博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
Python Flask豆瓣图书数据分析可视化系统 Echarts图表展示 爬虫数据采集 计算机毕业设计
- 数据采集模块:基于requests爬虫技术,定向抓取豆瓣图书核心数据(含书名、作者、出版年份、评分等),支持批量采集与数据更新,确保数据全面性。
- 可视化分析模块:集成Echarts可视化库,通过数据概况大屏、年份评分散点图、作者出版数量TOP10柱状图、作者词云图等多元图表,直观呈现图书年份分布、评分趋势、作者热度等分析结果。
- 图书查询模块:提供图书信息列表展示功能,支持用户快速浏览爬取的图书详情,清晰呈现核心数据,满足信息检索需求。
- 数据存储模块:采用MySQL数据库,安全存储爬取的图书数据及用户信息,保障数据完整性与访问稳定性,为分析功能提供数据支撑。
- 用户管理模块:设置注册登录功能,实现用户身份验证与权限管控,保障系统使用安全性与私密性。
- 后台管理模块:管理员可通过后台界面进行数据维护,包括图书数据审核、更新、管理等操作,确保系统数据准确性。
- 技术架构:以Python为开发语言,Flask框架搭建Web界面,结合requests爬虫、MySQL数据库与Echarts可视化技术,构建集数据采集、存储、分析、展示于一体的豆瓣图书数据平台,兼具专业性与易用性。
