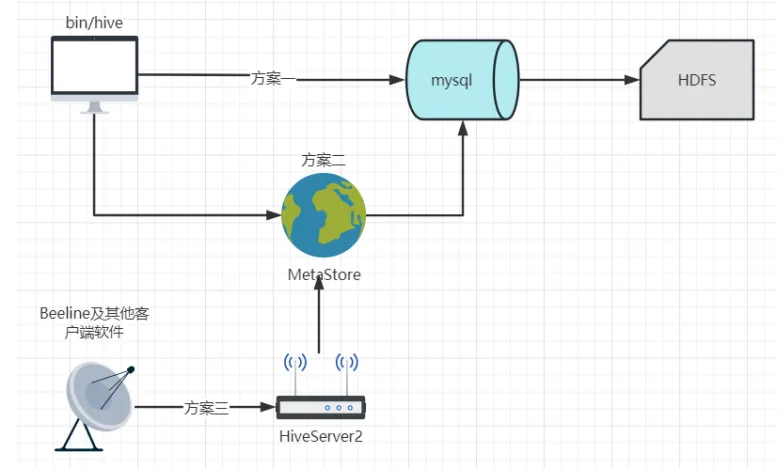
Hive中的Metastore服务是元数据管理的核心组件,其意义主要体现在以下几个方面:
1. 统一存储元数据
Metastore集中管理所有Hive表、分区、列、存储格式等元数据信息。例如:
- 表结构(字段名、类型)
- 分区信息(分区键、位置)
- 数据存储路径(HDFS路径)
- 表属性(如序列化格式
SerDe)
2. 解耦计算与元数据
- 计算引擎独立:HiveQL解析器、执行引擎(如MR/Tez/Spark)无需直接访问物理存储,只需通过Metastore获取元数据。
- 元数据共享:多个Hive客户端(CLI、JDBC等)可同时访问同一Metastore,保证元数据一致性。
3. 支持多计算框架
Metastore的元数据可被其他大数据工具复用,例如:
- Spark SQL:直接读取Hive表元数据
- Presto:跨数据源查询时复用分区信息
- Flink:集成Hive Catalog管理表结构
4. 元数据持久化
默认将元数据存储在关系型数据库(如MySQL/PostgreSQL),实现:
- 高可靠性:避免内存元数据丢失
- 事务支持:ACID特性保障元数据操作一致性
5. 服务化架构
支持两种部署模式:
- 内嵌模式(Embedded):适用于轻量级测试,元数据与Hive服务同进程
- 远程模式(Remote):独立服务,通过Thrift API提供高并发访问,支撑大规模集群
典型应用场景
+----------------+ +------------+ +-----------+
| Hive CLI |------>| Metastore |<------| Spark SQL |
| (执行查询) | | (元数据服务) | | (读Hive表) |
+----------------+ +------------+ +-----------+
|
v
+----------------+
| RDBMS |
| (MySQL/PostgreSQL) |
+----------------+通过解耦元数据管理,Metastore成为Hive生态系统的中枢神经,极大提升了数据治理效率和系统扩展性。