论文题目:Uncertainty Modeling for Out-of-Distribution Generalization
论文来源:ICLR 2022
论文作者:

论文链接:https://arxiv.org/pdf/2202.03958
论文源码:https://github.com/lixiaotong97/DSU
一、摘要
尽管深度神经网络在多种视觉任务中取得了显著进展,但在面对分布外(out-of-distribution) 场景时,其性能仍然明显下降。我们认为,特征统计量(均值和标准差)承载着训练数据的领域特性,可以通过合理操控来提升模型的泛化能力。现有方法通常将这些统计量视为从特征中计算得到的确定性值,未能显式考虑测试阶段由潜在领域偏移引起的统计不确定性。本文提出在训练阶段通过建模领域偏移的不确定性来提升网络的泛化能力。具体而言,我们假设特征统计量服从多元高斯分布,因此每个统计量不再是确定值,而是一个具有多种分布可能性的概率点。借助这种不确定特征统计量,模型可在训练中缓解领域扰动,增强对潜在领域偏移的鲁棒性。我们的方法可无缝集成到现有网络中,无需引入额外参数或损失函数。大量实验表明,该方法在多个视觉任务(包括图像分类、语义分割和实例检索)中持续提升模型的泛化性能。
二、Introduction
深度神经网络在计算机视觉中表现卓越,但其成功严重依赖于"训练与测试域服从独立同分布"的假设(Ben-David et al., 2010; Vapnik, 1992)。然而,现实场景常违背该假设。例如:
- 在雨天/雾天环境部署晴天训练的语义分割模型(Choi et al., 2021)
