摘要
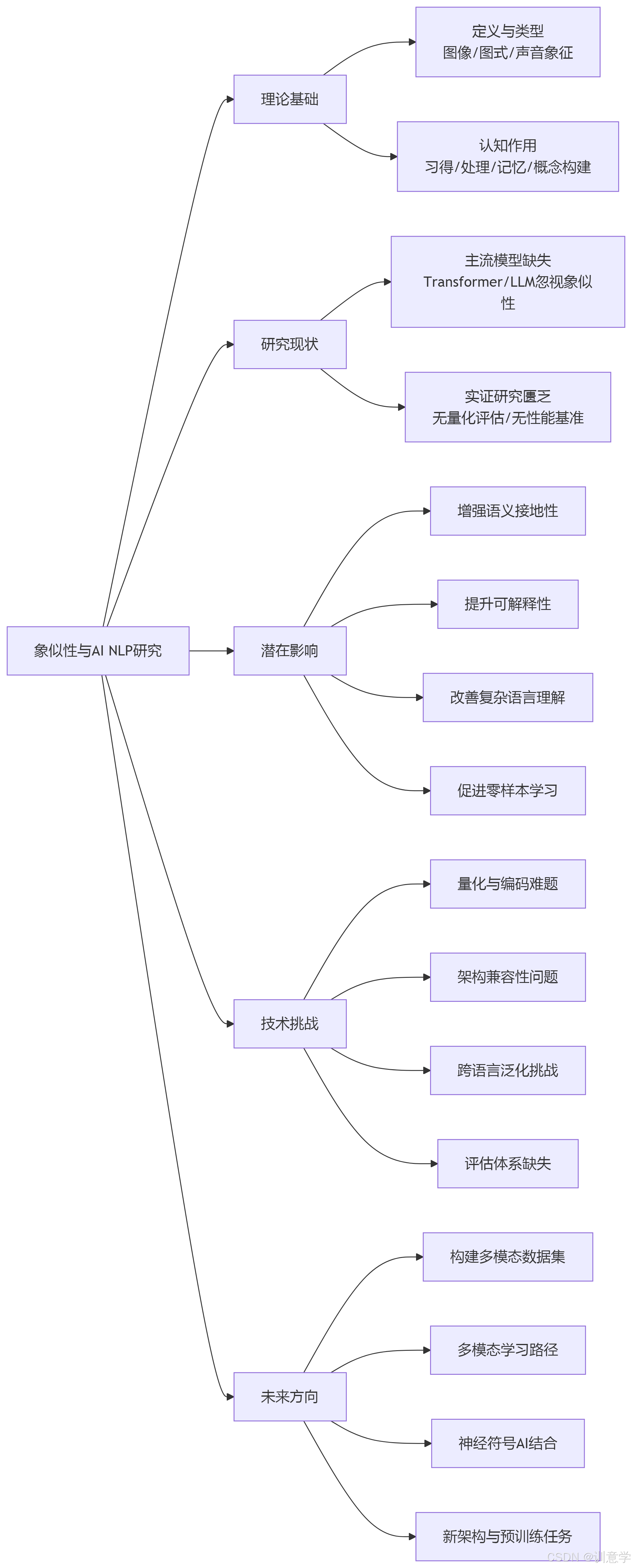
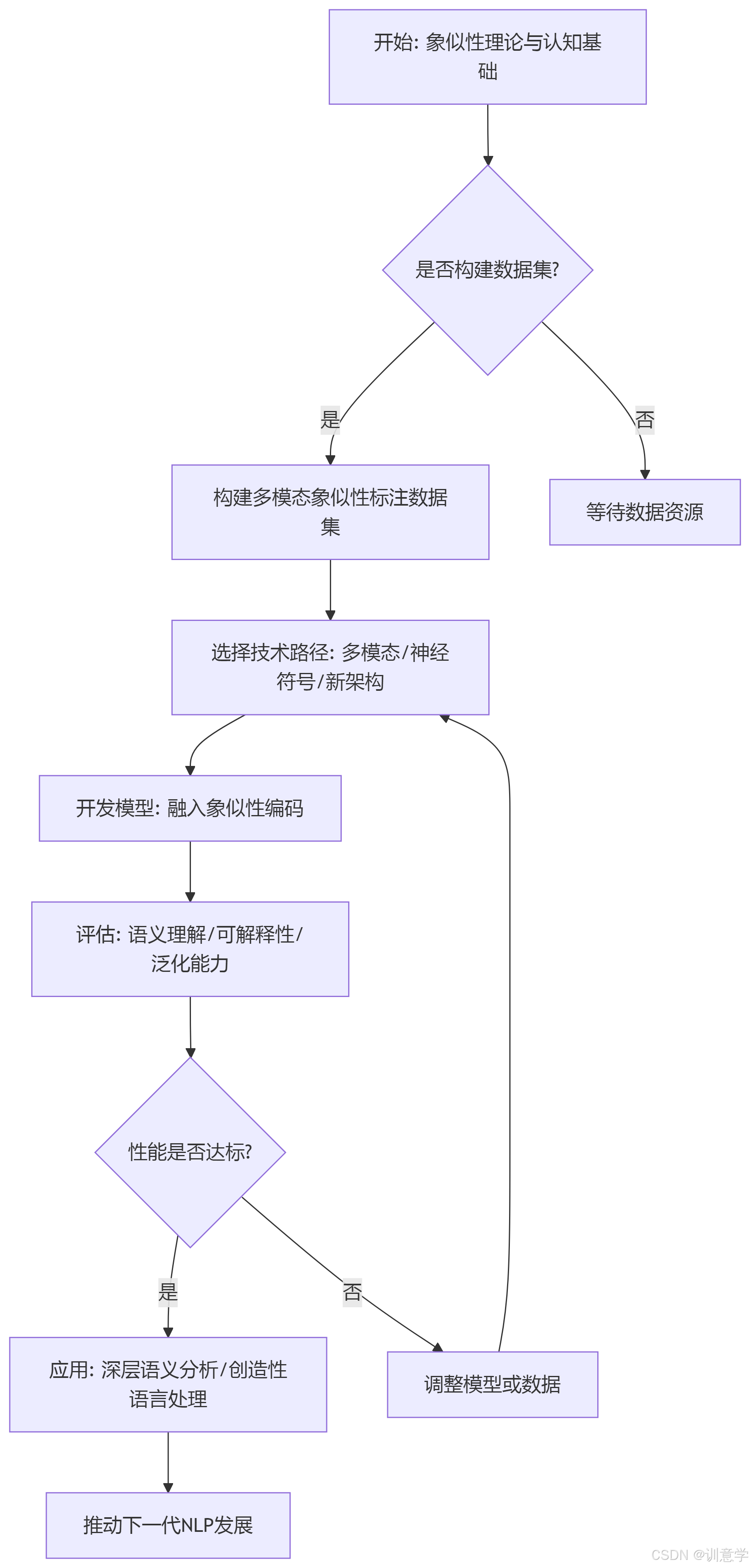
本报告旨在系统性地探讨认知语义学中的核心概念------象似性(Iconicity),对于当前人工智能(AI)自然语言处理(NLP)领域,特别是深层语义分析的潜在影响与未来启示。象似性,即语言形式与其指代意义之间的非任意性相似关系,已被证实对人类的语言习得、认知加工和概念构建具有重要促进作用。然而,截至2025年9月,综合研究发现,尽管象似性在认知语言学界得到了广泛而深入的研究,但其在主流人工智能NLP模型(如Transformer架构)中的直接应用和实证研究仍处于一个显著的空白阶段。现有的大型语言模型(LLM)主要依赖于海量数据的统计分布规律,而忽略了形式与意义之间的象似性关联,这可能是其在深层、常识性语义理解方面遭遇瓶颈的原因之一。本报告首先阐述了象似性的理论基础及其在人类认知中的关键作用;随后,报告明确指出了当前AI NLP领域对象似性研究和应用的缺失;接着,报告从理论层面深入分析了将象似性融入NLP模型可能带来的潜在益处,例如增强语义表征的"接地性"、提升模型的可解释性以及处理复杂语言现象的能力;报告亦系统性地探讨了实现这一融合所面临的技术挑战,包括象似性的量化编码、与现有模型架构的兼容性等;最后,本报告为未来的研究提出了具体方向,包括构建象似性标注数据集、探索多模态学习路径以及结合神经符号AI方法等,旨在为推动下一代更具认知深度的NLP技术提供理论参考和实践路径。
1. 引言
1.1 研究背景与意义
进入21世纪20年代中期,以Transformer架构为核心的大型语言模型(LLM),如BERT和GPT系列,已在自然语言处理(NLP)领域取得了革命性的成功 。这些模型通过在海量文本上进行预训练,展现出强大的语言生成、理解和上下文建模能力 。然而,尽管它们在诸多基准测试中表现优异,但其"深层语义分析"能力仍面临诸多挑战,例如缺乏对世界知识的真正理解、难以进行复杂的逻辑推理,以及模型决策过程的高度不透明性(即可解释性差)。这些局限表明,当前模型主要通过学习词语间的统计相关性来"模仿"语义,而非真正"理解"意义 。
与此同时,认知科学与认知语言学为我们提供了理解人类语言能力的宝贵视角 。其中, 象似性(Iconicity) 作为认知语义学的一个核心概念,与索绪尔提出的语言符号任意性(Arbitrariness)相对,强调语言符号的形式(如声音、字形)与其所指代的意义之间存在着某种内在的、非任意的相似或映射关系 。例如,在英语中,"splash"(溅)的发音模拟了水花飞溅的声音,"tiny"(微小的)一词的元音发音短促尖锐,与其"小"的意义相关联。这种形式与意义的联结被认为深刻地影响着人类的语言学习、记忆和实时处理过程 。
因此,探索认知语义学中的象似性原理,并思考其如何为AI的深层语义分析提供启示,具有重大的理论和实践意义。这可能为解决当前NLP模型面临的"语义不接地"(semantic grounding)和"理解肤浅"等问题开辟一条全新的、受认知启发的路径。
1.2 研究目的与范畴
