本文介绍的是 VLDB'25 论文《OLTP in the Cloud: Architectures, Tradeoffs, and Cost》,论文系统分析了云上 OLTP 的工作负载,并确定每种负载下成本最优的架构及硬件配置。对于云上 OLTP 数据库选型以及了解数据库量化分析方法具有较好的参考意义。
前言
OLTP 数据库迁移上云已经成为一种趋势,公有云为数据库提供了更好的弹性伸缩、低成本等优势。
目前,各类云厂商提供了丰富的云上数据库架构选型,比如 AWS Aurora/RDS、Microsoft Socrates/SQL Database、Google AlloyDB/Cloud SQL 等。而每种数据库下,又提供了多种存储选项和服务器实例配置。这形成了巨大的设计空间,使得系统设计者难以做出明确的决策。
如果你正准备把业务迁移上云,一定会很头疼:
要选择哪种数据库(架构)、哪种硬件配置,才能满足业务诉求,且成本最低?
云上 OLTP 数据库架构
论文把现有的云上 OLTP 数据库总结归纳成如下 6 类架构:
-
Classic
-
HADR(High Availability Disaster Recovery)
-
RBD(Remote Block Device)
-
In-Memory
-
Aurora-like
-
Socrates-like
其中 Aurora-like 和 Socrates-like 属于云原生架构。
Classic 架构
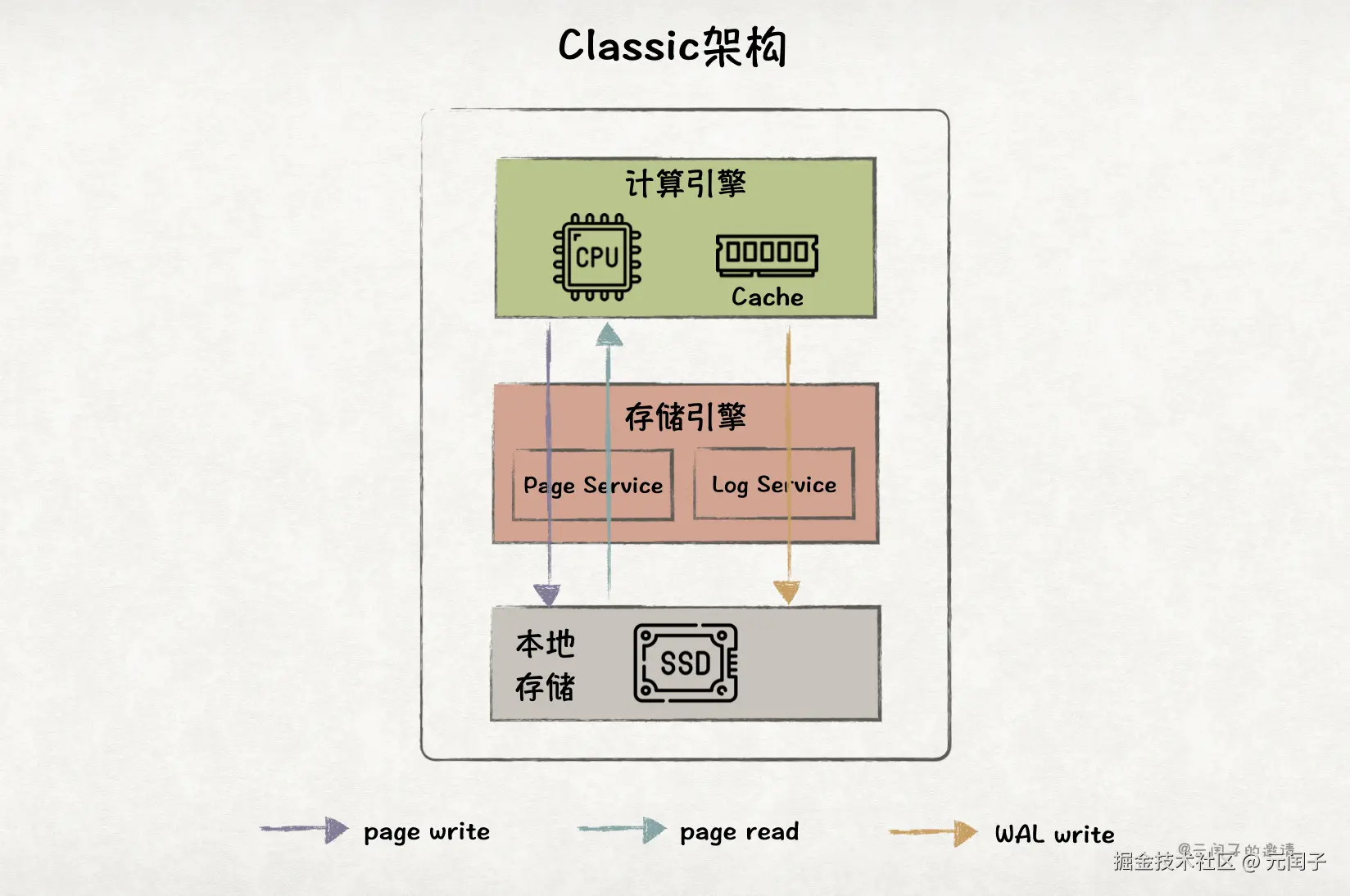
Classic 架构是一种单体架构,数据库的计算引擎和存储引擎都在一个进程、部署在一个服务器实例下。
其中,存储引擎可以分为 2 部分,Log Service 复杂将 WAL 写入本地 SSD,保证数据可靠性;Page Service 负责 page 的管理,包括从 SSD 中读取 page 到内存中,以及将 dirty page 写回到 SSD 中。
鉴于 HDD 性能已无法满足现代 OLTP 性能要求,论文中的本地磁盘只考虑 SSD。
Classic 架构最大的优点是,所有数据都来自于本地 SSD,避免了高昂的网络开销;而且本地 SSD 可以提供高达 3.3M IOPS@4K 随机读的性能(AWS EC2 实例)。
然而,Classic 架构最大的缺点也是所有数据都存储在本地 SSD。在公有云上,我们通常认为弹性服务器实例的本地 SSD 是不可靠的,实例的下线或硬件故障,会导致本地 SSD 数据丢失。
