文章目录
- [1. Redis持久化机制](#1. Redis持久化机制)
-
- [1.1 RDB(Redis DataBase) -- 定期备份](#1.1 RDB(Redis DataBase) -- 定期备份)
-
- [1.1.1 手动触发(save/bgsave)](#1.1.1 手动触发(save/bgsave))
-
- [1.1.1.1 save](#1.1.1.1 save)
- [1.1.1.1 bgsave(background)](#1.1.1.1 bgsave(background))
- [1.1.2 自动触发(bgsave)](#1.1.2 自动触发(bgsave))
- [1.1.3 RDB的优缺点](#1.1.3 RDB的优缺点)
- [1.2 AOF(Append Only File) -- 实时备份](#1.2 AOF(Append Only File) -- 实时备份)
-
- [1.2.1 AOF工作流程](#1.2.1 AOF工作流程)
- [1.2.2 重写机制(rewrite)](#1.2.2 重写机制(rewrite))
-
- [1.2.2.1 手动触发](#1.2.2.1 手动触发)
- [1.2.2.2 自动触发](#1.2.2.2 自动触发)
- [1.2.2.3 AOF重写流程](#1.2.2.3 AOF重写流程)
- [1.3 混合持久化](#1.3 混合持久化)
1. Redis持久化机制
先来回顾一下MySQL的事务的四大特性(ACID):
- 原子性: 一个事务中的所有操作要么全部成功,要么全部失败。
- 一致性: 数据库中的数据满足业务的预期要求。
- 持久性: 进程/主机重启之后,数据是否存在。(把数据存储在硬盘上 -----> 持久, 把数据存储在内存中 ---->不持久)。
- 隔离性:允许多个事务并发执行,但是各个事务之间不受任何影响。
Redis是一个内存数据库,是把数据存储在内存上的,但是为了数据持久化,还要想办法将数据存储在硬盘上。当我们要插入一条数据的时候,需要把数据同时写入内存和硬盘。当我们查询数据的时候,直接从内存中读取,这样就能保证Redis快的特性,还能保证数据的持久化。
硬盘中的数据只是在redis重启的时候,用来恢复内存数据的。
虽然说要在内存和硬盘上都写入数据,但是具体怎么写入可以保证整体的效率更高一些?
Redis有两种持久化的机制:RDB、AOF。
1.1 RDB(Redis DataBase) -- 定期备份
RDB持久化是把当前Redis中的数据生成一个快照保存到硬盘上的过程。
RDB持久化生成快照的触发机制有两种:手动触发、自动触发。
1.1.1 手动触发(save/bgsave)
通过redis客户端,执行特定的命令,来触发快照的生成。
1.1.1.1 save
使用save命令时,redis会阻塞其他客户端的命令,全力以赴的生成快照。
几乎不使用这种方式,阻塞服务是非常不可取的,如果数据量很大,生成快照备份的时间就会很长,这就意味着redis服务将长时间不可用,非常危险~~
1.1.1.1 bgsave(background)
执行bagsave命令时,并不会影响redis服务器处理其他客户端的请求和命令。

- 执行bgsave命令,Redis父进程判断是否有其他进行正在执行RDB/AOF子进程,如果有就直接返回。
- 如果没有,父进程会执行fork命令创建出来一个子进程。
- 父进程继续执行客户端的请求和命令。
- 子进程会创建RDB文件,根据父进程的内存生成临时快照文件,当这个快照生成完毕之后,再删除之前的rdb文件,把新生成的临时rdb文件名改成刚才的dump.rdb,完成对原有的RDB文件的替换,意思就是自始至终,rdb文件只有一个。
- 子进程执行完成之后,会发送信号给父进程。
查看生成的 .rdb文件:
bash
root@iZ2ze4j894d3dddy89j3laZ:~# dir /var/lib/redis
dump.rdbdump.rdb 文件时rdb机制生成的镜像文件,该文件是一个二进制的文件,它把内存中的数据以压缩(虽然压缩会消耗一定的CPU资源,但是能节省内存空间)的形式,保存在这个二进制文件中。
注意千万不要随意修改这个文件!!!
