1. 引言
😄 前两节把 LangChain 的文档撸了个遍,对 "七大核心组件 " 的 API 进行了系统的学习:
- 【Models】 统一接口调用不同大语言模型,实现灵活切换和简化管理。
- 【Prompts】 支持动态生成提示词模板,提高复用性和灵活性。
- 【Tools】 封装外部功能接口,可使Agent调用搜索、计算等多种工具。
- 【Chains】 链式调用组合多个组件,支持复杂任务和异步流式处理。
- 【Memory】 管理对话历史和上下文,实现多用户会话隔离和状态持久。
- 【Indexes】 构建文档索引,支持加载、分割、嵌入和语义检索。
- 【Agents】 智能体,结合LLM推理和工具调用,实现循环决策与行动。
😶 "基础 " 有了,写起 简单Demo 也是信手拈来,接着就该折腾如何 "进阶 " 了。从 "知道 " 到 "熟练精通 ",最有效的方式往往是通过 "项目实战":
将零散的知识点串联起来,不断深入对框架的理解,逐步掌握高级功能和应用模式,形成解决复杂问题的能力。
💁♂️ 由浅入深,先来整个 "基于个人文档的智能问答机器人 ",这是 LangChain 最经典、最重要的应用场景之一,也是所有复杂LLM应用的基石。核心:利用 RAG (检索增强生成) 让 LLM 能够回答其自身知识库之外的、基于你私有文档的问题。RAG 技术实现步骤之前已有提及,再搬运下:
- 文档加载 :使用 Document Loaders 加载你的本地文件(如PDF、TXT、Markdown)或网页内容。
- 文本分割:将加载的文档切割成小的、语义完整的文本块 (Chunks),以便于后续处理。
- 向量化:使用嵌入模型 (如OpenAI Embeddings) 将文本块转换为向量表示。
- 向量存储:将向量化的文本块存入向量数据库 (如 Chroma, FAISS)。
- 检索:当用户提问时,将问题也进行向量化,并在向量数据库中检索最相关的文本块。
- 生成 :将检索到的相关文本块和用户原始问题一起作为上下文,构建一个精确的提示 (Prompt),丢给LLM生成最终答案。
2. 全局思维与规划
😄 别急着 "写代码",先像设计一款真正的软件产品一样来思考,清晰的规划会让整个开发过程事半功倍。
2.1. 明确需求 & 目标
🤔 首先,明确我们希望这个机器人具体能做什么?
- 核心目标:创建一个智能机器人,它能且仅能根据知识库的内容,回答用户提出的问题。
- 用户输入:涉及知识库主题的自然语言问题,如:"请解释一下LangChain中的LCEL是什么?"。
- 期待输出:一个基于知识库、准确流畅的回答,最好能附上答案所参考的原文链接,方便用户深入阅读。
- 关键约束 :机器人的回答必须严格基于知识库的内容,不能 "自由发挥" 或 "凭空捏造" (即"AI幻觉") 。
- 用户体验:当找不到答案时,它应该如何回应?如:"根据我的知识库,我找不到相关信息"。
- 交互方式:是一个简单的命令行工具,还是一个带界面的 Web 应用?
2.2. 技术选型 & 可行性分析
😶 基于需求选择合适的技术栈,LangChain 固然是核心,但它需要语其它组件配合。
- LLM:用哪个模型?OpenAI、Gemini、Claude,或是其它开源模型 (如 Llama)?这会直接影响到成本和回答的质量。
- Embedding 模型:如何将你的文本转化为向量?用 OpenAI 的 text-embedding-3-small?还是选择Hugging Face 上的开源模型?
- 向量数据库:文章向量化后需要存储在哪里以便快速检索?对于个人项目,内存中的 FAISS 或本地存储的 Chroma 都是不错的选择。如果未来文档量巨大,可以考虑 Pinecone 或 Weaviate 等云服务。
- 文档加载与处理:知识库文章是什么格式的?Markdown、HTML?需要选择合适的文档加载器。
2.3. 开发流程
一个标准的 AI 应用开发流程应该包含以下几个关键阶段:
- 数据准备 (Data Preparation)
- 系统设计 (System Design)
- 核心实现 (Implementation)
- 评估与迭代 (Evaluation & Iteration)
- 部署与监控 (Deployment & Monitoring)
😏 规划完,接着就是按部就班一一实践了~
3. 数据准备
3.1. 数据收集
🤔 知识库文章的保存格式?纯文本 (.txt) 还是 Markdown (.md) ?这里我选择后者。然后是 "如何获取知识库的文章 "? 两种常规手段: "逐篇手工复制粘贴另存为" 和 "写爬虫自动爬 "。🤡 杰哥用的 "语雀" 管理知识库:
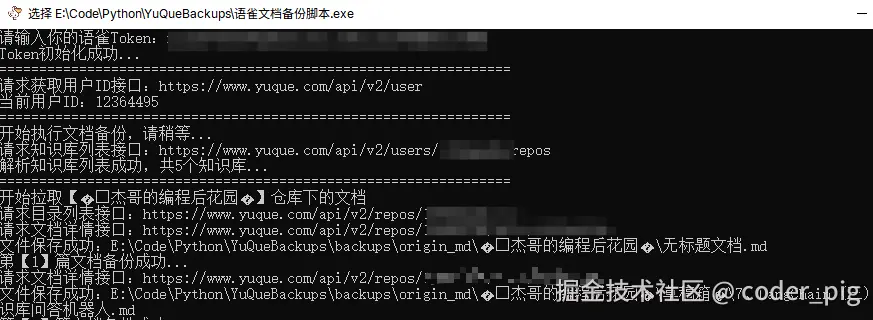
🤷♀️ 不支持整个知识库导出,只支持单篇文章逐一导出,"超级会员 " 可以申请 Token ,然后利用 API 批量导出md文件,具体怎么搞,可以看我之前写的:《🐦数据无价!自己写个"语雀" 自动备份脚本》,懒得看的,直接使用 coder-pig/YuQueBackups 里的 "语雀文档备份脚本.exe",双击运行后,粘贴Token回车即可自动备份:
😶 我这种情况获取到的文章数据都是比较 "干净 " 的,平时写爬虫,爬取到的内容包含导航栏、页脚、广告、评论区等无关信息,这些 "噪声 " 会严重干扰后续的检索质量,所以还需进行 "数据清晰 ",如:使用 BeautifulSoup 库精确提取文章正文部分的HTML内容,或者用 正则表达式 去除固定的页眉页脚。😄 干净的数据源是高质量回答的第一步。
3.2. 文本分割
🤔 为什么要分割?
答:LLM 有 "上下文长度" 限制,我们无法将一整篇长文一次性都扔给它,需要将长文档分成更小的块。
如何分割?
