1 简介
Stable Diffusion是 2022 年发布的深度学习文字到图像生成模型。它主要用于根据文字的描述产生详细图像,能够在几秒钟内创作出令人惊叹的作品。
1.1 电脑配置
最低配置
操作系统:Windows 10(64 位)、macOS Monterey(12.5)及以上版本或支持 CUDA 的 Linux 发行版(如 Ubuntu 18.04 及以上版本)。
显卡:推荐 NVIDIA 显卡,型号为 GTX 1050 Ti 或更高,需支持 CUDA,显存至少 4GB。
内存:至少 8GB。
存储空间:硬盘空间至少预留 10GB,机械硬盘可满足基本需求,但固态硬盘更佳。
其他:Python 3.8 及以上版本,稳定的网络连接。
推荐配置
操作系统:Windows 11、macOS Ventura(13.0)及以上版本或 Ubuntu 20.04 及以上版本。
显卡:推荐 NVIDIA 显卡,如RTX 4060 Ti 16GB或更高配置,显存至少 12GB。
内存:至少 16GB,32GB 或更高更好。
存储空间:硬盘空间至少预留 500GB,推荐使用 NVMe 协议的固态硬盘。
其他:Python 3.10 或 3.11 版本,高速稳定的网络连接。
电脑配置最核心的关键点:看显卡、看内存、看硬盘、看CPU。其中最重要的是看显卡,N卡(英伟达Nvida独立显卡)首选,效率远超集显/AMD/Intel显卡和CPU渲染,最低10系起步,体验感佳用40系,显存最低4G,6G及格,上不封顶;内存最低8G,16G及格,上不封顶;硬盘可用空间最好有个500G朝上,固态最佳。
系统要求:支持 Win10/Win11/macOS(仅限Apple Silicon,Intel 版本的 Mac 无法调用 Radeon 显卡)和 Linux 系统,苹果版SD兼容的插件数量较少,功能性不及 Windows 与 Linux 电脑。
如果身边没有合适的电脑可以考虑购买云主机,比如腾讯GPU云服务器。若无法使用独立显卡和云服务,亦可修改启动配置,使用CPU渲染(兼容性强,出图速度慢,需要16G以上内存)。
1.2 安装方法
Github上下载地址如下:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
现在完成后可参照说明进行安装,也可搜索其他安装教程或者直接使用网上整合包,本人环境如下,仅供参考:
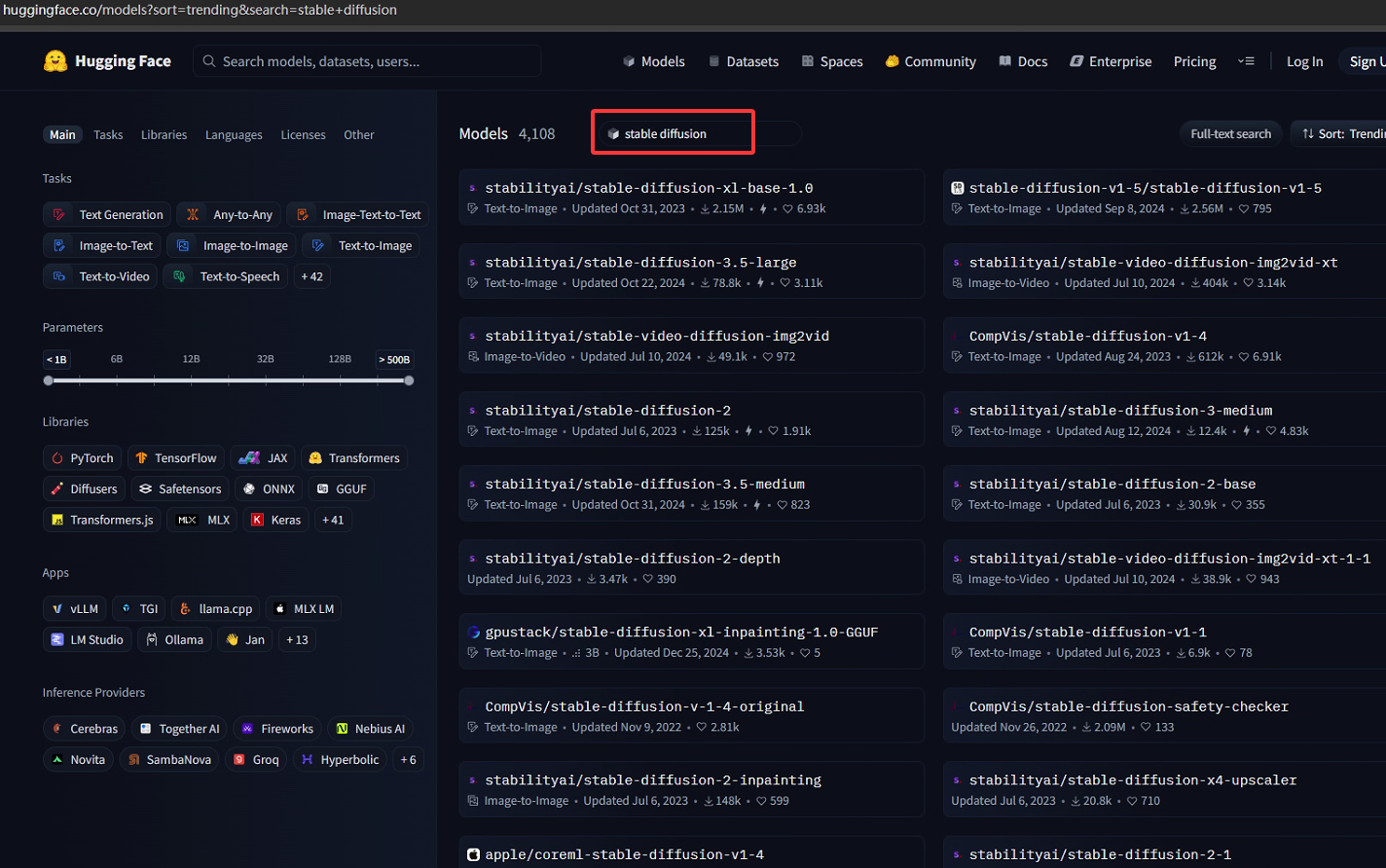
之后需要下载相应的模型,基础模型可从Hugging Face官方页面下载,包含 v1.4 到 v2.1 的全系列模型。
也可以从第三方平台civitai.com、LiblibAI、吐司等平台下载合适模型。Stable Diffusion 不同类型的模型下载后存放路径有所不同,以下是常见模型的存放路径:
基础模型(大模型):通常存放在Stable Diffusion安装目录\models\Stable-diffusion路径下。例如,将 Stable Diffusion 安装在D:\stable-diffusion-webui,那么基础模型就应放在D:\stable-diffusion-webui\models\Stable-diffusion中。
VAE 模型:可以存放在Stable Diffusion安装目录\models\VAE路径下。部分大模型会自带 VAE 模型,也可根据需要将单独下载的 VAE 模型放置在此目录,然后在 Stable Diffusion 用户界面的设置中选择相应的 VAE 模型。
