详解DataX开发达梦数据库插件
引言

DataX对于达梦数据库支持有限,不像MySQL有自己的reader和writer插件,DataX将达梦数据库视作关系型数据库,其读写逻辑统一放在了rdbmsreader和rdbmswriter中,读达梦数据库的兼容性尚且够用,写达梦数据库只支持insert,不知道upsert,即当达梦数据库存在一条相同的记录时,只能做insert操作,不能做update操作。下面我就来详细介绍一下如何对DataX进行二次开发,实现一个达梦数据库的writer插件,reader插件暂时使用rdbmsreader即可,如果有个性化需要,可以参照开发dmwriter的方式自行开发。
开发步骤
- 下载并认识
DataX代码 - 添加
dmwriter模块 - 修改达梦数据库的写逻辑
- 调试
DataX代码 - 发布
DataX代码
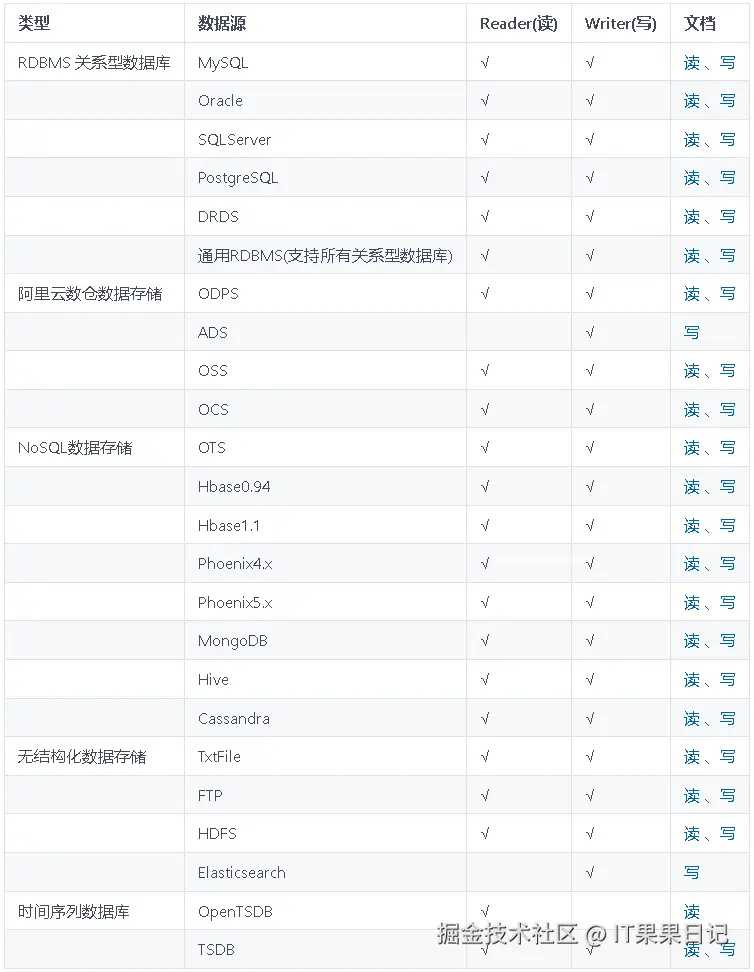
DataX的代码最新一次更新是2020年了,代码非常容易上手,其中的异构和插件思想很适合初学者学习。下图是DataX支持的数据库类型,可以看到对于关系型数据库,MySQL、PostgreSQL和Oracle是有官方的支持,而其他关系型数据库都可以在通用RDBMS中得到有限的支撑。
DataX的代码结构如下图,由于编译打包的速度太慢,所以我只保留了我需要的几个插件,其他的插件我都在pom.xml配置中注释掉了。
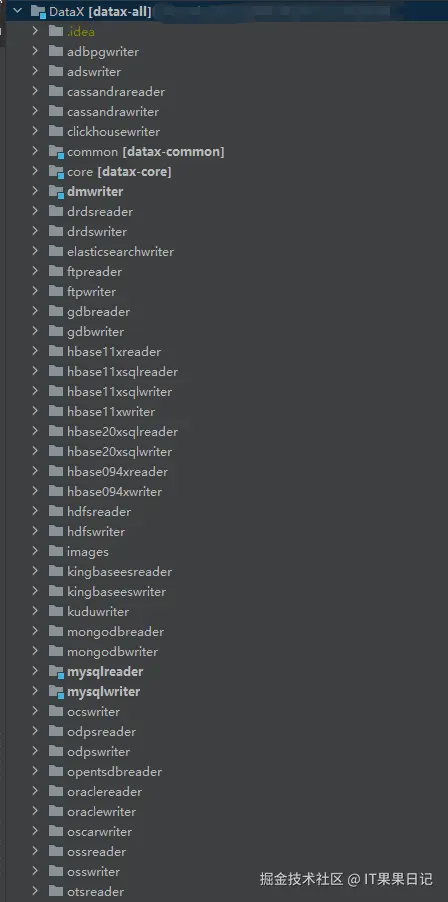
我保留了mysqlreader、mysqlwriter、rdbmsreader、rdbmswriter和新增加的dmwriter这几个插件。除此之外,还需要保留DataX的核心模块:
- datax-common
- datax-core
- plugin-rdbms-util
- plugin-unstructured-storage-util
- datax-transformer
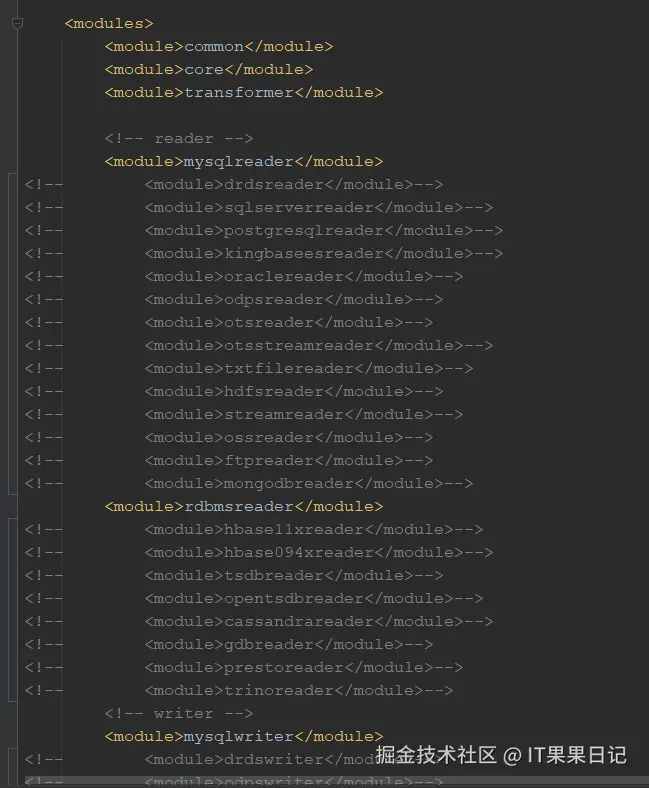
如何屏蔽DataX的插件?修改DataX根目录下的pom.xml文件,将<modules></modules>下的用不到的reader和writer模块都注释掉。
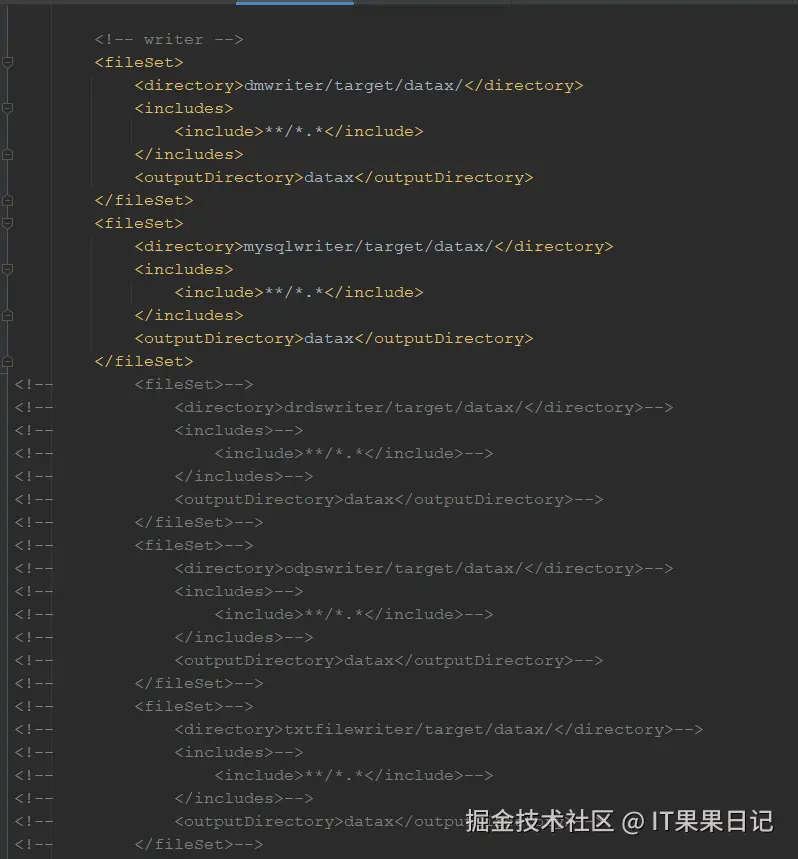
如何屏蔽打包的插件?修改DataX根目录下的package.xml文件,将<fileSets></fileSets>下的不需要的fileSet去掉,这样在打包DataX的时候就不会打包这些不用的插件。

添加dmwriter模块
仿照mysqlwriter的代码结构,自己创建一个模块,或者直接复制mysqlwriter,修改模块名为dmwriter。
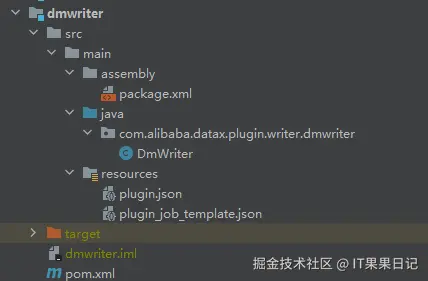
dmwriter有5个文件:
- package.xml
- DmWriter.java
- plugin.json
- plugin_job_template.json
- pom.xml
package.xml
这5个文件基本上和mysqlwriter的代码一样,复制过来修改一下关键字,把mysql改成dm即可。包的名称com.alibaba.datax.plugin.writer.mysqlwriter改为com.alibaba.datax.plugin.writer.dmwriter;
dmwriter模块的package.xml 代码,基本上就是改关键词:
xml
<assembly
xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0 http://maven.apache.org/xsd/assembly-1.1.0.xsd">
<id></id>
<formats>
<format>dir</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<fileSets>
<fileSet>
<directory>src/main/resources</directory>
<includes>
<include>plugin.json</include>
<include>plugin_job_template.json</include>
</includes>
<outputDirectory>plugin/writer/dmwriter</outputDirectory>
</fileSet>
<fileSet>
<directory>target/</directory>
<includes>
<include>dmwriter-0.0.1-SNAPSHOT.jar</include>
</includes>
<outputDirectory>plugin/writer/dmwriter</outputDirectory>
</fileSet>
</fileSets>
<dependencySets>
<dependencySet>
<useProjectArtifact>false</useProjectArtifact>
<outputDirectory>plugin/writer/dmwriter/libs</outputDirectory>
<scope>runtime</scope>
</dependencySet>
</dependencySets>
</assembly>DmWriter.java
DmWriter.java代码,除了修改关键词,还需要增加一个DataBaseType.DAMENG的枚举类型:
java
package com.alibaba.datax.plugin.writer.dmwriter;
import com.alibaba.datax.common.plugin.RecordReceiver;
import com.alibaba.datax.common.spi.Writer;
