官方文档:https://www.litedb.org/docs/
本文基于版本"5.0.21"
一、什么是LiteDB?
1 LiteDB核心特性
- 嵌入式数据库:无需安装服务,直接嵌入Unity项目。
- 文档型存储:数据以BSON(类似JSON)格式存储。
- 跨平台支持:兼容Windows、Android、iOS、WebGL等。
- 零配置:自动创建和管理数据库文件。
2 为什么选择LiteDB?
- 轻量级:仅依赖单个DLL文件(约200KB)。
- C#原生风格:可以直接存取C#对象,使用LINQ查询,无需SQL 。
- 免费开源:MIT协议,可商用。
- 不依赖任何native库:完全C#实现,移植性强。
- NoSQL数据库:使用简单,极易上手。
二、什么是NoSQL数据库?
1 NoSQL的定义
- 非关系型数据库:无需预定义表结构,灵活存储JSON、键值对、文档等格式数据。
- 适用场景:游戏存档、实时数据分析、快速迭代开发、高扩展性需求。
2 NoSQL vs 关系型数据库
| 特性 | NoSQL(如LiteDB) | SQL(如MySQL) |
|---|---|---|
| 数据结构 | 文档/键值对/图等 | 固定表结构 |
| 扩展性 | 水平扩展 | 垂直扩展 |
| 查询语言 | 无统一标准(基于API) | SQL |
| 事务支持 | 最终一致性 | ACID事务 |
三、获取LiteDB
https://github.com/litedb-org/LiteDB
https://www.nuget.org/packages/LiteDB
1.在Unity中使用
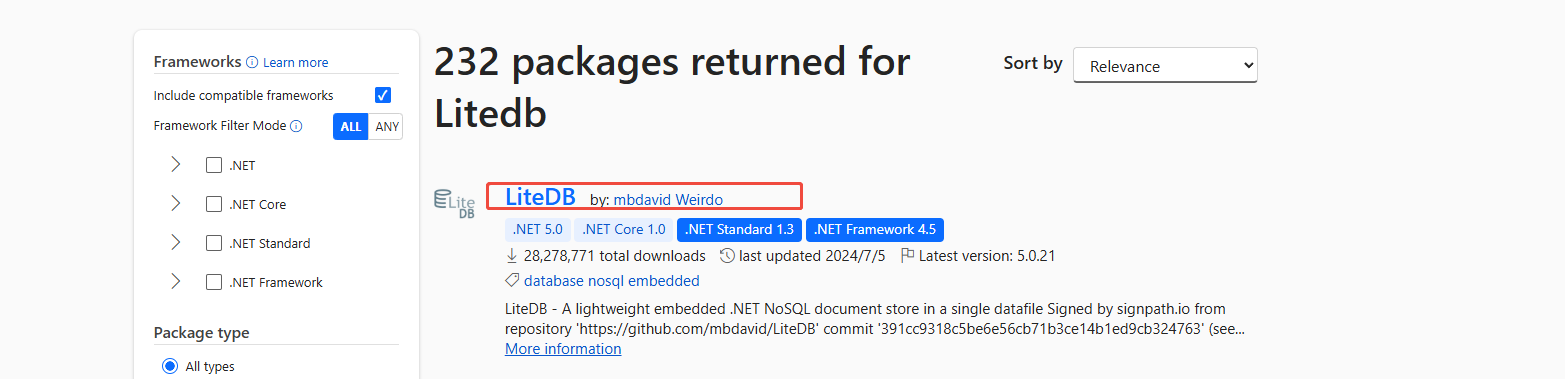
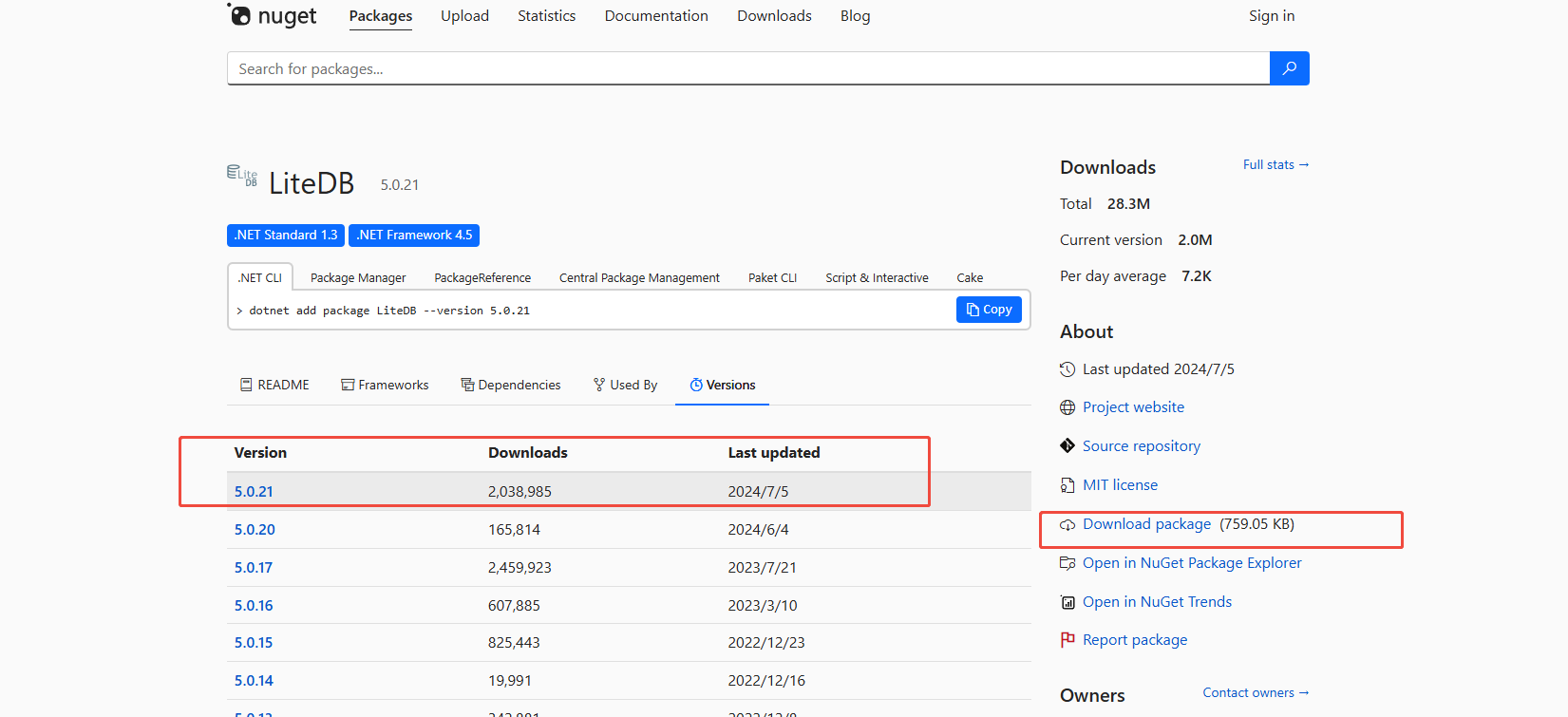

下载后解压(改下后缀),将DLL(litedb.5.0.21\lib\netstandard2.0)放入Plugins下就可以了
2.donet程序使用
直接使用Nuget包管理器获取

四、LiteDB的一些基础概念
cs
// 定义实体
public class Customer
{
public int Id { get; set; } // 客户编号(主键,自动递增)
public string Name { get; set; } // 客户名称
