思维导图
本文的思维导图如下:
一、Redis 线程模型
(一)Redis 是单线程吗?
Redis 常被称为"单线程",但这里的单线程特指:
主线程负责处理客户端请求( 接受客户端请求 → 解析命令 → 执行数据读写操作 → 返回结构给客户端) 整个流程都由一个线程完成。
正因为命令处理在同一个线程中顺序执行,不需要加锁,也没有线程竞争,Redis 才能在内存操作上达到极高性能。
但 Redis 程序本身并不是完全单线程的:
虽然 Redis 的命令执行是单线程,但 Redis 在启动时会创建若干 后台 I/O 线程(BIO) 来处理一些可能导致阻塞的耗时操作。
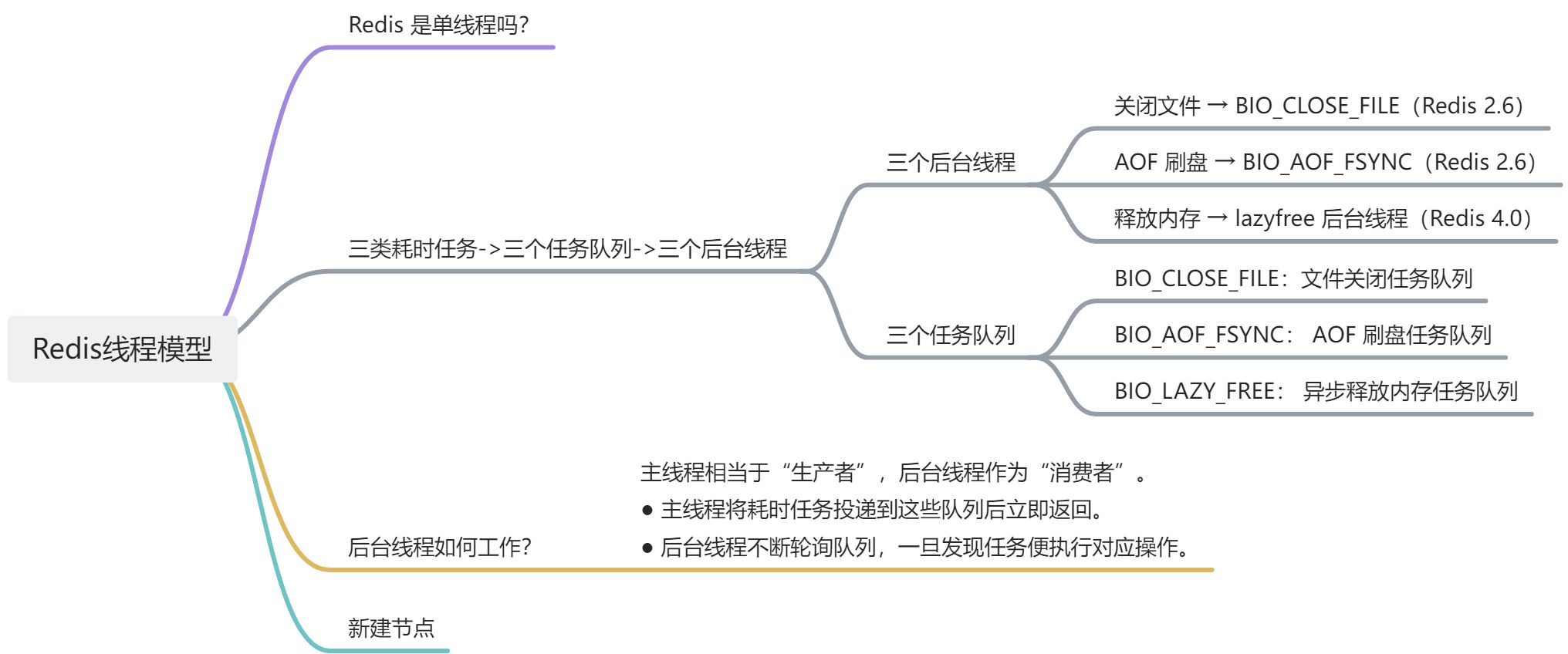
(二)Redis 的后台线程
三个后台线程
Redis 为「关闭文件、AOF 刷盘、释放内存」这些任务分别创建了单独的线程来处理,是因为这些任务的操作都是很耗时的,如果把这些任务都放在主线程来处理,那么 Redis 主线程就很容易发生阻塞,这样就无法处理后续的请求了。
2.6 版本后的 Redis 会启动 2 个后台线程,分别用于处理关闭文件、AOF 刷盘这两个任务。
-
关闭文件
当 Redis 需要关闭文件(如客户端断开导致文件句柄关闭)时,close(fd) 在某些情况下可能阻塞,因此 Redis 将其放入后台线程处理。
-
AOF 刷盘
如果开启 AOF,写入日志后需要 fsync() 刷盘,而 fsync 是典型的慢操作。