import com.alibaba.datax.common.util.Configuration;
import com.alibaba.datax.plugin.rdbms.util.DataBaseType;
import com.alibaba.datax.plugin.rdbms.writer.CommonRdbmsWriter;
import com.alibaba.datax.plugin.rdbms.writer.Key;
import java.util.List;
public class DmWriter extends Writer {
private static final DataBaseType DATABASE_TYPE = DataBaseType.DAMENG;
public static class Job extends Writer.Job {
private Configuration originalConfig = null;
private CommonRdbmsWriter.Job commonRdbmsWriterJob;
@Override
public void preCheck(){
this.init();
this.commonRdbmsWriterJob.writerPreCheck(this.originalConfig, DATABASE_TYPE);
}
@Override
public void init() {
this.originalConfig = super.getPluginJobConf();
this.commonRdbmsWriterJob = new CommonRdbmsWriter.Job(DATABASE_TYPE);
this.commonRdbmsWriterJob.init(this.originalConfig);
}
// 一般来说,是需要推迟到 task 中进行pre 的执行(单表情况例外)
@Override
public void prepare() {
//实跑先不支持 权限 检验
//this.commonRdbmsWriterJob.privilegeValid(this.originalConfig, DATABASE_TYPE);
this.commonRdbmsWriterJob.prepare(this.originalConfig);
}
@Override
public List<Configuration> split(int mandatoryNumber) {
return this.commonRdbmsWriterJob.split(this.originalConfig, mandatoryNumber);
}
// 一般来说,是需要推迟到 task 中进行post 的执行(单表情况例外)
@Override
public void post() {
this.commonRdbmsWriterJob.post(this.originalConfig);
}
@Override
public void destroy() {
this.commonRdbmsWriterJob.destroy(this.originalConfig);
}
}
public static class Task extends Writer.Task {
private Configuration writerSliceConfig;
private CommonRdbmsWriter.Task commonRdbmsWriterTask;
@Override
public void init() {
this.writerSliceConfig = super.getPluginJobConf();
this.commonRdbmsWriterTask = new CommonRdbmsWriter.Task(DATABASE_TYPE);
this.commonRdbmsWriterTask.init(this.writerSliceConfig);
}
@Override
public void prepare() {
this.commonRdbmsWriterTask.prepare(this.writerSliceConfig);
}
//TODO 改用连接池,确保每次获取的连接都是可用的(注意:连接可能需要每次都初始化其 session)
public void startWrite(RecordReceiver recordReceiver) {
this.commonRdbmsWriterTask.startWrite(recordReceiver, this.writerSliceConfig,
super.getTaskPluginCollector());
}
@Override
public void post() {
this.commonRdbmsWriterTask.post(this.writerSliceConfig);
}
@Override
public void destroy() {
this.commonRdbmsWriterTask.destroy(this.writerSliceConfig);
}
@Override
public boolean supportFailOver(){
String writeMode = writerSliceConfig.getString(Key.WRITE_MODE);
return "replace".equalsIgnoreCase(writeMode);
}
}
}DataBaseType.java 添加一个DAMENG的枚举类型,并在所有的方法里含有switch case语法的代码块,添加DAMENG类型:
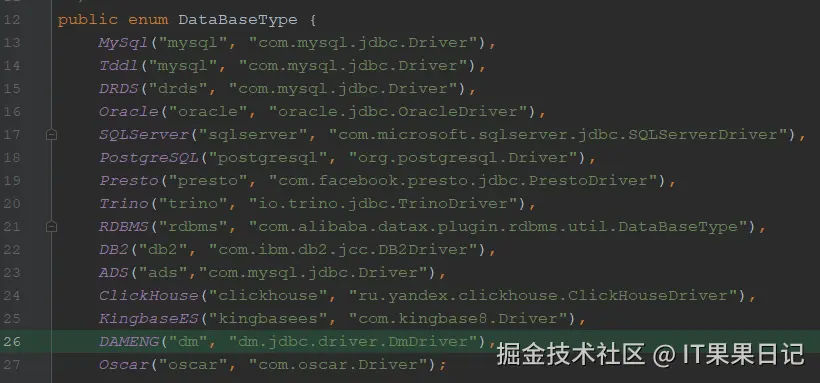
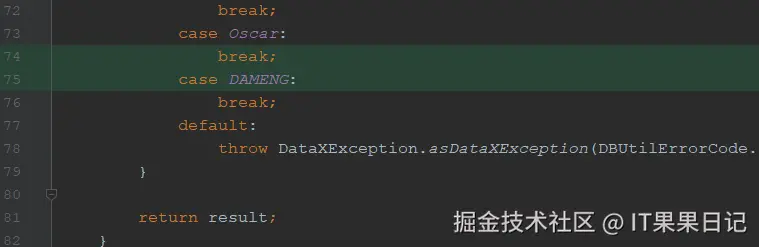
java
package com.alibaba.datax.plugin.rdbms.util;