Lora 模型:可以存放在Stable Diffusion安装目录\extensions\sd-webui-additional-networks\models\lora路径下,也可以放在Stable Diffusion安装目录\models\Lora目录中。
Embedding 模型:存放在Stable Diffusion安装目录\embeddings路径下。
如在本人安装目录下有以下两种基础模型:

这两种比较典型的模型文件,它们有以下区别:
1 存储结构与原理
.ckpt(Checkpoint):是 PyTorch 原生的模型保存格式,它是一种通用的模型权重存储格式,能够保存整个模型的状态字典(包括所有层的权重、偏置等参数) ,以及训练过程中的一些信息,比如优化器的状态、训练轮数等。在深度学习训练中,经常会保存.ckpt文件来记录模型在某个训练阶段的状态,方便后续继续训练或者加载使用。
.safetensors:是专门为安全加载而设计的一种张量格式,它的设计目的是防止代码执行漏洞。与.ckpt相比,.safetensors 只专注于存储张量数据(即模型的权重参数),不会存储像优化器状态这类额外的训练信息。它通过验证张量的元数据来确保加载过程的安全性,减少了恶意代码注入的风险。
2 文件大小
.ckpt:由于.ckpt文件除了模型权重外,还会存储一些训练相关的额外信息,所以通常文件大小相对较大。
.safetensors:只保存张量数据,不包含其他额外信息,在存储相同模型权重的情况下,文件大小一般会比.ckpt 文件更小,这在下载和存储模型时可以节省一定的磁盘空间和网络带宽。
3 加载速度与性能
.ckpt:在加载.ckpt文件时,PyTorch 需要解析文件中的各种信息,包括模型权重、优化器状态等,加载过程相对复杂一些,尤其是当文件较大且包含大量额外信息时,加载速度可能会受到影响。
.safetensors:.safetensors的设计更侧重于快速加载张量数据,其加载速度通常更快,特别是对于较大的模型,在 Stable Diffusion 中使用.safetensors格式的模型可以更快地启动生成图像的过程。
4 兼容性与社区支持
.ckpt:作为 PyTorch 的原生格式,.ckpt被广泛支持,在各种深度学习框架和工具中都能比较方便地加载和使用。在 Stable Diffusion 早期,.ckpt是主流的模型分享格式,社区中有大量基于.ckpt格式的模型资源。
.safetensors:随着对模型安全加载需求的增加,.safetensors逐渐受到欢迎,目前在 Stable Diffusion 社区中也有大量的模型以这种格式发布,并且越来越多的工具和框架开始支持.safetensors格式,其兼容性在不断提升。使用.safetensors格式的模型可以更快地启动生成图像的过程。
2 使用详解
2.1 界面介绍
这里直接使用python launch.py启动项目:
主界面内容显示如下:
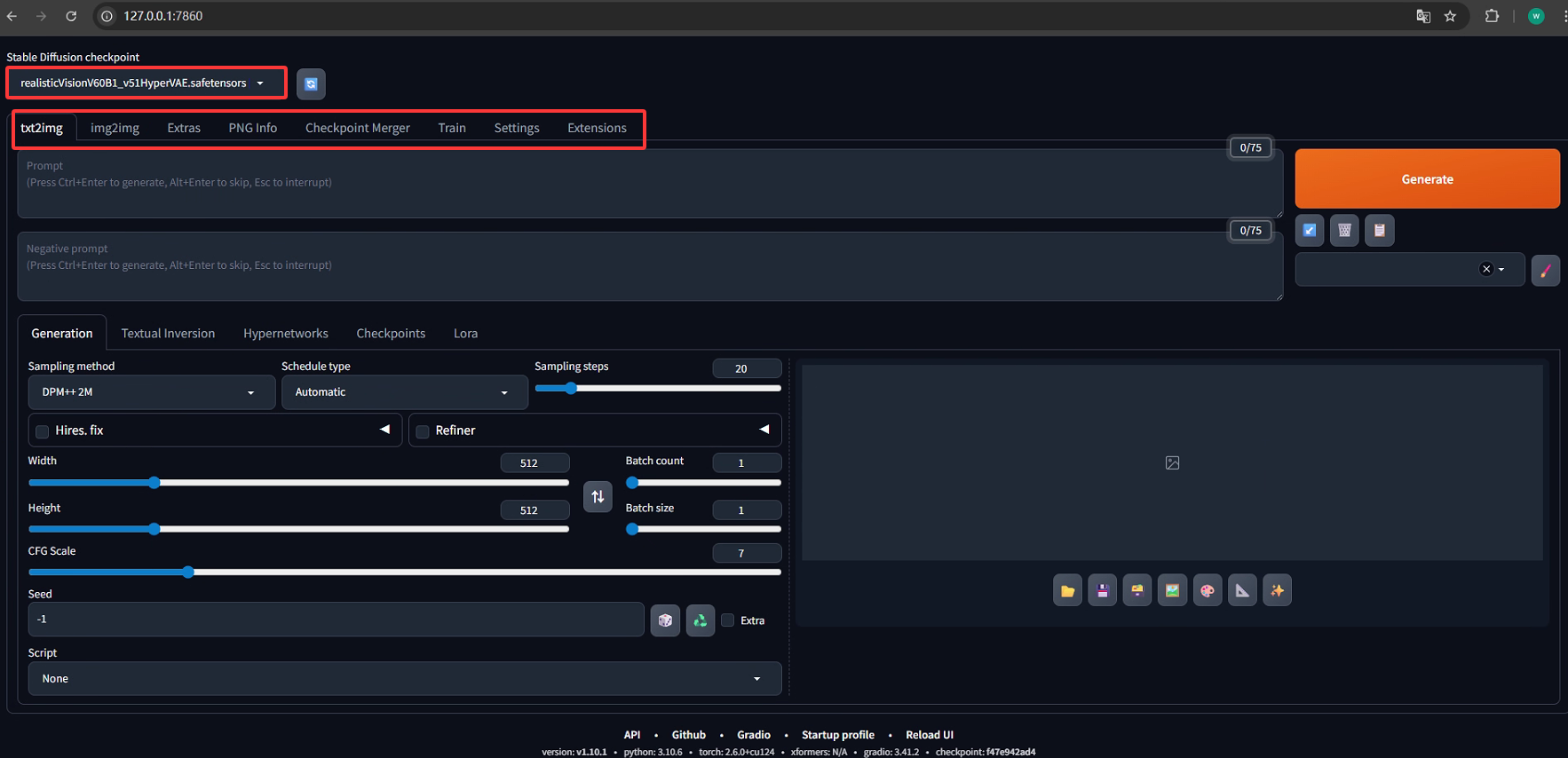
1. 主要功能
这里默认使用的是CivitAI上模型Realistic Vision V6.0 B1,本安装下主要功能选项如下:
txt2img:文生图,根据文本提示生成图像;
img2img:图生图,根据提供的图像作为范本、结合文本提示生成图像;
Extras:更多,如优化(清晰、扩展)图像;
PNG Info:显示图像基本信息,包含提示词和模型信息(除非信息被隐藏);
Checkpoint Merger:模型合并,把已有的模型按不同比例进行合并生成新模型;
Train:根据提供的图片训练具有某种图像风格的模型;
Settings:所有设置项;
Extensions:显示安装及使能扩展项;
