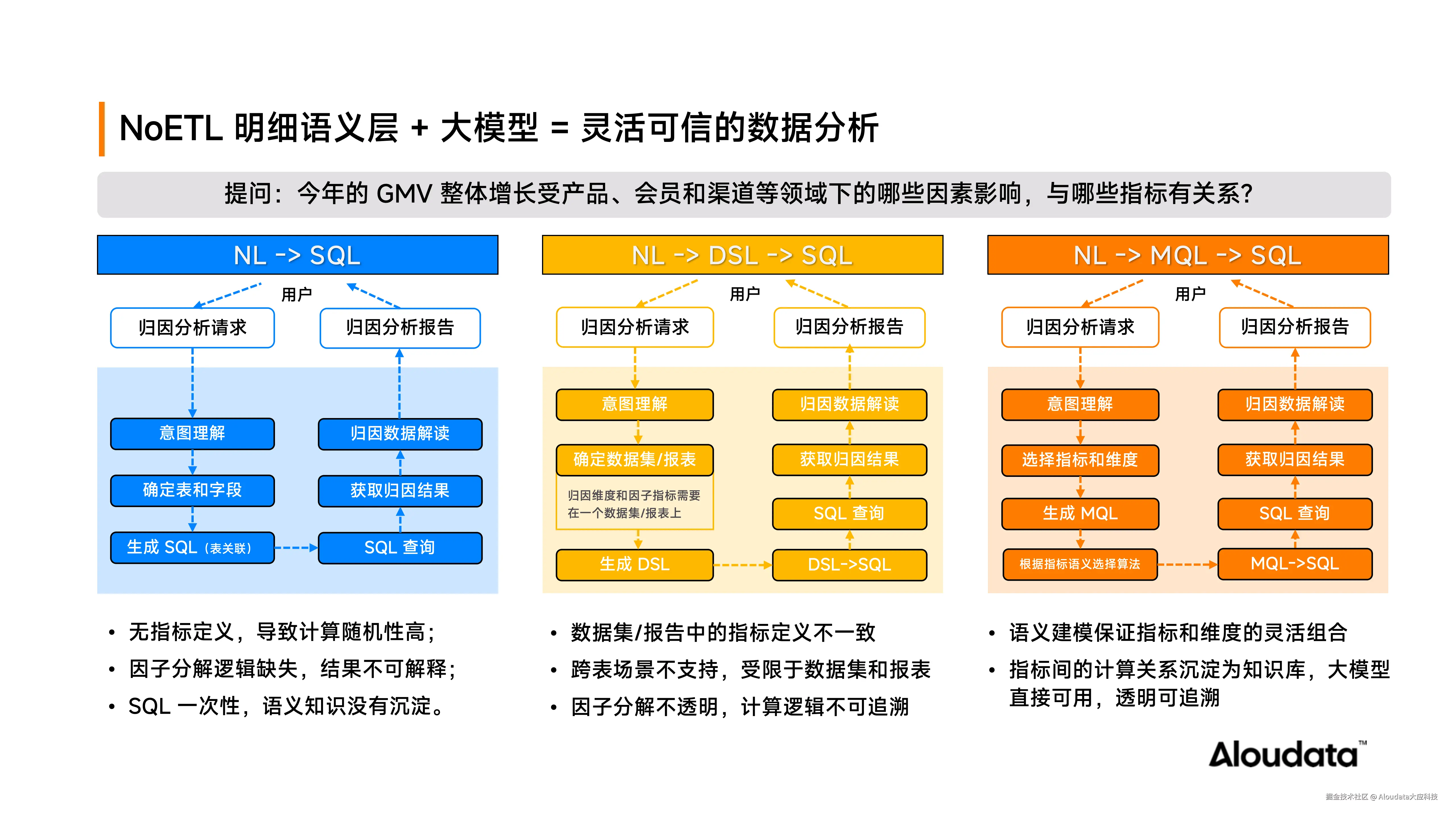
以用户提问"今年的 GMV 整体增长受产品、会员和渠道等领域下的哪些因素影响,与哪些指标有关系?"为例。
- 若采用 NL2SQL 的路径,大模型识别用户问题意图后,需跨多张物理表(产品域、会员域、渠道域)动态关联,SQL 生成复杂度高,大模型易产生幻觉,导致结果不稳定。生成 SQL 后进行查询、数据解读并返回分析报告,分析过程属于"一次性消费",无知识沉淀,无法向用户解释"为何选这些字段"、"因子如何影响 GMV"。
- 若采用 NL2DSL2SQL 的路径,用户需先创建包含产品、会员和渠道全部维度信息的数据集或报表,灵活性差、维护成本高。且不同用户可能使用不同数据集和报表进行 GMV 归因,指标口径不一致,因子分解不透明,归因结果不可比、不可信。
- 若基于指标语义层的归因路径。所有指标(如 GMV )与其可分析维度(产品类目、会员等级、渠道类型等)已在语义层完成沉淀。大模型只需理解用户意图,即可动态拼装维度组合(如"产品+会员"、"会员+渠道"),新增可分析维度也可直接应用于 GMV 指标进行维度归因,非常灵活。