一些基本概念
-
万维网 (
world wide web):是一个基于互联网的全球性 信息系统,通过超文本技术 实现信息的互联与共享 ,用户可通过浏览器访问 分布在全球 服务器上的文档、图片等资源。 -
超文本 :包含 了指向其他链接 的文本文档称为超文本,能够 被浏览器所识别 。一个超文本由多个信息源组成 ,而这些信息源可以分布在世界各地,并且数量不受限制 。超文本技术是万维网的基础------通过超文本技术将一个又一个链接连接在一起,就组成了一个超大型的联机式信息储藏所。
-
万维网使用的是B/S模型 :即浏览器服务器模型。浏览器向服务器发送请求,服务器响应浏览器并发送客户端所需要的超文本。
-
URL(Uniform Resource Locator)统一资源定位符 :用来标识超文本在万维网中的唯一标识,表明了该超文本的信息,具有唯一性。网络访问中,就是依照此来进行请求以及响应的。-
URL由四部分 组成协议:// 主机名:端口号/路径 -
例如:
http://www.baidu.com/index.php------其中www.baidu.com采用域名解析 的方式代替了主机名:端口号这一网络唯一标识 -
协议 :指出使用的是何种协议来获取万维网的文档,除了
http以外还可以是https(http的加密版本),FTP(文件传输协议),SMTP(邮件传输协议)等。 -
主机名:是万维网文档所在的主机
ip,通常 以www开头,也可以直接使用主机的ip地址来替代。 -
端口号:要连接的主机的端口号,对于
http协议而言,默认的端口号就是**80**。 -
路径:较长的字符串,超文本文档所在的路径。
-
-
域名解析:简单的来说就是将容易记忆的域名,比如:
baidu.com。解析成互联网上的位置ip:端口号。域名解析技术 同样是万维网的基础。
超文本传输协议HTTP
-
概念:
HTTP协议定义了浏览器是怎样从万维网中请求超文本,以及服务器如何把文档传递给浏览器的。 -
定位:
HTTP协议是面向事务 的应用层协议 ,能够实现可靠的文件传输。-
事务:一次
http连接是一个整体 ,要么全部 执行,要么就全部不执行,即http连接具有原子性 ------由此也可以看出http本身是无连接的协议。 -
可靠:
http协议信息传输使用的协议是TCP协议或者QUIC协议,而这两个协议都具有可靠性 ,所以HTTP的文件传输是可靠的。
-
-
HTTP协议永远是客户端发起请求 ,服务器响应请求 。这样就限制了HTTP协议使用时,无法实现在客户端没有发起请求时,服务器就向客户端发送消息。 -
HTTP协议是无状态 的协议,即:本次连接和过去未来的任何一次连接都没有关系。 -
HTTP协议本身是无连接 的,服务器在处理完客户端的请求之后会断开连接。
可以看出HTTP的设计理念是按照需求给与资源——每次请求只能由客户端发起确认了按需获取资源的模式——服务器不会在客户端不需要某些资源的情况下主动向客户端发送资源。 同时http协议的无连接性也表明服务器只处理当前请求,而不考虑未来可能的请求——这也体现了按需处理的理念。
超文本标记语言HTML
-
HTML
(HyperText Markup Language):超文本标记语言,是用来完成超文本文档的编写的------html并不是一种协议,而是万维网浏览器能够识别的一种语言。 -
该语言中定义了需要使用的排版命令 ,这些命令我们称之为"标签"
-
使用
html语言编写的文档称为超文本,后缀为**.html或者.htm** -
浏览器主要解析的就是该语言编写出来的超文本,能够将相关标签解析为界面。
-
简单来说
html语言就是超文本使用的一种**ui排版语言**。
常用标签
-
标签格式:使用双尖括号包裹着关键字,通常成对出现
