前言
你是不是也遇到过这种尴尬:用 GraphRAG 搞了个酷炫的知识图谱,本以为问答会变得智能又丝滑,结果模型输出一堆"答非所问"?别急,这锅可能不在模型,而在 图数据质量。今天我们就来聊聊:
- GraphRAG 常见"翻车"问题
- 为啥图数据质量是幕后大 Boss
- 怎么优雅地评估你的图数据
🐛 GraphRAG 那些"坑"
GraphRAG 很强大,但也有不少小毛病,我们以GraphRAG:让 RAG 更聪明的一种新玩法中的数据为例:
yaml
在 2023 年的深圳,一家名为「星河机器人」的初创公司与华为签署了合作协议,计划联合研发下一代类人机器人。
这项合作由星河机器人的创始人李明推动,他此前曾在麻省理工学院学习人工智能。
协议中提到,华为将提供 5G 通讯技术与昇腾芯片,而星河机器人则负责机器人的操作系统与感知算法。
与此同时,在北京,中科院自动化研究所也在进行类似的研究,其负责人王芳曾多次公开表示,中国在未来十年内有望在机器人与脑机接口的结合上取得突破。
值得注意的是,王芳与李明在 2021 年上海的「全球人工智能大会」上曾经同台演讲,探讨过 AI 与神经科学的交叉应用。
如果这两条研发路线最终能够汇合,可能会加速人形机器人在医疗康复与工业制造中的落地。-
实体识别乱七八糟
-
有中文也有英文:
李明与LI MING,应该是同意个实体。 -
议与王,应该是文本分割造成问题。 -
2023,这个应该是时间。
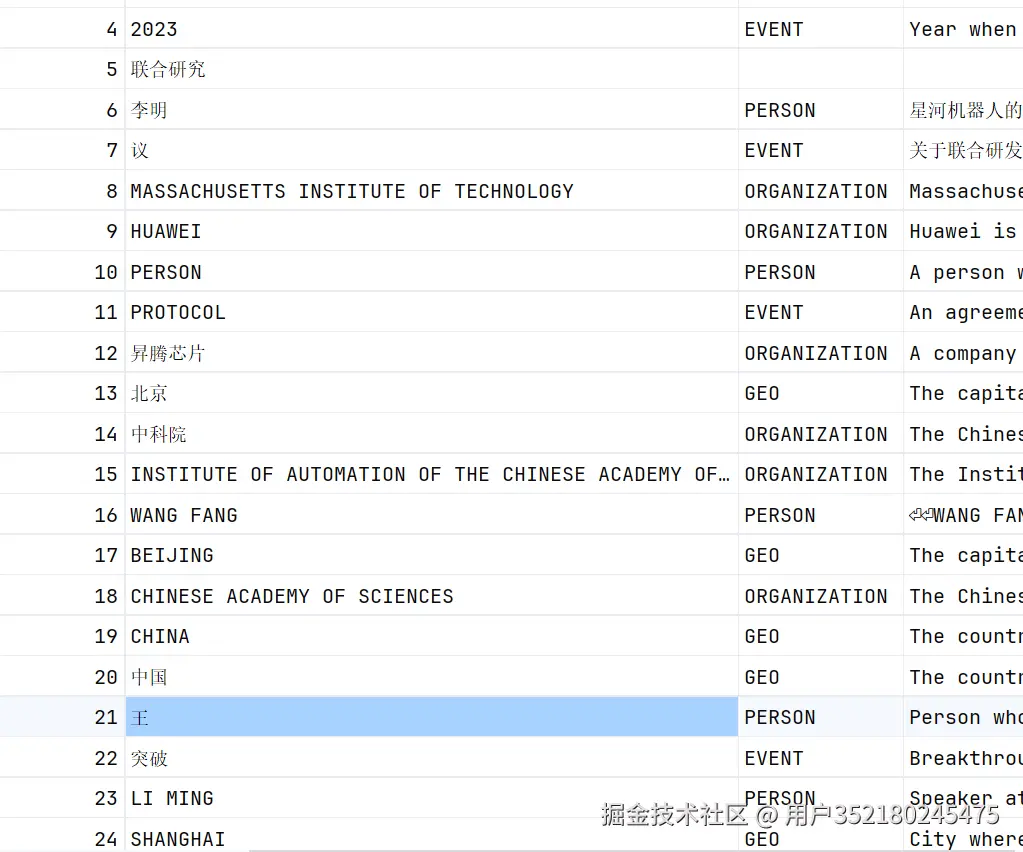
-
-
代词迷失
- 句子里出现"他",模型就像迷路的小羊:"他"是谁来着?