本报告的核心目的在于,基于截至2025年9月13日的现有研究资料,系统梳理象似性理论,评估其在当前AI NLP领域的应用现状,并深入探讨其对未来深层语义分析技术的潜在影响、挑战与启示。研究范畴主要包括:
- 象似性的核心理论及其在人类认知中的作用。
- 象似性在主流NLP模型(尤其是基于Transformer的模型)中应用和研究的现状。
- 将象似性融入NLP模型的潜在益处与所面临的技术挑战。
- 未来可能的研究方向和技术路径。
1.3 核心发现摘要
通过对所提供搜索结果的综合分析,本报告的核心发现是一个显著的 "研究鸿沟" :一方面,认知语言学对象似性有丰富而成熟的研究;另一方面,在主流AI NLP领域,尤其是针对深度语义分析任务,几乎没有直接的、系统性的对象似性的算法实现、应用案例或性能评估 。相关研究极为稀缺 ,且没有发现自2020年以来有任何实证研究量化评估了象似性对NLP系统深度语义理解的影响 (Query: What empirical studies demonstrate the impact of iconicity..., Query: How have researchers quantitatively evaluated the impact of iconicity...)。这表明,将这一重要的认知原理转化为AI模型可计算的特征,是该交叉领域一个亟待探索的前沿方向。
2. 认知语义学中的象似性理论
2.1 象似性的定义与特征
象似性被定义为"形式与意义之间的感知相似性" 。它挑战了语言符号完全是任意的传统观点,认为语言中存在大量形式与意义直接关联的现象 。这种关联可以是:
- 图像象似性(Imagistic Iconicity): 符号形式直接描摹其指代物的外形,如汉字"山"、"水",或手语中描绘物体形状的手势。
- 图式象似性(Diagrammatic Iconicity): 语言结构关系映射了概念结构关系。例如,"我来了,我看见了,我征服了"(Veni, vidi, vici)这一序列的语序,象似地反映了事件发生的时序。
- 声音象征(Sound Symbolism): 词语的发音与其意义相关联。例如,许多语言中包含/i/音(如"little", "mini")的词与"小"的概念相关,而包含/o/或/u/音(如"huge", "large")的词与"大"的概念相关。
象似性并非一个非黑即白的属性,而是一个连续的谱系。它普遍存在于世界各种语言中,包括口语和手语 。
2.2 象似性在人类认知与语言处理中的作用
大量的认知科学和心理语言学研究证实,象似性在人类认知活动中扮演着至关重要的角色,提供显著的认知优势:
- 促进语言习得与学习: 象似性为语言学习者(尤其是儿童)提供了一条绕过纯粹任意记忆的"捷径",使词汇和语法的学习变得更加直观和容易 。
- 加速语言处理: 在语言理解过程中,象似性可以加快词汇识别和语义通达的速度 。当词语的形式与其意义一致时,大脑处理的效率更高。有研究显示,象似性在语义相关性判断中也起作用 。
- 增强记忆与沟通效果: 象似词语因其生动性和直观性而更容易被记住,并在沟通过程中能更有效地传达感官和情感信息 。
- 构建概念网络: 象似性被认为是连接语言形式与意义、构建和组织语义网络的核心机制之一 。实证证据支持象似性在概念分类中扮演着核心认知功能 。