同时,在指标语义层指标间的计算逻辑具备完整可解释性。例如,当用户发现"GMV 增长主要受客单价与客户数驱动"的归因结论时,可反向追溯 GMV 的语义定义,看到其计算表达式为:GMV = 客单价 × 客户数。由此,业务用户可直观理解因子选择的依据,增强对分析结果的信任与认同。若用户基于领域认知,认为 GMV 还受其他非直接计算因子影响,我们也在"知识库"中提供归因知识沉淀的路径,帮助用户增加其他的归因知识。
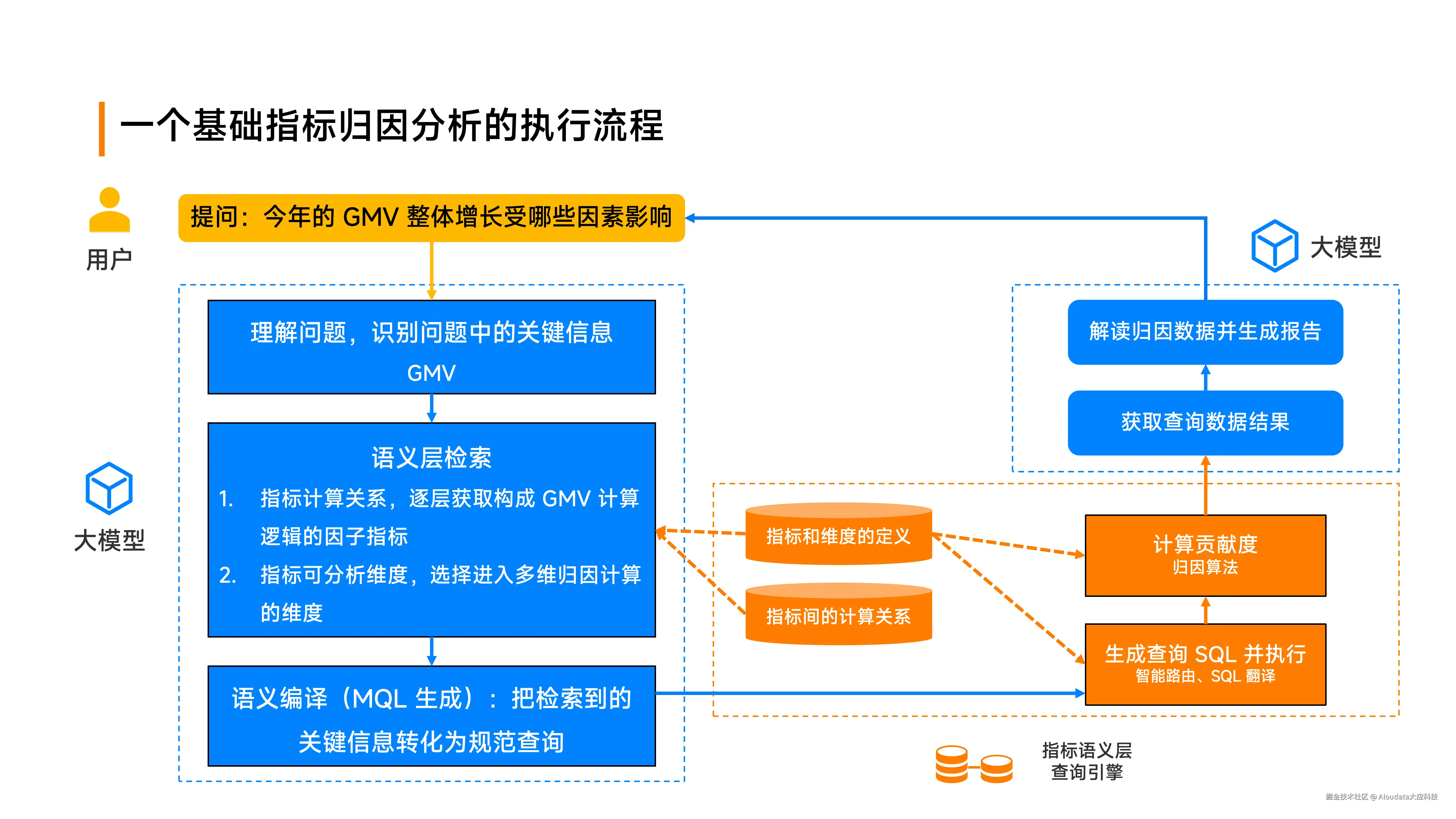
以基础指标归因分析流程为例,大模型拿到用户问题后,首先识别关键要素,确定要对哪个指标进行归因,然后带着指标信息在语义层检索相关维度和用户想要的维度,同时获取指标计算关系和计算逻辑的因子指标。在指标语义层获取全部信息后,进行语义编译和拼装,生成 SQL,计算贡献度,生成归因报告返回给用户。
通过这一架构,Aloudata Agent 实现了从"经验驱动的模糊归因"到"语义驱动的精准归因"的范式升级,让每一次差异分析都具备可组合、可追溯、可解释、可复用的业务价值,真正赋能用户在复杂数据环境中做出敏捷、精准、可执行的决策。