public string[] Phones { get; set; } // 客户的电话号码数组
public bool IsActive { get; set; } // 是否为活跃客户
}
// 打开数据库(如果不存在则创建)
using(var db = new LiteDatabase(@"C:\Temp\MyData.db"))
{
// 获取一个集合(如果不存在则创建),名称为 "customers"
var col = db.GetCollection<Customer>("customers");
// 创建一个新的客户对象实例
var customer = new Customer
{
Name = "John Doe",
Phones = new string[] { "8000-0000", "9000-0000" },
IsActive = true
};
// 插入新的客户文档(Id 会自动递增)
col.Insert(customer);
// 更新集合中的某个文档
customer.Name = "Jane Doe"; // 修改客户名称
col.Update(customer); // 更新该文档
// 为 Name 属性创建索引(提升查询效率)
col.EnsureIndex(x => x.Name);
// 使用 LINQ 查询文档(筛选、排序、转换)
var results = col.Query()
.Where(x => x.Name.StartsWith("J")) // 以 J 开头的名称
.OrderBy(x => x.Name) // 按名称排序
.Select(x => new { x.Name, NameUpper = x.Name.ToUpper() }) // 投影成匿名对象
.Limit(10) // 限制最多返回 10 条
.ToList();
// 为电话号码属性创建索引(多键索引,支持数组元素查找)
col.EnsureIndex(x => x.Phones);
// 查询是否包含指定电话号码
var r = col.FindOne(x => x.Phones.Contains("8888-5555"));
}这是一个官方示例,借此我们介绍几个概念.
数据库:示例提到打开或创建数据库,一个数据库对应一个.db文件,我们可以创建多个数据库.