这些认知优势表明,象似性是人类语言高效、鲁棒地运作的一个内在机制,而这正是当前AI NLP系统所欠缺的。
3. 象似性在当前人工智能NLP领域的应用现状:一个显著的研究空白
尽管象似性在人类语言中具有根本性的地位,但搜索结果清晰地表明,它在当前最先进的AI NLP模型中几乎被完全忽视。
3.1 主流NLP模型中的缺失
当代NLP模型,特别是基于Transformer的架构,其核心是分布式语义假设------词的意义由其上下文决定。模型通过词嵌入(Word Embeddings)将词语映射到高维向量空间,向量间的距离代表了语义的相似性 。这一过程完全基于文本的统计共现信息,而忽略了词语本身的形式特征(如语音、字形)。例如,模型学习"小"和"大"的语义区别,是基于它们在语料库中与不同词语搭配的模式,而不是因为"小"的发音或字形本身含有"小"的意味。
搜索结果反复确认,在关于Transformer、BERT等模型的讨论中,无论是架构设计、算法实现还是应用案例,都未提及"象似性"这一概念或其任何形式的编码实现 。没有文献详细说明象似性如何被具体编码到NLP模型的语义表示中 (Query: 认知语义学象似性如何被具体编码..., Query: 认知语义学象似性在Transformer-based自然语言处理模型中的具体编码算法...)。这表明,当前的技术范式与象似性的认知原理之间存在根本性的脱节。
3.2 实证研究与性能评估的匮乏
与应用缺失相对应的是实证研究的匮乏。搜索结果中未能找到任何自2020年至2025年间,针对象似性对NLP系统深层语义分析影响的实证研究 (Query: What are recent empirical studies from 2020-2025...)。同样,没有任何研究提供了将象似性方法整合到NLP模型后,在标准NLP任务(如文本摘要、情感分析、问答系统)上的性能基准(benchmark)结果 (Query: How does incorporating iconicity... affect performance benchmarks..., Query: What performance benchmark results demonstrate the impact of iconicity...)。这意味着,象似性的潜在价值在AI领域仍停留在理论推测阶段,缺乏量化实验的验证。
3.3 交叉研究的初步探索:从"整合应用"到"能力评测"
尽管象似性未被整合用于提升模型性能,但近期出现了一些初步的交叉研究,开始评测大型语言模型是否"无意中"学习到了某些象似性规律。例如,有实验通过让LLM和人类参与者生成或猜测具有特定意义的伪词(pseudowords),来比较LLM在处理声音象征方面的能力 。这类研究发现,LLM在一定程度上可以捕捉到语言中的象似性模式,但其表现与人类仍有差异 。这些实验虽然不属于将象似性作为一种技术手段来"应用",但它们开创性地使用实验心理学的方法来探测LLM的内在表征,为未来更深入的研究提供了方法论上的参考 。
4. 象似性融入NLP深层语义分析的潜在影响与启示