- 用照片训练模型识别艺术画作(Li et al., 2017)
此类分布外部署场景均会导致性能显著下降。因此,域泛化(Domain Generalization) ------提升模型在未知测试域上的鲁棒性------成为关键问题。
核心问题分析:先前工作(Huang & Belongie, 2017; Li et al., 2021)表明,作为特征矩的特征统计量(均值与标准差) 携带了训练数据的领域特征(如照片风格、拍摄环境)。不同数据分布的域通常具有不一致的特征统计量(Wang et al., 2020b; Gao et al., 2021a)。主流深度学习方法遵循经验风险最小化(Empirical Risk Minimization) 原则(Vapnik, 1999),虽在训练域表现良好,但未显式建模测试时统计差异的不确定性,导致模型过拟合训练域,对测试时的统计变化高度敏感。
解决方案动机 :测试域可能引发方向和强度均不确定的统计偏移(如图1所示)。
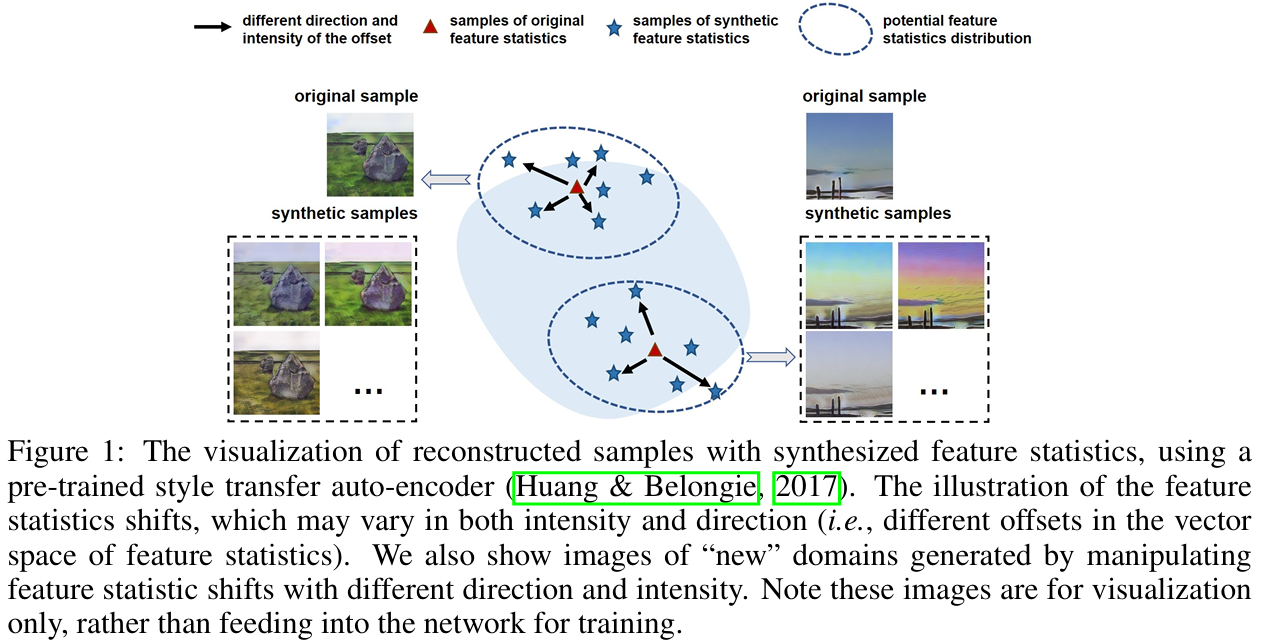
关键洞察 :通过合成特征统计量变体建模域偏移的不确定性,可提升网络对不同测试分布的适应性。
本文提出不确定性域偏移建模(Domain Shifts with Uncertainty, DSU):将特征统计量重新定义为概率分布(多元高斯分布),其中心为原始统计量,分布范围表示潜在域偏移的变异强度。通过随机采样合成的统计量变体替代原始值,迫使模型学习域不变特征。
方法优势:
- 轻量化,无额外参数,训练阶段插入,测试阶段移除。
- 通用性,适用于图像分类、分割、检索等多种任务。