-
图结构要么稀疏要么爆炸
- 稀疏:检索不到答案。
- 爆炸:一堆无关节点连成网,噪声大到怀疑人生。
-
数据陈旧没更新
- 还在用去年的数据回答今年的问题,妥妥"历史遗留 bug"。
这些问题的共同根源?👉 图数据质量差。如果图数据不靠谱,RAG 再聪明也只能"胡说八道"。
🚦 为什么图数据质量评估很重要
- 不给模型背锅:别让好模型被坏数据拖下水。
- 精准优化:数据问题 ≠ 模型问题,搞清楚症结才能对症下药。
- 长久稳定运行:评估 + 监控 = 持续高质量输出。
- 团队协作:量化指标比"我感觉这不对"更有说服力。
- **持续改进:**通过质量的评估量化,我们可以不断改进与优化我们的GraphRAG方案。
📊 评估思路(别慌,其实很简单)
- 节点指标
- 精确率 (Precision)、召回率 (Recall)、F1:预测实体对不对。
- 去重率:有多少重复节点。
- 边指标
- 同样用 Precision / Recall / F1:连接是否正确。
- 结构指标
- 连通性:节点之间有没有合理路径。
- 稀疏度 / 密度:过稀疏=找不到信息,过密=噪声太多。
- 一致性检查
- 有没有逻辑冲突:比如 A→B 和 B→A 意思完全相反。
🧪 让我们动手评估!(示例代码)
评估代码需要根据我们自己的图数据类型来的,我们这边仅提供实体与关系这两类的评估,我们这边提供的不一定是最优的结果,我们的重点通过这个评估的代码,我们判断我们优化的方案是否有效!
🗂️ 示例数据
我们这边使用之前的GraphRAG:让 RAG 更聪明的一种新玩法的样例数据,下面是人工识别的出来的实体与关系信息:
实体:
json
[
{
"id": "1",
"title": "深圳",
"type": "GEO",
"description": "深圳是中国南方科技中心城市,星河机器人与华为的合作地点",
"coreference": null
},
{
"id": "2",
"title": "星河机器人",
"type": "ORGANIZATION",
"description": "星河机器人是一家专注于类人机器人研发的初创公司",
"coreference": null
},
{
"id": "3",
"title": "华为",
"type": "ORGANIZATION",
"description": "华为是一家全球领先的科技公司,提供 5G 通讯技术和昇腾芯片",
"coreference": null
},
{
"id": "4",
"title": "类人机器人",
"type": "ORGANIZATION",
"description": "类人机器人是星河机器人与华为联合研发的高级机器人技术",
"coreference": null
},
{
"id": "5",
"title": "李明",
"type": "PERSON",
"description": "李明是星河机器人的创始人,曾在麻省理工学院学习人工智能",
"coreference": null
},
{
"id": "6",
"title": "李明",
"type": "PERSON",
"description": "李明是星河机器人的创始人,曾在麻省理工学院学习人工智能",
"coreference": "他"
},
{
"id": "7",
"title": "麻省理工学院",
"type": "GEO",
"description": "麻省理工学院是李明学习人工智能的著名学术机构",
"coreference": null
},
{
"id": "8",
"title": "5G通讯技术",
"type": "ORGANIZATION",
"description": "5G 通讯技术是华为为类人机器人研发提供的关键技术",
"coreference": null
},
{
"id": "9",
"title": "昇腾芯片",
"type": "ORGANIZATION",
"description": "昇腾芯片是华为为类人机器人研发提供的高性能芯片",
"coreference": null
},
{
"id": "10",
"title": "机器人操作系统",
"type": "ORGANIZATION",
"description": "机器人操作系统由星河机器人开发,用于类人机器人控制",
"coreference": null
},
{
"id": "11",
"title": "感知算法",
"type": "ORGANIZATION",
"description": "感知算法由星河机器人开发,用于类人机器人的环境感知",
"coreference": null
},
{
"id": "12",
"title": "北京",
"type": "GEO",
"description": "北京是中科院自动化研究所的所在地,科技研究重镇",
"coreference": null
},
{
"id": "13",
"title": "中科院自动化研究所",
"type": "ORGANIZATION",
"description": "中科院自动化研究所从事机器人与脑机接口研究",
"coreference": null
},
{
"id": "14",
"title": "王芳",
"type": "PERSON",
"description": "王芳是中科院自动化研究所的负责人,研究机器人与脑机接口",
"coreference": null
},
{
"id": "15",
"title": "中科院自动化研究所",
"type": "ORGANIZATION",
"description": "中科院自动化研究所从事机器人与脑机接口研究",
"coreference": "其"
},
{
"id": "16",
"title": "中国",
"type": "GEO",
"description": "中国是机器人与脑机接口研究的重要国家",
"coreference": null
},
{
"id": "17",
"title": "未来十年",
"type": "EVENT",
"description": "未来十年是中国机器人与脑机接口技术的突破期",
"coreference": null
},
{
"id": "18",
"title": "脑机接口",
"type": "ORGANIZATION",
"description": "脑机接口是中科院自动化研究所研究的前沿技术",
"coreference": null
},
{
"id": "19",
"title": "王芳",
"type": "PERSON",
"description": "王芳是中科院自动化研究所的负责人,研究机器人与脑机接口",
"coreference": null
},
{
"id": "20",
"title": "李明",
"type": "PERSON",
"description": "李明是星河机器人的创始人,曾在麻省理工学院学习人工智能",
"coreference": null
},
{
"id": "21",
"title": "李明和王芳",
"type": "PERSON",
"description": "李明和王芳在2021年全球人工智能大会上同台演讲",
"coreference": "他们"
},
{
"id": "22",
"title": "2021年",
"type": "EVENT",
"description": "2021 年是全球人工智能大会的举办时间",
"coreference": null
},
{
"id": "23",
"title": "上海",
"type": "GEO",
"description": "上海是2021年全球人工智能大会的举办城市",
"coreference": null
},
{
"id": "24",
"title": "全球人工智能大会",
"type": "EVENT",
"description": "全球人工智能大会是2021年李明与王芳同台演讲的平台",
"coreference": null
},
{
"id": "25",
"title": "人工智能",
"type": "ORGANIZATION",
"description": "人工智能是李明和王芳研究的重点领域",
"coreference": null
},
{
"id": "26",
"title": "神经科学",
"type": "ORGANIZATION",
"description": "神经科学是王芳在全球人工智能大会上探讨的领域",
"coreference": null
},
{
"id": "27",
"title": "医疗康复",
"type": "ORGANIZATION",