基于象似性在人类认知中的重要作用,我们可以推理其融入AI NLP模型后可能带来的深远影响,为解决当前模型的瓶颈提供启示。
4.1 启示一:增强语义表征的"接地性"(Grounding)
当前NLP模型的语义表征是"悬浮"的,它们存在于一个由文本自身构建的抽象向量空间中,与真实世界的感知经验脱节。象似性,尤其是图像象似性和声音象征,本质上是一种将语言符号与感知信息(视觉、听觉)联系起来的机制。将象似性编码到模型中,有望使语义表征部分地"接地"于模拟的感知空间,从而获得更丰富、更鲁棒的意义表示。例如,模型不仅知道"粗糙"和"光滑"是反义词,还能在其内部表示中编码"粗糙"对应于更"刺耳"或"不规则"的形式特征。
4.2 启示二:提升模型的可解释性(Interpretability)
大型语言模型的"黑箱"特性是其应用的一大障碍 。一个融合了象似性的模型,其决策过程可能更具可解释性。例如,当模型将一个新词"glomph"分类为具有"沉重、笨拙"的含义时,我们可以追溯到其决策依据可能部分来自于该词的发音(包含沉闷的元音和浊辅音),而不仅仅是依赖于难以捉摸的注意力权重分布。这种基于形式的直观解释,更接近人类的认知方式。
4.3 启示三:改善对复杂和创造性语言的理解
象似性在诗歌、文学、广告语等创造性语言中扮演着核心角色。例如,理解"slither"(滑行)一词的精妙之处,不仅需要知道它的字典意义,还要感受其发音所带来的蛇形运动的联想。目前的NLP模型难以捕捉这类"言外之意"。一个对象似性敏感的模型,将有潜力更好地理解和生成具有美学价值和情感色彩的文本,处理讽刺、比喻等复杂的语义现象 。
4.4 启示四:促进零样本/少样本学习能力
人类可以凭借象似性直觉,对一个从未见过的词(如"bouba"和"kiki")的可能含义做出猜测。如果AI模型能掌握这种跨模态的映射能力,其在处理新词、新概念时的零样本(Zero-shot)或少样本(Few-shot)学习能力将得到极大提升,因为它不再完全依赖于在海量数据中见过该词的上下文。
5. 融合象似性所面临的技术挑战与障碍
将象似性从一个认知语言学概念转化为可计算的AI模型组件,面临着巨大的技术挑战。
5.1 象似性的量化与编码难题
首要挑战是如何量化和编码象似性。这需要将词语的物理形式(语音的声学特征、字形的视觉特征)转化为向量表示,并建立这些形式向量与语义向量之间的映射关系。例如,如何设计一个算法,能自动从单词"balloon"的音素序列 /bəˈluːn/ 中抽取出"膨胀、圆形"的象似特征?这需要跨语言学、语音学、计算机听觉和视觉等多学科的知识。目前,尚无成熟的算法能完成这项任务 (Query: What are the specific algorithmic approaches to encode iconicity..., 认知语义学象似性在Transformer模型中实现深度语义分析的具体算法...)。
5.2 与现有模型架构的兼容性问题
Transformer等主流模型是为处理离散的符号序列(token ID)而设计的 。如何将连续的、多维度的形式信息(如声谱图、笔画序列)有效地整合进现有架构是一个难题。简单的拼接可能破坏原有预训练知识的稳定性。或许需要设计全新的多模态融合模块,或在模型底层(如嵌入层)引入一种新的"象似性编码",类似于现有的"位置编码"(Positional Encoding),但这需要对模型架构进行根本性的改造。