- 有效性,实验证明其显著提升模型对域偏移的鲁棒性。
三、相关工作
3.1 域泛化 (Domain Generalization)
数据增强 (Data Augmentation)
- 图像级:AugMix(Hendrycks et al., 2020)、CutMix(Yun et al., 2019)
- 特征级:Mixup(Zhang et al., 2018)及其流形扩展Manifold Mixup(Verma et al., 2019)
- 统计量操作:MixStyle(Zhou et al., 2021b)对实例间统计量线性插值;pAdaIn(Nuriel et al., 2021)通过批次置换交换统计量
不变表示学习 (Invariant Representation Learning)
- 域对齐:最小化域间分布距离(Li et al., 2018b,c)
- 解耦表示:分离域特定/不变特征(Chattopadhyay et al., 2020; Piratla et al., 2020)
- 归一化方法:通过标准化移除风格信息(Pan et al., 2018; Choi et al., 2021)
学习策略 (Learning Strategies)
- 集成学习:组合多样化模型(Zhou et al., 2020b)或模块(Seo et al., 2020)
- 元学习:模拟域偏移的元训练范式(Finn et al., 2017; Li et al., 2018a)
- 自挑战机制:如RSC(Huang et al., 2020)通过丢弃主导特征迫使模型学习通用表示