技术栈:
python语言、Flask框架、MySQL数据库、requests爬虫技术、豆瓣图书、Echarts可视化、HTML
毕业设计:豆瓣图书数据分析可视化系统 Flask框架 python语言 requests爬虫 MySQL数据库(建议收藏)✅
2、项目界面
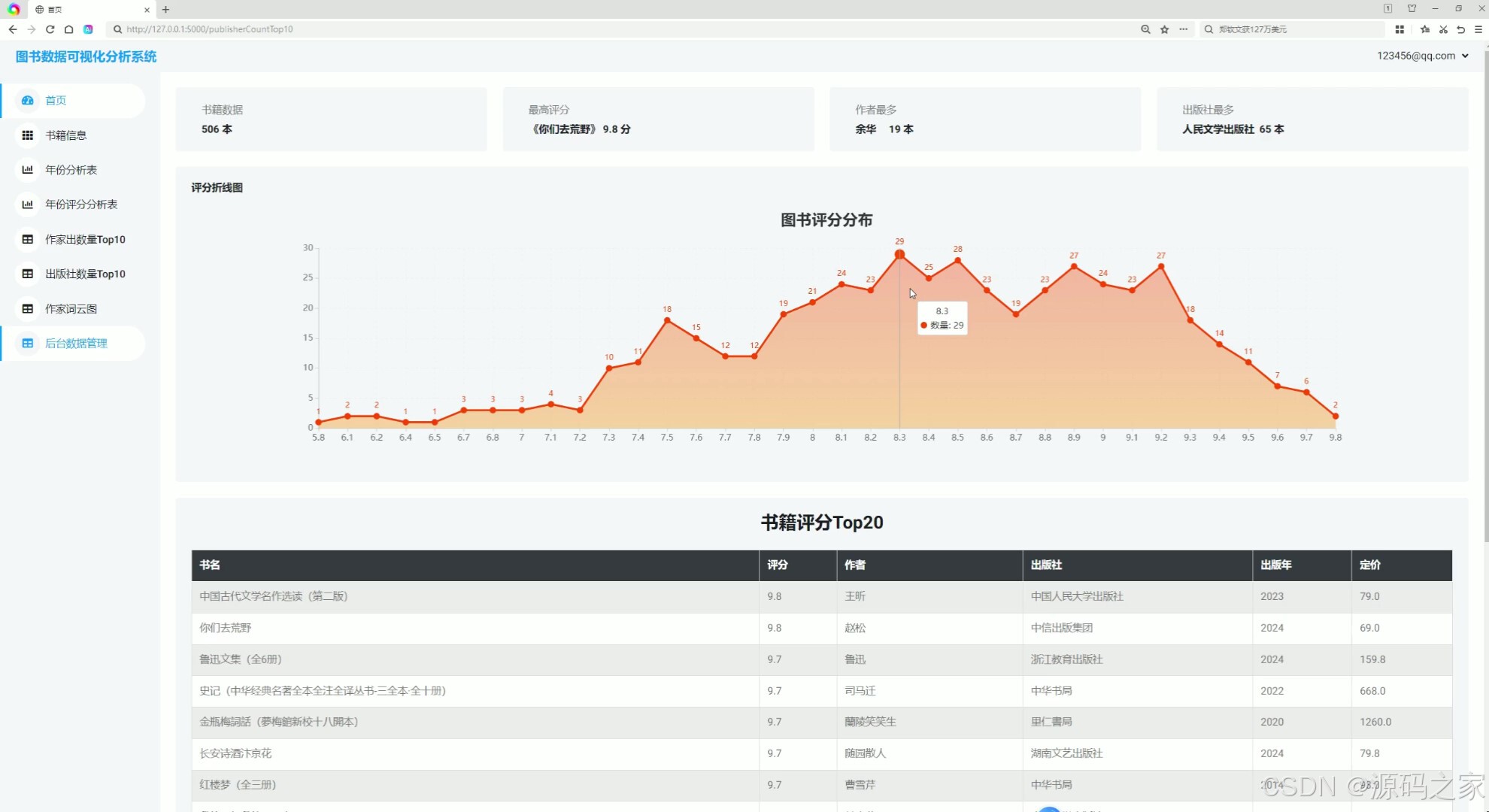
(1)系统首页---数据概况
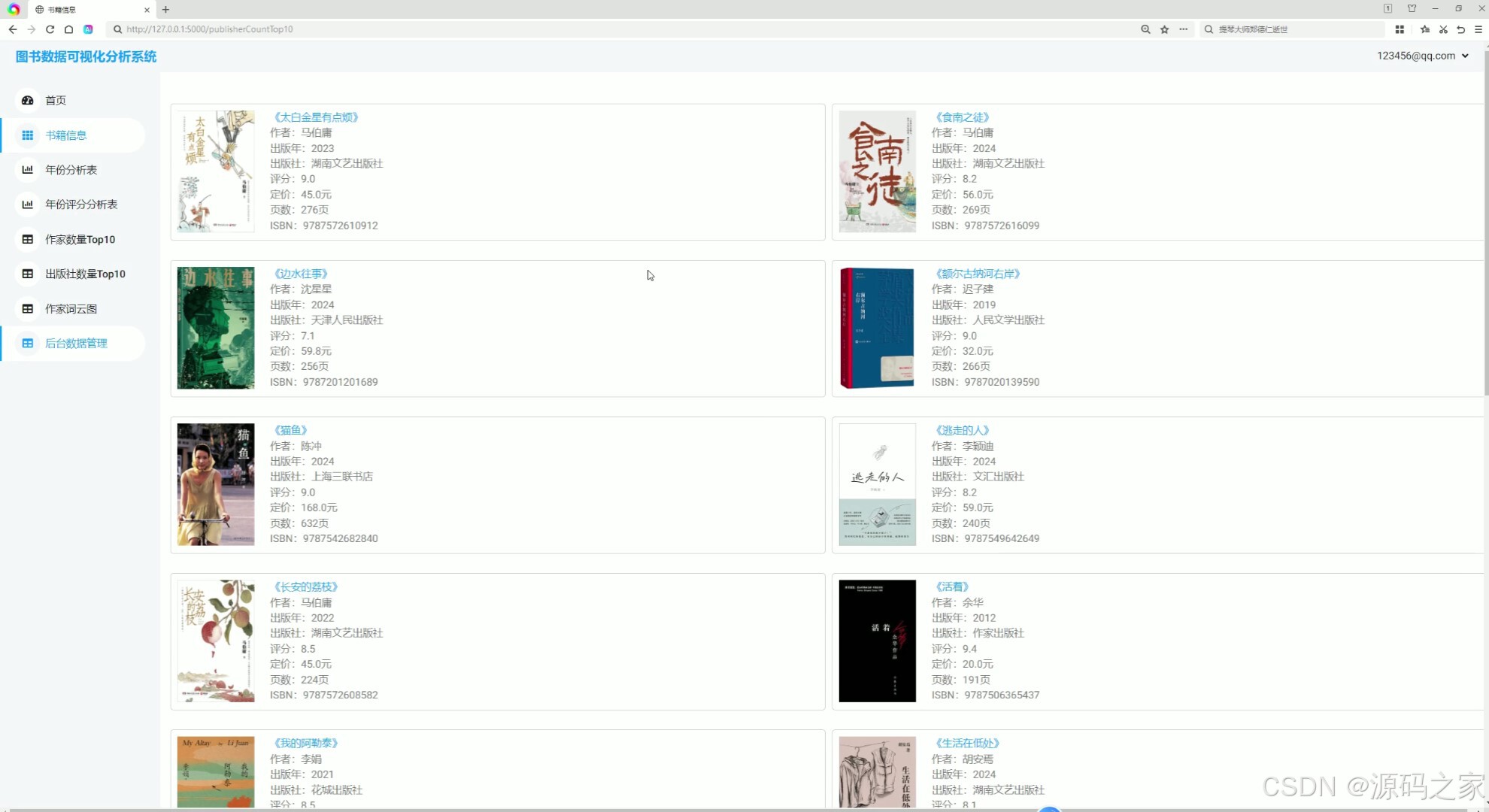
(2)图书信息列表
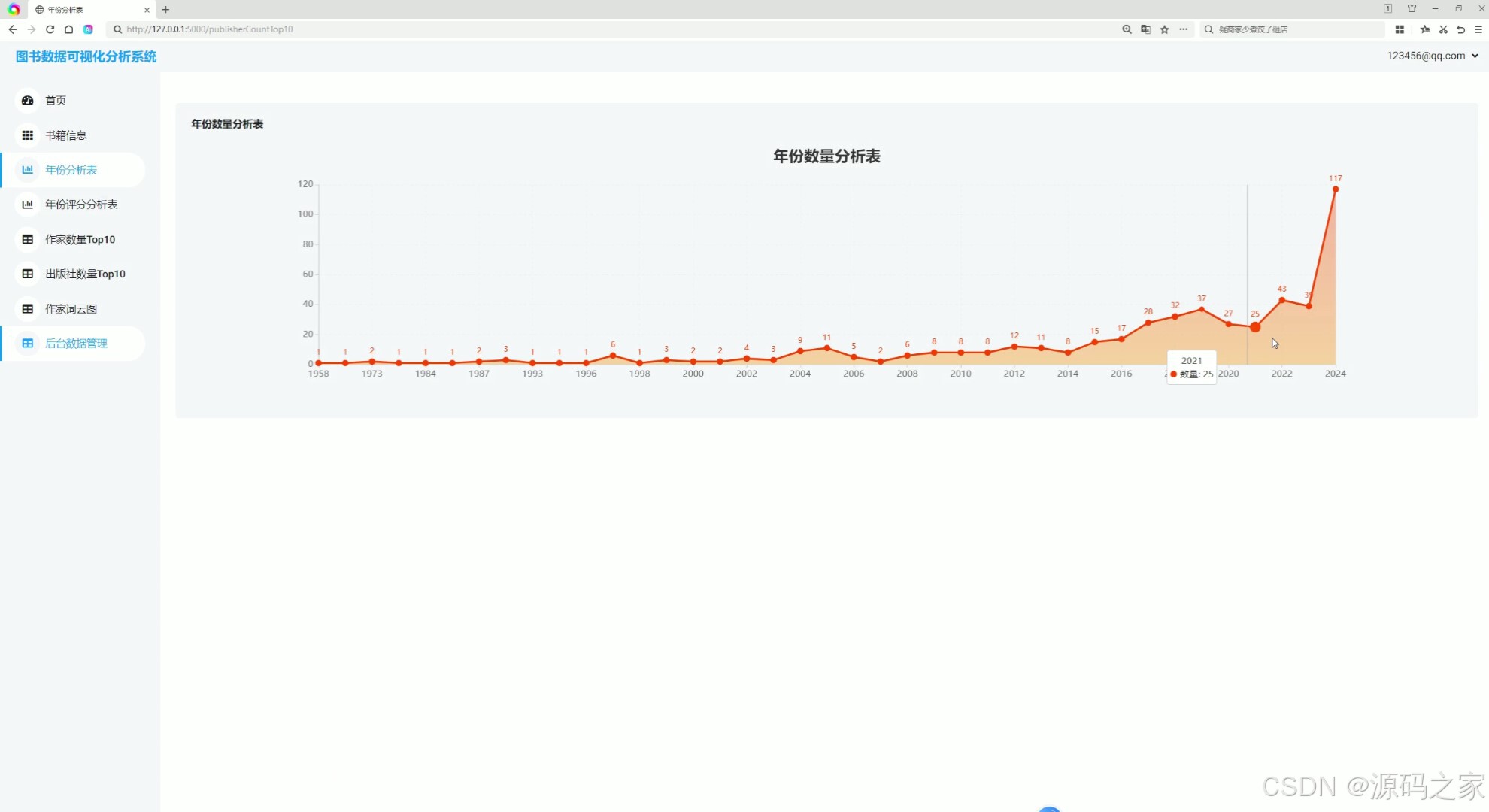
(3)图书年份数据分析
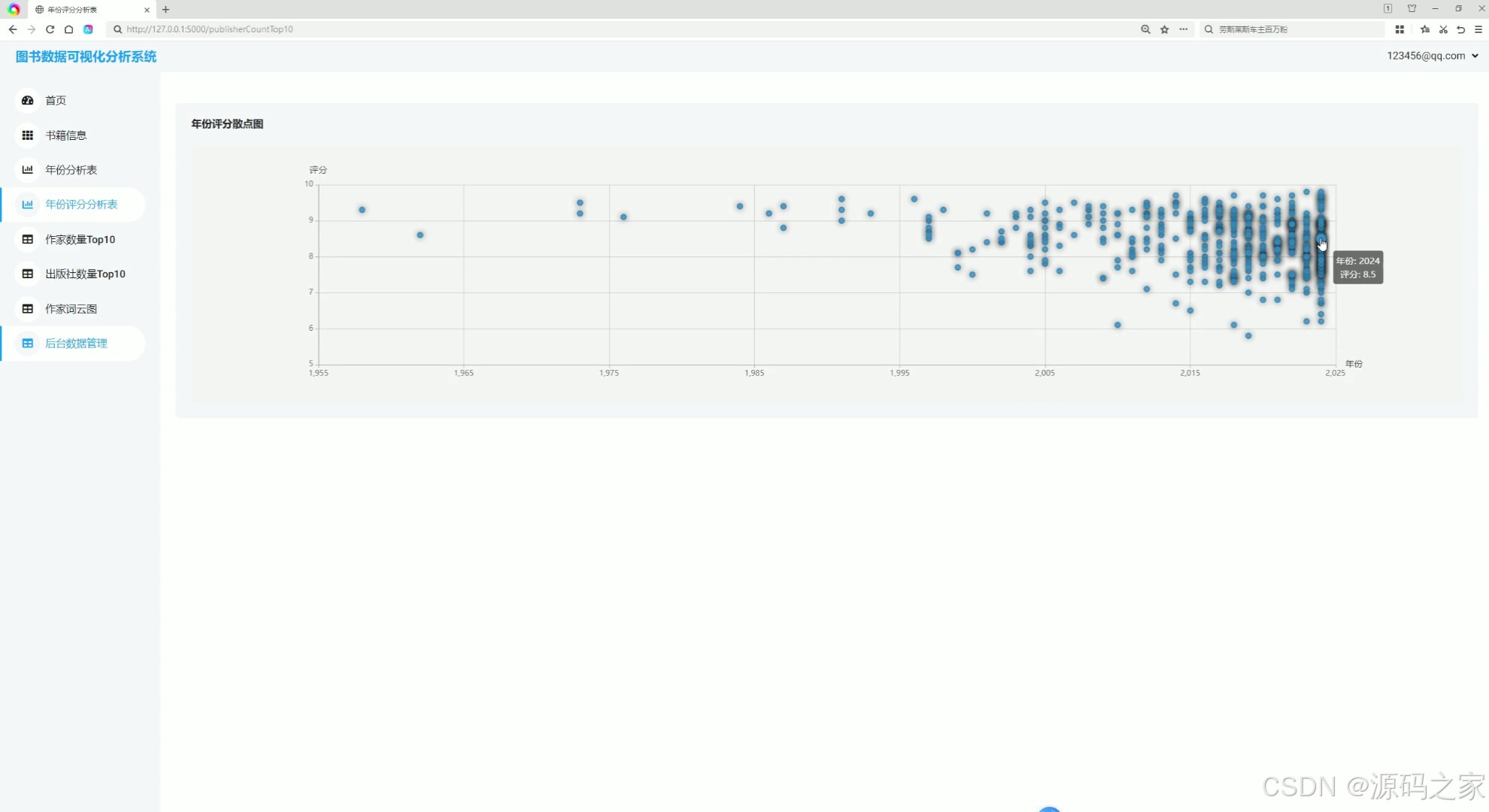
(4)年份评分散点图
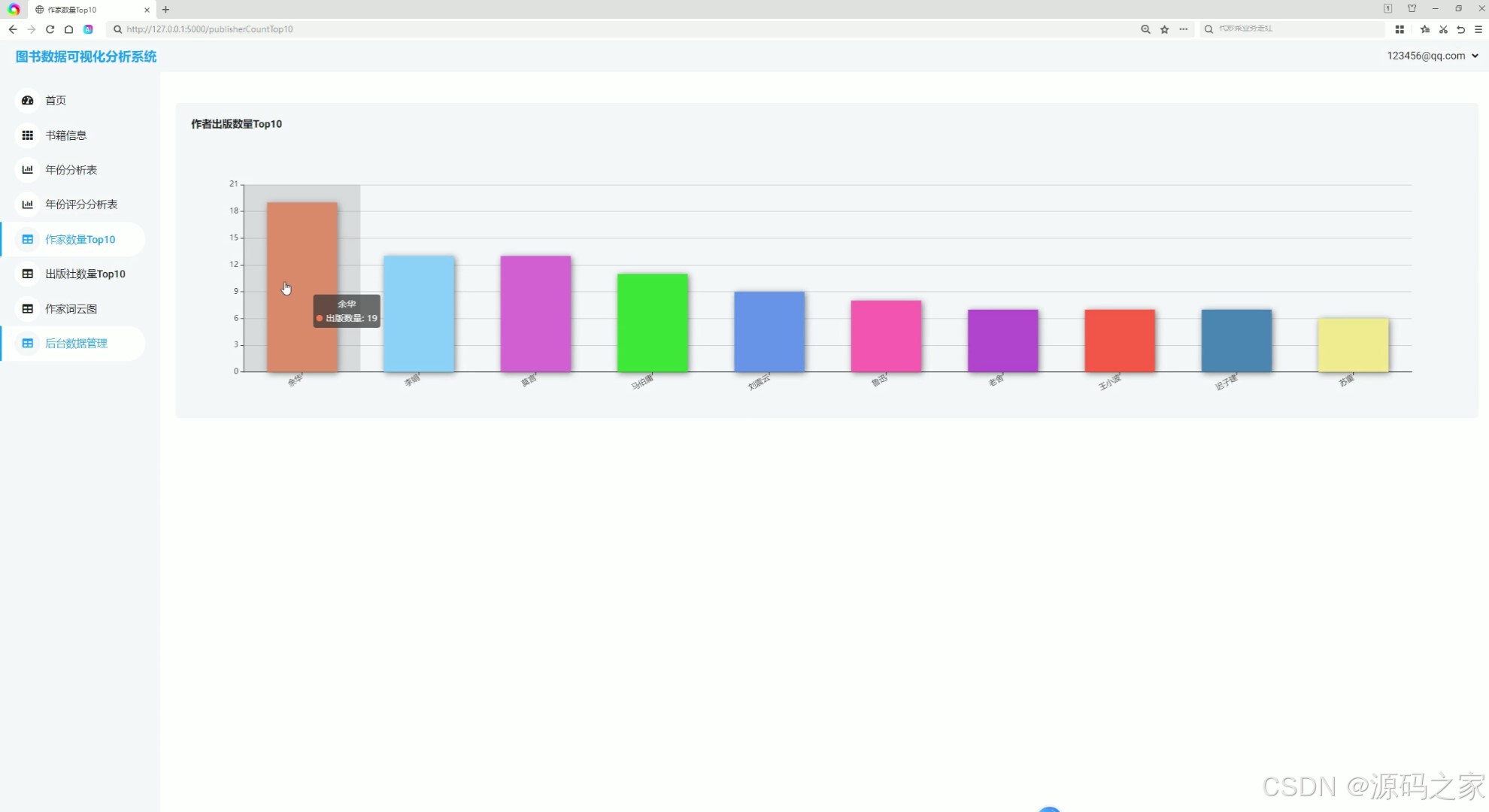
(5)作者出版数量TOP10
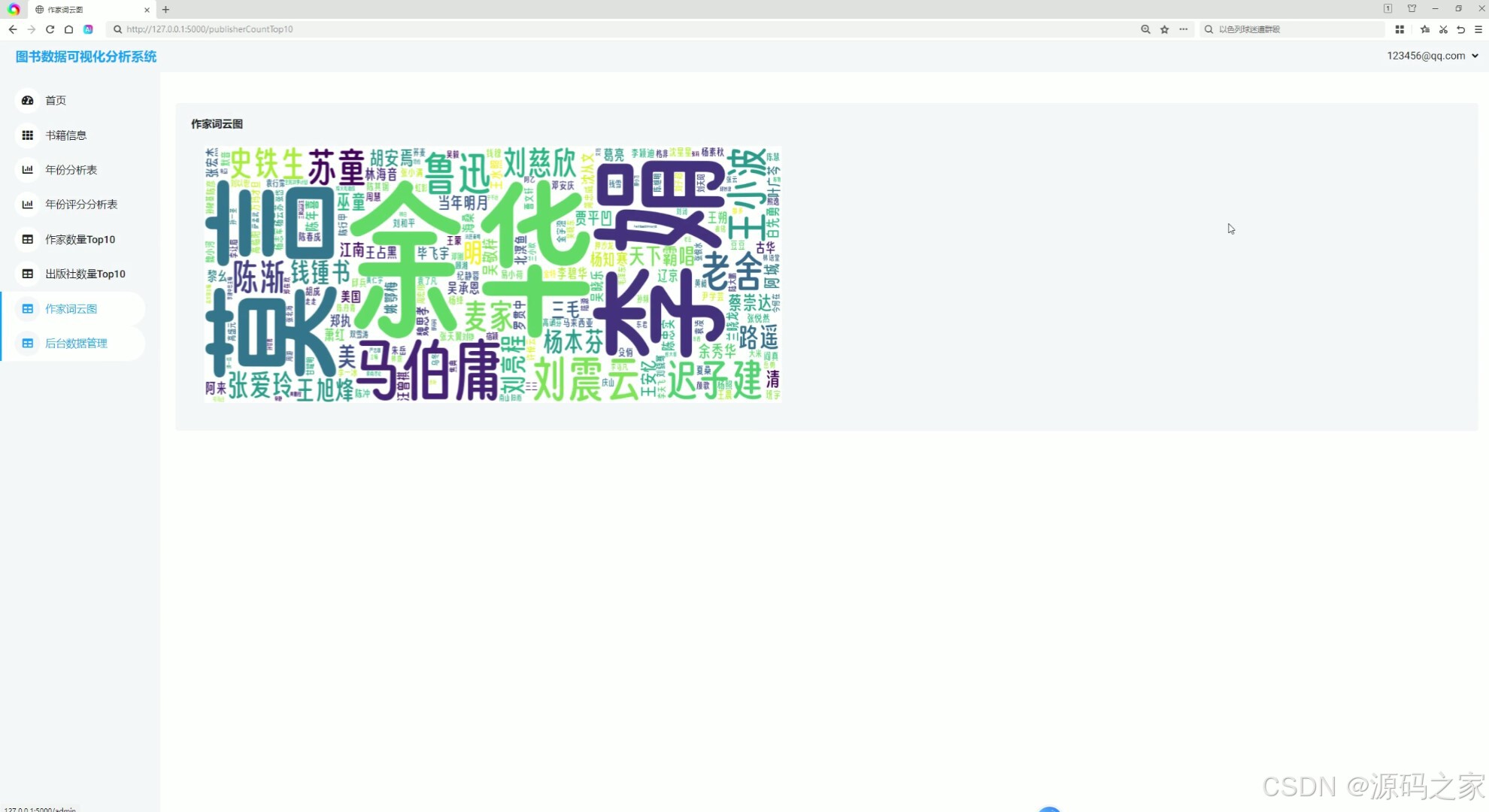
(6)作者词云图分析
(7)注册登录
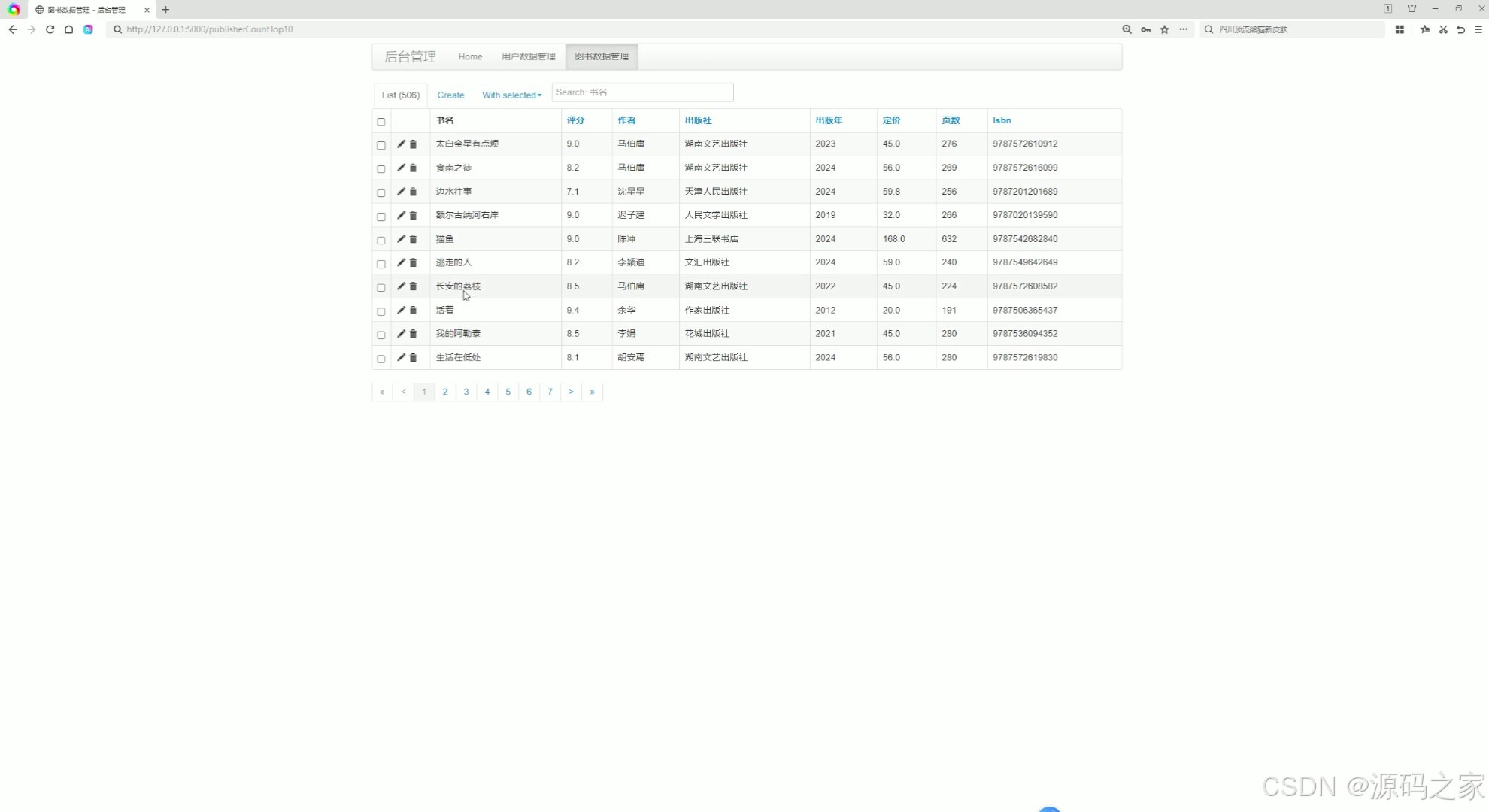
(8)后台数据管理
(9)数据采集
3、项目说明
Python Flask豆瓣图书数据分析可视化系统 Echarts图表展示 爬虫数据采集 计算机毕业设计