另外,Classic 架构无法进行水平扩展,随着业务负载的增大,容易成为单点瓶颈。
HADR 架构
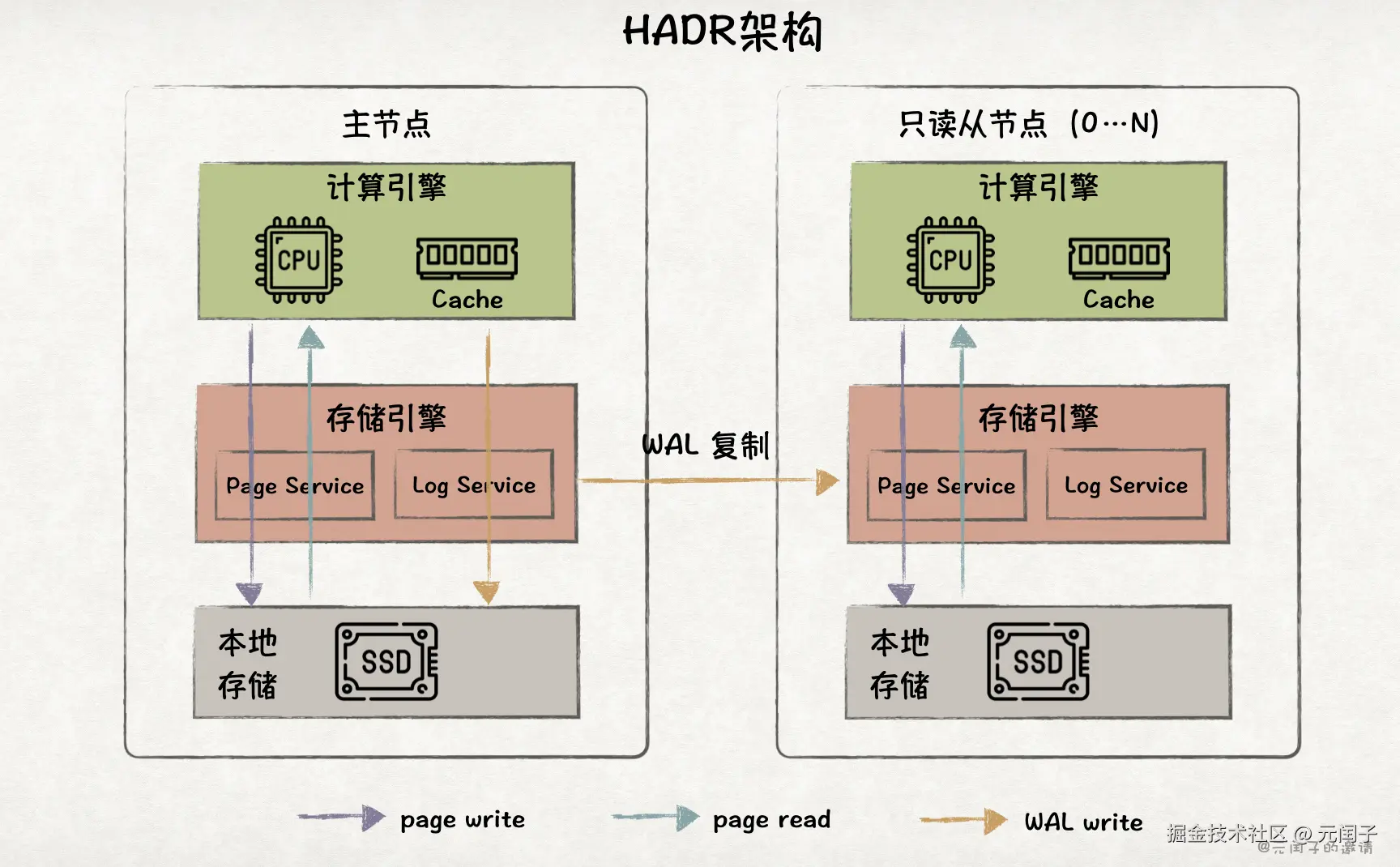
HADR 架构是一种主从架构,在 Classic 架构的基础上,引入了多个从节点。
主节点可同时处理读和写请求,从节点只能处理读请求。主节点通过将 WAL 复制到从节点上,来进行数据同步。从节点通过将 WAL 回放成 page,对外提供数据查询服务。
HADR 架构拥有多个数据副本,当主节点故障时,系统仍可从剩余的从节点上恢复,对比 Classic 架构,在可用性、可靠性上有了很大的提升。
HADR 节点的数据流与 Classic 架构相同,新增了从主节点到从节点复制 WAL 的网络开销。
虽然从节点支持水平扩展,但只有主节点能处理写请求,在写密集型负载下容易成为瓶颈。
另外,全量数据仍在本地 SSD 上,而本地 SSD 容量有限(AWS EC2 最大可支持单盘 1.9TB,最多可配置 8 盘,共 15.2TB),这就导致当业务规模大到一定程度后,HADR 架构无法放下所有数据了。
RBD 架构
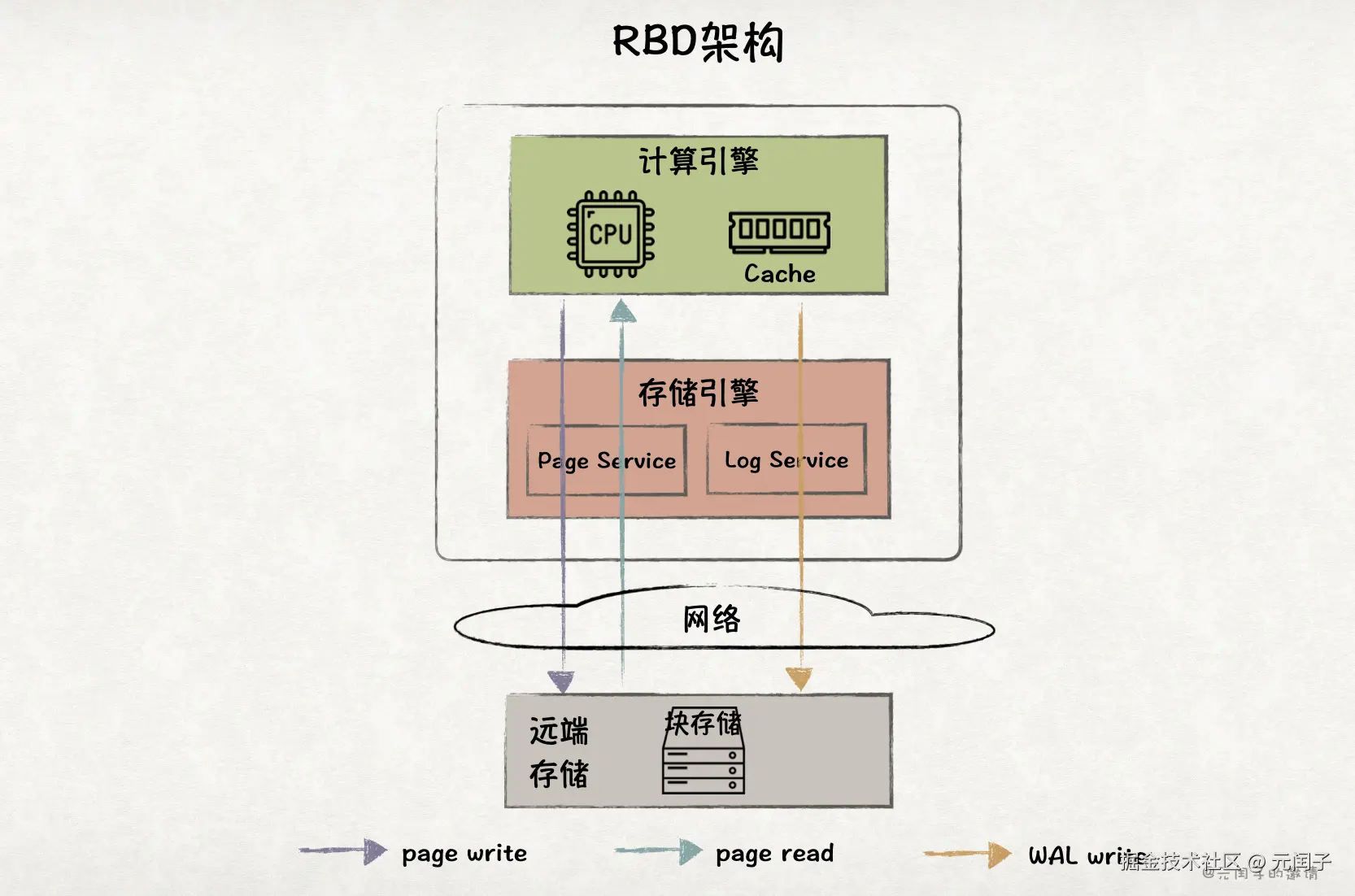
RBD 架构将本地 SSD 替换成远端存储,比如 AWS Elastic Block Store(EBS)或者 Azure Managed Disks,提供了更高的可靠性、更低的成本。而且,这使得存储摆脱了单点瓶颈,容量可以无限扩展下去。
然而,RBD 架构并未实现存算分离,主要原因是块存储不支持同步语义接口,导致 RBD 架构无法像 HADR 架构一样扩展多个只读节点。
另外,存储拉远后,数据的读写增加了网络开销,对比本地 SSD,在读写带宽和时延上都更差。
In-Memory 架构
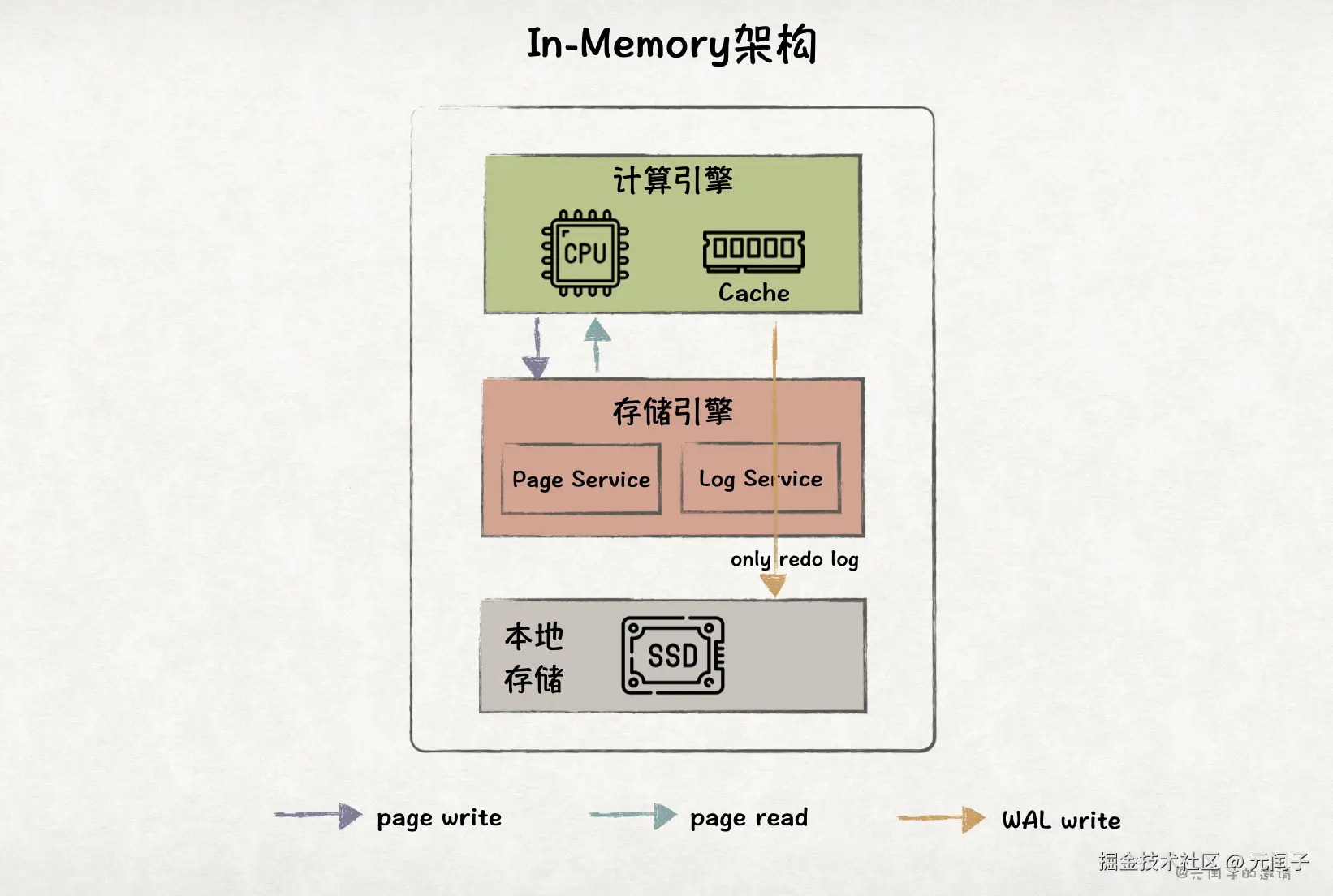
In-Memory 架构也属于单体架构,但与 Classic 架构不同,他把所有数据都加载到内存里,只会将 redo log 写入本地 SSD 保证事务持久性。
因此,In-Memory 架构只在处理写请求时有少量的磁盘 IO,性能在所有架构里是最强的。
但 In-Memory 架构的缺点也很明显,相比磁盘,内存的成本更高,而且容量更小(AWS EC2 实例最高只支持 4TB 内存容量)。所以,它只适合那些高读写负载、数据集很小的业务场景。