3.2 深度学习中的不确定性 (Uncertainty in Deep Learning)
- 数据不确定性:变分自编码器(Kingma & Welling, 2013)建模隐空间不确定性
- 模型不确定性:Dropout(Srivastava et al., 2014)可作为贝叶斯近似(Gal & Ghahramani, 2016)
- 应用场景:处理噪声标签(DistributionNet)、人脸质量评估(DUL, PFE)
本文创新:首次将不确定性建模用于特征统计量,以解决分布外泛化问题,区别于前述方法。
四、方法
4.1 预备知识
给定网络中间层的特征张量
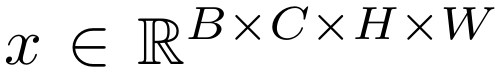
其中,B 为批次大小,C 为通道数,H 和W 为空间尺寸。我们定义每个实例在批次中的通道级特征均值和标准差为
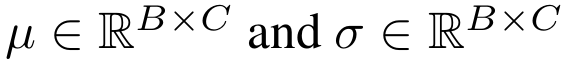
它们可通过以下等式计算得出
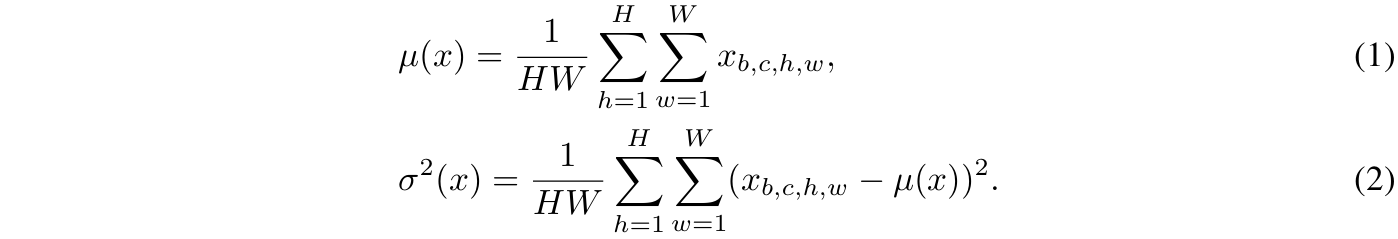
先前工作(Huang & Belongie, 2017; Li et al., 2021)表明,特征统计量可抽象化表征域的关键特性(如颜色、纹理、对比度)。在分布外场景中,不同域的统计量不一致性会削弱模型泛化能力(Wang et al., 2019a; Gao et al., 2021a)。现有方法(如MixStyle、pAdaIN)通过样本间线性操作(交换或插值)生成新统计量,但受限于参考样本的选择,其生成的变异方向与强度有限,难以覆盖真实域偏移的多样性。
4.2 不确定性域偏移建模