为了避免主线程被磁盘 I/O 阻塞,Redis 会把 fsync 封装为任务发送到后台线程执行。
Redis 4.0 引入了第三个后台线程,用来异步释放 Redis 内存(lazyfree)。
其目的在于避免删除大 key 时引发主线程卡顿。
例如 Redis 在执行以下命令:
UNLINK keyFLUSHDB ASYNCFLUSHALL ASYNC
这些命令不会立即在主线程中释放对象,而是把删除操作交给 lazyfree 线程,主线程可以立即继续处理其他请求,不会因释放大对象而阻塞。
提示:当我们要删除一个大 key 的时候,不要使用 del 命令删除,因为 del 是在主线程处理的,这样会导致 Redis 主线程卡顿,因此我们应该使用 unlink 命令来异步删除大key。
三个任务队列
关闭文件、AOF 刷盘、释放内存这三个后台任务都有各自独立的任务队列:
- BIO_CLOSE_FILE:文件关闭任务队列
当后台线程发现队列有任务后,后台线程会调用 close(fd),将文件关闭。 - BIO_AOF_FSYNC: AOF 刷盘任务队列
当 AOF 日志配置成 everysec 选项后,主线程会把 AOF 写日志操作封装成一个任务,也放到队列中。
当后台线程发现队列有任务后,后台线程会调用 fsync(fd),将 AOF 文件刷盘。 - BIO_LAZY_FREE: 异步释放内存任务队列
当后台线程发现队列有任务后,后台线程会调用 free(obj) 释放对象 / free(dict) 删除数据库所有对象 / free(skiplist) 释放跳表对象。