Aurora-like 架构
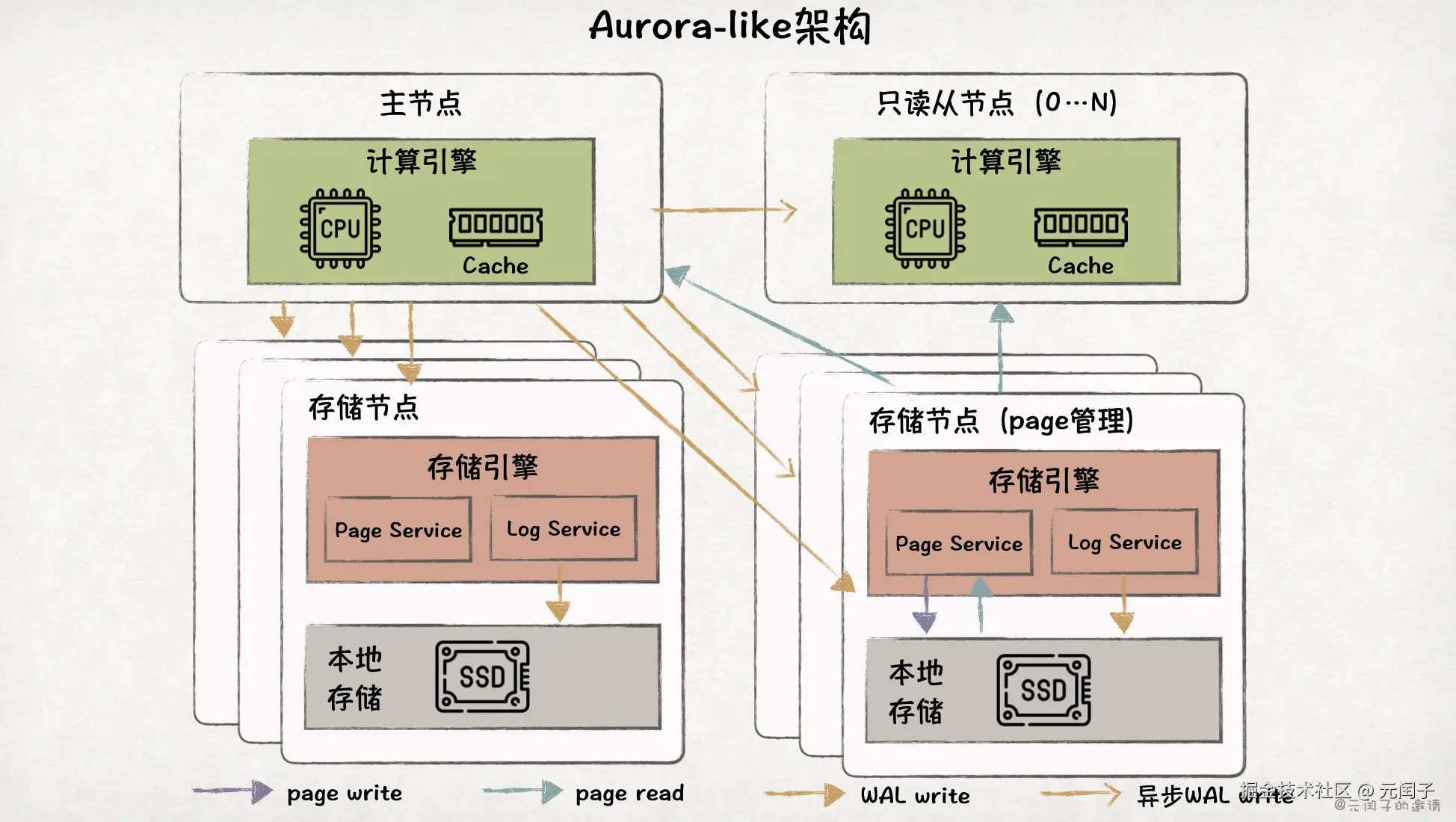
Aurora-like 架构是云原生架构,真正实现了存算分离。
计算引擎部署在无状态的计算节点,能够根据业务负载来进行弹性扩缩容。
存储节点将数据保存在本地 SSD。数据被切分成 10GB 大小的 chunk,每个 chunk 由至少 6 个存储节点组成的集群管理,通过一致性协议来保证数据可靠性。
Aurora-like 架构也是一写多读的架构。数据写入时,主节点会将 WAL 同时发到 6 个存储节点上,得到至少 4 个节点确认后,写入成功。
存储节点实时回放 WAL 来构建 page,供计算节点查询。为降低存储成本,Aurora-like 架构只在其中 3 个节点上管理 page。
因为 page 和 WAL 都存在多副本,所以 Aurora-like 架构具备较高的可靠性。但数据副本都存储在本地 SSD,成本很高,不适合拥有大量冷数据的场景。
另外,每次读请求都会涉及存储节点和计算节点间的网络通信,带来了额外的开销。
Socrates-like 架构
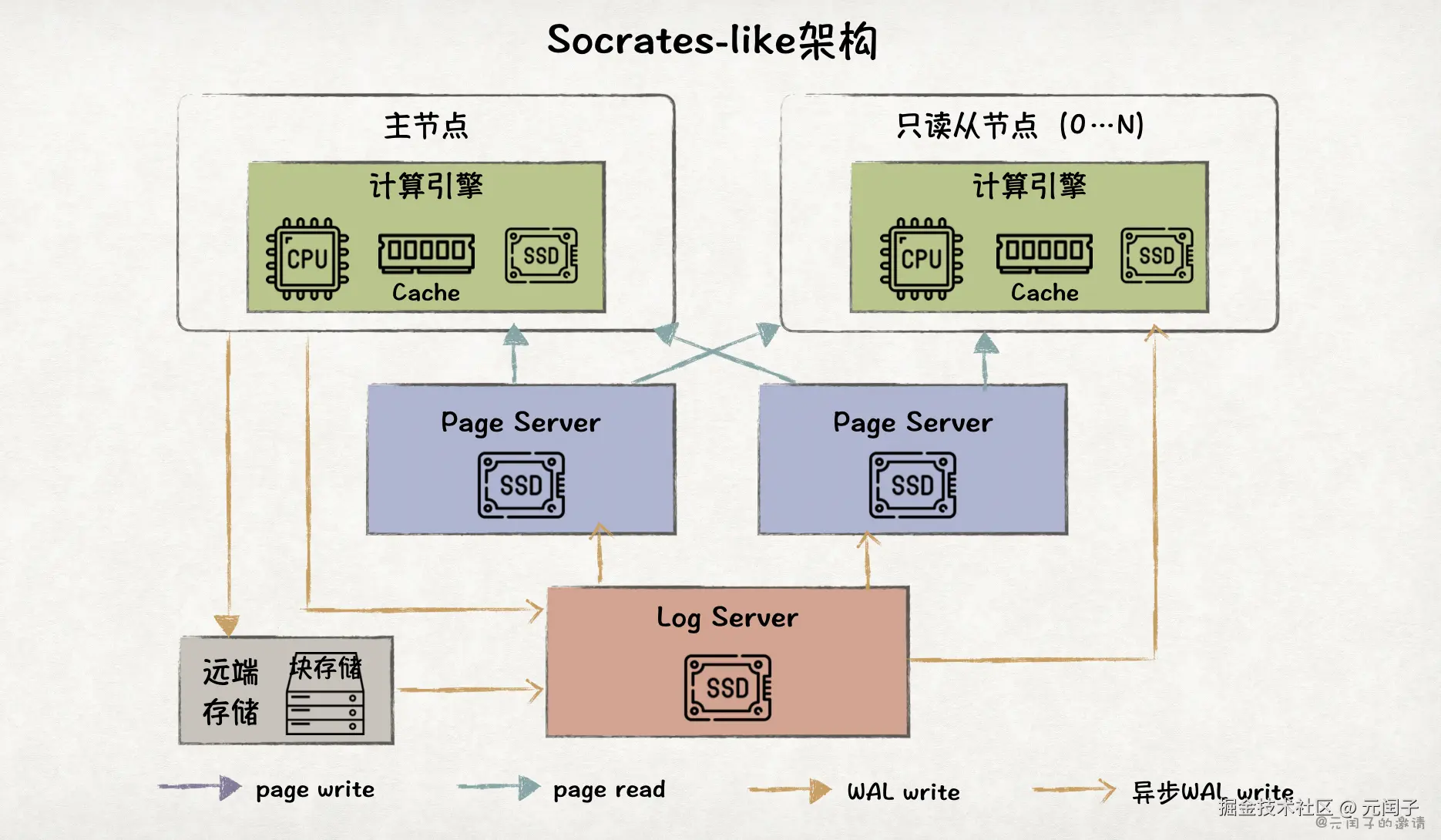
Socrates-like 架构在 Aurora-like 架构的基础上进一步将存储节点拆分成了 Log Server(XLog)和 Page Server,使得它们具备独立扩展的能力。
数据写入时,主节点会同步将 WAL 写入远端快存储,保证可靠性。Log Server 负责将 WAL 整合和分发到 Page Server 和只读从节点上,它们会实时回放 WAL 来构建 page。
Socrates-like 架构在计算节点、Log Server、Page Server 上都设了本地 SSD 缓存,它们共同构成了一个名为 Resilient Buffer Pool Extension(RBPEX)的统一缓存系统。
数据查询时,计算节点只在 Cache Miss 时,才会发起到 Page Server 的读请求,对比 Aurora-like 架构有着更低的读时延。
另外,Socrates-like 架构的可靠性主要依靠远端块存储来保障,无需在本地 SSD 保存全量数据,所以成本比 Aurora-like 架构更低。