- 数据采集模块:基于requests爬虫技术,定向抓取豆瓣图书核心数据(含书名、作者、出版年份、评分等),支持批量采集与数据更新,确保数据全面性。
- 可视化分析模块:集成Echarts可视化库,通过数据概况大屏、年份评分散点图、作者出版数量TOP10柱状图、作者词云图等多元图表,直观呈现图书年份分布、评分趋势、作者热度等分析结果。
- 图书查询模块:提供图书信息列表展示功能,支持用户快速浏览爬取的图书详情,清晰呈现核心数据,满足信息检索需求。
- 数据存储模块:采用MySQL数据库,安全存储爬取的图书数据及用户信息,保障数据完整性与访问稳定性,为分析功能提供数据支撑。
- 用户管理模块:设置注册登录功能,实现用户身份验证与权限管控,保障系统使用安全性与私密性。
- 后台管理模块:管理员可通过后台界面进行数据维护,包括图书数据审核、更新、管理等操作,确保系统数据准确性。
- 技术架构:以Python为开发语言,Flask框架搭建Web界面,结合requests爬虫、MySQL数据库与Echarts可视化技术,构建集数据采集、存储、分析、展示于一体的豆瓣图书数据平台,兼具专业性与易用性。
1. 系统首页------数据概况
系统首页是用户进入系统后的第一个界面,主要用于展示整个系统的数据概况。这里可能会显示图书的总数量、最新采集的图书信息、热门图书推荐等内容。通过简洁的图表和数据展示,用户可以快速了解系统的整体数据情况。
2. 图书信息列表