后台线程如何工作?
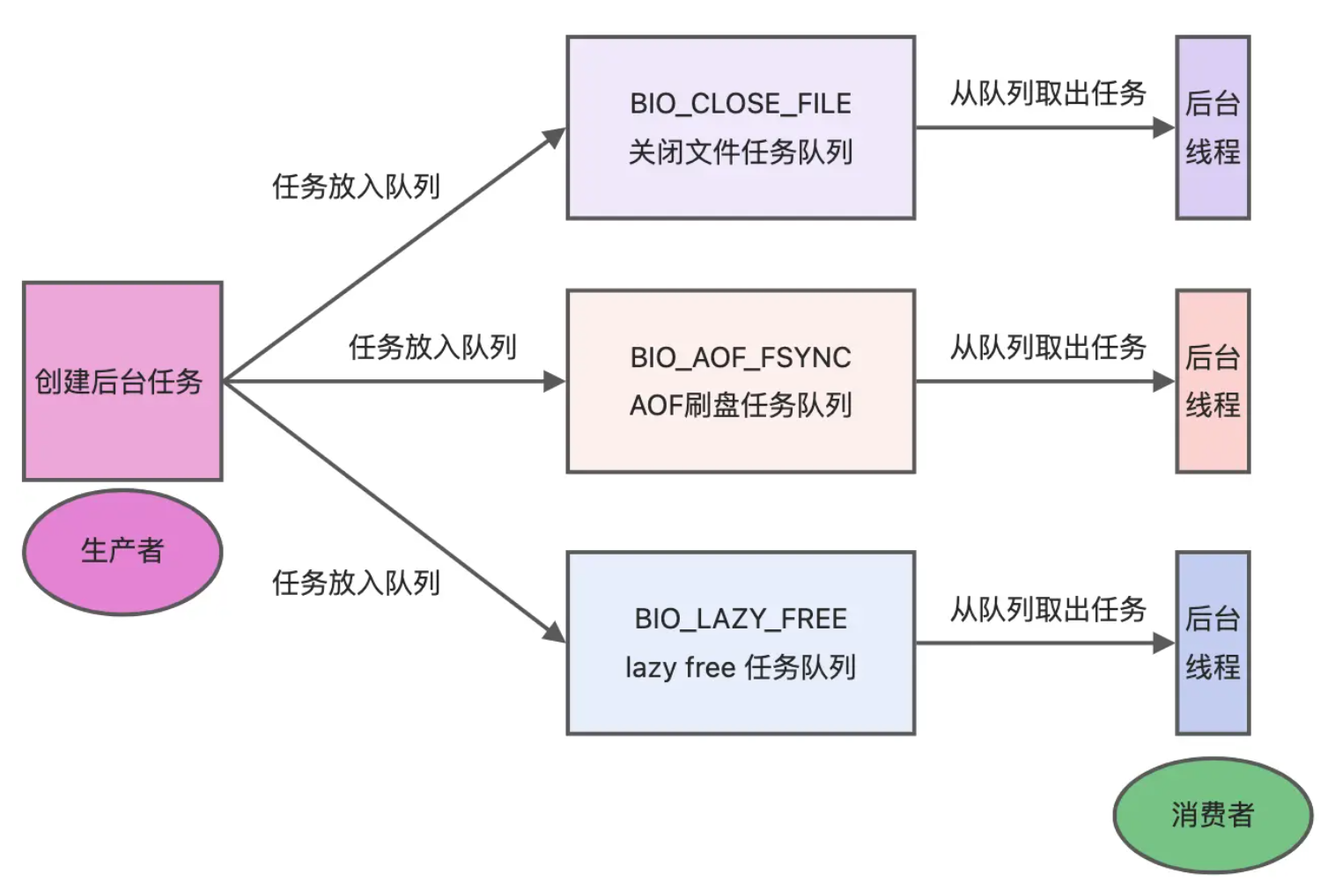
主线程相当于"生产者",后台线程作为"消费者"。
- 主线程将耗时任务投递到这些队列后立即返回。
- 后台线程不断轮询队列,一旦发现任务便执行对应操作。
这种"生产者 → 消费者"结构既保证了主线程的轻量运行,又能避免慢 I/O 导致的阻塞。
二、相关面试题
1. Redis 是单线程,还是多线程?
回答:
Redis 的++核心处理++一直都是单线程的。
原因: 因为 Redis 主线程负责处理客户端请求的整个流程都由一个线程完成。
好处: 命令处理在同一个线程中顺序执行,这样就不需要加锁,也没有线程竞争,让 Redis 在内存操作上达到极高性能。
补充: 但是 Redis 在 6.0 中引入了多线程。
注意:
Redis 整个程序的本身并不是完全单线程的:
虽然 Redis 的命令执行是单线程,但 Redis 在启动时会创建若干 **后台 I/O 线程(BIO)**来处理一些可能导致阻塞的耗时操作。
2. Redis 为什么选择单线程作为核心处理?
分析: 为什么用单线程?其潜台词就是为什么不用多线程?
我们不能只说多线程有多大成本、多复杂,这样很容易被追问:
- 为什么多线程这么多问题,很多组件(比如MySQL)都是用的多线程呢?多
- 线程肯定有它的优势,那 Redis 为什么不利用这种优势?