集合 :从数据库获取获取或创建一个集合,上述例子中就是一个顾客集合,里面有很多数据,标准点说里面有很多文档.
文档(document):对象被序列化为BSON格式后,我们称它为文档.所以LiteDB也被称为文档数据库.
文档是一个重要概念,后面会详细介绍.
主键:确保数据的唯一性.上述类的Id属性就是主键,只要你声明了名为Id的属性,该属性就被默认当做主键,声明为int类型会自动递增.
索引:示例中为Name字段创建了索引,为字段创建索引之后,在大量数据查询某个文档的时候,可以帮助我们大大缩短查询时间
五、BSON和Extended JSON
BSON
LiteDB 使用 BSON(Binary JSON) 格式存储数据。每一条数据记录在 LiteDB 中称为一个"文档",本质上就是一个 BSON 。
文档是一种无模式(schemaless)的结构,它既包含数据,也包含结构定义。BSON 是 JSON 的二进制扩展形式,具备更多类型支持(如日期、二进制、ObjectId 等),并能嵌套文档和数组,适合高效存储和传输。

cs
var customer = new Customer { Id = 1, Name = "John Doe" };
BsonDocument doc = BsonMapper.Global.ToDocument(customer);在刚才的代码示例中我们直接将对象插入到一个集合里面,实际上里面隐式进行了转化,将对象映射为BsonDocument类型,然后序列化为BSON. 实际使用了该方法进行了转化.
可以看到BSON和JSON很像,但是有一些差别:JSON只能存储基本结构,但是BSON除了基本结构还能存储一些别的类型的数据,比如createDate键存储了DataTime值.
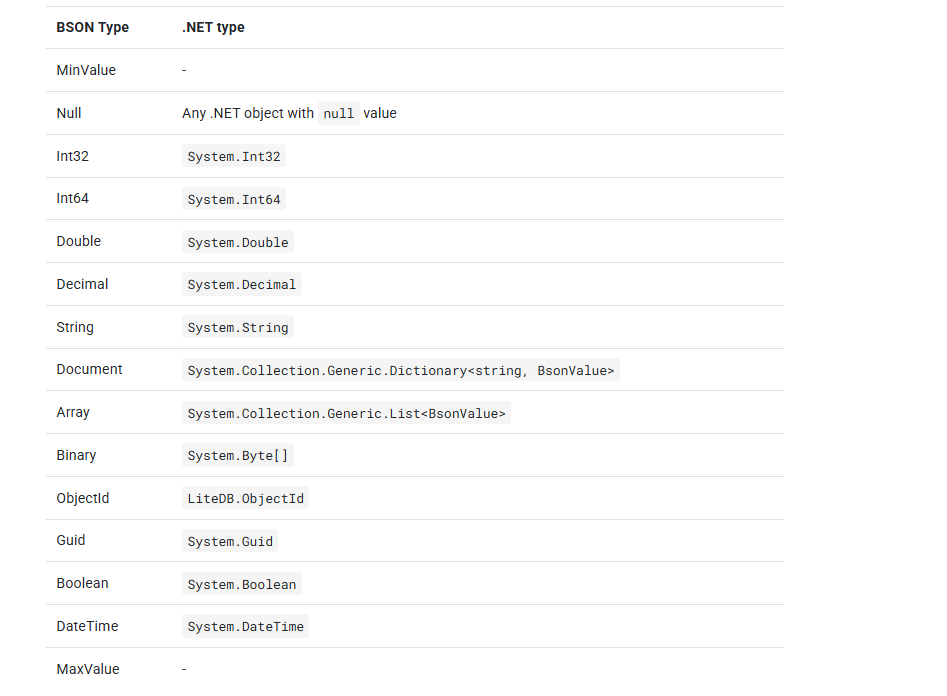
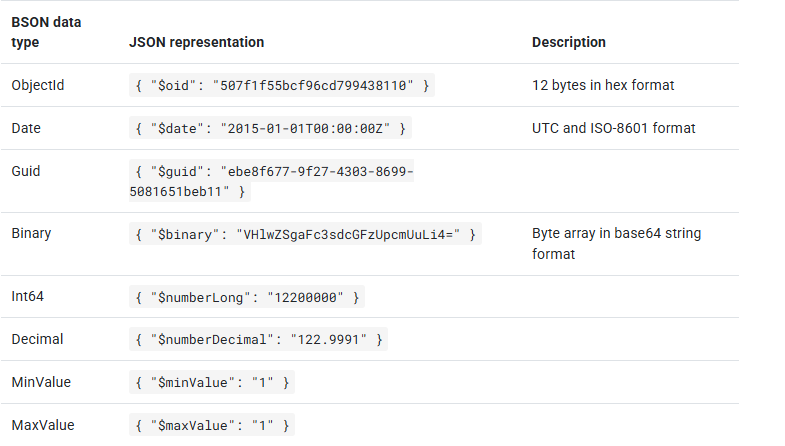
BSON规范不是LiteDB制定的(实际来自MongoDB),LiteDB也只是使用了BSON规范的一部分,下图是对照关系.