2 个 Page Server 的设计,更多的是基于可用性的考虑,当其中之一故障时,能够快速容灾到另一个。也可配置更多的 Page Server 来提供更高的可用性。
量化评估方法
因为架构+硬件配置的组合太多,不可能通过实测的方法来确定(成本太高)。所以,论文提出了一个量化评估模型,能够根据给定的目标负载、数据库架构和硬件配置来快速找到最划算的组合。
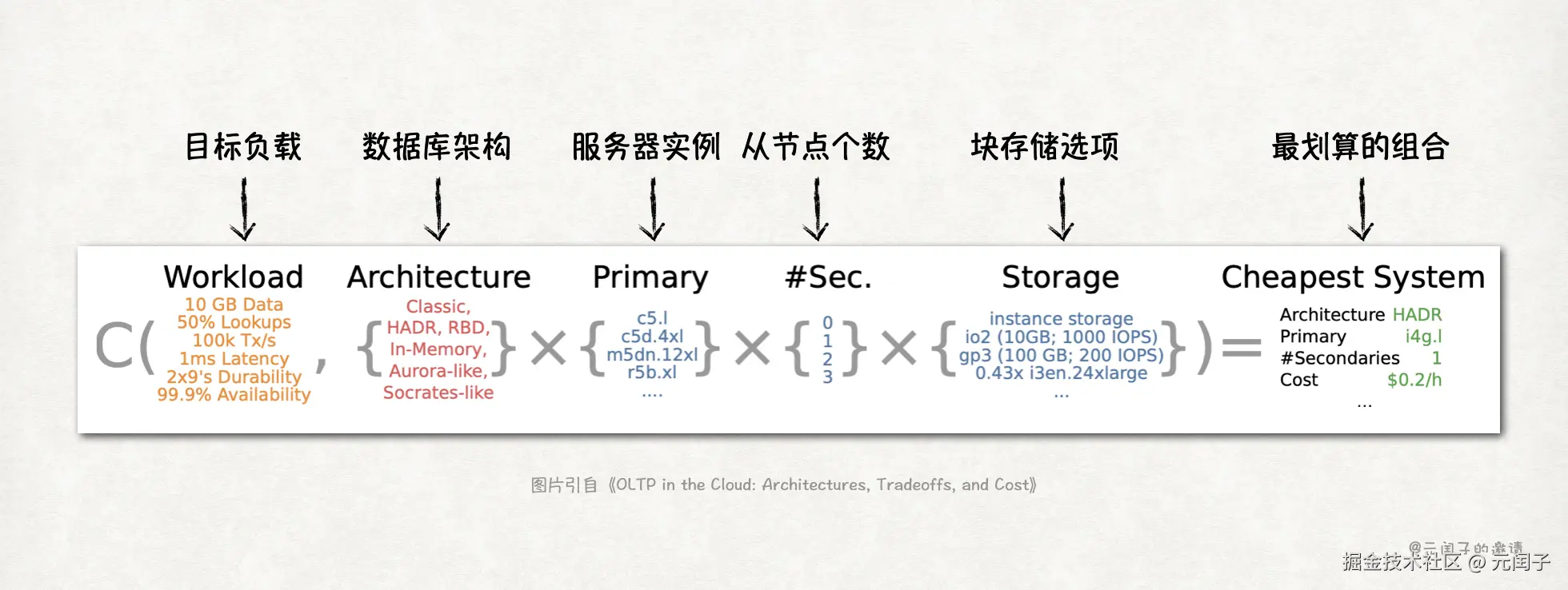
下面是量化模型的假设:
-
假设数据库都使用 B-Tree 索引,page 大小为 4K。
-
每个 CPU 核每秒处理的事务数固定,忽略锁开销。(不影响结果结果评估)
-
不考虑客户端与服务端之间的网络开销,只考虑数据库内部的网络流量。
-
只保留最近 1 小时的 WAL 文件。
-
服务器实例的 90% 内存可用作数据库缓存。
-
只读节点数量最多为 3 个。
-
硬件资源有限满足更新事务,有剩余的留给读事务。
模型的目标负载主要考虑如下几个维度:
目标负载
单位
取值范围
数据集大小
byte
10GB - 100TB
事务处理速率
tx/s
1k/s - 100M/s
读事务占比
%
0% - 100%
持久化
9's/year
1x9 - 11x9
平均事务处理时延
us
1us - 1ms
可用性
容灾类型
Node, AZ, Region
硬件配置上,主要是服务器实例和存储,前者选择 AWS EC2 弹性实例,后者选择 AWS EBS 块存储服务,都有多种配置可选。
要快速找到最划算的组合,关键是能够评估出指定架构在指定的硬件下能够达到的真实负载水平。如果可以满足目标负载,则该组合可行,记录对应的成本。这样就能对比所有组合的成本,找到最划算的组合。
下面以 Classic 架构为例,介绍模型的评估算法。

评估算法可表示为 S = computeClassicProperties(W, N):
-
输入 W 表示目标负载,包含数据本身大小 W_{dbSize} (单位:byte), WAL Record 大小 W_{ariesRecordSize} (单位:byte),WAL 是否采用 group commit W_{groupCommit} (True/False),目标更新事务率 W_{reqUpdate} (单位:tx/s),目标读事务率 W_{reqLookups} (单位:tx/s)。
-