以文生图为例,接下来内容是描述语分为正向/负向描述,它们也叫tag(标签)或prompt(提示词)
正面提示词:相比Midjourney需要写得更精准和细致,描述少就给AI更多自由发挥空间。
负面提示词:不想让SD生成的内容。
正向:masterpiece, best quality, 更多画质词,画面描述
反向:nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry,根据画面产出加入不想出现的画面。
对于正向提示词,一般而言,概念性的、大范围的、风格化的关键词写在前面,叙述画面内容的关键词其次,最后是描述细节的关键词,大致顺序如下:
(画面质量提示词), (画面主题内容)(风格), (相关艺术家), (其他细节)2. 采样方法
在Stable Diffusion中,不同采样方法在生成图像的质量、速度、效果多样性等方面各有特点,以下是常见采样方法的介绍:
DPM++ 系列
DPM++ 2M:是一种较为常用的采样方法,在生成图像质量和速度上取得了较好的平衡,能生成细节丰富、清晰度较高的图像。
DPM++ SDE:倾向于生成更加多样化和具有创意的图像,对于需要探索不同风格和效果的场景比较适用,但在生成速度上可能会稍慢一些。
DPM++ 2M SDE:结合了 DPM++ 2M 和 SDE 的优点,在生成图像的多样性和质量上有不错的表现,相比 DPM++ SDE,它在速度上可能会有所提升。适合用于创意探索,比如在进行艺术创作、概念设计等任务,快速得到多种不同风格和创意的图像,以获取灵感。
DPM++ 2M SDE Heun:在 DPM++ 2M SDE 的基础上,采用了 Heun 方法来改进数值积分过程。Heun 方法是一种二阶数值积分方法,相比一些基础的积分方法,它通过对梯度进行预估校正,能更准确地逼近真实的解曲线。生成速度慢一些,更适合对图像质量要求较高的场景。
DPM++ 2S a:通常能够产生相对稳定且质量较高的图像,在一些对生成效果稳定性要求较高的情况下可以优先选择。
DPM++ 3M SDE:在处理复杂图像生成任务时表现出色,能更好地捕捉和呈现细节,但计算量相对较大,生成时间可能较长。
Euler 系列
Euler a:采样速度较快,生成的图像往往具有较为鲜明的风格特点,但在图像细节的精确性上可能不如一些更复杂的采样方法,适合快速预览生成效果。
Euler:是较为基础的采样方法,生成效果相对简洁,在一些对计算资源要求较高的情况下,使用它可以降低计算开销,但生成图像的细节丰富程度可能有限。
其他方法
LMS(Least Mean Squares):在生成图像时,能够较好地保持图像的整体结构和连贯性,生成的结果通常比较符合预期,不会出现过于夸张或不自然的效果。
Heun:是一种改进的数值积分方法,生成的图像在质量上有一定保障,同时在速度方面也有不错的表现,适用于对图像质量有一定要求且希望生成过程不要太慢的场景。
DPM2:可以在相对较短的时间内生成质量较好的图像,对于一些对生成速度有要求,但又希望图像质量不至于太差的任务比较合适。
DPM fast:正如其名,采样速度非常快,能够快速生成图像,适合需要快速得到大量生成结果的初步探索阶段,但图像质量可能会略逊于一些更精细的采样方法。
DPM adaptive:能够根据生成过程自动调整采样步长,在保证一定图像质量的同时,尽量提高生成效率,在不同的生成任务中表现较为灵活。
Restart:在生成过程中通过重新启动采样过程,有可能探索到更多不同的结果,增加生成图像的多样性,但也可能会导致生成时间变长。
DDIM(Denoising Diffusion Implicit Models):生成的图像质量较高,能够生成细节丰富、逼真的图像,不过生成速度相对较慢,适用于对图像质量要求极高的场景。