Extended JSON
该结构其实不是真正的BSON,因为BSON是二进制的,该结构其实是将BSON转化为Extended JSON.
仔细看该结构,是完全符合JSON标准的,但是有些地方比较奇怪:JSON支持的比如int,array的类型,Extended JSON和JSON没有区别,但是JSON是不支持DataTime类型,所以你可以看到键加了一个$,值使用字符串,这个巧妙地设计即不违反JSON规范,又因为有特殊标识符,使Extended JSON能认出JSON不支持的类型.下面列出这些被拓展的类型.
你可能感到奇怪,我似乎只考虑BSON和对象之间的转换就够了啊,怎么又搞出一个拓展JSON?
其实还是很有必要的, 比如在调试,日志,配置,导出,跨平台通讯等情况时,我们就需要将BSON转成JSON,而且必须是经过拓展的JSON.
比如调试的时候你总不能看二进制的BSON吧!
ObjectId
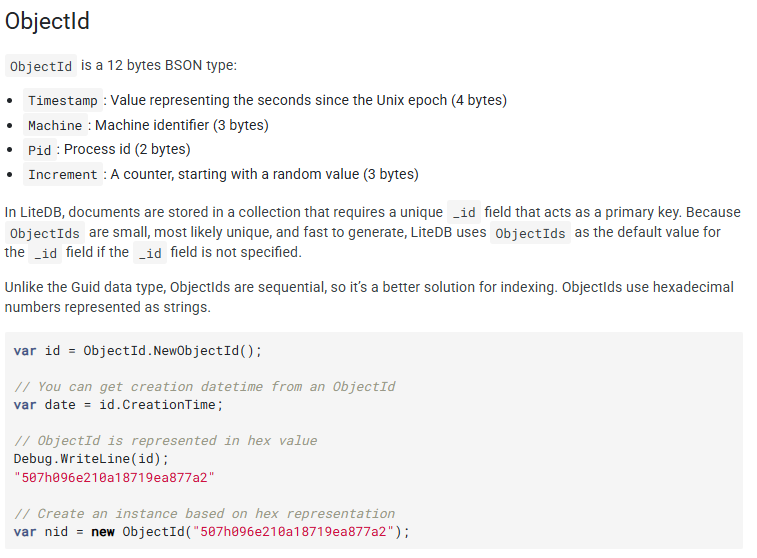
上述类型中基本都是常见类型,这里介绍一下ObjectId类型.
每个集合里面的数据必须是唯一的,所以使用主键来确保数据的唯一性.比如你的数据实体声明了Id属性,那么Id自动被认为是主键,如果是int类型会自动帮你自增(如果你没主动赋值),如果你声明为字符串类型,那么也会被认为是主键,但是需要你自己确保数据的唯一性(不推荐).
ObjectId是专门设计出来作为主键类型的,使用了12个字节(通过各种设计来保证唯一性),这点不过多介绍,我只将其类比于GUID,能保证数据的唯一性就够了.感兴趣它是怎么设计的,请看下面的官网原文.
强烈推荐使用ObjectId作为主键.