该模块展示了系统中存储的所有图书信息,包括书名、作者、出版年份、评分等。用户可以通过搜索、筛选等功能快速找到自己感兴趣的图书。列表形式的展示方便用户浏览和比较不同图书的信息。
3. 图书年份数据分析
此模块通过图表(如柱状图或折线图)展示不同年份图书的出版数量或评分变化趋势。用户可以直观地看到图书出版的高峰期以及不同年份图书的评分差异,从而了解图书市场的动态变化。
4. 年份评分散点图
该模块通过散点图的形式,将图书的出版年份与评分进行关联展示。每个点代表一本图书,横轴为出版年份,纵轴为评分。用户可以通过这种可视化方式,快速发现不同年份图书评分的分布规律,例如某些年份的图书是否普遍评分较高。
5. 作者出版数量TOP10
该模块展示了系统中出版图书数量最多的前10位作者。通过柱状图或饼图的形式,用户可以清楚地看到哪些作者在图书市场中占据主导地位,以及他们的作品数量对比。
6. 作者词云图分析
词云图是一种直观展示文本数据中关键词频率的可视化方式。在这个模块中,通过词云图展示系统中出现频率最高的作者名字。字体越大,表示该作者的作品数量越多或影响力越大。这种可视化方式可以让用户快速了解系统中最受欢迎或最活跃的作者群体。
7. 注册登录
这是系统的用户管理模块,提供用户注册和登录功能。用户可以通过注册账号,保存自己的浏览记录、收藏图书等个性化信息。登录功能则确保用户信息安全,同时提供更个性化的体验。
8. 后台数据管理