所以,我们需要从投入产出比来分析这道题。
先看产出(收益):
Redis 的定位是内存 k-v 存储,是做短平快的热点数据处理,一般来说 CPU 执行会很快,CPU 执行本身不应该成为 Redis 的瓶颈,Redis 的瓶颈通常在 网络 I/O。所以处理逻辑多线程化并不会有太大收益。
再看投入(成本):
多线程虽然某些方面表现优异,但是它也引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,比如:
- 为了支持事务的原子性、隔离性,Redis 就不得不引入一些很复杂的实现;
- 多线程模式也会使得程序调用更加复杂,会带来额外的开发成本和维护成本;
- 线程的上下文切换成本、同步机制的开销;
- 线程本身也占据内存。
回答:
我们可以从投入产出来分析这个问题。
首先来看收益: 如果我们引入多线程,主要是希望充分利用多核的性能 ,但 Redis 的定位是内存 k-v 存储 ,是做短平快的热点数据处理,一般来说执行很快,执行本身并不会成为瓶颈,其瓶颈通常在网络 I/O,所以我们处理逻辑多线程化并不会有太多收益。
再来看成本: 如果引入多线程,系统的复杂度会大大增加,比如线程上下文切换、同步机制等开销。
这样综合来看,成本高收益不大,所以 Redis 最终选择单线程。
事实也证明,单线程的 Redis 也确实足够高效。
3. Redis 单线程性能如何?
分析:
这题主要考察对 Redis 直观的认知:Redis 实际表现为单机(普通 8 核 16G 的机器)读 10 多万,写几万,非常炸裂。
也可以说自己用过 redis-benchmark 来测试过其性能。
命令:
plsql
redis-benchmark -h 127.0.0.1 -p 6379 -t set,get -n 10000 -q结果:
plsql
SET: 108695.65 requests per second
GET: 149253.73 requests per second回答:
Redis 单线程的性能是很好的,在普通机器每秒能有 10 多万的读性能、几万的写性能。我在我的 mac 上也用
redis-benchmark 来测试过,写性能高达 11 万,读性能高达 15 万。
4. Redis 为什么这么快?
类似问题: Redis 为什么采用了单线程还这么快?
回答:
Redis 单线程却依然很快,主要有四个原因:
完全基于**++内存++**操作
Redis 的所有数据都在内存中,内存的读写速度比磁盘快几个数量级,
所有的操作都在内存里完成,所以很多操作几乎都是瞬时完成的。
高效的++数据结构++
Redis 专门设计了很多高效的数据结构,比如哈希表、列表、有序集合等。
这些结构能在 O(1) 或接近 O(1) 的时间复杂度内完成大多数操作。
++单线程++反而避免了开销
Redis 单线程意味着没有上下文切换,也没有锁竞争、没有死锁,
从而提高了运行效率和响应速度。
++I/O 多路复用++让单线程也能并发
Redis 结合了 epoll 这样的 I/O 多路复用机制,一个线程就能管理成千上万的客户端连接,当有事件发生在进行处理,从而提高 IO 利用率、提升并发性能。
5. Redis 6.0 为什么引入了多线程?
回答:
Redis 的主要瓶颈是 I/O 而不是 CPU,但是随着互联网的高速发展,在部分高并发场景下,单核 CPU
也不见得处理得过来了,所以针对核心处理过程中的解包、发包这两个 CPU 耗时操作,Redis 进行了多线程优化,充分发挥了多核优势。
补充:
解包:协议解析,Redis 解析客户端发送的命令。
发包:协议序列化,Redis 将数据返回给客户端。
6. Redis 6.0 多线程是默认开启的吗?
Redis 6.0 的多线程默认的关闭的。
如果想要使用多线程,需要用户在配置文件 redis.conf 中手动开启。
Redis 为什么默认关闭多线程? 主要有两个原因:
1)兼容性考虑
毕竟在大多数用户都习惯了 Redis 是单线程的。
为了兼容老版本的使用方式,避免引入潜在的不兼容行为,所以默认不开启。
2)多线程只优化网络 I/O,不是必需品
Redis 的核心命令仍然是单线程,多线程只是加速网络读写。
大数据业务场景本身 QPS 就能轻松抗住,所以不开启多线程也够用,没必要默认开启。
补充:
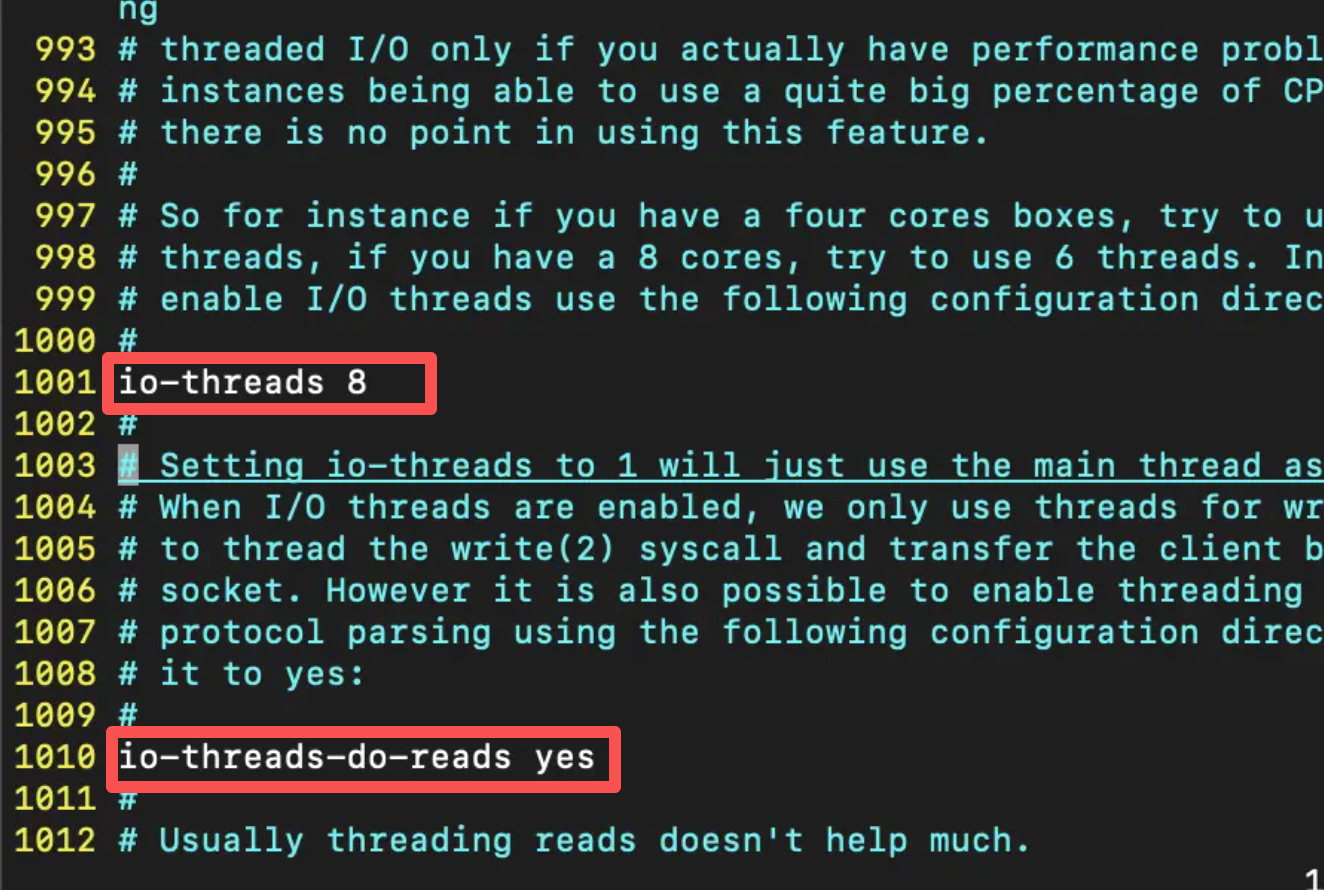
如果想要使用多线程,用户需要在配置文件 redis.conf 中手动开启:
- 设置
io-thread的值为想要的 io 线程数。 - 设置
io-threads-do-reads yes打开读事件处理的多线程。