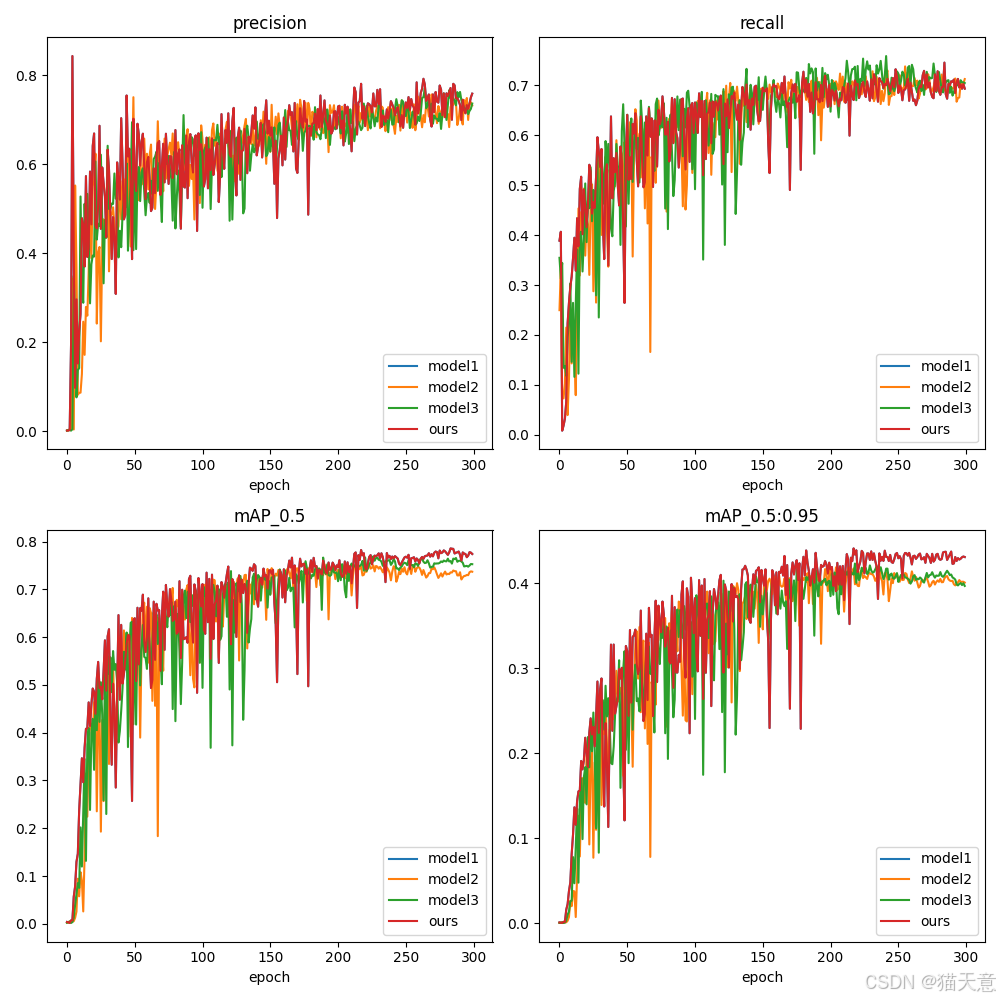
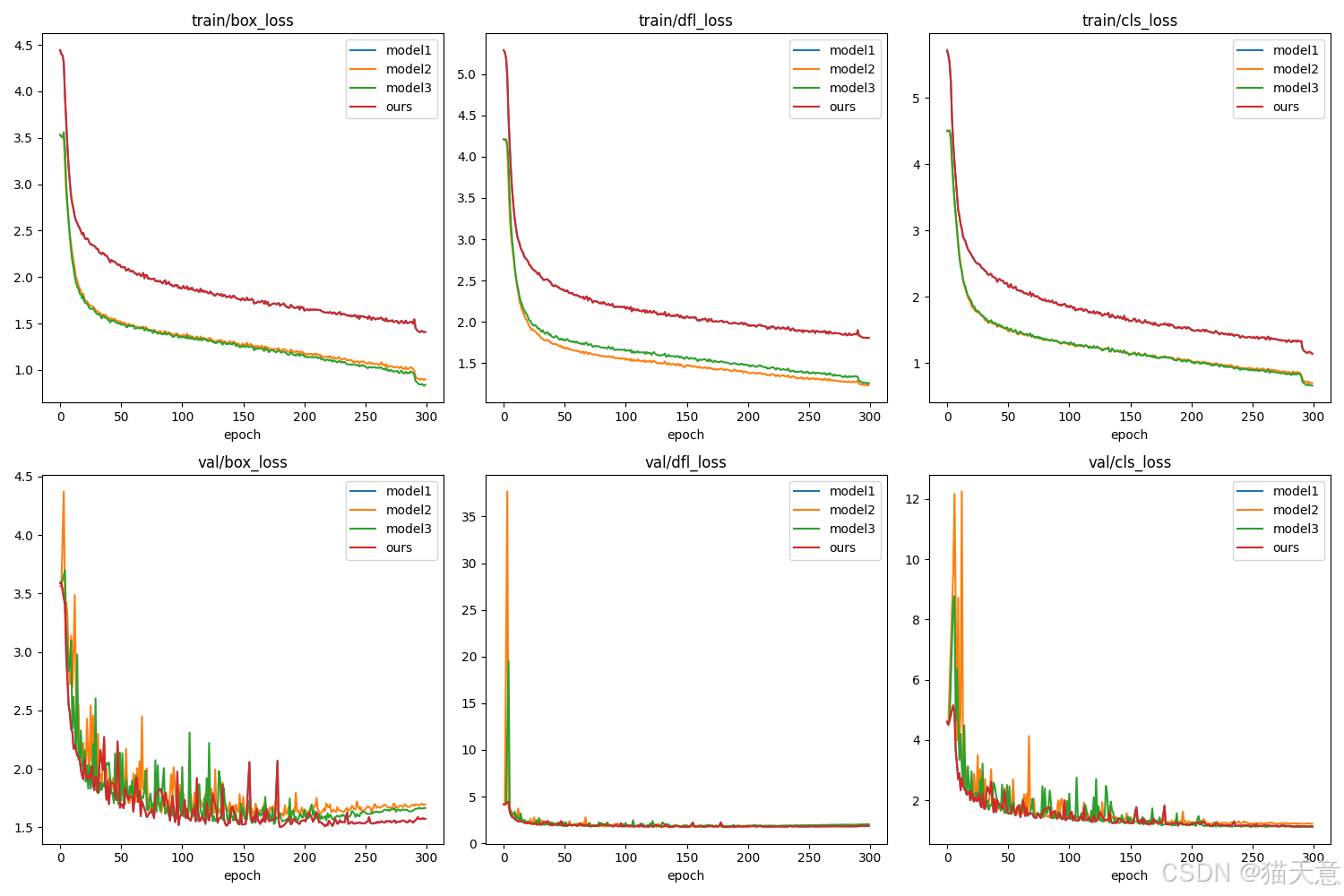
代码如下:
py
import warnings
warnings.filterwarnings('ignore')
import os
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
pwd = os.getcwd()
names = ['model1', 'model2', 'model3','ours']
plt.figure(figsize=(10, 10))
plt.subplot(2, 2, 1)
for i in names:
data = pd.read_csv(f'runs/train/{i}/results.csv')
data['metrics/precision(B)'] = data['metrics/precision(B)'].astype(np.float32).replace(np.inf, np.nan)
data['metrics/precision(B)'] = data['metrics/precision(B)'].fillna(data['metrics/precision(B)'].interpolate())
plt.plot(data['metrics/precision(B)'], label=i)
plt.xlabel('epoch')
plt.title('precision')
plt.legend()
plt.subplot(2, 2, 2)
for i in names:
data = pd.read_csv(f'runs/train/{i}/results.csv')
data['metrics/recall(B)'] = data['metrics/recall(B)'].astype(np.float32).replace(np.inf, np.nan)
data['metrics/recall(B)'] = data['metrics/recall(B)'].fillna(data['metrics/recall(B)'].interpolate())
plt.plot(data['metrics/recall(B)'], label=i)
plt.xlabel('epoch')
plt.title('recall')
plt.legend()
plt.subplot(2, 2, 3)
for i in names:
data = pd.read_csv(f'runs/train/{i}/results.csv')
data['metrics/mAP50(B)'] = data['metrics/mAP50(B)'].astype(np.float32).replace(np.inf, np.nan)
data['metrics/mAP50(B)'] = data['metrics/mAP50(B)'].fillna(data['metrics/mAP50(B)'].interpolate())
plt.plot(data['metrics/mAP50(B)'], label=i)
plt.xlabel('epoch')
