hive部署,参考:HBase实战(三)中Hive与HBase集成部分。
1.关于Hive
1.1 Hive是什么
Hive是由Facbook开源的一个解决海量结构化日志的数据统计工具,是Apache的一个顶级项目。官网地址: http://hive.apache.org/ 。我们要了解一个组件,官网的介绍是最重要的:
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
Hive提供了一种使用SQL语句来读、写、管理基于分布式系统的大型数据的功能。可以基于已有的数据进行部署。Hive给用户提供了一个命令行工具以及JDBC驱动用来连接Hive。
通常情况下, Hive是基于Hadoop的一个数据仓库工具,他可以将hdfs上的结构化数据文件映射成一张表,并提供以类SQL语句(HQL语句)进行查询统计的功能。而他的本质,其实就是将SQL语句转化成为模版化了的Mapreduce程序。整体的一个流程是这样。
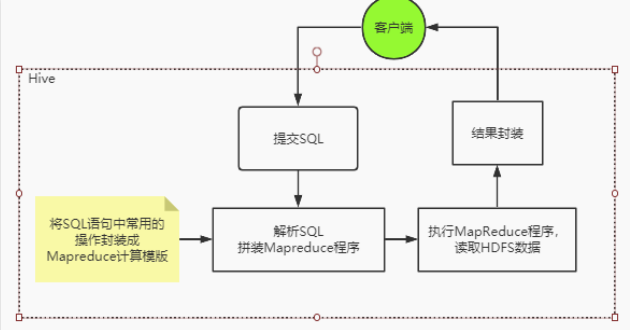
所以Hive不存储数据,自己也没有任何计算功能,只是相当于类SQL语句与Hadoop文件之间的一个解释器。他本质上只是一个对HDFS上的文件进行索引与计算的工具。他需要依赖Hadoop的Yarn来进行资源分配,也需要Hadoop的MapReduce来提供计算支持。后面我们会知道,hive在进行数据计算时,不仅可以用MapReduce来支持,也可以集合其他更灵活,更高效的大数据计算框架。
1.2 Hive的适用场景
从上面的介绍可以简单掌握Hive的特点:
优点:
(1)使用SQL语法查询,不用再去写复杂的MapReduce程序,减少开发成本,上手快。
(2)基于MapReduce算法,所以在处理大数据时,优势非常明显。
(3)可以支持自定义函数,计算能力强。
缺点:
(1)Hive的执行延迟比较高。这是因为启动并运行一个MapReduce程序本身需要消耗非常多的资源。
(2)Hive的HQL语句表达能力有限,并且他是基于模版实现的,所以通常不够智能化。很多复杂的大数据计算无法支持。比如迭代式计算。
(3)Hive处理大数据量非常擅长,但是处理小数据量就没有优势。
所以,Hive通常适用于大数据的OLAP场景,做一些面向分析,允许有延迟的数据挖掘工作。并且结合其他组件也可以用来做一些数据清洗之类的简单数据处理工作。
Hive是针对数据仓库来进行设计的,这种场景下,通常是读多写少。并且数据都是来自于外部的HDFS,所以Hive中不建议做数据的修改操作,所有的数据最好是在加载的时候就已经确定好了。
1.3 Hive的整体架构
Hive的整体架构大概是这样:
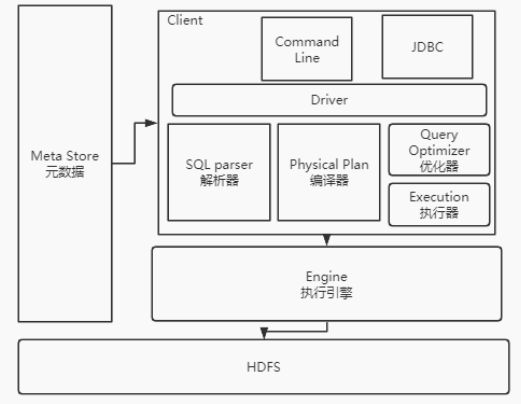
(1)用户接口:Hive提供了Command Line命令行工具,JDBC接口的方式来管理数据,并且也提供了WebUI,在浏览器访问hive。
(2)元数据:用来记录Hive中数据组织方式的数据。比如库名、表名、数据所在目录等。元数据默认是存储在自带的derby数据库中。derby是一个本地单机数据库,不利于元数据共享。通常情况下,会使用MqSQL来存储元数据。