答: LangChain 提供了多种文本分割器,RecursiveCharacterTextSplitter 是一个比较通用的选择,它会尝试按段落、句子等方式进行递归分割,以保持语义的完整性。你只需设定合适的 chunk_size (块大小) 和 chunk_overlap (块之间的重叠字数,有助于保持上下文连续性)。
3.3. 向量化与存储
🤔 嵌入模型 用 OpenAI 的 text-embedding-3-small ,向量数据库 用 轻量级本地存储 的 Chroma 。创建下我们的项目「cp-qa-robot 」,可以在 Python IDE (如 PyCharm ) 直接创建, 也可以在 终端 中执行下述命令行创建:
python
mkdir cp-qa-robot
cd cp-qa-robot
# 创建独立的Python环境,避免与系统中的其它库冲突
python -m venv venv
# 激活虚拟环境
# Windows
.\venv\Scripts\activate
# macOS/Linux
source venv/bin/activate
# 根目录创建 requirements.txt 文件
echo. > requirements.txt
# 打开文件
start requirements.txt
# 添加下述依赖 (复制粘贴到文件中)
langchain>=0.3.27
langchain-community>=0.3.28
langchain-core>=0.3.75
langchain-openai>=0.3.32
langchain-text-splitters>=0.3.9
python-dotenv>=1.0.0
chromadb==0.4.24
# 安装所有依赖
pip install -r requirements.txt
# 创建Git仓库
git init参考下述 目录结构,创建相关文件和文件夹:
bash
/cp-qa-robot/
├── .env # 存放环境变量,如 API 密钥 (!!! 不要提交到 Git)
├── .gitignore # Git 忽略文件配置
├── README.md # 项目说明文档
├── requirements.txt # 项目依赖的 Python 包
|
├── data/ # 存放你的原始知识库文档 (例如 .md 文件)
│ └── my-blog-post-1.md
│ └── my-blog-post-2.md
|
├── vector_store/ # 存放持久化的向量数据库文件 (例如 ChromaDB 的数据)
|
├── scripts/ # 存放一次性或辅助性的脚本
│ └── ingest.py # 数据处理脚本:加载、分割、向量化并存入数据库
|
├── src/ # 核心源代码目录
│ ├── __init__.py
│ ├── core/ # 存放项目核心逻辑
│ │ ├── __init__.py
│ │ └── qa_chain.py # 问答链的构建逻辑,这是项目的"大脑"
│ ├── utils/ # 存放通用的辅助函数
│ │ ├── __init__.py
│ │ └── helpers.py
│ ├── main_cli.py # 命令行交互的入口文件
│ └── main_web.py # (可选) Web 应用 (如 Streamlit, FastAPI) 的入口文件
|
└── tests/ # (进阶) 存放测试用例
├── __init__.py
└── test_qa_chain.py在 .env 文件中配下API_KEY等参数,然后添加到 .gitignore文件中,避免提交到Git:
bash
API_KEY="sk-xxx"
BASE_URL="https://xxx.xxx.ai/v1"
LLM_MODEL="gemini-2.5-flash-lite"
EMBEDDINGS_MODEL="text-embedding-3-small"3.3.1. Chroma 速成
① 创建 Chroma 客户端
一位20歲中國女生,擁有野性美與精緻五官。瘦瘦的臉龐、大眼、小巧挺直的鼻子、櫻桃小嘴與尖下巴,面带微笑。黑色長直髮細軟飄逸,偏瘦的模特兒身材。她身穿黃色露肩針織長袖上衣,內搭細吊帶,露出鎖骨,下身配淺藍色寬鬆牛仔褲,雙腿屈膝盤坐。簡約室內環境,淺色牆面與棕色物件構成背景,半身近景居中構圖。日系清新自然風格,8K高清畫質。柔和室內漫射光營造溫暖氛圍,7200K暖光逆側光與倫勃朗光突顯立體感,暗調與暗影增添質感,低飽和色調搭配細膩膚質表現,展現居家生活的寧靜愜意與鬆弛感。
import chromadb
# 内存
chromadb.Client()
# 持久化 (后面是数据存储路径)
chromadb.PersistentClient(path="vector_store")💡 当你首次创建集合并没有指定其它 "嵌入函数 " 时,Chroma 会在后台自动下载 all-MiniLM-L6-v2 模型所需的文件。如果需要使用其它 Sentence Transformer 模型,可在创建集合时通过 embedding_function 参数明确指定类型的名称。
② 基础操作
一位20歲中國女生,擁有野性美與精緻五官。瘦瘦的臉龐、大眼、小巧挺直的鼻子、櫻桃小嘴與尖下巴,面带微笑。黑色長直髮細軟飄逸,偏瘦的模特兒身材。她身穿黃色露肩針織長袖上衣,內搭細吊帶,露出鎖骨,下身配淺藍色寬鬆牛仔褲,雙腿屈膝盤坐。簡約室內環境,淺色牆面與棕色物件構成背景,半身近景居中構圖。日系清新自然風格,8K高清畫質。柔和室內漫射光營造溫暖氛圍,7200K暖光逆側光與倫勃朗光突顯立體感,暗調與暗影增添質感,低飽和色調搭配細膩膚質表現,展現居家生活的寧靜愜意與鬆弛感。
# ================================
# 💡 ① 创建集合用于存储向量数据
# ================================
collection = client.get_or_create_collection(
# 用于标识向量集合的名称
name="book_notes",
# 集合的元数据配置,告诉ChromaDB应使用什么方式计算向量间的相似度
# hnsw:space 参数
# [cosine]:余弦相似度 - 最常用,因为它关注向量方向而不是绝对距离,
# 非常适合比较文档或文本片段的语义相似性!
# [12]:欧几里得距离 (L2距离)
# [ip]:内积相似度
metadata={"hnsw:space": "cosine"}
)
# ================================
# 💡 ② 添加集合
# ================================
documents = [
"Python 是一种高级编程语言,广泛用于数据科学和机器学习。",
"JavaScript 是网页开发的核心语言,可以运行在浏览器和服务器上。",
"机器学习是人工智能的一个重要分支,通过算法让计算机学习数据模式。",
"深度学习使用神经网络来解决复杂的模式识别问题。",
"自然语言处理帮助计算机理解和生成人类语言。"
]
metadatas = [
{"category": "programming", "language": "python"},
{"category": "programming", "language": "javascript"},
{"category": "ai", "topic": "machine_learning"},
{"category": "ai", "topic": "deep_learning"},
{"category": "ai", "topic": "nlp"}
]
ids = ["doc1", "doc2", "doc3", "doc4", "doc5"]
print("📝 添加文档到集合...")
collection.add(
documents=documents, # 要存储的实际文档内容,list[str],这些文档会被自动转换为向量嵌入并存储
metadatas=metadatas, # 为每个文档添加额外的信息标签, 可以用来过滤搜索结果,比如只搜索某个类别的文档
ids=ids # 为每个文档提供唯一的标识符,用于后续更新、删除或查询特定文档
)
# ================================
# 💡 ③ 查询文档
# ================================
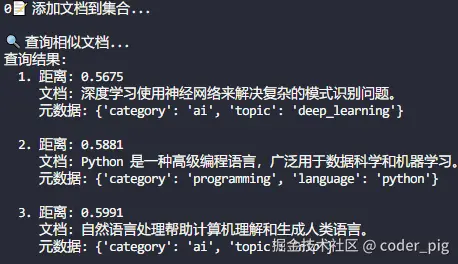
print("\n🔍 查询相似文档...")