针对测试域特征统计量的任意方向与强度偏移(图1),我们提出不确定性域偏移建模(DSU):
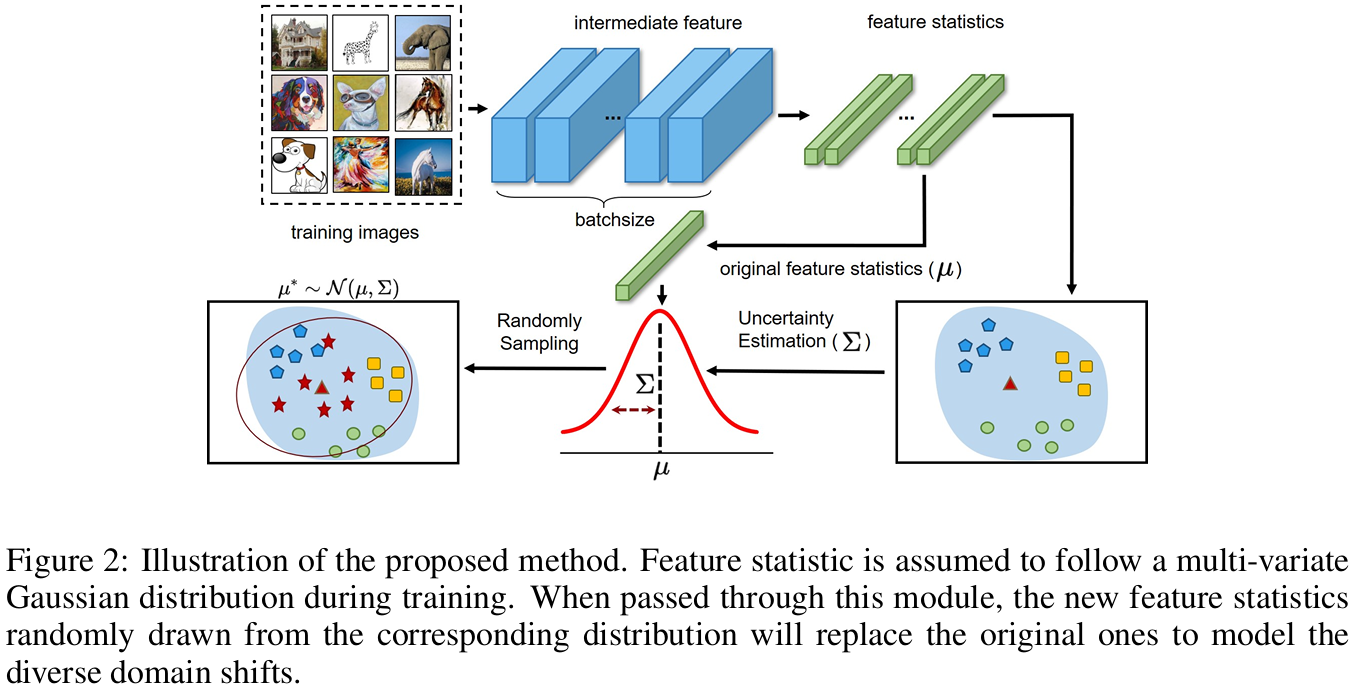
假设每个特征统计量在考虑潜在不确定性后服从多元高斯分布,即均值μ 和标准差σ分别服从
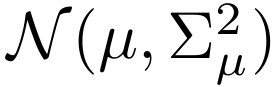
和
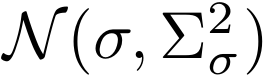
分布中心为原始统计量,标准差Σ描述潜在偏移的不确定性范围。
4.2.1 不确定性估计
由于测试域未知,我们提出非参数化估计方法,利用批次统计量方差指导变异范围:
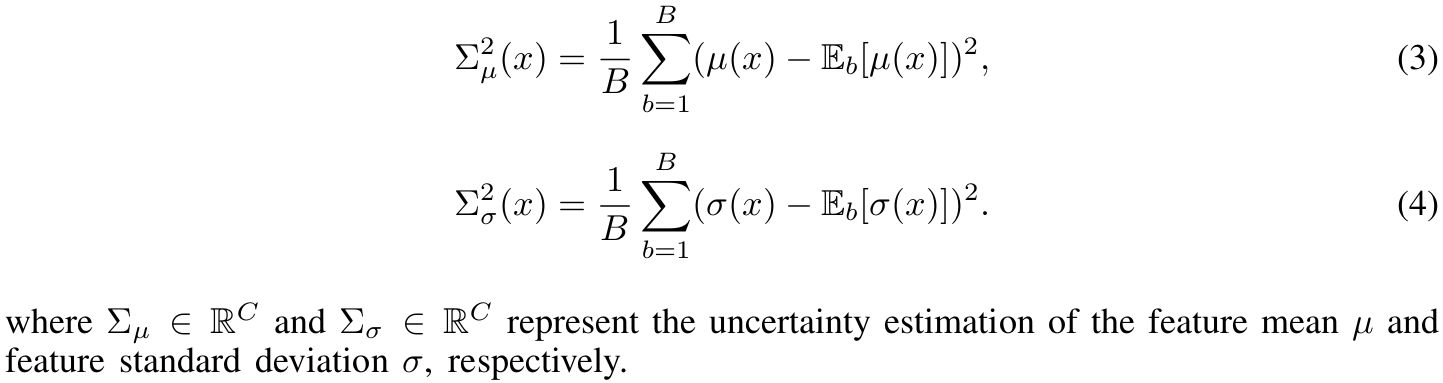
这里的是指对batch维度求期望(均值),且
.
4.2.2 特征统计量的概率分布
通过重参数化技巧(Kingma & Welling, 2013)从分布中采样新统计量:
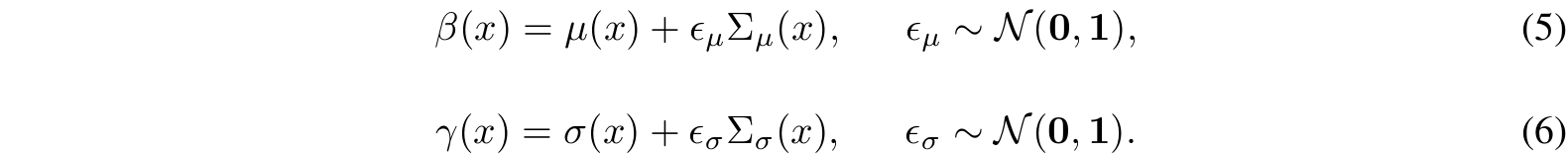
该操作生成方向和强度随机组合的多样化统计量变体。
4.2.3 实现
通过自适应实例归一化(AdaIN)(Huang & Belongie, 2017)实现特征变换:
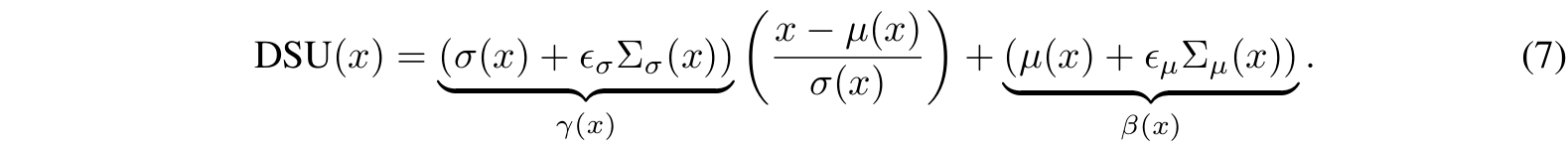
该模块可插入网络任意位置,训练时按概率p激活,测试时移除。算法流程如下:

五、实验
我们在多种视觉任务上验证了所提出方法的有效性,包括图像分类、语义分割、实例检索以及对图像损坏的鲁棒性测试。这些任务的训练和测试数据之间存在不同类型的分布偏移,例如风格变化、合成到现实的差距、场景变化和像素级损坏。