"description": "医疗康复是人形机器人的潜在应用领域",
"coreference": null
},
{
"id": "28",
"title": "工业制造",
"type": "ORGANIZATION",
"description": "工业制造是人形机器人的潜在应用领域",
"coreference": null
},
{
"id": "29",
"title": "人工智能",
"type": "ORGANIZATION",
"description": "人工智能是星河机器人和华为合作研发的核心技术领域",
"coreference": null
},
{
"id": "30",
"title": "神经科学",
"type": "ORGANIZATION",
"description": "神经科学是全球人工智能大会探讨的交叉研究领域",
"coreference": null
},
{
"id": "31",
"title": "AI与神经科学的交叉应用",
"type": "ORGANIZATION",
"description": "AI 与神经科学的交叉应用是李明与王芳在大会上探讨的主题",
"coreference": null
},
{
"id": "32",
"title": "两条研发路线",
"type": "ORGANIZATION",
"description": "两条研发路线指星河机器人和中科院自动化研究所的类人机器人与脑机接口研究",
"coreference": null
}
]关系:
json
[
{
"id": 1,
"source": "星河机器人",
"target": "华为",
"description": "星河机器人与华为签署了合作协议,计划联合研发项目",
"relationship_strength": 0.9
},
{
"id": 2,
"source": "星河机器人",
"target": "深圳",
"description": "星河机器人位于深圳,这座城市是其运营的基础",
"relationship_strength": 0.8
},
{
"id": 3,
"source": "星河机器人",
"target": "2023年",
"description": "2023年是星河机器人与华为合作的关键年份",
"relationship_strength": 0.8
},
{
"id": 4,
"source": "星河机器人",
"target": "合作协议",
"description": "星河机器人与华为签署的合作协议是双方合作的基础",
"relationship_strength": 0.9
},
{
"id": 5,
"source": "华为",
"target": "深圳",
"description": "华为的总部位于深圳,这使得两者在地理上紧密相关",
"relationship_strength": 0.8
},
{
"id": 6,
"source": "华为",
"target": "2023年",
"description": "2023年是华为与星河机器人签署合作协议的年份",
"relationship_strength": 0.8
},
{
"id": 7,
"source": "华为",
"target": "合作协议",
"description": "华为与星河机器人签署的合作协议是其研发合作的一部分",
"relationship_strength": 0.9
},
{
"id": 8,
"source": "星河机器人",
"target": "李明",
"description": "李明是星河机器人的创始人,推动公司的研发项目",
"relationship_strength": 1.0
},
{
"id": 9,
"source": "星河机器人",
"target": "类人机器人",
"description": "星河机器人专注于类人机器人的研发,致力于推动这一领域的发展",
"relationship_strength": 0.9
},
{
"id": 10,
"source": "李明",
"target": "类人机器人",
"description": "李明推动了类人机器人的研发项目,代表了技术的进步",
"relationship_strength": 0.8
},
{
"id": 11,
"source": "华为",
"target": "麻省理工学院",
"description": "华为与麻省理工学院在人工智能领域有合作关系,可能涉及技术交流或研究项目",
"relationship_strength": 0.5
},
{
"id": 12,
"source": "中科院自动化研究所",
"target": "王芳",
"description": "王芳是中科院自动化研究所的负责人,负责该机构的研究方向和发展",
"relationship_strength": 1.0
},
{
"id": 13,
"source": "中科院自动化研究所",
"target": "中国",
"description": "中科院自动化研究所的研究与中国的科技发展密切相关",
"relationship_strength": 0.7
},
{
"id": 14,
"source": "中科院自动化研究所",
"target": "北京",
"description": "中科院自动化研究所位于北京,受该城市的科技环境影响",
"relationship_strength": 0.8
},
{
"id": 15,
"source": "王芳",
"target": "中国",
"description": "王芳的研究观点与中国未来的发展方向密切相关",
"relationship_strength": 0.7
},
{
"id": 16,
"source": "中国",
"target": "未来十年",
"description": "未来十年是中国在科技和经济发展方面的重要时期",
"relationship_strength": 0.7
},
{
"id": 17,
"source": "中国",
"target": "王芳",
"description": "王芳在中国的机器人与脑机接口研究领域工作",
"relationship_strength": 0.7
},
{
"id": 18,
"source": "王芳",
"target": "李明",
"description": "王芳与李明在2021年上海的「全球人工智能大会」上曾经同台演讲",
"relationship_strength": 0.6
},
{
"id": 19,
"source": "王芳",
"target": "全球人工智能大会",
"description": "王芳在2021年上海的「全球人工智能大会」上演讲",
"relationship_strength": 0.6
},
{
"id": 20,
"source": "李明",
"target": "全球人工智能大会",
"description": "李明在2021年上海的「全球人工智能大会」上演讲",
"relationship_strength": 0.6
},
{
"id": 21,
"source": "人形机器人",
"target": "医疗康复",
"description": "人形机器人在医疗康复中被应用以加速康复过程",
"relationship_strength": 0.7
},
{
"id": 22,
"source": "人形机器人",
"target": "工业制造",
"description": "人形机器人在工业制造中被应用以提高生产效率",
"relationship_strength": 0.7
},
{
"id": 23,
"source": "星河机器人",
"target": "5G 通讯技术",
"description": "星河机器人使用华为提供的 5G 通讯技术进行类人机器人研发",
"relationship_strength": 0.8
},
{
"id": 24,
"source": "星河机器人",
"target": "昇腾芯片",
"description": "星河机器人使用华为提供的昇腾芯片进行类人机器人研发",
"relationship_strength": 0.8
},
{
"id": 25,
"source": "星河机器人",
"target": "机器人操作系统",
"description": "星河机器人负责开发机器人操作系统用于类人机器人",
"relationship_strength": 0.8
},
{
"id": 26,