plt.title('mAP_0.5')
plt.legend()
plt.subplot(2, 2, 4)
for i in names:
data = pd.read_csv(f'runs/train/{i}/results.csv')
data['metrics/mAP50-95(B)'] = data['metrics/mAP50-95(B)'].astype(np.float32).replace(np.inf, np.nan)
data['metrics/mAP50-95(B)'] = data['metrics/mAP50-95(B)'].fillna(data['metrics/mAP50-95(B)'].interpolate())
plt.plot(data['metrics/mAP50-95(B)'], label=i)
plt.xlabel('epoch')
plt.title('mAP_0.5:0.95')
plt.legend()
plt.tight_layout()
plt.savefig('metrice_curve.png')
print(f'metrice_curve.png save in {pwd}/metrice_curve.png')
plt.figure(figsize=(15, 10))
plt.subplot(2, 3, 1)
for i in names:
data = pd.read_csv(f'runs/train/{i}/results.csv')
data['train/box_loss'] = data['train/box_loss'].astype(np.float32).replace(np.inf, np.nan)
data['train/box_loss'] = data['train/box_loss'].fillna(data['train/box_loss'].interpolate())
plt.plot(data['train/box_loss'], label=i)
plt.xlabel('epoch')
plt.title('train/box_loss')
plt.legend()
plt.subplot(2, 3, 2)
for i in names:
data = pd.read_csv(f'runs/train/{i}/results.csv')
data['train/dfl_loss'] = data['train/dfl_loss'].astype(np.float32).replace(np.inf, np.nan)
data['train/dfl_loss'] = data['train/dfl_loss'].fillna(data['train/dfl_loss'].interpolate())
plt.plot(data['train/dfl_loss'], label=i)
plt.xlabel('epoch')
plt.title('train/dfl_loss')
plt.legend()
plt.subplot(2, 3, 3)
for i in names:
data = pd.read_csv(f'runs/train/{i}/results.csv')