输入 N 表示硬件配置,包括存储容量大小 N_{storageCapacity} (单位:byte),单次 IO 数据大小 N_{maxIOSize} (单位:byte),最大随机读 IOPS N_{readOps} (单位:ops/s),最大随机写 IOPS N_{writeOps} (单位:ops/s),CPU 每秒的周期数 N_{cpuCycles},内存容量大小 N_{memoryCapacity} (单位:byte)。
-
输出 S 表示真实负载水平,包含更新事务性能 S_{update} (单位:tx/s),读事务性能 S_{lookups} (单位:tx/s), 持久化能力 S_{durability} (单位:9's/year)和事务平均时延 S_{opLatency} (单位:us)。
如果 S < W,说明此组合无法满足目标负载。
以下为算法详细介绍:
**1:**首选要判断硬件的存储容量是否够用。Classic 架构的存储包含了数据本身大小 W_{dbSize} 和 最近 1 小时内 WAL 文件大小 ariesLogStorage。其中,ariesLogStorage = W_{ariesRecordSize} * W_{reqUpdate} * 3600s。
**2:**Classic 架构在处理更新请求时,如果对应 page 不在内存中,还需先从磁盘读上来,涉及 1 次读操作。因此,每次更新事务所需的读操作数 readsPerUpdate 等于缓存缺失率 p(cacheMiss),可近似为 N_{memoryCapacity}/W_{dbSize}。
**3:**logWritesPerUpd 为每次更新写入 WAL 的 IO 次数。如果设置了 group commit,则 WAL Record 会累计到 N_{maxIOSize} 大小后批量写入,否则,每次更新都会写 1 次。
**4:**writesPerUpdate 为每次更新的 IO 次数,等于 p(dirtyPageEvict) + logWritesPerUpd。其中,p(dirtyPageEvict) 为 dirty page 回写的概率,近似为 更新事务占比*p(cacheMiss),这是因为数据会优先写到内存中的 page,如果缓存缺失,则需要从磁盘读上来,并与内存中的 page 替换,若被替换的是 dirty page,则需要回写到磁盘。