DDIM CFG++:在 DDIM 的基础上进行了改进,进一步提升了生成图像与提示词的匹配度,使得生成的图像更符合用户输入的文本描述。
PLMS(Predictive Latent Model Sampling):生成的图像具有较好的稳定性和质量,在处理一些常规的图像生成任务时表现出色,是一个比较均衡的选择。
UniPC:在采样效率和图像生成质量上都有不错的表现,能够在较短时间内生成高质量的图像,逐渐受到用户的关注和使用。
LCM(Latent Consistency Models):采样速度极快,相比其他很多采样方法,它能在极短的时间内生成图像,并且生成的图像质量也能达到较高的水平,非常适合追求高效生成图像的场景。
3. 调度类型
不同调度类型会影响采样过程中噪声调度(即去噪的节奏和方式),进而影响生成图像的质量、风格和速度等,以下是各选项特点分析:
Automatic(自动):由系统自动选择最合适的调度策略,无需用户手动指定。适合新手或希望快速生成图像,不想深入调整调度细节的场景,能在大多数情况下保证基本的生成效果。
Uniform(均匀):噪声在整个采样过程中以均匀的方式进行调度,去噪的步长或强度变化较为平稳、规律。生成的图像可能在风格上比较均衡,没有过于突兀的变化,但有时可能缺乏一些细节上的 "惊喜" 或独特性。
Karras:是一种经过优化的调度策略,通常能生成质量较高、细节更丰富的图像。它在噪声调度的设计上更贴合扩散模型的特性,有助于更好地捕捉图像的纹理、结构等细节,在追求图像质量的场景中较为常用。
Exponential(指数):噪声调度遵循指数规律变化,去噪的节奏可能在前期或后期有更明显的加速或减速。生成的图像可能在风格上带有一定的 "动态感",或者在某些艺术表现上有特殊的效果,比如营造出渐变、过渡自然的视觉体验。
Polyexponential(多指数):结合了多种指数相关的调度方式,能更灵活地控制去噪过程。可以根据不同的生成需求,在不同阶段采用不同的指数调度逻辑,从而生成风格多样、细节表现更丰富的图像,不过对参数的敏感性可能更高。
SGM Uniform(Score - Based Generative Model Uniform):基于分数生成模型(SGM)的均匀调度,利用分数模型对数据分布的建模能力,结合均匀调度的平稳性,在生成图像的真实性和多样性之间取得平衡,适合生成更接近真实场景或具有自然分布特征的图像。
KL Optimal(KL 最优):以 KL 散度(Kullback - Leibler divergence)为优化目标,追求在调度过程中使模型分布与真实分布的差异最小化。生成的图像往往在概率分布层面更接近真实数据,质量较高,细节和纹理的还原度较好。
Align Your Steps:注重采样步骤之间的协调性和一致性,确保每一步的去噪操作都能很好地衔接,避免步骤间的 "跳跃" 或不协调导致图像出现瑕疵。生成的图像在整体连贯性和完整性上表现较好,适合生成结构复杂、需要各部分协调统一的图像。
Simple(简单):采用简洁的调度逻辑,计算开销小,生成速度快。适合快速生成图像进行预览,或者在对图像质量要求不高、更看重生成效率的场景下使用,不过生成的图像可能在细节丰富度上有所欠缺。
Normal(正常):是一种比较基础、常规的调度方式,各方面表现相对均衡,没有特别突出的偏向性。适用于一般的图像生成任务,作为默认或基准的调度选择。
DDIM(Denoising Diffusion Implicit Models):是一种经典的扩散模型采样方法,能通过较少的采样步骤生成质量较高的图像,在速度和质量之间有较好的平衡。生成的图像通常细节清晰,并且可以通过控制采样步骤数来灵活调整生成速度和质量。