5.1 多领域分类任务
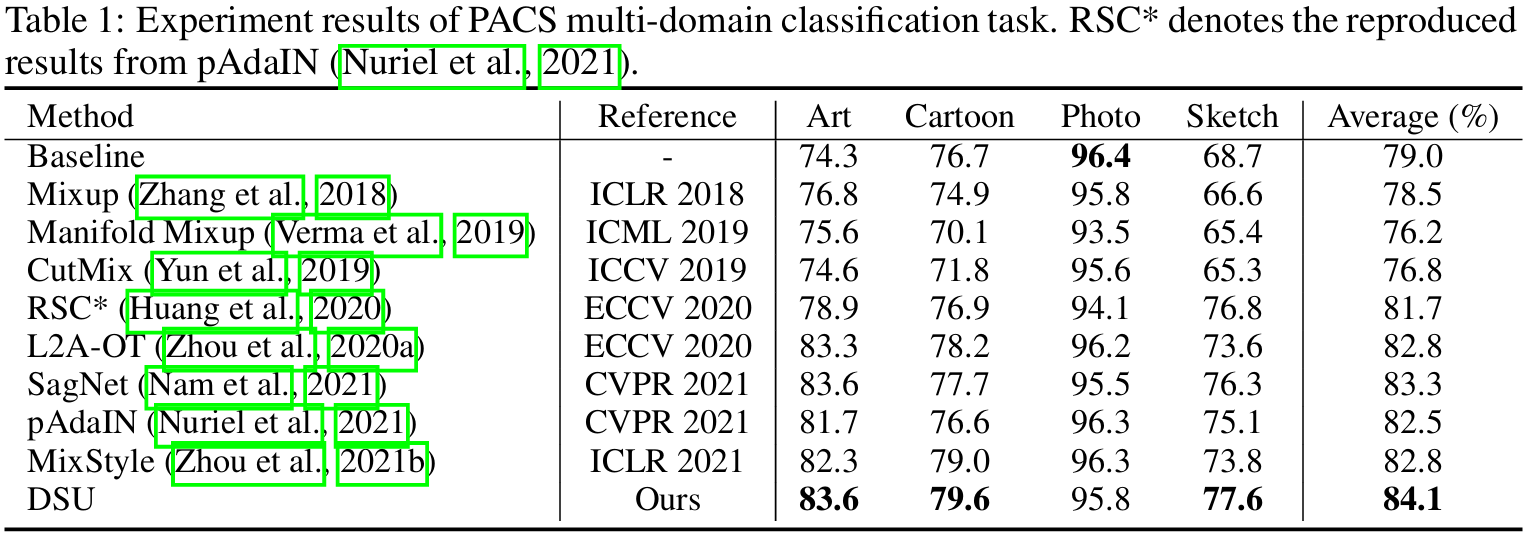
- 设置与实现细节:我们在PACS数据集上进行评估,该数据集包含四种风格:艺术画(Art)、卡通(Cartoon)、照片(Photo)和素描(Sketch)。采用留一领域验证协议(leave-one-domain-out),使用ResNet18作为骨干网络,训练设置与MixStyle一致。此外,我们还在Office-Home数据集上进行了实验。
- 实验结果:如表1所示,我们的方法相比基线方法有显著提升,尤其是在Art和Sketch领域,平均准确率提升近10%。与现有方法(如 MixStyle、pAdaIN、SagNet 等)相比,DSU也表现出更强的泛化能力。
5.2 语义分割任务
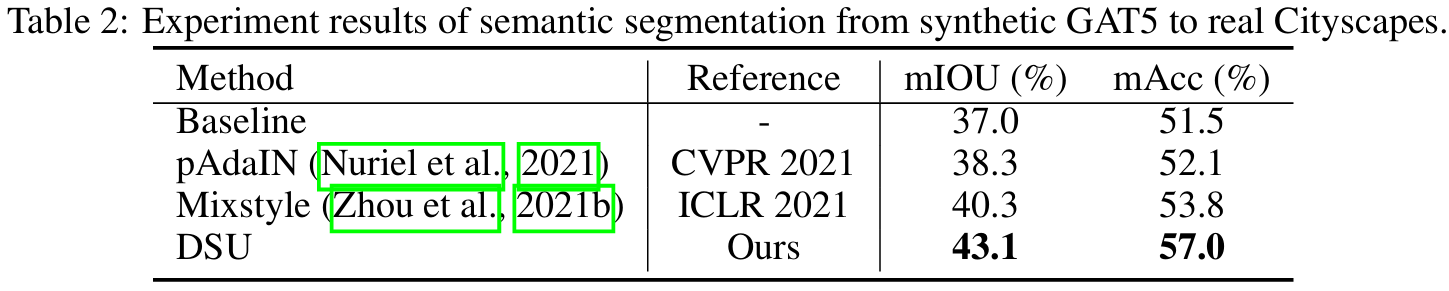
- 设置与实现细节:使用合成数据集GTA5训练,真实数据集Cityscapes测试。采用DeepLab-v2网络(ResNet101骨干),评估指标为mIOU和mAcc。
- 实验结果:如表2所示,DSU在mIOU和mAcc上分别提升了6.1%和5.5%,显著优于基线和其他方法。可视化结果表明,DSU能更好地保留细节并适应真实场景。
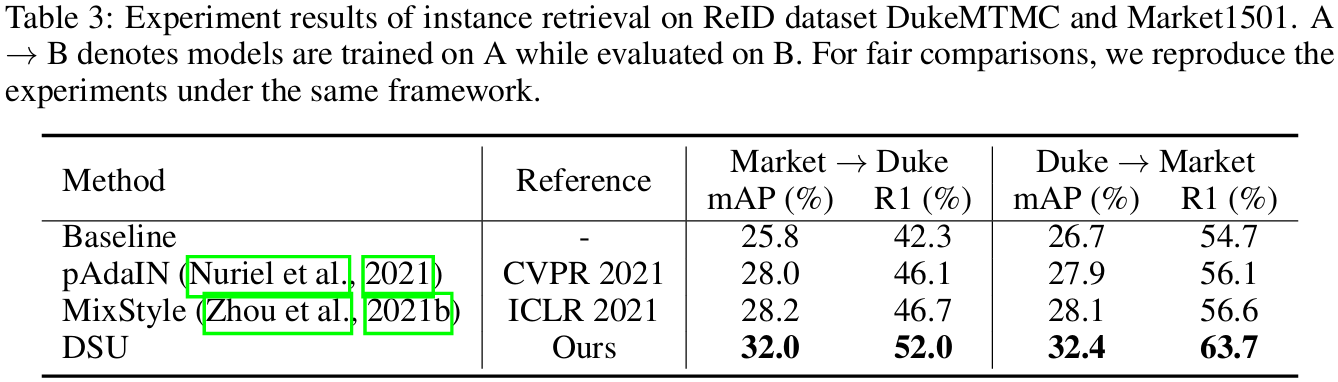
5.3 实例检索任务
- 设置与实现细节:在DukeMTMC和Market1501数据集上进行跨域行人重识别实验,使用ResNet50骨干网络,评估指标为mAP和Rank-1准确率。
