在现代数据库管理系统(如MySQL InnoDB、PostgreSQL、Oracle等)中,MVCC(Multi-Version Concurrency Control,多版本并发控制) 是实现高性能事务处理的核心技术之一。它巧妙地解决了数据库领域一个经典难题:如何最大化地实现读写并发,同时避免不必要的阻塞,保证事务的隔离性? 理解MVCC,是深入理解数据库如何工作的关键。
一、MVCC要解决什么问题?
在传统的基于锁的并发控制(如简单的行锁)中,读写操作之间会相互阻塞:
-
读-写阻塞:一个事务正在写某行数据时,会加锁,其他读事务必须等待写锁释放。
-
写-读阻塞:一个事务正在读某行数据时,也会阻止其他事务修改该行数据。
这种阻塞会严重限制数据库的并发性能。MVCC的设计目标就是消除纯粹的读操作与写操作之间的相互阻塞 ,使得读不阻塞写,写也不阻塞读,从而大幅提升数据库的并发处理能力。
二、MVCC的核心思想
MVCC的核心思想非常直观:为数据项创建多个版本。
-
当需要修改一条记录时,MVCC不会直接覆盖原有数据,而是创建该记录的一个新版本。
-
每个数据版本都会有一个生命周期,由两个关键属性来标识(具体名称因数据库而异):
-
创建版本号:创建该数据版本的事务ID(或系统版本号)。
-
删除版本号:删除该数据版本的事务ID(或系统版本号)。如果为NULL,则表示该版本尚未被删除。
-
-
在读 操作时,数据库会根据当前事务的隔离级别 和开始时间 ,从多个版本中挑选出对其可见的那个版本(通常是事务开始前已提交的最新版本)来返回。
-
在写操作时,创建新版本,并标记其创建版本号。
通过这种方式,读操作不再需要申请读锁,因为它总可以找到一个合适的、已经提交的旧版本数据来读取,从而不会阻碍写操作去创建新的数据版本。
三、MVCC的关键实现机制:以InnoDB为例
不同的数据库实现MVCC的细节不同,但思想相通。我们以最常用的MySQL InnoDB引擎为例,剖析其实现细节。
1. 必需的隐藏字段
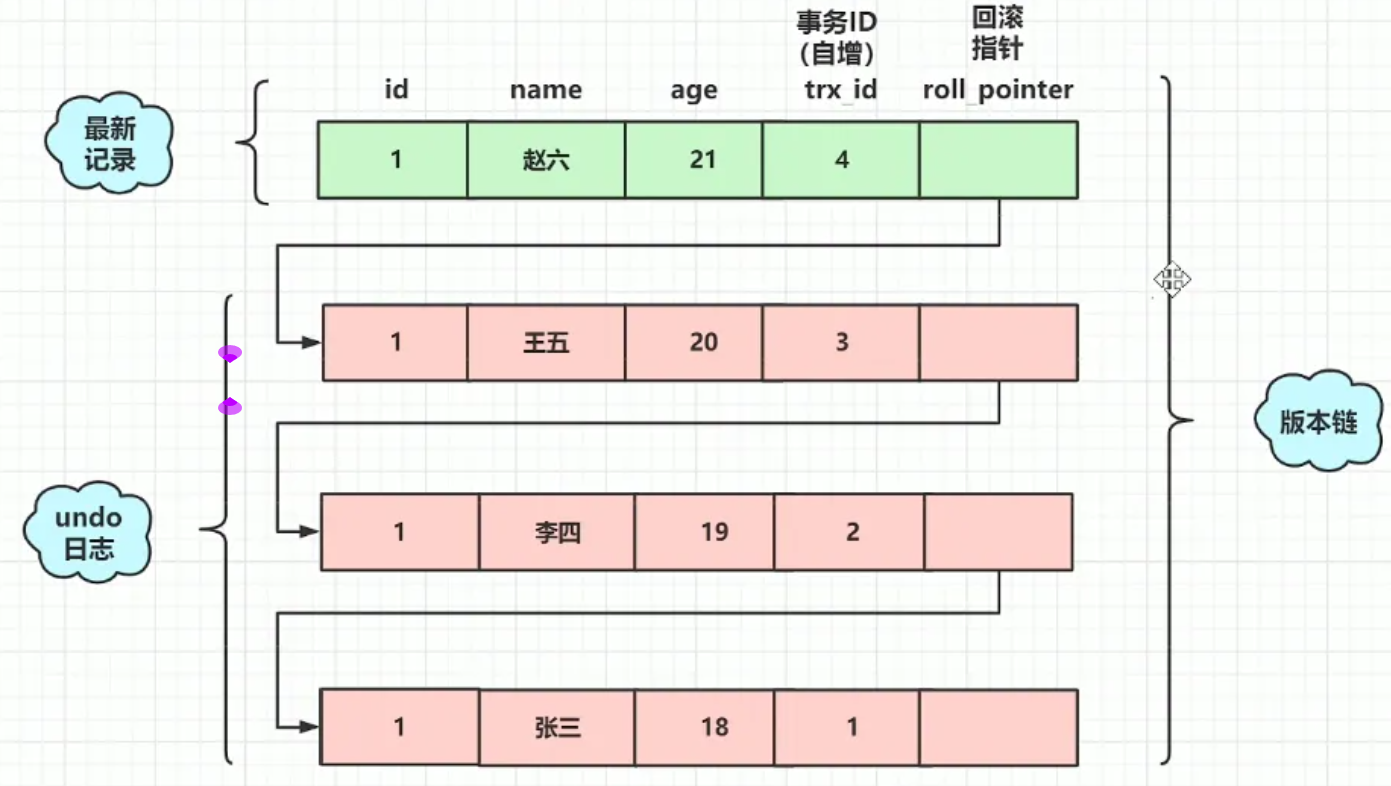
InnoDB为每一行记录(聚簇索引)都隐式地添加了三个字段:
-
DB_TRX_ID(6字节):事务ID 。表示最后一次插入或更新该行记录的事务ID。DELETE操作在内部也被视为一次更新。 -
DB_ROLL_PTR(7字节):回滚指针 。指向该行记录上一个版本 在Undo Log 中的地址。所有旧版本数据通过这个指针连接成一个版本链。 -
DB_ROW_ID(6字节):行ID。如果表没有定义主键,InnoDB会自动生成一个隐藏的主键 using this field.
2. 核心组件:Undo Log(回滚日志)
-