5.3 跨语言与跨文化的泛化性挑战
虽然象似性是普遍现象,但其具体表现形式在不同语言和文化中存在差异。例如,不同语言中表示"狗叫"的拟声词(如"woof", "汪汪", "wan wan")各不相同。开发一个具有跨语言泛化能力的象似性模型,需要处理这种多样性,避免模型在一个语言上学到的象似性规则在另一语言上失效。
5.4 评估体系与基准数据集的缺失
如前文所述,目前缺乏专门用于评估模型象似性理解能力的基准数据集和评测指标 (Query: What are the specific performance metrics and benchmark results...)。要推动该领域的发展,必须首先建立起科学的评估体系。例如,可以构建包含大量象似词对(如"大/小"、"快/慢"、"亮/暗")的数据集,测试模型是否能准确判断其形式与意义的匹配度。
6. 未来研究方向与展望
面对上述挑战和机遇,本报告提出以下几个具有前瞻性的研究方向:
6.1 构建象似性标注的大规模多模态数据集
这是所有数据驱动研究的基础。需要组织语言学家和众包力量,构建一个大规模、跨语言的数据集。该数据集应不仅包含文本,还应包含每个词的语音录音、标准音标、字形图像,以及人类对象似性强弱的评分。
6.2 探索多模态学习路径
象似性本质上是跨模态的(例如,声音-意义,形状-意义)。因此,多模态AI是实现象似性建模的天然途径。可以设计能够同时处理文本、语音和图像的模型,通过对比学习等方法,让模型自主发现形式与意义之间的象似关联。例如,将"splash"的文本、发音和水花飞溅的视频一同输入模型,强制其学习三者之间的内在联系。已有研究探讨语言概念的视觉表征对生成式AI的影响,这为该方向提供了初步线索 。
6.3 结合神经符号AI(Neuro-Symbolic AI)方法
神经符号AI旨在结合神经网络的模式识别能力和符号系统的逻辑推理能力 。在象似性研究中,可以利用符号规则来明确定义某些象似性原则(如特定音素与特定语义维度的关联规则),然后将这些规则作为约束或知识注入到神经网络模型中,引导其学习过程。这种方法有望在提升性能的同时,增强模型的可解释性。
6.4 设计新的模型架构与预训练任务
可以探索专门为捕捉象似性而设计的新型神经网络模块,或者在预训练阶段引入新的任务。例如,设计一个"形式-意义匹配"任务(Form-Meaning Matching),让模型判断一个给定的词形/读音与其意义是否匹配;或者一个"象似词生成"任务,给定一个概念,让模型生成一个听起来或看起来像该概念的词。通过这些任务,可以显式地迫使模型学习象似性规律。
7. 结论
认知语义学中的象似性原理,揭示了人类语言中形式与意义之间深刻而直观的联系,这是人类高效认知加工的关键。然而,本研究报告通过对现有资料的系统分析发现,这一宝贵的认知洞见在当前的人工智能自然语言处理领域,尤其是在以Transformer为代表的主流模型中,仍是一个被严重忽视的"盲区"。