results = collection.query(
query_texts=["编程语言"], # 进行向量搜索的查询文本
n_results=3 # 返回的结果数量
)
print("查询结果:")
for i, (doc, distance, metadata) in enumerate(zip(
results['documents'][0],
results['distances'][0],
results['metadatas'][0]
)):
print(f" {i+1}. 距离: {distance:.4f}")
print(f" 文档: {doc}")
print(f" 元数据: {metadata}")
print()
# ================================
# 💡 ④ 文档更新
# ================================
collection.update(
ids=["update_doc_1"],
documents=["这是更新后的文档内容,包含更多信息"],
metadatas=[{"version": 2, "status": "published"}]
)
# ================================
# 💡 ⑤ 文档删除
# ================================
collection.delete(ids=["temp_1", "temp_2"])
# ================================
# 💡 ⑥ 其它
# ================================
# Collection
upsert() # 插入或更新文档
delete() # 删除指定文档
count() #获取文档总数
name # 集合名称
metadata #集合元数据
id # 集合ID
# Client
list_collections() # 列出所有集合
get_collection() #获取现有集合
get_or_create_collection() # 获取或创建集合
delete_collection() # 删除集合
reset() #重置所有数据运行输出结果 (🤡 这里踩了一个小坑,一开始用的 chromadb 版本是1.0.20 ,执行add、query等操作,程序就直接结束了,后续代码不走,也没有任何的输出,后面发现回退到 0.4.24 版本就好了,猜测是兼容性问题):
③ 高级过滤 (query设置其它参数)
一位20歲中國女生,擁有野性美與精緻五官。瘦瘦的臉龐、大眼、小巧挺直的鼻子、櫻桃小嘴與尖下巴,面带微笑。黑色長直髮細軟飄逸,偏瘦的模特兒身材。她身穿黃色露肩針織長袖上衣,內搭細吊帶,露出鎖骨,下身配淺藍色寬鬆牛仔褲,雙腿屈膝盤坐。簡約室內環境,淺色牆面與棕色物件構成背景,半身近景居中構圖。日系清新自然風格,8K高清畫質。柔和室內漫射光營造溫暖氛圍,7200K暖光逆側光與倫勃朗光突顯立體感,暗調與暗影增添質感,低飽和色調搭配細膩膚質表現,展現居家生活的寧靜愜意與鬆弛感。
# ================================
# 💡 根据元数据进行过滤搜索
# ================================
# 根据类别过滤
where={"category": "programming"}
# 复杂过滤条件
where={
"$and": [
{"category": "ai"},
{"topic": "machine_learning"}
]
}
# 数值范围过滤
where={"price": {"$gte": 100, "$lte": 500}}
# ================================
# 💡 根据文档内容进行过滤
# ================================
# 包含特定文本的文档
where_document={"$contains": "Python"}
# 不包含特定文本
where_document={"$not_contains": "JavaScript"}
# ================================
# 💡 指定返回结果中包含的信息类型
# 默认值:["metadatas", "documents", "distances"]
# 可选值:默认值的基础上多个"embeddings"
# ================================
# 只返回文档和距离
include=["documents", "distances"]
# 返回所有信息
include=["embeddings", "metadatas", "documents", "distances"]
# ================================
# 💡 直接使用向量嵌入进行查询,与query_texts二选一
# ================================
# 使用预计算的向量
query_embeddings=[[0.1, 0.2, 0.3, ...]]
# ================================
# 💡 使用图像进行查询(需要支持多模态的嵌入模型)
# ================================
# 读取本地图像文件
with open("./images/query_image.jpg", "rb") as img_file:
image_data = img_file.read()
# 使用图像数据进行查询
results = collection.query(
query_images=[image_data], # 传入图像的二进制数据
n_results=5,
include=["documents", "metadatas", "distances"]
)
# ================================
# 💡 使用URI进行查询
# ================================
# 使用网络图像URL进行查询
results = collection.query(
query_uris=["https://example.com/sample_image.jpg"],
n_results=5,
where={"category": "nature"}, # 可以结合过滤条件
include=["documents", "metadatas", "distances"]
)
print("基于URL的图像查询结果:")
for doc, metadata in zip(results['documents'][0], results['metadatas'][0]):
print(f"找到相似内容: {doc}")
print(f"标签: {metadata}")3.3.2. 嵌入模型的敲定
上面说了 ChromaDB 默认使用 all-MiniLM-L6-v2 模型作为 "嵌入参数":
一位20歲中國女生,擁有野性美與精緻五官。瘦瘦的臉龐、大眼、小巧挺直的鼻子、櫻桃小嘴與尖下巴,面带微笑。黑色長直髮細軟飄逸,偏瘦的模特兒身材。她身穿黃色露肩針織長袖上衣,內搭細吊帶,露出鎖骨,下身配淺藍色寬鬆牛仔褲,雙腿屈膝盤坐。簡約室內環境,淺色牆面與棕色物件構成背景,半身近景居中構圖。日系清新自然風格,8K高清畫質。柔和室內漫射光營造溫暖氛圍,7200K暖光逆側光與倫勃朗光突顯立體感,暗調與暗影增添質感,低飽和色調搭配細膩膚質表現,展現居家生活的寧靜愜意與鬆弛感。
# 使用 "默认模型" 需要安装 sentence-transformers 库 (也间接依赖 torch库)
from langchain_community.embeddings import SentenceTransformerEmbeddings
embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# 上述代码运行会有警告,因为 SentenceTransformerEmbeddings
# (实际上是 HuggingFaceEmbeddings) 在 LangChain 0.2.2被标记为废弃
# pip 安装完 langchain_huggingface 库后,做下修改
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")🤔 这个模型的特点:
- 优势:轻量 (模型小巧,推理速度快)、通用性好 (适合大多数英文文本场景)、开箱即用 (ChromaDB 默认集成,无需额外配置)、成本低 (本地运行,无API调用费用)。
- 局限 :对中文文本的理解 可能不如专门的中文模型,特定领域/任务 (医学、法律) 可能表现不佳,向量维度-384维,可能不如更大模型的表达能力。
😶 我的知识库里的文档都是 中文 ,还是用 LLM 厂商提供的嵌入模型吧,让AI比较下 OpenAI 和 Gemini:
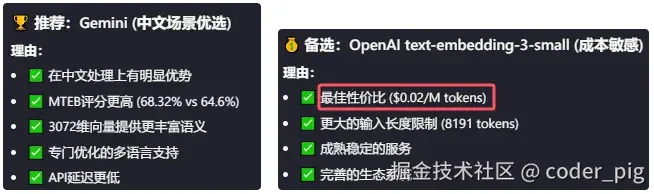
Gemini 很强很好,但是我还是选择了 "性价比最高 " 的 OpenAI text-embedding-3-small → $0.02/M tokens,🤡 Gemini embedding-001 比 text-embedding-3-large 还贵(0.15 VS 0.13)...
3.3.3. 文本分割的设计
🤔 分割器用的 RecursiveCharacterTextSplitter ,主要是 chunk_size 、chunk_overlap 和 separators 这三参数配置的权衡。先是 嵌入模型 - OpenAI text-embedding-3-small 的技术规格:
- 最大输入长度: 8,191 tokens,使用 cl100k_base 编码 (OpenAI自研分词方案,词表规模约100000)
- 推荐工作范围: 512-4096 tokens (最佳性能区间)
- 中文Token化比例: 1字符 ≈ 1.5-2 tokensde
💡 估计有同学会有这样的疑问:"GPT-4o 上下文都128k,怎么这个嵌入模型才8k啊?" 😄 因为 应用场景不同 ,前者用于一次性处理极长对话或文档,如整本书、数小时对话、完整代码库等。后者则被设计用于 将文本切分成向量 ,主要关注 向量质量 、吞吐量 和 成本。扩大上下文会使计算和显存成本按二次方增长,还会降低每次请求的吞吐量和效率。对于大多数检索、聚类或分类任务,8 k token 已足够覆盖绝大部分文档片段。
然后是 知识库特点 的分析:
- 内容类型: 心理学、自我成长类长文本
- 段落结构: 观点+案例+总结的模式
- 平均段落长度: 200-400字符
- 语义单元: 一个完整观点通常需要500-800字符
😶 思考结果:
- chunk_size -块大小,1000 ,x1.5 = 1500 tokens (保守估计),x 2 = 2000 tokens (最大情况),出于嵌入模型的 "甜区" (模型性能最佳区间)。1000字符也正好包含一个完整的"观点+案例",能保证语义的完整性。远低于8191 tokens限制,还能避免截断风险。
- chunk_overlap -块之间的重叠字数,150 ,150 ÷ 1000 = 15%重叠率,认知科学研究 15-20%重叠率 是维持文本连贯性的最小阈值。信息检索论文时15%的重叠在精确度和效率之间能达到最佳平衡。心理学文本的观点往往有逻辑递进,15%能捕获关键连接词。
- separators -分割优先级 ,段落级 ("\n\n") → 最大的语义单元,心理学文本的每段通常包含一个核心观点。句子级 ("。", "!", "?") → 语义边界 -句号标志完整思想表达、情感完整 -感叹号、问号保持情感表达的完整性。子句级 (";", ",") → 逻辑连接 -分号连接相关观点、语义缓冲-逗号作为最后的语义边界。
3.3.4. 嵌入模型的调用
😂 一开始就碰到一个 "小坑" ,用的 Chroma.from_documents() 来向量化和存储数据:
($0.15
texts = text_splitter.split_documents(documents)
db = Chroma.from_documents(texts, embeddings, persist_directory=DB_PATH)OpenAIEmbeddings 初始化没自定义 chunk_size 参数,这玩意默认值是 1000 ❗️ ❗️ ❗️

内部实现:
($0.15
# OpenAIEmbeddings
def embed_documents(self, texts: list[str], chunk_size: Optional[int] = None):