作用 :Undo Log不仅用于事务回滚,更是MVCC多版本数据的存储载体。
-
工作原理 :当一条记录被多次修改,就会形成一条由
DB_ROLL_PTR指针连接的版本链,链头是最新的记录,链尾是最老的记录。这个版本链就存储在Undo Log中。
3. 快照读与当前读
MVCC引入了两种读方式:
-
快照读 :普通的
SELECT语句(不包括SELECT ... FOR UPDATE或SELECT ... LOCK IN SHARE MODE)就是快照读。它基于事务开始时的数据快照,读取的是历史版本,因此是无锁的,性能极高。 -
当前读 :特殊的读操作和所有的写操作(
INSERT,UPDATE,DELETE)都是当前读。它读取的是记录的最新版本,并且会对读取的记录加锁(如行锁、间隙锁),以保证数据的一致性。
4. ReadView(一致性视图)
这是决定"哪个版本对当前事务可见"的关键数据结构,在可重复读(RR) 和读已提交(RC) 隔离级别下,ReadView的生成策略不同。
一个ReadView主要包含:
-
m_ids:生成ReadView时,系统中活跃的(未提交的)事务ID列表。 -
min_trx_id:m_ids中的最小值。 -
max_trx_id:生成ReadView时,系统将要分配给下一个事务的ID。 -
creator_trx_id:创建该ReadView的事务ID。
可见性判断算法:
当访问一条记录时,会遍历其版本链,并依次判断每个版本的DB_TRX_ID(创建它的事务ID):
-
如果
DB_TRX_ID == creator_trx_id,说明是本事务自己修改的,可见。 -
如果
DB_TRX_ID < min_trx_id,说明该版本在ReadView创建前已提交,可见。 -
如果
DB_TRX_ID >= max_trx_id,说明该版本是由在ReadView创建之后才开启的事务生成的,不可见。 -
如果
DB_TRX_ID在m_ids中,说明该版本是由生成ReadView时还处于活跃状态的事务创建的,不可见 。否则,可见。
四、不同隔离级别下的MVCC行为
MVCC的行为与数据库的隔离级别密不可分。需要明确的是,MVCC主要用于实现"读已提交(RC)"和"可重复读(RR)"这两个隔离级别。对于其他级别,数据库会采用不同的策略。
1. 读未提交 (Read Uncommitted, RU)
-
核心特点 :可以读取到其他事务未提交的修改。
-
MVCC角色 :基本不适用。
-
实现机制 :在这个级别下,数据库通常不会使用MVCC的快照读机制 。读操作直接读取最新的记录版本,而不管其是否已提交。这本质上是一种当前读。
-
问题 :因此,它无法解决脏读、不可重复读和幻读等任何并发问题。这是性能最高但一致性最差的级别。