- 实验结果:如表3所示,DSU在两项指标上均显著优于基线,并超越MixStyle和pAdaIN。这表明DSU在细粒度任务中也能有效保留关键信息并提升泛化能力。
5.4 对图像损坏的鲁棒性
- 设置与实现细节:在ImageNet-C数据集上测试模型对15种图像损坏的鲁棒性,使用ResNet50骨干网络,评估指标为Clean Error和mCE(平均损坏误差)。
- 实验结果:如表4所示,DSU在保持清洁图像性能的同时,显著提升了模型对损坏图像的鲁棒性。与APR方法结合后,mCE从65.0%降至64.1%,表明DSU可与其他增强方法兼容并进一步提升性能。

5.5 其它实验
图5定量对比了baseline与DSU模型在未见域上的特征统计量(均值+标准差)分布。DSU的分布明显更靠近训练域,说明其通过不确定性扰动有效抑制了统计偏移。
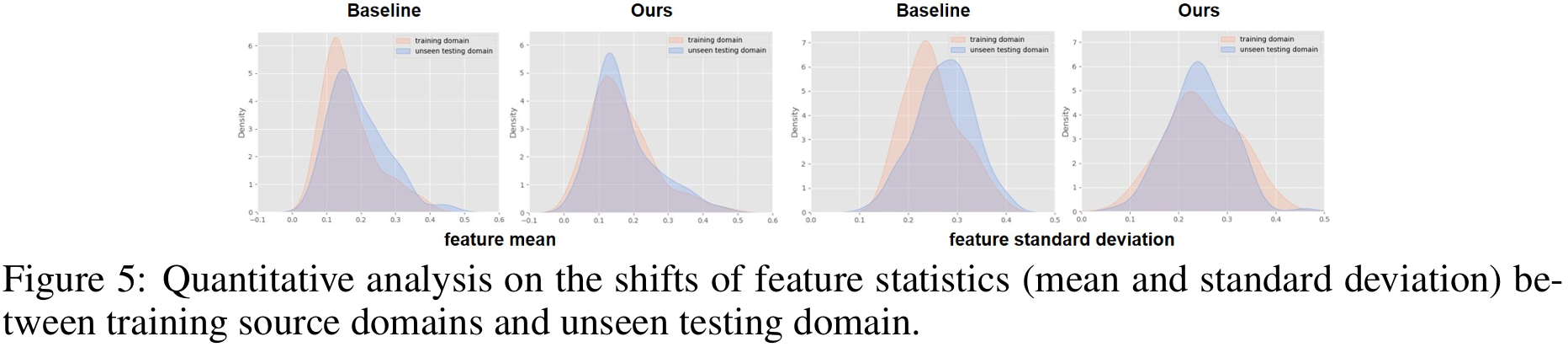
图6用自编码器把DSU扰动后的特征重建回图像,展示同一输入可生成多样风格、纹理与对比度变化。这些可视化证实DSU能在特征空间产生丰富且合理的域偏移样本,从而提升模型泛化能力。

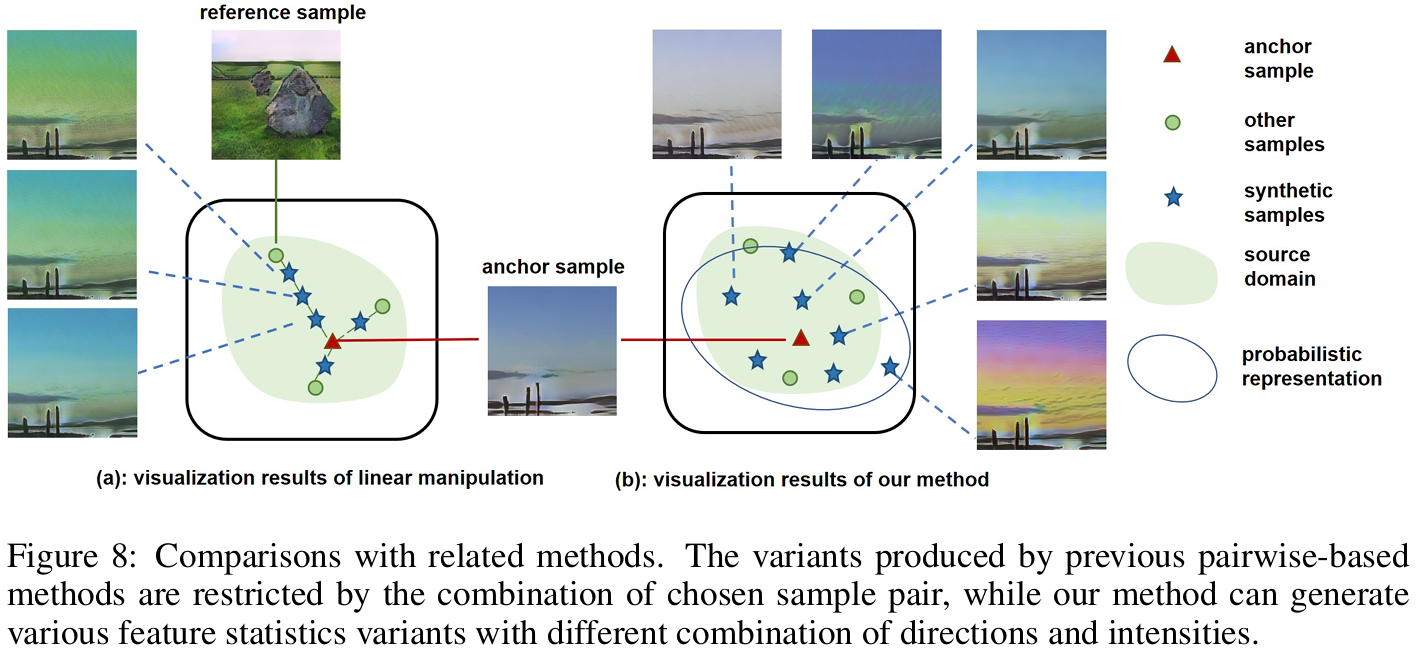
图8对比MixStyle/pAdaIN的线性插值或交换与DSU的多元高斯采样:后者无需参考样本即可生成方向与强度更丰富的特征统计变异,突破训练域凸包限制。
六、结论
在本文中,我们提出了一种概率化的方法,通过在训练阶段建模领域偏移的不确定性,并利用合成的特征统计量来提升网络的泛化能力。具体而言,我们假设每个特征统计量服从一个多元高斯分布,以建模各种潜在的偏移情况。由于生成的特征统计量具有多样化的分布可能性,模型能够对不同的领域偏移具备更好的鲁棒性。实验结果验证了我们所提出方法在提升网络泛化能力方面的有效性。