html<body> 内容 </body> -
标签分类:
html单标签:空标签<标签名/> 例如<br/> 双标签:成对出现<标签名/>内容<标签名/> -
常用的标签:
htmlh1 - h6 标题标签 p 段落标签 div 盒子标签 input 输入标签
第一个HTML文件
html
<!-- 第一行:文档类型,html说明是超文本文档 -->
<!DOCTYPE html>
<!-- 第二行:表示整个界面的开始标签,是一个双标签 -->
<html lang="en">
<!-- 浏览器头部信息 -->
<head>
<!-- 表示编码格式 -->
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<!-- 浏览器的标题 -->
<title>第一个HTML文件</title>
</head>
<body>
<!-- 整个页面的整体 -->
<!-- h标签表示的是一个标题 -->
<h1>第一个HTML文件</h1>
<!-- a标签表示的是一个超链接 -->
<a href="www.baidu.com">百度一下</a>
<br>
账号:<input type="text">
<br>
密码:<input type="password">
</body>
<!-- 结束 -->
</html>HTTP版本
http 1.0版本
浏览器诞生后的第一个标准,是一个短连接 的版本------一次http链接只进行一次数据收发。
这个版本很大的一个问题就是每发起一个请求 ,就要建立一次 TCP的连接 ,极大的浪费了TCP在长数据传输上的优势;并且还是串行请求 ------就像以前的批处理操作系统 一样,只有 上一次请求完成之后才能进行下一次请求。
http 1.1版本
在1.0版本的基础上增加了连续连接 的功能。服务器在发送响应后的一段时间内仍然 保持这条连接,使同一个客户端和服务器可以在这条连接上继续后续的请求和响应工作。直到 某一端主动断开 连接或者长时间不响应 时也会断开连接 。------这种方式就极大了减少 了不必要的tcp连接次数,增大了传输效率。
http 1.1版本支持两种工作模式:
-
非流水线方式 :客户端在收到前一个响应之后才能发出下一个请求。
-
流水线方式 :客户端在收到前一个响应之前 就能直接发送下一个而请求。
特点:简单 ,灵活易于扩展
不足:依旧是无状态 ,没有加密机制。
http1.1版本的特点
使用长连接的方式,解决了1.0版本的短连接的性能问题:只要任意一端没有明确提出断开连接,那么则一直保持TCP的连接状态 使用管道网络传输:允许在同一个TCP连接中,建立多个管道,客户端可以发送多个请求,不需要等到客户端响应后才发送另一个请求。这样就提高了整体的响应时间。解决了请求的对头阻塞 不足是:服务器端必须按照接收请求的顺序发送这些请求的响应,如果服务器在处理请求A花费了很长的时间,那么后续的请求的处理就都会被阻塞,这称为响应队头阻塞 实际上HTTP1.1的管道化技术并不是默认开启的,而且很多浏览器技术都不支持。所以,大家只需要知道http1.1版本提供了该功能,但是并没有得到广泛应用
http1.1的瓶颈
头部巨大且重复:http头部会含有很多固定的字段,并且加起来会有几百字节甚至上千字节,未经压缩就直接发送。大量的请求和响应报文中会有很多重复的字段:http协议是无状态的,想要记录之前的操作,在首部外加了一个cookie的技术,也会使得首部比较巨大 http1.1版本传输请求和响应的过程使用的是ASCII编码完成,而不是二进制编码 并发连接数是有限的,以谷歌为例,最大的并发连接数是6个,而且每个连接都要经过TCP的三次握手,以及TCP的慢启动过程 响应队头阻塞问题没有解决 不支持服务器推送过程,只能客户端请求,服务器响应.