import com.alibaba.datax.common.exception.DataXException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* refer:http://blog.csdn.net/ring0hx/article/details/6152528
* <p/>
*/
public enum DataBaseType {
MySql("mysql", "com.mysql.jdbc.Driver"),
Tddl("mysql", "com.mysql.jdbc.Driver"),
DRDS("drds", "com.mysql.jdbc.Driver"),
Oracle("oracle", "oracle.jdbc.OracleDriver"),
SQLServer("sqlserver", "com.microsoft.sqlserver.jdbc.SQLServerDriver"),
PostgreSQL("postgresql", "org.postgresql.Driver"),
Presto("presto", "com.facebook.presto.jdbc.PrestoDriver"),
Trino("trino", "io.trino.jdbc.TrinoDriver"),
RDBMS("rdbms", "com.alibaba.datax.plugin.rdbms.util.DataBaseType"),
DB2("db2", "com.ibm.db2.jcc.DB2Driver"),
ADS("ads","com.mysql.jdbc.Driver"),
ClickHouse("clickhouse", "ru.yandex.clickhouse.ClickHouseDriver"),
KingbaseES("kingbasees", "com.kingbase8.Driver"),
DAMENG("dm", "dm.jdbc.driver.DmDriver"),
Oscar("oscar", "com.oscar.Driver");
private String typeName;
private String driverClassName;
DataBaseType(String typeName, String driverClassName) {
this.typeName = typeName;
this.driverClassName = driverClassName;
}
public String getDriverClassName() {
return this.driverClassName;
}
public String appendJDBCSuffixForReader(String jdbc) {
String result = jdbc;
String suffix = null;
switch (this) {
case MySql:
case DRDS:
suffix = "yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true";
if (jdbc.contains("?")) {
result = jdbc + "&" + suffix;
} else {
result = jdbc + "?" + suffix;
}
break;
case Oracle:
break;
case SQLServer:
break;
case DB2:
break;
case PostgreSQL:
break;
case Presto:
break;
case Trino:
break;
case ClickHouse:
break;
case RDBMS:
break;
case KingbaseES:
break;
case Oscar:
break;
case DAMENG:
break;
default:
throw DataXException.asDataXException(DBUtilErrorCode.UNSUPPORTED_TYPE, "unsupported database type.");
}
return result;
}
public String appendJDBCSuffixForWriter(String jdbc) {
String result = jdbc;
String suffix = null;
switch (this) {
case MySql:
suffix = "yearIsDateType=false&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true&tinyInt1isBit=false";
if (jdbc.contains("?")) {
result = jdbc + "&" + suffix;
} else {
result = jdbc + "?" + suffix;
}
break;
case DRDS:
suffix = "yearIsDateType=false&zeroDateTimeBehavior=convertToNull";
if (jdbc.contains("?")) {
result = jdbc + "&" + suffix;
} else {
result = jdbc + "?" + suffix;
}
break;
case Oracle:
break;
case SQLServer:
break;
case DB2:
break;
case PostgreSQL:
break;
case Presto:
break;
case Trino:
break;
case ClickHouse:
break;
case RDBMS:
break;
case KingbaseES:
break;
case Oscar:
break;
case DAMENG:
break;
default:
throw DataXException.asDataXException(DBUtilErrorCode.UNSUPPORTED_TYPE, "unsupported database type.");
}
return result;
}
public String formatPk(String splitPk) {
String result = splitPk;
switch (this) {
case MySql:
case Oracle:
if (splitPk.length() >= 2 && splitPk.startsWith("`") && splitPk.endsWith("`")) {
result = splitPk.substring(1, splitPk.length() - 1).toLowerCase();
}
break;
case SQLServer:
if (splitPk.length() >= 2 && splitPk.startsWith("[") && splitPk.endsWith("]")) {
result = splitPk.substring(1, splitPk.length() - 1).toLowerCase();
}
break;
case DB2:
case PostgreSQL:
case Presto:
case KingbaseES:
case Oscar:
break;
case DAMENG:
break;
default:
throw DataXException.asDataXException(DBUtilErrorCode.UNSUPPORTED_TYPE, "unsupported database type.");
}
return result;
}
public String quoteColumnName(String columnName) {
String result = columnName;
switch (this) {
case MySql:
result = "`" + columnName.replace("`", "``") + "`";
break;
case Oracle:
break;
case SQLServer:
result = "[" + columnName + "]";
break;
case DB2:
case PostgreSQL:
case Presto:
case Trino:
case KingbaseES:
case Oscar:
case DAMENG:
break;
default:
throw DataXException.asDataXException(DBUtilErrorCode.UNSUPPORTED_TYPE, "unsupported database type");
}
return result;
}
public String quoteTableName(String tableName) {
String result = tableName;
switch (this) {
case MySql:
result = "`" + tableName.replace("`", "``") + "`";
break;
case Oracle:
break;
case SQLServer:
break;
case DB2:
break;
case PostgreSQL:
break;
case Presto:
break;
case Trino:
break;
case KingbaseES:
break;
case Oscar:
break;
case DAMENG:
break;
default:
throw DataXException.asDataXException(DBUtilErrorCode.UNSUPPORTED_TYPE, "unsupported database type");
}
return result;
}
private static Pattern mysqlPattern = Pattern.compile("jdbc:mysql://(.+):\\d+/.+");
private static Pattern oraclePattern = Pattern.compile("jdbc:oracle:thin:@(.+):\\d+:.+");
/**
* 注意:目前只实现了从 mysql/oracle 中识别出ip 信息.未识别到则返回 null.
*/
public static String parseIpFromJdbcUrl(String jdbcUrl) {
Matcher mysql = mysqlPattern.matcher(jdbcUrl);
if (mysql.matches()) {
return mysql.group(1);
}
Matcher oracle = oraclePattern.matcher(jdbcUrl);
if (oracle.matches()) {
return oracle.group(1);
}
return null;
}
public String getTypeName() {
return typeName;
}
public void setTypeName(String typeName) {
this.typeName = typeName;
}
}plugin.json
修改关键词即可
json
{
"name": "dmwriter",
"class": "com.alibaba.datax.plugin.writer.dmwriter.DmWriter",
"description": "useScene: prod. mechanism: Jdbc connection using the database, execute insert sql. warn: The more you know about the database, the less problems you encounter.",