**5:**限制 S_{update} 不能达到目标性能 W_{reqUpdate} 的原因,可能是读 IO 瓶颈,此时它为 N_{readOps}/readsPerUpdate;也可能是写 IO 瓶颈,此时它为 N_{writeOps}/writesPerUpdate;也可能是 CPU 瓶颈,此时它为 N_{cpuCycles}/cpuCyclesPerTx,其中每次事务所需的 CPU 周期数 cpuCyclesPerTx = 4000 ,通过在 In-Memory 数据库 LeanStore 下实测结果,并考虑在不同服务器实例下的通用性,最后保守评估的值。包含了计算和访存。
**6-11:**基于计算 S_{update} 后剩余的资源,按照同样的方法,计算 S_{lookups}。
**12:**Classic 架构的数据都存在本地 SSD,因此 S_{durability}=1-AFR_{SSD},其中 AFR_{SSD} 为本地 SSD 的年化故障率(Annualized Failure Rate)。
**13:**其中,memoryOpLatency 和 nvmeReadLatency 都是经过实测评估出来,分别为 2us 和 132us。
其他架构的量化评估算法大同小异。
比如,HADR 架构处理更新事务时,还需通过网络将 WAL 复制给所有从节点,因此在计算 S_{update} 时还需考虑网络瓶颈,若为网络瓶颈,则 S_{update}=N_{networkOutLimit}/networkOutPerUpdate,其中 networkOutPerUpdate = W_{logRecordSize} ∗ numSecondaries,N_{networkOutLimit} 为网络带宽。
量化评估结果
事务处理性能
在不同的目标事务处理速率(tx/s)与数据集大小的配置下,最划算的架构和硬件配置,以及对应成本如下所示:

上图的右侧是不同架构对比在同等配置下最低成本架构的,成本比。
1表示本身为最低成本的架构,1.2表示该架构的成本是成本最低架构的1.2倍。
结论 1:RBD 架构在高事务处理速率的场景,成本会变得非常昂贵。
主要因为当事务处理速率增加时,数据库需要执行更多的读写操作,这意味着远程块设备必须配置更高的 IOPS。而云服务商(如AWS)对单个服务器实例所能支持的 EBS 设备数量、总带宽和 IOPS 都有严格的限制。这意味着,处理更高的 IOPS 通常需要更大、更昂贵的实例。