Redis服务器重启时,就会尝试加载这个rdb文件,如果发现这个文件的格式错误,就可能会加载数据失败。虽然不去主动的修改这个rdb文件,但是一些操作(网络传输)也可能会导致这个文件被破坏。
Redis提供了rdb文件的检查工具:
bash
root@iZ2ze4j894d3dddy89j3laZ:~# redis-check-rdb /var/lib/redis/dump.rdb
[offset 0] Checking RDB file /var/lib/redis/dump.rdb
[offset 27] AUX FIELD redis-ver = '6.0.16'
[offset 41] AUX FIELD redis-bits = '64'
[offset 53] AUX FIELD ctime = '1757684664'
[offset 68] AUX FIELD used-mem = '871616'
[offset 84] AUX FIELD aof-preamble = '0'
[offset 93] Checksum OK
[offset 93] \o/ RDB looks OK! \o/
[info] 0 keys read
[info] 0 expires
[info] 0 already expired1.1.2 自动触发(bgsave)
自动触发也是使用的bgsave的方式,其过程和手动触发使用bgsave的命令完全一样,都是使用创建子进程的方式。
自动触发就是在Redis的配置文件中进行设置,每个多长时间/产生多少次修改就触发RDB。
生成一次rdb快照,这是一个成本较高的操作,不能让这个操作执行的太频繁,所以在配置文件中进行配置时需要注意一下触发生成rdb快照文件的条件。
因为rdb文件不能生成的太频繁,所以快照中的数据和实时数据有一定的偏差。
在两次生成快照的中间,redis接收接收到了大量的key变化的请求,生成下一次快照之前,redis服务器挂了,那么中间这些key的变化就全丢了。
如果是通过正常流程service redis-server restart重新启动的Redis服务器,此时Redis服务器会在退出的时候,自动触发rdb操作。
如果是异常重启(kill -9、系统崩溃 或者 服务器掉电),此时Redis服务器来不及生成rdb文件,数据就会随着重启而丢失。
如果想要查看dump.rdb文件是否重新生成了,可以使用stat dump.rdb命令来查看文件的inode编号,inode编就相当于是文件的身份标识。
LInux文件系统主要是把整个文件系统分成了三个部分:
- 超级块:存储整个文件系统的信息,一些管理信息。
- inode表:所有文件的元数据(大小、权限、指针),
- Data Blocks(数据块):所有文件的实际内容。
1.1.3 RDB的优缺点
- RDB是一个压缩紧凑的二进制文件,非常适用于备份、全量复制等场景。
- Redis加载RDB要比AOF快的多。
原因:
- RDB是使用二进制的方式来组织数据的。直接把数据读取到内存中,按照字节的格式取出来放到结构体/对象中即可。
- AOF是使用文本的方式来组织数据的,需要进行一系列的字符串切分操作。
- RDB不能做到实时持久化。
- RDB使用特定二进制格式保存,Redis版本演进过程中有多个RDB版本,兼容性可能会有风险。
老版本Redis中的rdb文件,放到新版本的redis中不一定能识别。