Beta:与扩散过程中的 β 参数(控制噪声添加的系数)相关,通过对 β 的调度来影响去噪过程。可以精细地控制噪声的添加和去除节奏,从而对生成图像的风格、对比度等产生影响,适合有针对性地调整图像效果的场景。
4. 采样步数
稳定扩散通过从充满噪音的画布开始创建图像,并逐渐去噪以达到最终输出。此参数控制这些去噪步骤的数量,通常越高越好,但在一定程度上,我们使用的默认值是25个步骤。以下是不同情况下使用哪个步骤编号的一般指南:
如果您正在测试新的提示,并希望获得快速结果来调整您的输入,请使用10-15个步骤
当您找到您喜欢的提示时,请将步骤增加到25
如果是有毛皮的动物或有纹理的主题,生成的图像缺少一些细节,尝试将其提高到40
5. Hires. fix
用于高分辨率修复,作用是先生成低分辨率图像,再通过特定算法将其放大到更高分辨率,同时优化细节,避免放大后模糊。下面逐一解释各参数:
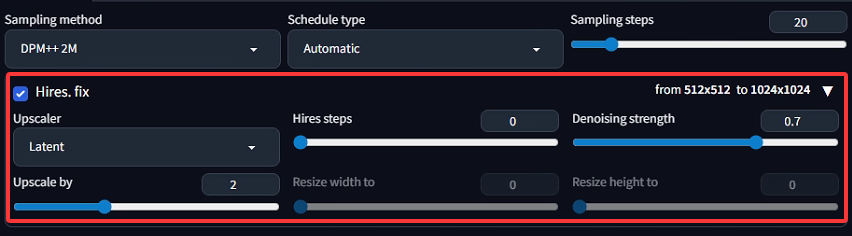
1)Hires. fix(高分辨率修复)
勾选后启用该功能,会分两步生成图像:先以较小尺寸(如图中初始的 512x512)生成基础图像,再放大到目标尺寸(如图中 1024x1024)并优化细节。
2)Upscaler(升采样器)
选择 "Latent" 表示使用潜在空间升采样算法。这种算法在 Stable Diffusion 的潜在空间(而非像素空间)中进行放大,能更高效地保留图像细节,同时利用扩散模型的生成能力补充放大后的纹理。
3)Upscale by(放大倍数)
上图中设为 2,表示将初始图像的长和宽都放大 2 倍(比如 512x512 放大后变为 1024x1024)。也可通过 Resize width to/Resize height to 直接指定目标宽高(当这两个参数不为 0 时,优先级更高)。
4)Hires steps(高分辨率步骤数)
设为0时,通常表示 "复用基础生成的步骤数"(或由插件/版本自动处理)。若设为正数,会额外增加专门用于高分辨率优化的采样步骤,步骤越多细节优化越精细,但生成时间越长。
5)Denoising strength(去噪强度)
范围 0~1,控制放大过程中 "重新生成细节" 的程度:
接近 0:几乎保留低分辨率图像的所有像素,放大后变化小(但可能模糊)。
接近 1:更激进地根据提示词重新生成细节,放大后图像更清晰、细节更丰富,但可能与低分辨率版本差异较大。
图中设为 0.7,属于中等强度,平衡了细节优化和与原图的一致性。
6. Refiner
精细化模型,作用是分阶段使用不同模型生成图像:先由基础模型生成初步图像,再切换到更擅长细节优化的 "Refiner 模型",对图像进行精细化处理,提升最终效果的细节质量。下面逐一解释各参数:

1)Refiner(核心开关)
勾选后启用 "精细化模型" 功能,允许生成过程中切换模型,用专门的 Refiner 模型优化图像细节。
2)Checkpoint(模型选择)
下拉菜单用于选择精细化模型(需提前下载并放入模型目录)。Refiner 模型通常是针对 "细节优化" 训练的,能在生成后期为图像补充更精细的纹理、光影等。
3)Switch at(切换时机)
取值范围 0~1,表示 "在总采样步骤的百分之多少时,切换到 Refiner 模型"。
例如图中设为 0.8,表示前 80% 的采样步骤用基础模型生成图像大轮廓,后 20% 的步骤用Refiner 模型优化细节。切换时机越晚(值越大),基础模型对图像整体风格的影响越强;切换时机越早(值越小),Refiner 模型对细节的优化越充分,但可能改变基础模型的整体风格。