chunk_size_ = chunk_size or self.chunk_size # 默认1000
# 关键:OpenAI会自动分批处理!
embeddings = []
for i in range(0, len(texts), chunk_size_):
response = self.client.create(
input=texts[i : i + chunk_size_], # 分批发送
**client_kwargs
)
embeddings.extend(r["embedding"] for r in response["data"])
return embeddings🙃 直接一次性发送了 1000个 分割文档,把 OpenAI 都干到 拒绝连接 了:

看控制台直接一次干了 694535 的 Token...

🤔 想了下,决定每批2个文档块,2 × 2000 tokens ≈ 4000 tokens,仍在512-4096最佳性能区间,最终代码:
($0.15
import os
import logging
import uuid
from dotenv import load_dotenv
import chromadb
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_openai import OpenAIEmbeddings
# 加载 .env 文件中的环境变量
load_dotenv()
# 配置日志
logging.basicConfig(
level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
)
# 启用详细日志
logging.getLogger("openai").setLevel(logging.DEBUG)
logging.getLogger("langchain").setLevel(logging.INFO)
logging.getLogger("chromadb").setLevel(logging.INFO)
# 定义常量
DATA_PATH = "data/"
DB_PATH = "vector_store/"
COLLECTION_NAME = "read_notes"
def create_vector_db():
"""
创建并持久化向量数据库
"""
logging.info("开始加载文档...")
# 使用 DirectoryLoader 加载 data 目录下的所有 .md 文件
loader = DirectoryLoader(
DATA_PATH,
glob="*.md",
# lambda表达式创建一个指定UTF-8编码的TextLoader类
loader_cls=lambda path: TextLoader(path, encoding="utf-8"),
)
documents = loader.load()
logging.info(f"成功加载 {len(documents)} 篇文档")
# 文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=150,
separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""],
)
texts = text_splitter.split_documents(documents)
logging.info(f"文档被分割成 {len(texts)} 个文本块")
logging.info("开始创建并存储向量...")
# 使用OpenAI嵌入模型
embeddings = OpenAIEmbeddings(
openai_api_key=os.getenv("API_KEY"),
openai_api_base=os.getenv("BASE_URL"),
model=os.getenv("EMBEDDINGS_MODEL"),
request_timeout=600, # 设置超时时间
max_retries=3, # 设置重试次数
chunk_size=2, # 批处理大小
)
# 创建ChromaDB客户端和集合
client = chromadb.PersistentClient(path=DB_PATH)
collection = client.get_or_create_collection(name=COLLECTION_NAME)
logging.info(f"开始处理 {len(texts)} 个文本块(一次性生成嵌入向量)...")
try:
# 准备所有文档数据
all_documents = []
all_metadatas = []
all_ids = []
for i, doc in enumerate(texts):
# 生成唯一ID
doc_id = str(uuid.uuid4())
# 准备文档内容
all_documents.append(doc.page_content)
# 准备元数据
metadata = dict(doc.metadata)
metadata["chunk_index"] = i
all_metadatas.append(metadata)
# 添加ID
all_ids.append(doc_id)
# 一次性生成所有嵌入向量(OpenAI内部会自动分批)
logging.info("🚀 开始生成嵌入向量...")
all_embeddings = embeddings.embed_documents(all_documents)
logging.info(f"✅ 成功生成 {len(all_embeddings)} 个嵌入向量")
# 一次性添加到ChromaDB集合
logging.info("💾 添加到向量数据库...")
collection.add(
documents=all_documents,
metadatas=all_metadatas,
ids=all_ids,
embeddings=all_embeddings,
)
logging.info("✅ 成功添加到向量数据库")
except Exception as e:
logging.error(f"❌ 处理过程中发生错误: {str(e)}")
raise
# 最终统计信息
count = collection.count()
logging.info(
f"向量数据库创建完成 - 集合: {COLLECTION_NAME}, 文档数: {count}, 路径: {DB_PATH}"
)
if __name__ == "__main__":
create_vector_db()1110个文本块,分560个批次处理完,看下价格,总共估计就花了2美分多一点:
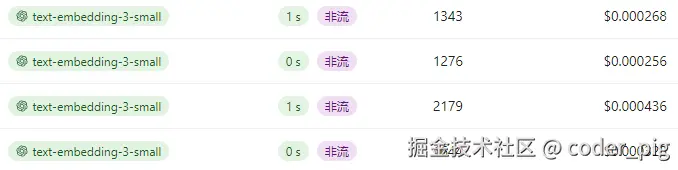
可以用 SQLiteStudio (免费) 等工具打开生成 vector_store\chroma.sqlite3,写sql查询记录数:
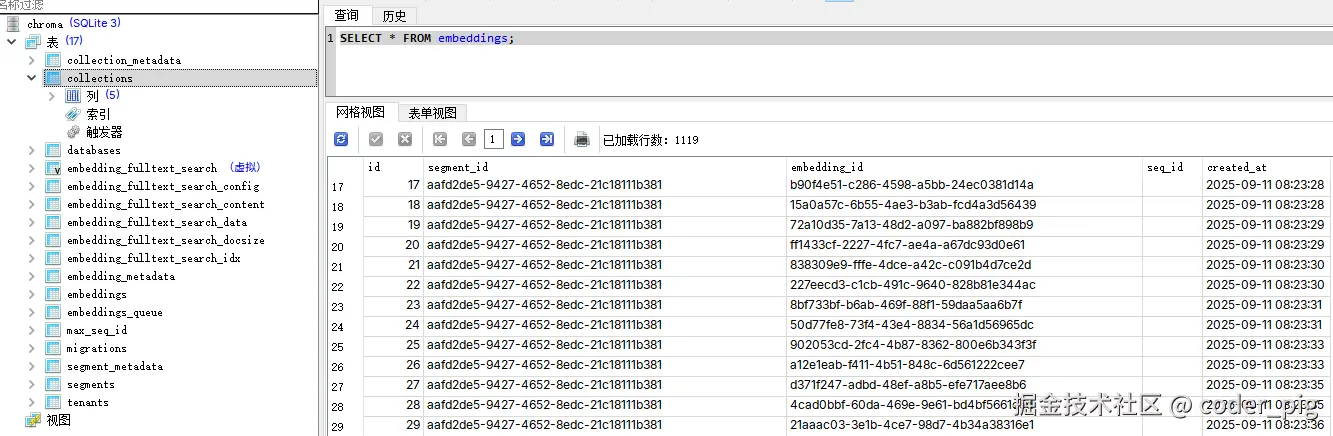
💁♂️ 这一阶段的产出:包含知识库所有文章向量化数据的、可供检索的向量数据库。
💡 Tips :如果想自己统计花费的 Token,可以使用 tiktoken (OpenAI官方推荐) 或 transformers 库。
python
import tiktoken
# 获取对应模型的编码器
encoding = tiktoken.encoding_for_model("text-embedding-3-small")
# 统计token数
def count_tokens(text):
return len(encoding.encode(text))
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-base-patch32")
def count_tokens(text):
return len(tokenizer.encode(text))3.3.5. 优化:增量索引
🤔 不难看出上述代码存在 "效率问题 ",每次运行都会重新处理所有文档,不管文档是否发生变更,都会重新执行分割和向量化,由此产生一些没必要的API调用费用。😄 这个问题可以用 LangChain 的 Indexes (索引) 组件的 "增量索引 " 来解决:基于 文件哈希 检测文档是否发生变化,只处理新增或修改的文档,自动清理被删除的文档。涉及到两个API:
① RecordManager - 记录管理器
跟踪哪些文档已经被索引,记录文档的哈希值和时间戳,检测文档变更 (通过哈希对比),管理 source_id 映射。
python
from langchain.indexes import SQLRecordManager
# 创建记录管理器
record_manager = SQLRecordManager(
namespace="my_index", # 命名空间,用于隔离不同的索引
db_url="sqlite:///record_manager_cache.sql" # 存储文档状态的数据库
)
record_manager.create_schema() # 创建必要的表结构② index() 函数
python
result = index(
#【文档源】,可以是BaseLoader或文档的可迭代对象,懒加载,只有在需要时才读取文档
loader,
#【记录管理器】,踪文档的状态和时间戳 (存储文档的哈希值、最后更新时间、源文件信息、文档是否存在于向量库中)
record_manager,
#【向量存储】,实际存储文档向量的地方,提供向量搜索、添加、删除文档能力
vectorstore,
#【清理模式】,四种:
#「incremental」增量,实时清理不再存在的文档,只删除与当前批次源文件相关的过期文档,边索引边清理,减少重复内容
# 需要设置 需要【source_id_key】参数,优点是:最高效,适合频繁更新,
#
#「full」全量,删除所有未被本次加载器返回的文档,清理在索引完成后执行,使用场景:完全重建索引时
#
#「scoped_full」范围全量,类似于full,但只清理与本次源文件相关的文档,内存中跟踪源 ID,使用场景:难以确定批大小时
#
#「None」无清理,不删除任何文档,只添加和更新,使用场景:纯增量添加
cleanup="incremental", # 增量清理模式
# 源文件标识, 标识文档来源,用于增量清理,通常是文档的 metadata["source"] 字段
source_id_key="source",
# 批处理大小,每次索引的文档数量,越大效率越高,但需要更多内存,推荐2-10
batch_size=2, # 批处理大小
# ,用于生成文档的唯一标识,默认是sha1,推荐使用sha256,提高安全性
# 其它:sha512-最安全但较慢,blake2b-高性能且安全
key_encoder="sha256",
)完整实现代码 (注意 Chroma 的导包是有区别的 ❗️):
python
import os
import logging
from dotenv import load_dotenv
from langchain.indexes import SQLRecordManager, index
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# 加载环境变量
load_dotenv()
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
# 定义常量
DATA_PATH = "data/"
DB_PATH = "vector_store/"
COLLECTION_NAME = "read_notes"
NAMESPACE = f"chroma/{COLLECTION_NAME}"
def create_incremental_vector_db():
"""
使用LangChain indexing API创建增量向量数据库
"""
logging.info("🚀 开始增量索引...")
# 1. 初始化嵌入模型
embeddings = OpenAIEmbeddings(
openai_api_key=os.getenv("API_KEY"),
openai_api_base=os.getenv("BASE_URL"),
model=os.getenv("EMBEDDINGS_MODEL"),
request_timeout=600,
max_retries=3,
chunk_size=2
)
# 2. 初始化向量存储
vectorstore = Chroma(
collection_name=COLLECTION_NAME,
embedding_function=embeddings,
persist_directory=DB_PATH,
)
# 3. 初始化记录管理器
record_manager = SQLRecordManager(
namespace=NAMESPACE,
db_url=f"sqlite:///{DB_PATH}/record_manager.db"
)
record_manager.create_schema()
# 4. 创建文档加载器
loader = DirectoryLoader(
DATA_PATH,
glob="*.md",
loader_cls=lambda path: TextLoader(path, encoding="utf-8"),
)
# 5. 设置文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=150,
separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""],
)
# 6. 加载并分割文档
logging.info("📚 加载文档...")
documents = loader.load()
logging.info(f"成功加载 {len(documents)} 篇文档")
# 为每个文档设置source字段(用于增量更新)
for doc in documents:
# 使用相对路径作为source_id
source_path = os.path.relpath(doc.metadata['source'], DATA_PATH)
doc.metadata['source'] = source_path
logging.info("✂️ 分割文档...")
texts = text_splitter.split_documents(documents)
logging.info(f"文档被分割成 {len(texts)} 个文本块")
# 7. 执行增量索引 🎯
logging.info("🔄 开始增量索引...")
result = index(
texts,
record_manager,
vectorstore,
cleanup="incremental",
source_id_key="source",
batch_size=50,
force_update=False,
key_encoder="sha256",
)
# 8. 输出结果统计 📊
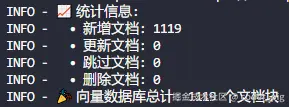
logging.info("✅ 索引完成!")
logging.info(f"📈 统计信息:")
logging.info(f" • 新增文档: {result['num_added']}")
logging.info(f" • 更新文档: {result['num_updated']}")
logging.info(f" • 跳过文档: {result['num_skipped']}")
logging.info(f" • 删除文档: {result['num_deleted']}")
# 9. 最终统计
total_docs = vectorstore._collection.count()
logging.info(f"🎉 向量数据库总计: {total_docs} 个文档块")
return result
if __name__ == "__main__":
create_incremental_vector_db()运行输出结果:
4. 系统设计
🤔 接着,就要设计如何利用准备好的数据来回答问题了,这里无脑 RAG (检索增强生成)。LangChain 中,可以利用 LCEL (LangChain表达式语言 ) 来优雅地构建这个流程,它的美妙之处就在于它的 管道(|) 操作,"将左边的输出,作为右边的输入 ",然后使用 {}嵌套 可以 并行执行,先列出期望的代码执行流程:
python
# 代码执行流程:
用户问题 ("如何提高学习效率?")