六、Object Mapping
cs
public class Customer
{
public ObjectId CustomerId { get; set; }
public string Name { get; set; }
public DateTime CreateDate { get; set; }
public List<Phone> Phones { get; set; }
public bool IsActive { get; set; }
}
//强类型集合
var typedCustomerCollection = db.GetCollection<Customer>("customer");
// 不指定类型
var schemelessCollection = db.GetCollection("customer"); LiteDB 集合类型与映射机制简要总结
-
强类型集合
使用
GetCollection<T>()明确指定类型,只能插入该类型的对象。LiteDB 会先将对象映射(通过使用BsonMapper类)为BsonDocument,再序列化为 BSON 存储。这里的映射是自定义类型和BsonDocument类型之间的映射 -
无类型集合
使用
GetCollection()不指定类型,等价于GetCollection<BsonDocument>(),字段结构更灵活,适合动态数据。 -
底层统一存储结构
无论使用哪种方式,LiteDB 最终存储的都是
BsonDocument类型序列化的Bson。强类型集合只是为了开发时提供类型安全和更好的开发体验。 -
适用场景
-
强类型集合:结构固定、逻辑清晰,适合大部分业务系统。
-
无类型集合:结构不确定或动态字段,适合灵活场景或通用存储。
-
-
类型互转示例
csvar doc = mapper.ToDocument(customer); // 对象 → 文档 var obj = mapper.ToObject<Customer>(doc); // 文档 → 对象 -
自定义映射器
csvar mapper = new BsonMapper(); var db = new LiteDatabase("my.db", mapper); // 使用自定义映射规则 -
注意事项
-
无类型集合需手动处理字段和类型;
-
映射遵循默认规则(Id、BsonIgnore、BsonField 等);
-
可通过属性或 Fluent API 自定义映射逻辑。
-
映射约定
BsonMapper.ToDocument() 自动将类中的每个属性按下列约定转化为文档字段
(1)属性既可以是只读的也可以是可读可写的
(2)类中应有一个 Id 属性做主键,可以是以下几种形式之一:
-
名为
Id的属性 -
名为
<类名>Id的属性(例如CustomerId) -
使用
[BsonId]属性标记的任意属性 -
或者通过 Fluent API 映射的属性
(3)使用 [BsonIgnore] 标记的属性不会被映射到文档字段
可以用它排除一些不需要存储的字段。
(4)使用 [BsonField("字段名")] 可以自定义文档字段的名字
如果你不想用属性名作为字段名,可以用这个属性进行重命名。
(5)不允许存在循环引用
LiteDB 不支持对象之间的相互引用(例如 A 包含 B,B 又包含 A)。
(6)默认最多支持 20 层嵌套类(嵌套深度限制)
可以通过 BsonMapper 修改这个限制。
(7)
你可以使用全局 BsonMapper.Global 实例,或者自己创建一个 BsonMapper 实例并传入 LiteDatabase 构造函数中
建议你把这个自定义映射器保存在一个地方重复使用,避免每次打开数据库时重新创建映射配置。
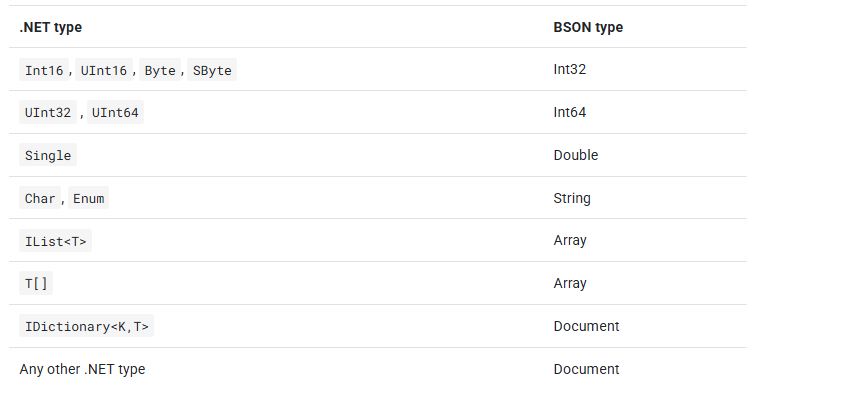
除了BSON的基本类型,BsonMapper还将其他.NET类型映射为BSON数据类型,如下
LiteDB 支持使用 Nullable<T> 类型(即 int?、DateTime? 等)。
-
如果属性的值是
null,它会被映射为 BSON 的Null类型; -
如果有值,则会把它当作普通的
T类型来映射。
LiteDB 也支持将 IDictionary<K, T> 类型的属性映射为 BSON 的对象(类似 JSON 的嵌套对象),但有以下限制:
-
键(Key)必须是字符串,或者是可以通过
Convert.ToString(...)转换为字符串的简单类型 (如int,enum,Guid等); -
值(Value)可以是任意类型
T,LiteDB 会继续递归映射。
注意:
-
如果你使用了
Dictionary<int, string>这样的类型,LiteDB 会自动尝试调用Convert.ToString(int)来生成字符串键; -
但如果是复杂类型(如自定义对象)作为键,则 不被支持,因为 BSON 的 key 必须是字符串。
反序列化所使用的构造器
cs
public class Customer
{
public ObjectId CustomerId { get; }
public string Name { get; }
public DateTime CreationDate { get; }
public bool IsActive { get; }
public Customer(string name, bool isActive)
{
CustomerId = ObjectId.NewObjectId();
Name = name;
CreationDate = DateTime.Now;
IsActive = true;
}
[BsonCtor]
public Customer(ObjectId _id, string name, DateTime creationDate, bool isActive)
{
CustomerId = _id;
Name = name;
CreationDate = creationDate;
IsActive = isActive;
}
}
var typedCustomerCollection = db.GetCollection<Customer>("customer");通过GetCollection<T>获取集合进而取对象的时候,Litedb需要使用T类型的构造器来反序列化.
