几天前,Google 悄然发布了一款小型 AI 模型,名为 Gemma 3 270M。
它体型极小,甚至能在配置极低的设备上运行。当然,也不是真的能在"土豆"(指完全无法使用的设备)上运行,但它仅需约 0.5GB 内存。这......基本上相当于没占多少内存。
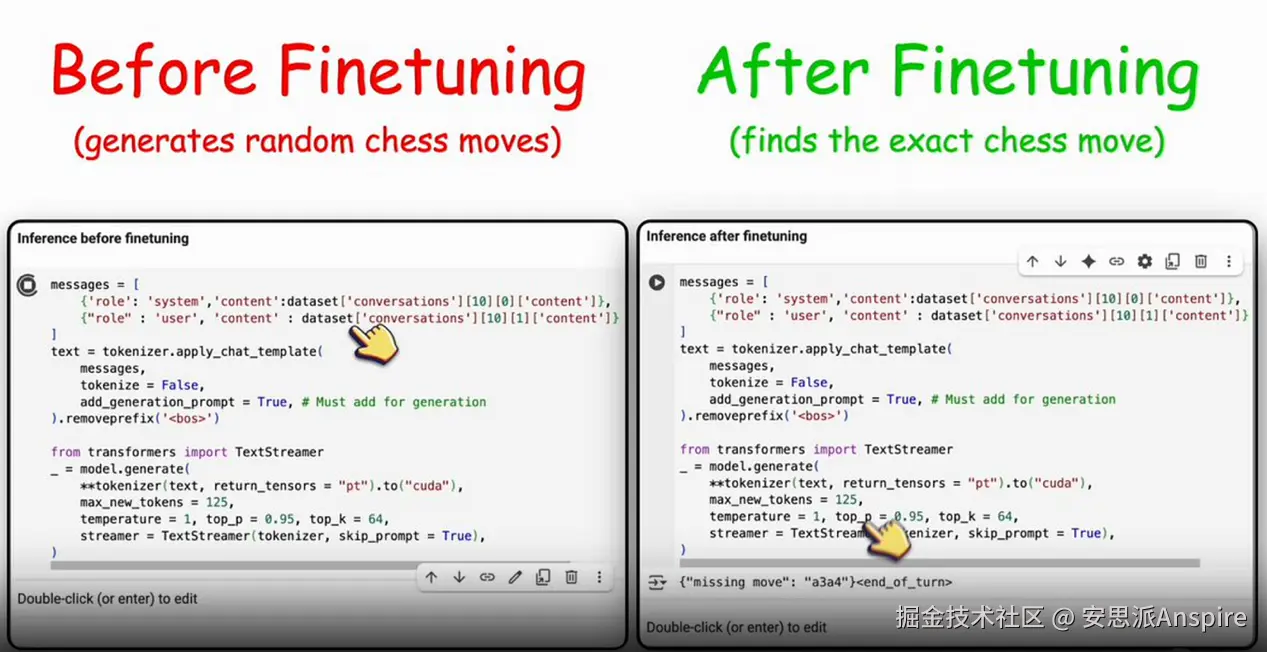
显然,我忍不住想找个有趣的方向对它进行微调,于是选择了国际象棋这个主题。
我的目标是:给它一个接近结束的国际象棋棋局,问它"缺失的走法是什么?",看看它能否准确给出答案。
全程离线进行。不需要云端 GPU,也不会产生让我心疼的信用卡账单。
我使用的工具
以下是我为这次实验准备的小工具集:
-
Unsloth AI------能让小型模型的微调速度快到惊人。
-
Hugging Face Transformers------因为它是本地运行 LLM 的标准工具。
-
ChessInstruct 数据集------包含带有一个缺失走法的棋局,用于训练。
步骤 1:加载模型
这一步很简单。通过 Unsloth 加载 Gemma 3 即可:
ini
# pip install unsloth
from unsloth import FastLanguageModel
import torch
MODEL = "unsloth/gemma-3-270m-it"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = MODEL,
max_seq_length = 2048,
dtype = None,
load_in_4bit = False,
full_finetuning = False
)搞定。模型已加载。
步骤 2:LoRA 微调(又称"小幅修改,显著效果")
我没有对整个模型重新训练(那样会让我的笔记本电脑"过载"),而是使用了 LoRA(低秩适应)。可以把它理解为:不给 AI 更换整个"大脑",只给它新增几个神经元。
ini
from unsloth import FastModel
model = FastModel.get_peft_model(
model,
r = 128,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
use_gradient_checkpointing = "unsloth",
lora_alpha = 128,
lora_dropout = 0,
bias = "none",
random_state = 3407
)步骤 3:获取数据集
该数据集包含不完整的棋局。任务(在本次实验中即 AI 的任务)是补全其中缺失的走法。
ini
from datasets import load_dataset
dataset = load_dataset("Thytu/ChessInstruct", split="train[:10000]")
print(dataset[0])样本条目示例:
sql
走法(Moves):c2c4、g8f6、b1c3、......、?,结果(result):1/2-1/2
预期答案(Expected):e6f7步骤 4:将数据处理为适用于对话的格式
模型偏好以结构化的方式"交互",因此我将数据封装成了对话格式。
python
from unsloth.chat_templates import standardize_data_formats
dataset = standardize_data_formats(dataset)
def convert_to_chatml(example):
return {
"conversations": [
{"role": "system", "content": example["task"]},
{"role": "user", "content": str(example["input"])},
{"role": "assistant", "content": example["expected_output"]}
]
}
dataset = dataset.map(convert_to_chatml)步骤 5:训练设置
设置较小的批次大小、少量训练步数,即可启动训练。
ini
from trl import SFTTrainer, SFTConfig
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
args=SFTConfig(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
max_steps=100,
learning_rate=5e-5,
optim="adamw_8bit"
)
)步骤 6:开始训练!
ini
trainer_stats = trainer.train()