"developer": "alibaba"
}plugin_job_template.json
修改关键词即可
json
{
"name": "dmwriter",
"parameter": {
"username": "",
"password": "",
"writeMode": "",
"column": [],
"session": [],
"preSql": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
]
}
}pom.xml
除了修改关键词,还需要修改数据库驱动的依赖配置,将MySQL的数据库驱动依赖改为达梦的数据库依赖。
xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.alibaba.datax</groupId>
<artifactId>datax-all</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>dmwriter</artifactId>
<name>dmwriter</name>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>com.alibaba.datax</groupId>
<artifactId>datax-common</artifactId>
<version>${datax-project-version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.datax</groupId>
<artifactId>plugin-rdbms-util</artifactId>
<version>${datax-project-version}</version>
</dependency>
<dependency>
<groupId>com.dameng</groupId>
<artifactId>DmJdbcDriver18</artifactId>
<version>8.1.3.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- compiler plugin -->
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>${jdk-version}</source>
<target>${jdk-version}</target>
<encoding>${project-sourceEncoding}</encoding>
</configuration>
</plugin>
<!-- assembly plugin -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptors>
<descriptor>src/main/assembly/package.xml</descriptor>
</descriptors>
<finalName>datax</finalName>
</configuration>
<executions>
<execution>
<id>dwzip</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>dataX-all
在DataX根目录下的package.xml文件中<fileSets></fileSets> 中添加一段代码,打包的时候可以将dmwriter模块编译打包。
xml
<fileSet>
<directory>dmwriter/target/datax/</directory>
<includes>
<include>**/*.*</include>
</includes>
<outputDirectory>datax</outputDirectory>
</fileSet>在DataX根目录下的pom.xml文件中<modules></modules>中添加一行代码
xml
<module>dmwriter</module>修改达梦数据库的写逻辑
不论使用什么关系型数据库,其核心的代码都在plugin-rdbms-util这个模块里,下图是其代码结构,可以看到DataBaseType.java、DBUtil.java和WriterUtil.java是经常会被使用到的工具类。
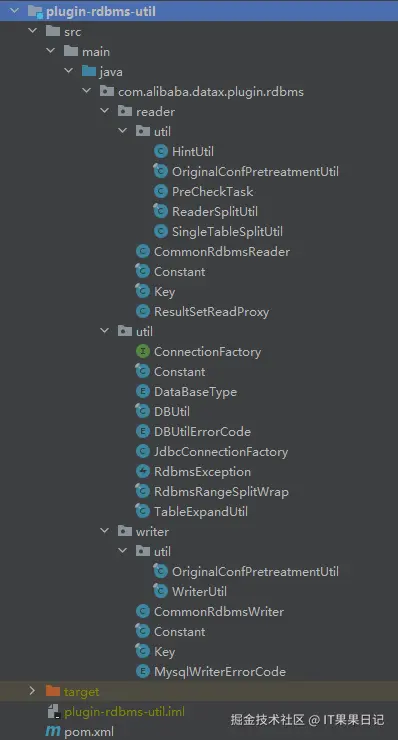
MySQL等关系型数据库的写逻辑共用了WriterUtil.java里的代码。WriterUtil.java 有个方法getWriteTemplate() 会生成insert或upsert的sql模板。DataX原始代码是只支持两种语法:
- INSERT INTO VALUES ... ON DUPLICATE KEY UPDATE ...
- REPLACE INTO VALUES ...
这两种达梦8都不支持,所以可以在这个方法里增加一种模板,使用MERGE INTO ... USING ... 的语法。
sql
MERGE INTO <目标表名> [<别名>]
USING <源表/视图/子查询> [<别名>]
ON (<匹配条件>) -- 通常是主键或唯一键列的比较
WHEN MATCHED THEN -- 目标表中存在匹配的记录
UPDATE SET <列1> = <值1>[, <列2> = <值2> ...]
WHEN NOT MATCHED THEN -- 目标表中不存在匹配的记录
INSERT [(<列1>, <列2>, ... )]
VALUES (<值1>, <值2>, ...);示例如下:
sql
MERGE INTO employees AS tgt
USING ( -- USING 子句定义源数据