遵循下列顺序:
(1)首先会寻找被显示添加了BsonCtorAttribute的构造器( 该构造器的参数必须是简单类型,BsonDocument或者BsonArray**)**
(2)没找到则会尝试寻找无参构造器(并假定所有属性都是公共的和可写的)
(3)最后会尝试寻找参数名和文档字段名匹配的构造器
AutoId
内置的自动生成主键的方法如下:
-
ObjectId:ObjectId.NewObjectId() -
Guid:Guid.NewGuid() -
Int32/Int64: 自增
LiteDB 在插入文档的时候,如果你没有自己设置 _id 字段的值 ,它才会自动帮你生成 _id。否则,它就用你提供的 _id。
如果你是用强类型(例如一个 Customer 类),你即使定义了 Id 属性,但它是空的(默认值),LiteDB 也会当成"你没有设置",于是它就自动给你生成一个。
自动赋值的前提是:你的 Id 字段必须能"被 LiteDB 设置"。
LiteDB 中的自增整数 ID(比如 int 类型)不是永久保存在数据库文件中的,它是"内存里临时生成的序列"。
例如:
-
你插入了 5 条数据,ID 分别是:1, 2, 3, 4, 5;
-
然后你删掉了 ID = 5 的那条数据;
-
然后你关闭并重新打开数据库;
-
再插入新数据,它很可能又用 ID = 5(不是 6!)
因为 LiteDB 不保存"当前自增值",它每次启动会从当前集合中已有的最大值重新开始。
所以推荐使用ObjectId或者Guid
Fluent Mapping
为自定义类做配置,推荐使用Fluent Api
cs
var mapper = BsonMapper.Global;
mapper.Entity<MyEntity>()
.Id(x => x.MyCustomKey) // set your document ID
.Ignore(x => x.DoNotSerializeThis) // ignore this property (do not store)
.Field(x => x.CustomerName, "cust_name"); // rename document field七.集合
文档数据保存在集合中,并以集合为单位进行组织。LiteCollection<T> 是 LiteDB 用于管理集合的泛型类。
命名规则
每个集合都必须有一个唯一的名称,命名规则如下:
| 限制 | 描述 |
|---|---|
| ✅ 只包含 | 字母、数字和下划线 _ |
| ✅ 不区分大小写 | Customer 和 customer 是同一个集合 |
❌ 不能以 _ 开头 |
_xxx 是 LiteDB 的内部系统集合 |
❌ 不能以 $ 开头 |
$xxx 是系统保留集合(如虚拟集合) |
总集合名的限制
一个数据库中,所有集合名的总长度 不能超过 8000 字节 。如果每个集合名平均长度为 10 字节,你最多只能有约 800 个集合 。如果你打算有很多集合,建议使用短名字,如 usr, log, msg,避免用过长的名字。
集合的创建机制
只有执行插入(Insert)或建索引(EnsureIndex)时,集合才会被自动创建。如果集合不存在,仅执行查询(Find)、删除(Delete)、更新(Update)不会自动创建集合。
关于 LiteCollection<T> 泛型类
LiteCollection<T> 可以使用 T = BsonDocument 实现无结构(Schema-less)文档管理。
-
LiteCollection<BsonDocument>用于手动构建字段灵活的文档。 -
LiteCollection<MyClass>则用于强类型管理,LiteDB 内部会将MyClass自动映射为BsonDocument。
示例
cs
// Typed collection
using(var db = new LiteDatabase("mydb.db"))
{
// Get collection instance
var col = db.GetCollection<Customer>("customer");
// Insert document to collection - if collection does not exist, it is created
col.Insert(new Customer { Id = 1, Name = "John Doe" });
// Create an index over the Field name (if it doesn't exist)
col.EnsureIndex(x => x.Name);
// Now, search for your document
var customer = col.FindOne(x => x.Name == "john doe");
}
// Untyped collection (T is BsonDocument)
using(var db = new LiteDatabase("mydb.db"))
{
// Get collection instance
var col = db.GetCollection("customer");
// Insert document to collection - if collection does not exist, it is created
col.Insert(new BsonDocument{ ["_id"] = 1, ["Name"] = "John Doe" });
// Create an index over the Field name (if it doesn't exist)
col.EnsureIndex("Name");
// Now, search for your document
var customer = col.FindOne("$.Name = 'john doe'");
}这两个最终都操作的是名为 "customer" 的集合,只是使用方式不同 ,但数据本质上都是以 BsonDocument 形式存储。
这里只有一个集合,只是使用方式不同,因为集合里面最终存储的是文档,文档是不分类型的无约束的,所以理论上你使用第二种使用形式往里面存什么都是可以的,但是可能出现错误,所以推荐第一种使用方法.