该模块是系统管理员使用的后台管理界面,用于管理图书数据、用户数据、采集任务等。管理员可以在这里添加、删除或修改图书信息,查看用户行为数据,以及配置数据采集任务的运行参数。
9. 数据采集
数据采集模块是系统的核心功能之一,通过爬虫技术从豆瓣图书等数据源获取图书信息。用户可以通过设置采集任务的参数(如采集频率、采集范围等),自动获取最新的图书数据,并存储到系统数据库中。该模块确保系统数据的实时性和完整性。
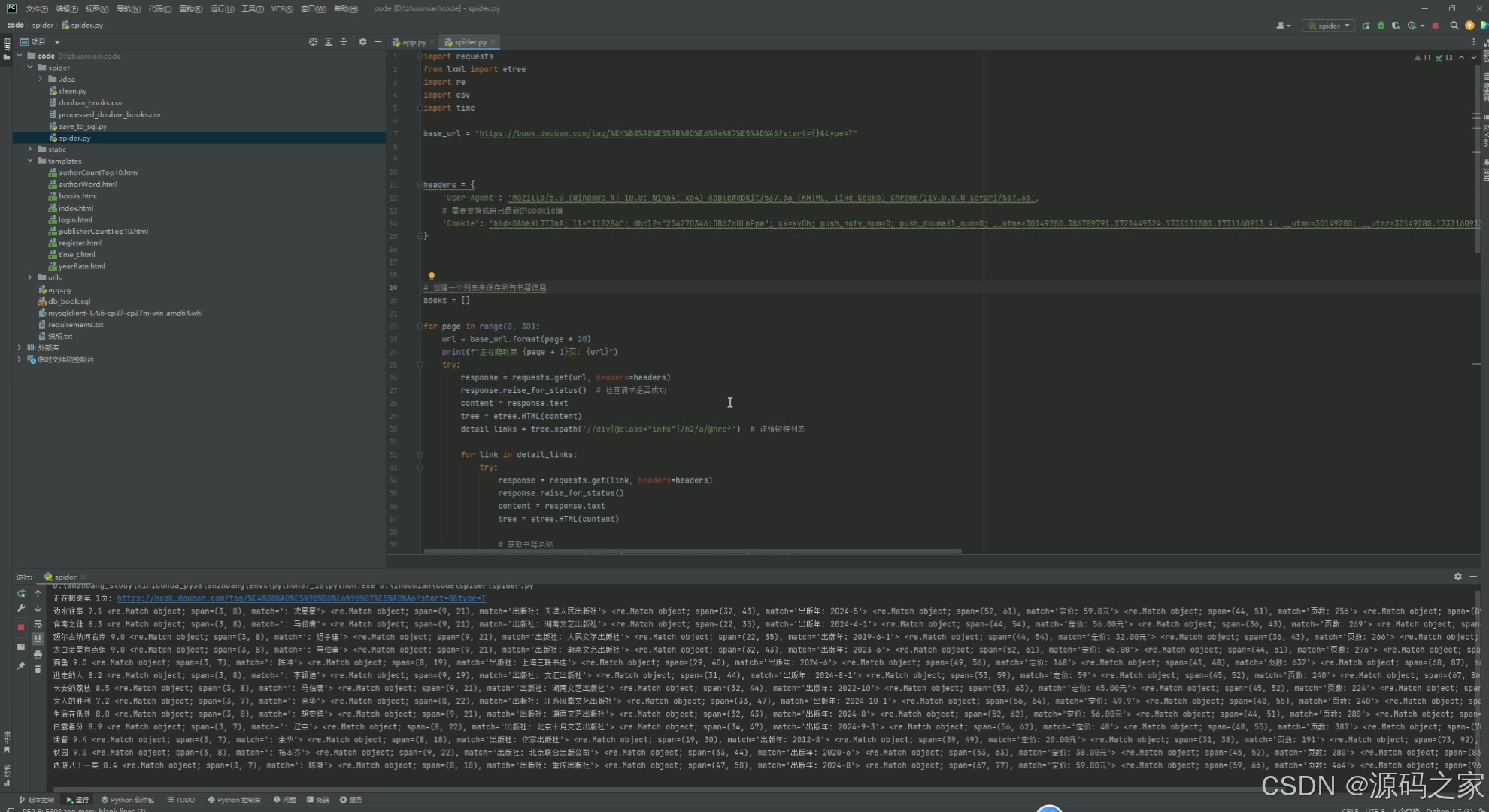
4、核心代码
python
# 创建一个列表来保存所有书籍信息
books = []
for page in range(0, 30):
url = base_url.format(page * 20)
print(f"正在爬取第 {page + 1}页: {url}")
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # 检查请求是否成功
content = response.text
tree = etree.HTML(content)
detail_links = tree.xpath('//div[@class="info"]/h2/a/@href') # 详情链接列表
for link in detail_links:
try:
response = requests.get(link, headers=headers)
response.raise_for_status()
content = response.text
tree = etree.HTML(content)
# 获取书籍名称
title = tree.xpath('//span[@property="v:itemreviewed"]/text()')
title = title[0] if title else '未知'
# 获取图片
img_src = tree.xpath('//a[@class="nbg"]/img/@src')
img_src = img_src[0] if img_src else '未知'
# 获取评分
_rate = tree.xpath('//strong/text()')
rate = [item.strip() for item in _rate if item.strip()]
rate = rate[0] if rate else '暂无评分'
_info = tree.xpath('//div[@id="info"]//text()')
info = [item.strip() for item in _info if item.strip()]
# 提取信息
author = re.search(r':\s*([^\s,]+)', ' '.join(info))
publisher = re.search(r'出版社:\s*([^\s,]+)', ' '.join(info))
publish_year = re.search(r'出版年:\s*([^\s,]+)', ' '.join(info))
price = re.search(r'定价:\s*([^\s,]+)', ' '.join(info))
page_number = re.search(r'页数:\s*([^\s,]+)', ' '.join(info))
isbn = re.search(r'ISBN:\s*([^\s,]+)', ' '.join(info))
print(title,rate,author,publisher,publish_year,price,page_number,isbn)
books.append([
title,
img_src,
rate,
author.group(1) if author else '未知',
publisher.group(1) if publisher else '未知',
publish_year.group(1) if publish_year else '未知',
price.group(1) if price else '未知',
page_number.group(1) if page_number else '未知',
isbn.group(1) if isbn else '未知',
link, # 修改为单个链接
])
# print(books)
time.sleep(1) # 请求之间的延迟
except Exception as e:
print(f"Error fetching book details from {link}: {e}")
except Exception as e:
print(f"Error fetching page {page + 1}: {e}")
# 保存数据到 CSV 文件
with open('douban_books.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
# 写入表头
writer.writerow(['书名', '图片链接', '评分', '作者', '出版社', '出版年', '定价', '页数', 'ISBN', '详情链接'])
# 写入书籍信息
writer.writerows(books)
print("数据已保存到 douban_books.csv")🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式

🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