data['train/cls_loss'] = data['train/cls_loss'].astype(np.float32).replace(np.inf, np.nan)
data['train/cls_loss'] = data['train/cls_loss'].fillna(data['train/cls_loss'].interpolate())
plt.plot(data['train/cls_loss'], label=i)
plt.xlabel('epoch')
plt.title('train/cls_loss')
plt.legend()
plt.subplot(2, 3, 4)
for i in names:
data = pd.read_csv(f'runs/train/{i}/results.csv')
data['val/box_loss'] = data['val/box_loss'].astype(np.float32).replace(np.inf, np.nan)
data['val/box_loss'] = data['val/box_loss'].fillna(data['val/box_loss'].interpolate())
plt.plot(data['val/box_loss'], label=i)
plt.xlabel('epoch')
plt.title('val/box_loss')
plt.legend()
plt.subplot(2, 3, 5)
for i in names:
data = pd.read_csv(f'runs/train/{i}/results.csv')
data['val/dfl_loss'] = data['val/dfl_loss'].astype(np.float32).replace(np.inf, np.nan)
data['val/dfl_loss'] = data['val/dfl_loss'].fillna(data['val/dfl_loss'].interpolate())
plt.plot(data['val/dfl_loss'], label=i)
plt.xlabel('epoch')
plt.title('val/dfl_loss')
plt.legend()
plt.subplot(2, 3, 6)
for i in names:
data = pd.read_csv(f'runs/train/{i}/results.csv')
data['val/cls_loss'] = data['val/cls_loss'].astype(np.float32).replace(np.inf, np.nan)
data['val/cls_loss'] = data['val/cls_loss'].fillna(data['val/cls_loss'].interpolate())
plt.plot(data['val/cls_loss'], label=i)
plt.xlabel('epoch')
plt.title('val/cls_loss')
plt.legend()
plt.tight_layout()
plt.savefig('loss_curve.png')
print(f'loss_curve.png save in {pwd}/loss_curve.png')可视化结果展示