SELECT 1003 AS new_emp_id, '王' AS new_first, '力' AS new_last, 'Finance' AS new_dept, 9000 AS new_sal
FROM DUAL -- DUAL 是达梦兼容Oracle的伪表,提供单行环境
) AS src
ON (tgt.employee_id = src.new_emp_id) -- 匹配条件:根据员工ID匹配
WHEN MATCHED THEN -- 如果找到匹配的记录
UPDATE SET -- 更新目标表的记录
tgt.first_name = src.new_first,
tgt.last_name = src.new_last,
tgt.department = src.new_dept,
tgt.salary = src.new_sal
WHEN NOT MATCHED THEN -- 如果没有找到匹配的记录
INSERT (employee_id, first_name, last_name, department, salary) -- 指定插入的列(可选但推荐)
VALUES (src.new_emp_id, src.new_first, src.new_last, src.new_dept, src.new_sal);改写WriterUtil.java,最主要的是增加了onDuplicateKeyMergeString()这个方法,以及在getWriteTemplate()方法中的调用。
java
public static String getWriteTemplate(List<String> columnHolders, List<String> valueHolders, String writeMode, DataBaseType dataBaseType, boolean forceUseUpdate) {
boolean isWriteModeLegal = writeMode.trim().toLowerCase().startsWith("insert")
|| writeMode.trim().toLowerCase().startsWith("replace")
|| writeMode.trim().toLowerCase().startsWith("update");
if (!isWriteModeLegal) {
throw DataXException.asDataXException(DBUtilErrorCode.ILLEGAL_VALUE,
String.format("您所配置的 writeMode:%s 错误. 因为DataX 目前仅支持replace,update 或 insert 方式. 请检查您的配置并作出修改.", writeMode));
}
// && writeMode.trim().toLowerCase().startsWith("replace")
String writeDataSqlTemplate;
if (forceUseUpdate ||
((dataBaseType == DataBaseType.MySql || dataBaseType == DataBaseType.Tddl) && writeMode.trim().toLowerCase().startsWith("update"))
) {
//update只在mysql下使用
writeDataSqlTemplate = new StringBuilder()
.append("INSERT INTO %s (").append(StringUtils.join(columnHolders, ","))
.append(") VALUES(").append(StringUtils.join(valueHolders, ","))
.append(")")
.append(onDuplicateKeyUpdateString(columnHolders))
.toString();
} else {
if(dataBaseType == DataBaseType.DAMENG){
writeDataSqlTemplate = onDuplicateKeyMergeString(writeMode, columnHolders);
} else {
//这里是保护,如果其他错误的使用了update,需要更换为replace
if (writeMode.trim().toLowerCase().startsWith("update")) {
writeMode = "replace";
}
writeDataSqlTemplate = new StringBuilder().append(writeMode)
.append(" INTO %s (").append(StringUtils.join(columnHolders, ","))
.append(") VALUES(").append(StringUtils.join(valueHolders, ","))
.append(")").toString();
}
}
return writeDataSqlTemplate;
}
public static String onDuplicateKeyMergeString(String writeMode, List<String> columnHolders) {
//构建 USING 子查询部分(带占位符)
StringJoiner srcColumns = new StringJoiner(", ");
StringJoiner placeholders = new StringJoiner(", ");
for (String column : columnHolders) {
srcColumns.add("? AS " + column);
placeholders.add("?");
}
//构建 MERGE INTO
StringBuilder sqlBuilder = new StringBuilder().append("MERGE INTO %s as tgt USING (SELECT ")