结论 2:HADR 架构在扩展性上存在较大的局限性,仅在极少数场景具备成本效益。
即使在胜出的 3 个场景中,HADR 成本对比其他架构也没有明显的优势。
结论 3:Socrates-like 架构是在满足中等持久化要求(99.9%)下,在大多数场景都是成本效益最好的选择。
结论 4:Aurora-like 架构因为 SSD 多副本的原因,在数据集较大时,成本效益较低。
比如,在 100TB + 1K tx/s 的场景,Aurora-like 架构对比最好的 RBD 架构成本要贵 2.3 倍。
结论 5:ARM 服务器实例对比 x86 服务器实例,成本更优。
比如,论文提到,在 1TB + 100K tx/s 的场景,同等的事务处理性能下,ARM 实例对比 Intel 实例,成本要低 13%。
可靠性(持久化)能力
在不同的目标事务处理速率(tx/s)、数据集大小的配置下,满足不同可靠性要求的,最划算的架构以及对应成本如下所示:

结论 6:Aurora-like 架构适合那些需要满足 11x9's 的高可靠性场景。
主要得益于 Aurora-like 架构的多副本设计。
结论 7:在不需要高可靠的场景,Classic 架构仍是最划算的一个。
可用性能力
只有 RBD、HADR、Aurora-like、Socrates-like 架构存在多节点,涉及可用性评估。
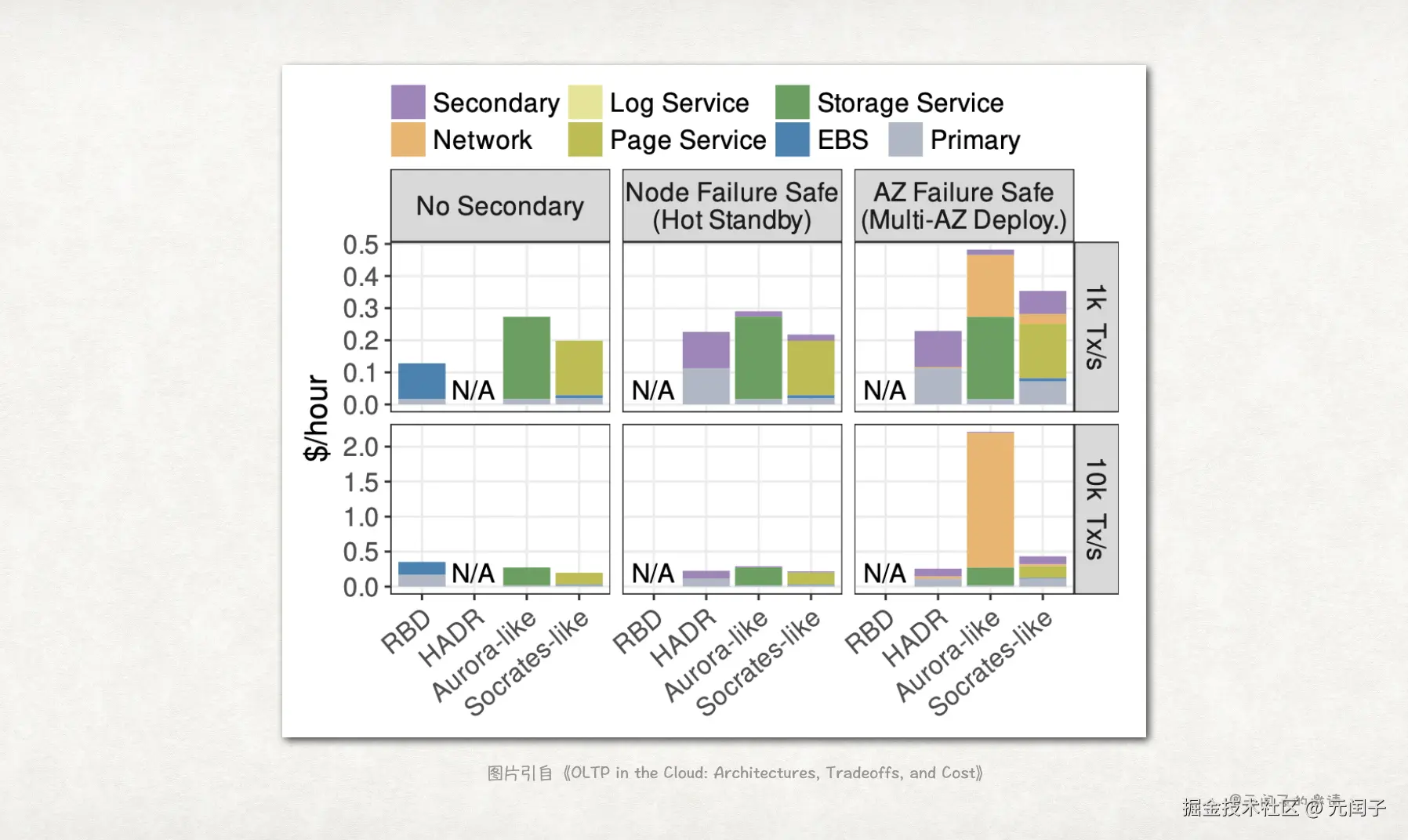
结论 8:跨 AZ 容灾时,Aurora-like 架构的网络将成为主要成本开销。
主要因为 Aurora-like 架构内计算节点和存储节点间存在较多的网络通信。
结论 9:Socrates-like 架构的 Page Server 主要用于增强可用性,而不是可靠性。
因为有本地 SSD 缓存的原因,即使是跨 AZ 容灾,Socrates-like 架构的网络成本也不高。
哪种事务成本更高?
观察不同的读和更新事务占比下的成本,结果如下:
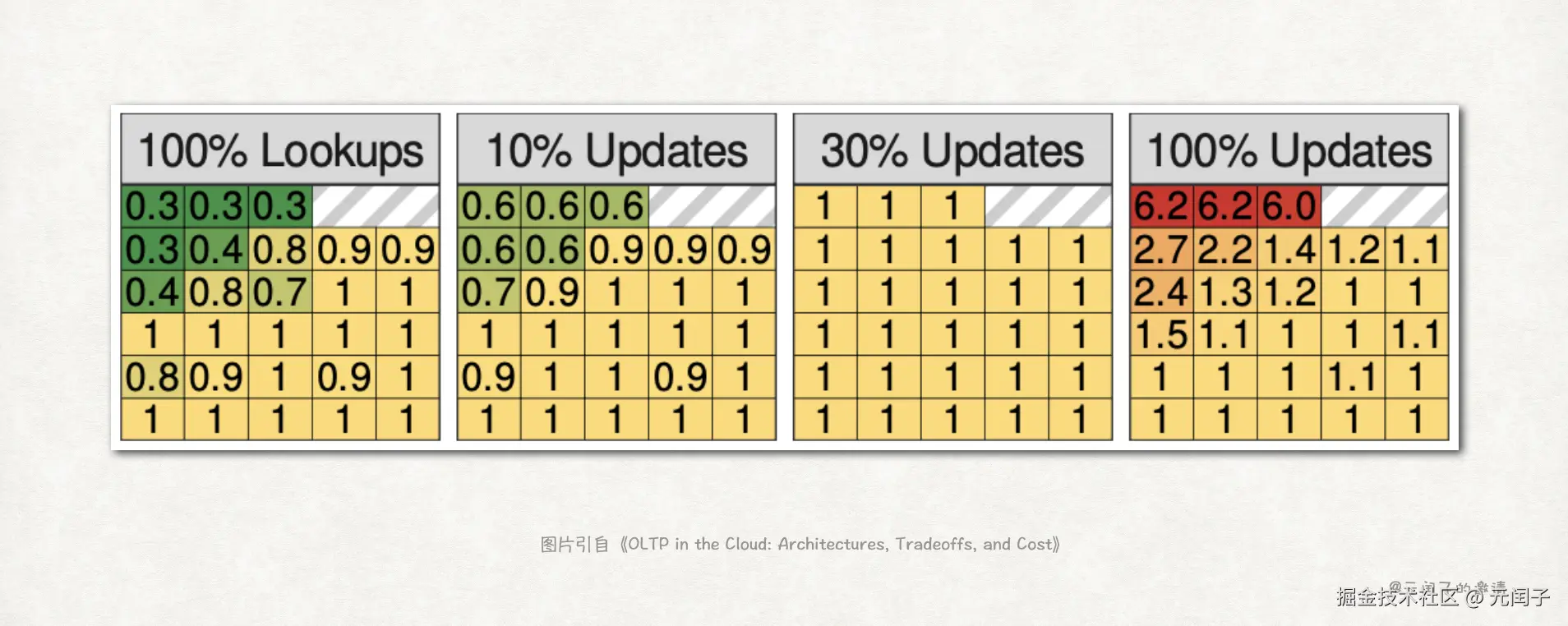
结论 10:更新事务通常比读事务有更高的成本,特别是在高事务处理速率和低数据集的场景。
事务时延与成本
下图为在保证不同事务时延(横坐标)的限制下,需要多大的成本曲线图:
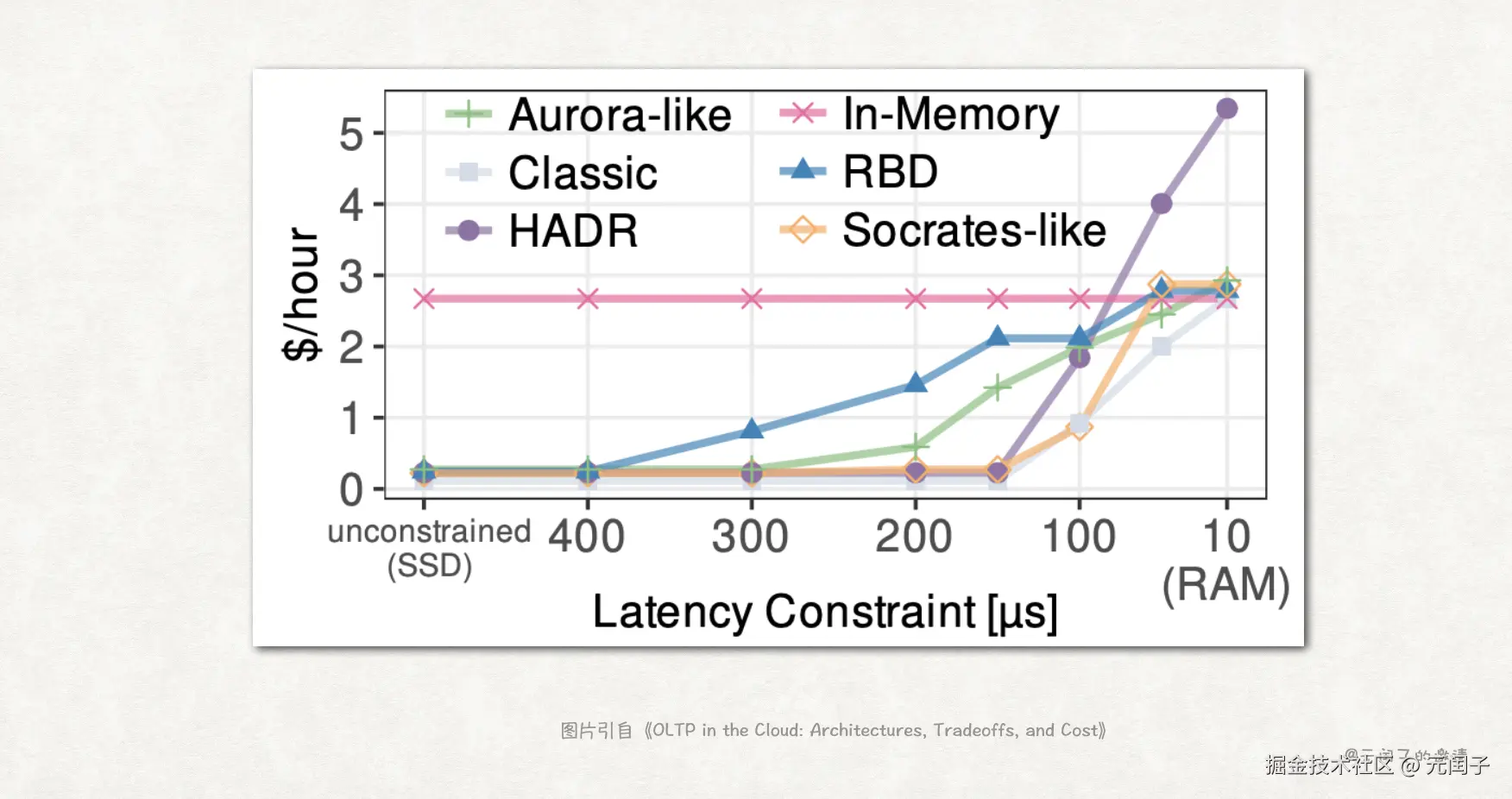