7. 其他配置
接下来介绍最后剩余的参数内容:
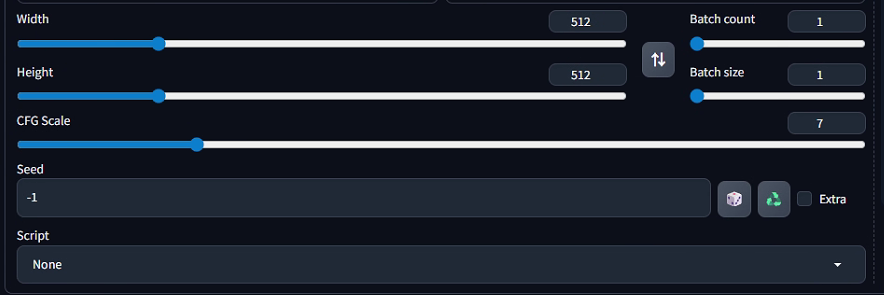
1)Width(宽度)
控制生成图像的宽度像素值(图中为 512)。值越大,图像横向越宽,能容纳更多横向细节,但对显卡显存要求更高,生成速度也会变慢。
2)Height(高度)
控制生成图像的高度像素值(图中为 512)。与 Width 共同决定图像的分辨率(图中为 512×512),值越大,图像纵向越高,细节越丰富,但显存和速度压力也越大。
3)Batch count(批量生成次数)
表示 "要生成多少组图像"(每组的数量由 Batch size 决定)。例如 Batch count=2、Batch size=1 会生成 2 张独立的图像。
4)Batch size(每批生成数量)
表示 "每次同时生成多少张图像"(受显卡显存限制,显存小则需设小值)。例如 Batch size=2 会一次生成 2 张图像,效率更高,但对显存要求翻倍。
5)CFG Scale(分类器自由引导尺度)
控制提示词(Prompt)对生成图像的影响强度:
值越小:生成越 "自由",图像可能偏离提示词,但风格更随机、有创意。
值越大:生成越 "严格遵循提示词",图像更贴合文字描述,但可能缺乏变化,甚至出现生硬感。
图中设为 7,属于 "中等强度",平衡了提示词约束与生成灵活性。
6)Seed(随机种子)
控制生成的随机性:
设为固定数值(如 1234):每次用相同种子生成的图像会完全一致,方便复现结果。
设为 -1(图中状态):每次生成都是 "随机种子",图像结果完全不同,用于探索多样的创意。
右侧骰子图标:点击后随机生成新种子;循环箭头图标:复制当前种子(方便复现)。
7)Script(脚本)
下拉菜单可选择自定义脚本(图中为 None,即不使用脚本)。脚本用于实现特殊生成逻辑,例如 "批量生成不同姿势的角色""按顺序变化某一参数" 等高级功能。
2.2 实例讲解
以Civitai中https://civitai.com/images/90751853为例说明一下该图像生成过程,从其主页可知,它使用的基础模型是Realistic Vision V6.0 B1,如果该模型未下载需首先下载该模型并将模型文件放到相应目录,此外该示例还使用到4x_NMKD-Siax_200k这一用于图像超分辨率(即放大图像并增强细节)的模型,该模型属于 "升采样器(Upscaler)",其特点是能将低分辨率图像(如512x512)放大到更高分辨率(如2048x2048),同时通过模型训练学到的 "细节模式",为放大后的图像补充纹理、边缘等细节,避免传统插值放大(如双线性、双三次)导致的模糊、锯齿感。

可以在页面链接中先下载该模型,并将其放到stable-diffusion-webui\models\ESRGAN目录下,虽然4x_NMKD-Siax_200k并非严格意义上基于 ESRGAN 架构,但在webui中,通常将超分辨率模型都放置在这个目录下。放置好后,重启 Stable Diffusion webui,在 "Extras"(额外)选项卡中的 "Upscaler"(放大算法选择框)里就能找到该模型,用于对已生成的图像进行超分辨率处理;在 "High - Resolution Fix"(高分辨率修复)功能中,也可以选择它作为放大模型 。将正反提示词拷贝进相应输入框,然后Sampling method选为DPM++ SDE,Sampling steps设置为6,CFG Scale设置为1.5,Seed设置为3197516009,按示例图片的大小配置宽高为512x768,然后单击Generate按钮即可生成和示例类似的图片。