"source": "星河机器人",
"target": "感知算法",
"description": "星河机器人负责开发感知算法用于类人机器人",
"relationship_strength": 0.8
},
{
"id": 27,
"source": "中科院自动化研究所",
"target": "脑机接口",
"description": "中科院自动化研究所研究机器人与脑机接口的结合",
"relationship_strength": 0.8
},
{
"id": 28,
"source": "王芳",
"target": "脑机接口",
"description": "王芳推动中科院自动化研究所的脑机接口研究",
"relationship_strength": 0.8
},
{
"id": 29,
"source": "李明",
"target": "人工智能",
"description": "李明在麻省理工学院学习人工智能,奠定了其技术背景",
"relationship_strength": 0.7
},
{
"id": 30,
"source": "王芳",
"target": "神经科学",
"description": "王芳在全球人工智能大会上探讨 AI 与神经科学的交叉应用",
"relationship_strength": 0.6
},
{
"id": 31,
"source": "全球人工智能大会",
"target": "上海",
"description": "全球人工智能大会于2021年在上海举办",
"relationship_strength": 0.7
},
{
"id": 32,
"source": "类人机器人",
"target": "脑机接口",
"description": "类人机器人与脑机接口的研发路线可能汇合以加速技术应用",
"relationship_strength": 0.5
}
]🧑💻 评估代码
这边人工打标的数据是json或者parquet格式,graphrag存储格式:parquet。
核心逻辑:
-
实体比较
-
title+type的比较,注意大家要统一下type的类型,否则得出的结果很差。
-
description描述的比较,一般需要使用向量进行比较,这边代码暂时包含此内容,有兴趣的朋友可以自己添加。
-
核心代码:
pythondef compare_entities(predicted_entities: List[Dict], ground_truth_entities: List[Dict], name_threshold: float = 0.8, type_match_required: bool = True) -> Tuple[float, float, float]: """比较预测实体和真实实体,计算准确率、召回率和F1分数""" # 将实体转换为可比较的格式 predicted_set = set() for entity in predicted_entities: entity_key = (normalize_entity_name(entity.get('title', '')), entity.get('type', '').lower() if type_match_required else '') predicted_set.add(entity_key) ground_truth_set = set() for entity in ground_truth_entities: entity_key = (normalize_entity_name(entity.get('title', '')), entity.get('type', '').lower() if type_match_required else '') ground_truth_set.add(entity_key) # 计算真正例 true_positives = len(predicted_set.intersection(ground_truth_set)) logger.info(f"完全匹配数: {true_positives}") # 计算准确率、召回率和F1分数 precision = true_positives / len(predicted_set) if len(predicted_set) > 0 else 0.0 recall = true_positives / len(ground_truth_set) if len(ground_truth_set) > 0 else 0.0 f1 = calculate_f1_score(precision, recall) return precision, recall, f1
-
-
关系比较
-
关系对source与target的比较,source与target的值可能是对调的,但是我们也认识能识别到这个关系对,如:
source=星河机器人、target=华为与target=星河机器人、source=华为是同一个关系对。 -
description描述的比较,一般需要使用向量进行比较,这边代码暂时包含此内容,有兴趣的朋友可以自己添加。
-
关系的权重比较,如果加上这个就比较严格了,不同模型的出的权重会不一样,根据自己的需求确定是否包含此功能,本代码中没有此功能比较,因为效果会比较差。
-
核心代码:
pythondef compare_relationships(predicted_relationships: List[Dict], ground_truth_relationships: List[Dict], name_threshold: float = 0.8, description_threshold: float = 0.7) -> Tuple[float, float, float]: """比较预测关系和真实关系,计算准确率、召回率和F1分数""" # 简化比较逻辑:基于源实体、目标实体和关系描述的组合 predicted_set = set() for rel in predicted_relationships: normalized = normalize_relationship(rel) rel_key = (normalized['source'], normalized['target']) # 取前50个字符进行比较 predicted_set.add(rel_key) ground_truth_set = set() #我们比较的是关系对,source与target的顺序可能不对,所以在比较的时候包含两个顺序的组合 ground_truth_double_set = set() for rel in ground_truth_relationships: normalized = normalize_relationship(rel) rel_key = (normalized['source'], normalized['target']) rel_desc_key = (normalized['target'],normalized['source']) ground_truth_set.add(rel_key) ground_truth_double_set.add(rel_key) ground_truth_double_set.add(rel_desc_key) #description需要向量的比较 # 计算真正例 true_positives = len(predicted_set.intersection(ground_truth_double_set)) logger.info(f"完全匹配数: {true_positives}") # 计算准确率、召回率和F1分数 precision = true_positives / len(predicted_set) if len(predicted_set) > 0 else 0.0 recall = true_positives / len(ground_truth_set) if len(ground_truth_set) > 0 else 0.0 f1 = calculate_f1_score(precision, recall) return precision, recall, f1
-
-
完整代码:
pythonimport json import logging import os import sys from datetime import datetime from typing import List, Dict, Tuple, Optional import pandas as pd # 配置日志记录,确保UTF-8编码 logging.basicConfig( level=logging.INFO, format='%(message)s', handlers=[ logging.FileHandler('test_qwen_tokenizer_split_text.log', encoding='utf-8'), logging.StreamHandler(sys.stdout) ] ) logger = logging.getLogger(__name__) def read_parquet_file(file_path: str) -> pd.DataFrame: """读取parquet文件并返回DataFrame""" try: logger.info(f"正在读取parquet文件: {file_path}") df = pd.read_parquet(file_path) logger.info(f"成功读取文件,共{len(df)}行数据") return df except Exception as e: logger.error(f"读取文件{file_path}失败: {str(e)}") raise def read_json_file(file_path: str) -> pd.DataFrame: """读取JSON文件并返回DataFrame""" try: logger.info(f"正在读取JSON文件: {file_path}") with open(file_path, 'r', encoding='utf-8') as f: data = json.load(f) df = pd.DataFrame(data) logger.info(f"成功读取文件,共{len(df)}行数据") return df except Exception as e: logger.error(f"读取文件{file_path}失败: {str(e)}") raise def read_file(file_path: str) -> pd.DataFrame: """根据文件扩展名自动选择读取方法""" file_extension = os.path.splitext(file_path)[1].lower() if file_extension == '.parquet': return read_parquet_file(file_path) elif file_extension == '.json': return read_json_file(file_path) else: logger.error(f"不支持的文件格式: {file_extension}") raise ValueError(f"不支持的文件格式: {file_extension}") def normalize_entity_name(entity_name: str) -> str: """标准化实体名称用于比较""" if pd.isna(entity_name): return "" return str(entity_name).strip().lower() def normalize_relationship(rel: Dict) -> Dict: """标准化关系用于比较""" normalized_rel = { 'source': normalize_entity_name(rel.get('source', '')), 'target': normalize_entity_name(rel.get('target', '')), 'description': str(rel.get('description', '')).strip().lower() } return normalized_rel def calculate_f1_score(precision: float, recall: float) -> float: """计算F1分数""" if precision + recall == 0: return 0.0 return 2 * (precision * recall) / (precision + recall) def compare_entities(predicted_entities: List[Dict], ground_truth_entities: List[Dict], name_threshold: float = 0.8, type_match_required: bool = True) -> Tuple[float, float, float]: """比较预测实体和真实实体,计算准确率、召回率和F1分数""" # 将实体转换为可比较的格式 predicted_set = set() for entity in predicted_entities: entity_key = (normalize_entity_name(entity.get('title', '')), entity.get('type', '').lower() if type_match_required else '') predicted_set.add(entity_key) ground_truth_set = set() for entity in ground_truth_entities: entity_key = (normalize_entity_name(entity.get('title', '')), entity.get('type', '').lower() if type_match_required else '') ground_truth_set.add(entity_key) # 计算真正例 true_positives = len(predicted_set.intersection(ground_truth_set)) logger.info(f"完全匹配数: {true_positives}") # 计算准确率、召回率和F1分数 precision = true_positives / len(predicted_set) if len(predicted_set) > 0 else 0.0 recall = true_positives / len(ground_truth_set) if len(ground_truth_set) > 0 else 0.0 f1 = calculate_f1_score(precision, recall) return precision, recall, f1 def compare_relationships(predicted_relationships: List[Dict], ground_truth_relationships: List[Dict], name_threshold: float = 0.8, description_threshold: float = 0.7) -> Tuple[float, float, float]: """比较预测关系和真实关系,计算准确率、召回率和F1分数""" # 简化比较逻辑:基于源实体、目标实体和关系描述的组合 predicted_set = set() for rel in predicted_relationships: normalized = normalize_relationship(rel) rel_key = (normalized['source'], normalized['target']) # 取前50个字符进行比较 predicted_set.add(rel_key) ground_truth_set = set() #我们比较的是关系对,source与target的顺序可能不对,所以在比较的时候包含两个顺序的组合 ground_truth_double_set = set() for rel in ground_truth_relationships: normalized = normalize_relationship(rel) rel_key = (normalized['source'], normalized['target']) rel_desc_key = (normalized['target'],normalized['source']) ground_truth_set.add(rel_key) ground_truth_double_set.add(rel_key) ground_truth_double_set.add(rel_desc_key) #description需要向量的比较 # 计算真正例 true_positives = len(predicted_set.intersection(ground_truth_double_set)) logger.info(f"完全匹配数: {true_positives}") # 计算准确率、召回率和F1分数 precision = true_positives / len(predicted_set) if len(predicted_set) > 0 else 0.0 recall = true_positives / len(ground_truth_set) if len(ground_truth_set) > 0 else 0.0 f1 = calculate_f1_score(precision, recall) return precision, recall, f1 def evaluate_entity_relation(predicted_entities_file: str, predicted_relationships_file: str, ground_truth_entities_file: Optional[str] = None, ground_truth_relationships_file: Optional[str] = None, output_dir: str = "./evaluation_results") -> Dict: """ 评估实体和关系的提取质量 参数: - predicted_entities_file: 预测实体的文件路径(支持parquet和json格式) - predicted_relationships_file: 预测关系的文件路径(支持parquet和json格式) - ground_truth_entities_file: 真实实体的文件路径(可选,支持parquet和json格式) - ground_truth_relationships_file: 真实关系的文件路径(可选,支持parquet和json格式) - output_dir: 评估结果输出目录 返回: - 包含评估指标的字典 """ # 创建输出目录 os.makedirs(output_dir, exist_ok=True) # 读取预测数据 predicted_entities_df = read_file(predicted_entities_file) predicted_relationships_df = read_file(predicted_relationships_file) # 转换为字典列表 predicted_entities = predicted_entities_df.to_dict('records') predicted_relationships = predicted_relationships_df.to_dict('records') evaluation_results = { 'timestamp': datetime.now().isoformat(), 'predicted_entities_count': len(predicted_entities), 'predicted_relationships_count': len(predicted_relationships), 'entity_types': list(predicted_entities_df['type'].unique()) if 'type' in predicted_entities_df.columns else [], } # 如果提供了真实标签数据,进行对比评估 if ground_truth_entities_file and ground_truth_relationships_file: # 读取真实数据 ground_truth_entities_df = read_file(ground_truth_entities_file) ground_truth_relationships_df = read_file(ground_truth_relationships_file) # 转换为字典列表 ground_truth_entities = ground_truth_entities_df.to_dict('records') ground_truth_relationships = ground_truth_relationships_df.to_dict('records') # 评估实体提取 entity_precision, entity_recall, entity_f1 = compare_entities( predicted_entities, ground_truth_entities ) # 评估关系提取 rel_precision, rel_recall, rel_f1 = compare_relationships( predicted_relationships, ground_truth_relationships ) # 添加评估指标到结果 evaluation_results.update({ 'has_ground_truth': True, 'ground_truth_entities_count': len(ground_truth_entities), 'ground_truth_relationships_count': len(ground_truth_relationships), 'entity_precision': entity_precision, 'entity_recall': entity_recall, 'entity_f1': entity_f1, 'relationship_precision': rel_precision, 'relationship_recall': rel_recall, 'relationship_f1': rel_f1 }) logger.info(f"实体评估结果 - 精确率: {entity_precision:.4f}, 召回率: {entity_recall:.4f}, F1分数: {entity_f1:.4f}") logger.info(f"关系评估结果 - 精确率: {rel_precision:.4f}, 召回率: {rel_recall:.4f}, F1分数: {rel_f1:.4f}") else: # 如果没有真实标签,提供基本统计信息作为自评估 evaluation_results['has_ground_truth'] = False # 分析实体类型分布 if 'type' in predicted_entities_df.columns: entity_type_counts = predicted_entities_df['type'].value_counts().to_dict() evaluation_results['entity_type_distribution'] = entity_type_counts # 分析关系强度分布(如果有) if 'relationship_strength' in predicted_relationships_df.columns: strength_stats = { 'mean': float(predicted_relationships_df['relationship_strength'].mean()), 'median': float(predicted_relationships_df['relationship_strength'].median()), 'min': float(predicted_relationships_df['relationship_strength'].min()), 'max': float(predicted_relationships_df['relationship_strength'].max()) } evaluation_results['relationship_strength_stats'] = strength_stats logger.info("没有提供真实标签数据,仅生成统计信息") # 保存评估结果 output_file = os.path.join(output_dir, f"evaluation_result_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json") with open(output_file, 'w', encoding='utf-8') as f: json.dump(evaluation_results, f, ensure_ascii=False, indent=2) logger.info(f"评估结果已保存到: {output_file}") # 生成详细报告 report_file = os.path.join(output_dir, f"evaluation_report_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt") generate_report(evaluation_results, report_file) return evaluation_results def generate_report(results: Dict, output_file: str) -> None: """生成人类可读的评估报告""" with open(output_file, 'w', encoding='utf-8') as f: f.write("===================== 实体关系评估报告 =====================\n") f.write(f"评估时间: {results['timestamp']}\n\n") f.write("===== 基本统计信息 =====\n") f.write(f"预测实体数量: {results['predicted_entities_count']}\n") f.write(f"预测关系数量: {results['predicted_relationships_count']}\n") if 'entity_types' in results and results['entity_types']: f.write(f"实体类型: {', '.join(results['entity_types'])}\n") f.write("\n") if results.get('has_ground_truth', False): f.write("===== 与真实标签对比结果 =====\n") f.write(f"真实实体数量: {results['ground_truth_entities_count']}\n") f.write(f"真实关系数量: {results['ground_truth_relationships_count']}\n\n") f.write("实体提取评估:\n") f.write(f" 精确率 (Precision): {results['entity_precision']:.4f}\n") f.write(f" 召回率 (Recall): {results['entity_recall']:.4f}\n") f.write(f" F1 分数 (F1-Score): {results['entity_f1']:.4f}\n\n") f.write("关系提取评估:\n") f.write(f" 精确率 (Precision): {results['relationship_precision']:.4f}\n") f.write(f" 召回率 (Recall): {results['relationship_recall']:.4f}\n") f.write(f" F1 分数 (F1-Score): {results['relationship_f1']:.4f}\n") else: f.write("===== 自评估统计信息 =====\n") f.write("注意: 没有提供真实标签数据,以下为统计信息分析\n\n") if 'entity_type_distribution' in results: f.write("实体类型分布:\n") for entity_type, count in results['entity_type_distribution'].items(): percentage = (count / results['predicted_entities_count']) * 100 f.write(f" {entity_type}: {count} ({percentage:.1f}%)\n") f.write("\n") if 'relationship_strength_stats' in results: stats = results['relationship_strength_stats'] f.write("关系强度统计:\n") f.write(f" 平均值: {stats['mean']:.2f}\n") f.write(f" 中位数: {stats['median']:.2f}\n") f.write(f" 最小值: {stats['min']:.2f}\n") f.write(f" 最大值: {stats['max']:.2f}\n") f.write("\n===================== 评估报告结束 =====================\n") logger.info(f"评估报告已保存到: {output_file}") def batch_evaluate(dataset_dir: str, output_dir: str = "./evaluation_results") -> None: """ 批量评估多个数据集 参数: - dataset_dir: 包含多个数据集的目录 - output_dir: 评估结果输出目录 """ logger.info(f"开始批量评估数据集,目录: {dataset_dir}") # 支持的文件格式 supported_formats = ['.parquet', '.json'] # 遍历目录中的所有子目录 for subdir in os.listdir(dataset_dir): subdir_path = os.path.join(dataset_dir, subdir) if not os.path.isdir(subdir_path): continue logger.info(f"评估数据集: {subdir}") # 查找实体和关系文件(支持多种格式) entities_file = None relationships_file = None # 先检查parquet格式,然后是json格式 for ext in supported_formats: # 查找实体文件 if entities_file is None: potential_entities = os.path.join(subdir_path, f"entities{ext}") if os.path.exists(potential_entities): entities_file = potential_entities # 查找关系文件 if relationships_file is None: potential_relationships = os.path.join(subdir_path, f"relationships{ext}") if os.path.exists(potential_relationships): relationships_file = potential_relationships # 如果两种文件都找到了,就停止查找 if entities_file is not None and relationships_file is not None: break # 检查文件是否存在 if not entities_file or not relationships_file: logger.warning(f"数据集 {subdir} 缺少必要的实体或关系文件(支持的格式:{', '.join(supported_formats)}),跳过评估") continue logger.info(f"发现实体文件: {entities_file}") logger.info(f"发现关系文件: {relationships_file}") # 创建该数据集的输出目录 dataset_output_dir = os.path.join(output_dir, subdir) os.makedirs(dataset_output_dir, exist_ok=True) # 执行评估 try: evaluate_entity_relation( entities_file, relationships_file, output_dir=dataset_output_dir ) except Exception as e: logger.error(f"评估数据集 {subdir} 失败: {str(e)}") logger.info("批量评估完成") if __name__ == "__main__": # 示例用法 import argparse parser = argparse.ArgumentParser(description="实体和关系提取评估工具") parser.add_argument("--entities", help="实体数据文件路径(支持parquet和json格式)") parser.add_argument("--relationships", help="关系数据文件路径(支持parquet和json格式)") parser.add_argument("--ground-truth-entities", help="真实实体数据文件路径(可选,支持parquet和json格式)") parser.add_argument("--ground-truth-relationships", help="真实关系数据文件路径(可选,支持parquet和json格式)") parser.add_argument("--output-dir", default="./evaluation_results", help="评估结果输出目录") parser.add_argument("--batch", help="批量评估模式,指定包含多个数据集的目录") args = parser.parse_args() if args.batch: # 批量评估模式 batch_evaluate(args.batch, args.output_dir) else: # 单数据集评估模式 if not args.entities or not args.relationships: parser.error("单数据集评估模式必须提供--entities和--relationships参数") evaluate_entity_relation( args.entities, args.relationships, args.ground_truth_entities, args.ground_truth_relationships, args.output_dir ) -
测试代码:
pythonimport os import sys from entity_relation_evaluator import evaluate_entity_relation import logging # 配置日志记录,确保UTF-8编码 logging.basicConfig( level=logging.INFO, format='%(message)s', handlers=[ logging.FileHandler('test_qwen_tokenizer_split_text.log', encoding='utf-8'), logging.StreamHandler(sys.stdout) ] ) logger = logging.getLogger(__name__) def main(): """测试读取JSON格式的真实数据文件并进行评估""" # 定义文件路径 current_dir = os.path.dirname(os.path.abspath(__file__)) # 使用demo_data目录中的预测数据(parquet格式) predicted_entities_file = os.path.join(current_dir,"..", "..", "collaboration","gpt","output", "entities.parquet") predicted_relationships_file = os.path.join(current_dir, "..", "..", "collaboration","gpt","output", "relationships.parquet") # 使用target目录中的真实数据(JSON格式) ground_truth_entities_file = os.path.join(current_dir, "..", "..", "target", "entities.json") ground_truth_relationships_file = os.path.join(current_dir, "..", "..", "target", "relationships.json") # 输出目录 output_dir = os.path.join(current_dir, "demo_json_results") # 检查文件是否存在 for file_path in [predicted_entities_file, predicted_relationships_file, ground_truth_entities_file, ground_truth_relationships_file]: if not os.path.exists(file_path): logger.info(f"错误: 文件不存在: {file_path}") return try: # 执行评估 logger.info(f"开始评估实体和关系提取质量...") logger.info(f"预测实体文件: {predicted_entities_file}") logger.info(f"预测关系文件: {predicted_relationships_file}") logger.info(f"真实实体文件: {ground_truth_entities_file}") logger.info(f"真实关系文件: {ground_truth_relationships_file}") evaluation_results = evaluate_entity_relation( predicted_entities_file=predicted_entities_file, predicted_relationships_file=predicted_relationships_file, ground_truth_entities_file=ground_truth_entities_file, ground_truth_relationships_file=ground_truth_relationships_file, output_dir=output_dir ) # 打印评估结果 logger.info("\n评估结果摘要:") logger.info(f"- 预测实体数量: {evaluation_results['predicted_entities_count']}") logger.info(f"- 预测关系数量: {evaluation_results['predicted_relationships_count']}") logger.info(f"- 真实实体数量: {evaluation_results['ground_truth_entities_count']}") logger.info(f"- 真实关系数量: {evaluation_results['ground_truth_relationships_count']}") logger.info(f"- 实体F1分数: {evaluation_results['entity_f1']:.4f}") logger.info(f"- 关系F1分数: {evaluation_results['relationship_f1']:.4f}") logger.info(f"\n完整评估结果已保存到: {output_dir}") except Exception as e: logger.info(f"评估过程中发生错误: {str(e)}") import traceback traceback.print_exc() if __name__ == "__main__": main()把
predicted_entities_file、predicted_relationships_file、ground_truth_entities_file、ground_truth_relationships_file改成自己文件的对应的路径,然后执行即可。
🥫graphrag生成的实体
graphrag具体的部署与运行请参考GraphRAG:让 RAG 更聪明的一种新玩法部分,这边补充下本文测试的对应的配置:
模型:
default_chat_model:gpt-4o-mini
default_embedding_model:BAAI/bge-m3
encoding_model:cl100k_base
文件分割配置:
yaml
chunks:
size: 50
overlap: 10🎉 运行结果示例

🔍 小结 & Tips
- 图数据质量是 GraphRAG 的命脉:坏数据=坏答案。
- 先查数据质量,再调模型,省时省力还显专业。
- 长期方案:
- 建立自动化质量监控
- 引入别名归一化 与版本管理
- 定期清理和更新图谱
🎯 一句话总结 :想让你的 GraphRAG 不再"答非所问"?先从图数据质量评估开始吧,让你的知识图谱稳得像"地基打得牢"的摩天大楼!