↓
第1步: {"context": retriever | format_docs, "question": RunnablePassthrough()}
├─ retriever: 检索相关文档 → List[Document]
├─ | format_docs: 格式化文档 → str
└─ question: 直接传递问题 → str
↓ 输出: {"context": "格式化的文档字符串", "question": "如何提高学习效率?"}
↓
第2步: | prompt
↓ 将字典数据填入提示词模板
↓ 输出: 完整的提示词字符串
↓
第3步: | llm
↓ LLM生成回答
↓ 输出: AIMessage对象
↓
第4步: | StrOutputParser()
↓ 提取字符串内容
↓ 输出: 最终的回答字符串接着写下伪代码 "串出一条链":
python
retriever = vector_store.as_retriever()
prompt_template = ChatPromptTemplate.from_template(...)
llm = ChatOpenAI()
rag_chain = (
{
"context": retriever | format_docs, # 检索相关文档 → 格式化文档
"question": RunnablePassthrough() # 将上一步用户输入的问题直接传递到下一个组件
} | prompt_template |llm| StrOutputParser()
)😄 流程非常清楚了,直接写出qa_chain.py的代码:
python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
def format_docs(docs):
"""
将检索到的文档列表格式化为结构化字符串
参数:
docs: List[Document] - 检索器返回的文档列表
返回:
str - 格式化后的文档字符串,包含来源信息
"""
if not docs:
return "没有找到相关文档。"
formatted_docs = []
for i, doc in enumerate(docs, 1):
source = doc.metadata.get('source', '未知来源')
# 提取文件名(去掉路径前缀)
if '\' in source:
source = source.split('\')[-1]
elif '/' in source:
source = source.split('/')[-1]
# 获取文档内容
content = doc.page_content.strip()
doc_section = f"【参考资料 {i}】\n来源:{source}\n内容:{content}"
formatted_docs.append(doc_section)
return "\n\n".join(formatted_docs)
def create_qa_chain(retriever, llm):
"""
基于提供的检索器和 LLM 创建一个 RAG 问答链。
参数:
retriever: 一个配置好的 LangChain 检索器对象。
llm: 一个配置好的 LangChain LLM 或 ChatModel 对象。
返回:
一个可执行的 LangChain 链 (Runnable)。
"""
# ===============================
# 💡 创建提示词模板
# ===============================
prompt_template = """
# 角色
你是一位专业的AI问答助手,严格按照以下规则回答问题。
# 判断标准
- 如果上下文为空(显示"没有找到相关文档")或上下文内容与问题完全无关,则输出:"根据您提供的文档,我无法回答这个问题。"
- 如果上下文中包含与问题直接相关的信息,则基于上下文内容回答问题。
# 输出格式要求
## 情况一:信息不足
输出内容:根据您提供的文档,我无法回答这个问题。
## 情况二:信息充足
格式:
[回答内容]
**参考来源:**
- [来源1]
- [来源2]
(来源需要去重,只列出实际引用的文档)
# 严格约束
1. 绝对不允许编造任何上下文中没有的信息
2. 绝对不允许使用自己的知识补充回答
3. 必须严格按照上述两种格式之一输出
4. 如果上下文信息模糊或不完整,选择"信息不足"的回答方式
上下文:
{context}
问题:
{question}
请严格按照上述格式要求回答:"""
prompt = ChatPromptTemplate.from_template(prompt_template)
# ===============================
# 💡 创建问答链
# ===============================
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
return qa_chain💁♂️ 这一阶段的产出:一个定义清晰、逻辑完整的问答(RAG)链。
💡 Tips :😶 可能部分读者对这个 LECL 的使用还不太理解,上点代码示例就懂了~
python
# 例子1: 简单的文本处理链
text_chain = input_text | text_processor | output_formatter
# 例子2: 复杂的RAG链
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt_template
| llm
| output_parser
)
# 例子3: 多路处理
complex_chain = {
"main_context": {
"documents": retriever | format_docs,
"summary": retriever | summarizer,
"metadata": retriever | extract_metadata
},
"user_input": {
"question": RunnablePassthrough(),
"intent": RunnablePassthrough() | intent_classifier,
"language": RunnablePassthrough() | language_detector
},
"system_info": {
"timestamp": lambda _: datetime.now().isoformat(),
"version": lambda _: "1.0.0"
}
}5. 核心实现
🤔 这步就是将前面的所有 设计(想法) 付诸实践的阶段,😄 因为复杂度比较低,边想边写,代码基本写得差不多了。就差一个接受用户输入,调用RAG链,生成结果输出的 "交互界面 "。先写个最简单的 while循环的命令行界面 做下验证吧:
python
import os
from dotenv import load_dotenv
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from core.qa_chain import create_qa_chain
VECTOR_STORE_PATH = os.path.join(os.path.dirname(__file__), "../vector_store/")
COLLECTION_NAME = "read_notes"
load_dotenv()
API_KEY = os.getenv("API_KEY")
BASE_URL = os.getenv("BASE_URL")
EMBEDDINGS_MODEL = os.getenv("EMBEDDINGS_MODEL")
LLM_MODEL = os.getenv("LLM_MODEL")
def main():
if not os.path.exists(VECTOR_STORE_PATH):
print(f"错误:向量数据库目录 '{VECTOR_STORE_PATH}' 不存在。")
print("请先运行 'scripts/ingest.py' 来创建数据库。")
return
# ① 初始化组件
embeddings = OpenAIEmbeddings(
openai_api_key=API_KEY,
openai_api_base=BASE_URL,
model=EMBEDDINGS_MODEL,
)
vector_store = Chroma(
persist_directory=VECTOR_STORE_PATH,
collection_name=COLLECTION_NAME,
embedding_function=embeddings,
)
llm = ChatOpenAI(
openai_api_key=API_KEY,
openai_api_base=BASE_URL,
model=LLM_MODEL,
temperature=0,
)
retriever = vector_store.as_retriever(
search_type="similarity", # 搜索类型:similarity(相似度)或 mmr(最大边际相关性)
search_kwargs={"k": 10}
)
# ② 创建RAG问答链
qa_chain = create_qa_chain(retriever, llm)
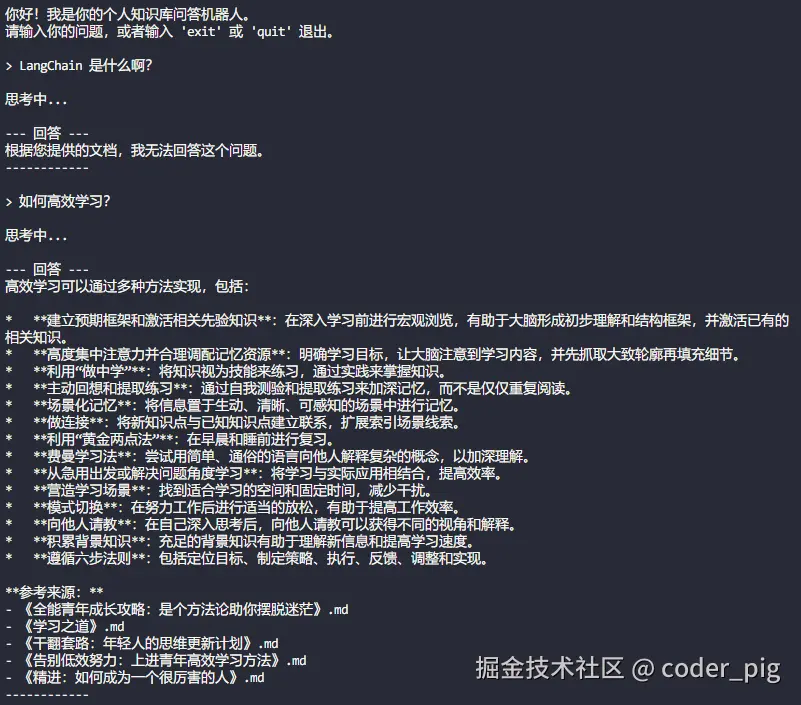
print("\n你好!我是你的个人知识库问答机器人。")
print("请输入你的问题,或者输入 'exit' 或 'quit' 退出。")
# ③ 启动交互式问答循环
while True:
try:
question = input("\n> ")
if question.lower() in ["exit", "quit"]:
print("感谢使用,再见!")
break
if not question.strip():
continue
print("\n思考中...")