需要说明的是示例并没有给出Schedule type具体选项,在生成是选择不同的选项产生的图片还是有些许区别的,这里选择Simple感觉和示例图片最为接近。最后可在Extras功能页对产生的图片4x_NMKD-Siax_200k进行Scalex2操作,即可得出清晰度更高的图片。
3 API应用
3.1 开启API
使用如下命令重新启动程序:
python launch.py --api --listen然后再浏览器中输入地址:http://127.0.0.1:7860/docs,就能看到如下所示所有接口文档了,可从文档中找到需要接口及详细参数。

3.2 文生图调用示例
文生图接口,可以通过向stable-diffusion-webui post发送正向关键字、反向关键字、图片尺寸、采样步数等参数来调用AI能力生成图片,下图显示了它有哪些可配置的payload参数选项。

以下对常用的配置参数进行了注释:
{
"prompt": "", // 正向关键字
"negative_prompt": "", // 反向关键字
"styles": [
"string"
],
"seed": -1, // 随机种子
"subseed": -1, // 子级种子
"subseed_strength": 0, // 子级种子影响力度
"seed_resize_from_h": -1,
"seed_resize_from_w": -1,
"sampler_name": "string", // 采样方法
"scheduler": "string",
"batch_size": 1, // 每次生成的张数
"n_iter": 1, // 生成批次
"steps": 50, // 生成步数
"cfg_scale": 7, // 提示词影响程度
"width": 512, // 生成图像宽度
"height": 512, // 生成图像高度
"restore_faces": true, // 面部修复
"tiling": true, // 平铺
"do_not_save_samples": false,
"do_not_save_grid": false,
"eta": 0, // 等待时间
"denoising_strength": 0,
"s_min_uncond": 0,
"s_churn": 0,
"s_tmax": 0,
"s_tmin": 0,
"s_noise": 0,
"override_settings": {}, // 覆盖性配置
"override_settings_restore_afterwards": true,
"refiner_checkpoint": "string",
"refiner_switch_at": 0,
"disable_extra_networks": false,
"firstpass_image": "string",
"comments": {},
"enable_hr": false,
"firstphase_width": 0,
"firstphase_height": 0,
"hr_scale": 2,
"hr_upscaler": "string",
"hr_second_pass_steps": 0,
"hr_resize_x": 0,
"hr_resize_y": 0,
"hr_checkpoint_name": "string",
"hr_sampler_name": "string",
"hr_scheduler": "string",
"hr_prompt": "",