七、个人思考与理解
- 不确定性是如何嵌入到模型的学习过程的?
不确定性来源:
- 小批统计量的通道方差
- 重参数化时注入的标准高斯噪声
如何嵌入到模型:通过等式(7)对进行特征变换,然后使用变换后的统计量进行特征归一化(类似AdaIN操作),于是不确定性就嵌入到模型的学习过程中。
- DSU的本质是什么?
一种无参数的、非监督的、基于特征统计扰动的方法。
- 与LLM的潜在结合之处有哪些?
- 特征统计扰动的泛化思想迁移:在Transformer中,LayerNorm也使用了均值和方差进行归一化;可以尝试对LayerNorm的统计量进行类似的"扰动建模",增强模型对文本风格、领域变化的鲁棒性。
- 不确定性建模用于提示学习(Prompt Learning):在soft prompt或continuous prompt中,prompt embedding可视为随机变量;引入类似DSU的不确定性建模,增强prompt的泛化能力。
- 数据增强策略:在文本表示空间(如CLS向量或中间层表示)引入统计扰动,作为一种表示级数据增强;有助于提升模型在跨域文本(如新闻 vs 微博、正式 vs 口语)上的泛化能力。
- 对抗鲁棒性提升:DSU的扰动机制可视为一种隐式对抗训练;可用于提升LLM在面对输入扰动(如拼写错误、风格变化)时的鲁棒性。
- 重参数化是什么?
一种将随机采样操作转化为可微表达式的技巧,支持梯度回传。可以看一下博客:搞明重参数化。感觉说得还算清楚。