# 4. 调用链并打印结果
answer = qa_chain.invoke(question)
print("\n--- 回答 ---")
print(answer)
print("------------")
except Exception as e:
print(f"\n发生错误: {e}")
break
if __name__ == "__main__":
main()运行输出结果:
👏 Nice ,是我们想要的效果,接着用 Streamlit 快速搭建一个简单的 "Web UI",以提供更好的交互体验~
5.1. Streamlit 速成
Streamlit 是一个专门用于 快速构建和部署 数据科学和机器学习应用Web界面的开源Python库,旨在以最简单、最快速的方式将 数据脚本 转化为可共享的 Web 应用。极大地简化了 Web 开发的流程,让您 无需掌握前端技术 (如 HTML, CSS, JavaScript) 就能构建功能丰富的用户界面。
5.1.1. 简单示例
pip install streamlit 装下库,写个简单Demo试试水:
python
import streamlit as st
import pandas as pd
import numpy as np
# 页面配置
st.set_page_config(
page_title="我的第一个Streamlit应用",
page_icon="🎉",
layout="wide"
)
# 标题
st.title("🎉 欢迎来到Streamlit世界!")
st.write("这是我的第一个Streamlit应用")
# 创建一些示例数据
data = pd.DataFrame({
'x': np.random.randn(100),
'y': np.random.randn(100)
})
# 显示图表
st.line_chart(data)执行命令运行应用:streamlit run test_streamlit.py,中断会输出一个url,并自动打开浏览器:
效果还不错:
5.1.2. 概念 & 原理
Streamlit 采用 "从上到下" 的执行模式::
- 重新运行机制:每次用户交互都会重新执行整个脚本。
- 状态管理 :通过 st.session_state 管理应用状态。
- 缓存系统 :使用 @st.cache_data 和 @st.cache_resource 优化性能
核心架构
python
import streamlit as st
# 1. 页面配置(必须在最前面)
st.set_page_config(...)
# 2. 导入和初始化
# 数据加载、模型初始化等
# 3. 侧边栏(可选)
with st.sidebar:
# 侧边栏内容
# 4. 主要内容区域
# 标题、文本、图表、交互组件等
# 5. 用户交互处理
# 按钮点击、输入处理等5.1.3. 基础使用
python
import streamlit as st
import pandas as pd
import numpy as np
# ==============================
# 💡 文本和标题
# ==============================
# 各级标题
st.title("主标题")
st.header("二级标题")
st.subheader("三级标题")
# 文本显示
st.text("纯文本")
st.markdown("**Markdown文本**")
st.write("万能显示函数")
# 代码显示
st.code("print('Hello Streamlit')", language='python')
# 数学公式
st.latex(r"\frac{1}{2} \sum_{i=1}^{n} x_i^2")
# ==============================
# 💡 交互组件
# ==============================
# 输入组件
name = st.text_input("请输入您的姓名")
age = st.number_input("请输入您的年龄", min_value=0, max_value=120)
date = st.date_input("选择日期")
time = st.time_input("选择时间")
# 选择组件
option = st.selectbox("选择选项", ["选项1", "选项2", "选项3"])
options = st.multiselect("多选", ["A", "B", "C", "D"])
slider_val = st.slider("滑块", 0, 100, 50)
range_val = st.slider("范围滑块", 0, 100, (20, 80))
# 布尔组件
agree = st.checkbox("我同意条款")
radio = st.radio("选择一个", ["是", "否"])
# 按钮
if st.button("点击我"):
st.write("按钮被点击了!")
# 文件上传
uploaded_file = st.file_uploader("上传文件", type=['csv', 'txt'])
if uploaded_file:
st.write(uploaded_file.name)
# ==============================
# 💡 布局和容器
# ==============================
# 列布局
col1, col2, col3 = st.columns([1, 2, 1])
with col1:
st.write("左列")
with col2:
st.write("中间列")
with col3:
st.write("右列")
# 扩展器
with st.expander("展开查看详情"):
st.write("这里是详细内容")
# 容器
container = st.container()
with container:
st.write("容器内容")
# 空占位符
placeholder = st.empty()
placeholder.text("占位符内容")
# ==============================
# 💡 数据显示
# ==============================
# 创建示例数据
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'score': [85, 90, 78]
})
# 数据表格
st.dataframe(df) # 交互式表格
st.table(df) # 静态表格
# JSON数据
st.json({'name': 'Alice', 'age': 25})
# 指标显示
st.metric("温度", "37°C", "1.2°C")
# ==============================
# 💡 图标可视化
# ==============================
import matplotlib.pyplot as plt
import plotly.express as px
import altair as alt
# 原生图表
data = pd.DataFrame(np.random.randn(20, 3), columns=['a', 'b', 'c'])
st.line_chart(data) # 折线图
st.area_chart(data) # 面积图
st.bar_chart(data) # 柱状图
# Matplotlib图表
fig, ax = plt.subplots()
ax.plot(data['a'])
st.pyplot(fig)
# Plotly图表
fig = px.scatter(data, x='a', y='b')
st.plotly_chart(fig)
# Altair图表
chart = alt.Chart(data).mark_circle().encode(x='a', y='b')
st.altair_chart(chart)5.1.4. 高级功能
python
# ==============================
# 💡 状态管理
# ==============================
# 初始化会话状态
if 'counter' not in st.session_state:
st.session_state.counter = 0
# 使用状态
st.write(f"计数器: {st.session_state.counter}")
# 修改状态
if st.button("增加"):
st.session_state.counter += 1
# 回调函数中修改状态
def increment():
st.session_state.counter += 1
st.button("增加(回调)", on_click=increment)
# ==============================
# 💡 缓存系统
# ==============================
# 数据缓存 - 用于缓存数据(DataFrame、字典等)
@st.cache_data
def load_data():
"""加载数据的函数"""
return pd.read_csv("large_dataset.csv")
# 资源缓存 - 用于缓存全局资源(数据库连接、模型等)
@st.cache_resource
def init_model():
"""初始化机器学习模型"""
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
return model
# 使用缓存
data = load_data()
model = init_model()
import time
# ==============================
# 💡 进度条和状态
# ==============================
# 进度条
progress_bar = st.progress(0)
status_text = st.empty()
for i in range(100):
progress_bar.progress(i + 1)
status_text.text(f'进度: {i+1}%')
time.sleep(0.01)
# 状态消息
st.success("成功!")
st.error("错误!")
st.warning("警告!")
st.info("信息提示")
# 气球庆祝
st.balloons()
# ==============================
# 💡 表单处理
# ==============================
# 表单容器
with st.form("my_form"):
name = st.text_input("姓名")
age = st.number_input("年龄")
email = st.text_input("邮箱")
# 表单提交按钮
submitted = st.form_submit_button("提交")
if submitted:
st.write(f"姓名: {name}, 年龄: {age}, 邮箱: {email}")
# ==============================
# 💡 多页面应用
# ==============================
# pages/home.py
import streamlit as st
st.title("首页")
st.write("这是首页内容")
# pages/about.py
import streamlit as st
st.title("关于我们")
st.write("这是关于页面")
# main.py
import streamlit as st
# 页面配置
st.set_page_config(page_title="多页面应用")
# 侧边栏导航
pages = {
"首页": "home",
"关于": "about"
}
selected_page = st.sidebar.selectbox("选择页面", list(pages.keys()))
# 根据选择显示不同页面
if selected_page == "首页":
exec(open("pages/home.py").read())
elif selected_page == "关于":
exec(open("pages/about.py").read())5.1.5. 简单页面实现
😄 说下核心逻辑:
- 把 qa_chain() 对象的创建逻辑放到自定义的 load_qa_system() 方法中,使用 @st.cache_resource 装饰,它能确保系统组件只初始化一次!