"hr_negative_prompt": "",
"force_task_id": "string",
"sampler_index": "Euler",
"script_name": "string",
"script_args": [], // lora模型参数配置
"send_images": true, // 是否发送图像
"save_images": false, // 是否在服务端保存生成的图像
"alwayson_scripts": {},
"infotext": "string"
}以下python代码示例了文生图api接口调用,及处理返回结果并保存生成图像的详细过程:
import requests
import json
import base64
from PIL import Image
import io
# Stable Diffusion API 的基础 URL,需替换为你实际部署的地址
base_url = "http://127.0.0.1:7860"
api_endpoint = "/sdapi/v1/txt2img"
# 构建请求体参数
payload = {
"prompt": "a beautiful landscape with mountains and a lake", # 正向提示词,描述要生成的图像
"negative_prompt": "ugly, blurry, low quality", # 负向提示词,避免生成的问题
"steps": 20, # 采样步数
"width": 512, # 生成图像宽度
"height": 512, # 生成图像高度
"cfg_scale": 7, # CFG 缩放,控制提示词影响程度
"sampler_name": "Euler", # 采样器名称
"batch_size": 2 # 每批生成图像数量
}
try:
# 发送 POST 请求
response = requests.post(
f"{base_url}{api_endpoint}",
json=payload
)
response.raise_for_status() # 若响应状态码非200,抛出异常
# 解析响应 JSON 数据
response_data = response.json()
# 提取图像数据(通常在 'images' 列表中,是 base64 编码的字符串)
if "images" in response_data:
nLen = len(response_data["images"])
if nLen > 0:
for i in range(nLen):
image_data = response_data["images"][i]
# 将 base64 编码的图像数据转换为字节流
image_bytes = io.BytesIO(base64.b64decode(image_data))
# 打开图像
image = Image.open(image_bytes)
filename = "generated_image%d.png"%i
# 保存图像
image.save(filename)
print("图像生成成功,已保存为"+filename)
else:
print("响应中未找到图像数据")
except requests.exceptions.RequestException as e:
print(f"请求发生错误: {e}")
except json.JSONDecodeError:
print("响应 JSON 解析失败")
except Exception as e:
print(f"发生未知错误: {e}")