结论 11:云上 OLTP 数据库通过低成本 SSD 实现亚毫秒事务时延,而实现 100us 及更低的时延,需要更多的数据保存在内存里,带来了更高的成本。
考虑数据倾斜
上述所有分析都认为对数据库中的数据是均匀访问的,而在大多的真实业务中,都会存在数据热点。
因此,论文基于 Zipf 分布来建立数据访问模型,zipf factor 越大,表示数据热点越明显。
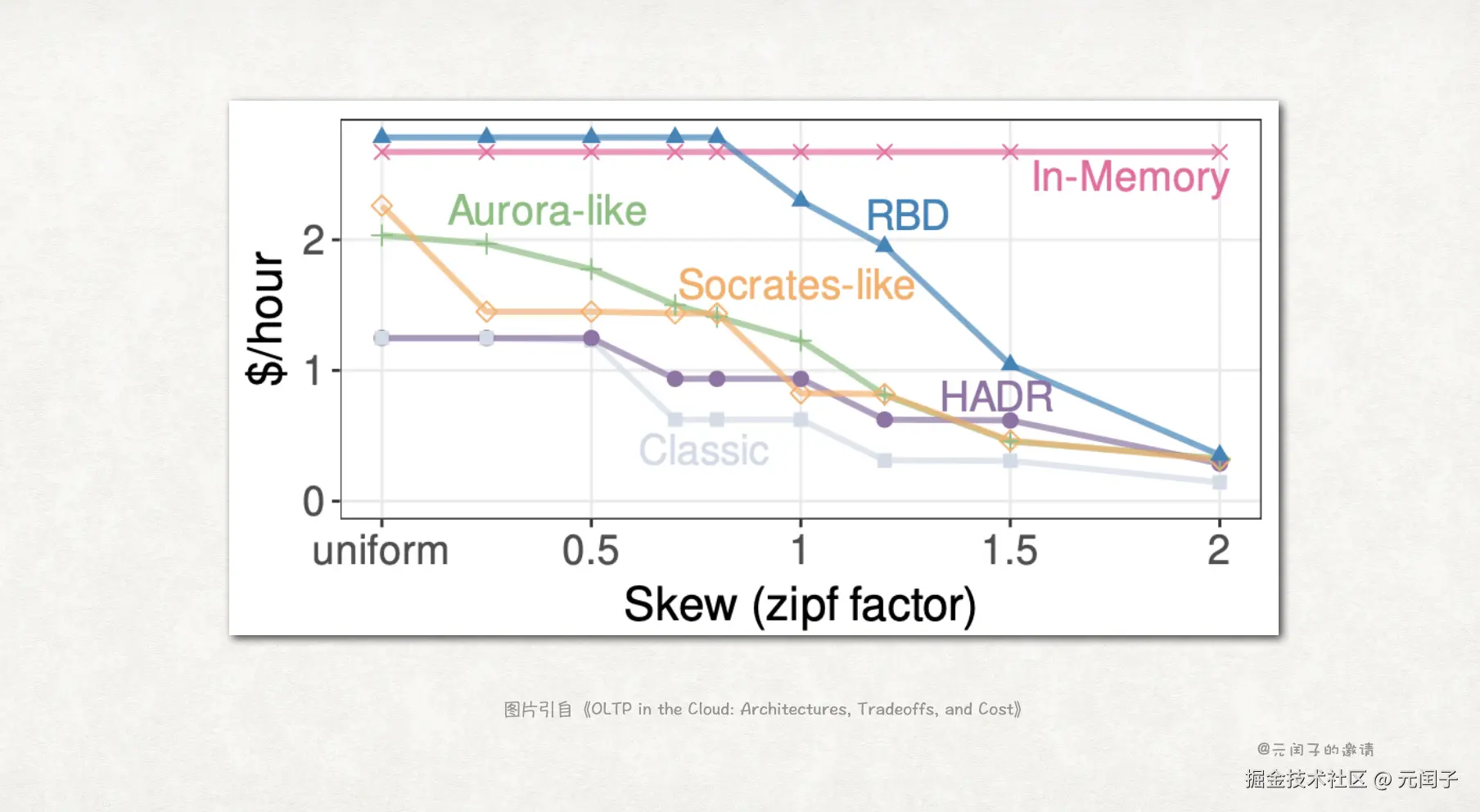
结论 12:除了 In-Memory 架构外,得益于空间局部性,热数据能降低成本。
最后
根据论文分析的结论,云原生架构(Aurora-like/Socrates-like)对比迁移上云的传统架构(Classic/RBD/In-Memory)更具备成本效益,它们能够处理更广泛的工作负载,同时提供高可用性和持久性。
在存储选择上,虽然 AWS S3 对象存储在存储成本上更低,但 IOPS 成本高出数量级;具备更高持久化能力的 EBS io2 同样面临 IOPS 成本高的问题;而 DRAM 存储成本则是遥遥领先。
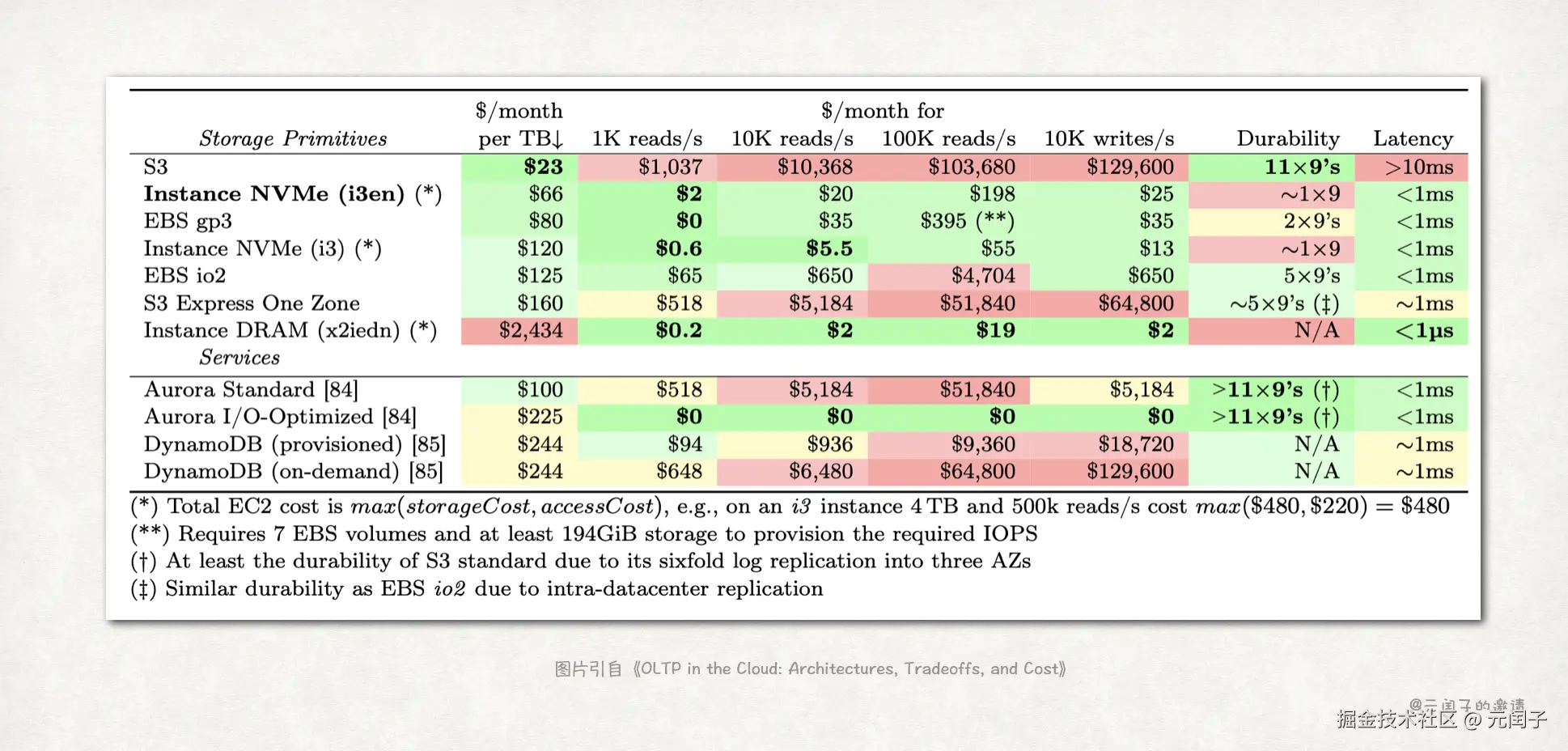
所以,NVMe SSD 是更好的 OLTP 主存选择。
另外,Aurora-like 和 Socrates-like 架构也还有改进空间。
Socrates-like 架构虽然分离了 Page Server 和 Log Server,但依赖远程块存储进行 WAL 持久化,限制了其可靠性和性能;
Aurora-like 架构将 WAL 实时流式负载到多个存储节点,在可靠性和性能上会更好,但 Page Server 和 Log Server 未拆分,导致灵活性和扩展性稍弱了一点。
可以把两者的优点结合在一起,Page Server 和 Log Server 分离。page 缓存在 Page Server 的本地 SSD 上;WAL 发送到多个 Log Server 上的本地 SSD 完成持久化;它们都用并用廉价的对象存储作为后端。
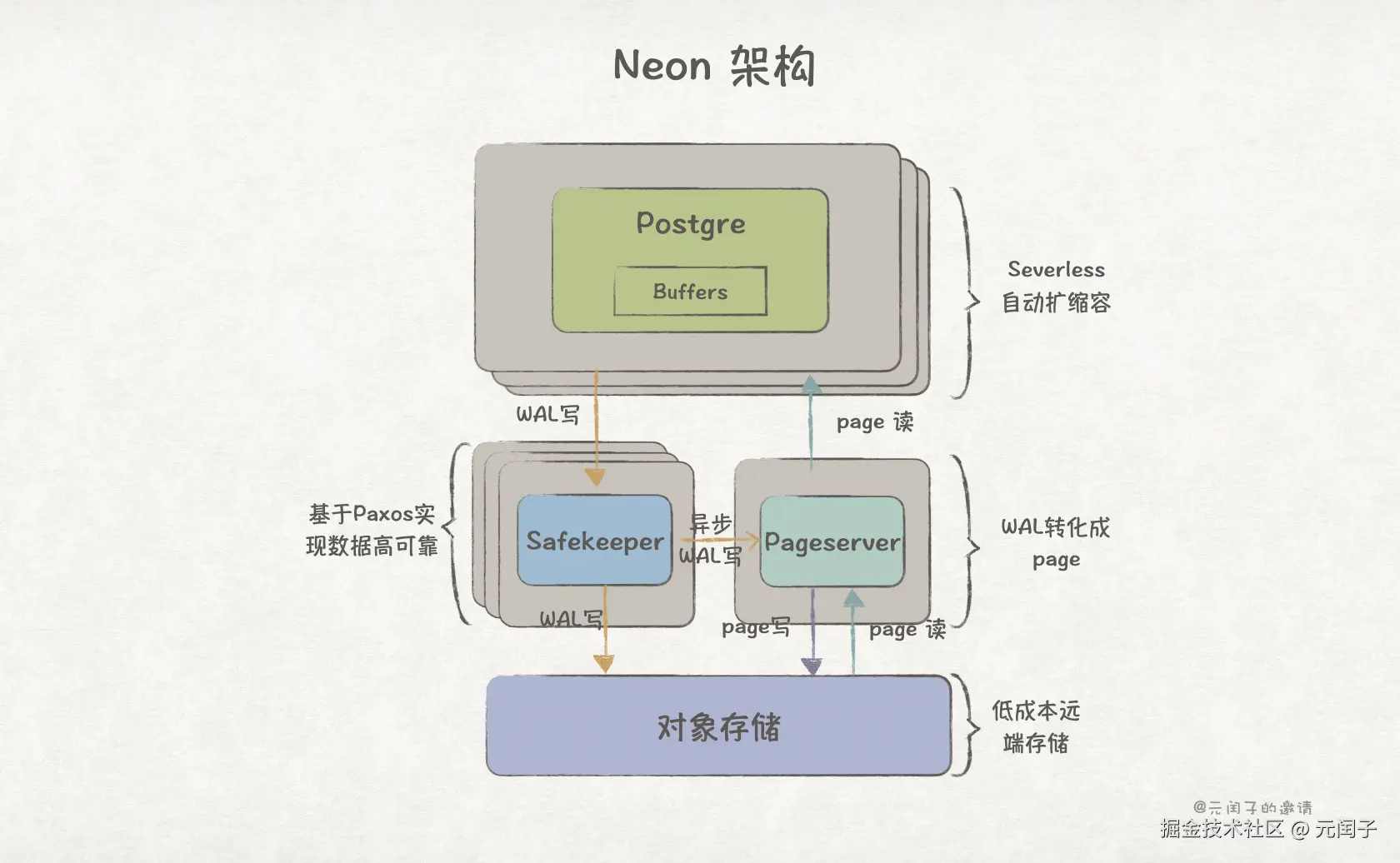
有点像 Neon 的架构了。
文章配图
可以在 用Keynote画出手绘风格的配图 中找到文章的绘图方法。
参考
1 OLTP in the Cloud: Architectures, Tradeoffs, and Cost, Salesforce
(完)