.append(srcColumns)
.append(" FROM DUAL) AS src ");
// 构建 ON 条件(唯一索引匹配)
List<String> uniqueColumns = parseUniqueColumns(writeMode);
// 验证唯一索引字段有效性
for (String col : uniqueColumns) {
if (!columnHolders.contains(col)) {
throw new IllegalArgumentException("Unique column '" + col + "' not found in field list");
}
}
sqlBuilder.append(" ON ( ");
StringJoiner onConditions = new StringJoiner(" AND ");
for (String column : uniqueColumns) {
onConditions.add("tgt." + column + " = src." + column);
}
sqlBuilder.append(onConditions).append(") ");
// 构建 UPDATE SET 部分(排除唯一索引列)
sqlBuilder.append(" WHEN MATCHED THEN UPDATE SET ");
StringJoiner updateSet = new StringJoiner(", ");
for (String column : columnHolders) {
//if (!column.equals(uniqueColumn)) {
if (!uniqueColumns.contains(column)) {
updateSet.add(" tgt." + column + " = src." + column);
}
}
sqlBuilder.append(updateSet);
// 构建 INSERT 部分
sqlBuilder.append(" WHEN NOT MATCHED THEN INSERT ");
StringJoiner insertColumns = new StringJoiner(", ", " (", ")");
StringJoiner insertValues = new StringJoiner(", ", " VALUES (", ");");
for (String column : columnHolders) {
insertColumns.add(column);
insertValues.add("src." + column);
}
sqlBuilder.append(insertColumns).append(insertValues);
return sqlBuilder.toString();
}
/**
* 解析 writeMode 配置获取唯一索引字段列表
*
* @param writeMode 配置字符串,格式示例:
* "update(id)" -> 单字段唯一索引
* "update(id,user_id)" -> 多字段组合唯一索引
* "update( "id" , user_id)" -> 带空格的复杂格式
* null 或空值 -> 使用默认字段名"id"
*/
private static List<String> parseUniqueColumns(String writeMode) {
// 默认使用 "id" 作为唯一索引
if (StringUtils.isBlank(writeMode)) {
return Collections.singletonList("id");
}
// 提取括号内的内容
String content = writeMode
.replaceFirst(".*?\\(", "") // 移除前缀和左括号
.replaceAll("\\)$", ""); // 移除右括号
// 分割多个字段并清理空白
return Arrays.stream(content.split(","))
.map(String::trim) // 移除前后空格
.filter(s -> !s.isEmpty()) // 过滤空字段
.collect(Collectors.toList());
}
public static String onDuplicateKeyUpdateString(List<String> columnHolders){
if (columnHolders == null || columnHolders.size() < 1) {
return "";
}
StringBuilder sb = new StringBuilder();
sb.append(" ON DUPLICATE KEY UPDATE ");
boolean first = true;
for(String column:columnHolders){
if(!first){
sb.append(",");
}else{
first = false;
}
sb.append(column);
sb.append("=VALUES(");
sb.append(column);
sb.append(")");
}
return sb.toString();
}调试DataX代码
DataX 的入口在Engine.java这个类的main()方法里,当用户使用python命令执行DataX时,python脚本实际上调用的就是这个方法。
在Engine.java的main()方法里添加一段代码,做两件事情:
- 设置运行的
datax的家目录 - 设置
datax的运行脚本信息
datax的家目录就是DataX源码编译后的target目录下的datax目录
datax的运行脚本信息就是datax要启动的json配置文件地址。
java