(3)驱动器Driver:通过一系列的组件来执行SQL。首先通过SQL parser解析器将客户端的SQL语句解析成抽象语法树AST(Abstract Syntax Tree)。这一步通常会用一些第三方工具来完成,比如antlr。接下来 Physical Plan 编译器将ASTA树编译生成具体的逻辑执行计划然后 Query Optimizer 优化器对逻辑执行计划进行优化。最后 把逻辑执行计划转换成为可以运行的物理计划。对于Hive,物理计划就是一个MapReduce计算程序。
(4)Execution Engine 执行引擎:Hive将生成的MapReduce计算程序提交给外部的计算工具执行。默认Hive是使用的Hadoop的Mapreduce来执行,另外,hive也支持tez和spark。而计算的所有数据来源最终全都来自于Hdfs。
1.4 为什么要用Hive而不用关系型数据库
Hive是基于Hadoop的,所以Hive的可扩展性与Hadoop的可扩展性是一致的。而Hadoop相比于传统数据库:
一方面他的扩展能力相当强,Hadoop支持将不同配置的机器一起组成庞大的集群。目前世界上最大的Hadoop集群在Yahoo,有超过5000台节点。而关系型数据库相比就差很远了。例如,Oracle理论上的扩展能力也只有100台左右,这还是基于高成本服务器组成的理论环境。
另一方面他的数据处理能力也相当强。当数据量非常大时,关系型数据库虽然也可以用分库分表等方式做一些扩展,但是数据承载能力始终相当有限,并且数据量大了之后,性能下降明显。而基于Hadoop的大数据体系承载海量数据就轻松很多。数据量增大对整体性能的影响非常有限。
2.hive的配置总结
2.1 hive指令的其它用法
我们多次用到了hive指令,这里就需要梳理一下hive指令到底有哪些功能。
powershell
hive -help;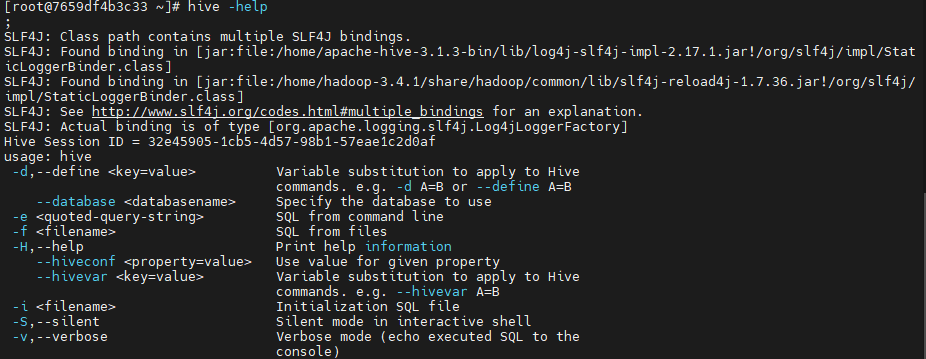
这里面,用得比较多的是 -e 和 -f 两个指令。 -e 指令可以直接执行一个SQL,例如 hive -e "select * from student;"。而 -f 可以指定一个SQL文件,并且通常我们还会使用Linux指令将输出结果重定向到一个文件。 例如 hive -f /root/hivetest.sql > /root/hivetestResult。
然后,我们还用过了hive --service 指令来启动hive的元数据服务。我们可以这样来看一下hive中内置了多少服务。
例如,我们就可以使用version服务查看hive的版本信息:

2.2 hive的日志配置
hive的log日志默认存放在/tmp/root/hive.log文件中(跟用户名有关)。
如果要修改hive跟日志相关的配置,可以将$HIVE_HOME/conf下的hive-log4j2.properties.template复制成为hive-log4j2.properties,然后对里面的配置进行定制。例如hive日志文件的地址配置在property.hive.log.dir属性,而日志文件名配置在property.hive.log.file属性。
2.3 hive的关键配置
hive相比hadoop、spark这些组件来说还是简单很多,所以他的核心配置也少很多。他的所有核心配置属性,都在$HIVE_HOME/conf/hive-default.xml.template文件中,这里面有所有的常用配置信息以及描述,是很重要的优化Hive的参考。比如最重要的这个配置:

这个配置就是hive的执行引擎,默认是使用Hadoop的MapReduce。同时也支持Tez。