LiteDB 系统集合说明(System Collections)
系统集合是 LiteDB 内部提供的特殊集合,用于查看数据库的元数据和运行状态。所有系统集合的名称都以 $ 开头,除 $file 外,其他系统集合都是 只读 的。
这些系统集合不需要你手动创建,是数据库运行时自动维护的。
适合用于调试、监控、自动化分析 LiteDB 文件结构。
| 集合名 | 说明 |
|---|---|
$cols |
显示数据库中的所有集合,包括系统集合。 |
$database |
显示数据库的基本信息,如版本、大小等。 |
$indexes |
列出所有集合的索引信息。 |
$sequences |
列出所有自增序列(用于 Int/Long 类型的 AutoId)。 |
$transactions |
显示当前打开的事务(如果有)。 |
$snapshots |
列出现有的快照(用于并发读)。 |
$open_cursors |
列出当前打开的游标(用于调试目的)。 |
$dump(pageID) |
显示指定页(或所有页)的详细内部信息。可用于调试或分析数据结构。 |
$page_list(pageID) |
显示指定页(或所有页)的简要信息。更简洁的页视图。 |
$query(subquery) |
可以传入查询字符串,返回该查询的结果,类似子查询(试验性功能)。 |
$file(path) |
是唯一可以写入的系统集合,用于存储文件数据(例如 GridFS)。 |
八.BsonDocument
该类是Litedb对于文档的实现类,该类内部使用Dictionary<string, BsonValue>来存储键值对.
cs
var customer = new BsonDocument();
customer["_id"] = ObjectId.NewObjectId();
customer["Name"] = "John Doe";
customer["CreateDate"] = DateTime.Now;
customer["Phones"] = new BsonArray { "8000-0000", "9000-000" };
customer["IsActive"] = true;
customer["IsAdmin"] = new BsonValue(true);
customer["Address"] = new BsonDocument
{
["Street"] = "Av. Protasio Alves"
};
customer["Address"]["Number"] = "1331";LiteDB支持对象被序列化后的BSON大小最大到16MB.
关于文档字段名(key):
-
字段名不区分大小写(case-insensitive)
"Name"和"name"被认为是同一个字段名。 -
不允许重复字段名
文档中不能有两个键名一样的字段。
-
字段顺序保留(保持插入顺序)
除了
_id字段,它始终会被放在文档的第一个位置。其余会保持原始的顺序
关于字段值(value):
-
字段值支持的 BSON 数据类型 有:
Null、Int32、Int64、Decimal、Double、String、Document、Array、Binary、ObjectId、Guid、Boolean、DateTime、MinValue、MaxValue
-
字段值如果被建立索引,序列化成 BSON 后不能超过 1024 字节(≈1KB)。
-
_id字段的限制:-
不能是 Null、MinValue、MaxValue
-
因为
_id会默认建立唯一索引,所以也必须小于 1024 字节。
-
关于 .NET 中的类型映射:
LiteDB 提供了以下几个核心类来处理 BSON 值:
BsonValue
-
用来表示任意 BSON 数据类型(相当于 BSON 的"万能容器")。
-
提供隐式转换(可以直接用
string,int等赋值)。 -
值是不可变的(immutable)。
-
通过
.RawValue可以拿到底层的原始 .NET 值。
BsonArray
-
实现了
IEnumerable<BsonValue>,可以表示 BSON 数组。 -
数组中的每个值可以是任意 BSON 类型。
BsonDocument
-
表示嵌套文档。
-
即使字段不存在,也不会抛异常,而是返回
BsonValue.Null。
九.LiteDB 表达式(BsonExpression)
LiteDB 除了支持 C# lambda 查询 (collection.Find(x => x.Name == "Tom"))外,还提供了 表达式引擎(BsonExpression)。
表达式语法类似 JSONPath + SQL ,可以通过 $ 来定位文档字段,例如:
-
$.Name→ 获取Name字段 -
$.Books[*].Title→ 获取所有书的标题 -
$.Books[@.Price > 100]→ 获取价格大于 100 的书
表达式不仅能用于查询,还能用于 索引、更新、聚合,例如:
cs
collection.EnsureIndex("LOWER($.Name)"); var docs = collection.Find("$.Age > 18");和 lambda 不同的是:
-
Lambda 写法 → 类型安全,适合日常代码。
-
表达式写法 → 类似小型 SQL,适合做动态查询或脚本。
LiteDB 内部最终都会把 lambda 翻译成 BsonExpression 来执行,所以二者只是写法不同。
十.DbRef(文档引用)
LiteDB 的 DbRef(文档引用)
LiteDB 是文档数据库,不支持 SQL 的 JOIN 操作。如果你想在不同集合(表)之间建立关联,有两种方式:
-
嵌入文档(Embedded Document)
-
默认保存对象时,会把子对象直接嵌入到父文档里。