public static void main(String[] args) throws Exception {
int exitCode = 0;
try {
//设置运行的datax的家目录
System.setProperty("datax.home", "D:\\DataX\\target\\datax\\datax");
//设置datax的运行脚本信息
String jsonName = "mysql_to_dameng.json";
args = new String[]{"-mode", "standalone", "-jobid", "-1", "-job", "D:\\" + jsonName};
Engine.entry(args);
} catch (Throwable e) {
exitCode = 1;
LOG.error("\n\n经DataX智能分析,该任务最可能的错误原因是:\n" + ExceptionTracker.trace(e));
if (e instanceof DataXException) {
DataXException tempException = (DataXException) e;
ErrorCode errorCode = tempException.getErrorCode();
if (errorCode instanceof FrameworkErrorCode) {
FrameworkErrorCode tempErrorCode = (FrameworkErrorCode) errorCode;
exitCode = tempErrorCode.toExitValue();
}
}
System.exit(exitCode);
}
System.exit(exitCode);
}mysql_to_dameng.json配置文件代码如下。从MySQL数据库读取表src_table,写到达梦数据库的target_table表。读使用的是mysqlreader插件,写使用的是dmwriter插件。
writeMode配置的是update(id,user_id),表示执行upsert操作,唯一主键采用id和user_id的联合主键。如果writeMode配置的update,则默认以id作为唯一主键,等同于update(id)。
json
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "xxx",
"column": [
"*"
],
"connection": [
{
"querySql": [
"select * from src_table;"
],
"jdbcUrl": [
"jdbc:mysql://localhost:3306/mysql_db?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=GMT%2B8"
]
}
]
}
},
"writer": {
"name": "dmwriter",
"parameter": {
"writeMode": "update(id,user_id)",
"username": "SYSDBA",
"password": "Dameng123",
"column": [
"id"
,"user_id"
,"parent_id"
,"user_name"
],
"connection": [
{
"jdbcUrl": "jdbc:dm://localhost:5236/dameng_db",
"table": [
"dameng_db.target_table"
]
}
]
}
}
}
]
}
}在启动之前,还需要做一件事情就是打包DataX,不然我们二开的代码不会生效,并且后续只要有代码修改,都需要在DataX根目录重新执行以下命令:
java
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
// 如果是powershell命令行,要加上单引号
mvn -U clean package assembly:assembly '-Dmaven.test.skip=true'至此,就可以在ide工具下使用debug模式启动main()方法。
发布
以上步骤,我们修改的代码影响了两个包:
- 一个是新加的
dmwriter插件,将target编译目录下的dmwriter文件夹拷贝到生产环境的DATAX_HOME\plugin\writer目录下
- 另外一个是
plugin-rdbms-util-0.0.1-SNAPSHOT.jar这个包文件,它是所有reader和writer插件都会共用的工具包,理论上这个包更新了需要把所有插件目录下libs文件夹内的此包覆盖成最新 ,但是因为这个包里我们改动的代码只会影响dmwriter的写逻辑,其他插件没有用到改动的代码,所以不需要更新。
rdbmsreader读达梦数据库
最后这里说个题外话,rdbmsreader要读取达梦数据库,需要注意看代码里的达梦版本是多少,DataX源码默认的驱动版本给的是达梦7,而现在普遍使用的是达梦8,所以需要修改达梦的依赖包。

xml
<dependency>
<groupId>com.dm</groupId>
<artifactId>dm</artifactId>
<scope>system</scope>
<systemPath>${basedir}/src/main/libs/DmJdbcDriver18.jar</systemPath>
</dependency><systemPath>${basedir}/src/main/libs/DmJdbcDriver18.jar</systemPath> 使用的是系统目录,不是在云仓库下载驱动,所以需要手动把包放到libs目录下。
参考
dataxPluginDev.md · dataxGroup/datax - Git...
【原创】DataX在麒麟操作系统部署及从Mysql同步至达梦8数据库 - Linux技术交流 - DA 论坛 - Powered by Discuz!