1.2 AOF(Append Only File) -- 实时备份
AOF类似于MySQL中的binlog,会把用户的每个操作都记录到文件中。
当开启AOF时,rdb文件就不生效了。当Redis重启时会读取aof这个文件来用来恢复数据。
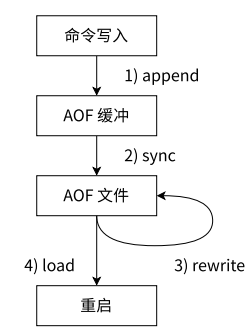
1.2.1 AOF工作流程
- 所有的写入命令都会哦追加到aof_buf中
- AOF缓冲区根据对应的策略向硬盘中(AOF文件)写入数据。
- AOF文件越来越大,进行重写操作。
- 重启时读取AOF文件中的数据。
AOF虽然既写内存又写硬盘,但是并没有影响到Redis处理请求的速度。主要有以下两个原因:
- AOF机制并不是直接让工作线程把数据写入硬盘,而是先写入一个内存的缓冲区,积累到一定的量时,再统一写入硬盘。
但是这样如果数据还在缓存中,并没有写入到硬盘上,如果进程突然挂了,那么缓冲区中的数据也就丢了。
先写入一个内存缓冲区中,就大大降低了写硬盘的次数。写硬盘的时候,写入硬盘的数据的多少,对性能没有很大的影响。但是写入硬盘的次数对性能影响很大。
- AOF每次写入都是写入原文件的末尾,属于顺序写入。
在硬盘上读写数据,顺序读写的速度虽然没有在内存中操作的快,但是还是比较快的。
1.2.2 重写机制(rewrite)
AOF文件会持续增长,体积会越来越大,会影响到下一次Redis启动的速度(因为Redis启动时要读取AOF文件的内容)。
AOF文件中记录着操作的过程,但是Redis重新启动读取时,并不关注这个过程,只关注结果。
Redis中就存在一个重写机制,会对AOF文件进行整理,提出其中的一些冗余操作,并且合并一些操作。
1.2.2.1 手动触发
调用bgrewriteaof命令。
1.2.2.2 自动触发
根据 auto-aof-rewrite-min-size 和 auto-aof-rewrite-percentage 参数确定自动触发时
机。
1.2.2.3 AOF重写流程
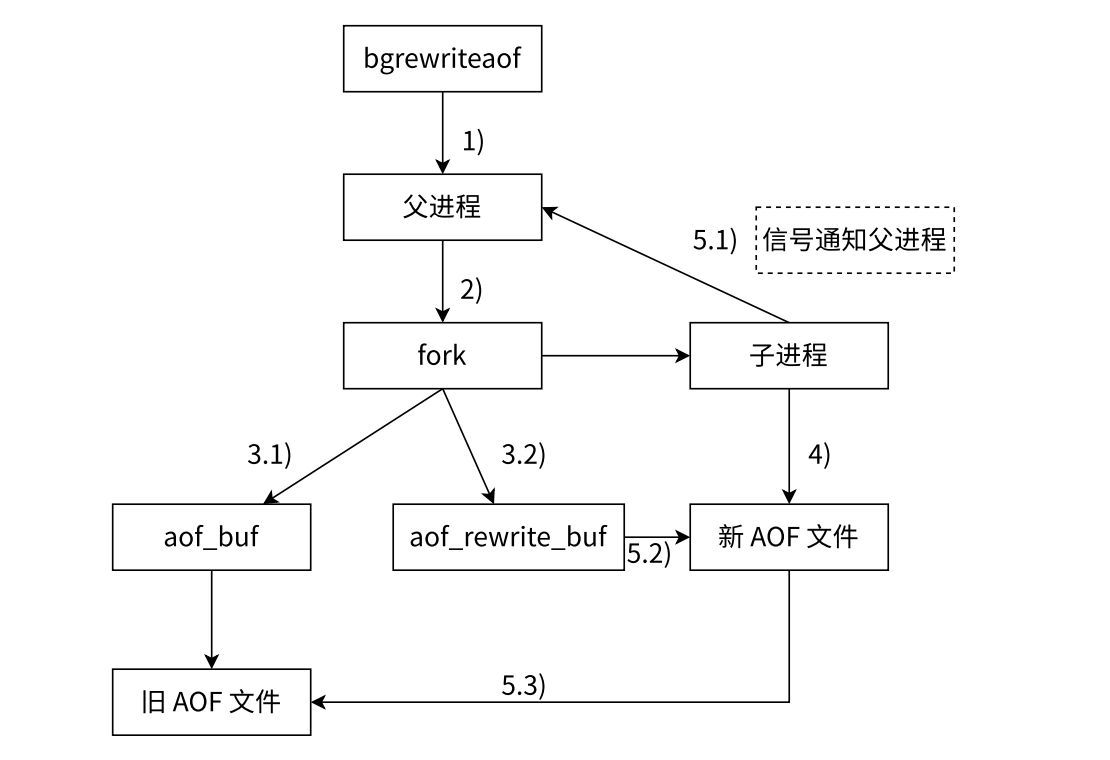
- 父进程执行bgrewriteaof操作。
如果当前进程正在执行 AOF 重写,请求不执行 。如果当前进程正在执行 bgsave 操作,重写命令延迟到 bgsave 完成之后再执行 。
- 父进程fork出一个子进程。
- 重写。
3.1 父进程不受影响继续处理客户端请求,处理的请求操作依旧写入AOF缓冲区。
3.2 在fork出子进程的一瞬间,子进程就继承了父进程的内存状态。所以子进程中的数据状态时父进程fork之间的数据状态,那fork之后父进程依旧在处理请求,这期间对内存的修改,子进程是不知道的。使用aof_rewrite_buf来专门存放fork之后的数据。
- 子进程把内存中当前的数据获取出来,以AOF的格式写入到一个新的AOF文件中。
子进程并不需要读取 硬盘上哪个庞大的旧的AOF文件,而是遍历当前内存数据库中的所有数据,为每个键值对生成一条最精简的命令,并将其写入一个新的临时的AOF文件。
- 子进程完成重写。
5.1 子进程把数据写完之后会发送一个信号通知父进程。
5.2 父进程把aof_rewrite_buf缓冲区中的内容也吸入到新的AOF文件中。
5.3 用新的AOF文件替换旧的AOF文件。
问:父进程坚持写即将消亡的旧的AOF文件有什么意义吗?