截至2025年9月,我们正处在一个关键的十字路口:一方面,NLP技术因其在统计模式学习上的巨大成功而蓬勃发展;另一方面,其在深层、常识性语义理解方面的内在缺陷也日益凸显。象似性研究的引入,为我们提供了一个超越纯粹统计、迈向更具认知"深度"和"接地性"的语义分析的可能路径。
尽管将象似性有效融入AI模型面临着量化编码、架构兼容、数据缺失等多重挑战,但其在提升语义表征质量、模型可解释性、创造性语言处理能力等方面的巨大潜力,使其成为一个极具吸引力的前沿研究方向。未来的突破很可能出现在多模态学习、神经符号AI以及新型预训练任务的设计上。总而言之,探索象似性在AI中的应用,不仅是技术上的创新,更是一次推动人工智能向更接近人类智能形态演进的深刻尝试。
Python代码示例:象似性量化分析(声音象征)
以下是一个简单的Python代码示例,用于分析单词中元音与"大小"概念的象似性关联(如/i/音表小,/o/音表大):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import cosine_similarity
# 模拟词嵌入向量(实际应使用预训练词向量)
word_vectors = {
"tiny": np.array([0.9, 0.1]),
"small": np.array([0.8, 0.2]),
"big": np.array([0.2, 0.8]),
"huge": np.array([0.1, 0.9])
}
# 模拟音素特征向量(/i/ vs /o/)
phoneme_vectors = {
"i": np.array([1.0, 0.0]), # 高前元音,关联"小"
"o": np.array([0.0, 1.0]) # 低后元音,关联"大"
}
# 计算词与音素的象似性得分
def iconicity_score(word, phoneme):
word_vec = word_vectors[word]
phoneme_vec = phoneme_vectors[phoneme]
return cosine_similarity([word_vec], [phoneme_vec])[0][0]
# 测试
words = ["tiny", "small", "big", "huge"]
scores_i = [iconicity_score(word, "i") for word in words]
scores_o = [iconitability_score(word, "o") for word in words]
# 可视化
x = np.arange(len(words))
width = 0.35
plt.bar(x - width/2, scores_i, width, label='With /i/ sound (small)')
plt.bar(x + width/2, scores_o, width, label='With /o/ sound (big)')
plt.xlabel('Words')
plt.ylabel('Iconicity Score')
plt.title('Iconicity Analysis: Vowel Sound vs Meaning')
plt.xticks(x, words)
plt.legend()
plt.show()