- 会话状态初始化:st.session_state 可以用于在页面刷新间保持数据状态。
- 表单提交后,更新状态:st.session_state.messages.append({"role": "user", "content": question})
- st.rerun() 触发整个页面重新执行。
直接写出代码:
python
import os
import streamlit as st
from dotenv import load_dotenv
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from core.qa_chain import create_qa_chain
# 配置页面
st.set_page_config(
page_title="📚 个人知识库问答机器人",
page_icon="🤖",
layout="wide"
)
# 常量配置
VECTOR_STORE_PATH = os.path.join(os.path.dirname(__file__), "../vector_store/")
COLLECTION_NAME = "read_notes"
@st.cache_resource
def load_qa_system():
"""
初始化问答系统组件(使用缓存提高性能)
"""
load_dotenv()
API_KEY = os.getenv("API_KEY")
BASE_URL = os.getenv("BASE_URL")
EMBEDDINGS_MODEL = os.getenv("EMBEDDINGS_MODEL")
LLM_MODEL = os.getenv("LLM_MODEL")
# 检查向量数据库是否存在
if not os.path.exists(VECTOR_STORE_PATH):
st.error(f"❌ 向量数据库目录 '{VECTOR_STORE_PATH}' 不存在。")
st.info("📝 请先运行 'scripts/ingest.py' 来创建数据库。")
st.stop()
try:
# 初始化组件
embeddings = OpenAIEmbeddings(
openai_api_key=API_KEY,
openai_api_base=BASE_URL,
model=EMBEDDINGS_MODEL,
)
vector_store = Chroma(
persist_directory=VECTOR_STORE_PATH,
collection_name=COLLECTION_NAME,
embedding_function=embeddings,
)
llm = ChatOpenAI(
openai_api_key=API_KEY,
openai_api_base=BASE_URL,
model=LLM_MODEL,
temperature=0,
)
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 10}
)
# 创建问答链
qa_chain = create_qa_chain(retriever, llm)
return qa_chain
except Exception as e:
st.error(f"❌ 初始化问答系统失败: {str(e)}")
st.stop()
def main():
"""
主函数:构建Streamlit Web界面
"""
# 页面标题和描述
st.title("📚 个人知识库问答机器人")
st.markdown("---")
st.markdown("### 🤖 你好!我是你的个人知识库助手")
st.markdown("💡 **使用说明**: 在下方输入框中输入你的问题,点击发送按钮获取答案")
# 初始化会话状态
if "messages" not in st.session_state:
st.session_state.messages = []
# 初始化问答系统
with st.spinner("🔄 正在初始化问答系统..."):
qa_chain = load_qa_system()
st.success("✅ 问答系统已就绪!")
# 显示历史对话
if st.session_state.messages:
st.markdown("### 💬 对话历史")
for i, message in enumerate(st.session_state.messages):
if message["role"] == "user":
st.markdown(f"**🙋♂️ 你**: {message['content']}")
else:
st.markdown(f"**🤖 助手**: {message['content']}")
st.markdown("---")
# 问题输入区域
st.markdown("### ❓ 请输入你的问题")
# 创建输入表单
with st.form(key="question_form", clear_on_submit=True):
col1, col2 = st.columns([4, 1])
with col1:
question = st.text_input(
label="问题",
placeholder="例如:什么是刻意练习?如何提高自控力?",
label_visibility="collapsed"
)
with col2:
submit_button = st.form_submit_button(
label="🚀 发送",
use_container_width=True,
type="primary"
)
# 处理用户问题
if submit_button and question.strip():
# 添加用户问题到会话状态
st.session_state.messages.append({"role": "user", "content": question})
# 显示用户问题
st.markdown(f"**🙋♂️ 你**: {question}")
# 显示思考状态
with st.spinner("🤔 正在思考中..."):
try:
# 调用问答链获取答案
answer = qa_chain.invoke(question)
# 添加助手回答到会话状态
st.session_state.messages.append({"role": "assistant", "content": answer})
# 显示回答
st.markdown("**🤖 助手**:")
st.markdown(answer)
except Exception as e:
error_message = f"❌ 抱歉,处理问题时出现错误: {str(e)}"
st.error(error_message)
st.session_state.messages.append({"role": "assistant", "content": error_message})
# 自动重新运行以更新显示
st.rerun()
elif submit_button and not question.strip():
st.warning("⚠️ 请输入有效的问题!")
# 清除对话按钮
if st.session_state.messages:
st.markdown("---")
if st.button("🗑️ 清除对话历史", type="secondary"):
st.session_state.messages = []
st.rerun()
if __name__ == "__main__":
main()😳 每次输入一堆命令来启动,有些麻烦,直接搞一个启动脚本,还可以做一些命令参数的配置:
python
import subprocess
import sys
import os
def main():
"""
启动Streamlit Web应用
"""
print("🚀 正在启动个人知识库问答机器人Web界面...")
print("📝 提示:启动后会自动在浏览器中打开,如未自动打开请访问 http://localhost:8501")
print("🔄 按 Ctrl+C 停止服务")
print("-" * 50)
# 检查src/main_web.py是否存在
web_app_path = os.path.join("src", "main_web.py")
if not os.path.exists(web_app_path):
print(f"❌ 错误:找不到文件 {web_app_path}")
sys.exit(1)
try:
# 运行streamlit应用
subprocess.run([
sys.executable, "-m", "streamlit", "run",
web_app_path,
"--server.address", "localhost",
"--server.port", "8501",
"--server.headless", "false",
"--browser.gatherUsageStats", "false"
], check=True)
except subprocess.CalledProcessError as e:
print(f"❌ 启动失败:{e}")
sys.exit(1)
except KeyboardInterrupt:
print("\n👋 感谢使用,再见!")
sys.exit(0)
if __name__ == "__main__":
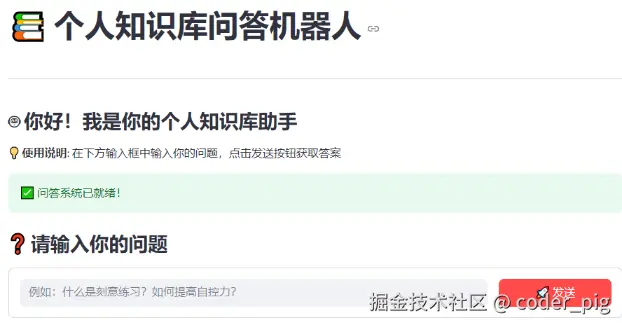
main()运行后:

6. 小结
😄 本节我们实现了一个基于 RAG 技术的 "个人知识库问题机器人🤖",听着很高大上,实现起来还挺简单的,只是踩坑费了点时间,核心其实就三步:
- ① 文档分割,批量调嵌入模型向量化,数据塞向量数据库里头。
- ② 用户提问,对问题向量化,基于余弦相似度检索对应数据。
- ③ 写Prompt模板,拼接问题+上面的数据 (作为上下文),丢给随便一个LLM模型就好了。
😶 例子只是抛砖引玉,感兴趣的读者还可以继续折腾,如:
- 尝试不同的文本分割策略,观察其对检索效果的影响。
- 替换不同的嵌入模型和向量数据库,理解它们的优劣。
- 优化检索过程,使用不同的检索算法 (如MMR, Maximal Marginal Relevance)。
- 使用 LangSmith 等工具对这个机器人进行追踪、可视化和评估。
- 将你的应用打包成 Docker 镜像,并部署在云服务上,供更多的人使用,等等...
🤷♀️ 懒得传Github了,直接压缩传网盘,源码取需:cp-qa-robot.7z