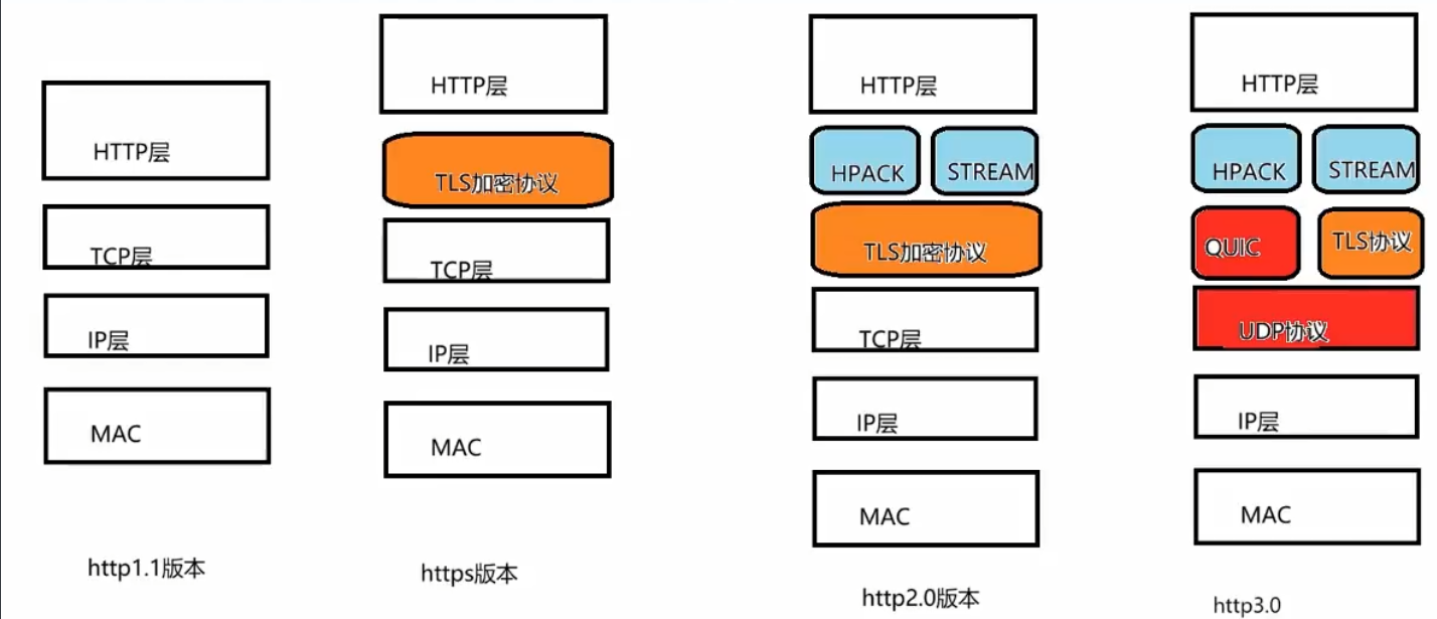
http2.0版本
-
2015年推出了http2.0版本,目的是为了改善http的性能 ,并且兼容 了http1.1版本 -
http2.0版本只在应用层 做了改变 ,传输层还是使用的TCP传输协议。http2.0把http分成 从语义 和语法 两部分,其中语义层不做改动 ,跟http1.1保持一致,但是在语法部分做了很多改动,基本上改变 了HTTP的报文传输格式 -
http2.0完成了头部压缩,http2.0使用了**HPACK** 的算法,发送的是压缩后的内容,这样就可以节约带宽,解决了http1.1版本的头部巨大且重复 的问题。HPACK算法将传输过程中进行的同一个TCP传输的内容进行合并 ,重复 的内容不需要 进行传输 了,提高 传输效率。 -
http2.0能够实现并发 传输:引入了stream的概念,可以实现并发发送stream,只需 要建立一个TCP的连接 ,节约 了多次建立连接过程中握手 机制的时间 ------实际 上就是一种多路复用 机制,避免 了连接数量过多 带来的一些问题。 -
http2.0实现了数据推送 功能:服务器 端和客户端 双方都会 建立一个stream,并且 使用streamID进行区分 。客户端建立的是奇数号,服务器建立的是偶数号。服务器推送数据时,会先发送PUSH_PROMISS帧,告诉客户端接下来哪个stream发送资源。
http2.0的不足
也存在响应队头阻塞问题——这个问题源于tcp协议,tcp协议中规定的接收顺序是先阻塞先接收,没有确定应答包的所属机制,如果服务器不按照请求顺序回复就会导致应答混乱。 TCP的握手延时问题——解决方法是将tcp的握手和http的连接合在一起。 网络迁移时需要进行重新连接:服务器和客户端建立连接的四要素:源ip地址,源端口号,目的ip地址,目的端口号——这同样是因为tcp属于数据报服务,ip改变后需要重新连接。 总结:以上问题主要的原因是应用层使用的是TCP协议,无论http如何设计都是徒劳,想要解决问题只能解决tcp.
http 3.0版本
为了解决上述tcp协议带来的一些问题,我们解决了tcp协议。(bushi)
-
http3.0将传输层的TCP协议更改成了**UDP协议** 。使用的是基于UDP的**QUIC**的协议 -
QUIC协议:基于UDP实现的面向无连接 的协议,也不需要 三次握手 和四次挥手 。在协议中实现了类似TCP的连接管理 ,拥塞控制 ,流量控制 等相关操作,相当于 将UDP的不可靠传输 改成可靠的传输协议。 -
QUIC协议中也有一个stream的概念,保证 了数据的可靠性 ,每个stream数据报都有 一个唯一 的ID标识 。当某一个数据报丢失 后,该数据报会 被重传 ,不会影响 其他数据报的传输。 -
能实现更快的连接建立:**
QUIC**协议也需要进行握手连接,相当于将TCP的握手机制结合在一起,基于一个ID进行连接,而不是基于四元组。 -
不是基于四元组进行连接的,是通过一个
stream ID完成,那么就可以实现在不同网络下的迁移。
https
-
为了传输的安全性,引入了
https,加密的超文本传输协议 -
在
http层和传输层之间加入了TLS协议,该协议提高了信息加密 ,校验机制 ,以及数字证书 -
TLS协议需要进行四次握手机制客户端向服务器发送一个随机数C,TLS协议版本号,和公钥 服务器收到客户端信息后回复一个ACK 服务器在发送一个随机数S,确认TLS版本号,经过加密的密钥 客户端回复一个ACK -
TLS的四次握手,是发生在TCP的三次握手建立连接之后 执行的安全性检查。是一个耗时操作,但是确保了信息的安全性。
模型