答:如果父进程不坚持写旧的AOF文件,可能重启就没办法保证数据的完整性了。假如子进程在重写的过程中,服务器突然挂了,新的AOF文件内容还并不完整,子进程的数据就会丢失。
1.3 混合持久化
RDB和AOF各有各的优点,Redis就引入了混合持久化的方式,结合了rdb和aof的特点。
混合持久化的核心是在AOF重写的过程中。
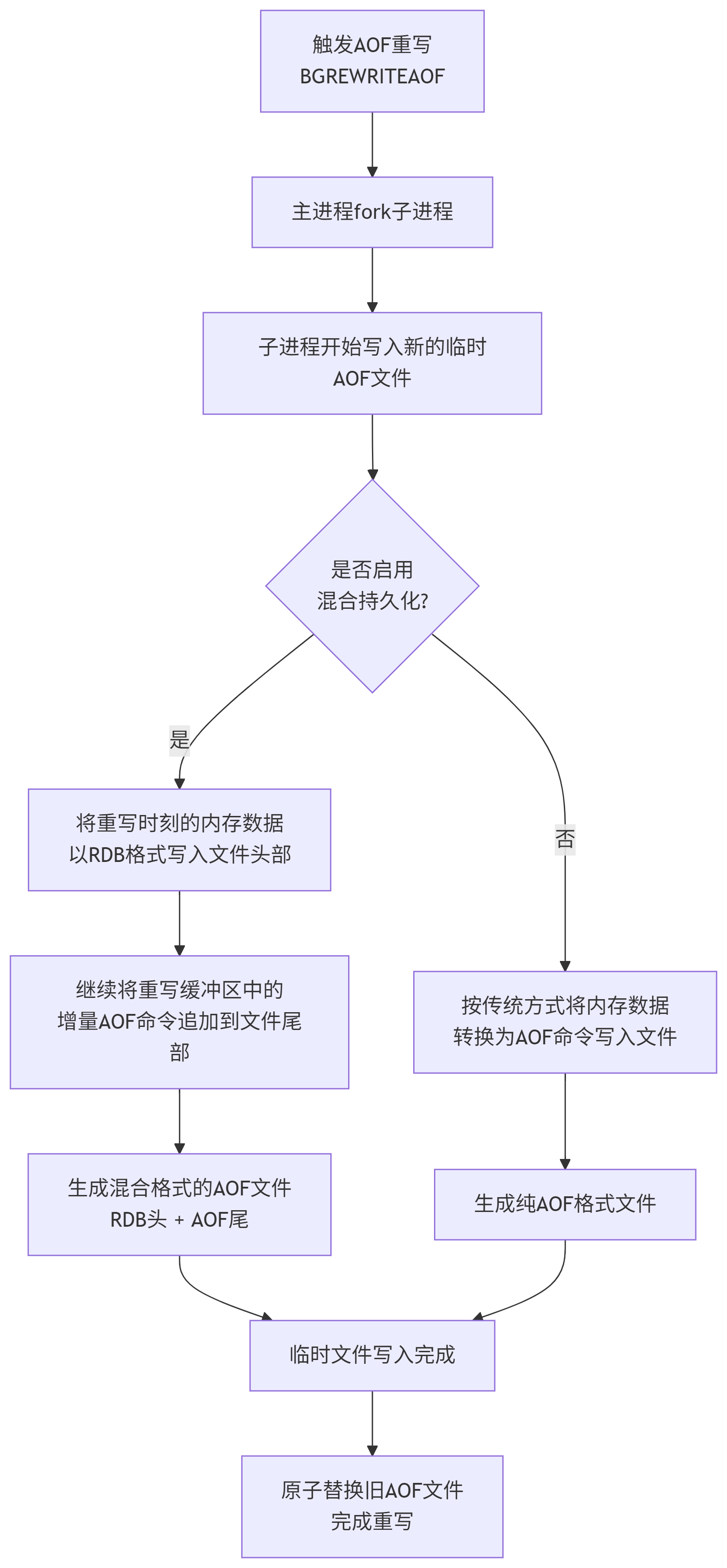
按照aof的方式,每一个请求/操作,都记录到文件中。在触发aof重写之后,会把当前内存的状态按照rdb的二进制的格式写入到新的aof文件的头部,后续再将缓冲区的增量AOF命令写入新的AOF文件的末尾,生成混合格式的RDB头和AOF尾的AOF文件,再用新的AOF文件替换旧的文件。