-
修改原集合的对象不会影响已保存的嵌入副本。
-
示例:
Order => { _id: 123, Customer: { CustomerId: 99, Name: "John Doe" } }
-
-
引用文档(DbRef)
-
只存对象的
_id和集合名,类似外键。 -
查询时可用
.Include()自动加载被引用对象,保持数据同步。 -
支持单个对象或列表/数组。
-
设置引用
-
属性标记方式:
public class Order { public int OrderId { get; set; } [BsonRef("customers")] public Customer Customer { get; set; } } -
Fluent API 方式:
BsonMapper.Global.Entity<Order>() .DbRef(x => x.Customer, "customers");
注意:被引用的类必须有主键
[BsonId],LiteDB 会用它来建立引用。
查询引用
var orders = db.GetCollection<Order>("orders");
var order1 = orders
.Include(x => x.Customer) // 自动加载 Customer
.FindById(1);-
对于列表引用也类似:
db.Query
()
.Include(x => x.Customer)
.Include(x => x.Products)
.ToList();
总结
-
嵌入文档:简单直接,数据冗余,适合不需要频繁更新的场景。
-
DbRef:只存引用,支持跨集合同步,适合对象被多处引用的场景。
| 特性 | 嵌入文档(默认) | 引用文档(DbRef) |
|---|---|---|
| 存储方式 | 把整个对象拷贝到文档里 | 只存对象的 _id 和集合名(类似外键) |
| 更新同步 | 不同步,修改原对象不影响已嵌入副本 | 同步,查询时可加载最新对象 |
| 数据冗余 | 高,重复存储对象数据 | 低,只存引用 |
| 查询加载 | 一次读取即可获取全部数据 | 需要 .Include() 才加载关联对象 |
| 使用场景 | 对象不会频繁变动,想一次性保存完整数据 | 对象可能被多处引用,需要保持最新状态 |
| 示例 | Order.Customer = { CustomerId: 1, Name: "John" } |
Order.Customer = { $id: 1, $ref: "customers" } |
十一.连接字符串
LiteDB 连接字符串(Connection String)
LiteDB 可以通过 连接字符串初始化数据库,格式为:
key1=value1; key2=value2; ...-
如果连接字符串中没有
=,LiteDB 会认为整个字符串是 数据文件路径(Filename)。 -
值中如果包含特殊字符(如
;或=),可以使用双引号"或单引号'包裹。 -
键和值 不区分大小写。
支持的选项
| Key | 类型 | 描述 | 默认值 |
|---|---|---|---|
Filename |
string | 数据文件完整或相对路径,支持 :memory:(内存数据库)或 :temp:(临时磁盘数据库,关闭时删除) |
必填 |
Connection |
string | 连接类型,"direct" 或 "shared" | "direct" |
Password |
string | 使用 AES 加密数据文件 | null(不加密) |
InitialSize |
string/long | 数据文件初始大小,支持单位 "KB/MB/GB" | 0 |
ReadOnly |
bool | 以只读模式打开数据文件 | false |
Upgrade |
bool | 如果数据文件是旧版本,打开前自动升级 | false |
连接类型
LiteDB 提供两种连接模式,会影响文件打开方式:
-
Direct(默认,推荐)
-
数据文件独占打开,直到
Dispose()才关闭。 -
更快、更可缓存,但同一文件不能被其他进程打开。
-
-
Shared
-
每次操作后关闭数据文件,用系统命名的 Mutex 做锁。
-
支持多进程访问,但性能比 Direct 慢。
-
仅在 .NET 实现支持命名 Mutex 的平台有效。
-
示例
配置文件:
cs
<connectionStrings>
<add name="LiteDB" connectionString="Filename=C:\database.db;Password=1234" />
</connectionStrings>C# 使用:
using System.Configuration;
var connStr = ConfigurationManager.ConnectionStrings["LiteDB"].ConnectionString;
using var db = new LiteDatabase(connStr);
cs
// 通过构造函数传连接字符串
using var db = new LiteDatabase(@"Filename=C:\Temp\MyData.db;Password=1234");
// 或者用命名参数(LiteDB 5+ 版本支持)
using var db2 = new LiteDatabase(new ConnectionString
{
Filename = @"C:\Temp\MyData.db",
Password = "1234"
});总结:
-
LiteDB 的连接字符串类似 键值对配置,可以控制文件路径、加密、初始大小、读写模式等。
-
选择 Direct 模式更快,Shared 模式适合多进程访问。