2. 读已提交 (Read Committed, RC)
-
核心特点 :只能读取到其他事务已提交的修改。
-
MVCC角色 :核心实现方式。
-
实现机制 :每次执行快照读(
SELECT)语句时,都会生成一个新的ReadView。 -
效果 :因为每次读都重新生成视图,所以每次读都能看到最新已经提交的数据 。这解决了脏读 问题,但无法避免不可重复读 和幻读(因为两次读之间,其他事务可以提交修改)。
3. 可重复读 (Repeatable Read, RR)
-
核心特点:在一个事务内,多次读取同一数据的结果是一致的。
-
MVCC角色 :核心实现方式。
-
实现机制 :只在事务中第一次 执行快照读时生成一个ReadView,后续所有的快照读操作都复用这个ReadView。
-
效果 :因为整个事务都使用同一个"快照",所以它看不到其他事务在此之后提交的修改,从而解决了不可重复读 问题。结合Next-Key Lock(临键锁) 机制,InnoDB在RR级别下也很大程度上避免了幻读。
4. 串行化 (Serializable, SER)
-
核心特点:最严格的隔离级别,强制所有事务串行执行。
-
MVCC角色 :完全失效。
-
实现机制 :在这个级别下,数据库会完全禁用MVCC的快照读 。所有的读操作(包括普通的
SELECT)都会自动转换为当前读 ,类似于SELECT ... FOR SHARE(在MySQL中),会对读取的记录加共享锁(S锁)。 -
效果 :读会加共享锁,写会加排他锁(X锁),读写操作会相互阻塞。它通过强烈的锁机制 解决了所有并发问题(脏读、不可重复读、幻读),但性能开销最大,并发度最低。
总结对比
| 隔离级别 | MVCC作用 | 读操作本质 | 解决的并发问题 | 性能 |
|---|---|---|---|---|
| 读未提交 (RU) | 不适用 | 当前读(直接读最新版) | 无 | 最高 |
| 读已提交 (RC) | 核心 | 快照读(每次生成新ReadView) | 脏读 | 高 |
| 可重复读 (RR) | 核心 | 快照读(复用首次ReadView) | 脏读、不可重复读、部分幻读 | 中等 |
| 串行化 (SER) | 失效 | 当前读(自动加共享锁) | 所有问题 | 最低 |
五、MVCC的优缺点
优点:
-
高并发:读写互不阻塞,极大地提升了数据库的并发吞吐量。
-
避免死锁:读操作不需要加锁,减少了死锁发生的概率。
缺点:
-
空间开销:需要额外的存储空间(Undo Log)来保留旧数据版本。
-
维护开销:需要后台进程(Purge Thread)定期清理不再需要的旧版本数据(Purge操作)。
-
可能读到旧数据:在RR级别下,事务可能无法看到其他事务最新提交的数据。